- The paper introduces HESTIA, a Hessian-guided differentiable quantization framework that maintains gradient flow and improves optimization in extremely low-bit LLMs.
- It replaces hard rounding with temperature-controlled softmax relaxation, leveraging the Hessian trace to drive fine-grained, sensitivity-aware quantization.
- The framework achieves significant zero-shot performance gains, demonstrating improvements of 5.39% and 4.34% for 1B and 3B models, and reduces training data requirements for efficient AI deployment.
"HESTIA: A Hessian-Guided Differentiable Quantization-Aware Training Framework for Extremely Low-Bit LLMs" (2601.20745)
Introduction
LLMs are central to the progress of artificial intelligence, following clear scaling laws that enhance reasoning and generalization capability. However, the computational demands of scaling, primarily driven by memory requirements, have spurred efforts to achieve extremely low-bit quantization. Traditional quantization-aware training (QAT) methods use hard rounding and the straight-through estimator (STE), prematurely impacting the optimization landscape, causing gradient mismatch and hindering the effective optimization of quantized models. The proposed method, \mname{}, addresses these challenges with a Hessian-guided differentiable QAT framework suitable for extremely low-bit LLMs.
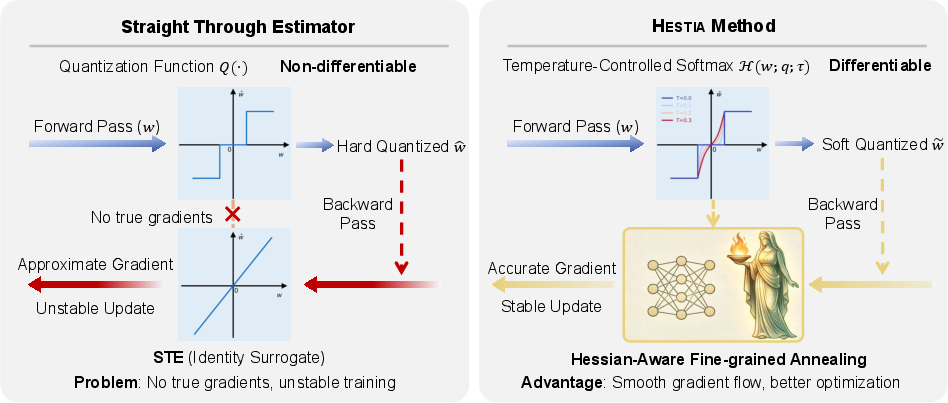
Figure 1: Overview of \mname{}, contrasting the STE with the proposed Softmax relaxation method.
Methodology
Differentiable Quantization Framework
\mname{} introduces temperature-controlled Softmax relaxation to replace rigid step functions in early training, maintaining gradient flow and progressively hardening quantization. The Hessian trace metric serves as a lightweight curvature signal to drive temperature annealing, enabling fine-grained, sensitivity-aware discretization across the model components. This approach leverages the structural heterogeneity in LLM tensors, optimizing the quantization process.
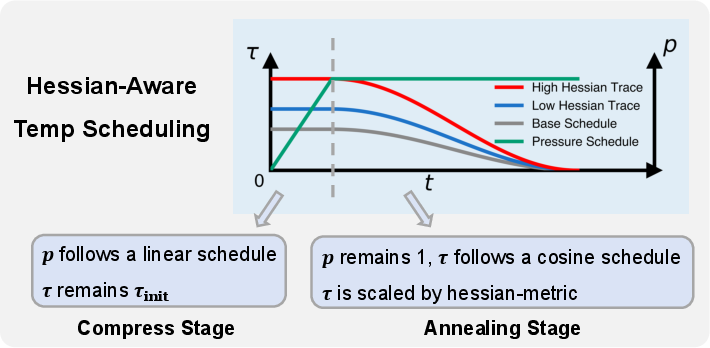
Figure 2: \mname{}'s tensor-wise fine-grained temperature annealing process, driven by the Hessian trace signal.
Theoretical Analysis
The theoretical framework of \mname{} focuses on the relaxed quantization operator H(w;τ), demonstrating exact gradient fidelity through variance modulation and establishing boundary localization as τ→0+. This optimization path smooths dead zones and prevents latent weight stagnation. The method provides well-defined gradients over the latent weight space, ensuring continuous refinement of the optimization landscape while approaching discrete state assignments.
Experimental Evaluation
Evaluations on Llama-3.2 models showcase a marked improvement over existing ternary QAT baselines. \mname{} achieves average zero-shot improvements of 5.39% and 4.34% for the 1B and 3B models respectively. These enhancements demonstrate \mname{}'s capacity to recover representational integrity in 1.58-bit LLMs.
Comparative Analysis
When comparing \mname{} against other ternary LLM frameworks across different token budgets and model sizes, \mname{} exhibits stronger zero-shot generalization. The method achieves higher accuracy scores with less training data compared to competitors, validating the impact of optimized soft-to-hard quantization schedules.
Practical Implications and Future Work
The practical implications of \mname{} revolve around its ability to optimize LLM deployment in memory-constrained environments without substantial performance loss. This framework potentially widens the accessibility of cutting-edge AI applications through efficient model compression techniques. Future work could explore expanding the adaptability of \mname{} to broader quantization settings and additional model architectures, further enhancing deployment efficiency across various platforms.
Conclusion
\mname{} represents a significant advancement in quantization-aware training for extremely low-bit LLMs. Through temperature-adjusted softmax relaxation guided by Hessian metrics, the framework successfully addresses critical optimization bottlenecks, thus maintaining robust zero-shot performance. The findings underscore the importance of adopting continuous relaxation for effective training of low-bit architectures, paving the way for more sustainable AI model scaling strategies.

