Tongyi DeepResearch Technical Report
Abstract: We present Tongyi DeepResearch, an agentic LLM, which is specifically designed for long-horizon, deep information-seeking research tasks. To incentivize autonomous deep research agency, Tongyi DeepResearch is developed through an end-to-end training framework that combines agentic mid-training and agentic post-training, enabling scalable reasoning and information seeking across complex tasks. We design a highly scalable data synthesis pipeline that is fully automatic, without relying on costly human annotation, and empowers all training stages. By constructing customized environments for each stage, our system enables stable and consistent interactions throughout. Tongyi DeepResearch, featuring 30.5 billion total parameters, with only 3.3 billion activated per token, achieves state-of-the-art performance across a range of agentic deep research benchmarks, including Humanity's Last Exam, BrowseComp, BrowseComp-ZH, WebWalkerQA, xbench-DeepSearch, FRAMES and xbench-DeepSearch-2510. We open-source the model, framework, and complete solutions to empower the community.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces Tongyi DeepResearch, a special kind of AI that acts like a tireless online research assistant. Its job is to handle tough, multi-step research tasks: plan what to do, search the web, read and understand information, run small code snippets when needed, and finally write a clear report. The big idea is to train this AI to work independently over long sessions, just like a person doing a detailed school project—but faster and more reliably.
Goals and Questions
The team set out to:
- Build an AI that can plan, search, reason, and combine information over many steps, not just answer simple questions.
- Train it without needing lots of expensive human-made examples by generating high-quality practice data automatically.
- Keep training stable and efficient by using carefully designed “practice environments.”
- Show that this AI can beat other strong systems on tough research tests.
- Share the model and tools with the community so others can improve or use it.
How It Works (Methods, in simple terms)
Think of training this AI like teaching a smart student to do deep research:
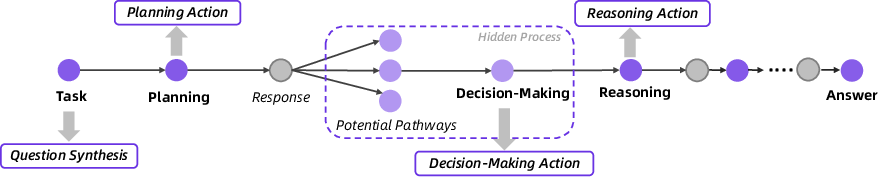
The AI’s working style: Think–Act–Observe
- First it thinks (“What should I do next?”).
- Then it acts (uses a tool like web search, visits a page, runs Python, reads a PDF, or checks Google Scholar).
- Then it observes (reads what came back) and updates its plan.
- It repeats these steps until it writes a final report and answer.
This is called a ReAct loop: Reason + Act, step by step.
Managing memory: a smart notebook
AI models have a limited “context window” (they can’t remember everything forever). Tongyi DeepResearch uses a running summary—like a tidy notebook—of the most important facts and steps so it stays focused and doesn’t get overwhelmed. After each step, it updates this summary and uses it to decide what to do next.
Training recipe: two big phases
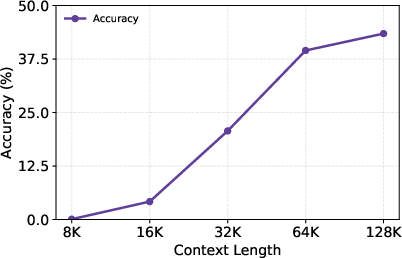
- Agentic mid-training (bootcamp): The model practices agent-like behaviors (planning, tool use, long reasoning) on huge amounts of automatically made practice data. It also learns to handle very long inputs (up to 128,000 tokens).
- Agentic post-training (advanced course): The model first imitates great examples (supervised fine-tuning for a “cold start”), then improves by trial and reward (reinforcement learning), getting points when its final answers match verified correct ones.
Synthetic data: automatic practice questions
Instead of hiring people to write millions of complex tasks, the team uses AI to generate:
- Hard, realistic questions that often need multi-step reasoning.
- Example plans for how to break problems into steps.
- Full reasoning chains showing how to reach answers.
- Decision points (what to do next) so the model learns to choose well.
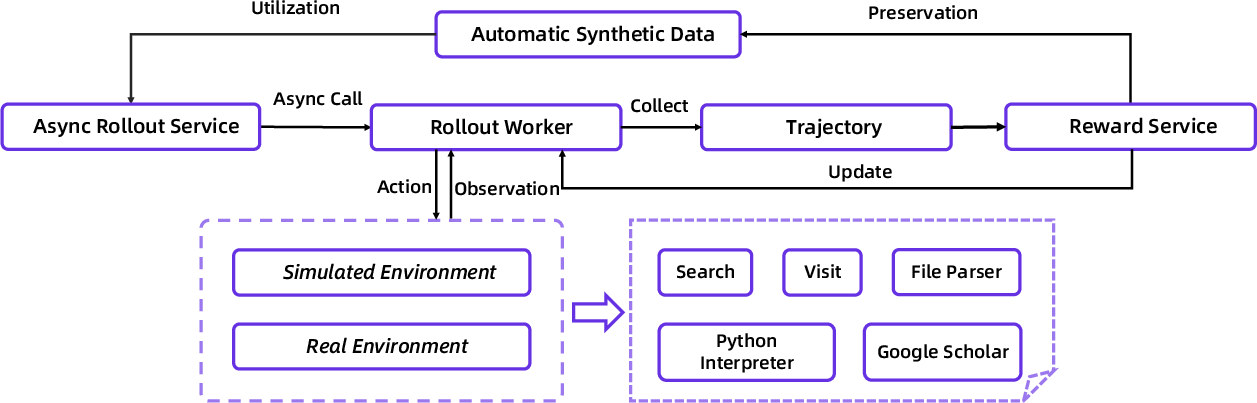
This synthetic data is fast to make, easy to check, and can be scaled up. As the model improves, it helps create even better practice data—a “data flywheel.”
Practice environments: safe training arenas
To keep training stable and affordable, the team uses three kinds of environments:
- Prior world: no live web calls—just tasks and tools defined, perfect for cheap, stable practice.
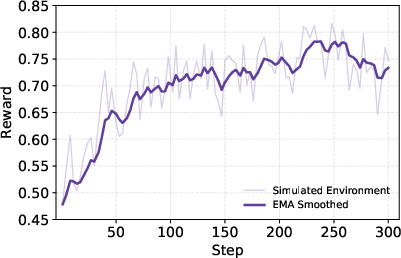
- Simulated world: a local copy of information (like a Wikipedia snapshot) with search tools, fast and controllable.
- Real world: the actual internet. Here they add a “sandbox” layer to make web tools reliable (retry on errors, cache results, switch to backups). This prevents random web problems from ruining training.
Speeding up learning
The model runs many research attempts in parallel and learns from them. A separate process keeps refreshing the training set: it filters out tasks that became too easy and adds new medium-hard ones, so the model keeps improving without hitting a plateau.
Model merging
If different trained versions are good at different skills, the team blends them (by averaging their parameters) to get a balanced final model—like combining the strengths of multiple teammates.
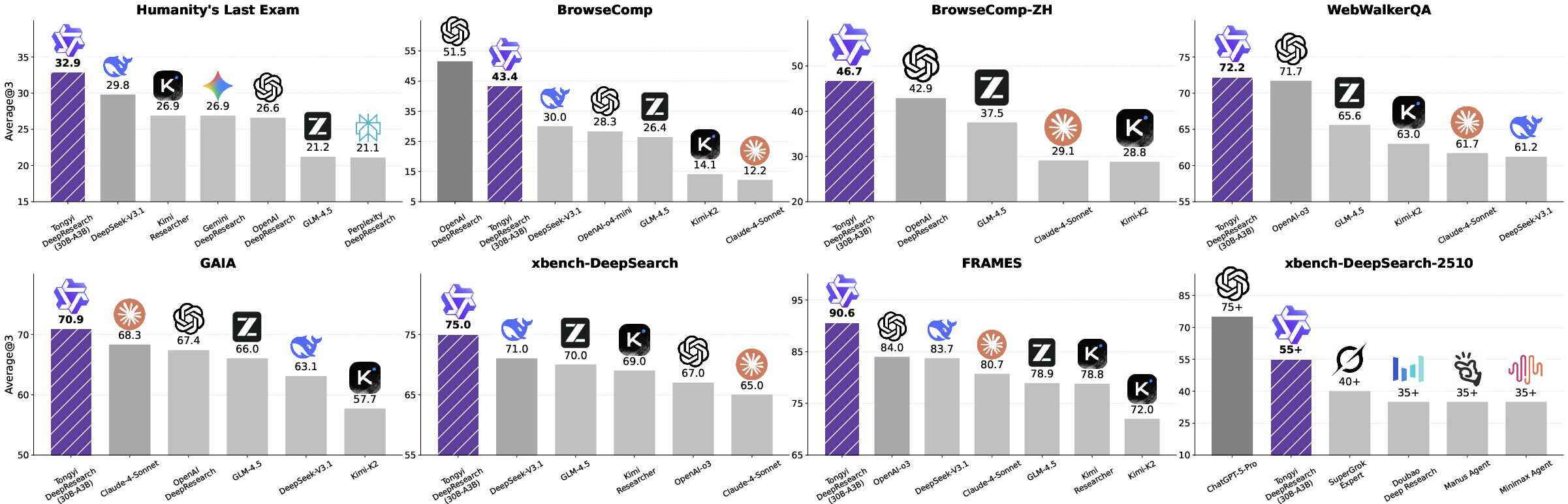
Main Results and Why They Matter
Tongyi DeepResearch is efficient and strong:
- The model has 30.5 billion total parameters but only activates about 3.3 billion per token (similar to a mixture-of-experts design). That means more power with less compute per step.
- It achieves top or near-top scores on many tough benchmarks:
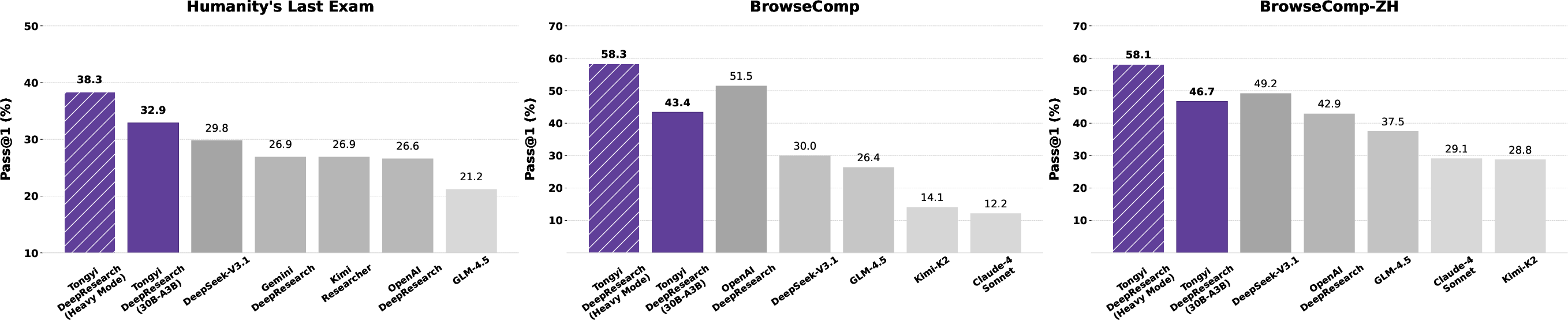
- Humanity’s Last Exam: 32.9
- BrowseComp: 43.4
- BrowseComp-ZH (Chinese): 46.7
- WebWalkerQA: 72.2
- GAIA: 70.9
- xbench-DeepSearch: 75.0
- FRAMES: 90.6
- xbench-DeepSearch-2510: 55.0
It often beats strong commercial systems (like OpenAI o3 and DeepSeek) while being open-source and more efficient.
Heavy Mode: smarter test-time scaling
For extra performance, they run several parallel “researchers” on the same question. Each one writes a compact summary of what it found. A final “synthesis” step combines these summaries to pick the best answer. This boosts scores further (for example, higher results on Humanity’s Last Exam and BrowseComp-ZH) without blowing up the context limit, because they aggregate summaries, not full raw logs.
Implications and Impact
This work shows a clear path to building open, capable AI research agents:
- It proves you can get great results without relying on expensive human labels by using smart synthetic data and well-designed training environments.
- It moves AI closer to doing useful, long, complex tasks—like helping students with deep projects, aiding scientists with literature reviews, or assisting analysts with multi-source investigations.
- Because it’s open-sourced, the community can reproduce, study, and extend it, which speeds up progress.
- The approach emphasizes stability, efficiency, and transparency—key qualities for trustworthy AI that can explain its steps and tools.
In short, Tongyi DeepResearch is a major step toward AI systems that can plan, search, and reason across the web like diligent researchers—making deep, reliable information work more accessible to everyone.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what the paper leaves uncertain or unexplored, intended to guide future research.
- Quantify real-world generalization from synthetic data: no measurement of how mid/post-training on fully synthetic agentic trajectories transfers to open-ended, non-benchmarked web tasks with noisy, evolving information.
- Synthetic data validation and bias: limited evidence that the proposed verification (set-theoretic modeling, entity operations) prevents subtle factual errors, spurious correlations, or biased reasoning patterns; no audit of dataset composition, sources, or demographic/topic bias.
- Data contamination risk: no safeguards reported to prevent overlap between synthesized questions and benchmark test sets (or leakage via Wikipedia 2024 snapshot), nor an audit proving independence from evaluation content.
- Scale and composition of training data: missing quantitative details (sizes, domains, language mix, proportion of agentic vs general data) for Agentic CPT and SFT datasets that are required to reproduce training outcomes.
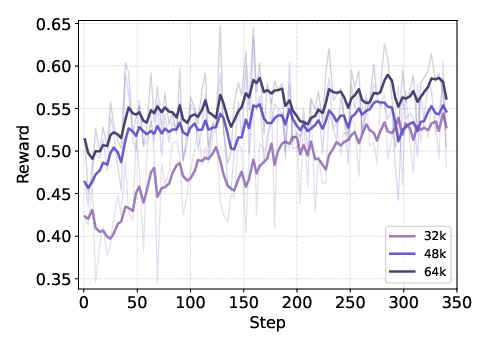
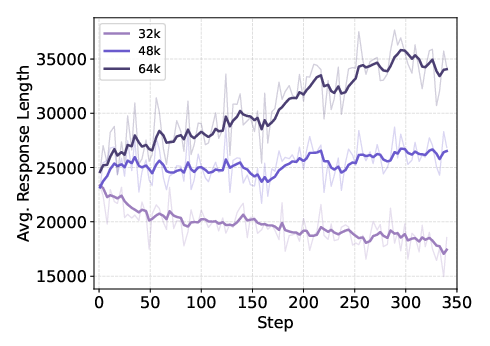
- Ablation of training stages: no controlled ablations isolating the marginal gains from mid-training vs SFT vs RL (including long-context expansion from 32K to 128K), making it unclear which components drive performance.
- Effectiveness of “Decision-Making Action” synthesis: the benefit of explicitly modeling decision sequences is asserted but not empirically isolated or quantified.
- Context management trade-offs: no analysis of information loss, error accumulation, or misprioritization introduced by Markovian state reconstruction (S_t) relative to full-history conditioning; no metrics for summary fidelity or citation retention.
- Long-horizon credit assignment: RL uses only binary final-answer rewards (RLVR), leaving open whether process-level rewards, step-level correctness, tool-use quality, or calibration signals would improve stability and sample efficiency.
- Reward for open-ended research: unresolved approach for tasks without ground-truth answers or with multiple valid answers, which are common in real research (e.g., literature reviews, hypothesis formation).
- Algorithm choice sensitivity: limited justification for GRPO adaptations (clip-higher, leave-one-out) vs alternatives (PPO/DPO/ORPO/off-policy methods, hierarchical or options-based RL); no head-to-head comparisons or robustness analysis.
- Exploration strategies: absence of exploration mechanisms (e.g., entropy scheduling, curiosity, intrinsic rewards) tailored to sparse, costly, long-horizon environments.
- Training stability safeguards: negative-sample exclusion is described, but no principled criteria or sensitivity analysis; unclear how this affects convergence and generalization.
- Compute, cost, and efficiency: missing reporting of training steps, wall-clock time, GPU types/counts, rollout throughput, API costs, and energy use for mid-training, SFT, RL, and Heavy Mode.
- Environment sim-to-real gap: no quantitative assessment of transfer from the simulated Wikipedia/RAG environment to the live web (failure modes, degradation, robustness), nor domain coverage limits of the simulation.
- Toolchain robustness and safety: sandbox addresses latency and failures, but not prompt injection, adversarial content, tracking/ads, malicious scripts, data exfiltration, or safety policies for interacting with untrusted pages.
- Coverage of dynamic/complex web: tool set (Search, Visit, Python, Scholar, File Parser) omits interactions requiring authentication, forms, paginated tables, JavaScript-heavy sites, and complex data extraction (e.g., dynamic charts), limiting real-world applicability.
- Citation and provenance: no measurement of citation accuracy, source diversity, or support for verifiable claims in outputs; unclear how S_t preserves provenance and how final reports ensure trustworthy references.
- Uncertainty calibration: the agent’s ability to estimate confidence, hedge, or flag uncertainty is not evaluated; no calibration metrics reported (e.g., Brier scores, reliability diagrams).
- Multilingual and domain coverage: evaluation is mostly English and Chinese; no results for other major languages or specialized domains (e.g., legal, clinical), and no domain-adaptive tooling (e.g., PubMed, arXiv beyond Scholar).
- Multi-modal research: beyond a File Parser, the system lacks explicit support for images/figures, scanned PDFs/OCR, tables, plots, and code repositories, which are central in real research workflows.
- Heavy Mode details and trade-offs: omission of aggregator model specification, selection/diversity strategy for parallel agents, compute/latency scaling with n, diminishing returns analysis, and robustness to correlated errors or synthesis bias.
- Fairness of comparisons: Heavy Mode (test-time scaling) is compared to single-pass baselines without normalizing for compute or latency; no cost-adjusted performance curves.
- Model merging methodology: no criteria for variant selection, merge weight determination, or analysis of interference/catastrophic forgetting; reproducibility of the final merged model is unclear.
- Safety, ethics, and governance: no discussion of misinformation risks, unsafe recommendations, privacy, or misuse in autonomous web research; absence of red-teaming or safety evals tailored to research agents.
- Human-in-the-loop: the system is fully automated; missing protocols for human oversight, interactive clarification, or post-hoc review that are typical in professional research settings.
- User interaction and multi-session memory: no exploration of iterative user-agent dialogues, longitudinal memory across sessions, or personalized preference modeling.
- Tool-use policy learning: unclear how the agent learns tool selection strategies (e.g., when to use Scholar vs generic Search) and whether learned policies generalize across unseen tools/APIs.
- Non-stationarity handling: sandbox stabilizes APIs but may mask distribution shift; no strategy to adapt policies to evolving web content, API changes, or seasonality.
- Benchmark sensitivity: evaluations note instability but lack statistical significance testing, confidence intervals, or variance decomposition; hard to assess whether reported gains are robust.
- Pass@k metrics and real-world utility: improved Pass@3 is reported, but there is no mapping from multiple attempts to acceptable user-facing latency/cost, nor analysis of answer diversity vs correctness.
- Limit of 128 tool calls and 128K context: no study of tasks that exceed these limits, nor adaptive strategies for ultra-long research (e.g., hierarchical decomposition, external memory stores).
- ReAct vs richer frameworks: the “Bitter Lesson” argument favors simplicity, but it remains an open question whether debate, verification, or planner-executor architectures could yield superior safety or reliability at similar compute.
- Open-source completeness: unclear whether all training datasets, environment snapshots, prompts, and synthesis pipelines are released with licenses permitting reproducibility; no guarantees of deterministic replay for RL rollouts.
- Leakage from teacher models: the synthesis process leverages high-performing open-source models; the degree to which student gains reflect distillation vs novel capability is unexamined.
- Evaluation timeframe and staleness: reported scores are tied to specific dates; no continuous or rolling evaluation to measure robustness to benchmark updates or web drift.
Practical Applications
Practical Applications Derived from the Tongyi DeepResearch Paper
Below are actionable, real-world applications grounded in the paper’s findings, methods, and innovations. They are grouped as Immediate Applications (deployable now with available tooling and open-sourced framework) and Long-Term Applications (requiring further research, scaling, or integration).
Immediate Applications
- Research copilot for enterprises
- Sectors: software, finance, healthcare, energy, legal/compliance, manufacturing
- What: Deploy DeepResearch as an internal “research desk” to plan, search, synthesize, and produce auditable long-form reports with citations across intranet and web sources (e.g., competitive analysis, vendor due diligence, regulatory watch, standards tracking).
- Tools/workflows: Search, Visit, Scholar, File Parser, Python; context management for long-horizon tasks; unified sandbox with caching, retries, and rate limiting; “Heavy Mode” as a premium reliability tier (parallel agents + synthesis).
- Assumptions/dependencies: Secure network segmentation; API keys for search/scholar; content licensing; data privacy/PII redaction; governance for external browsing; compute budget for 128K context and parallel runs.
- Literature review and evidence synthesis assistant
- Sectors: healthcare (clinical guidelines, HTA), pharma/biotech (target/indication landscaping), academia (systematic reviews, related-work surveys)
- What: Semi-automated scoping reviews, paper triage, retrieval and synthesis with source tracking; periodic updates to living reviews.
- Tools/workflows: Scholar + File Parser to pull and parse PDFs; context management to maintain evolving structured summaries (S_t); Python for citation graph stats and simple meta-analysis.
- Assumptions/dependencies: Access to paywalled literature (licenses); rigorous citation grounding; human-in-the-loop for inclusion/exclusion criteria; institutional review policies.
- Newsroom and fact-checking research desk
- Sectors: media, policy analysis, risk intelligence
- What: Rapid verifiable backgrounders, source cross-checking, timeline reconstructions, quote and data verification.
- Tools/workflows: Search/Visit, File Parser for documents and datasets; synthesis reports with explicit claims-evidence mapping; Heavy Mode for high-stakes pieces.
- Assumptions/dependencies: Reliable source whitelists/blacklists; policy for unverifiable claims; audit logs retained.
- Policy and regulatory horizon scanning
- Sectors: public sector, energy, finance, healthcare, privacy/compliance
- What: Track bills, rulemakings, agency guidance, standards updates; summarize impacts and required actions for internal stakeholders.
- Tools/workflows: Search/Visit; File Parser for PDFs, filings; context-managed periodic synthesis into memos with action items; model merging to blend domain-specialized variants (e.g., financial vs. privacy).
- Assumptions/dependencies: Access to government registries; change-detection triggers; clear policy on use of unofficial sources.
- Internal knowledge base research and design documentation assistant
- Sectors: software/IT, enterprise ops
- What: Retrieve, reconcile, and synthesize ADRs, RFCs, design docs, incident reports into cohesive proposals or postmortems.
- Tools/workflows: Offline simulated environment via local RAG over enterprise corpus (mirrors paper’s simulated Wikipedia environment); context management to avoid context overflow; Python for dependency graphs.
- Assumptions/dependencies: Up-to-date document ingestion and chunking; permissioning; model access to internal RAG indices.
- E-discovery and document review triage
- Sectors: legal, compliance
- What: Identify, cluster, and summarize key documents; generate issue maps, custodial timelines, and cross-references.
- Tools/workflows: File Parser; context-managed rolling summaries; ReAct tool chains to query within large corpora.
- Assumptions/dependencies: Strict data custody; defensibility/audit trails; human review of privileged content.
- Investment and market intelligence assistant
- Sectors: finance, private equity, corporate strategy
- What: Earnings call synthesis, competitor product teardowns, TAM/SAM analysis, M&A rumor verification.
- Tools/workflows: Search/Visit; File Parser for filings and transcripts; Python for basic KPI calculations; Heavy Mode for contradictory signals.
- Assumptions/dependencies: Data licensing; regulatory restrictions on research; guardrails for market-moving content.
- Threat intelligence and OSINT research
- Sectors: security, defense, fraud/AML
- What: Monitor forums, advisories, CVEs; synthesize threat actor profiles; connect indicators of compromise (IOCs) across sources.
- Tools/workflows: Search/Visit; File Parser; context-managed rolling knowledge graph summaries; sandbox with safe browsing policies.
- Assumptions/dependencies: Source vetting; operational security; compliance with platform ToS; human analyst oversight.
- Education: research-based tutoring and assignment scaffolding
- Sectors: education, EdTech
- What: Guide students through multi-step research projects (planning, source gathering, synthesis, citations) with transparent intermediate notes.
- Tools/workflows: ReAct with context management to teach explicit planning; Scholar/File Parser; rubrics aligned with curricula.
- Assumptions/dependencies: Academic integrity policies; disclosure that an assistant was used; content attribution.
- Synthetic dataset generation for agent training and evaluation
- Sectors: AI/ML, software
- What: Use the paper’s automated pipeline to create super-human QA datasets, domain-specific benchmarks, and “answer-verifiable” RL data for internal models.
- Tools/workflows: Prior world + simulated environments; uncertainty-raising operations; set-theoretic formalization for structure and verification; automatic data curation loop.
- Assumptions/dependencies: Validation harnesses; compute for large-scale synthesis; domain expert spot-checks.
- Safe, stable tool invocation layer for agent products
- Sectors: software, platform providers
- What: Adopt the unified sandbox (rate limiting, retries, caching, failover) to harden tool use in production agents.
- Tools/workflows: Central orchestration layer; deterministic formatting; monitoring of latency/failure modes.
- Assumptions/dependencies: Integration with vendor APIs; cost control; observability stack.
- Cost-controlled long-context reasoning via context management
- Sectors: cross-sector
- What: Replace naive “full history” prompts with Markovian state reconstructions (S_t) to keep long tasks focused and affordable.
- Tools/workflows: Workspace reconstruction policy; periodic synthesis checkpoints; report-oriented memory updates.
- Assumptions/dependencies: Prompt engineering alignment; user experience for intermediate drafts; QA for lost context risks.
- Domain-specialized model merging for bundled capabilities
- Sectors: platform providers, enterprise AI teams
- What: Train or fine-tune multiple variants (e.g., legal, clinical, finance) and merge parameters to create a single, broadly capable research model.
- Tools/workflows: Weighted parameter interpolation; skill profiling and regression tests per domain.
- Assumptions/dependencies: Common base model lineage; licensing for model weights; systematic evaluation to avoid degradation.
Long-Term Applications
- Autonomous scientific research agents
- Sectors: academia, pharma/biotech, materials science
- What: From open literature to experiment proposals, protocol generation, and iterative hypothesis refinement with minimal supervision.
- Tools/workflows: Extended toolchains (ELN/LIMS integration, data analysis pipelines), stronger verification (lab data), multi-agent Heavy Mode for contradicting evidence.
- Assumptions/dependencies: Safe integration with lab systems; experiment feasibility checks; robust grounding and error detection; IRB/ethics compliance.
- Continuous governance and regulatory intelligence copilots
- Sectors: government, regulated industries (finance, health, energy)
- What: Real-time monitoring, impact modeling, and “regulatory delta” simulation across jurisdictions; automated compliance gap analyses.
- Tools/workflows: Multi-source ingestion, policy graph modeling, simulation of scenarios; Heavy Mode adjudication.
- Assumptions/dependencies: Up-to-date legal corpora; legal interpretability standards; audit-ready justifications.
- Enterprise “research memory” and institutional knowledge synthesis
- Sectors: large enterprises, consultancies
- What: Persistent, evolving research memory that composes and recomposes knowledge across projects, mergers, markets, and teams.
- Tools/workflows: Long-horizon context management with durable S_t artifacts; versioned knowledge objects; model merging for team-specific skills.
- Assumptions/dependencies: Knowledge lifecycle governance; change management; privacy and access controls.
- Verified information marketplaces and agent-to-agent research services
- Sectors: platform/ecosystem, software marketplaces
- What: Exchanges where agents deliver verifiable research artifacts with formal uncertainty modeling and automated verification traces.
- Tools/workflows: Set-theoretic problem formalization; standardized verification APIs; staking/escrow for quality.
- Assumptions/dependencies: Standards and incentives for veracity; interoperability across agent frameworks; liability models.
- Clinical decision support with evidence trails
- Sectors: healthcare delivery, payers
- What: Integrate evidence synthesis with EHRs to surface guidelines, outcomes evidence, and payer coverage policies with transparent citations.
- Tools/workflows: EHR connectors; Scholar/File Parser; Heavy Mode for critical decisions; guardrails for scope-of-practice.
- Assumptions/dependencies: Regulatory approval (e.g., CDS rules); patient privacy; rigorous post-deployment monitoring.
- Automated compliance auditing and controls testing
- Sectors: finance, cybersecurity, privacy
- What: Periodic automated audits (policies, configs, logs) mapped against controls frameworks, with change explanations and remediation plans.
- Tools/workflows: File Parser for policies and evidence; simulated environments for what-if control tests; research reports with control-by-control coverage.
- Assumptions/dependencies: Access to systems-of-record; evidence integrity; auditor acceptance; false-positive management.
- Cross-lingual deep research assistants
- Sectors: global enterprises, international NGOs, academia
- What: Multi-lingual research with consistent reasoning quality across languages (e.g., EN–ZH verified synthesis, as suggested by BrowseComp-ZH results).
- Tools/workflows: Multilingual corpora access; localized tool adapters; cross-lingual claim alignment and verification.
- Assumptions/dependencies: Domain adaptation; cultural context understanding; evaluation datasets per locale.
- Autonomous procurement and supply chain due diligence
- Sectors: manufacturing, retail, energy
- What: Vendor vetting, ESG risk analysis, sanctions screening, and disruption monitoring across fragmented sources.
- Tools/workflows: OSINT ingestion; structured risk scoring; periodic synthesis updates; Heavy Mode for conflicting signals.
- Assumptions/dependencies: Accurate entity resolution; up-to-date sanctions/ESG data; legal constraints on data usage.
- Education at scale: research-centered curricula and assessments
- Sectors: K–12, higher-ed, vocational
- What: Personalized research projects, scaffolded learning paths, and assessment rubrics that emphasize planning, source quality, and synthesis.
- Tools/workflows: Context management to capture process artifacts; automated feedback on planning and evidence use; cohort-level analytics.
- Assumptions/dependencies: Institutional acceptance; anti-plagiarism safeguards; transparency and student data protections.
- Adaptive, domain-specific RL training loops for enterprise agents
- Sectors: platform providers, enterprise AI
- What: Continual agent improvement via on-policy RL with automated data curation in simulated and real environments built from enterprise corpora.
- Tools/workflows: rLLM-style asynchronous rollout servers; offline simulated environments mirroring enterprise data; verifiable reward design.
- Assumptions/dependencies: Stable tool layer; well-posed reward signals; safe exploration; MLOps maturity and cost management.
- High-assurance research deliverables for safety-critical domains
- Sectors: aviation, nuclear, medical devices
- What: Research outputs with formalized uncertainty, structured evidence chains, and mandatory multi-agent adjudication.
- Tools/workflows: Heavy Mode ensembles with decision provenance; standardized assurance cases; red-team/blue-team agent protocols.
- Assumptions/dependencies: Regulatory frameworks for AI-generated analyses; certification processes; rigorous incident response.
- Consumer-grade deep research assistants
- Sectors: consumer apps
- What: Evidence-backed assistance for major purchases, travel planning, education choices, and personal finance with side-by-side source links.
- Tools/workflows: Browser extension or mobile app using Search/Visit; report-style outputs with pros/cons and evidence; optional Heavy Mode on-demand.
- Assumptions/dependencies: UX for citations and uncertainty; content licensing; affordability of long-context compute.
Notes on feasibility across all applications:
- Model and framework availability: The paper states the model, framework, and solutions are open-sourced; confirm license terms for commercial use.
- Reliability and verifiability: Heavy Mode improves reliability but increases cost; human-in-the-loop recommended for high-stakes settings.
- Data governance: Ensure compliance with data privacy, IP, and sector-specific regulations; maintain audit logs of tool calls and decisions.
- Infrastructure: Productionizing requires a stable tool sandbox, monitoring, cost controls, and fallback strategies; simulated environments help with safe iteration before going “real-world.”
- Generalization and domain adaptation: While benchmarks are strong, domain-specific evaluation and fine-tuning (plus model merging) may be needed to meet accuracy and policy requirements.
Glossary
- Advantage: In reinforcement learning, a value estimating how much better an action is compared to a baseline for a given state and time. "is an estimator of the advantage at token :"
- Agentic Continual Pre-training (Agentic CPT): A mid-training approach that continues pre-training with agent-specific data to instill agent-like behaviors. "Tongyi DeepResearch employs a two-stage Agentic Continual Pre-training (Agentic CPT)~\citep{agentfounder2025} as its core mid-training phase."
- Agentic mid-training: A training stage introducing and strengthening agent-like behaviors before post-training. "Agentic mid-training cultivates inherent agentic biases by exposing the model to large-scale, high-quality agentic data"
- Agentic post-training: A training stage enhancing agent capabilities after mid-training, often via reinforcement learning. "Agentic post-training further unlocks the modelâs potential via scalable multi-turn reinforcement learning on a strong base model."
- Agentic reinforcement learning: RL adapted for autonomous agents performing multi-step reasoning and tool use in environments. "The post-training pipeline comprises three stages: data synthesis, supervised fine-tuning for cold start, and agentic reinforcement learning."
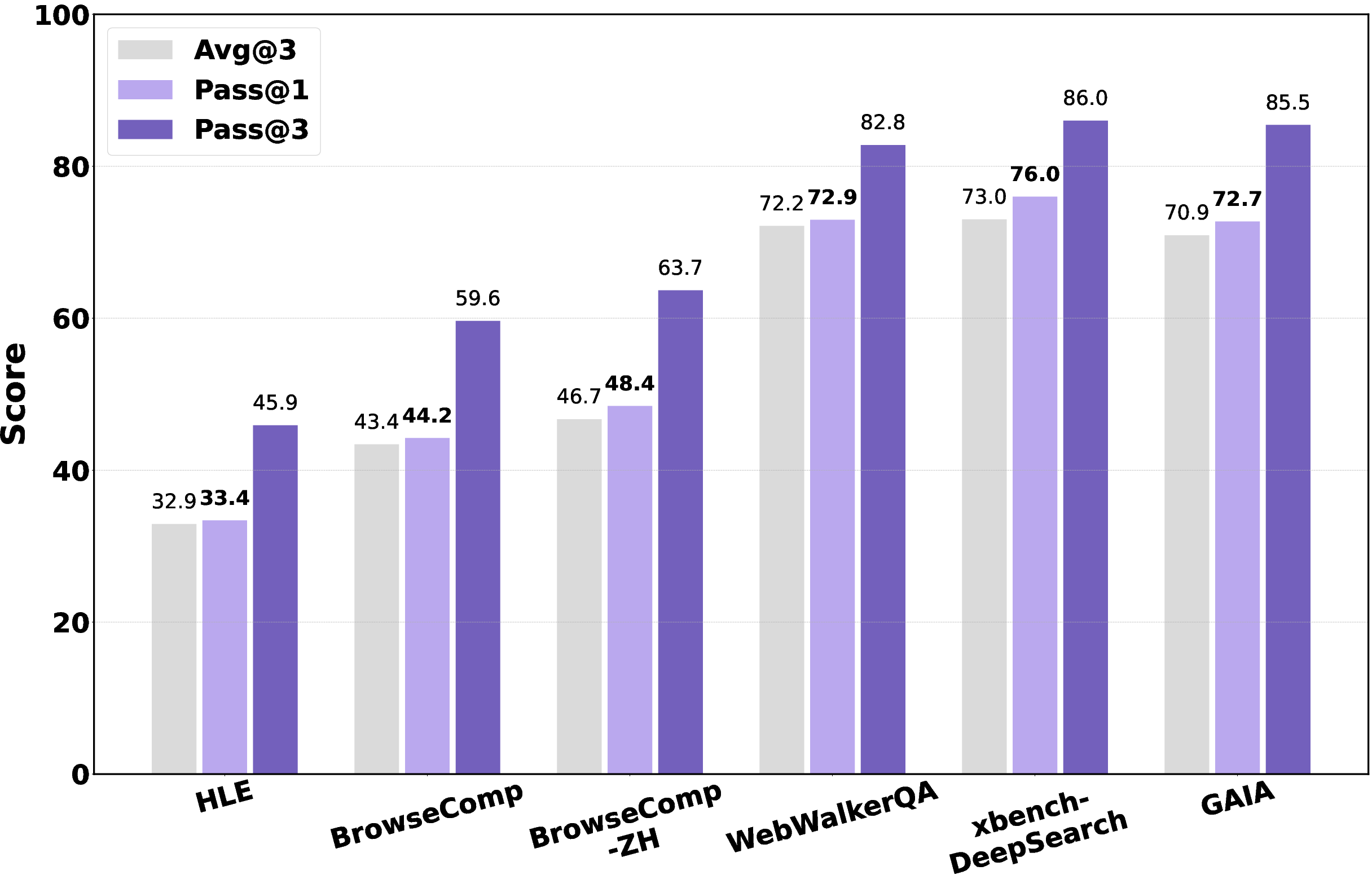
- Avg@3: An evaluation metric averaging a model’s performance over three independent runs. "we report the average performance (Avg@3) as the main metric."
- Behavior cloning: Supervised learning that imitates demonstrated behavior without exploration. "However, behavior cloning alone tends to produce mimicry without exploration."
- Bitter Lesson: The insight that scalable general methods and compute tend to outperform hand-engineered approaches. "This decision is informed by \"The Bitter Lesson\"~\citep{sutton2019bitter}"
- Clip-higher strategy: A PPO-style modification that clips policy updates to encourage exploration while maintaining stability. "we apply the token-level policy gradient loss in the training objective and clip-higher strategy to encourage more exploration."
- Cold start: Initial phase of training to establish a stable policy before RL, typically via supervised fine-tuning. "reinforcement learning with supervised fine-tuning (SFT) for cold start."
- Context management paradigm: A method that reconstructs a compact state each step to avoid context overflow and enforce structured reasoning. "we propose the context management paradigm \citep{qiao2025webresearcher}, which employs a dynamic context management mechanism based on Markovian state reconstruction."
- Context window: The maximum token length a model can attend to during inference or training. "The execution of long-horizon tasks is fundamentally constrained by the finite length of the agent's context window."
- DAPO: An RL optimization technique employing token-level policy gradient and clipping strategies. "Following DAPO~\citep{yu2025dapo}, we apply the token-level policy gradient loss in the training objective and clip-higher strategy to encourage more exploration."
- Decision-Making Action: An explicit modeling of choices among potential reasoning and action paths at each agent step. "Decision-Making Action. Each step of an agent's thinking and action is essentially an implicit decision-making process."
- Distributional fidelity: The degree to which an environment’s data distribution matches real-world conditions. "Its advantage lies in absolute distributional fidelity; the cost is expensive interactions, significant non-stationarity, and exploration risks."
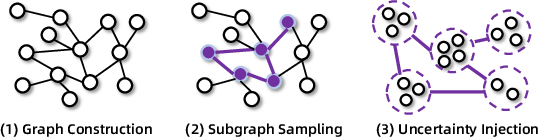
- Environment scaling: Expanding and diversifying simulated environments to broaden function-calling scenarios. "we systematically scale the function-calling data through environment scaling."
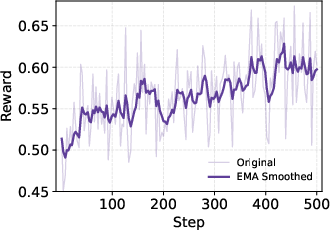
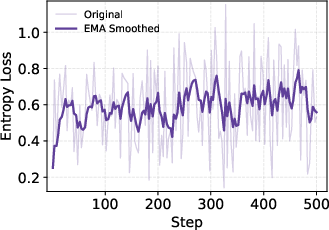
- Entropy: A measure of policy unpredictability; stable entropy indicates balanced exploration-exploitation. "Concurrently, the policy entropy exhibits exceptional stability"
- Function-calling: Direct invocation of tools or APIs by an agent as part of its action space. "we systematically scale the function-calling data through environment scaling."
- GRPO: A reinforcement learning algorithm variant adapted for sequence models and group-relative baselines. "Our RL algorithm is a tailored adaptation of GRPO~\citep{shao2024deepseekmath}:"
- Heavy Mode: A test-time scaling approach that runs parallel research agents and synthesizes their compressed reports. "we introduce the Heavy Mode, which leverages test-time scaling through a Research-Synthesis framework"
- Importance sampling ratio: The ratio between current and old policy probabilities used to weight gradient updates. " is the importance sampling ratio (remains 1.0 for strictly on-policy training)"
- Inductive bias: Built-in assumptions guiding a model’s learning; here, biases toward agent-like behavior. "General foundation models usually lack agentic inductive bias."
- Isomorphic tables: Structurally similar tables extracted from real websites to build realistic synthetic datasets. "and isomorphic tables from realâworld websites, ensuring a realistic information structure."
- Knowledge graph via random walks: Constructing a graph of entities and relations by random traversal to source interconnected knowledge. "constructing a highly interconnected knowledge graph via random walks"
- Leave-one-out strategy: A variance-reduction technique where each sample’s baseline excludes itself. "we adopt a leave-one-out strategy~\citep{chen2025reinforcement}."
- Markovian state reconstruction: Building a minimal sufficient state at each step so the next decision depends only on current summaries and observations. "based on Markovian state reconstruction."
- Model merging: Combining parameters of related models (e.g., via weighted averaging) to integrate capabilities. "We employ model merging at the last stage of the pipeline."
- Non-stationarity: Changing environment distributions over time that destabilize training. "Non-stationarity. The dynamic nature of environments causes continuous distribution shift in training data"
- On-policy: Training exclusively on data sampled from the current policy to ensure relevance of learning signals. "We employ a strict on-policy regimen, where trajectories are consistently sampled using the most up-to-date policy"
- On-Policy Asynchronous Rollout Framework: A parallel, step-level RL system separating model inference and tool invocation for efficient rollouts. "To overcome this, we implement a custom, step-level asynchronous RL training loop built on the rLLM framework~\citep{rllm2025}."
- Pass@1: The best performance over one sampled attempt per problem across repeated runs. "Pass@1 (best result over 3 runs) and Pass@3"
- Pass@3: Performance considering up to three sampled attempts per problem. "Pass@1 (best result over 3 runs) and Pass@3"
- Policy collapse: A failure mode where the policy degrades, often after unstable training on poor data. "can lead to policy collapse after extended training."
- Prior World Environment: A zero-cost, perfectly stable environment using pre-existing knowledge without live feedback. "Prior World Environment. This environment provides task elements, tools, and state definitions"
- QPS: Queries per second; rate-limiting and concurrency control for reliable tool/API calls. "proactive QPS rate constraints"
- RAG tools: Retrieval-Augmented Generation tools that fetch and integrate external documents locally. "develop a suite of local RAG tools to simulate the web environment."
- Read–write database: An environment abstraction that agents interact with by reading and writing states. "with each environment instantiated as a readâwrite database."
- ReAct: A framework interleaving reasoning (Thought) and acting (Action) to form trajectories. "Tongyi DeepResearch's architecture is fundamentally based on the vanilla ReAct~\citep{yao2023react} framework"
- Rejection sampling: Filtering synthesized or generated outputs by rejecting those that fail quality checks. "which are then subjected to a rigorous rejection sampling protocol."
- Research-level questions: High-difficulty, multi-source, multi-hop problems designed to stress deep reasoning. "Synthesizing research-level questions is easy to scale."
- Research-Synthesis framework: A two-phase approach that parallelizes research and then integrates compressed findings. "leverages test-time scaling through a Research-Synthesis framework"
- Reward plateaus: A stagnation point in RL training where rewards stop improving, triggering data refresh. "when the training reaches a certain step count or the reward plateaus, we refresh the active training set"
- RLVR: Reinforcement Learning from Verifiable Rewards, granting reward based on matching a known correct answer. "receives a reward if its final answer matches the ground truth (RLVR)~\citep{r1}."
- rLLM framework: A system for RL with LLMs supporting asynchronous, step-level training loops. "built on the rLLM framework~\citep{rllm2025}."
- Rollout: A complete sequence of agent interactions and decisions for a task attempt. "the model generates a complete task attempt (a \"rollout\") and receives a reward"
- Sandbox: A controlled, unified interface wrapping external tools with fault-tolerance to stabilize training. "we developed a unified sandbox."
- Sim-to-real gap: The performance difference between simulated and real environments due to imperfect fidelity. "exhibiting a notable sim-to-real gap."
- Simulated Environment: A controlled replica of real-world interactions enabling stable, low-cost experimentation. "Simulated Environment. This environment constructs controlled, reproducible replicas of real-world interactions locally."
- Supervised fine-tuning (SFT): Training on curated demonstrations to establish a reliable agent baseline. "reinforcement learning with supervised fine-tuning (SFT) for cold start."
- Test-time scaling: Using more compute or parallel strategies at inference to improve accuracy without retraining. "leverages test-time scaling through a Research-Synthesis framework"
- Token-level policy gradient loss: An RL objective applying policy gradients at the token level for sequence models. "we apply the token-level policy gradient loss in the training objective"
- Tool invocation: The act of calling external tools/APIs as part of the agent’s actions. "This design abstracts the tool invocation into a deterministic and stable interface"
- Trajectory: The sequence of thoughts, actions, and observations produced step-by-step by an agent. "This process forms a trajectory, , which is a sequence of thought-action-observation triplets:"
- Uncertainty: Controlled ambiguity introduced to increase task difficulty in synthetic QA. "strategically increasing the uncertainty within the question to enhance its difficulty"
- Weighted average: Parameter interpolation combining multiple model variants to merge capabilities. "we create the final merged model by computing a weighted average of their parameters:"
Collections
Sign up for free to add this paper to one or more collections.

