Self-Distillation Enables Continual Learning
Abstract: Continual learning, enabling models to acquire new skills and knowledge without degrading existing capabilities, remains a fundamental challenge for foundation models. While on-policy reinforcement learning can reduce forgetting, it requires explicit reward functions that are often unavailable. Learning from expert demonstrations, the primary alternative, is dominated by supervised fine-tuning (SFT), which is inherently off-policy. We introduce Self-Distillation Fine-Tuning (SDFT), a simple method that enables on-policy learning directly from demonstrations. SDFT leverages in-context learning by using a demonstration-conditioned model as its own teacher, generating on-policy training signals that preserve prior capabilities while acquiring new skills. Across skill learning and knowledge acquisition tasks, SDFT consistently outperforms SFT, achieving higher new-task accuracy while substantially reducing catastrophic forgetting. In sequential learning experiments, SDFT enables a single model to accumulate multiple skills over time without performance regression, establishing on-policy distillation as a practical path to continual learning from demonstrations.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about helping big AI models keep learning new things over time without “forgetting” what they already know. The authors introduce a simple training method called Self-Distillation Fine-Tuning (SDFT) that lets a model learn from examples (demonstrations) in a way that reduces forgetting and improves performance on new tasks.
Key Questions the Paper Asked
To make the ideas easy to follow, here are the main questions the authors wanted to answer:
- How can an AI model learn new skills or facts from examples without losing its old abilities?
- Can we get the benefits of “on-policy” learning (learning from the model’s own behavior) even when we only have demonstrations and no reward scores?
- Does this new method work better than standard fine-tuning (SFT), and does it scale to bigger models?
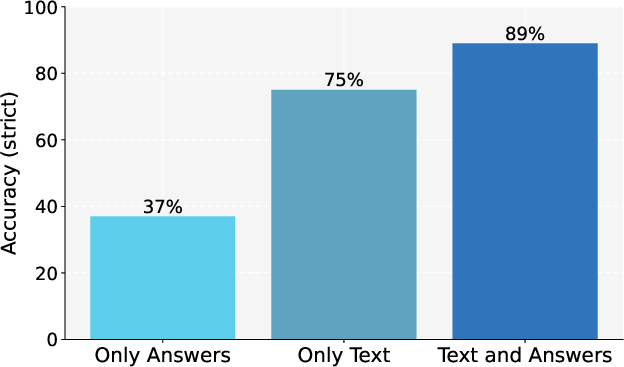
- Can it help models learn reasoning skills even when the data only includes final answers (and not full step-by-step reasoning)?
How the Method Works
The everyday idea
Imagine you’re learning math:
- As a student, you try to solve a problem on your own.
- Then, you look at a sample solution for a similar problem to see how a “teacher” would approach it.
- You compare your approach to the teacher’s and adjust your thinking.
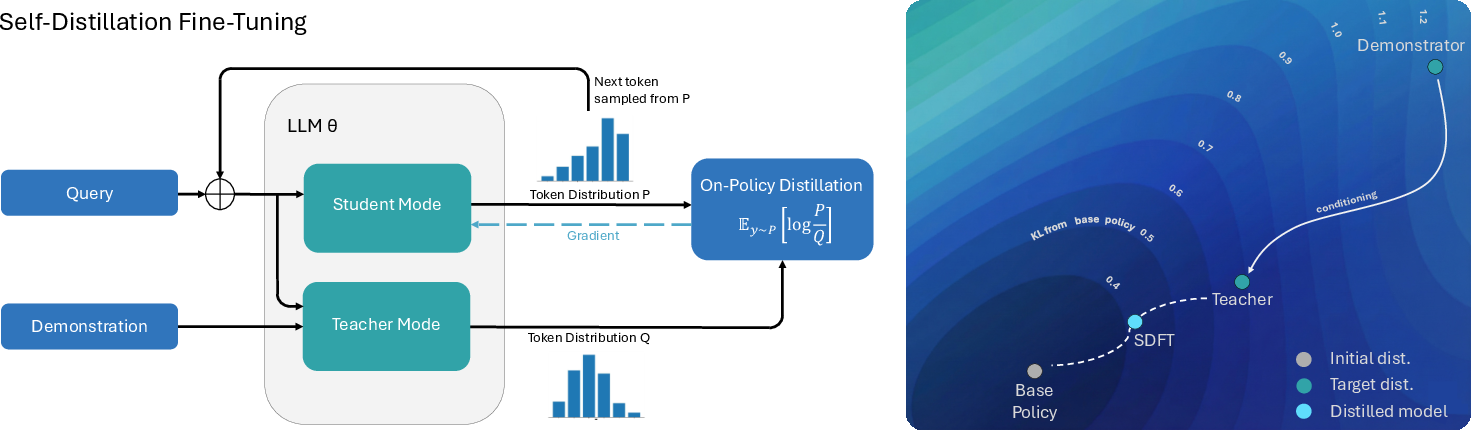
SDFT does something like that—except the “teacher” and the “student” are actually the same model, used in two different ways.
Why “on-policy” matters
- Off-policy learning: The model trains only on a fixed dataset made by experts. It’s like practicing only with solutions from a textbook, not with your own mistakes. This often causes “catastrophic forgetting” (losing old skills) and poorer generalization.
- On-policy learning: The model learns from the situations it actually encounters during practice (its own outputs). This reduces forgetting and helps it improve steadily—like practicing while you play.
SDFT in simple steps
Here’s how SDFT trains the model:
- The model plays two roles:
- Student: It tries to answer a prompt using only the question.
- Teacher: It answers the same prompt, but this time it’s shown a relevant expert demonstration (an example).
- The student generates its own answer first (this keeps the learning “on-policy”).
- The student then learns to move its behavior closer to the teacher’s answer distribution.
- Technically, the “closeness” is measured using a “difference score” called KL divergence, which you can think of as “how different are these two sets of likely answers?” SDFT reduces this difference where the student’s own answers matter most.
Key point: The teacher is the same model, but with extra context (the demonstration). This makes it smart in the moment, and it teaches the student how to behave that way even without the extra context next time.
What They Tested and Found
The authors checked SDFT in two main scenarios: learning skills and learning new facts.
Skill Learning (doing tasks better)
They trained models on:
- Science questions (chemistry reasoning),
- Tool use (picking the right API call for a user request),
- Medical questions (clinical reasoning).
Main findings:
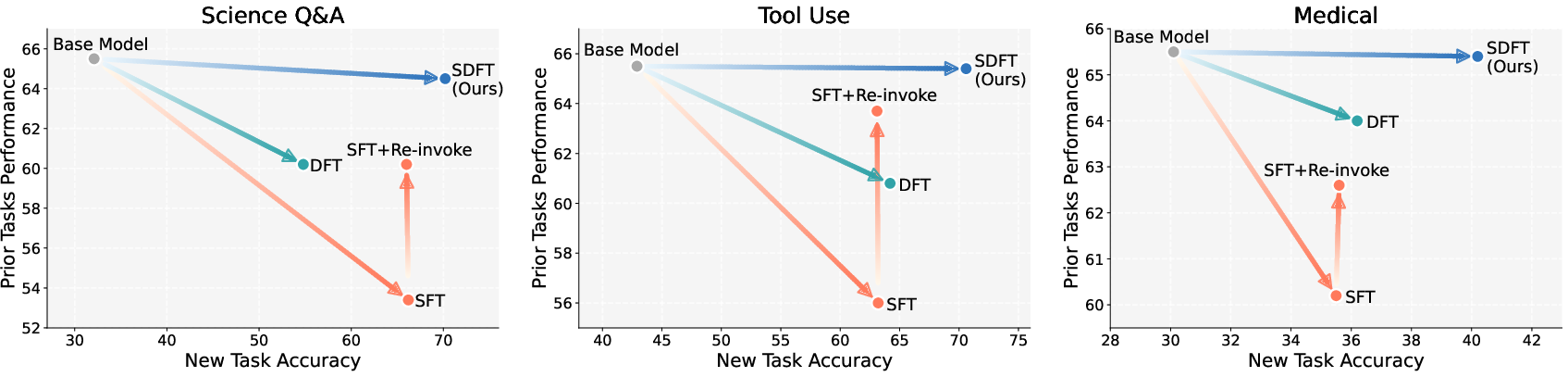
- SDFT learned new tasks better than standard supervised fine-tuning (SFT).
- It forgot less: the model kept its general abilities (like common-sense reasoning, coding tests, and knowledge quizzes).
- In a tougher test, they trained one model on three tasks in a row. SDFT let the model stack skills without losing old ones. SFT got worse on earlier tasks after training new ones.
Knowledge Acquisition (learning new facts)
They injected new 2025 factual information (e.g., recent natural disasters) that the base model didn’t know.
- SDFT answered direct questions about these new facts very well, close to a system that looks up the correct article (an “oracle RAG”).
- It also did better on tricky questions that required using the new facts indirectly (not just repeating memorized lines). This shows the facts were truly integrated into the model’s knowledge, not just copied.
Other important findings
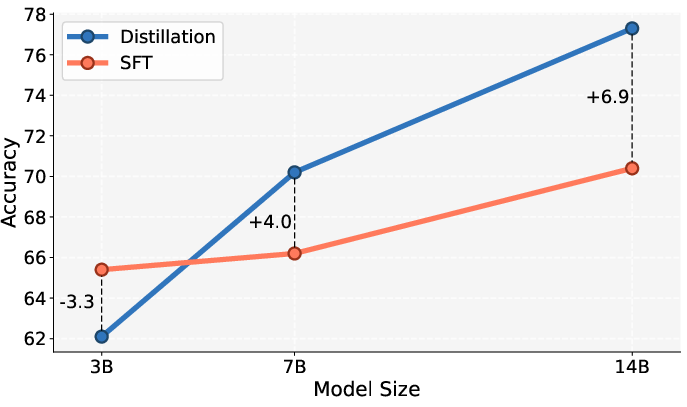
- Scaling: Bigger models have stronger “in-context learning” (they learn better from examples), so SDFT works even better as model size increases.
- Reasoning without reasoning data: When training a reasoning model on data that only has final answers (no step-by-step thinking), SFT tended to collapse the model’s reasoning depth and hurt accuracy. SDFT improved accuracy and preserved longer, thoughtful reasoning.
- On-policy is essential: If you try to distill from the teacher only on a fixed dataset (offline), it helps—but it still falls short of SDFT’s on-policy approach.
Why This Is Important
SDFT offers a practical path to “continual learning” for AI models:
- The model can steadily learn new tasks and facts from demonstrations while preserving old skills.
- It avoids relying on explicit reward functions (which are often hard to design).
- It improves generalization to new situations and reduces catastrophic forgetting.
This matters for real-world AI systems (like assistants, robots, and educational tools) that need to adapt over time without breaking what already works.
Limitations and Future Impact
SDFT is promising, but there are some trade-offs and open questions:
- It needs models with good “in-context learning.” Smaller or weaker models might not benefit as much.
- It costs more compute than simple fine-tuning because the model must generate its own answers during training.
- Sometimes the student picks up stylistic habits from the teacher (like saying “Based on the text…” even when no text was provided). The authors propose simple fixes, but a cleaner solution is still needed.
- SDFT is complementary to on-policy reinforcement learning (RL). It works well when you have demonstrations but no reward function. In many applications, combining SDFT (to learn from examples) with RL (to learn from feedback) could be even better.
Overall, the paper shows a clear, practical way for AI models to keep learning from demonstrations over time, gaining new abilities without losing old ones—a big step toward more adaptive, life-long learning AI.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, framed to enable concrete follow-up work.
- Theoretical guarantees: no convergence, stability, or regret bounds are provided for SDFT’s reverse-KL on-policy updates under the in-context teacher assumption; formal analysis of when/why SDFT improves return and reduces forgetting remains open.
- Validity of the in-context optimality assumption: empirical support is shown on a single tool-use dataset; it is unknown how well the assumption holds across domains (e.g., coding, math proofs, safety-critical dialog), higher difficulty regimes, or adversarial/ambiguous prompts.
- Measuring teacher proximity during training: KL proximity to the base model is evaluated at initialization, but not tracked throughout training; it is unclear whether the teacher remains sufficiently “close” (trust-region-like) as the student drifts.
- Demonstration selection policy: the method assumes an “appropriate” per-instance demonstration
cbut does not define a scalable retrieval/matching strategy; it is unknown how performance degrades with suboptimal retrieval, mismatched demonstrations, or limited demo pools. - Robustness to imperfect demonstrations: SDFT’s behavior under noisy, suboptimal, biased, or contradictory demonstrations is not measured; robustness mechanisms (e.g., confidence-weighted distillation, outlier detection, denoising) are unexplored.
- Hyperparameter sensitivity: the paper does not quantify sensitivity to EMA decay, learning rate, sampling temperature, KL weighting, or sequence length; automated tuning and stability diagnostics for SDFT remain to be developed.
- Divergence choice: only reverse KL is used; it is unknown whether alternative f-divergences (forward KL, JS, α-divergences), trust-region schedules, or mixed objectives better balance generalization vs. retention.
- Gradient variance and sampling: SDFT uses a single on-policy sample per prompt; the variance–efficiency trade-off, benefits of multiple samples, control variates, or low-variance estimators are not studied.
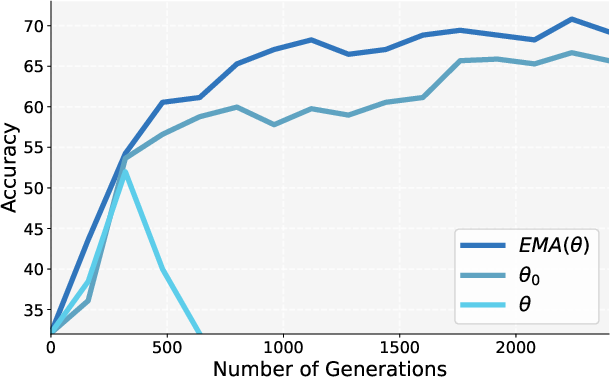
- Teacher parameterization: only a limited ablation is reported (EMA vs. non-EMA); the impact of stronger external teachers, cross-model teachers, temperature-scaling of teacher logits, or adaptive teacher refresh intervals is unexamined.
- Scale limits and small-model regimes: SDFT underperforms SFT on small models; concrete techniques to uplift weak-ICL models (e.g., auxiliary ICL pretraining, retrieval-augmented teachers) are not explored.
- Long-horizon continual learning: results cover three tasks; scalability to dozens of tasks, non-stationary task streams, task recurrency, and interleaved/mixed-task training remains untested.
- Interference across heterogeneous task types: how SDFT behaves when alternating between very different modalities or objectives (e.g., code, math, dialogue safety, tool use) is not evaluated.
- Multi-turn and interactive settings: experiments use single-turn text tasks; behavior in multi-step reasoning, tool-use with environment feedback, or partially observable interactive agents is unknown.
- Safety, bias, and alignment: SDFT may distill biases and unsafe patterns from demonstrations; impacts on toxicity, hallucination, and safety benchmarks are not measured; mitigation strategies (e.g., safety-aware teachers) are not investigated.
- Chain-of-thought handling: the method prompts teachers to include “thinking”; effects on COT leakage, privacy, refusal behavior, and downstream alignment/compliance are not systematically evaluated.
- Artifact transfer: the paper notes learned stylistic artifacts and proposes masking early tokens as a heuristic; principled approaches (e.g., output-style disentanglement, conditional losses) are not developed.
- Knowledge integration depth: knowledge acquisition is shown on a 200K-token corpus; the extent to which facts integrate into broader conceptual graphs (compositional or counterfactual queries) is only partially probed.
- Fairness of knowledge-injection baselines: CPT vs. SFT vs. SDFT use different supervision forms and token budgets; controlled experiments matching effective tokens and curriculum are needed to isolate method effects.
- Calibration and uncertainty: the impact of SDFT on probability calibration, confidence alignment, and selective prediction is not measured.
- Pass@k vs. entropy: although pass@k improves, broader analyses of entropy dynamics, diversity–quality trade-offs, and semantic diversity of solutions are limited.
- Compute and memory cost: training requires ~2.5× FLOPs and ~4× wall-clock vs. SFT; systematic cost–benefit analyses across model sizes, sequence lengths, and generation budgets (including KV-cache and teacher-logit reuse) are missing.
- Inference-time efficiency: SDFT may preserve or lengthen reasoning traces; the latency and token-usage implications at inference are not quantified beyond a single reasoning model.
- Retrieval + SDFT synergy: while an oracle RAG upper bound is reported, practical retrieval (imperfect retrievers, top-k contexts) combined with SDFT—and joint training of retriever and policy—remains unexplored.
- Mixing SDFT with on-policy RL: concrete training schedules, objective blending, and credit-assignment interplay (token-level vs. trajectory-level signals) are not evaluated.
- Catastrophic forgetting analysis: retention is summarized by an average over a small suite; per-benchmark degradation, long-tail behaviors, and correlation with distributional shift are not deeply analyzed.
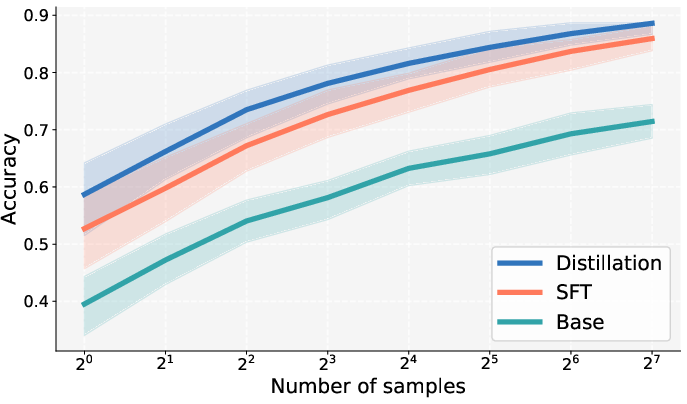
- Sample efficiency: relative data efficiency vs. SFT/DFT (accuracy per demonstration) is not reported; learning curves, low-data regimes, and data scaling laws for SDFT are open.
- Domain and modality generality: experiments are text-only; application to vision–language, speech, robotics policies, or structured action spaces is untested.
- Task detection and scheduling: how to detect the emergence of new tasks in the wild, select which demonstrations to condition on, and schedule SDFT updates online remains unaddressed.
- Security and poisoning risks: on-policy learning from demonstrations could amplify targeted data poisoning; defenses, anomaly detection, and trust calibration for teachers are not studied.
- Evaluation reproducibility: key implementation details (e.g., demonstration selection policy, temperature, decoding strategy) can materially affect outcomes; comprehensive ablations and public training logs/curves would improve reproducibility.
Practical Applications
Immediate Applications
Below are specific, deployable use cases that leverage Self-Distillation Fine-Tuning (SDFT) to learn from demonstrations on-policy, improving new skills while reducing catastrophic forgetting.
- Software and Developer Tools
- Use case: Rapidly update code assistants to new APIs and tool-calls (e.g., mapping user requests to correct tool invocations), preserving general coding abilities.
- Sector: Software/DevTools
- Workflow/product: “SDFT Tool-Use Upgrade” pipeline—curate expert demos (API specs + example calls), condition the teacher via the provided prompt template, perform on-policy reverse-KL distillation with EMA teacher weights, monitor prior-capability benchmarks.
- Assumptions/dependencies: High-quality demonstrations; LLMs with strong in-context learning (ICL); tolerance for ~2.5× FLOPs and ~4× wall-clock overhead vs SFT; loss masking to suppress learned artifacts (“Based on the text…”).
- Enterprise Chatbots and Customer Support
- Use case: Continually integrate new products, policies, and troubleshooting steps without degrading general QA performance.
- Sector: Software/Enterprise
- Workflow/product: Knowledge-acquisition pipeline—ingest updated docs, auto-generate Q&A pairs, train with SDFT; optional hybrid “RAG + SDFT” for content beyond context windows; evaluate OOD questions to verify integration (not mere memorization).
- Assumptions/dependencies: Curated, authoritative documentation; benchmarking for prior capabilities (e.g., MMLU, TruthfulQA) to catch forgetting; artifact mitigation through prompt/loss controls.
- Healthcare: Clinical Decision Support Updates
- Use case: Adapt models to new clinical guidelines, drug approvals, or protocols while maintaining broad medical reasoning; train reasoning models with answer-only supervision.
- Sector: Healthcare
- Workflow/product: “SDFT Clinical Sync”—use demonstration-conditioned teacher to preserve reasoning style even when datasets lack chain-of-thought; monitor both task accuracy and reasoning-depth proxies (e.g., average generated tokens).
- Assumptions/dependencies: Regulatory review (HIPAA, MDR, etc.); expert-verified demonstrations; larger models for stronger ICL; safety/robustness validation.
- Education: Course- or Exam-Specific Tutoring
- Use case: Customize tutors to particular curricula (e.g., Chemistry, medical scenarios) using example solutions, without losing general tutoring skills.
- Sector: Education
- Workflow/product: “SDFT Tutor Adapt”—teacher conditioned on course-specific examples; on-policy distillation; retention monitoring across general reasoning benchmarks; pass@k tracking to ensure genuine skill acquisition.
- Assumptions/dependencies: Quality exemplars; scalable training infra; alignment checks to prevent shortcut learning.
- Finance: Regulatory and Instrument Updates
- Use case: Integrate new regulations (e.g., SEC rules) and novel instruments (ETFs, derivatives) into financial analysis assistants, improving OOD reasoning (e.g., “Which filings imply X?”) while retaining prior skills.
- Sector: Finance
- Workflow/product: “SDFT Filing Digest”—ingest filings, create Q&A pairs, perform on-policy distillation, verify OOD generalization beyond the injected corpus.
- Assumptions/dependencies: Trusted sources and curation; compliance oversight; model scale sufficient for high-quality teacher signals.
- Legal and Public Policy Assistants
- Use case: Continuous updates with new statutes, case law, and agency rules, maintaining general knowledge and safe behavior.
- Sector: Public Policy/LegalTech
- Workflow/product: “SDFT Legal Update”—corpus ingestion + Q&A generation; teacher conditioning; retention audits; OOD tests for composite queries (e.g., cross-jurisdictional implications).
- Assumptions/dependencies: Authoritative legal sources; governance and auditing workflows; artifact suppression (e.g., avoid “following the example…” preambles).
- MLOps: Model Maintenance and Continual Learning
- Use case: Replace multi-stage SFT + on-policy repair (“Re-invoke”) with a single SDFT stage that both learns the new task and preserves prior capabilities.
- Sector: Software/MLOps
- Workflow/product: “SDFT Continual Learning Service”—EMA teacher, one on-policy generation per prompt, reverse-KL token-level loss, retention dashboards; KL-proximity monitoring to ensure trust-region-like updates.
- Assumptions/dependencies: Training infra for on-policy sampling; standardized benchmarks for prior capability; careful prompt design to avoid teacher copying.
- Safety and Alignment Preservation During Updates
- Use case: Maintain safety and instruction-following while adding capabilities (benefit of staying close to pretrained distribution).
- Sector: Cross-sector AI Safety
- Workflow/product: Safety eval suite gated alongside SDFT; measure KL distance to base policy; deploy loss masking to mitigate learned artifacts.
- Assumptions/dependencies: Continuous safety auditing; policies for rollback if retention drops; sufficient ICL quality.
Long-Term Applications
Below are opportunities that likely require further research, scale, integration, or validation before broad deployment.
- Robotics: Continual Skill Acquisition from Teleoperation
- Use case: Teach robots new manipulation or navigation skills from expert demos (no reward engineering), while preserving previously learned behaviors.
- Sector: Robotics
- Potential workflow/product: “SDFT Robot Coach”—teacher conditioned on video/trajectory demos; student updated on-policy in sim-to-real loops; retention and safety checks across skills; combine SDFT with reward-based RL for fine-grained control.
- Assumptions/dependencies: Robust multimodal ICL (vision/action); safe on-policy data collection; strong sample efficiency; hardware safety constraints.
- Autonomous Vehicles and Driver Assistance
- Use case: Incrementally learn new maneuvers or policies from human driving demonstrations without regressing safety-critical skills.
- Sector: Mobility/Automotive
- Potential workflow/product: “SDFT Driving Adapt”—teacher conditioning on scenario-specific demos; trust-region-like updates monitored via KL; joint training with explicit safety rewards.
- Assumptions/dependencies: Regulatory approvals; large-scale, high-fidelity demos; formal verification; strong ICL in multimodal models.
- Scientific AI and Lab Automation
- Use case: Laboratory assistants that internalize new protocols and research findings from demonstrations and literature, improving OOD reasoning about experiments.
- Sector: Scientific R&D
- Potential workflow/product: “SDFT Protocol Sync”—corpus + demo conditioning; OOD questions to validate integration; chain-of-thought preservation for safety-critical steps.
- Assumptions/dependencies: High-quality, expert-vetted demonstrations; contamination controls; model-scale for reliable ICL.
- Energy and Infrastructure Operations
- Use case: Grid or plant operation assistants that incorporate updated procedures, standards, and incident playbooks without forgetting fundamental operations.
- Sector: Energy/Industrial
- Potential workflow/product: “SDFT Ops Update”—demo-conditioned teacher built from operator notes; retention auditing; hybrid RAG+SDFT for large corpora.
- Assumptions/dependencies: Safety certification; incident simulation for on-policy updates; governance.
- Multimodal Foundation Models (Language + Vision + Action)
- Use case: Extend SDFT to multimodal settings where demonstrations include text, images, audio, or actions, enabling continual learning across modalities.
- Sector: Cross-sector AI Platforms
- Potential workflow/product: “SDFT-X”—generalized reverse-KL distillation across modalities; EMA teacher; multimodal artifact mitigation.
- Assumptions/dependencies: Mature multimodal ICL; scalable training; careful token/logit alignment across modalities.
- Federated and On-Device Continual Learning
- Use case: Personal assistants that learn user-specific skills from local demonstrations while preserving base capabilities across devices/users.
- Sector: Consumer AI
- Potential workflow/product: “Federated SDFT”—privacy-preserving on-policy distillation; retention monitoring per cohort; personalized demo packs.
- Assumptions/dependencies: Compute-efficient SDFT for small models; privacy and security guarantees; robust ICL in compact models (current results suggest smaller models benefit less).
- Capability Add-ons via “Demonstration Packs”
- Use case: Marketplace of vetted demonstration bundles that can be applied via SDFT to add capabilities (e.g., domain tool-use, specialized QA).
- Sector: Software/Developer Ecosystems
- Potential workflow/product: “Capability Packs”—standardized demo curation, teacher prompts, retention checks, licensing and provenance tracking.
- Assumptions/dependencies: Demo quality control; legal/licensing; automated artifact detection.
- SDFT + RL Hybrid Training
- Use case: Use SDFT to establish a strong, retention-preserving initialization, followed by reward-based RL for fine-grained optimization (e.g., latency, style, safety).
- Sector: Cross-sector AI Training
- Potential workflow/product: “Hybrid On-Policy Stack”—SDFT first-phase; GRPO or similar second-phase; shared monitoring for pass@k and OOD generalization.
- Assumptions/dependencies: Reward design; exploration costs; integration of token-level and trajectory-level signals.
- Robust SDFT from Noisy or Non-Expert Demonstrations
- Use case: Learning from imperfect user logs or mixed-quality demos, with automated teacher conditioning and confidence controls.
- Sector: Real-world Data Platforms
- Potential workflow/product: “Noise-Tolerant SDFT”—demo filtering/scoring; teacher reliability estimation; adaptive masking to avoid artifacts.
- Assumptions/dependencies: Methods for demo quality estimation; robust prompting; additional research on stability.
- Changing Generation Styles (e.g., inducing or transforming chain-of-thought)
- Use case: Modify a model’s generation pattern (e.g., enable explicit reasoning traces) without harming prior capabilities.
- Sector: Reasoning Models
- Potential workflow/product: “Style-Aware SDFT”—modified objectives/prompting to support more fundamental behavioral shifts beyond retention-friendly updates.
- Assumptions/dependencies: New objectives beyond reverse-KL; empirical methods to avoid reasoning collapse; larger models for stronger ICL.
- Compute-Efficient SDFT and Infrastructure
- Use case: Reduce on-policy generation cost to make SDFT feasible for resource-constrained deployments and on-device updates.
- Sector: AI Infrastructure
- Potential workflow/product: “Efficient SDFT”—sample reuse, distillation caching, partial-token credit assignment, low-rank updates.
- Assumptions/dependencies: Algorithmic advances to lower FLOPs/time; careful trade-off analysis vs retention and accuracy.
Glossary
- Advantage (trajectory-level advantage): In reinforcement learning, a measure of how much better an action or trajectory performs relative to a baseline, used to guide credit assignment. "Moreover, our supervision is provided at the token level (or even the logit level), providing denser credit assignment than the trajectory-level advantage used in GRPO."
- Adversarial IRL: A class of inverse reinforcement learning methods that use a discriminator to distinguish expert from learner trajectories to infer rewards. "adversarial IRL methods \citep{ho2016generative} assume that expert and learner trajectories can be distinguished by a classifier;"
- Autoregressive: Refers to models that generate each token conditioned on previously generated tokens, enabling sequence decomposition. "Leveraging the autoregressive nature of the model, we decompose this objective into a token-level loss (see \citet{tang2025few} for a derivation)"
- Boltzmann policy: A soft-optimal policy where action probabilities are proportional to the exponentiated (scaled) rewards. "Maximum-entropy IRL assumes that experts follow a soft-optimal Boltzmann policy \citep{ziebart2008maximum, wulfmeier2015maximum};"
- Catastrophic forgetting: The degradation of previously learned capabilities when a model is adapted to new tasks. "Across skill learning and knowledge acquisition tasks, SDFT consistently outperforms SFT, achieving higher new-task accuracy while substantially reducing catastrophic forgetting."
- Chain-of-thought: Explicit intermediate reasoning steps produced by a model to arrive at an answer. "In all cases, not only were the final tool calls correct, but the intermediate chain-of-thought was valid and semantically grounded."
- Compounding errors: Accumulation of mistakes when a learned policy encounters states not covered by training data, leading to rapidly worsening performance. "The seminal result of \citet{ross2011reduction} shows that off-policy imitation learning suffers from compounding errors at inference time, as the learned policy drifts away from the states covered in the demonstrations, errors accumulate rapidly, a failure mode that on-policy algorithms avoid by continually training under their own state distribution."
- Context distillation: Training a student model to replicate the outputs of a teacher model that is given additional context, so the student can internalize the effect of that context. "Our method also relates to the growing line of work on context distillation, in which a model conditioned on additional information acts as a teacher for a version of itself without that information \citep{bai2022constitutional, snell2022learning}."
- Continual learning: Enabling models to keep acquiring new skills and knowledge over time without degrading existing capabilities. "To enable the next generation of foundation models, we must solve the problem of continual learning: enabling AI systems to keep learning and improving over time, similar to how humans accumulate knowledge and refine skills throughout their lives \citep{hassabis2017neuroscience, de2021continual}."
- Continual Pre-Training (CPT): Continued training on raw text with next-token prediction to integrate new knowledge into a model. "In the Knowledge Acquisition setting, we compare our method to CPT (Continual Pre-Training), which trains directly on the text corpus using next token prediction loss and SFT, which trains on the question-answer pairs."
- Credit assignment: The process of attributing observed performance or reward to specific actions or tokens to guide learning. "Moreover, our supervision is provided at the token level (or even the logit level), providing denser credit assignment than the trajectory-level advantage used in GRPO."
- Demonstration-conditioned: Refers to a model conditioned on expert demonstrations to guide its outputs for a given query. "We introduce Self-Distillation Fine-Tuning (SDFT), which turns expert demonstrations into on-policy learning signals by using a demonstration-conditioned version of the model as its own teacher."
- DFT: A fine-tuning method that uses importance sampling to approximate on-policy learning from offline datasets. "In the Skill Learning setting, we compare our method to standard SFT and to DFT \citep{wu2025generalization}, which uses importance sampling to treat the offline dataset as on-policy samples."
- Distillation: A training paradigm where a student model learns to match a teacher model’s output distribution, often minimizing divergence between them. "Our approach builds on the framework of student-teacher distillation, where a student model is trained to match the behavior of a teacher model by minimizing the divergence between their output distributions."
- Entropy reduction: Decreasing the uncertainty (entropy) of a model’s output distribution, which can superficially inflate metrics without genuine skill acquisition. "Finally, with on-policy RL there is a concern for superficial improvements through entropy reduction rather than acquisition of new behaviors \citep{yue2025does, wu2025invisible}."
- Exponential moving average (EMA): A smoothing technique that maintains a weighted average of parameters over time, giving more weight to recent updates. "Subsection \ref{subsec:ablation} includes an ablation regarding this design choice, but unless mentioned otherwise, we use an exponential moving average (EMA) of the student parameters for the teacher."
- GRPO: An on-policy reinforcement learning method that uses grouped rollouts for advantage estimation. "A practical advantage of SDFT is its efficiency. Our method requires only a single on-policy generation per prompt, whereas many on-policy RL methods, such as GRPO, rely on group-based sampling to estimate relative advantages, substantially increasing generation cost."
- Group-based sampling: Generating multiple samples per prompt during training to estimate relative advantages in on-policy RL. "A practical advantage of SDFT is its efficiency. Our method requires only a single on-policy generation per prompt, whereas many on-policy RL methods, such as GRPO, rely on group-based sampling to estimate relative advantages, substantially increasing generation cost."
- Importance sampling: A statistical technique for reweighting samples from one distribution to estimate expectations under another, used to correct off-policy biases. "In the Skill Learning setting, we compare our method to standard SFT and to DFT \citep{wu2025generalization}, which uses importance sampling to treat the offline dataset as on-policy samples."
- In-context learning: The ability of a model to adapt its behavior by conditioning on examples within the input, without changing parameters. "SDFT leverages in-context learning by using a demonstration-conditioned model as its own teacher, generating on-policy training signals that preserve prior capabilities while acquiring new skills."
- In-distribution performance: Performance on data drawn from the same distribution as the training data. "Prior work has shown that on policy learning achieves better in-distribution performance than SFT \citep{ross2011reduction}, as well as superior out-of-distribution generalization \citep{chu2025sft}."
- Inverse Reinforcement Learning (IRL): Learning a reward function from expert demonstrations that can then be used for on-policy RL. "The challenges of off-policy learning can, in principle, be overcome by first learning a reward function from demonstrations (i.e., Inverse Reinforcement Learning or IRL), and then performing on-policy RL \citep{ng2000algorithms, abbeel2004apprenticeship}."
- Kullback–Leibler divergence (KL divergence): A measure of how one probability distribution diverges from another. "minimizes the reverse Kullback-Leibler (KL) divergence between the student and the teacher distributions"
- Maximum-entropy IRL: An IRL framework that assumes experts follow a soft-optimal policy maximizing entropy while achieving high reward. "Maximum-entropy IRL assumes that experts follow a soft-optimal Boltzmann policy \citep{ziebart2008maximum, wulfmeier2015maximum};"
- Off-policy imitation learning: Learning to imitate expert actions from a fixed dataset not generated by the current policy. "The seminal result of \citet{ross2011reduction} shows that off-policy imitation learning suffers from compounding errors at inference time, as the learned policy drifts away from the states covered in the demonstrations, errors accumulate rapidly, a failure mode that on-policy algorithms avoid by continually training under their own state distribution."
- On-policy distillation: Distillation where the student is trained under its own induced trajectory distribution, aligning to a teacher while staying on-policy. "establishing on-policy distillation as a practical path to continual learning from demonstrations."
- On-policy learning: Training on trajectories generated by the current policy, which reduces forgetting and improves generalization. "A growing body of recent work has highlighted the importance of on-policy learning for continual learning."
- Out-of-distribution generalization: Performance on data that differs from the training distribution, indicating robustness. "Prior work has shown that on policy learning achieves better in-distribution performance than SFT \citep{ross2011reduction}, as well as superior out-of-distribution generalization \citep{chu2025sft}."
- Oracle retriever: An idealized retrieval system that always provides the correct supporting document for a query. "Because the full corpus exceeds the model’s context window, we evaluate RAG with an oracle retriever that always provides the correct article for each question."
- Pareto efficiency: A state where improving one objective would worsen another; used to evaluate trade-offs between accuracy and retention. "SDFT consistently achieves superior Pareto efficiency compared to baselines across all three skill learning tasks."
- Pass@k: A metric measuring whether at least one of k sampled generations is correct, used to assess performance across multiple samples. "To ensure our gains are not merely due to distributional sharpening, we evaluate pass@ for up to 128 in the Skill Learning Setting."
- Policy gradient: The gradient of expected return with respect to policy parameters, used for optimizing policies in RL. "The policy gradient under the current policy is:"
- Preference-based IRL: IRL methods that infer rewards from comparative preferences between trajectories or outputs. "and preference-based IRL methods, such as RLHF \citep{ziegler2019fine, ouyang2022training}, assume access to pairs of positive–negative demonstrations."
- Retrieval-Augmented Generation (RAG): A technique that augments generative models with retrieved documents to improve factual accuracy. "Because the full corpus exceeds the model’s context window, we evaluate RAG with an oracle retriever that always provides the correct article for each question."
- Reverse KL divergence: The divergence D_KL(p || q) used to align the student’s distribution to the teacher’s, emphasizing coverage of the student’s support. "minimizes the reverse Kullback-Leibler (KL) divergence between the student and the teacher distributions"
- RLHF (Reinforcement Learning from Human Feedback): A preference-based RL approach that uses human comparisons to learn reward models and fine-tune policies. "preference-based IRL methods, such as RLHF \citep{ziegler2019fine, ouyang2022training}, assume access to pairs of positive–negative demonstrations."
- Re-invocation: A post-SFT procedure that performs additional on-policy distillation to recover prior capabilities. "We also include the recently proposed \"Re-invocation\" method \citep{lu2025onpolicydistillation}, which performs additional on-policy distillation from the base policy on general-purpose prompts after SFT to restore prior capabilities."
- Student–teacher distillation: A training framework where a student model is optimized to match the outputs of a teacher model. "Our approach builds on the framework of student-teacher distillation, where a student model is trained to match the behavior of a teacher model by minimizing the divergence between their output distributions."
- Supervised Fine-Tuning (SFT): Fine-tuning a model to imitate expert outputs using a supervised objective on a fixed dataset. "Supervised Fine-Tuning~(SFT) is commonly used to learn from expert demonstration datasets, but its off-policy nature leads to catastrophic forgetting of general capabilities."
- Tilted distribution: A reweighted distribution formed by exponentiating rewards relative to a base policy, representing the optimal update under a KL constraint. "For this objective, the optimal policy takes the known closed-form expression of a tilted distribution \citep{korbak2022rl, rafailov2023direct}:"
- Token-level loss: A decomposition of the training objective over individual tokens, enabling finer-grained supervision. "Leveraging the autoregressive nature of the model, we decompose this objective into a token-level loss (see \citet{tang2025few} for a derivation)"
- Trajectory-level reward: A reward defined over an entire generated sequence rather than individual steps or tokens. "While this defines a trajectory-level reward, our model has an autoregressive structure."
- Trust-region regularization: A constraint that keeps updates close to the current policy via a KL penalty, stabilizing optimization. "We begin with the standard formulation of trust-region-regularized reinforcement learning \cite{schulman2015trust}, where the policy update in step is constrained to stay close to the current policy :"
Collections
Sign up for free to add this paper to one or more collections.