Agentic Reasoning for Large Language Models
Abstract: Reasoning is a fundamental cognitive process underlying inference, problem-solving, and decision-making. While LLMs demonstrate strong reasoning capabilities in closed-world settings, they struggle in open-ended and dynamic environments. Agentic reasoning marks a paradigm shift by reframing LLMs as autonomous agents that plan, act, and learn through continual interaction. In this survey, we organize agentic reasoning along three complementary dimensions. First, we characterize environmental dynamics through three layers: foundational agentic reasoning, which establishes core single-agent capabilities including planning, tool use, and search in stable environments; self-evolving agentic reasoning, which studies how agents refine these capabilities through feedback, memory, and adaptation; and collective multi-agent reasoning, which extends intelligence to collaborative settings involving coordination, knowledge sharing, and shared goals. Across these layers, we distinguish in-context reasoning, which scales test-time interaction through structured orchestration, from post-training reasoning, which optimizes behaviors via reinforcement learning and supervised fine-tuning. We further review representative agentic reasoning frameworks across real-world applications and benchmarks, including science, robotics, healthcare, autonomous research, and mathematics. This survey synthesizes agentic reasoning methods into a unified roadmap bridging thought and action, and outlines open challenges and future directions, including personalization, long-horizon interaction, world modeling, scalable multi-agent training, and governance for real-world deployment.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Agentic Reasoning for LLMs” in simple terms
1) What’s this paper about?
This paper is a big “map” of a new idea in AI called agentic reasoning. Instead of treating a LLM like a fancy text autocomplete, it treats the model like an agent—a doer—that can plan, take actions (like using tools or browsing), learn from mistakes, and even team up with other agents. The paper doesn’t present one new model; it reviews and organizes many recent methods into a clear roadmap so others can build smarter, more reliable AI agents.
2) What questions are they trying to answer?
To make this easier to follow, here are the main questions the paper asks and organizes:
- How can an AI plan its steps, search for information, and use tools to get things done—not just talk about it?
- How can an AI improve over time by using feedback and memory, instead of starting from scratch each time?
- How can multiple AIs work together—like teammates with roles—and communicate effectively?
- What’s the difference between improving an AI “on the fly” during use versus training it ahead of time?
- How are these ideas being used in real areas like science, robots, healthcare, math/code, and the web—and how do we test them fairly?
3) How did they study it?
This is a survey paper. That means the authors read a lot of recent research (up to 2025), compared approaches, and organized them into a simple framework. Think of them as librarians arranging a messy bookshelf into neat sections so you can quickly find what you need.
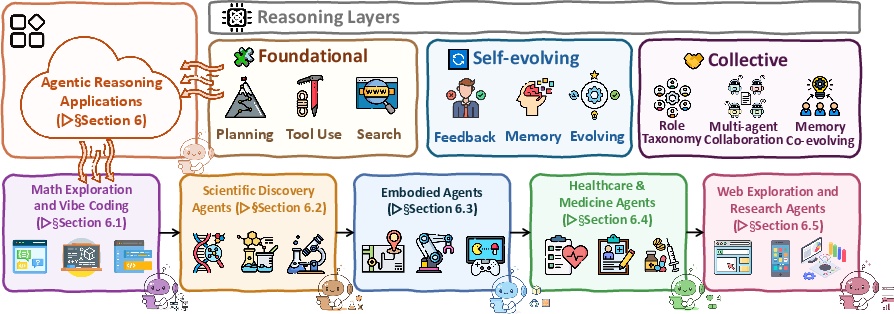
They organize agentic reasoning into three layers:
- Foundational (single agent): the basics—planning, using tools (like calculators or APIs), and search (like web browsing or code execution).
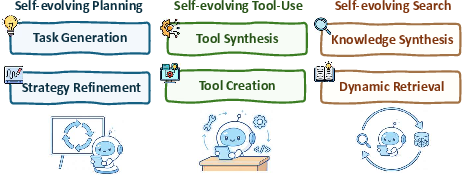
- Self-evolving (learning over time): improving with feedback, keeping useful memories, and adapting to new situations.
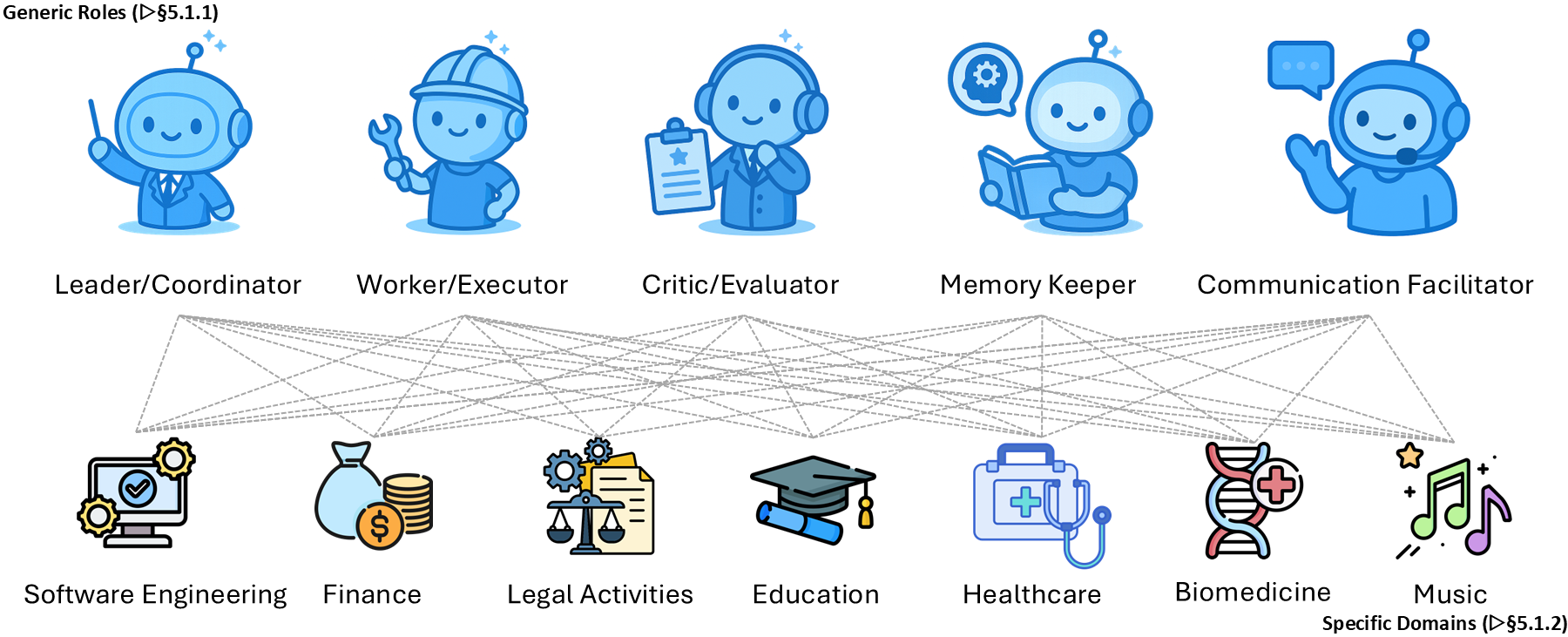
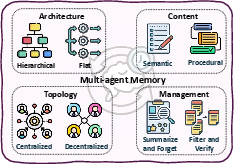
- Collective (multi-agent): multiple agents with roles (like a manager, worker, and critic) that talk and cooperate.
They also explain two ways to make agents smarter:
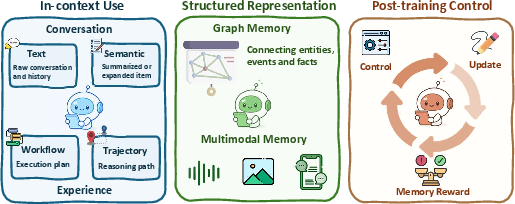
- In-context reasoning (during use): The model stays the same, but you guide it with smart steps, workflows, and prompts—like taking good notes during a test.
- Post-training reasoning (before use): You actually train or fine-tune the model using methods like reinforcement learning—like practicing a lot before the test so the skill is built-in.
They review how these ideas show up in real applications and how researchers measure progress with benchmarks (special tests and environments).
Technical terms in everyday language:
- Planning: making a step-by-step plan instead of jumping to the final answer.
- Tool use: calling a calculator, search engine, database, or code executor when needed.
- Search: exploring different options or information sources to find the best path.
- Feedback and memory: learning from mistakes and remembering helpful lessons for next time.
- Multi-agent collaboration: agents talking, splitting tasks, and checking each other’s work—like a study group.
4) What did they find, and why is it important?
The main results are not a single experiment, but a structured way to understand and build agentic systems. Here are the key takeaways:
- A clear three-layer roadmap:
- Foundational: Good agents break big tasks into smaller ones, use the right tools, and verify results. For example, an agent solving a math problem might plan steps, call a calculator, and check the final answer.
- Self-evolving: Agents work better when they reflect (“What went wrong?”), store memories (“What worked before?”), and adapt their strategies over time—without needing a full retraining every time.
- Collective: Teams of agents can be stronger than one—debating, dividing roles, and sharing knowledge—but they need structure to avoid confusion, wasted effort, or inconsistent answers.
- Two complementary ways to improve agents:
- In-context reasoning: Build smarter workflows (like plan–act–check loops, tree-of-thought exploration, or step-by-step verification) that help even a frozen model perform better at use time.
- Post-training reasoning: Use reinforcement learning or fine-tuning so successful strategies become part of the model itself, making it faster and more reliable.
- Real-world coverage:
- Applications: science (planning experiments), robotics (long tasks in changing environments), healthcare (tool use with safety checks), web automation (browsing and forms), and math/code (stepwise solutions with execution and tests).
- Benchmarks: new tests that check not just if an answer is right, but whether the agent can plan, adapt, use tools safely, and work with others.
Why this matters:
- The paper connects “thinking” (reasoning) to “doing” (actions). That shift helps AI systems handle messy, open-ended tasks—more like real life.
- It gives researchers and builders a shared language and set of design patterns, so progress can be faster and more consistent.
- It highlights where current systems still stumble, pointing the way to better, safer agents.
5) What’s the impact? Where does this go next?
The authors end with a simple but important message: smarter AI agents are not just about bigger models—they’re about better thinking-and-doing loops. If we follow this roadmap, we could get:
- More helpful assistants that plan, check, and learn from their own experience
- Robots and software that handle long, complex tasks without getting lost
- Scientific and medical tools that use external knowledge and verify steps
- Safer and more trustworthy systems that can explain their decisions
They also point out open challenges that need care:
- Personalization: making agents that remember and adapt to each user safely
- Long-horizon reliability: staying correct over many steps without drifting off course
- World modeling: understanding how the world changes after actions
- Scalable teamwork: training multiple agents to cooperate efficiently
- Governance: building guardrails and evaluation standards for real-world deployment
In short, this paper gives a clear, teen-friendly way to think about the next generation of AI: not just chatters, but capable doers that plan, act, learn, and collaborate.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored based on the paper’s framing of agentic reasoning.
- Identifiability and measurement of internal reasoning (): How to operationalize, learn, and evaluate the latent “thought” variable in the proposed POMDP factorization (e.g., metrics for reasoning quality, faithfulness, and usefulness; datasets and probes that don’t rely on final-answer supervision).
- Cost-aware orchestration policies: Formal methods for deciding when to use in-context search vs. post-training optimization, how much inference-time compute to spend, and how to schedule dynamic budgets under task time/energy constraints.
- Representation selection for planning: Criteria and automatic methods to choose among natural language, code, PDDL, and hybrid plans; round-trip conversion and consistency checking across representations; benchmarks that stress these choices.
- Heuristic/verifier learning for ToT/MCTS: Robust, calibrated evaluators for partial thoughts; theoretical regret or sample-complexity guarantees under partial observability; defenses against verifier overfitting and exploitation.
- Scalable backtracking and verification: Practical, general-purpose verification that scales beyond small tasks (e.g., proof/checker integration, runtime monitors) with bounded compute and latency.
- Tool schema induction and maintenance: Automatic discovery of tool affordances, argument schemas, and preconditions/effects; continual adaptation to API drift, versioning, rate limits, and failures without brittle handcrafting.
- Tool selection at scale: Efficient policies for choosing from thousands of tools (retrieval vs. learned policies), zero-shot grounding to unseen tools, and graceful degradation under missing or unreliable tools.
- Fault tolerance in tool pipelines: Principled strategies for retry, fallback, partial-results use, and replanning under tool errors, latency spikes, and non-determinism; end-to-end robustness metrics.
- Memory objective design: Learnable objectives for write/retrieve/forget decisions that prevent memory pollution, hallucinated entries, and redundancy; scalable compaction and indexing under lifelong operation.
- RL for memory and reflection: Credit assignment for write/retrieve/reflect actions, sample-efficient training in sparse/long-horizon settings, and safeguards against self-reinforcing biases in self-critique.
- Continual post-training without drift: Stable RL/SFT procedures that internalize agent skills while preserving base capabilities and safety; diagnostics for alignment drift and catastrophic forgetting in agents.
- Multi-agent mechanism design: Incentive structures and communication protocols that prevent collusion, deception, or information cascades; convergence and stability theory for decentralized reasoning processes.
- Multi-agent credit assignment and evaluation: Counterfactual and causal tools to attribute success/failure to specific agents/messages; scalable reward shaping and CTDE methods tailored to LLM agents.
- Governance of shared memories/knowledge: Version control, provenance, access control, and conflict resolution for shared artifacts; defenses against malicious or low-quality updates in collaborative settings.
- Standardized long-horizon benchmarks: Domain-diverse, partially observable, tool-rich environments with unified metrics for success, robustness, safety, compute cost, and human effort; reproducible, open evaluation protocols.
- Sim2real transfer: Methods to reduce reality gaps for web/GUI/robotics agents (prompt injection defenses, DOM/layout shifts, sensor noise), with robust generalization tests and incident reporting.
- World modeling integration: Learning, updating, and calibrating explicit world models; uncertainty-aware planning; deciding when to trust the model vs. act to gather information; compounding model-error analysis.
- Personalization at scale: Privacy-preserving preference learning (e.g., federated/on-device PEFT), consent and data governance, representation of evolving user goals, and standardized evaluation of personalized agentic behavior.
- Long-horizon temporal abstraction: Automatic discovery of reusable skills/options, hierarchical credit assignment across think–act loops, and sample-efficient exploration under delayed/sparse rewards.
- Safety and governance for real deployment: Permissioned tool-use sandboxes, audit trails, runtime monitors and kill-switches, incident taxonomies, and compliance-by-design with legal/ethical constraints.
- Reasoning provenance and privacy: Verifying the truthfulness and utility of chain-of-thought without exposing sensitive content; alternatives to CoT that retain verifiability (e.g., latent CoT, proof objects).
- Hybrid co-design of search and training: Automated curricula for internalizing frequently used tool chains/workflows into weights while retaining flexible in-context search for tail cases; when-to-amortize policies.
- Energy and cost efficiency: Compute/carbon accounting for agentic search and multi-agent orchestration; adaptive compute policies and anytime agents with explicit performance–cost tradeoffs.
- Multimodal grounding reliability: Alignment between language plans and perception/action modules; error propagation analysis across perception→reasoning→control; standardized robustness tests.
- Data quality and feedback loops: Preventing collapse from synthetic self-play/reflections, ensuring diversity and difficulty calibration in training data, and establishing curation/auditing protocols.
- Reproducibility and ablations: Rigorous controls isolating the impact of planning, memory, and tool-use components; standardized seeds, logs, and artifact releases to enable fair comparisons.
- Formal guarantees for agentic systems: Safety, liveness, and performance guarantees for sequential think–act loops and multi-agent interactions; runtime verification and certified recovery under failures.
Glossary
- A*: A graph search algorithm that uses heuristics to efficiently find least-cost paths; here, it scaffolds LLM planning by guiding expansions toward promising states. "A*-like guided expansions appear in \cite{wang2024qstar,meng2024llmastar,liu2024multimodal}, providing heuristic-driven planning with state evaluation."
- Agentic reasoning: A paradigm that treats LLMs as autonomous agents that plan, act, and learn through interaction, unifying reasoning with actions and feedback. "The emergence of agentic reasoning marks a paradigm shift, bridging thought and action by reframing LLMs as autonomous agents that plan, act, and learn through continual interaction."
- Beam search: A heuristic search/decoding method that keeps a fixed number of best candidates at each step to explore multiple reasoning paths. "Beam search is leveraged in \cite{xie2023self,golovneva2023pathfinder,qian2025discriminator} to prune and prioritize reasoning trajectories efficiently."
- Centralized-Training/Decentralized-Execution (CTDE): A multi-agent RL paradigm where agents are trained with centralized information but act independently at test time. "often utilizing Centralized-Training/Decentralized-Execution (CTDE) paradigms to stabilize the emergence of cooperative behaviors."
- Chain-of-Thought (CoT): A prompting technique that elicits step-by-step intermediate reasoning from LLMs. "techniques that explicitize intermediate reasoning, such as Chain-of-Thought prompting, decomposition, and program-aided solving, have significantly bolstered inference performance"
- Closed-world settings: Static, fully specified problem environments (e.g., math/code benchmarks) where all necessary information is available. "While LLMs demonstrate strong reasoning capabilities in closed-world settings, exemplified by standard benchmarks in mathematics and code, they struggle in open-ended and dynamic environments."
- Dec-POMDP (Decentralized Partially Observable Markov Decision Process): A formal model for multi-agent decision-making under partial observability with decentralized policies. "We extend the single-agent formulation to a decentralized partially observable multi-agent setting, commonly formalized as a Dec-POMDP."
- Diffusion models: Generative models that iteratively denoise samples; in planning, used for trajectory optimization in control/agent settings. "trajectory optimization via diffusion models is seen in \cite{xie2025latent,xiao2023safediffuser,shan2025contradiff}."
- Discount factor: The scalar γ∈(0,1) that down-weights future rewards in RL to ensure convergence and encode time preference. "and the discount factor."
- Group Relative Policy Optimization (GRPO): A policy-gradient method that estimates advantages by normalizing rewards across a group of samples, removing the need for a value network. "Group Relative Policy Optimization (GRPO) \citep{shao2024deepseekmath}-based methods are widely used for reasoning tasks."
- Heuristic value function: An approximate evaluator used during inference-time search to rank partial thoughts/plans without updating model parameters. "to maximize a heuristic value function ."
- Hierarchical RL: Reinforcement learning that organizes policies across multiple levels of abstraction (e.g., high-level goals and low-level skills). "while structured pipelines embed hierarchical RL or MCTS within the tree to choose promising edits and verification paths"
- In-context learning: The ability of LLMs to learn task behavior from examples and instructions provided in the prompt at inference time. "Methods such as prompt engineering, in-context learning, and chain-of-thought prompting have made reasoning more explicit, yet conventional LLMs remain passive sequence predictors"
- In-context Reasoning: Scaling an agent’s capabilities at inference time via structured orchestration, planning, and search without weight updates. "In-context Reasoning: scales inference-time interaction through structured orchestration and planning without parameter updates."
- Long-horizon interaction: Tasks requiring extended sequences of decisions/plans with delayed outcomes and persistent state. "personalization, long-horizon interaction, world modeling, scalable multi-agent training, and governance frameworks for real-world deployment."
- Meta-learning: Learning-to-learn across episodes, where the agent updates evolvable state (e.g., memory, skills) to improve future performance. "Self-Evolving Agents: The Meta-Learning Loop."
- Monte Carlo Tree Search (MCTS): A search algorithm that uses random simulations and tree statistics (e.g., UCT) to plan actions; adapted here for reasoning/search over thoughts. "MCTS is heavily explored in agentic research: \cite{hao2023reasoning,putta2024agent,sprueill2023monte,yu2023prompt,zhao2023large,ding2023everything,chen2024tree,kong2024latent,feng2023alphazero,yoon2025monte,schultz2024mastering,chen2025broaden} use MCTS or its variations for controlled exploration and improved reasoning fidelity."
- Observation kernel: The probabilistic mapping from latent states to observations in a POMDP/agentic model. " and denote the transition and observation kernels, the reward, and the discount factor."
- Partially Observable Markov Decision Process (POMDP): A framework for decision-making when the agent cannot fully observe the environment state. "We model the environment as a Partially Observable Markov Decision Process (POMDP) and introduce an internal reasoning variable to expose the ``think--act'' structure of agentic policies."
- Proximal Policy Optimization (PPO): A policy-gradient RL algorithm that stabilizes training via clipped objective updates. "While PPO \citep{schulman2017proximal} is standard, Group Relative Policy Optimization (GRPO) \citep{shao2024deepseekmath}-based methods are widely used for reasoning tasks."
- Retrieval-Augmented Generation (RAG): Enhancing generation with retrieved external knowledge to ground and improve reasoning/planning. "RAG-style systems \cite{yoo2024exploratory,li2024benchmarking, zou2025gtr} retrieve relevant knowledge to support continual instruction planning."
- Reward shaping: Modifying or supplementing rewards to guide learning and improve sample efficiency/stability. "while others like \cite{luyten2025strategic} emphasize reward shaping."
- Transition kernel: The probabilistic dynamics mapping from current state and action to next state in a Markovian model. " and denote the transition and observation kernels, the reward, and the discount factor."
- Tree-of-Thoughts (ToT): A prompting/planning framework that explores a search tree over intermediate thoughts to improve reasoning. "Tree-of-Thoughts (ToT \citep{yao2023tree}) and related MCTS-style approaches treat partial thoughts as nodes ... and search for an optimal path"
- World model: A learned or explicit model of environment dynamics used for model-based planning and prediction. "World model-based agents such as \cite{hao2023reasoning,guan2023leveraging,qiao2024agent,zhou2024behaviorgpt,zhou2024dino,gao2024flip,liu2025continual,wang2025adawm} learn or leverage environment models for model-based planning."
- Workflow orchestration: Structuring and coordinating the stages of agent behavior (planning, acting, verification) into adaptive pipelines. "emphasizing reasoning-centered workflow orchestration across in-context and post-training dimensions."
Practical Applications
Immediate Applications
Below are actionable, sector-linked use cases that can be deployed now using in-context orchestration, structured workflows, and tool-use frameworks, assuming human oversight and constrained environments.
- Software engineering (sector: software)
- Use case: Agentic code repair and feature implementation with plan–act–test loops.
- Tools/workflows: ReAct-style loops, OpenHands, Gorilla (API/code execution), hierarchical task trees with unit/integration tests, sandboxed runners.
- Potential products: “Agentic IDE,” CI/CD auto-fix bot, code review triad (manager–worker–critic).
- Assumptions/dependencies: Reliable test coverage, secure sandboxes, rollback strategies, audit logs, developer-in-the-loop.
- Customer support and IT operations (sector: software/enterprise)
- Use case: Ticket triage, knowledge-base lookup, guided resolution steps with tool calls (CRM/ITSM).
- Tools/workflows: Chain-of-Thought + tool calls, RAG over help articles, task decomposition (ReWOO), verification prompts.
- Potential products: “Support Copilot” for Zendesk/ServiceNow, auto-triage workflows.
- Assumptions/dependencies: High-quality KBs, API access to ticketing systems, human approval gates, escalation policies.
- Autonomous web RPA for business processes (sector: enterprise/operations)
- Use case: Form filling, procurement requests, scraping, reporting across internal portals and permissible websites.
- Tools/workflows: DOM grounding (Agent-E), WebArena/Mind2Web task patterns, inspect–reason–act–observe loops, screenshot grounding.
- Potential products: “Agentic RPA Builder,” compliance-aware web automations.
- Assumptions/dependencies: Stable UIs, site TOS compliance, authentication flows, monitoring and auditability.
- Data analysis co-pilots (sector: software/data)
- Use case: Plan–run–verify analytics in notebooks; pipeline synthesis and debugging.
- Tools/workflows: Tool use for SQL/agents over data warehouses, program-aided reasoning (PAL), reflective error handling.
- Potential products: “Agent Notebook Copilot,” auto-EDA and dashboard generation.
- Assumptions/dependencies: Schema/RBAC awareness, deterministic query engines, result verification and provenance logging.
- Scientific literature triage and hypothesis mapping (sector: academia/science)
- Use case: Multi-agent summarization, debate, and knowledge graph construction for a topical corpus.
- Tools/workflows: Multi-agent role assignments (manager–worker–critic), RAG, graph-of-thoughts planning, AutoGen/CAMEL-style communication.
- Potential products: “AutoReview” assistants for labs; domain KG builders.
- Assumptions/dependencies: Access to literature, citation/provenance tracking, domain expert review.
- Healthcare knowledge retrieval and administrative support (sector: healthcare)
- Use case: Guideline retrieval, care-pathway summarization, prior-auth document prep.
- Tools/workflows: Toolformer/ToolLLM for controlled API calling, medical RAG, plan–verify workflows.
- Potential products: “Clinical Copilot” for administrative and informational tasks; not for autonomous diagnosis.
- Assumptions/dependencies: HIPAA compliance, curated medical KBs, strict human-in-the-loop clinical oversight.
- Robotics task planning in controlled environments (sector: robotics/manufacturing)
- Use case: Behavior-tree planning for pick-and-place, inspection, and simple assembly in labs or structured settings.
- Tools/workflows: Hierarchical planning (behavior trees), world-model-guided subgoals, safety monitors and anomaly detectors.
- Potential products: “Robot Task Planner” integrated with existing controllers.
- Assumptions/dependencies: Structured environments, reliable perception stacks, safety interlocks and shutdown policies.
- Education and training assistants (sector: education)
- Use case: Personalized tutoring with memory-driven adaptation, curriculum decomposition and assessment item generation.
- Tools/workflows: Reflection (Reflexion), memory stores (Mem0/Memos), role-based multi-agent review for content quality.
- Potential products: LMS-integrated “Agent Tutor” and item-writing assistants.
- Assumptions/dependencies: Privacy controls, aligned content standards, educator oversight and fairness audits.
- Compliance document analysis and policy mapping (sector: finance/legal/enterprise)
- Use case: Mapping obligations across internal policies; gap analysis and evidence retrieval.
- Tools/workflows: Plan–search–verify workflows, knowledge graph linking, multi-agent cross-checking.
- Potential products: “Policy Navigator” and compliance traceability dashboards.
- Assumptions/dependencies: Access to updated policies/regulations, provenance and audit trails, legal review gates.
- Enterprise knowledge maintenance (sector: enterprise/software)
- Use case: Continuous KB updates, doc refactoring, release notes generation via writer–editor–critic agents.
- Tools/workflows: Multi-agent coordination (AutoGen), memory-driven retrieval, tool chains for doc builds.
- Potential products: “Agent Knowledge Ops” platforms.
- Assumptions/dependencies: Version control governance, style guidelines, review workflows.
- Personal productivity assistants (sector: daily life/consumer)
- Use case: Email triage, scheduling, travel planning, shopping returns with plan–act–verify loops.
- Tools/workflows: Tool registries for calendars, email, booking sites; reflection and verification steps.
- Potential products: “Personal Agent” with explicit approval checkpoints.
- Assumptions/dependencies: Account permissions and OAuth, user-configured guardrails, receipts/provenance of actions.
- Tool registries and orchestration platforms (sector: software/platform)
- Use case: Managing tool libraries, routing, and selection under cost and reliability constraints.
- Tools/workflows: ToolPlanner, HuggingGPT/TaskMatrix-like orchestrators, experience-based selection (ToolExpNet).
- Potential products: “ToolOps” platforms for enterprise agents.
- Assumptions/dependencies: Tool metadata and health signals, authentication, centralized logging.
Long-Term Applications
Below are higher-impact applications that require post-training optimization (RL/fine-tuning), robust world models, scalable multi-agent training, and mature governance frameworks.
- Autonomous research labs (sector: science/academia)
- Use case: Agents design experiments, synthesize code and protocols, iterate via feedback to discover materials/compounds.
- Tools/workflows: Reinforcement learning for tool use (ToolRL/ReTool), procedural evolution (Voyager-like skill libraries), lab robotics integration.
- Potential products: “AutoLab” discovery platforms.
- Assumptions/dependencies: Reliable simulators/world models, physical lab automation, safety and reproducibility standards.
- Clinical decision support with adaptive, longitudinal memory (sector: healthcare)
- Use case: Patient-specific planning, risk stratification, and care-pathway optimization over long horizons.
- Tools/workflows: Memory policy optimization (Memory-RL), verifiable reasoning, multi-modal data integration (EHR, imaging).
- Potential products: “Adaptive CDS” systems with explainability.
- Assumptions/dependencies: Regulatory approval, robust bias controls, interpretability, clinician oversight and outcome monitoring.
- Multi-agent “digital organizations” (sector: enterprise/operations)
- Use case: Manager–worker–critic teams that coordinate projects, budgets, and operations with shared memories.
- Tools/workflows: Dec-POMDP/CTDE training, incentive/mechanism design, structured communication topologies, joint policy optimization.
- Potential products: “Agent Teams” for program/project management.
- Assumptions/dependencies: Scalable multi-agent training, governance and accountability frameworks, cost controls.
- General-purpose household/service robots (sector: robotics)
- Use case: Embodied agents performing multi-step household tasks with language-guided planning and adaptation.
- Tools/workflows: World-model-based planning, hierarchical controllers, multimodal perception grounding.
- Potential products: “Home Service Robot” assistants.
- Assumptions/dependencies: Robust VLMs, safety certification, sample-efficient learning, fault-tolerant control.
- Codebase-scale autonomous refactoring and modernization (sector: software)
- Use case: Large-scale refactors, dependency upgrades, security patching across complex repos.
- Tools/workflows: MCTS/A* over code graphs, test synthesis, rollback and canary deployments.
- Potential products: “Repo Renovator” agents.
- Assumptions/dependencies: Advanced verification, impact analysis, organizational change management.
- Scientific discovery pipelines (materials, chemistry, physics) (sector: science)
- Use case: Hypothesis generation, simulation–experiment loops, active learning over large search spaces.
- Tools/workflows: Multi-agent debate and consensus, model-based planning, domain simulators, autonomous instruments.
- Potential products: “Discovery Orchestrators.”
- Assumptions/dependencies: Accurate domain models, integrated lab hardware, data provenance and publication standards.
- Autonomous web exploration and procurement at scale (sector: enterprise)
- Use case: Complex multi-site procurement, contract negotiation aids, market intelligence.
- Tools/workflows: Adaptive web agents with memory, robust anti-bot handling, plan–act–verify with negotiation modules.
- Potential products: “Strategic Web Agent” suites.
- Assumptions/dependencies: Standardized business APIs, ethical scraping guidelines, compliance and legal risk controls.
- Lifelong personalized memory agents (sector: consumer/enterprise)
- Use case: Building durable user/world models, proactive assistance across years.
- Tools/workflows: Memory writing/retrieval optimization, structural evolution of skills, privacy-preserving storage and access control.
- Potential products: “Personal Knowledge Manager” agents.
- Assumptions/dependencies: Privacy-by-design, drift detection, alignment to user preferences, secure data exchange.
- Agent governance, safety, and audit platforms (sector: policy/enterprise)
- Use case: Monitoring, logging, red-teaming, and compliance audits for agentic systems.
- Tools/workflows: Standardized telemetry (thought/action traces), reward modeling for safe behavior, incident response playbooks.
- Potential products: “AgentOps Governance Stack.”
- Assumptions/dependencies: Regulatory frameworks, standardized logs/specs, third-party certification.
- RL-trained enterprise agents for complex tool ecosystems (sector: software/enterprise)
- Use case: Agents specialized for CRM/ERP workflows via GRPO/PPO with sparse rewards.
- Tools/workflows: GRPO/ARPO/DAPO training, replay buffers, simulators for rare events, reward shaping.
- Potential products: “Enterprise Task Agents.”
- Assumptions/dependencies: High-fidelity simulators, safe reward design, scalable training infrastructure.
- Closed-loop curriculum and assessment generation (sector: education)
- Use case: Curriculum planning with feedback, adaptive testing, multi-agent peer review for quality.
- Tools/workflows: Collective reasoning, memory-driven personalization, evidence-based verification.
- Potential products: “Adaptive Curriculum Studio.”
- Assumptions/dependencies: Validated pedagogy, fairness/measurement standards, educator governance.
- Disaster response and logistics coordination (sector: public sector/policy)
- Use case: Multi-agent planning for resource allocation, routing, and situational updates.
- Tools/workflows: Dec-POMDP coordination, shared situational awareness, simulation-backed planning.
- Potential products: “Agentic Emergency Ops.”
- Assumptions/dependencies: Real-time data integration, chain-of-command alignment, robust simulations and communications.
- Energy grid planning and demand response (sector: energy)
- Use case: Predictive planning of load, distributed resource coordination, anomaly detection and mitigation.
- Tools/workflows: Model-based planning, tool use for telemetry/control APIs, verifier agents.
- Potential products: “Grid Planner Agents.”
- Assumptions/dependencies: Secure control interfaces, real-time telemetry, regulatory approvals, safety guarantees.
- Financial risk and compliance agents (sector: finance)
- Use case: Scenario simulation, stress testing, continuous control mapping to regulations.
- Tools/workflows: Multi-agent debate for consensus, tool chains over risk engines, world-models for market dynamics.
- Potential products: “Risk Simulation Orchestrators.”
- Assumptions/dependencies: Regulatory alignment, adversarial testing, explainability and auditability.
- Cross-modal world-model planning (sector: platform R&D)
- Use case: Agents reasoning over language, vision, code, and action with scalable world models.
- Tools/workflows: Learned world models, algorithmic planning (A*/MCTS), memory-driven adaptation across tasks.
- Potential products: “General Agentic Reasoner” platforms.
- Assumptions/dependencies: Large-scale multimodal datasets, training compute, new benchmarks and evaluation standards.
Collections
Sign up for free to add this paper to one or more collections.