BitNet Distillation
Abstract: In this paper, we present BitNet Distillation (BitDistill), a lightweight pipeline that fine-tunes off-the-shelf full-precision LLMs (e.g., Qwen) into 1.58-bit precision (i.e., ternary weights {-1, 0, 1}) for specific downstream tasks, achieving strong task-specific performance with minimal computational cost. Specifically, BitDistill incorporates three key techniques: the SubLN module, as introduced in BitNet; multi-head attention distillation, based on MiniLM; and continual pre-training, which serves as a crucial warm-up step to mitigate the scalability issue of the performance gap between finetuned full-precision and 1.58-bit LLMs on specific tasks. Experimental results show that BitDistill achieves performance comparable to the full-precision counterpart models across model size, while enabling up to 10x memory savings and 2.65x faster inference on CPUs. Code is available at https://github.com/microsoft/BitNet.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
BitNet Distillation — a simple explanation
What is this paper about?
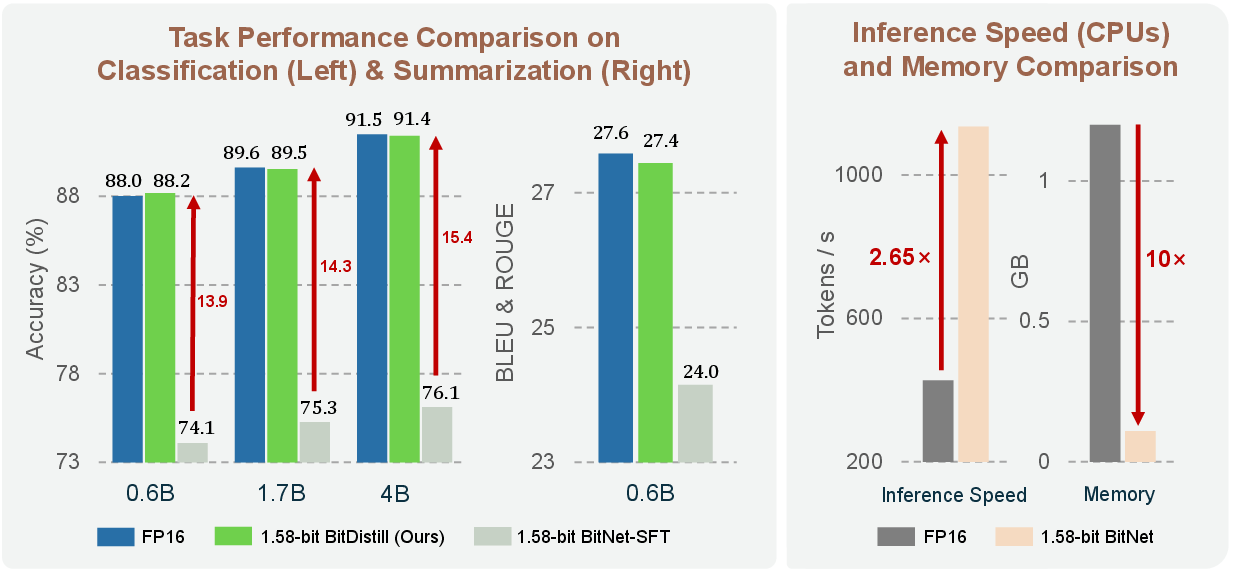
This paper shows a way to shrink big LLMs so they run fast and use very little memory, while still doing their jobs well. The trick is to turn most of the model’s numbers (its “weights”) into just three possible values: -1, 0, or 1. That’s called 1.58-bit or “ternary” weights. The authors present a recipe, called BitNet Distillation, that converts normal, full-precision LLMs (like Qwen) into these ultra-tiny versions for specific tasks (such as text classification or summarization) without losing much accuracy.
What questions are the researchers trying to answer?
- Can we turn existing, high-precision LLMs into ultra-low-bit models (only -1, 0, 1) for specific tasks without a big drop in accuracy?
- How can we make this training stable so it doesn’t crash or get stuck?
- Will this approach still work well as models get bigger?
- Does the smaller model actually run faster and use much less memory in practice?
How did they do it? (Methods explained simply)
The method has three main steps. You can think of it like getting a sports car ready for a rough, narrow road: you add stabilizers, do a warm-up lap, and then learn from a coach.
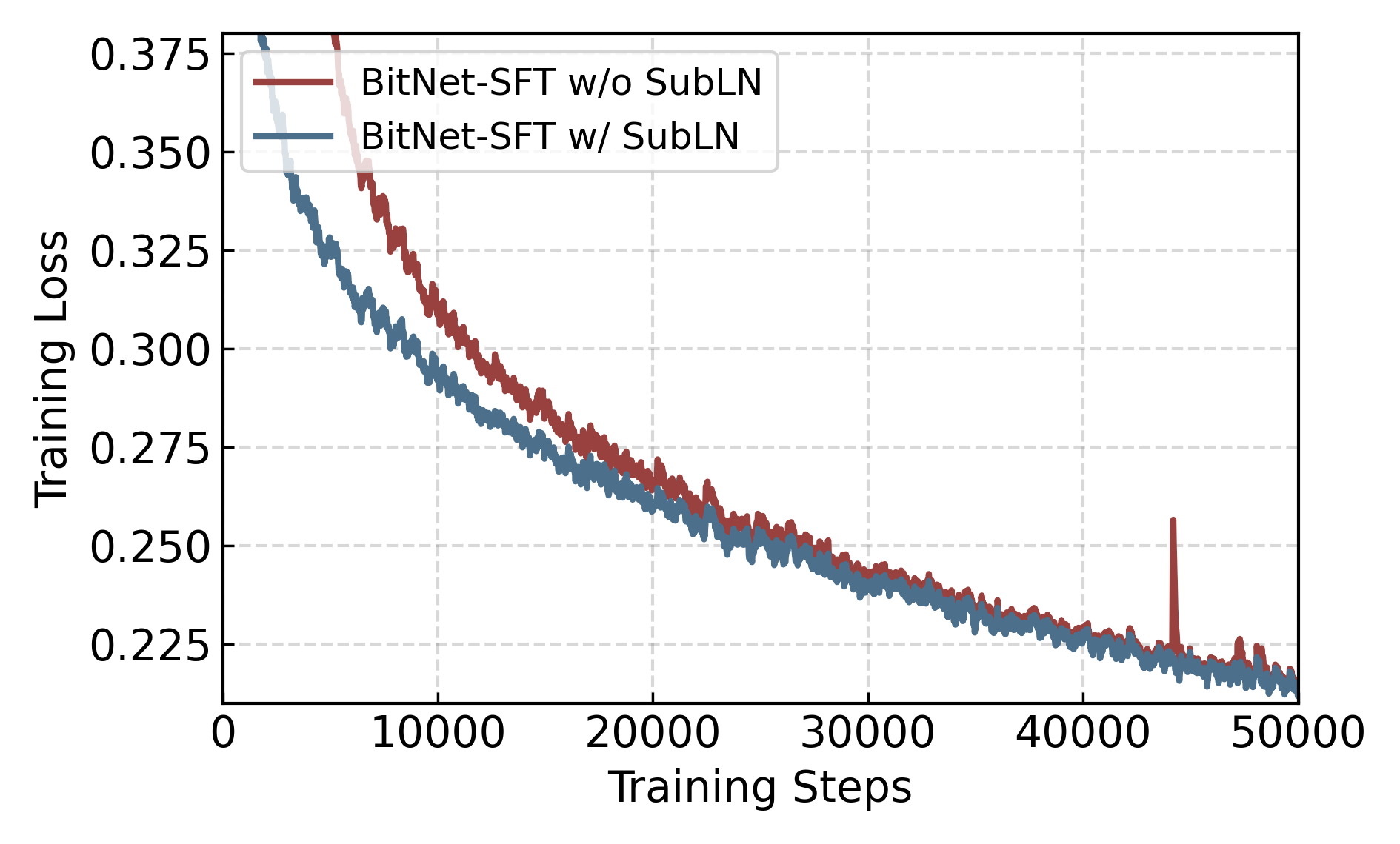
- Step 1: Add stabilizers inside the model (SubLN)
- In a Transformer (the kind of model that powers LLMs), the signals can get too loud or too quiet when you use very few bits. The authors add extra “normalization” layers (called SubLN) at key spots. These act like shock absorbers, keeping the signal levels steady so training doesn’t wobble or crash.
- Step 2: Warm-up training (Continue pre-training)
- When you suddenly force a model’s weights to be only -1, 0, or 1, it’s a big change. So the authors first give the model a light “warm-up jog” by training it for a short time on general text (about 10 billion tokens, which is tiny compared to full pre-training). This helps the model adjust to its new, super-limited “vocabulary” of weights before learning a specific task.
- Step 3: Learn from a coach (Knowledge distillation)
- A full-precision model (the teacher) guides the tiny model (the student).
- Two kinds of lessons:
- Logits distillation: The student learns to match the teacher’s final answer probabilities (like copying the teacher’s multiple-choice confidence).
- Attention distillation: The student also learns the teacher’s “attention patterns”—which words look at which other words when reading a sentence. This captures the teacher’s deeper reasoning structure.
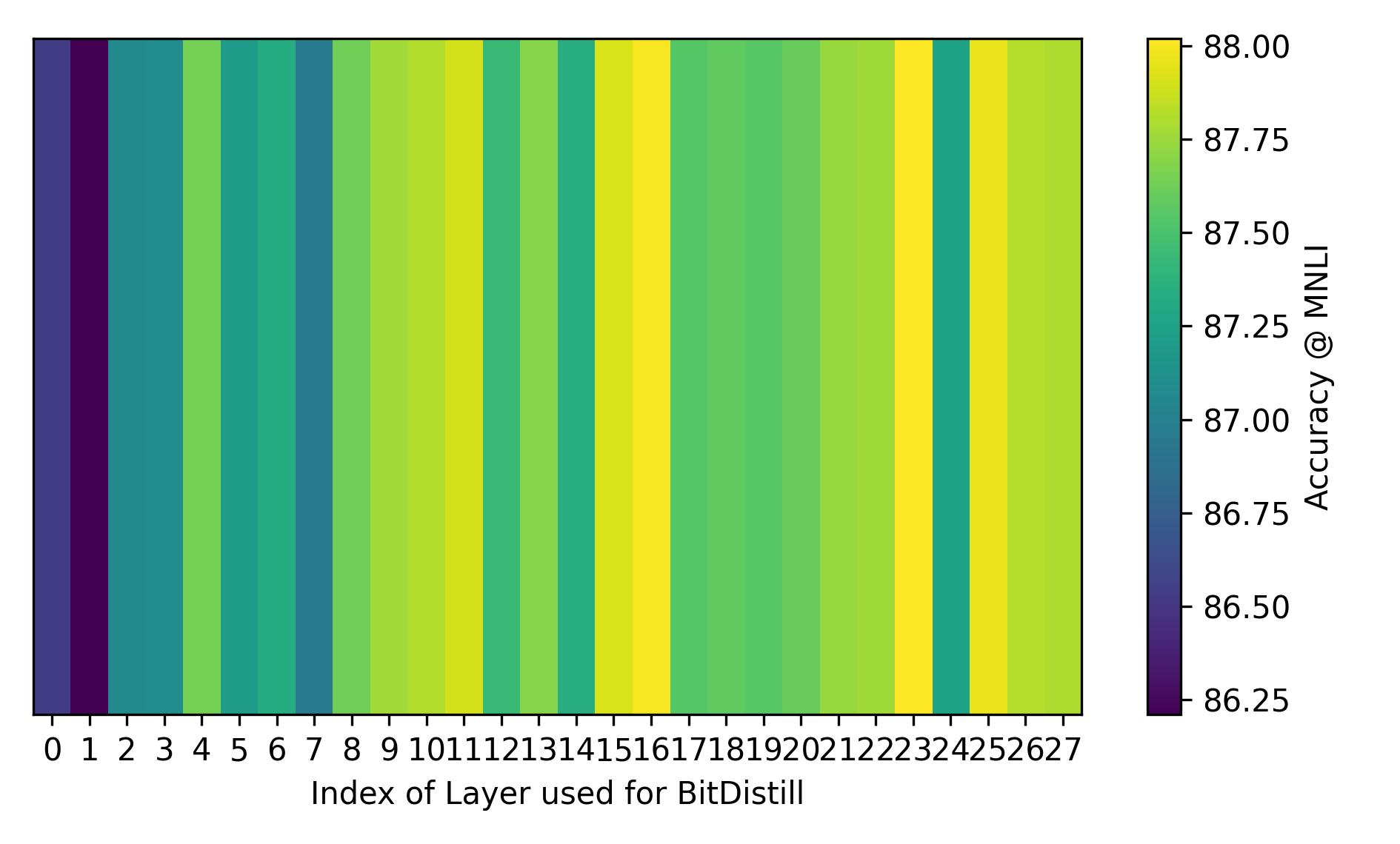
- They distill from just a single, carefully chosen layer for attention (instead of all layers). That gives the student more freedom to adjust elsewhere and improves results.
A couple of technical notes in everyday language:
- Quantization: Turning big, precise numbers into low-bit versions. Here, weights become ternary (-1, 0, 1), and activations (the model’s temporary signals) use 8 bits. This slashes memory use and speeds up inference.
- STE (Straight-Through Estimator): During training, some steps (like rounding to -1, 0, 1) aren’t smooth, which makes gradients hard to compute. STE is a common “pretend it’s smooth” trick that lets training continue and usually works well in practice.
What did they find, and why does it matter?
- Accuracy stays close to the original full-precision models
- On tasks like MNLI, QNLI, SST-2 (text classification) and CNN/DailyMail (summarization), the 1.58-bit models perform almost as well as the full models.
- Importantly, “just quantize and fine-tune” (without their method) loses a lot of accuracy, especially for bigger models. Their three-step recipe fixes that.
- Big efficiency gains
- Around 10× less memory usage.
- Up to about 2.65× faster inference on CPUs (reported with 16 threads).
- This means these models are far easier to run on laptops, servers with limited resources, or even edge devices.
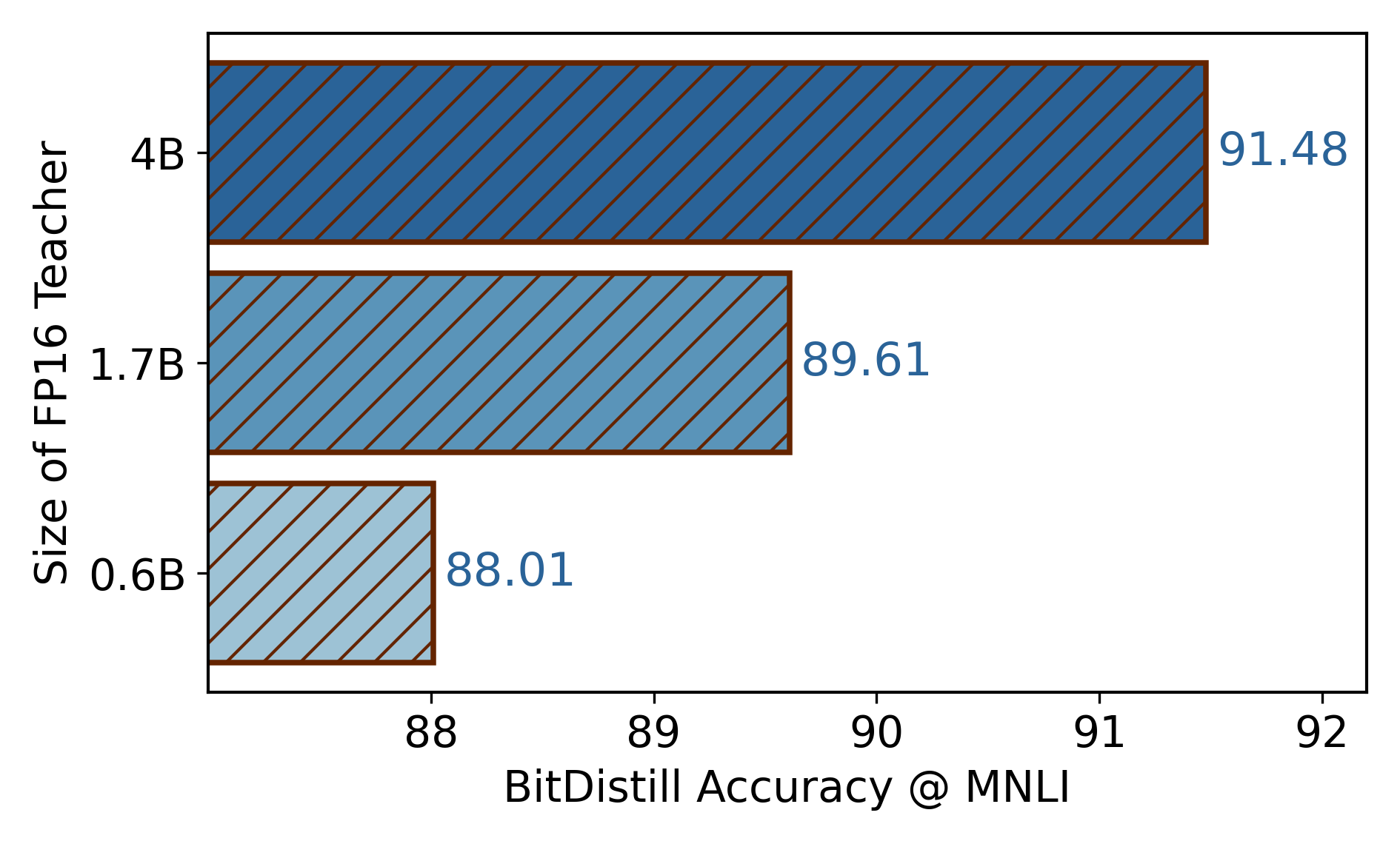
- Works across sizes and model families
- Tested on models with roughly 0.6B, 1.7B, and 4B parameters.
- Also works with different base models (like Qwen and Gemma), not just one architecture.
- Each step helps
- Experiments show the stabilizers (SubLN), warm-up training, and teacher–student learning each improve performance. Together, they deliver the best results.
- Using a stronger teacher model helps the student do even better.
- Distilling attention from a single later layer tends to work best.
Why it matters: Ultra-low-bit models are hard to train without losing quality. This work shows a practical path to keep accuracy high while making models much smaller and faster.
What’s the impact?
- Easier deployment on everyday hardware
- Cutting memory by 10× and speeding up inference makes it much more practical to run LLMs on CPUs, smaller servers, or potentially phones and embedded devices.
- Lower costs and energy use
- Faster, smaller models are cheaper to run at scale and better for the environment.
- A general recipe for tiny, task-ready models
- Their approach can plug into different quantization methods and different base models. That makes it a flexible toolkit for building compact LLMs tailored to real-world tasks.
- A step toward even tinier AI
- With a stable training path and good accuracy at 1.58 bits, future work can push limits further, making AI more accessible to everyone.
In short, BitNet Distillation shows how to turn large, powerful LLMs into tiny, efficient versions for specific jobs—without giving up much accuracy—by stabilizing training, warming up the model, and letting a full-precision teacher guide the way.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, framed as concrete, actionable items for future work.
- Evaluation scope and benchmarks
- Assess generalization beyond GLUE (MNLI, QNLI, SST-2) and CNNDM: add reasoning (e.g., GSM8K, MMLU, GPQA), instruction following (e.g., AlpacaEval, Arena-Hard), safety/harms, multilingual, code (e.g., HumanEval, LiveCodeBench), and retrieval/long-context tasks.
- Evaluate long-context stability and performance explicitly (e.g., 8k–128k tokens), including memory/speed scaling with sequence length.
- Provide zero-shot and few-shot results to understand transferability after task-specific 1.58-bit finetuning.
- Hardware efficiency and deployment realism
- Report energy/power and latency on diverse hardware (mobile CPU, ARM, GPU, NPU/TPU, edge accelerators), not just x86 CPU with 16 threads; include throughput under batch-1 streaming decode.
- Detail and open-source the ternary kernels/bit-packing used for the reported CPU speedups; quantify overheads from added SubLN and FP layers during inference.
- Measure end-to-end serving metrics (token-latency distribution, tail latency, memory bandwidth constraints) and KV-cache memory/compute benefits.
- Quantization design details and missing components
- Clarify and evaluate quantization of embeddings, output (unembedding) layer, LayerNorm/GroupNorm parameters, and biases; specify which remain FP16/FP32 and measure accuracy/speed trade-offs if also quantized.
- Quantize and evaluate the KV cache and attention softmax pathways (including numerical stability of softmax/scaling), not only weights and 8-bit activations.
- Resolve inconsistencies in the activation quantization description (per-token absmax vs absmean usage) and compare calibration choices (absmax, absmean, percentile) on accuracy and stability.
- Provide a principled study of STE variants (e.g., clipped STE, piecewise-linear surrogates) and their bias/variance impacts under 1.58-bit constraints.
- Methodological ambiguities and ablations
- Precisely specify SubLN insertion for multiple architectures (Llama, Gemma, Mixtral/MoE); test where/when SubLN is necessary and quantify its inference-time overhead.
- Systematically explore which single layer to use for attention-relation distillation across model sizes and tasks; propose an automatic selection criterion (e.g., gradient-based or CKA similarity).
- Perform sensitivity analyses over distillation hyperparameters (temperature τ, λ, γ, split_heads, chosen relational matrices) and report robustness across random seeds.
- Quantify the separate contributions of logits vs attention distillation under varied data sizes and teacher quality; test cross-architecture teachers (e.g., Gemma teacher for Qwen student).
- Continual pretraining (CT) design and cost
- Justify the choice of 10B tokens: sweep 0–20B (e.g., 0/1/2/5/10/20B) and characterize the accuracy–cost curve; report actual wall-clock and GPU-hour costs for each model size.
- Study domain effects: compare CT on task-relevant vs generic corpora, and measure domain mismatch sensitivity.
- Analyze catastrophic forgetting and cross-task interference introduced by CT; assess post-CT general LM quality (perplexity on held-out corpora).
- Baselines and comparative positioning
- Add direct comparisons to strong QAT/distillation baselines for ultra-low-bit LLMs (e.g., BitDistiller, TSLD, QLoRA+QAT hybrids, mixed-precision ternary schemes) under matched settings.
- Clarify how GPTQ/AWQ/Block-Quant were integrated in a 1.58-bit setting (these are typically 3–8 bit weight-only PTQ): define the exact configuration and ensure apples-to-apples comparisons.
- Scalability and limits
- Extend scaling experiments beyond 4B (e.g., 7B, 13B) to validate the claimed scalability and investigate when/why performance gaps reappear.
- Examine mixed-precision strategies (e.g., keeping attention output or first/last layers in higher precision) to map Pareto frontiers of accuracy vs memory/latency.
- Robustness, reliability, and safety
- Evaluate robustness to distribution shift, noise/adversarial perturbations, and calibration quality (ECE/Brier score) after ternarization and distillation.
- Investigate numerical stability and gradient pathologies (exploding/vanishing activations) introduced by SubLN and STE under different seeds and tasks.
- Theoretical understanding and diagnostics
- Provide a more formal justification for why CT reshapes weight distributions toward “BitNet-like” optima; test whether the observed histogram changes causally drive accuracy gains (e.g., intervention experiments).
- Analyze optimization landscapes under ternary constraints: track flip rates of ternary weights, sparsity patterns (proportion of zeros), and their correlation with task accuracy.
- Reproducibility and reporting
- Report variance across multiple runs, confidence intervals, and statistical significance for all tables; include complete training/evaluation recipes and seeds.
- Resolve minor inconsistencies (e.g., 2× vs 2.65× CPU speedup claims) and state the exact evaluation settings used for speed and memory metrics (sequence length, batch size, beam/greedy decode).
- Practical deployment and integration
- Study compatibility with LoRA/adapter methods on top of 1.58-bit backbones for rapid task retargeting without re-quantization.
- Evaluate privacy/security implications of using full-precision teachers (e.g., data leakage through distillation) and propose privacy-preserving distillation options.
Practical Applications
Immediate Applications
The following applications can be deployed today using the paper’s pipeline (SubLN-based model surgery, short continual pre-training, and MiniLM-style attention/logit distillation) to convert existing FP16 LLMs into 1.58-bit task-specific models with up to 10× memory savings and ~2.65× faster CPU inference.
- Task-specific LLM services on CPUs for text classification and summarization
- Sectors: software, cloud/SaaS, telecom, retail, public sector, finance
- Use cases: intent routing for support tickets; sentiment and topic tagging; policy/document triage; meeting/email/news summarization; log anomaly classification in DevOps
- Tools/workflow: “Distill-and-Deploy” pipeline (SubLN patch → 10B-token continual pre-training → LD+AD distillation → export for CPU inference with INT8 activations and ternary weights); integrate with HuggingFace and ONNX runtimes
- Assumptions/Dependencies: access to FP16 teacher weights; modest pretraining corpus (~10B tokens); CPU integer-friendly kernels for ternary matmul (BitNet library); task distribution similar to evaluated domains
- Cost and energy reduction in cloud inference
- Sectors: cloud platforms, enterprise IT, energy/sustainability
- Use cases: replace FP16 microservices for classification endpoints with 1.58-bit variants to increase per-node capacity, reduce RAM, and lower energy bills
- Tools/workflow: Kubernetes/Autoscaling profiles for CPU-only LLM endpoints; observability for tokens/sec, memory/latency, and energy KPIs
- Assumptions/Dependencies: workload fits single-turn inference (classification/summarization); predictable latency SLAs; conservative rollout with A/B guardrails
- Privacy-preserving on-device analytics
- Sectors: healthcare, finance, education, government
- Use cases: offline summarization of sensitive documents; local form processing; triage of patient messages; KYC document classification on secure laptops
- Tools/workflow: packaged desktop/mobile apps embedding 1.58-bit models; local inference without data egress
- Assumptions/Dependencies: device CPU performance sufficient for sequence lengths used; governance for local model updates; domain fine-tuning data available
- MLOps pipeline for low-bit model release
- Sectors: software, platform engineering
- Use cases: CI/CD job that compresses every new task model to 1.58-bit, runs accuracy/latency checks, and publishes artifacts
- Tools/workflow: SubLN patcher library; distillation layer auto-selector (late-layer AD by default); teacher selection heuristic (larger FP16 teacher if available); hyperparameter sweeps for λ/γ/τ
- Assumptions/Dependencies: reproducible training environments; calibration datasets; robust monitoring to catch rare instability
- Edge NLP in robotics and embedded systems
- Sectors: robotics, IoT, manufacturing
- Use cases: onboard intent classification for voice commands; quick summary of maintenance logs; lightweight task routing on gateways
- Tools/workflow: ROS nodes using CPU kernels; INT8 activations and ternary weights reduce memory pressure on embedded CPUs
- Assumptions/Dependencies: available integer GEMM kernels; tasks constrained to short prompts/outputs; careful profiling on target hardware
- Developer productivity workflows
- Sectors: software engineering
- Use cases: PR triage and code-change summarization in CI; log categorization; issue deduplication
- Tools/workflow: GitHub Actions or GitLab runners executing CPU-only 1.58-bit inference; caching of quantized models
- Assumptions/Dependencies: stable accuracy at typical CI token lengths; permission to run distilled models in pipelines
- Education and accessibility tools running locally
- Sectors: education, consumer apps
- Use cases: summarize reading passages on classroom Chromebooks; personalize study notes without Internet
- Tools/workflow: local apps bundling small 1.58-bit models; simple UI for input/output
- Assumptions/Dependencies: teachers/students can operate within supported sequence lengths; curated domain data for fine-tuning
- Quantization-aware model catalog offerings
- Sectors: model marketplaces, enterprises
- Use cases: productize “BitNet-D” variants of popular backbones (Qwen/Gemma) per task with selectable quantization (min–max, AWQ, GPTQ) plus distillation
- Tools/workflow: catalog API; automated conversion scripts; model cards documenting SubLN changes and distillation settings
- Assumptions/Dependencies: licensing for base models; cross-model compatibility validated; customer datasets for task adaptation
Long-Term Applications
These applications require further R&D, scaling, validation, or hardware co-design to realize.
- General-purpose 1.58-bit assistants on phones and laptops
- Sectors: consumer software, mobile OEMs
- Use cases: conversational assistance, multitask reasoning, multimodal summarization entirely on-device
- Tools/workflow: expanded continual pre-training beyond 10B tokens; broader distillation objectives (reasoning, tool use); runtime optimized for long contexts
- Assumptions/Dependencies: verified quality parity on complex tasks; memory-efficient attention and KV-cache strategies; UX constraints on latency
- Ternary-aware hardware acceleration
- Sectors: semiconductor, mobile SoC, data center
- Use cases: NPU/DSP/ASIC kernels optimized for ternary weights and INT8 activations; compiler support for BitNet ops
- Tools/workflow: co-designed kernels, quantization-friendly tiling; ONNX/TFLite custom ops; vendor SDKs
- Assumptions/Dependencies: ecosystem adoption; stable operator definitions; sustained demand for low-bit inference at scale
- Federated continual distillation at the edge
- Sectors: telecom, IoT, retail
- Use cases: fleets of devices perform small-scale continual training and push updates to improve local 1.58-bit models while preserving privacy
- Tools/workflow: privacy-preserving aggregation; robustness to data heterogeneity; on-device token budgets
- Assumptions/Dependencies: secure update pipelines; resilience to drift; energy-aware scheduling
- Certified low-bit models for regulated domains
- Sectors: healthcare, legal, finance, public sector
- Use cases: clinical summarization, legal document triage, audit-friendly classification
- Tools/workflow: validation protocols; bias/robustness testing; documentation linking distillation to risk controls
- Assumptions/Dependencies: regulatory acceptance of low-bit compression; domain-specific benchmarks; provenance tracking
- Adaptive mixed-precision runtimes
- Sectors: cloud, edge platforms
- Use cases: dynamic bit-width switching (1.58-bit to 4/8-bit) per layer or per request to balance accuracy/latency in real time
- Tools/workflow: controllers that adjust bits based on content or SLA; telemetry-driven policies
- Assumptions/Dependencies: reliable accuracy–latency trade-off models; seamless kernels for bit transitions; guardrails to prevent instability
- Multimodal low-bit LLMs (text + vision/audio)
- Sectors: media, accessibility, industrial inspection
- Use cases: local captioning, meeting transcription + summarization, report generation from images
- Tools/workflow: extend SubLN and distillation to multimodal encoders/decoders; quantization of cross-attention blocks
- Assumptions/Dependencies: new quantization/diffusion-friendly ops; additional teacher signals; task-specific evaluation
- Automated distillation services and layer selection
- Sectors: MLOps, model tooling
- Use cases: “push a FP16 model, get a task-tuned 1.58-bit model” with auto-search for best distillation layer(s) and teacher size
- Tools/workflow: Auto-AD layer search; teacher-size optimizers; hyperparameter tuning (λ, γ, τ)
- Assumptions/Dependencies: stable search heuristics across backbones; scalable orchestration; reproducibility guarantees
- Sustainability-aligned AI operations
- Sectors: data center operations, sustainability
- Use cases: CPU-first LLM scheduling aligned with renewable availability; capacity planning using low-bit models to cut emissions
- Tools/workflow: carbon-aware job schedulers; energy dashboards; model placement optimizers
- Assumptions/Dependencies: accurate energy telemetry; operational buy-in; end-to-end emissions accounting
- Standardization of low-bit model formats and governance
- Sectors: standards bodies, open-source
- Use cases: define .bit weight formats, metadata for SubLN/quantization settings, and reproducibility specs for distillation
- Tools/workflow: model cards with compression details; governance policies for compressed models
- Assumptions/Dependencies: community consensus; backward-compatible tooling; vendor support
- Autonomous systems using low-bit language interfaces
- Sectors: autonomous vehicles/drones, smart manufacturing
- Use cases: compact NLP modules for status reporting, intent interpretation, and task summaries onboard
- Tools/workflow: integration with real-time systems; safety-certified inference paths
- Assumptions/Dependencies: latency determinism; safety validation; expanded task coverage beyond current benchmarks
Notes on feasibility across all applications:
- Accuracy claims are demonstrated on classification and summarization; generalization to complex reasoning or multi-turn dialogue requires further validation.
- Training stability depends on SubLN placement, STE approximations, and distillation hyperparameters; misconfiguration can degrade performance.
- Continual pre-training cost (10B tokens) is far smaller than pretraining from scratch (~4T), but still non-trivial for some teams.
- Benefits are measured on CPUs (16 threads); gains may differ on GPUs/NPUs without ternary-optimized kernels.
- Licensing and data governance for teacher models and adaptation corpora must be respected.
Glossary
- 1.58-bit quantization: An extreme low-bit scheme that maps model weights to ternary values to drastically reduce memory and accelerate inference. "we focus on fine-tuning existing LLMs to 1.58-bit for specific downstream tasks"
- 8-bit activation quantization: Quantizing activations to 8-bit integers to reduce compute and memory during inference and training. "For LLM inputs, we employ 8-bit activation quantization."
- absmax: The absolute maximum value operation used to scale activations during quantization. "we use per-token absmax and absmean functions to quantize the activations"
- absmean: The mean of absolute values used to scale weights or activations for quantization. "we adopt per-tensor quantization using the absmean function"
- AWQ: Activation-aware weight quantization; a PTQ method improving accuracy under low-bit weight quantization. "B, G, A indicates Block Quant, GPTQ and AWQ, respectively."
- BLEU: A metric for evaluating text generation quality via n-gram overlap with references. "Summarization quality is assessed using BLEU and ROUGE-1, ROUGE-2, ROUGE-L and ROUGE-SUM."
- Block Quant: A block-wise post-training quantization method for neural network weights. "B, G, A indicates Block Quant, GPTQ and AWQ, respectively."
- GPTQ: A PTQ method that approximates quantization error by solving a local least-squares problem for weight blocks. "B, G, A indicates Block Quant, GPTQ and AWQ, respectively."
- Kullback–Leibler divergence: A statistical measure of difference between two probability distributions used in distillation losses. "$\mathcal{D}_{\text{KL}(\cdot\parallel\cdot)$ represents the KullbackâLeibler divergence."
- Logits distillation: Transferring knowledge by matching the softened output distributions of teacher and student models. "Logits distillation has recently been widely adopted in the QAT phase of quantized models, demonstrating promising effectiveness"
- MiniLM: A distillation approach focusing on attention relations to compress models while preserving performance. "multi-head attention distillation, based on MiniLM"
- Multi-Head Attention Distillation: Distilling attention relation patterns from a teacher to a student to capture structural dependencies. "MiniLM-based~\citep{wang2020minilm,wang2020minilmv2} multi-head attention distillation to recover full-precision accuracy."
- Multi-Head Self-Attention (MHSA): The transformer mechanism computing attention in multiple parallel heads to model token dependencies. "Multi-Head Self-Attention (MHSA) module"
- Per-tensor quantization: Using a single scale per tensor when quantizing weights. "we adopt per-tensor quantization using the absmean function"
- Per-token quantization: Using scales computed per token to quantize activations, improving dynamic range handling. "we use per-token absmax and absmean functions to quantize the activations"
- Post-training quantization (PTQ): Quantizing a trained model using calibration data without full retraining. "Post-training quantization (PTQ) like GPTQ~\citep{frantar2022gptq} and AWQ~\citep{lin2024awq} has been extensively studied for weight-only quantization of LLMs."
- Quantization-aware training (QAT): Training with quantization in the loop to preserve accuracy under low-bit constraints. "directly applying quantization-aware training (QAT) to existing full-precision LLMs at 1.58-bit for specific downstream tasks is often unstable"
- ROUGE: A family of recall-oriented metrics (e.g., ROUGE-1/2/L/SUM) for summarization quality evaluation. "Summarization quality is assessed using BLEU and ROUGE-1, ROUGE-2, ROUGE-L and ROUGE-SUM."
- RoundClip: A rounding operation with clamping to a specified interval, used in quantization functions. "Due to the presence of non-differentiable operations in Eq.~\ref{eq: weight} and Eq.~\ref{eq: activation} (e.g., \text{RoundClip})"
- Scaled dot-product attention: Computing attention via scaled dot products of queries and keys followed by a Softmax. "derived by applying scaled dot-product attention followed by \text{Softmax} with hidden dimension "
- Straight-Through Estimator (STE): A gradient approximation method that passes gradients through non-differentiable quantization ops. "we employ the Straight-Through Estimator (STE)~\citep{bengio2013ste} to approximate gradients for 1.58-bit quantized LLMs."
- SubLN: Additional normalization layers inserted to stabilize activation variance before quantized projections. "we introduce additional normalization layers named SubLN at carefully chosen positions inside each transformer block."
- Ternary weights: Weight values restricted to three levels (−1, 0, 1) for extreme low-bit models. "1.58-bit precision (i.e., ternary weights \{-1, 0, 1\})"
- Variance stabilization: Techniques to keep hidden-state variance within a stable range to improve optimization. "hidden representations entering quantized projection layers are variance-stabilized"
- Weight-only quantization: Quantizing model weights while keeping activations in higher precision. "has been extensively studied for weight-only quantization of LLMs."
Collections
Sign up for free to add this paper to one or more collections.

