- The paper introduces a novel low-bit PTQ method that employs a DeltaLoss sensitivity metric to drive layer-wise optimized bit allocation.
- It integrates a lightweight pre-tuning scale search with dynamic programming for adaptive quantization, achieving near full-precision accuracy even at 2-bit settings.
- Experimental results on LLaMA and Qwen families show performance within 1% of 4–5 bit baselines, highlighting practical LLM deployment potential.
SignRoundV2: Closing the Performance Gap in Extremely Low-Bit Post-Training Quantization for LLMs
Introduction and Motivation
Efficient deployment of LLMs at scale is hindered by the significant memory and compute costs associated with full-precision inference. Post-training quantization (PTQ) offers a practical solution by compressing model weights and activations to lower bit-widths, but at extreme low-bit settings (especially 2 bits), accuracy loss is typically prohibitive absent costly re-training or distillation. The "SignRoundV2" framework addresses this limitation, introducing methodological innovations for 2- to 4-bit quantization without requiring mixed-precision, expensive retraining, or specialized hardware. The approach centers on two technical contributions: a layer-wise sensitivity metric that fuses gradient and quantization-induced deviations, and a lightweight pre-tuning search for optimal quantization scale initialization.
Methodology
Quantization Framework and Extensions
Building on SignRoundV1, which incorporates sign-based gradient descent for rounding optimization, SignRoundV2 maintains the core quantize-dequantize (qdq) operation, expanding it with new adaptive and calibration strategies. The quantization process jointly optimizes rounding parameters and scaling, with bit allocations determined per layer to meet a global bit budget.
DeltaLoss Sensitivity Metric
A central advance in SignRoundV2 is the DeltaLoss metric, which accurately gauges a layer's sensitivity to quantization. Earlier approaches, such as those utilizing the Hessian or Fisher information matrix, fail to robustly correlate with direct task loss under significant perturbation and often lead to suboptimal mixed-precision allocations. DeltaLoss leverages a first-order Taylor expansion of the loss with respect to both weights and activations, combining gradient information with the quantization-induced deviation:
ΔL≈∣gaq∘(Af−Aq)∣+∣gwq∘(Wf−Wq)∣
Empirically, activation quantization dominates in loss recovery, so the metric primarily tracks ∣gaq∘(Af−Aq)∣. This provides direct guidance for adaptive bit-width allocation and significantly improves correlation with task-aware loss.
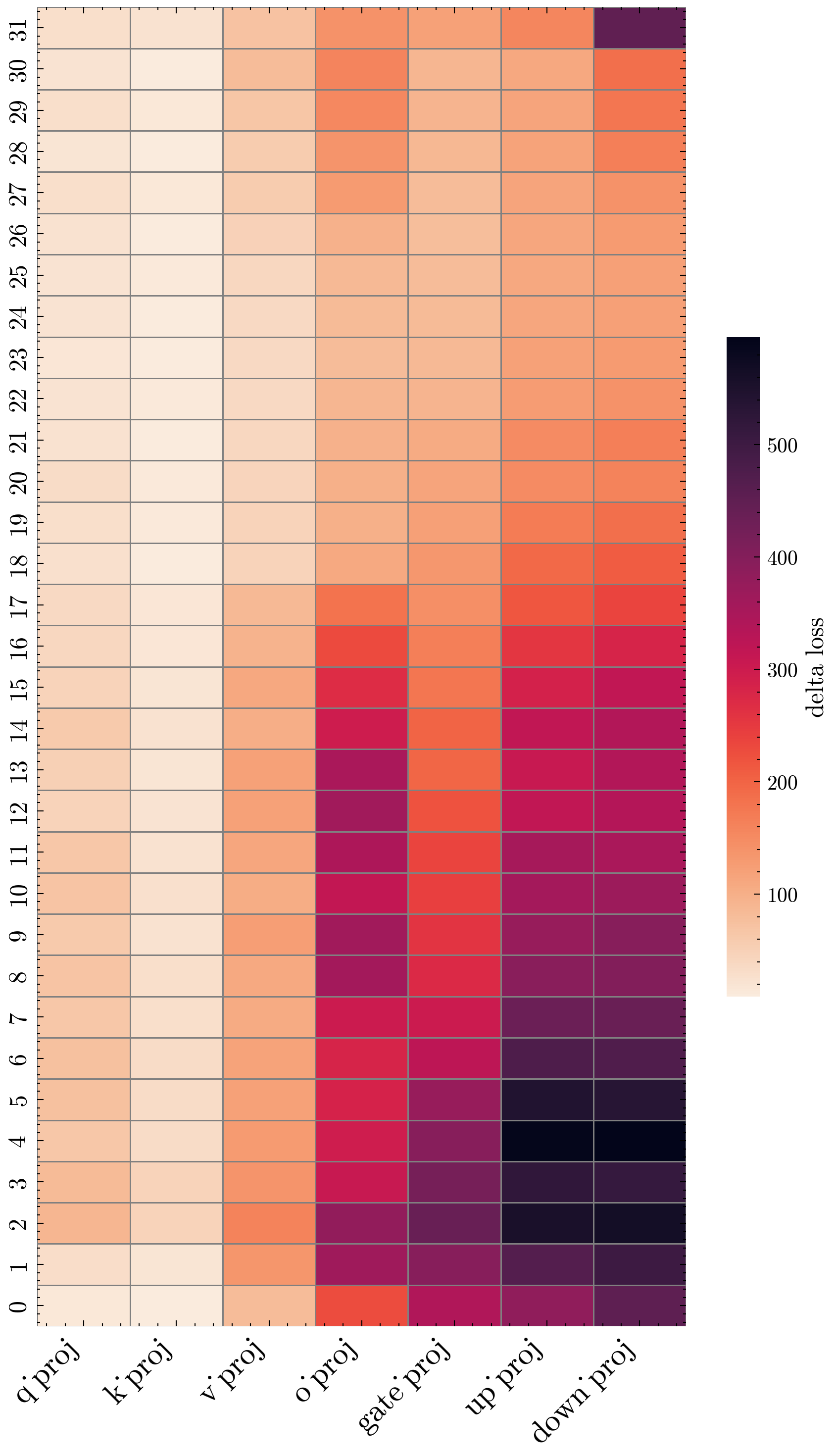
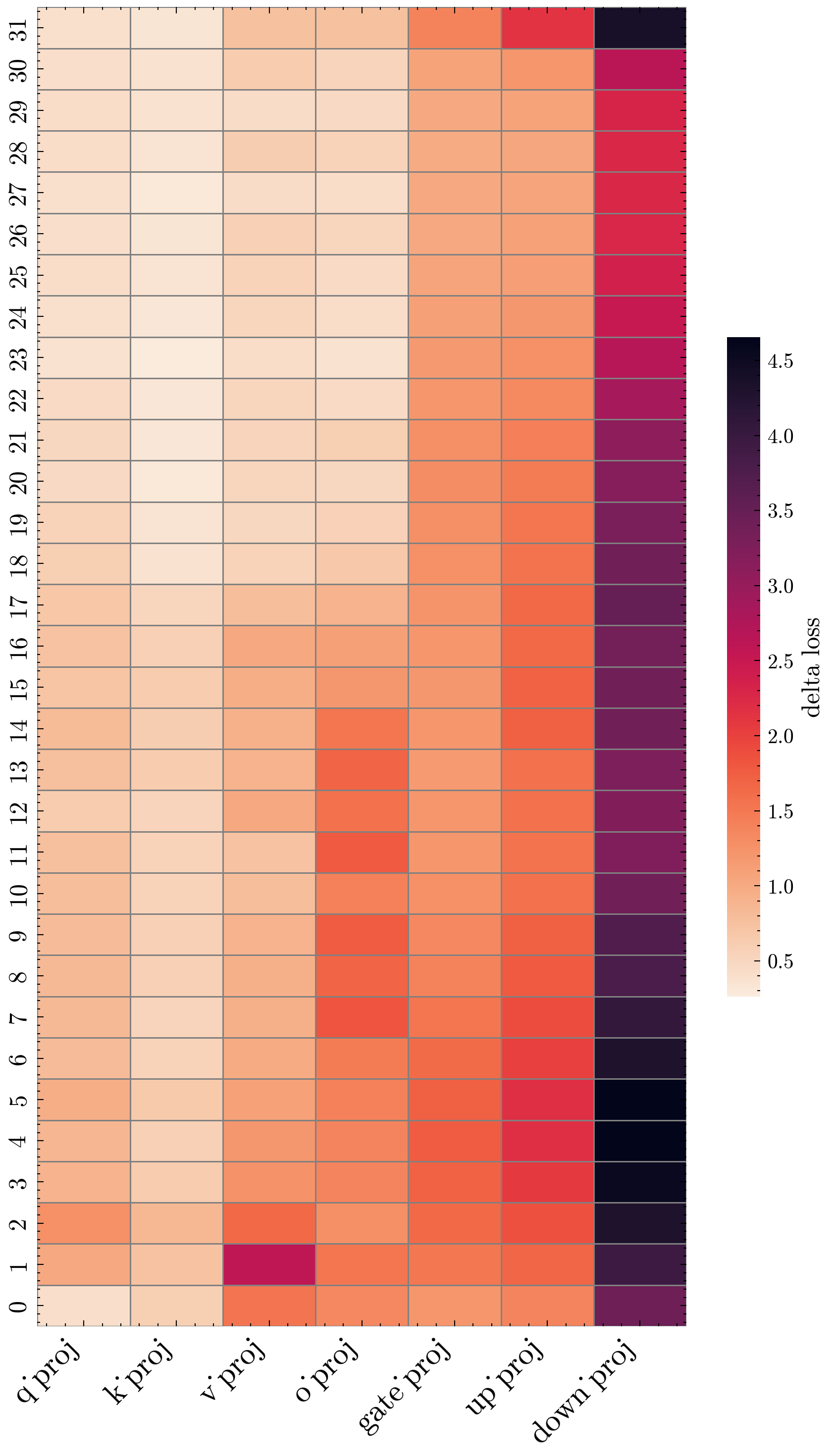
Figure 1: Layer-wise DeltaLoss sensitivity for Llama-3.1-8B-Instruct under W2A16, capturing high-variance sensitivity among layers, especially for the down_proj submodules.
Dynamic Programming Bit Allocation
Given a global average bit constraint, SignRoundV2 formulates layer-wise bit allocation as a discrete optimization over allowed bit choices, minimizing the sum of DeltaLoss across all layers while enforcing the target bit budget. The solution proceeds via dynamic programming, ensuring computational tractability even for multi-billion parameter LLMs.
Lightweight Pre-Tuning Scale Search
Accurate and stable quantization at low bits is notably sensitive to scale initialization. Drawing inspiration from importance matrices in Llama.cpp, SignRoundV2 executes a fast grid search for scale assignment prior to the main tuning phase, leveraging calibration data to minimize output deviation efficiently. This step yields a superior starting point for optimization, especially critical as bit-width approaches the information-theoretic minimum.
Additional Practical Details
SignRoundV2 includes strategies such as batch-wise exclusion of outlier losses and use of automatic mixed precision during optimization, facilitating improved stability and resource efficiency during tuning. Hyperparameters are set for consistency and practical runtime, with further accuracy enabled via a high-cost variant (Ours*) that increases step count and calibration samples.
Experimental Results
Accuracy under Extreme Low-Bit Quantization
SignRoundV2 is extensively evaluated on both LLaMA and Qwen model families using The Pile for calibration and standard benchmarks (ARC-Challenge, ARC-Easy, HellaSwag, PIQA, WinoGrande, etc.). In pure 2-bit W2A16 quantization on Llama 2/3 70B, SignRoundV2 achieves strong accuracy, outperforming PTQ baselines such as GPTQ, AWQ, OmniQuant, and SignRoundV1. Notably, at 2 bits, SignRoundV2 attains production-grade performance within roughly 1% of baseline accuracy at 4–5 bits.
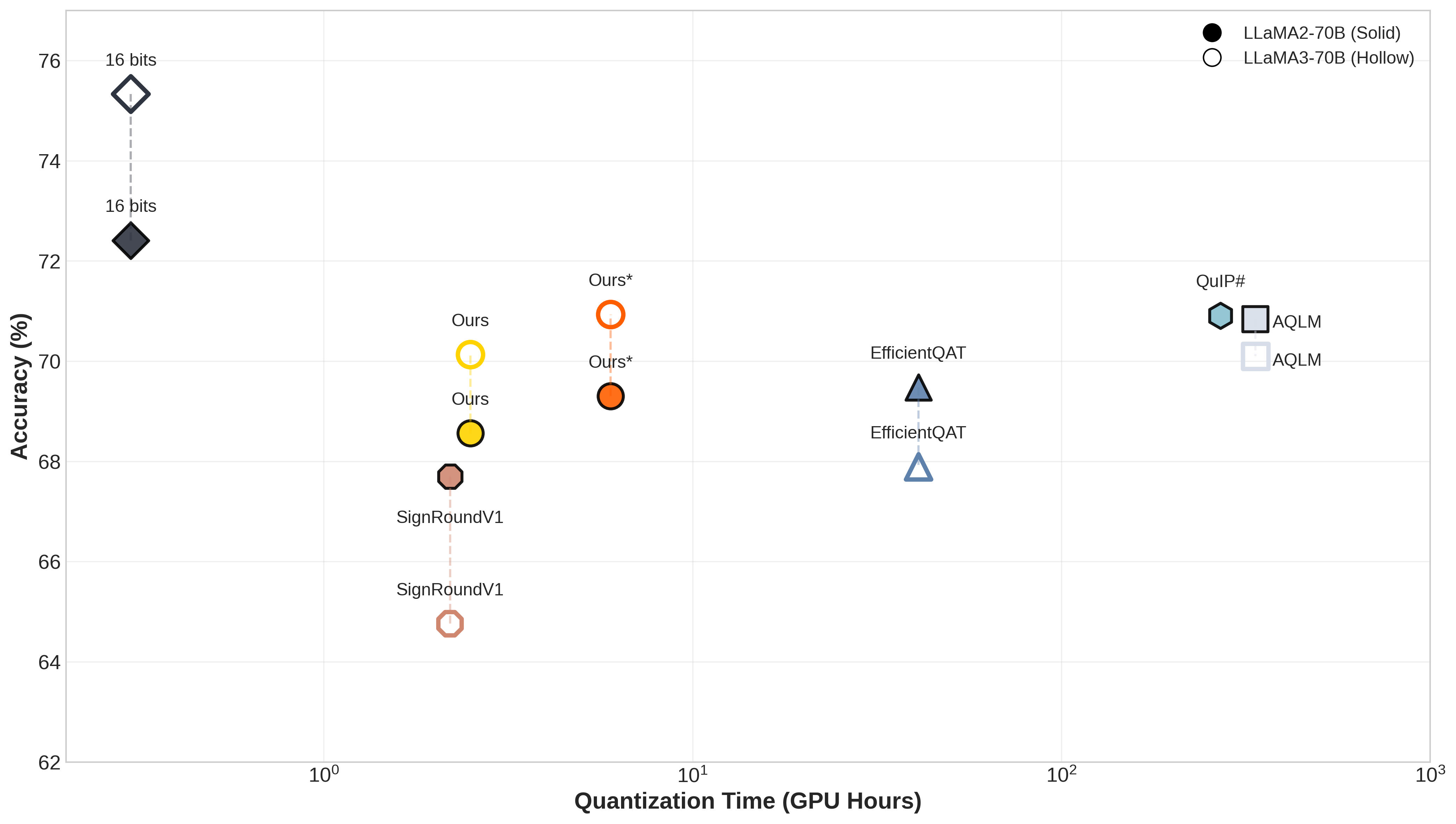
Figure 2: Average accuracy of pure 2-bit (W2A16) models on Llama 2/3 70B, highlighting competitive performance of SignRoundV2 relative to full-precision models and PTQ baselines.
At higher precision regimes (4–6 bits, MXFP4), SignRoundV2 approaches or matches full-precision accuracy, demonstrating recovery rates of 99% or higher on all tested models under mixed-precision budgets. The DeltaLoss-only (DL) variant further demonstrates that the sensitivity metric alone, even without subsequent fine-tuning, provides a superior bit allocation strategy compared to simple heuristics (e.g., head/tail 8-bit fallback).
Ablation and Cost
Ablation studies confirm that lightweight scale initialization materially improves accuracy and stability, especially under group-wise quantization. Importantly, the run-time and VRAM costs of DeltaLoss computation and full quantization remain practical even for 70B-scale models (2.5–6 GPU hours on A100-80GB), vastly undercutting QAT and related methods by orders of magnitude.
Implications and Discussion
SignRoundV2 demonstrates that high-accuracy, extremely low-bit quantization of LLMs is tractable via principled, task-aware layer sensitivity measurement and efficient bit allocation. Key implications include:
- Practical LLM Serving: SignRoundV2 brings sub-4-bit PTQ close to production viability, with negligible memory and compute overhead relative to full-precision, removing significant barriers to wide LLM deployment on consumer GPUs and edge hardware.
- Mixed vs. Uniform Precision: The results show that adaptive, data-driven bit assignment outperforms both uniform schemes and simple heuristics, suggesting a broader role for sensitivity-informed quantization in future efficient LLM design.
- Method Portability and Framework Limitations: The dependence on gradient computation constrains applicability in non-autodifferentiable frameworks such as ONNX. This limitation may drive new research in data-free or sensitivity-approximate methods.
- Scaling and Model Size: Extremely low-bit PTQ remains more challenging for small models, with a residual gap to full-precision at 2 bits unless mixed-precision or modest tuning cost is introduced.
Theoretical and Future Directions
The work suggests new opportunities in data-driven quantization, such as dynamic quantization during inference, further reduction in calibration data, or integration with sparsity and pruning for compound model compression. There is also scope for extending the approach to mixture-of-expert (MoE) architectures and for automated end-to-end compression pipelines leveraging sensitivity metrics as input to reinforcement learning–based hardware-aware quantization agents.
Conclusion
SignRoundV2 delivers a robust methodology for accurate, extremely low-bit PTQ of LLMs, uniting a principled sensitivity metric with adaptive bit-width assignment and lightweight scale initialization. The method enables competitive accuracy at 2–5 bits, minimal compute overhead, and immediate value for practical LLM deployment scenarios. It sets a foundation for future research into ultra-efficient, scalable, and hardware-aligned LLM inference.

