Planned Diffusion
Abstract: A central challenge in LLM inference is the trade-off between generation speed and output quality. Autoregressive models produce high-quality text but generate tokens sequentially. Diffusion models can generate tokens in parallel but often need many iterations to match the same quality. We propose planned diffusion, a hybrid method that combines the strengths of both paradigms. Planned diffusion works in two stages: first, the model creates a short autoregressive plan that breaks the output into smaller, independent spans. Second, the model generates these spans simultaneously using diffusion. This approach expands the speed-quality Pareto frontier and provides a practical path to faster, high-quality text generation. On AlpacaEval, a suite of 805 instruction-following prompts, planned diffusion achieves Pareto-optimal trade-off between quality and latency, achieving 1.27x to 1.81x speedup over autoregressive generation with only 0.87\% to 5.4\% drop in win rate, respectively. Our sensitivity analysis shows that the planning mechanism of planned diffusion is minimal and reliable, and simple runtime knobs exist to provide flexible control of the quality-latency trade-off.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces a new way for AI models to write text faster without losing much quality. It’s called “planned diffusion.” The idea is to mix two styles of writing that AI uses:
- Autoregressive (AR): writing one token (piece of a word) at a time, like typing word by word. It’s very accurate but slow.
- Diffusion: filling in many blanks at once in parallel, like completing a puzzle by placing several pieces together. It’s fast but can get messy if rushed.
Planned diffusion first creates a short plan (sequentially) to break the answer into independent parts, then writes those parts at the same time (in parallel). This gives a better balance between speed and quality.
Key Questions
The paper explores simple, practical questions:
- Can we make AI text generation faster without hurting quality too much?
- Can a model learn when parts of an answer can be written at the same time?
- Does mixing planning (sequential) with diffusion (parallel) beat existing methods on real tasks?
How the Method Works
Think of it like a group project:
- Step 1: Make a plan that splits the work into clear, separate sections.
- Step 2: Have team members work on those sections at the same time.
Two-stage generation: plan then parallel write
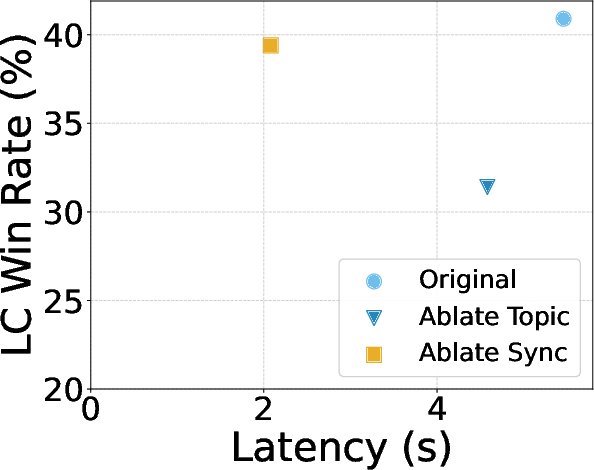
- Planning stage (AR): The model writes a brief plan using special tags. For example:
<topic> ... </topic>tells what each part will cover and about how long it should be.<async> ... </async>marks the sections that can be written in parallel.<sync/>marks a point where the model should pause; everything written before this becomes available to the next steps.
- Parallel stage (diffusion): The model fills in the content inside each
<async>section at the same time.
Training the model
To teach the model this behavior, the authors:
- Created a dataset where answers are annotated with the tags above. A strong model (Gemini) helps insert tags into responses to show which parts can be parallelized.
- Trained a single model on two objectives:
- Autoregressive loss to learn good planning.
- Diffusion loss to learn how to fill in masked tokens in parallel inside
<async>sections.
- Used custom “attention” rules (which control what the model can look at while writing):
- Planning tokens use causal attention (the model only looks left, like reading from start to the current point).
- Inside each
<async>section, the model uses bidirectional attention (looks left and right) to write coherently in parallel. - Different
<async>sections don’t talk to each other until a<sync/>tag allows it.
Making it fast at run time
- KV caching: Think of this as remembering previous computations so you don’t redo them. It speeds up the planning. Inside parallel spans (which look both ways), caching is limited, but after spans are done, future steps can reuse their "memory."
- Steps ratio: A simple knob to trade speed for quality. If
steps ratiois higher, the model takes more diffusion steps and writes better but slower. Lower ratio means faster but riskier. - Smart unmasking: The model reveals tokens in an order that reduces uncertainty (entropy) to keep the text coherent.
Main Findings
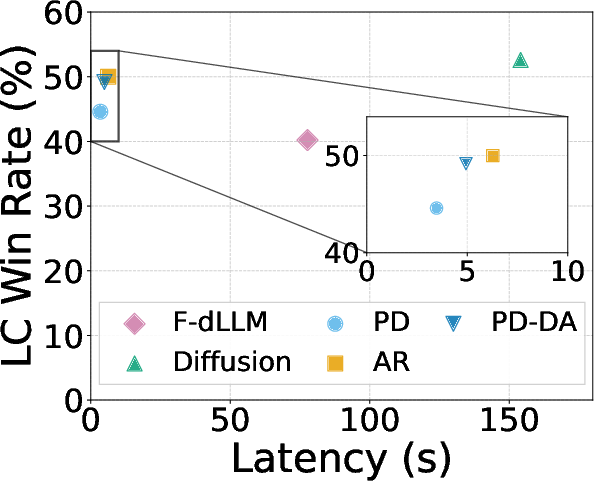
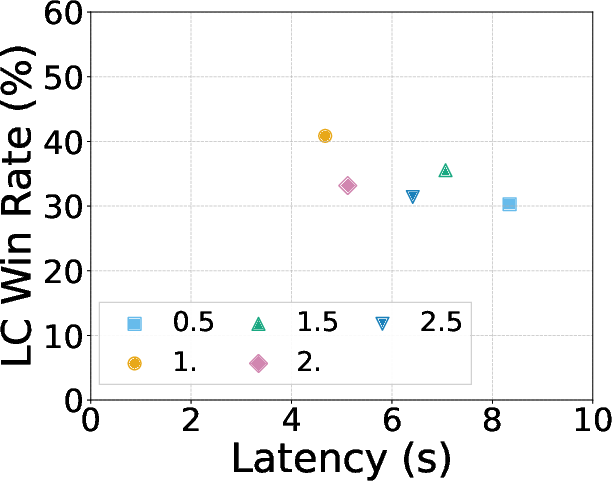
On AlpacaEval (805 instruction-following tasks), planned diffusion:
- Achieves a faster speed than standard autoregressive writing:
- 1.27× to 1.81× speedup depending on settings.
- Keeps quality close:
- Only a 0.87% to 5.4% drop in win rate compared to pure autoregressive.
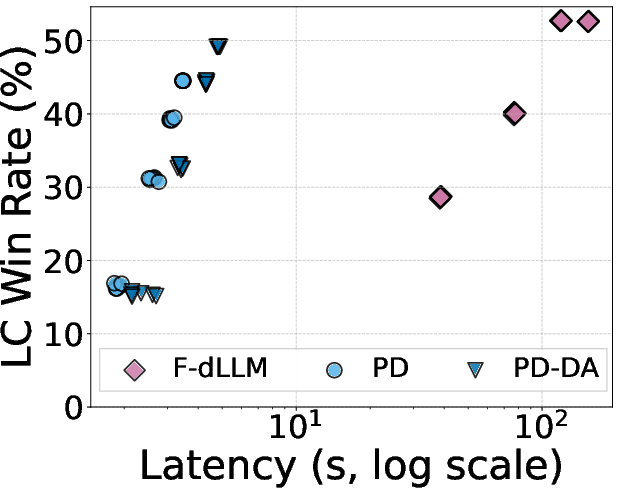
- Outperforms a popular fast diffusion method (Fast-dLLM) with much higher speed and better quality.
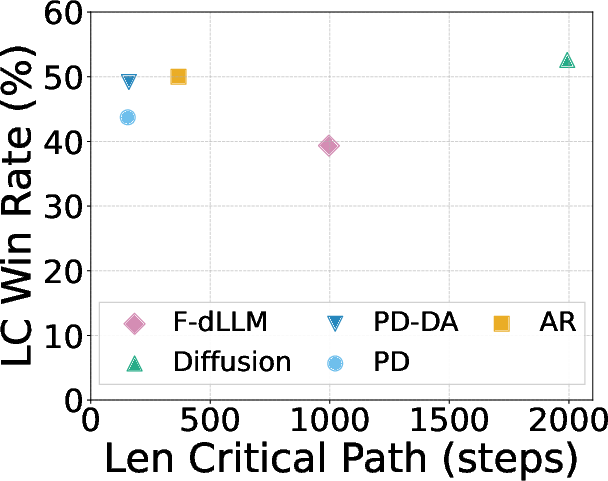
- Reduces the “critical path” (the number of sequential steps needed) by about 2.3× to 2.8×, which explains why it’s faster.
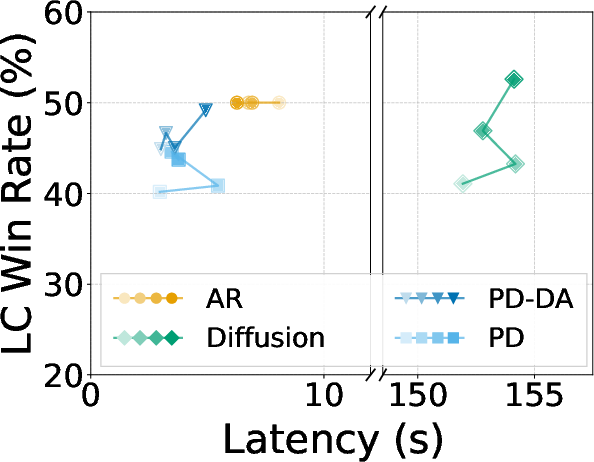
- Scales well: quality improves as you train more, whereas the pure autoregressive baseline stops improving.
The authors also tried a variant called “dense attention,” where parallel spans can fully look at each other. It’s more hardware-friendly and gives higher quality at a modest speedup.
Why This Is Important
Today’s LLMs are powerful but can be slow, especially when writing long answers one token at a time. Planned diffusion:
- Makes writing faster by doing parts in parallel.
- Keeps the text coherent by planning structure first.
- Lets users and developers choose their preferred speed–quality balance with simple controls (like a “speed slider”).
This could make AI more responsive and more practical in real-time settings like chat assistants, coding help, and educational tools.
Implications and Impact
- Practical speed-ups: Chatbots and assistants can reply faster with almost the same quality.
- Better use of hardware: Parallel generation fits modern GPUs well.
- Single hybrid model: Unlike methods that need multiple models (like speculative decoding), planned diffusion trains one model to plan and write in parallel.
- Flexible control: Easy knobs let you tune for speed or quality depending on the situation.
- Future directions: This framework can combine with other diffusion speedups and inspire new ways to structure model outputs into parallelizable chunks.
In short, planned diffusion shows a clear path to faster, high-quality AI text generation by planning first and writing smartly in parallel.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues and concrete opportunities for future research raised by the paper.
- Generalization across tasks: Evaluate planned diffusion on diverse generation settings (reasoning chains, long-form writing, code generation, multi-turn dialogue, knowledge-intensive QA) to test whether semantic parallelism and planning remain effective beyond instruction-following prompts.
- Human evaluation: Validate LLM-as-judge LCWR results with human preference studies and task-specific metrics (e.g., coherence, factual accuracy, consistency), including significance tests and inter-rater agreement.
- Robustness of plans at inference: Measure error rates of malformed or incoherent control-tag plans (e.g., unbalanced or missing <async>/<topic>/<sync/> tags), and develop recovery strategies (plan validation, auto-repair, fallback to AR) with quantitative impact on latency and quality.
- Formal criteria for “semantic independence”: Define and validate metrics to detect when spans can be safely parallelized (e.g., dependency tests, causal influence estimates), and quantify how violations affect coherence and correctness.
- Length prediction and adaptability: Investigate mechanisms to adapt span lengths during diffusion (e.g., end-of-span markers, dynamic re-masking or extension) to prevent truncation or over-padding when predicted lengths are wrong.
- Multi-iteration scheduling: Analyze and optimize the number and structure of planning/execution iterations (e.g., hierarchical or nested spans, staggered sync barriers, overlapping parallel windows) and their effect on latency-quality trade-offs.
- Learned controllers for latency budgets: Develop policies that select step ratio r, confidence threshold τ, and number/size of spans per prompt to meet latency or quality targets, and train them end-to-end (e.g., RL or constrained optimization).
- Integration with diffusion accelerators: Empirically evaluate combining planned diffusion with dKV caching for bidirectional attention, autoregressive verification, and fast sampling (e.g., Fast-dLLM inside spans), and quantify additive speedups and quality effects.
- Attention mask design: Characterize when dense cross-span attention (PD-DA) is beneficial vs. block-sparse independence, and provide guidance or learned switching strategies per prompt/span.
- Independence assumption validity: Quantify cross-span informational leakage under the factorization p_D(x|z,c)=∏_k p_D(x(k)|z,c), identify failure cases, and assess coherence degradation vs. speed benefits.
- KV caching within spans: Explore approximate or partial KV caching for bidirectional denoising (e.g., windowed caching, low-rank reuse, segment-wise freezing) and its net effect on throughput and memory.
- Unmasking schedule choices: Compare entropy-ordered unmasking against alternative schedules (confidence-ordered, learned policies, diffusion-step curriculum), and measure sensitivity across tasks.
- Model scale and pretraining dependence: Test planned diffusion across model sizes and architectures (including purely AR-pretrained bases) to isolate the effect of diffusion pretraining and assess scalability to larger LLMs.
- Data annotation dependence and bias: Assess how reliance on Gemini-annotated SlimOrca affects learned planning behavior (topic and length biases), and investigate self-supervised or weakly supervised planning without external taggers; release or replicate the annotation pipeline.
- Control-tag language design: Explore alternative or minimal tag schemes (e.g., soft prompts, latent plans, learned structural tokens), nesting support, and cross-lingual tokenization issues; quantify their impact on usability and performance.
- Error handling and plan revision: Develop iterative repair mechanisms (autoregressive verification, span-level re-diffusion, local AR edits) when the plan’s topics or lengths are poor, and assess latency overhead vs. quality gains.
- Quality-length confounding: Investigate why planned diffusion outputs fewer tokens on average, ensure fairness of LCWR normalization, and analyze whether shorter responses systematically influence judge preferences.
- Coherence and factual accuracy: Report task-level metrics for coherence across spans and factual correctness, especially when <sync/> barriers are reduced or removed; identify prompts where parallelization harms reasoning fidelity.
- Hardware and throughput characterization: Provide detailed throughput (tokens/sec), GPU utilization, memory footprint, and batch-size scaling across different accelerators (A100/H100/H200 and consumer GPUs), including PD vs. PD-DA trade-offs.
- Long-sequence behavior: Evaluate performance on very long generations (near or beyond 2048 tokens), measuring critical-path gains, memory limits, and quality degradation patterns.
- Streaming and interactive settings: Study planned diffusion in streaming/online generation and multi-turn dialogue, including partial-span availability and user interjections across sync barriers.
- Adaptive span partitioning: Compare model-generated spans to algorithmic partitioners (e.g., learned dependency graphs, external schedulers) and test hybrid planning (model proposes, scheduler refines) for better parallelization.
- Training objective choices: Justify and ablate the 1/t weighting and single-t diffusion across iterations in the loss, analyze training stability, and compare against alternative diffusion objectives (e.g., noise schedules, denoising score matching variants).
- Resource efficiency and energy: Measure energy consumption and cost per response vs. AR/diffusion baselines to substantiate practical benefits under real deployment constraints.
- Reproducibility assets: Release code, checkpoints, and full annotation prompts/examples; quantify the reproducibility gap and provide scripts for block-sparse attention kernels used by planned diffusion.
- Safety and failure analysis: Examine failure modes (hallucinations, brittle plans, incoherent merges) under adversarial prompts targeting plan generation, and propose safeguards or detectors.
- Multilingual/generalization: Test planned diffusion in non-English settings and with different tokenizers/vocabularies, including code tokens and domain-specific lexicons; verify that control tags and planning generalize.
Practical Applications
Immediate Applications
The following applications can be deployed now by integrating the planned diffusion decoding workflow into existing LLM-serving stacks or by fine-tuning compatible models as described in the paper. Each item links a specific use case to sectors, potential tools or workflows, and key feasibility considerations.
- Software and developer productivity
- Use case: Accelerated code generation in IDEs by planning functions/tests/docstrings as independent spans and denoising them in parallel.
- Tools/workflows: “Plan-and-Diffuse” IDE plugin; tag-aware code assistant that creates a short AR plan and diffuses spans with a configurable step ratio r; dense-attention variant for GPU efficiency.
- Dependencies: Requires a planned-diffusion-trained model on code data; correctness is sensitive to span independence (e.g., cross-function dependencies); integrates with KV caching and hybrid attention.
- Customer support, CX, and chatbots
- Use case: Faster multi-bullet answers (FAQs, troubleshooting steps) with minimal quality loss for call centers and help desks.
- Tools/workflows: Contact-center bot update using control tags (<topic/async/sync>), entropy-ordered unmasking, and runtime knobs (r and τ) to meet SLAs.
- Dependencies: Tag stripping in outputs; domain grounding (RAG/tool-use) must be preserved through planning; monitor quality with LCWR-like metrics.
- Search and RAG systems
- Use case: Multi-part answers (definition, steps, caveats, sources) generated in parallel; reduced wall-clock latency in end-to-end retrieval pipelines.
- Tools/workflows: RAG orchestrator that plans sections (e.g., “Summary,” “Evidence,” “Citations”) and diffuses them concurrently; per-span citation insertion after <sync/>.
- Dependencies: Ensure that planned spans do not need unseen details before <sync/>; careful treatment of citations and provenance.
- Content creation and marketing
- Use case: Blog posts, product pages, and campaign briefs with parallel section generation (intro, features, benefits, CTA).
- Tools/workflows: CMS plugin incorporating planned diffusion with length scaling factor set to 1.0 (as validated); dense attention for better GPU utilization.
- Dependencies: Acceptance of small quality deltas; editorial human-in-the-loop for brand tone.
- Education and tutoring
- Use case: Faster structured explanations (overview, examples, exercises) and graded feedback.
- Tools/workflows: Edtech tutor that plans response skeleton (topics + coarse lengths) then diffuses sections; per-lesson latency-quality knobs.
- Dependencies: Safety/age-appropriateness filters; span independence in pedagogical layouts.
- Healthcare documentation
- Use case: Drafting clinical notes (HPI, assessment, plan) and discharge summaries by parallelizing well-defined sections.
- Tools/workflows: EHR assistant that plans standard sections via control tags and diffuses each section in parallel; strict post-generation verification.
- Dependencies: HIPAA-compliant deployment; medical-domain fine-tuning; high-accuracy requirement suggests higher r (more steps).
- Legal and policy drafting
- Use case: Accelerated drafting of multi-clause contracts and policy memos (scope, definitions, obligations, limitations).
- Tools/workflows: Drafting assistant that pre-plans clauses and generates parallel text spans; implements <sync/> barriers for cross-references.
- Dependencies: Human review for legal soundness; span layout must respect interdependencies (definitions referenced by clauses).
- Finance and reporting
- Use case: Faster earnings summaries and risk reports with parallel sections (highlights, KPIs, outlook, risks).
- Tools/workflows: Report generator using planned diffusion; quality guardrails; per-span fact-checking after <sync/>.
- Dependencies: Data integrity and auditability; domain-specific fine-tuning; conservative r settings.
- Real-time summarization for media and meetings
- Use case: Low-latency live transcript summarization (agenda, decisions, action items) by parallelizing independent sections.
- Tools/workflows: Streaming summarizer setting step ratio r below 1.0 for faster turnaround and τ tuned to maintain readability.
- Dependencies: Streaming ingress/egress orchestration; accept moderate quality-speed trade-offs.
- E-commerce product Q&A
- Use case: Multi-part responses (compatibility, specs, use cases) with reduced latency.
- Tools/workflows: Storefront assistant employing planned spans; prompt templates that induce bullet structures.
- Dependencies: Domain-specific grounding; remove control tags from final UI.
- Personal productivity
- Use case: Email composition and note-taking where sections (greeting, body, action items) can be parallelized.
- Tools/workflows: Email client extension with planned diffusion and UI sliders for r and τ.
- Dependencies: Privacy constraints for local or enterprise hosting; user acceptability of minor quality changes.
- Data labeling and synthetic data pipelines
- Use case: High-throughput label generation (explanations, rationales, variants) with parallel spans to reduce latency and cost.
- Tools/workflows: Labeling service integrating planned diffusion; dashboards tracking critical-path reductions and LCWR proxies.
- Dependencies: Calibration of r/τ to meet quality targets; task suitability for semantic parallelism.
- Platform and infrastructure (ML Ops)
- Use case: Serving stack enhancements to support hybrid attention masks, tag-aware KV caching, and dense-attention variant for throughput.
- Tools/workflows: “Planned Diffusion Decoder” module for PyTorch/HF Transformers; block-sparse attention option; observability for r/τ sweeps.
- Dependencies: GPU kernels for dense attention; robust tag parsing/validation; integration tests for cache correctness.
- Datacenter cost and energy optimization
- Use case: Lower energy per response by shrinking the critical path and exploiting parallel denoising, with runtime adaptation to load.
- Tools/workflows: SLA-aware scheduler tuning r and τ per request; auto-configuration that omits <sync/> when acceptable (shown to cut latency significantly).
- Dependencies: Monitoring pipelines; quality guardrails; workload characterization to identify parallelizable outputs.
Long-Term Applications
These applications require additional research, scaling, or ecosystem development (e.g., domain-specific training, standardized tooling, or hardware/software co-design).
- Multimodal generation (ads, UI, documentation)
- Use case: Joint planning of text, images, and layout; parallel diffusion for multi-section assets (copy + visuals).
- Tools/workflows: Multimodal planned diffusion with synchronized cross-modal <sync/> points.
- Dependencies: New training objectives and datasets; multimodal attention masks; safety checks.
- Agent/tool-use orchestration
- Use case: Plans that map spans to tool calls (search, compute, database) and diffuse textual results in parallel.
- Tools/workflows: Agent frameworks that treat <topic/async/sync> as an orchestration language.
- Dependencies: Reliable planning and error recovery; tool latency variability; robust span-level caching.
- Hybrid acceleration with speculative decoding
- Use case: Combine speculative drafting with planned diffusion to further reduce critical path latency.
- Tools/workflows: Composite decoders (speculative AR for plan, diffusion for spans).
- Dependencies: Complexity of multi-stage verification; compatibility of caches and masks.
- On-device and edge deployment
- Use case: Mobile or embedded assistants with planned diffusion to achieve near-AR quality at lower latency/cost.
- Tools/workflows: Model distillation, kernel fusion, and dense-attention optimizations targeting NPUs.
- Dependencies: Efficient inference kernels; memory limits; privacy constraints.
- Standardization of control-tag schemas
- Use case: Interoperable “planning tags” for LLMs across vendors (topic, tokens, sync).
- Tools/workflows: Community spec; serving libraries; validators.
- Dependencies: Broad adoption and consensus; backward compatibility.
- Self-supervised planning tag discovery
- Use case: Models that learn when and how to parallelize without external annotation (automatic span discovery).
- Tools/workflows: Training objectives for discovering semantic independence; adaptive scheduling.
- Dependencies: Reliable metrics for independence; curriculum learning; robust evaluation.
- Span-level safety, compliance, and verification
- Use case: Moderation and fact-checking applied per span before <sync/>; reduce risk of propagating errors.
- Tools/workflows: Span classifiers, citation verifiers, red-team probes per section.
- Dependencies: Accurate detectors and calibrations; throughput-friendly verification pipelines.
- Collaborative drafting and co-authoring
- Use case: Multiple users (or agents) editing different spans concurrently with planned diffusion smoothing and synchronization.
- Tools/workflows: Real-time doc editors leveraging <sync/> barriers; conflict resolution strategies.
- Dependencies: Consistency guarantees; version control for spans; UX design.
- Domain-specialist models (medical, legal, finance)
- Use case: Field-specific planned diffusion models tuned for structure and accuracy in high-stakes settings.
- Tools/workflows: Curated datasets with tag schemas aligned to domain documents; stricter length prediction and r control.
- Dependencies: Data access, regulatory approvals, rigorous human oversight.
- Compiler-level scheduling and hardware co-design
- Use case: Automatic mapping of planned diffusion spans to GPU blocks/streams; dynamic block-sparse/dense switching.
- Tools/workflows: Graph compilers aware of hybrid attention masks; cost models optimizing critical path and utilization.
- Dependencies: Vendor kernel support; telemetry; cross-model generality.
- Streaming generation protocols
- Use case: Incremental outputs where spans are produced in overlapping windows; near-real-time interactive experiences.
- Tools/workflows: Streaming APIs for planned diffusion; chunked <sync/> semantics.
- Dependencies: Protocol design; partial-cache reuse; user experience tuning.
- Benchmarking and governance for semantic parallelism
- Use case: New evaluation suites measuring speed–quality Pareto frontiers and span independence across tasks.
- Tools/workflows: LCWR variants, critical-path metrics, domain-specific benchmarks; policy controls for r/τ.
- Dependencies: Community validation; alignment with human preference studies; reproducibility tooling.
Cross-cutting assumptions and dependencies
- Task suitability: Planned diffusion excels when outputs can be partitioned into semantically independent spans (lists, sectioned reports, multi-part answers). Highly interdependent reasoning tasks may need conservative settings or more <sync/> barriers.
- Model availability and training: Deployments need models trained with both AR and diffusion objectives plus control-tag vocabularies and attention masks; annotated data quality materially influences performance.
- Serving and engineering: Hybrid attention and tag-aware KV caching must be supported; dense-attention variant is often more GPU-friendly; careful tag stripping and post-processing is required.
- Quality–latency control: Operators must calibrate the step ratio r and confidence threshold τ for SLA targets; monitoring with LCWR-like metrics is recommended.
- Safety and compliance: High-stakes sectors (healthcare, legal, finance) require human oversight, verification, and domain-specific fine-tuning to mitigate risks.
Glossary
- AdamW: An optimizer that decouples weight decay from the gradient update to improve training stability and generalization. "We train with AdamW \citep{kingma2017adammethodstochasticoptimization,loshchilov2019decoupledweightdecayregularization}, peak learning rate with linear decay, and bfloat16 precision."
- AlpacaEval: A benchmark of instruction-following prompts used to evaluate LLM quality under length control. "On AlpacaEval, a suite of 805 instruction-following prompts, planned diffusion achieves Pareto-optimal trade-off between quality and latency"
- Any-order autoregressive: A modeling view where a diffusion model can answer arbitrary conditional queries, effectively supporting generation in any token order. "applying the interpretation of a diffusion model as an any-order autoregressive model capable of supporting arbitrary conditional queries at inference time"
- Attention mask: A mechanism that controls which tokens a model can attend to, enforcing causal or bidirectional dependencies during training and inference. "We implement the following rules via the attention mask ."
- Autoregressive planning: A sequential stage that produces a structured plan (with control tags) defining independent spans for later parallel generation. "The autoregressive planning stage uses causal attention and a conventional application of KV caching"
- Autoregressive verification: An acceleration technique that checks or corrects diffusion outputs using an autoregressive model. "the use of autoregressive verification \citep{hu2025accelerating, israel2025accelerating}"
- bfloat16 precision: A floating-point format with reduced mantissa used to speed up training while maintaining numerical stability. "and bfloat16 precision."
- Bidirectional attention: An attention mode where tokens within a span can mutually attend to each other in both directions, enabling parallel denoising. "tokens inside the same <async>\ldots</async> span use bidirectional attention"
- Block diffusion: A method that imposes an autoregressive structure over grouped blocks during diffusion generation. "Other related work include block diffusion \citep{arriola2025block} which enforces an autoregressive structure over blocks"
- Block-sparse attention: An attention pattern that restricts cross-span connections, improving efficiency by attending within blocks only. "this eliminates block-sparse attention and improves GPU utilization."
- Causal attention: An attention scheme that only allows tokens to attend to previous positions, enforcing sequential dependencies. "planning tokens, which are composed of control tags and their attributes, are given causal attention"
- Confidence threshold: A decoding hyperparameter that determines when to unmask a token based on the model’s top-token probability. "We configure denoising steps to be half the number of new tokens and use a confidence threshold of 0.9"
- Control tags: Special tokens that define planned structure and synchronization (<topic>, <async>, <sync/>, <eos/>) for hybrid generation. "We designed the control tag language, model training methodology, and inference algorithm"
- Critical path length: The number of sequential forward passes required to complete generation, reflecting inherent latency. "We define critical path length as the number of forward passes required to produce the final response."
- Cross-entropy loss: A standard training objective that measures prediction accuracy by comparing model probabilities with true tokens. "With as the cross-entropy loss, our overall training objective is given by"
- Dense attention: Full attention across concurrently generated spans, allowing cross-attention without block restrictions. "Planned diffusion with dense attention removes this independence assumption and uses dense attention during training and inference"
- Denoising steps: Iterative steps in diffusion sampling that progressively replace masks with predicted tokens. "Typically, diffusion models are configured to generate given a fixed number of denoising steps."
- Discrete Diffusion: A generative paradigm that reverses a token-masking corruption process to restore clean sequences. "Discrete Diffusion."
- Entropy-ordered unmasking: An inference strategy that decodes positions in increasing uncertainty order to improve diffusion quality. "We apply entropy-ordered unmasking, which is a default inference algorithm of Dream 7B \citep{ye2025dream}."
- Fast-dLLM: An inference-time optimization for diffusion LLMs that reduces steps while maintaining quality via confidence-based decoding. "Fast-dLLM \citep{wu2025fast} samples from the same diffusion model but with an inference-time only optimization."
- KV caching: A technique that reuses key/value attention states across steps to reduce computation during decoding. "KV caching plays a substantial role in the efficiency of planned diffusion."
- Length-controlled win rate (LCWR): A quality metric that evaluates model preference while controlling for response length. "length-controlled win rate (LCWR) with an LLM-as-judge."
- Pareto frontier: The set of non-dominated trade-offs balancing latency and quality in generation performance. "establishing a new Pareto frontier"
- Planned diffusion: A hybrid method that first plans autoregressively and then generates spans in parallel via diffusion. "We propose planned diffusion, a hybrid method that combines the strengths of both paradigms."
- Programmatic Scaffold: A structured placeholder representation that initializes each planned span with masks before diffusion. "Programmatic Scaffold: This plan is then translated into a scaffold where each span is initialized with a corresponding number of mask tokens."
- Semantic parallelism: The ability to generate multiple semantically independent text segments concurrently. "We define semantic parallelism as a broad class of techniques that produce models capable of parallelizing over semantically independent chunks of tokens."
- Speculative decoding: A parallel acceleration method that drafts multiple tokens and verifies them efficiently. "Speculative decoding accelerates autoregressive models by drafting multiple tokens and verifying them in parallel"
- Step ratio: A hyperparameter setting the number of diffusion steps relative to span length to trade off speed and quality. "We define a parameter called the steps ratio."
- Synchronization barrier: A decoding point (<sync/>) after which subsequent tokens can attend to all completed spans. "Recall that <sync/> marks a synchronization barrier"
- Top-p sampling: A nucleus sampling technique that restricts token choices to the smallest set whose cumulative probability exceeds p. "We sample with temperature $0.2$ and top- $0.95$"
- Variational lower bound: An optimization target that approximates the true likelihood in diffusion training. "maximizing a variational lower bound on the log-likelihood"
Collections
Sign up for free to add this paper to one or more collections.

