From Code Foundation Models to Agents and Applications: A Practical Guide to Code Intelligence
Abstract: LLMs have fundamentally transformed automated software development by enabling direct translation of natural language descriptions into functional code, driving commercial adoption through tools like Github Copilot (Microsoft), Cursor (Anysphere), Trae (ByteDance), and Claude Code (Anthropic). While the field has evolved dramatically from rule-based systems to Transformer-based architectures, achieving performance improvements from single-digit to over 95\% success rates on benchmarks like HumanEval. In this work, we provide a comprehensive synthesis and practical guide (a series of analytic and probing experiments) about code LLMs, systematically examining the complete model life cycle from data curation to post-training through advanced prompting paradigms, code pre-training, supervised fine-tuning, reinforcement learning, and autonomous coding agents. We analyze the code capability of the general LLMs (GPT-4, Claude, LLaMA) and code-specialized LLMs (StarCoder, Code LLaMA, DeepSeek-Coder, and QwenCoder), critically examining the techniques, design decisions, and trade-offs. Further, we articulate the research-practice gap between academic research (e.g., benchmarks and tasks) and real-world deployment (e.g., software-related code tasks), including code correctness, security, contextual awareness of large codebases, and integration with development workflows, and map promising research directions to practical needs. Last, we conduct a series of experiments to provide a comprehensive analysis of code pre-training, supervised fine-tuning, and reinforcement learning, covering scaling law, framework selection, hyperparameter sensitivity, model architectures, and dataset comparisons.
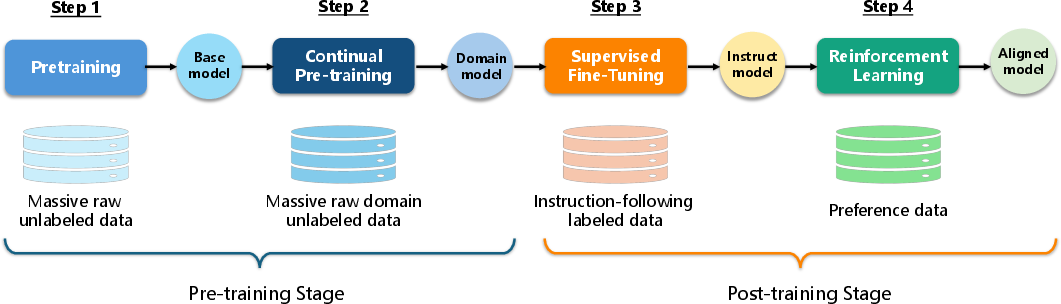
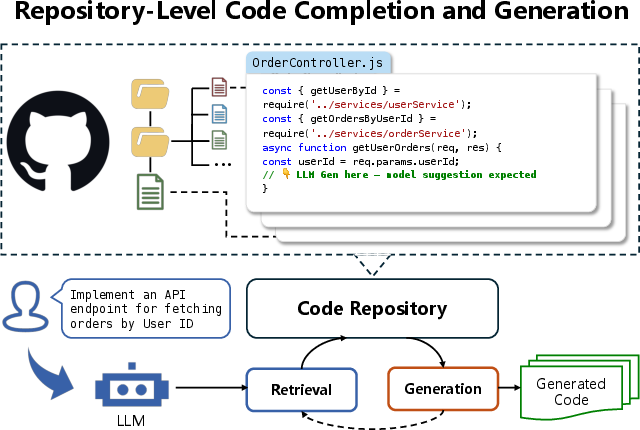
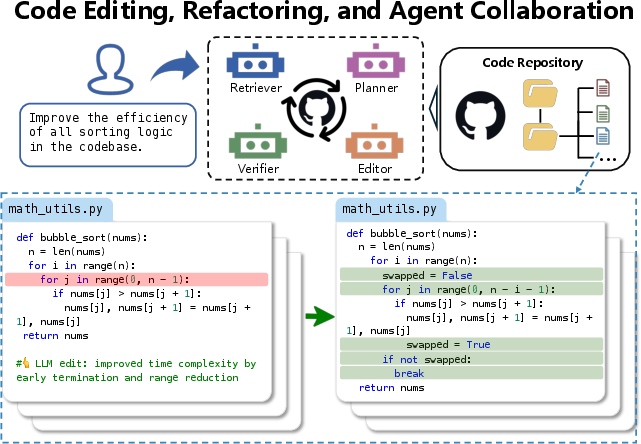
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Practical Applications
Immediate Applications
Below are practical, deployable applications that leverage the paper’s surveyed methods, evaluation insights, and tool ecosystems to improve current software and research workflows.
- Repository-aware AI pair programming within IDEs
- Sector: software; Tools/workflows: GitHub Copilot, Cursor, Claude Code, Gemini CLI, Code LLMs with retrieval-augmented generation (RAG), unit-test execution, static analysis
- Action: augment developer workflows with long-context prompts, retrieval over large repos, test-driven editing, and automatic PR drafting
- Assumptions/dependencies: sufficient test coverage; reliable sandboxed execution; IDE/API integrations; license-compliant retrieval indices; guardrails against tool hallucination
- Automated bug triage and patching for issue backlogs
- Sector: software; Tools/workflows: SWE agents (e.g., mini-SWE-agent), ReAct planning, tool calling, CI runners
- Action: propose patches for failing tests, generate diffs, and validate fixes via CI; prioritize issues based on feasibility and risk
- Assumptions/dependencies: reproducible environments; stable tool invocation; clear acceptance criteria; human-in-the-loop review
- Secure-by-default AI code generation pipelines
- Sector: cybersecurity, software; Tools/workflows: LLM codegen + security linters (Semgrep, Bandit), SAST/DAST, SBOM checks, CWE/CVE-aware prompts
- Action: enforce security scanners and policy gates in AI-assisted PRs; constraint prompting to avoid known vulnerability patterns; add secure templates
- Assumptions/dependencies: curated secure code datasets; org security policies; scanner coverage; policy-compliant tool chains
- Cross-language code translation and modernization
- Sector: software, enterprise IT; Tools/workflows: Code-specific LLMs (StarCoder, Code LLaMA, DeepSeek-Coder, QwenCoder), test harnesses, API diff maps
- Action: migrate legacy code (e.g., Python 2→3, Java→Kotlin) with automated test generation, API compatibility checks, and guided refactoring
- Assumptions/dependencies: accurate API/SDK compatibility metadata; backward-compat test suites; access to proprietary code bases
- AI-assisted data engineering and ETL scripting
- Sector: finance, healthcare, analytics; Tools/workflows: LLMs + SQL generation, schema-aware prompts, validation queries
- Action: generate and verify SQL/ETL pipelines, add unit tests for data quality, scaffold orchestration scripts (Airflow, Prefect)
- Assumptions/dependencies: schema documentation; data governance policies; production-safe execution environments
- Code review copilots for maintainability and performance
- Sector: software; Tools/workflows: LLM-based review with maintainability heuristics, cyclomatic complexity analysis, performance profiling hints
- Action: produce structured review comments (readability, complexity, security), suggest refactoring diffs and micro-optimizations
- Assumptions/dependencies: agreed coding standards; performance baselines; access to profiling data or synthetic benchmarks
- Documentation, API stubs, and tests generation at commit-time
- Sector: software, education; Tools/workflows: commit hooks that trigger LLM generation of docstrings, README updates, signature examples, unit/integration tests
- Action: increase coverage and consistency of documentation/tests aligned with code changes
- Assumptions/dependencies: CI integration; model alignment for consistent formatting; organizational documentation conventions
- LLM-integrated CI/CD guardrails
- Sector: DevOps; Tools/workflows: CI orchestrators (GitHub Actions, GitLab CI) calling LLMs for change impact summaries, risk flags, and rollback plans
- Action: summarize diffs, forecast risk in deployment, auto-populate release notes, and propose canary tests
- Assumptions/dependencies: reliable prompts on repo metadata; access controls; audit trails for AI-generated decisions
- Classroom and MOOC coding tutors with test-driven feedback
- Sector: education; Tools/workflows: auto-graders, step-by-step hints (chain-of-thought), code explanation, debugging guidance
- Action: personalized learning with immediate feedback; generation of scaffold exercises and explanations; notebook infilling (JuPyT5-style)
- Assumptions/dependencies: guardrails to avoid giving full solutions; alignment with curriculum; bias/fairness monitoring
- Policy-compliant license and provenance checks for training data
- Sector: policy, legal, academia; Tools/workflows: data curation pipelines, license filters, deduplication, provenance tracking
- Action: enforce licensing compliance and traceability of code corpora used for fine-tuning and evaluation
- Assumptions/dependencies: accurate metadata; organizational buy-in; ongoing data governance
- Benchmark-driven model evaluation and selection for code tasks
- Sector: academia, MLOps; Tools/workflows: HumanEval, MBPP, SWE-Bench Verified, LiveCodeBench; metrics beyond correctness (security, maintainability)
- Action: choose base/fine-tuned models via task-relevant benchmarks; incorporate hyperparameter sensitivity and scaling law insights
- Assumptions/dependencies: representative benchmarks; reproducible eval harnesses; compute to run multi-sample evaluations
- Reliability alignment for tool use and agent workflows
- Sector: software, robotics RPA; Tools/workflows: ReAct, Toolformer, reliability alignment techniques to reduce tool hallucination and timing errors
- Action: calibrate agents to pick correct tools, confirm results, and retry safely; log action traces for auditability
- Assumptions/dependencies: high-quality tool APIs; sandbox environments; telemetry for feedback loops
- On-device or cost-efficient serving with MoE/SSM hybrids
- Sector: software, edge/IoT; Tools/workflows: MoE for conditional compute, Mamba/RetNet/RWKV for low-memory inference
- Action: deploy smaller active-parameter models for IDE plugins, CLIs, and edge dev tools to reduce latency and cost
- Assumptions/dependencies: compatible hardware; model quantization; task-specific fine-tuning for code domains
Long-Term Applications
These applications build on frontier methods (RL on real SWE tasks, diffusion-based code models, hybrid architectures, autonomous agents) and require further research, scaling, or infrastructure maturation.
- Fully autonomous repository-level coding agents
- Sector: software; Tools/workflows: multi-step planning, computer-use stacks (terminal, editor, package manager, browser), RL on real tasks, parallel test-time compute
- Outcome: agents that plan, implement, test, and merge complex changes across large codebases with minimal supervision
- Assumptions/dependencies: robust long-horizon reasoning; comprehensive tests; safe execution sandboxes; organizational acceptance of automated merges
- Secure coding copilots with formal verification loops
- Sector: cybersecurity, safety-critical (healthcare, automotive, avionics); Tools/workflows: LLM codegen + static/dynamic analysis + formal tools (e.g., model checking, SMT solvers)
- Outcome: generation pipelines that automatically discharge security/functional proofs or produce counterexamples
- Assumptions/dependencies: scalable formal methods for real-world code; high-quality specs; performance constraints in CI
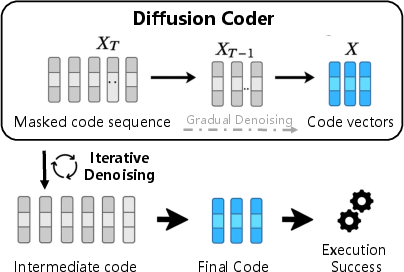
- Diffusion-based coding models for high-throughput, parallel code editing
- Sector: software; Tools/workflows: diffusion LMs (Mercury Coder, Gemini Diffusion), block denoising, hybrid AR–diffusion decoders
- Outcome: rapid parallel code refinement, multi-token generation with global constraints (style, security, performance)
- Assumptions/dependencies: faster samplers; reliable token-space diffusion; integration into IDEs and CI; empirical validation vs AR baselines
- Org-wide AI software factories with governance-by-design
- Sector: enterprise IT, finance, healthcare; Tools/workflows: standardized AI pipelines for requirements→design→implementation→tests→compliance→deployment
- Outcome: AI-managed SDLC with policy gates (licensing, security, privacy), automated traceability and audit trails
- Assumptions/dependencies: cross-functional governance; compliance frameworks; scalable model monitoring; cultural change management
- Large-scale codebase comprehension with retrieval + long-context hybrids
- Sector: software; Tools/workflows: hybrid attention (DeltaNet/Gated attention), 256K+ contexts, semantic code indexing, cross-file dependency graphs
- Outcome: reliable global reasoning across repositories, enabling refactoring, architectural analysis, and impact forecasting
- Assumptions/dependencies: efficient memory/KV cache strategies; accurate code graphs; optimized retrieval for “lost-in-the-middle” mitigation
- RL-trained coding specialists via real engineering environments
- Sector: academia, software; Tools/workflows: RLHF extensions with environment rewards (passing tests, security checks, performance), curriculum over tasks
- Outcome: models tuned to practical objectives (repair rate, security score, maintainability) outperform SFT-only baselines
- Assumptions/dependencies: safe reward design; reproducible sandboxes; diverse task suites; compute costs for online RL
- Multimodal GUI understanding and end-to-end UI automation
- Sector: software, RPA, robotics; Tools/workflows: screen parsing, UI hierarchies, interaction semantics, model-based planning
- Outcome: agents that reliably interpret complex UIs and automate workflows (testing, accessibility improvements, migration)
- Assumptions/dependencies: robust GUI perception; cross-app generalization; safety guardrails to prevent destructive actions
- Regulator-ready standards for AI-generated code and tool use
- Sector: policy, legal; Tools/workflows: certification benchmarks (security, provenance), disclosure requirements, auditability standards for agent actions
- Outcome: compliance frameworks for using AI in safety-critical or regulated domains; procurement guidelines
- Assumptions/dependencies: multi-stakeholder consensus; alignment with existing regulations; standardized evaluation suites
- Domain-specialized coders for healthcare/finance with embedded domain ontologies
- Sector: healthcare, finance; Tools/workflows: domain-augmented training (FHIR/HL7, ISO 20022), retrieval from authoritative specs, policy-aligned generation
- Outcome: safer, compliant generation and migration of interfaces, validators, and data pipelines
- Assumptions/dependencies: curated domain corpora; access to proprietary specs; bias and privacy controls; legal review
- Self-healing CI/CD and infra-as-code agents
- Sector: DevOps, cloud; Tools/workflows: agents that monitor deployments, detect drifts, patch infra code (Terraform, Kubernetes), and validate with canaries
- Outcome: reduced downtime and faster recovery through autonomous infra maintenance
- Assumptions/dependencies: robust observability; safe change windows; rollback strategies; strict policy gates
- Collaborative multi-agent coding teams with role specialization
- Sector: software; Tools/workflows: planner, implementer, tester, reviewer agents coordinated via shared memory and tool APIs
- Outcome: scalable “AI scrum teams” handling complex epics with structured handoffs and quality gates
- Assumptions/dependencies: reliable multi-agent coordination; conflict resolution; comprehensive telemetry and human oversight
- Energy-efficient code LLMs for edge and regulated environments
- Sector: energy, industrial IoT, defense; Tools/workflows: MoE routing, SSM/recurrent inference, quantization, distillation
- Outcome: deploy compliant assistant coders in constrained environments, enabling local development support and audits
- Assumptions/dependencies: hardware compatibility; performance–accuracy trade-offs; secure local storage and execution
- Advanced academic tooling: reproducible training recipes and dataset governance
- Sector: academia; Tools/workflows: open training recipes covering scaling laws, hyperparameter sensitivity, architecture choices; dataset curation with dedup/licensing/provenance
- Outcome: faster, more credible research iterations and cross-lab comparability; reduced leakage risk in evaluations
- Assumptions/dependencies: shared benchmarks and corpora; compute access; community norms around publishing recipes and data lineage
Notes on cross-cutting dependencies
Many applications depend on:
- High-quality, license-compliant datasets and retrieval indices
- Strong test coverage and reproducible execution environments
- Safe tool use (sandboxing, least-privilege) and reliability alignment
- Organizational governance (security policies, audit trails, human-in-the-loop)
- Access to capable models (closed or open) and cost-effective serving (MoE/SSM/hybrid)
- Evaluation beyond correctness (security, maintainability, efficiency) to avoid misaligned optimization
Collections
Sign up for free to add this paper to one or more collections.