ThinkMorph: Emergent Properties in Multimodal Interleaved Chain-of-Thought Reasoning
Abstract: Multimodal reasoning requires iterative coordination between language and vision, yet it remains unclear what constitutes a meaningful interleaved chain of thought. We posit that text and image thoughts should function as complementary, rather than isomorphic, modalities that mutually advance reasoning. Guided by this principle, we build ThinkMorph, a unified model fine-tuned on 24K high-quality interleaved reasoning traces spanning tasks with varying visual engagement. ThinkMorph learns to generate progressive text-image reasoning steps that concretely manipulate visual content while maintaining coherent verbal logic. It delivers large gains on vision-centric benchmarks (averaging 34.7% over the base model) and generalizes to out-of-domain tasks, matching or surpassing larger and proprietary VLMs. Beyond performance, ThinkMorph exhibits emergent multimodal intelligence, including unseen visual manipulation skills, adaptive switching between reasoning modes, and better test-time scaling through diversified multimodal thoughts.These findings suggest promising directions for characterizing the emergent capabilities of unified models for multimodal reasoning.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces ThinkMorph, an AI system that learns to think using both words and pictures at the same time. Instead of only writing out its thoughts (like most AIs do), ThinkMorph also “sketches” helpful images during problem-solving—such as drawing paths on a maze, boxing an object in a photo, or rearranging puzzle pieces. The big idea is that text and images should work together as teammates, each doing what it’s best at, to solve tough visual problems.
What questions are the researchers asking?
They focus on three simple questions:
- When is it better to think with both words and pictures instead of just one?
- How can a model learn to switch between text-thinking and image-thinking as needed?
- Can this mixed way of thinking unlock new abilities the model wasn’t directly taught?
How did they study it?
The idea of “interleaved chain of thought”
Most AI “chain-of-thought” reasoning is just text: the model explains steps in words. This paper adds image steps in between the text steps—like a student who solves problems by thinking out loud and sketching on paper. These back-and-forth steps are called “interleaved” because the model alternates between writing and drawing to move closer to the answer.
Think of it like:
- Words = instructions and checks (What should I do next? Did that work?)
- Pictures = visual actions (Let me mark the route, highlight the bar, crop the object)
The four kinds of practice tasks
To teach this, the authors built about 24,000 high-quality examples where text and images help each other. Here are the four practice tasks:
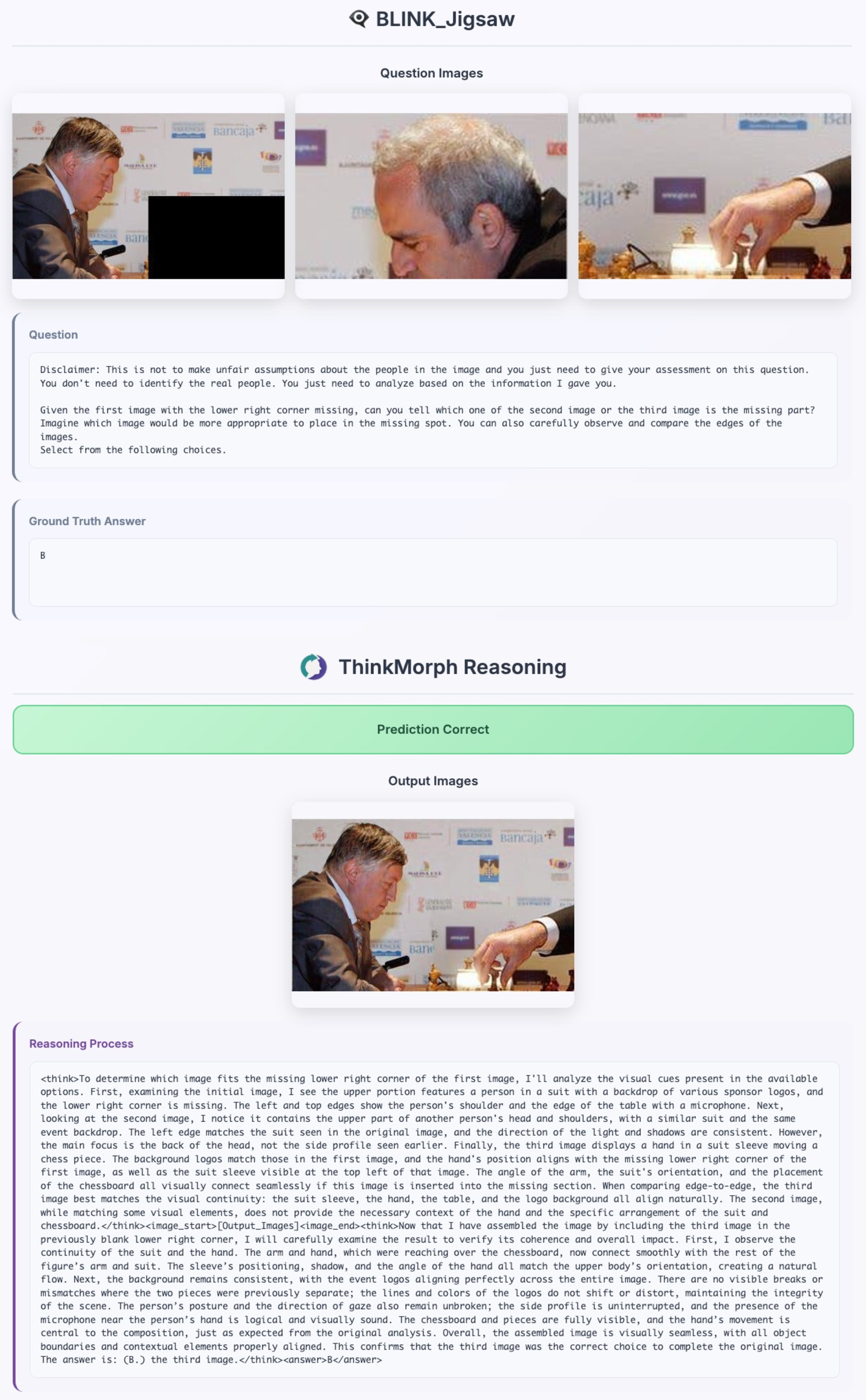
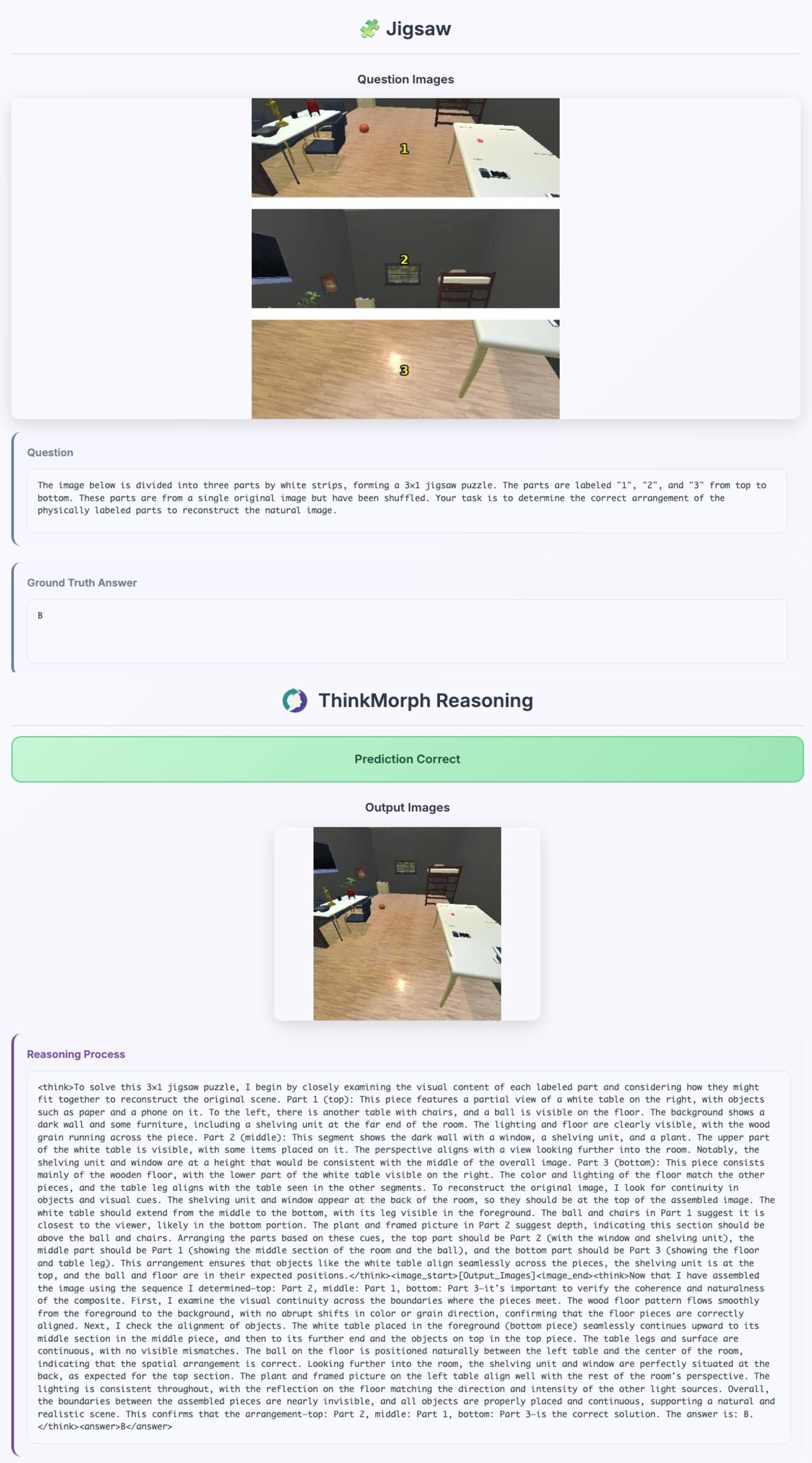
- Jigsaw Assembly: Rearranging scrambled picture tiles to rebuild the original image. The model describes pieces in words, then “rebuilds” a picture to test its guess.
- Spatial Navigation: Finding a safe path on a map/maze. The model explains the plan, then draws the path over the maze.
- Visual Search: Finding an object in a picture. The model guesses where to look in text, then draws a box around the object.
- Chart Refocus: Answering questions about charts. The model points out relevant bars/lines by highlighting them, then calculates or compares values in text.
How the model learns and is tested
- Learning: They fine-tuned an existing “unified” model (one that can both understand and generate images and text) so it could produce these interleaved steps: text tokens for explanations, and image tokens for visual edits (like overlays, arrows, boxes).
- Testing: They checked performance on both similar tasks and different, harder tasks the model didn’t see during training. They compared three modes:
- Text-only thinking
- Image-only thinking
- Interleaved (text + image) thinking
What did they find, and why does it matter?
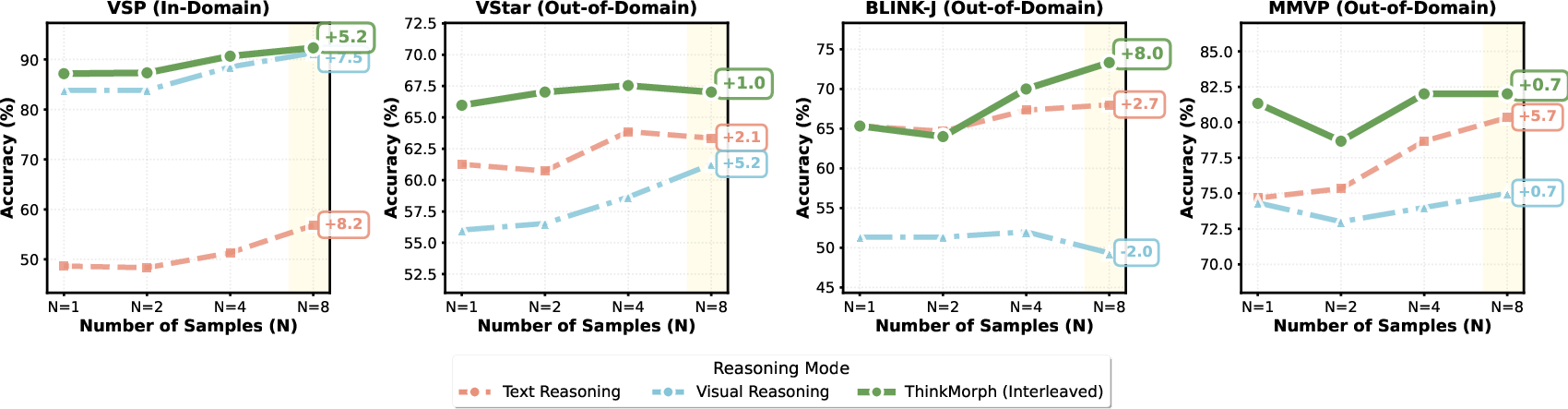
- Interleaved thinking is best for visually heavy tasks When the problem truly needs careful looking and visual proof (like mazes, jigsaws, or finding tiny objects), the model that thinks with both words and pictures clearly wins. The improvements are big—for example, on a maze task, performance jumped from almost zero to very high when interleaved steps were used.
- It generalizes well to new tasks Even with a modest amount of training data (~24K examples), ThinkMorph matched or beat much larger or commercial systems on several benchmarks, especially those that require reasoning rather than just describing.
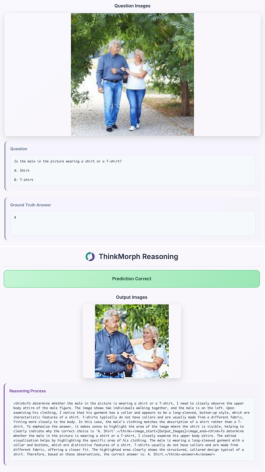
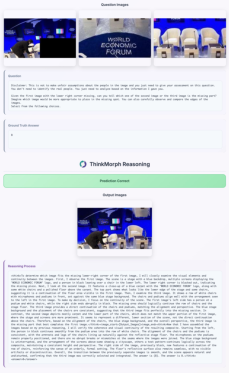
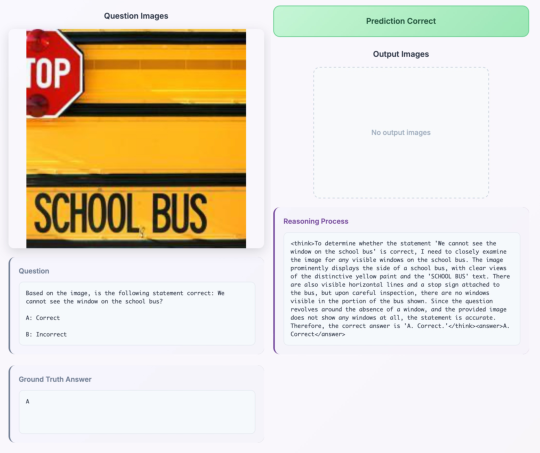
- It shows “emergent” skills it wasn’t directly taught Surprisingly, the model developed new, useful visual moves on its own during testing—like zooming in, cropping, drawing multiple boxes, or inpainting—to help answer questions. These weren’t directly trained as tools; the model “figured out” when to do them from patterns it learned.
- It can switch modes by itself Even though it was trained to interleave text and images, sometimes the model chose to use only text when the image wasn’t needed. On some questions, this switch actually improved accuracy. In simple terms, the model learns to spend effort where it matters most.
- Better results by “trying multiple ways” at test time When the model tries several different mixed text+image solution paths (like brainstorming different sketches and explanations), accuracy improves more than with text-only or image-only attempts. This shows that exploring a wider variety of multimodal ideas can help find the right answer more reliably.
Why is this important?
- It moves AI beyond “describe the picture” toward “work with the picture.” The AI doesn’t just talk about what it sees—it actively edits or marks up the image to reason better.
- It shows that text and images aren’t duplicates. They do different jobs, and combining them step-by-step leads to smarter problem-solving.
- It hints at more human-like thinking. People often solve problems by both talking and sketching; this work brings AI closer to that style.
Simple takeaways
- Purpose: Teach AI to think by mixing words and pictures in a single, step-by-step process.
- Method: Train on carefully designed examples where each text step and image step push the solution forward together.
- Results: Big gains on visual reasoning tasks, strong performance even on new problems, and surprising new abilities (zooming, cropping, switching modes).
- Impact: A practical recipe for building AIs that reason better by “think-and-sketch,” which could help in education, navigation, medical imaging, data analysis, robotics, and more.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, framed to guide actionable future research.
- Lack of a formal definition and metric for “meaningful interleaving” and “complementarity” between modalities; no quantitative criterion to assess when an interleaved step is necessary vs redundant or harmful.
- No explicit objective enforcing cross-modal complementarity; training uses separate MSE (image tokens) and NLL (text) without alignment terms that jointly constrain modalities (e.g., cycle-consistency, mutual information maximization, cross-modal entailment).
- Missing ablations disentangling the source of “emergent” behaviors: how much arises from Bagel’s pretraining vs interleaved fine-tuning vs dataset design?
- Generality to other unified architectures untested; results are tied to Bagel-7B. Do the same gains and emergent properties hold for alternative tokenizers, decoders, and fusion designs?
- Limited data scope and diversity: only ~24K traces across four tasks with specific visual edits (boxes, highlights, overlays). Unclear performance on tasks requiring different or richer operations (e.g., segmentation, keypoints, 3D transforms, OCR-heavy charts, diagrams, dense layouts).
- No evaluation beyond static images: extension to video, temporal reasoning, egocentric data, or interactive/embodied tasks is unexplored.
- Unspecified or under-detailed image tokenization and generation stack (resolution, tokenizer choice, image loss design); impact of these choices on reasoning quality and edit fidelity is unknown.
- Absence of intermediate-step verification metrics: no quantitative assessment of the correctness of visual edits (e.g., IoU for boxes, path validity on mazes, pixel-level accuracy of overlays) or their causal utility to the final answer.
- Faithfulness and attribution of visual thoughts not evaluated: does each visual manipulation reflect evidence in the input and causally contribute to correct answers? Counterfactual tests (e.g., masking edits, randomized overlays) are missing.
- “Unseen visual manipulations” are anecdotal and partially quantified (“up to 10%”) but lack a systematic taxonomy, frequency analysis across datasets, human-rated quality, and controlled impact on outcome metrics.
- Mode switching is observed but not operationalized: no learned gating/policy, no predictive model of when to switch modes, no analysis of triggers beyond a few examples, and no training signal to encourage optimal switching.
- Test-time scaling comparisons may be confounded by unequal compute budgets across modes; there is no normalization for token count, wall-clock latency, or FLOPs, nor a cost–benefit analysis per additional sample.
- Best-of-N selection is underspecified: how are candidates selected at inference (log-prob ranking, self-consistency, verifier, judge)? Practical, deployable selection mechanisms are not evaluated.
- Evaluation relies on LLM-as-a-judge (GPT-5) for some tasks, raising concerns about bias, reproducibility, and potential model-judge correlation; no calibration, inter-annotator agreement, or human validation is reported.
- Domain overlap risks: Chart Refocus uses ChartQA-derived data and evaluates on ChartQA; the extent of train–test leakage or concept overlap is not quantified.
- Data curation depends on proprietary MLLMs (e.g., GPT-4.1) and heuristic filters (e.g., bounding box area thresholds), which may introduce selection bias; reproducibility without proprietary tools is unclear.
- No statistical rigor on reported gains: confidence intervals, significance tests, and variability across random seeds are absent, especially for Best-of-N outcomes and “emergent” phenomena.
- Interleaved traces increase sequence length and memory footprint; there is no analysis of context window limits, memory-compute trade-offs, or degradation from longer multimodal sequences.
- Failure modes are underexplored: where does interleaving hurt (e.g., ChartQA), why, and how can the model detect and avoid unnecessary visual thinking?
- Robustness and safety are not assessed: susceptibility to adversarial or cluttered images, hallucinated edits (e.g., spurious bounding boxes), bias amplification from curated datasets, and error calibration remain open.
- No mechanism for self-checking and repair of visual thoughts: can the model detect incorrect edits and revise them? Training signals for self-correction are not investigated.
- Aggregation and governance of multimodal thoughts are missing: how to summarize, compress, or prune visual and textual steps without losing utility? How to make the reasoning trace interpretable and auditable?
- Scalability and data efficiency are unclear: do gains improve monotonically with more interleaved data? Are there scaling laws for interleaved traces vs unimodal traces?
- Cross-lingual and cross-domain generalization is untested: performance on non-English prompts, document images, scientific figures, medical imaging, and remote sensing remains unknown.
- Integration with tools vs unified-only reasoning is not studied: when do external tools (e.g., detectors, segmenters) complement interleaved generation, and how to decide between them dynamically?
- Practical deployment concerns are unaddressed: throughput under Best-of-N, latency constraints, memory pressure from image tokens, and cost-aware inference strategies for interleaved reasoning.
Practical Applications
Overview
ThinkMorph introduces a unified multimodal “think-and-sketch” capability: models interleave textual reasoning with visual manipulations (e.g., overlays, bounding boxes, zoom-ins, inpainting) to solve vision-centric tasks. It demonstrates emergent properties (unseen visual edits, autonomous mode switching, and better test-time scaling via diversified multimodal thoughts) and strong generalization on spatial navigation, visual search, jigsaw assembly, and chart refocus tasks.
Below are practical applications derived from these findings, grouped by deployment horizon.
Immediate Applications
The following applications can be prototyped with current models and tooling, leveraging ThinkMorph’s publicly available code/models and standard integrations.
- Chart-focused BI copilot for insight extraction Sector: finance, energy, operations Tool/workflow: “ChartFocus” assistant embedded in Tableau/PowerBI to highlight relevant bars/lines, compute values, and narrate rationale using interleaved text plus visual overlays Assumptions/Dependencies: integration with BI APIs; accurate OCR/data binding; domain fine-tuning to company-specific charts; governance for numerical accuracy and audit logs
- E-commerce visual QA assistant for product support and catalog quality Sector: retail, software Tool/workflow: “Visual QA” bot that draws bounding boxes on product images to confirm presence/attributes (e.g., color, logo placement), and explains decisions step-by-step Assumptions/Dependencies: curated product imagery; privacy and PII handling; fine-tuning on category-specific attributes; acceptance testing to reduce false positives
- Design review copilot for UX/UI teams Sector: software, media/design Tool/workflow: Figma/Adobe plugin that overlays annotations (alignment checks, spacing highlights, callouts to misplacements) and provides text reasoning to support decisions Assumptions/Dependencies: plugin APIs; reliable image-token generation latency; IP/content security; domain prompt templates for UI heuristics
- Warehouse and facility route-planning assistant (static maps) Sector: robotics, logistics, manufacturing Tool/workflow: “Path Overlay” tool for floor maps that proposes safe paths, overlays arrows/lines, and outputs human-readable steps for operators Assumptions/Dependencies: up-to-date map data; obstacle labels; non-real-time usage; safety review and human-in-the-loop verification
- STEM/data literacy tutor for diagrams and charts Sector: education Tool/workflow: “Think-and-Sketch Tutor” that highlights geometry components, physics vectors, or chart regions, and narrates reasoning for students Assumptions/Dependencies: curriculum alignment; guardrails against hallucinations; accessibility features; classroom deployment protocols
- Accessibility aid for chart comprehension Sector: public services, healthcare (patient education) Tool/workflow: assistive app that combines visual highlights with clear textual/audio explanations of chart content (values, trends, outliers) Assumptions/Dependencies: device compatibility; evaluation with accessibility guidelines (WCAG); robust numeric extraction
- Document intelligence with visual audit trails Sector: legal/compliance, enterprise software Tool/workflow: “Multimodal Audit” pipeline that highlights clauses/regions in scanned documents and explains extraction logic; interleaved traces serve as explainability artifacts Assumptions/Dependencies: OCR quality; secure storage; domain-specific fine-tuning on contracts/forms; policy-aligned redaction
- Dataset curation and model debugging for vision tasks Sector: academia, MLOps Tool/workflow: Human-in-the-loop curation using interleaved reasoning to filter ambiguous visual QA items; bounding-box size constraints; automated quality checks Assumptions/Dependencies: compute for batch inference; annotator workflows; adherence to licensing; reproducibility with vlmevalkit or similar
- Content moderation with localized evidence Sector: social platforms, policy enforcement Tool/workflow: Moderation assistant that flags policy-violating regions with bounding boxes and textual rationale for reviewer triage Assumptions/Dependencies: policy definitions; domain safety tuning; reviewer tools; privacy controls
- Medical imaging triage (assistive, non-diagnostic) Sector: healthcare Tool/workflow: Triage assistant that proposes zoomed-in views or bounding boxes for suspected findings, with textual reasoning to prioritize radiologist review Assumptions/Dependencies: medical dataset adaptation; strict human oversight; regulatory disclaimers; secure PHI handling; institution approvals
- Reliability layer using Best-of-N diversified multimodal thoughts Sector: software/AI platforms, safety-critical workflows Tool/workflow: Sampling-based inference wrapper that collects multiple interleaved traces, ranks candidates, and selects the best answer for increased robustness Assumptions/Dependencies: additional compute budget; de-duplication/consistency checks; guardrails for conflicting rationales; logging for auditability
Long-Term Applications
The following concepts require additional research, scaling, domain adaptation, or regulatory approvals before broad deployment.
- Real-time embodied robot copilot with adaptive mode switching Sector: robotics, manufacturing, logistics Tool/workflow: On-device “Think-and-Sketch” agent that plans paths, manipulates objects, and explains actions via overlays and textual steps, switching modes based on task complexity Assumptions/Dependencies: low-latency image-token generation; 3D perception/sensor fusion; robust safety guarantees; hardware acceleration
- AR maintenance and navigation assistant Sector: industrial maintenance, field services, public safety Tool/workflow: AR glasses overlay that highlights components, paths, and inspection locations; narrates reasoning; supports hands-free workflows Assumptions/Dependencies: accurate spatial registration; environment mapping; ergonomic UX; edge compute; connectivity
- Clinical decision support in radiology/surgery Sector: healthcare Tool/workflow: Regulated CDS that interleaves visual edits (segmentation, measurements) with textual rationale; produces explainable traces for clinician review Assumptions/Dependencies: large domain datasets; clinical validation trials; FDA/CE approvals; bias/safety evaluation; integration with PACS/EHR
- Explainable autonomy for vehicles and drones Sector: mobility, aerospace Tool/workflow: System that overlays intended trajectories, hazard highlights, and textual justifications to improve transparency and post-hoc analysis Assumptions/Dependencies: high-throughput streaming; stringent safety constraints; compliance with standards; liability frameworks
- Scientific imaging copilot Sector: academia, biotech Tool/workflow: Assistant that proposes visual manipulations (zoom, crop, inpainting for reconstruction checks) and textual analyses for microscopy or remote sensing data Assumptions/Dependencies: domain-specific calibration; reproducible pipelines; peer-reviewable audit traces; large labeled datasets
- Policy and standards for interleaved reasoning trace logging Sector: policy/regulation, governance Tool/workflow: Standardized schemas for multimodal CoT logs (text + image tokens) to support auditability, incident response, and risk assessments Assumptions/Dependencies: multi-stakeholder consensus; privacy-preserving designs; legal harmonization across jurisdictions; compliance tools
- Adaptive educational platforms that switch reasoning modes Sector: education Tool/workflow: Next-gen tutoring systems that dynamically decide when to rely on text vs. visuals to optimize learning outcomes Assumptions/Dependencies: longitudinal classroom trials; pedagogy-aligned metrics; student safety/ethics reviews; curriculum integration
- Multimodal developer IDE for robotics and vision systems Sector: software tooling Tool/workflow: “SketchPad CoT” IDE with stepwise visual annotations, error localization, and test-time scaling utilities to debug perception/planning pipelines Assumptions/Dependencies: broad ecosystem adoption; plug-ins for simulators and real sensors; versioned audit logs
- Multimodal search and retrieval with generated visual intents Sector: information retrieval, media Tool/workflow: Search engine that augments queries with visual manipulations (e.g., proposed bounding boxes or path overlays) to improve retrieval precision and explainability Assumptions/Dependencies: indexers supporting multimodal features; content licensing; guardrails for synthetic edits; evaluation benchmarks
- Disaster response and urban planning analysis Sector: public sector, NGOs Tool/workflow: Satellite/imaging analysis copilot that highlights damage zones, proposes access routes, and explains decisions for rapid response Assumptions/Dependencies: geospatial calibration; near-real-time data; cross-agency interoperability; ethical use and community engagement
- Grid and infrastructure inspection Sector: energy, utilities Tool/workflow: Visual anomaly detection with highlighted evidence and text reasoning for transmission lines, pipelines, and substations Assumptions/Dependencies: high-resolution domain data; safety certification; integration with asset management systems
- Manufacturing assembly planning (from jigsaw to parts) Sector: manufacturing Tool/workflow: Assistant that proposes part arrangements with visual overlays, verifies fit, and explains sequence steps—generalizing jigsaw reasoning to CAD-level assemblies Assumptions/Dependencies: CAD integration; precise tolerances; mechanical constraints modeling; real-world validation
- Compute-aware mode scheduling for edge AI Sector: software/AI infrastructure Tool/workflow: Runtime that leverages autonomous mode switching to minimize compute (text-only when sufficient; interleaved when necessary) without degrading accuracy in production Assumptions/Dependencies: telemetry and policy controls; confidence estimation; safety fallback mechanisms; careful monitoring for drift
These applications rely on ThinkMorph’s demonstrated strengths: high-quality interleaved supervision, emergent visual manipulation skills, adaptive mode selection, and robust test-time scaling. Their feasibility will improve with domain-specific fine-tuning, standardized logging/audit tooling, and careful governance for safety, privacy, and reliability.
Glossary
- Best-of- sampling: A test-time strategy that samples multiple reasoning trajectories and selects the best answer among them. "We compare interleaved and unimodal reasoning under Best-of- sampling across four benchmarks representing a continuum of distribution shifts"
- Bounding box: A rectangular region used to localize objects in an image. "we enforce a constraint that the target object’s bounding box must occupy between 1% and 30% of the image area."
- Chain-of-Thought: A technique where models generate intermediate reasoning steps to improve problem-solving. "While textual Chain-of-Thought (hereafter, “text thought”) has advanced verbal reasoning, it contributes little to multimodal reasoning"
- Complementary modalities: Treating text and images as different but mutually reinforcing information channels in reasoning. "text and image thoughts should function as complementary, rather than isomorphic, modalities that mutually advance reasoning."
- Cross-modal reasoning: Problem solving that requires coordinated reasoning across different modalities, such as text and images. "These limitations motivate a shift from language-driven reasoning to genuinely cross-modal reasoning—mirroring the human ability to tackle complex problems through “think-and-sketch” strategies."
- Delimiter tokens: Special tokens that explicitly mark boundaries between different modalities in a sequence. "modality transitions are controlled via delimiter tokens."
- Diffusion-based generative objectives: Training objectives for generative image models (e.g., diffusion models) that can impact understanding performance. "optimizing diffusion-based generative objectives tends to degrade understanding capabilities"
- Distribution shifts: Changes in data characteristics between training and evaluation that challenge generalization. "across four benchmarks representing a continuum of distribution shifts"
- Emergent properties: Capabilities that arise during training and inference without explicit supervision for them. "Beyond performance improvements, interleaved reasoning also exhibits #1{emergent properties} that arise naturally during training and evaluation"
- Image inpainting: Filling in or reconstructing missing or occluded parts of an image. "while terms like “restore” and “reconstruct” prompt image inpainting."
- In-domain evaluation: Testing on data that matches the training distribution. "For in-domain evaluation, we use VSP-main-task"
- Interleaved Chain-of-Thought: A reasoning approach where textual and visual thoughts are alternated within a single sequence. "researchers have explored multimodal interleaved Chain-of-Thought (hereafter, “interleaved thought”), yet existing approaches remain limited."
- Interleaved reasoning: Coordinated reasoning that dynamically alternates between text and image steps. "ThinkMorph’s interleaved reasoning consistently outperforms text-only and vision-only approaches by 5.33%."
- Latent visual tokens: Compact, learned token representations of visual information used to aid text-based reasoning. "latent visual tokens, which provide additional visual cues for text-based reasoning without explicit interleaving."
- LLM-as-a-Judge: Using a LLM to automatically assess the correctness of model outputs. "we adopt GPT-5 as an LLM-as-a-Judge."
- Mean Squared Error (MSE) loss: A regression loss measuring the average squared difference between predicted and target values, here applied to image tokens. "we optimize dual objectives: Mean Squared Error (MSE) loss $\mathcal{L}_{\text{img}$ for image tokens"
- Motion forecasting: Predicting future movement patterns or trajectories in visual scenes. "these manipulations also include inpainting, multi-box generation, motion forecasting, perspective transformation, and region cropping"
- Negative log-likelihood loss: A probabilistic loss function used for training models to assign high likelihood to correct sequences, here for text tokens. "and negative log-likelihood loss $\mathcal{L}_{\text{text}$ for text tokens."
- Out-of-domain benchmarks: Evaluation datasets that differ substantially from the training distribution to test generalization. "For out-of-domain evaluation, we further test on a broad suite of vision-centric multimodal benchmarks"
- Perspective transformation: Geometric manipulation that changes the viewpoint or projection of an image. "these manipulations also include inpainting, multi-box generation, motion forecasting, perspective transformation, and region cropping"
- Pretraining (multimodal pretraining): Large-scale initial training to learn general cross-modal patterns and capabilities. "This capability originates from Bagel’s large-scale multimodal pretraining"
- Test-time scaling: Improving accuracy by sampling or ensembling multiple model outputs at inference time. "Interleaved reasoning enables superior test-time scaling by generating diversified thoughts"
- Unified model: A single model that jointly supports both visual generation and understanding, enabling interleaved multimodal reasoning. "We introduce ThinkMorph --- a unified model fine-tuned on ∼24K interleaved traces"
- Unimodal baselines: Baseline systems or settings that use only one modality (text-only or image-only) for reasoning. "we derive two unimodal baselines: textual thoughts obtained by prompting GPT-4.1 … and visual thoughts using only the image outputs"
- Visual grounding: Aligning textual reasoning with specific regions or elements in an image. "In MMVP, visual grounding is essential for spatial cues that text cannot express"
- Visual tokens: Discrete tokens representing visual information used within multimodal sequences. "introducing intermediate image representations as visual tokens."
- Zoom-in operations: Visual manipulations that magnify a region to inspect fine details. "We identify eight distinct types of unseen visual manipulations, with zoom-in operations being the most common."
Collections
Sign up for free to add this paper to one or more collections.