Region-aware Spatiotemporal Modeling with Collaborative Domain Generalization for Cross-Subject EEG Emotion Recognition
Abstract: Cross-subject EEG-based emotion recognition (EER) remains challenging due to strong inter-subject variability, which induces substantial distribution shifts in EEG signals, as well as the high complexity of emotion-related neural representations in both spatial organization and temporal evolution. Existing approaches typically improve spatial modeling, temporal modeling, or generalization strategies in isolation, which limits their ability to align representations across subjects while capturing multi-scale dynamics and suppressing subject-specific bias within a unified framework. To address these gaps, we propose a Region-aware Spatiotemporal Modeling framework with Collaborative Domain Generalization (RSM-CoDG) for cross-subject EEG emotion recognition. RSM-CoDG incorporates neuroscience priors derived from functional brain region partitioning to construct region-level spatial representations, thereby improving cross-subject comparability. It also employs multi-scale temporal modeling to characterize the dynamic evolution of emotion-evoked neural activity. In addition, the framework employs a collaborative domain generalization strategy, incorporating multidimensional constraints to reduce subject-specific bias in a fully unseen target subject setting, which enhances the generalization to unknown individuals. Extensive experimental results on SEED series datasets demonstrate that RSM-CoDG consistently outperforms existing competing methods, providing an effective approach for improving robustness. The source code is available at https://github.com/RyanLi-X/RSM-CoDG.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Simple Summary of the Paper
What is this paper about?
This paper is about teaching a computer to tell how someone feels (their emotion) just by looking at their brainwaves, recorded using EEG. EEG is a cap with sensors that measures tiny electrical signals from the brain. The big challenge is that everyone’s brain signals look a bit different, so a model trained on some people often doesn’t work well on a new person. The authors propose a new method, called RSM-CoDG, to make emotion recognition work better across different people—even ones the model has never seen before.
What questions did the researchers ask?
They focused on three main questions:
- How can we use what we know about brain regions to make EEG features more comparable between people?
- How can we track both quick changes and longer, slower shifts in emotion over time in brain signals?
- How can we train a model that works well on totally new people without using their data during training?
How did they try to solve it?
The authors built one unified system (RSM-CoDG) with three key parts that work together:
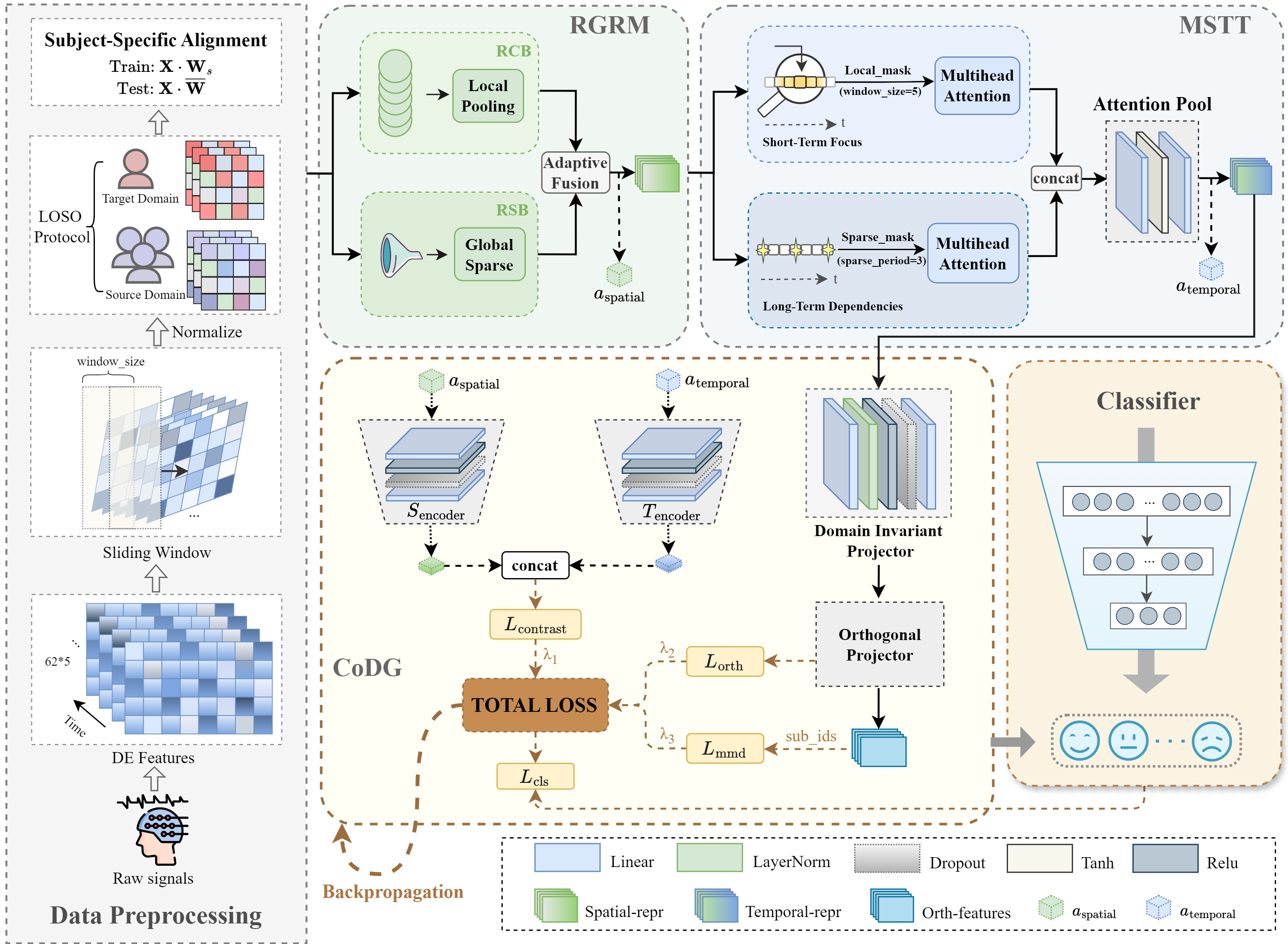
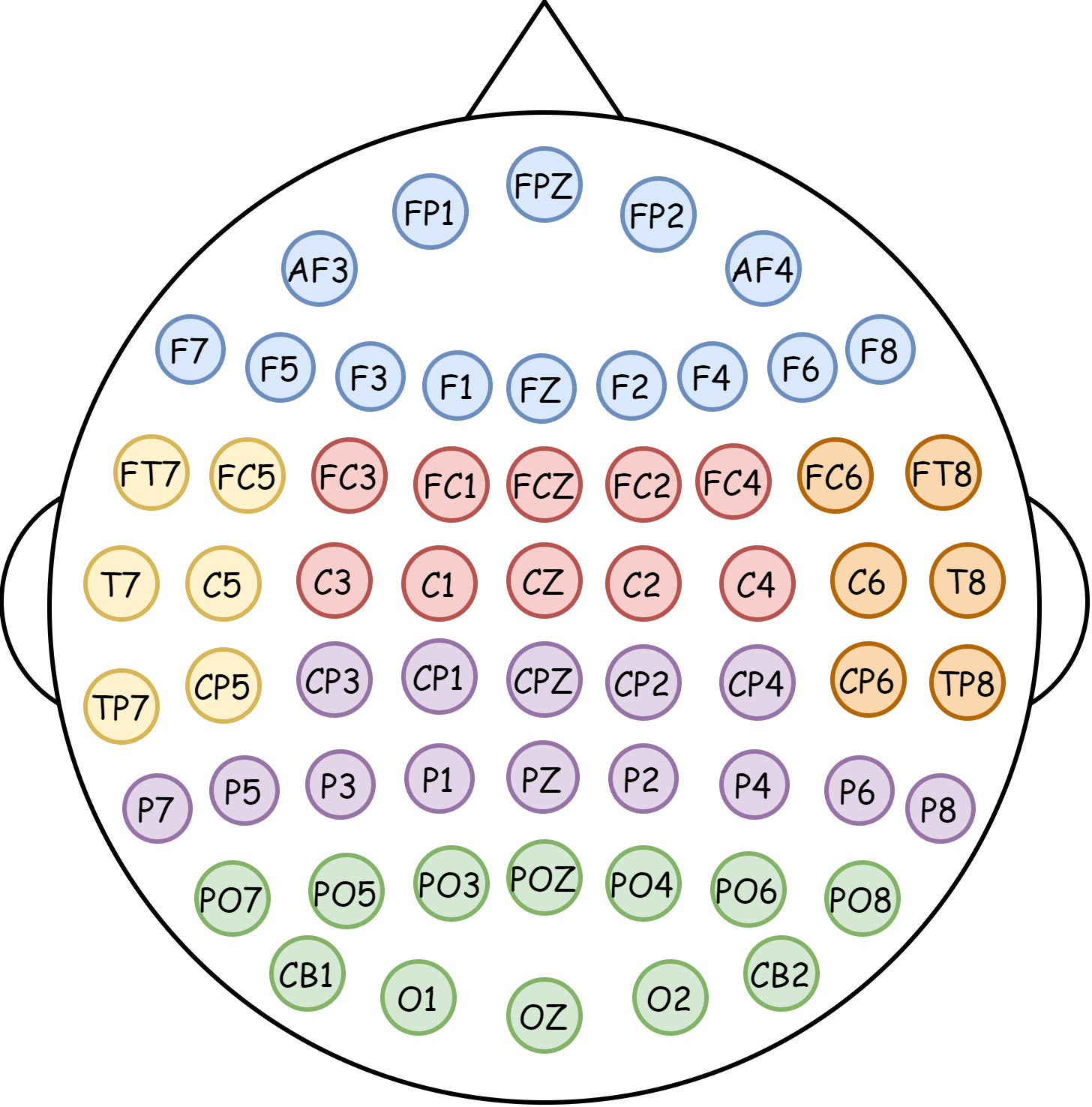
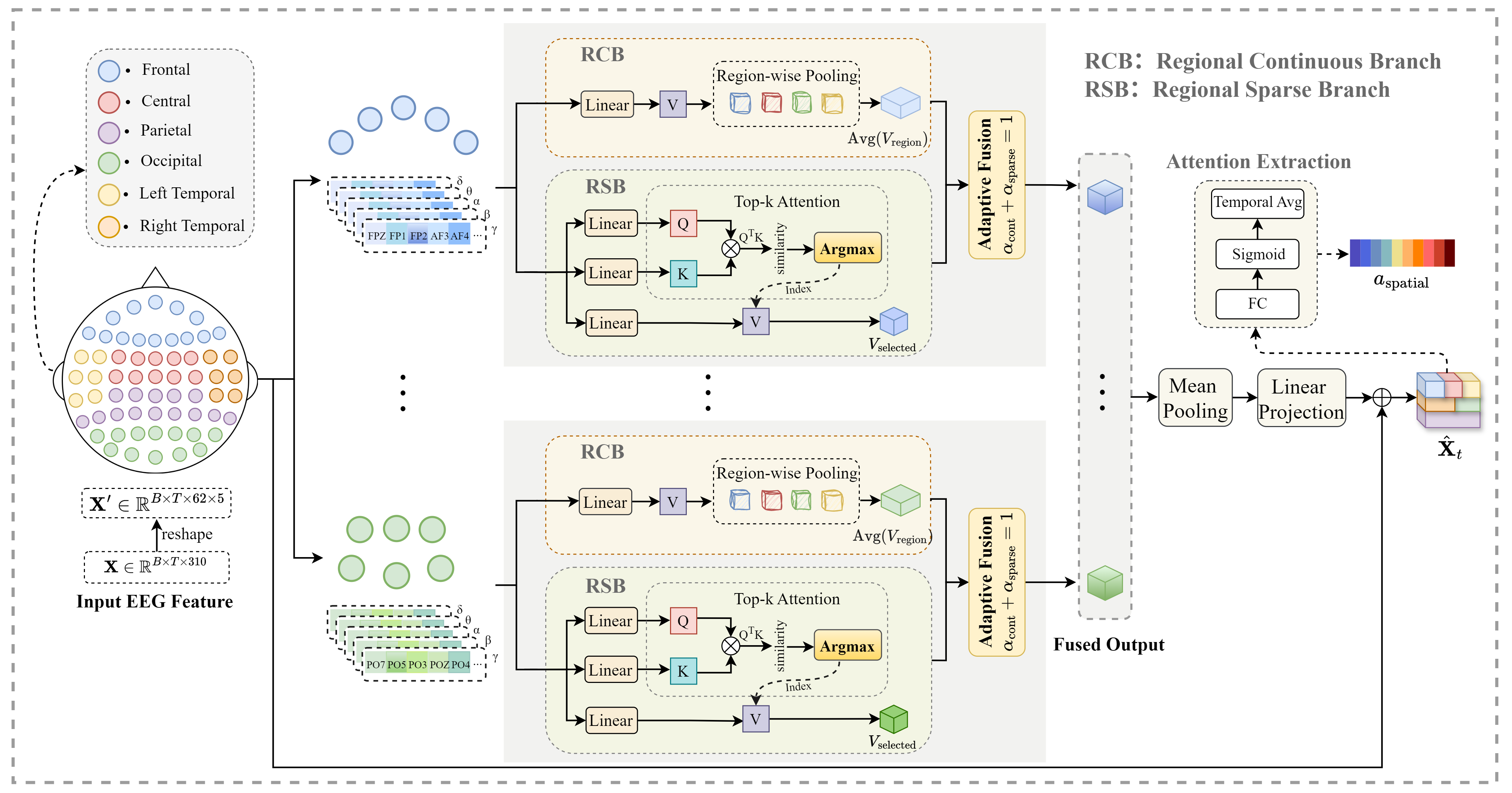
- Region-aware spatial modeling (RGRM): Think of the brain like a stadium divided into sections (frontal, central, parietal, left temporal, right temporal, occipital). Instead of treating all sensors the same, the model groups EEG sensors by these brain regions. Inside each region, it:
- Looks at the overall “average mood” of the region (smooth, stable signal).
- Also finds the most informative connections within the region (sparse, sharp signal).
- Then it blends these two views. This makes the features more meaningful and comparable across people.
- Multi-scale temporal modeling (MSTT): Emotions change both quickly and slowly. The model uses two “attention” views over time:
- A local view (like focusing on a small time window) to capture smooth, short-term changes.
- A global view (sampling key moments across the whole timeline) to catch important long-range shifts.
- Combining them helps the model follow emotion dynamics at multiple speeds—like listening for both the beat and the melody of a song.
- Collaborative domain generalization (CoDG): The model is trained to work on new people without seeing their data. It uses three training “rules” at the same time:
- Distribution alignment: Make features from different people look more similar overall (reduce the average gap between people).
- Attention consistency: Encourage the model to focus on similar brain regions and time points in a stable, meaningful way across people.
- Feature decorrelation: Reduce redundancy in the features so each part carries unique information (like making sure every student in a group project contributes something different).
- These rules help the model ignore person-specific quirks and focus on emotion-related patterns that generalize.
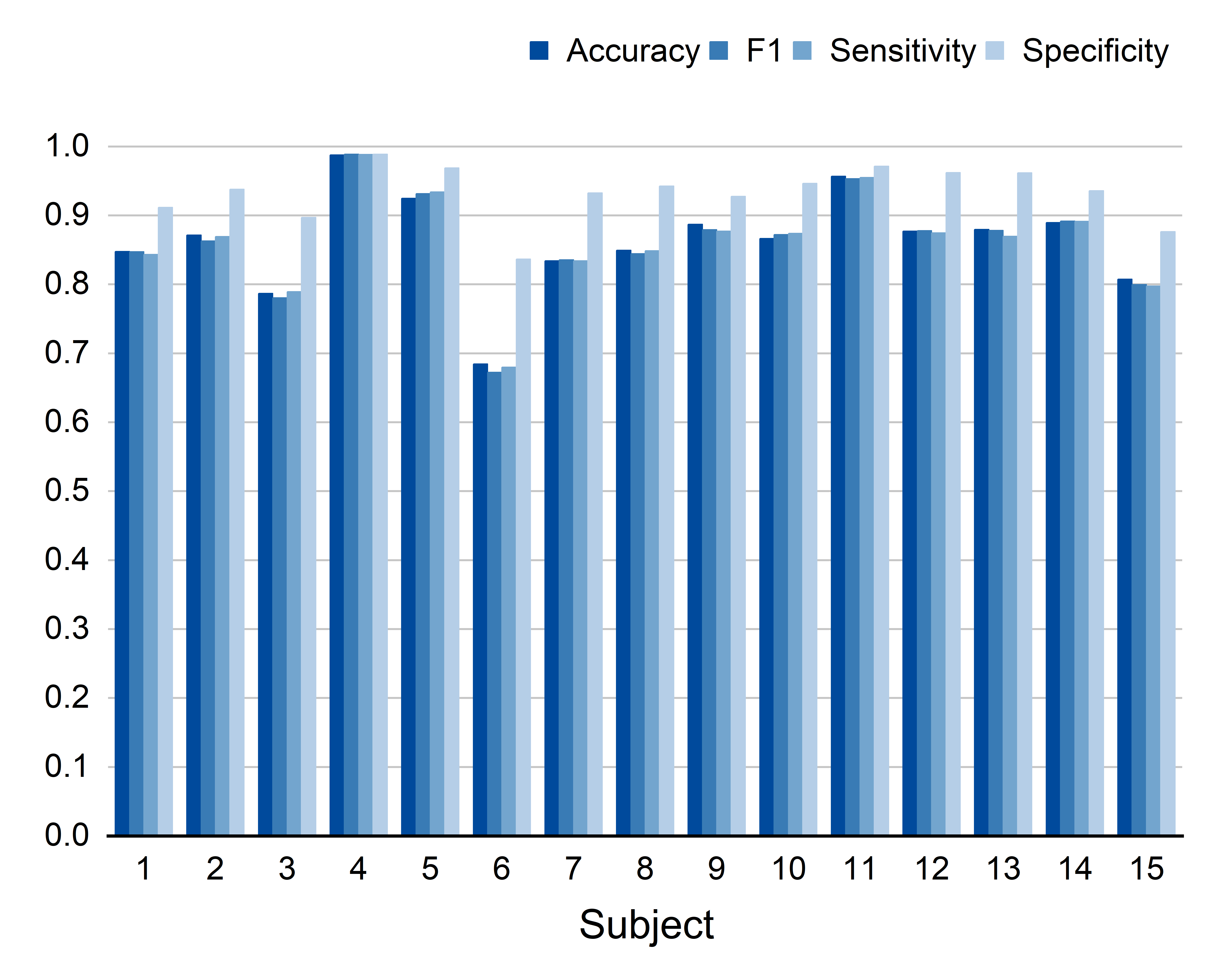
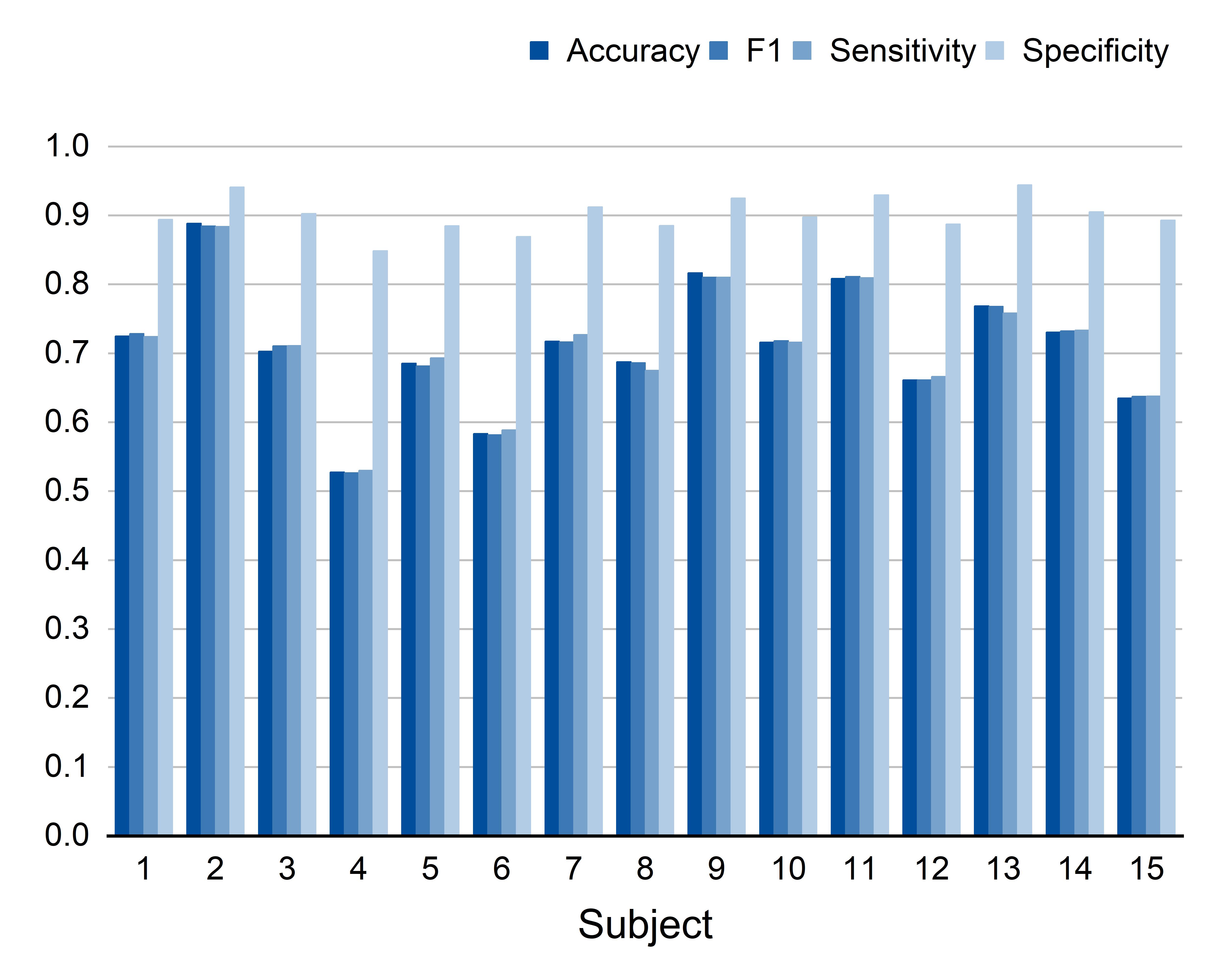
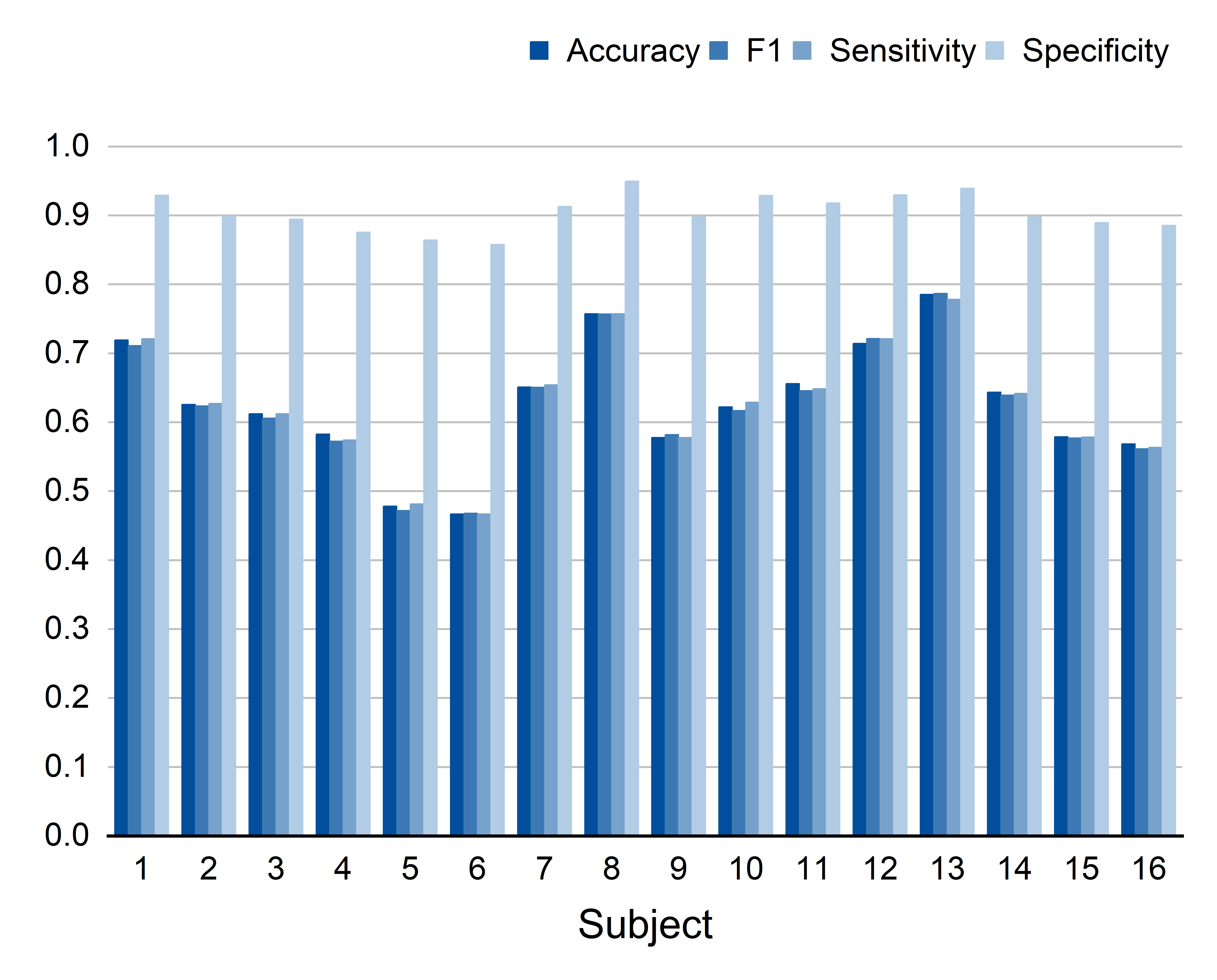
To test fairness, they used a “leave-one-subject-out” strategy: train on everyone except one person, then test on that left-out person. Repeat for each person and average the results.
What did they find?
Across three well-known emotion EEG datasets (SEED, SEED-IV, SEED-V), their method consistently beat other popular approaches. Highlights:
- On SEED (3 emotions), their accuracy reached about 86%, higher than previous methods.
- On SEED-IV (4 emotions) and SEED-V (5 emotions), they also achieved the best or near-best performance.
- The results show the model is better at handling the “new person” problem, which is often where EEG systems fail.
Why it matters:
- The gains come from combining brain-region knowledge, multi-scale timing, and smarter training rules—all in one system—rather than improving just one piece in isolation.
Why is this important?
If emotion recognition from EEG works well for new people without extra calibration, it becomes more practical in real life. This can help:
- Mental health support tools (e.g., early stress or mood detection)
- Personalized learning or work environments (adapting difficulty or content based on emotion)
- More natural human–computer interaction (devices that respond to how you feel)
In short, this research shows a clearer path toward reliable, fair, and ready-to-use emotion recognition from brain signals by:
- Respecting how the brain is organized into regions,
- Capturing both fast and slow emotional changes over time,
- And training the model to generalize to people it has never seen.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues, uncertainties, and missing explorations that future work could address to strengthen and extend the findings of the paper.
- Generalization beyond SEED-series: The model is only evaluated on SEED, SEED-IV, and SEED-V; cross-dataset generalization (e.g., train on SEED, test on DEAP/DREAMER/AMIGOS) remains untested.
- Single-session constraint: Experiments use single-session recordings; robustness across sessions (session-to-session drift within subjects) and across recording days is not evaluated.
- Dependence on DE features: The pipeline relies on handcrafted Differential Entropy features across five fixed bands; end-to-end learning from raw EEG, alternative feature spaces (e.g., PSD, time-frequency scalograms), and robustness to different feature engineering choices are not explored.
- Electrode montage and channel count variability: The approach assumes a 62-channel 10–20 montage; generalization to different montages (e.g., 32/64/128 channels, missing channels, misplacements, re-referencing schemes) is not assessed.
- Fixed, coarse brain parcellation: The six-region partition based on 10–20 system is a coarse prior; the impact of alternative, data-driven or fine-grained parcellations, individualized parcellations, or atlas-based cortical mappings is unknown.
- Partition sensitivity analysis: No ablation on the choice, correctness, or granularity of region partitioning (e.g., merging/splitting regions, lateralization manipulations) and its effect on performance or interpretability.
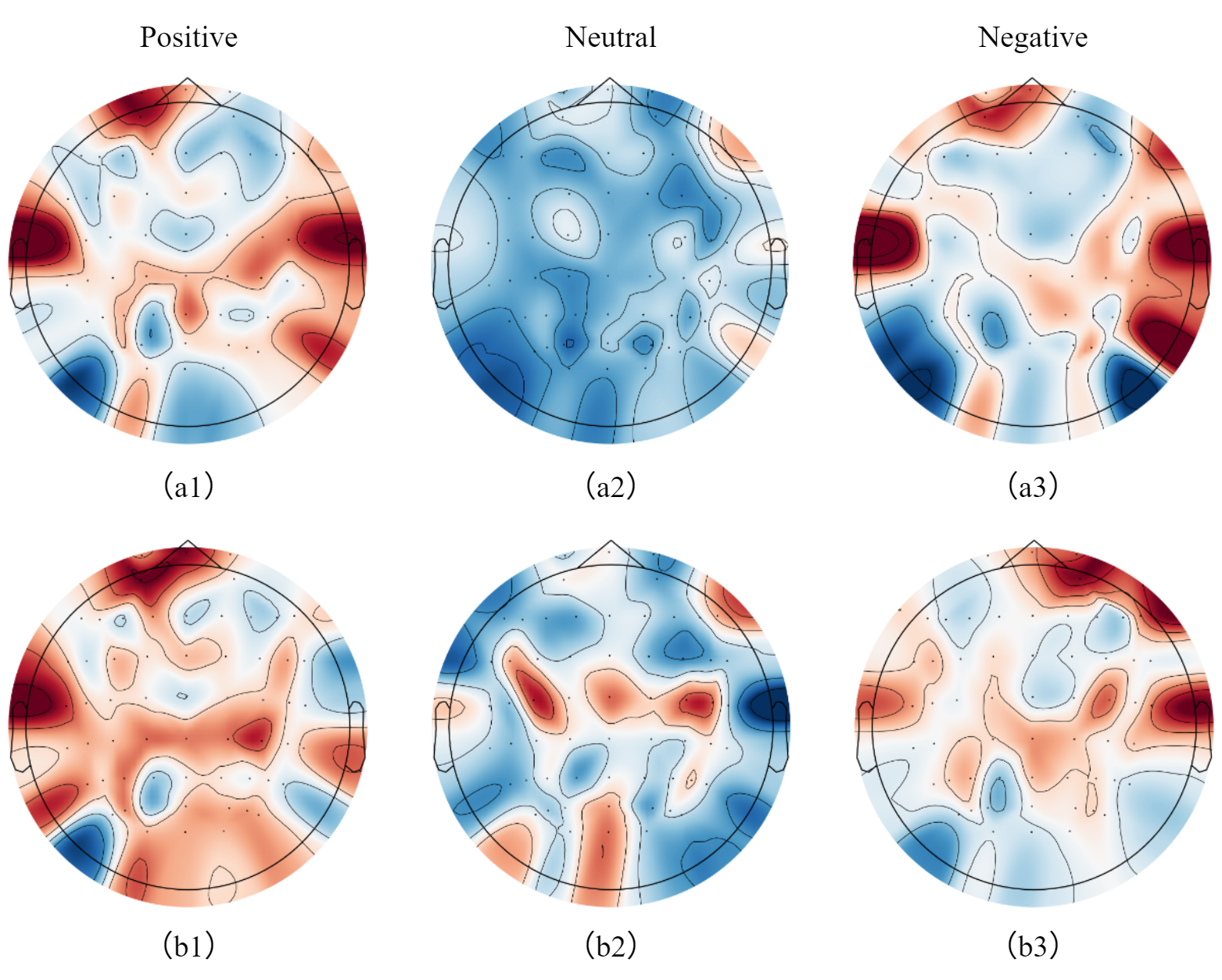
- Biological validity of attention: Spatial and temporal attention are proposed as neurophysiologically meaningful, but their alignment with known emotional processing (e.g., hemispheric lateralization, frontal asymmetry, limbic contributions) is not validated with independent neurobiological markers or expert annotations.
- Temporal mask hyperparameters: The local window size w and global sparse period p are hand-set; whether these should be learned, adapted per subject/trial, or tuned per dataset is not investigated.
- Event-boundary awareness: The periodic sparse attention may not align with stimulus boundaries or cognitive state transitions; models that infer or adapt to event boundaries (e.g., change-point detection) are not considered.
- Sequence length and streaming: Scalability to longer sequences, real-time streaming inference, latency, and memory footprint for online emotion decoding are not reported.
- Domain generalization fairness: DA methods (DANN, MS-MDA, etc.) typically require target-domain data; the paper does not clarify whether DA baselines were granted access to unlabeled target data or evaluated under a constrained DG setting, which may bias comparisons.
- CoDG alignment granularity: Distribution alignment uses first-order mean matching across subjects; higher-order statistics, class-conditional alignment (avoiding class mixing), and label-shift corrections are not addressed.
- Contrastive attention design: InfoNCE uses subject identity as positives and different subjects as negatives, potentially reinforcing subject-specific patterns; strategies to encourage cross-subject invariance (e.g., class-based positives, multi-view positives across subjects) are not explored.
- Orthogonal decorrelation trade-offs: The orthogonal constraint penalizes feature correlations globally; its effect on class-discriminative subspace structure (e.g., potentially suppressing useful correlated features) is not analyzed.
- Subject-specific alignment layer: Training learns per-subject linear transforms and averages them at test time; the theoretical justification and empirical effectiveness of averaging W_s for unseen subjects, and the risk of overfitting to source subject idiosyncrasies, are not examined.
- Robustness to artifacts: Real-world EEG artifacts (EOG, EMG, motion, electrode drift) are not explicitly handled; performance under artifact contamination and the impact of different preprocessing pipelines are unknown.
- Normalization protocol: Min–max normalization is applied, but it is unclear whether it is per-subject, per-session, or global; the influence of normalization choices on DG performance is not studied.
- Emotion taxonomy: The model is evaluated on discrete categories; generalization to dimensional affect (valence/arousal/dominance), mixed or ambiguous affective states, and continuous labels is not assessed.
- Label reliability and bias: SEED labels derive from video stimuli; the absence of concurrent self-reports or physiological ground truth raises questions about label noise and cultural/contextual biases.
- Class imbalance and calibration: Handling of class imbalance, probabilistic calibration, and threshold selection for multi-class decisions is not discussed.
- Interpretability evaluation: Beyond attention visualization, quantitative interpretability (e.g., causal attribution, perturbation analyses, trustworthiness metrics) and clinician-relevant explanations are missing.
- Computational cost: Model size, parameter counts, training/inference time, and energy consumption (especially for edge deployment) are not reported.
- Hyperparameter sensitivity: No systematic sensitivity analysis of λ1–λ3, dropout rates, noise level, learning rates, or MSTT/RGRM dimensions; training stability and reproducibility across seeds beyond a single fixed seed are not shown.
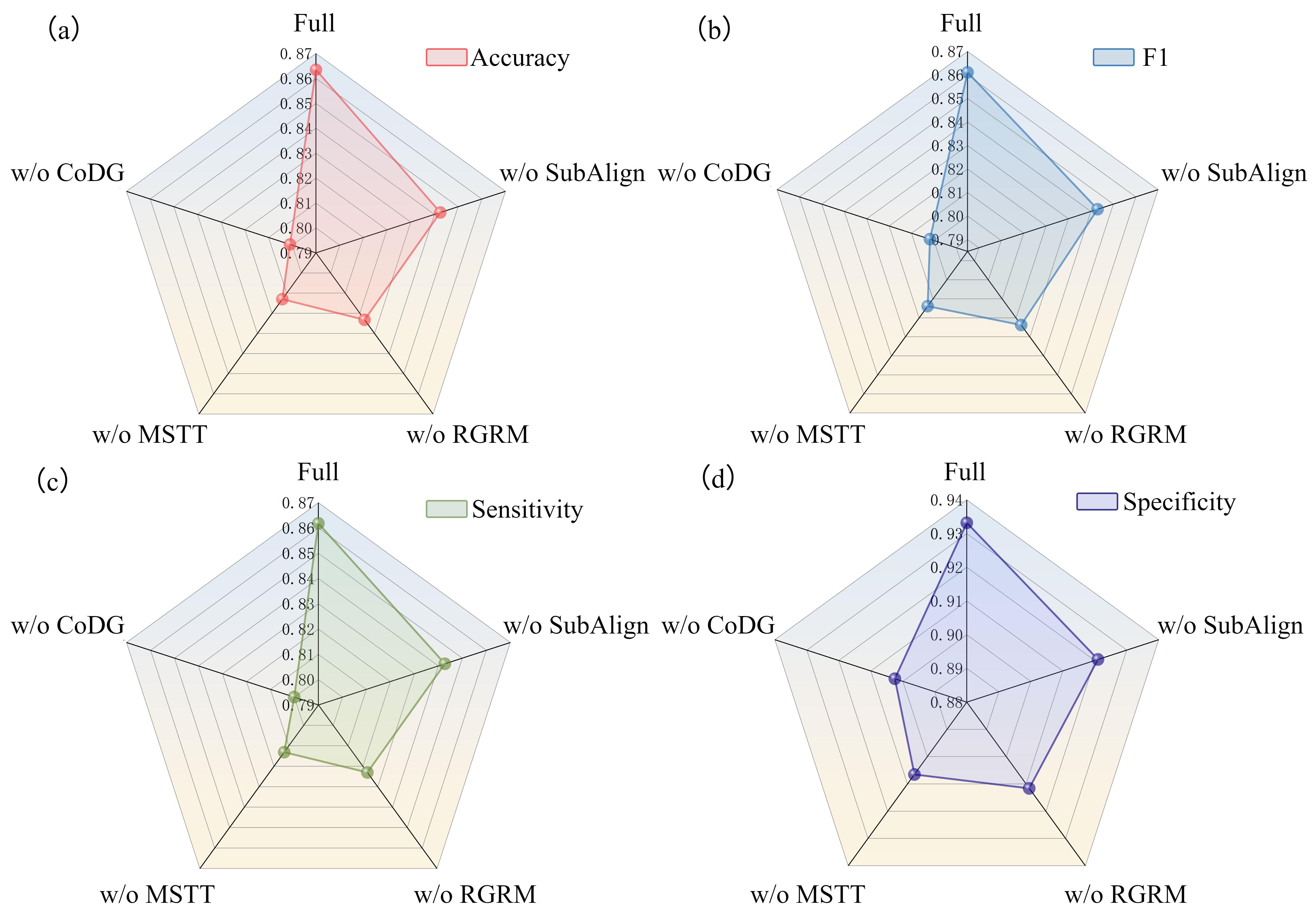
- Ablations and component contributions: The paper does not present (in the provided text) ablation studies isolating contributions of RGRM vs. MSTT vs. CoDG, or of each CoDG loss term, to validate the necessity of each component.
- Statistical significance: Although mean ± std accuracy is reported, statistical significance testing (e.g., paired tests across LOSO folds) and effect sizes are not provided.
- Cross-modal fusion: The model is unimodal EEG; whether adding peripheral signals (EOG/EMG/GSR/PPG) or audio-visual context improves robustness under DG is unaddressed.
- Demographic and clinical diversity: Performance across demographics (age, gender), neurological conditions, or clinical cohorts is unknown; fairness audits and subgroup analyses are missing.
- Real-world deployment: Practical considerations (sensor quality variability, missing data handling, calibration-free setup, user comfort, long-term monitoring) and failure modes in-the-wild are not studied.
- Security and adversarial robustness: Resistance to adversarial perturbations or spoofing in EEG-based emotion recognition systems is not assessed.
Glossary
- Adam optimizer: A stochastic gradient-based optimization algorithm commonly used to train neural networks. "Our model was trained using the Adam optimizer with an initial learning rate of "
- Adaptive adjacency matrices: Learnable graph connectivity matrices that adjust edge strengths based on data rather than using a fixed topology. "learn adaptive adjacency matrices based on feature similarity \cite{10}"
- Affective computing: An interdisciplinary field that studies and develops systems that can recognize, interpret, and process human emotions. "three public EEG datasets widely used in affective computing"
- Band-pass filtered: A signal processing operation that preserves frequencies within a specified range while attenuating others. "The raw EEG signals were band-pass filtered within 0--75\,Hz"
- Collaboratively optimized Domain Generalization (CoDG): A multi-constraint training strategy that jointly enforces distribution alignment, attention consistency, and feature decorrelation to improve generalization without target data. "our Collaboratively optimized Domain Generalization strategy (CoDG)"
- Contrastive learning: A self-supervised learning paradigm that brings similar pairs closer and pushes dissimilar pairs apart in representation space. "through contrastive learning mechanisms \cite{46}"
- Correlation Alignment (CORAL): A domain adaptation method that aligns second-order statistics (covariances) between source and target domains. "Correlation Alignment (CORAL) \cite{57}"
- Cosine similarity: A similarity measure between two vectors based on the cosine of the angle between them. "denotes cosine similarity"
- Denoising Mixed Mutual Reconstruction (DMMR): A domain generalization framework that uses noise injection and mutual reconstruction of mixed-subject features to improve robustness. "the Denoising Mixed Mutual Reconstruction (DMMR) framework"
- Differential Entropy (DE): A continuous analog of entropy used as a feature for EEG time–frequency characterization. "Differential Entropy (DE) features \cite{50} were then extracted"
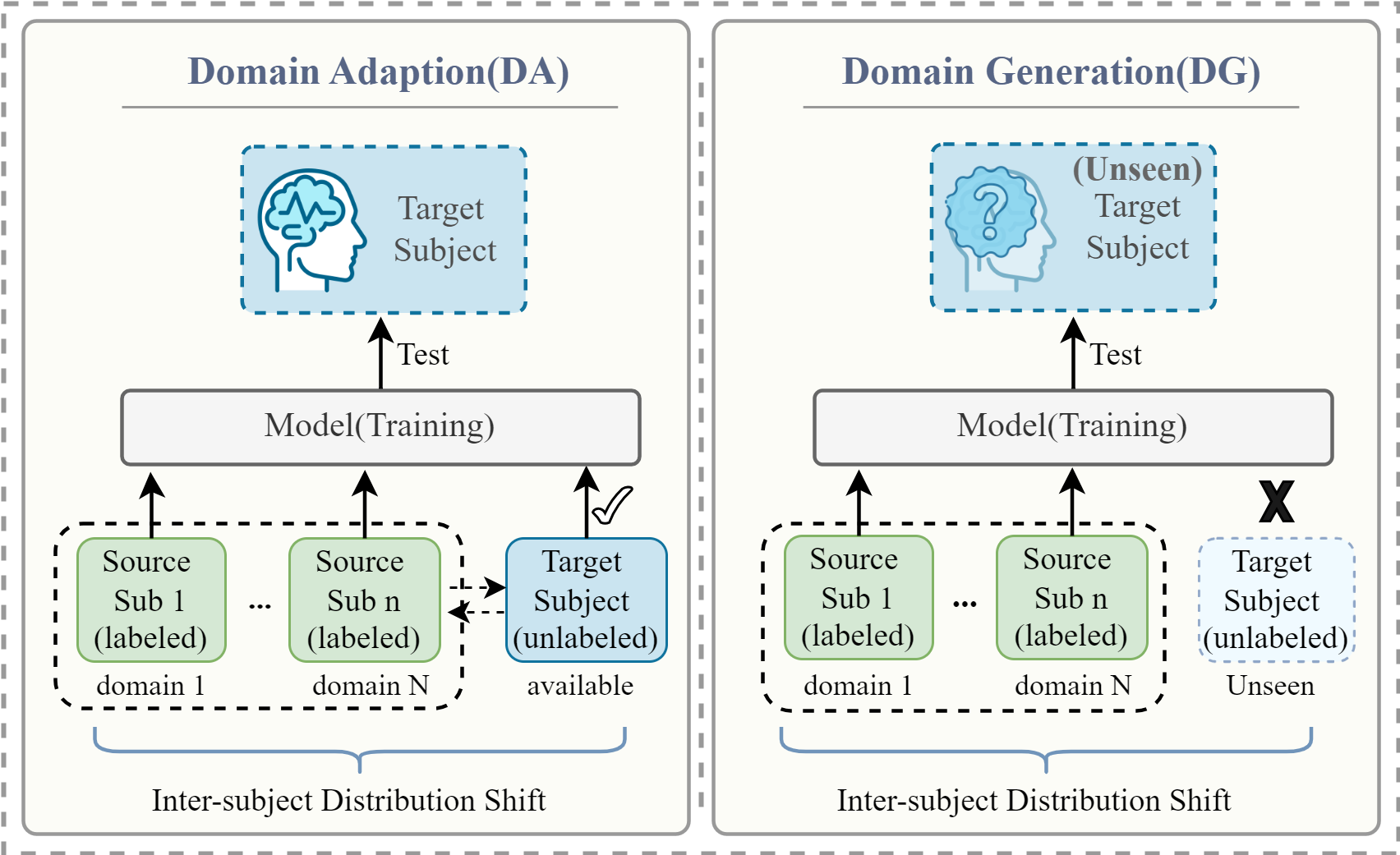
- Domain adaptation (DA): Techniques that adapt a model trained on source data to perform well on a different but related target domain, often using unlabeled target data. "domain adaptation (DA) methods attempt to mitigate these inter-subject shifts"
- Domain generalization (DG): Techniques that train models on multiple source domains to generalize to unseen target domains without access to target data during training. "domain generalization (DG) aims to learn robust and transferable representations"
- Domain-invariant features: Representations that are stable across different domains (e.g., subjects), reducing performance drops due to distribution shifts. "learn domain-invariant features"
- Frobenius norm: A matrix norm equal to the square root of the sum of the absolute squares of its elements, often used for regularization. "and denotes the Frobenius norm"
- Geodesic Flow Kernel (GFK): A manifold-based domain adaptation method that integrates features along geodesic paths between source and target subspaces. "Geodesic Flow Kernel (GFK) \cite{53}"
- Graph Convolutional Networks (GCNs): Neural architectures that generalize convolution to graph-structured data to aggregate information over nodes and edges. "using Graph Convolutional Networks (GCNs) for spatial feature extraction \cite{11}"
- Graph Neural Networks (GNNs): A class of neural networks designed to operate on graphs by propagating and aggregating node/edge information. "overcome the homogeneity of conventional GNNs"
- Hemispheric lateralization: The functional specialization of the left and right hemispheres of the brain for different tasks. "hemispheric lateralization in emotion processing"
- Inductive bias: Assumptions built into a model that guide learning toward certain solutions; here, neuroscientific structure informs modeling. "as a structural inductive bias"
- InfoNCE: A contrastive loss formulation that maximizes agreement between positive pairs relative to negatives, typically with a temperature parameter. "Based on the InfoNCE framework, this loss encourages attention patterns from the same subject to be close"
- International 10–20 system: A standardized method to place EEG electrodes on the scalp based on anatomical landmarks. "international 10â20 system"
- Layer normalization: A normalization technique applied across the features of each data sample to stabilize and accelerate training. "a residual connection followed by layer normalization is applied"
- Leave-One-Subject-Out (LOSO): A cross-validation protocol where each subject is held out as the test set once while training on the remaining subjects. "a Leave-One-Subject-Out (LOSO) cross-validation strategy"
- Log-softmax: A function that outputs log probabilities by applying log to the softmax outputs, often used with negative log-likelihood loss. "predicted emotion probabilities via a log-softmax layer"
- Maximum Mean Discrepancy (MMD): A statistical distance between distributions used to align features across domains. "Maximum Mean Discrepancy Loss (MMD Loss)"
- Meta-learning: Learning-to-learn methods that train models to adapt quickly to new tasks or domains, often used for domain generalization. "meta-learning or data augmentation to simulate domain shifts \cite{24,25,26}"
- Min–max normalization: A feature scaling technique that rescales values to a fixed range, typically [0, 1]. "all features were normalized using min--max normalization"
- Multi-Scale Temporal Transformer (MSTT): A Transformer-based temporal module that captures both local and global temporal dynamics via structured attention. "we introduce the Multi-Scale Temporal Transformer (MSTT)"
- Orthogonal Constraint Loss: A regularization objective that encourages feature dimensions to be uncorrelated (orthogonal), reducing redundancy. "Orthogonal Constraint Loss"
- Orthogonal projection matrix: A linear transformation matrix constrained to be orthogonal, preserving lengths and promoting decorrelated features. "a bias-free orthogonal projection matrix $\mathbf{W}_{\mathrm{orth}$"
- Periodic sparse attention: An attention mechanism that attends to a subset of time points sampled periodically to capture long-range dependencies efficiently. "a global encoder leverages periodic sparse attention to capture salient long-range dependencies"
- Residual connection: A skip connection that adds a layer’s input to its output to facilitate training deeper networks. "Finally, a residual connection followed by layer normalization is applied"
- Self-attention: A mechanism allowing each element in a sequence to attend to other elements to model dependencies. "modeling global dependencies via self-attention"
- StepLR scheduler: A learning rate scheduler that decays the learning rate by a factor every fixed number of epochs. "A StepLR scheduler (step size: 15 epochs, decay factor: 0.7) was applied"
- Subject-invariant representation: A representation that captures task-relevant information while being insensitive to differences between subjects. "learns a subject-invariant representation from multiple source subjects"
- Subject-specific alignment: A preprocessing or modeling step that calibrates features per subject to reduce inter-subject variability. "a lightweight subject-specific alignment layer"
- Structured attention masks: Predesigned attention masking patterns that constrain which positions can attend to which others to encode inductive biases. "by introducing structured attention masks"
- Temperature hyperparameter: A scaling parameter in contrastive/softmax-based losses that controls the sharpness of probability distributions. "and is a temperature hyperparameter"
- Weight decay: L2 regularization applied to model weights to reduce overfitting during training. "a weight decay of "
Practical Applications
Below are practical, real-world applications that follow from the paper’s findings, methods, and innovations. They are grouped by their time-to-deployment potential, and each item notes sector relevance, concrete use cases, potential tools/products/workflows, and key dependencies/assumptions that affect feasibility.
Immediate Applications
The following can be piloted or deployed now in research labs, R&D units, or controlled industry settings using available 32–64 channel EEG systems and the released code.
- Cross-subject EEG emotion decoding for content testing and UX research (media, advertising, gaming, VR)
- Use case: Out-of-the-box emotion inference across new participants to assess engagement/valence without per-user calibration in A/B tests of trailers, ads, games, or VR scenes.
- Potential tools/products/workflows: A lab dashboard that streams EEG to an RSM-CoDG inference server; batch analysis pipeline for post-hoc labeling of segments by emotional state; integration into Unity/Unreal for stimulus tagging.
- Dependencies/assumptions: High-density EEG (≈62 channels) and clean recordings similar to SEED protocols; film-elicited emotion may not fully represent in-the-wild stimuli; privacy/consent and IRB compliance required.
- Rapid prototyping of affect-aware BCIs in controlled environments (software, HCI)
- Use case: Adaptive interfaces that modulate difficulty, pacing, or notifications based on inferred emotional state during usability sessions.
- Potential tools/products/workflows: Python SDK wrapping the GitHub code; a ROS/ZeroMQ bridge for real-time feeds; attention-weight visualizations for interface designers.
- Dependencies/assumptions: Latency budgets compatible with MSTT; motion artifact control; initial deployment in lab or seated settings.
- Academic baselines and benchmarks for cross-subject generalization in EEG (academia)
- Use case: Reproducible baseline for LOSO experiments in emotion recognition, with interpretable region-aware attention maps for neuroscientific analysis.
- Potential tools/products/workflows: MNE-Python or EEGLAB plugin that runs RGRM+MSTT and exports regional attention; Jupyter templates for LOSO/DG evaluation; ablation scripts for course labs.
- Dependencies/assumptions: Mapping electrodes to the six-region 10–20 partition; DE feature extraction pipeline; GPU access for training.
- Transfer of the CoDG strategy to other EEG decoding tasks (academia, healthcare R&D)
- Use case: Improve cross-subject robustness for cognitive workload estimation, vigilance, P300/ERN studies, or mental fatigue detection.
- Potential tools/products/workflows: Drop-in CoDG loss terms (distribution alignment, attention consistency, decorrelation) in existing EEG models; reproducible training recipes.
- Dependencies/assumptions: Appropriately defined “attention” proxies for non-emotion tasks; availability of multi-subject datasets; similar signal quality.
- Semi-automated EEG annotation assistance for large studies (software tools in research CROs)
- Use case: Pre-label emotional segments to reduce human annotation load in longitudinal or multi-site studies.
- Potential tools/products/workflows: Batch inference CLI that ingests EDF/BDF + DE features; active-learning loop where human raters review uncertain segments flagged by entropy/attention scores.
- Dependencies/assumptions: Quality-controlled recordings; harmonized preprocessing across sites; model confidence calibration.
- Region-aware interpretability for neuroscientists (academia, clinical research)
- Use case: Hypothesis generation about frontal/temporal lateralization and region contributions to affect processing via RGRM’s region-level attention.
- Potential tools/products/workflows: Region-wise heatmaps over time; export to BIDS derivatives with attention tracks; statistical comparison across cohorts.
- Dependencies/assumptions: Validity of six-region partition for the specific paradigm; careful interpretation to avoid over-attribution; multiple-comparison corrections.
- Neuromarketing lab services with reduced per-subject calibration (marketing analytics)
- Use case: Faster onboarding of participants with more stable cross-subject emotion metrics (valence/engagement proxies).
- Potential tools/products/workflows: Turnkey lab service packages; standardized stimuli libraries; automated report generation with confidence intervals.
- Dependencies/assumptions: Ethical guidelines and informed consent for emotion inference; demographic diversity to avoid hidden biases; data governance for sensitive biosignals.
- Quality assurance and model governance for EEG emotion AI (policy, compliance, MLOps)
- Use case: Standardized LOSO/DG evaluation and reporting to reduce target-leakage and ensure fair claims.
- Potential tools/products/workflows: Model cards documenting LOSO accuracy, per-subject variance, and failure modes; reproducible DG test harness; bias and robustness checklists.
- Dependencies/assumptions: Agreement on DG metrics and protocols; access to holdout subjects; institutional policies around emotion AI.
Long-Term Applications
These will require further research, validation beyond lab settings, hardware adaptation (e.g., fewer/dry electrodes or ear-EEG), regulatory approval (for clinical uses), or multimodal integration.
- Ambient mental health monitoring and just-in-time interventions (healthcare, digital therapeutics)
- Use case: Continuous assessment of affective state to support depression/anxiety management, with personalized neurofeedback or CBT prompts.
- Potential tools/products/workflows: Wearable-friendly variants of RSM-CoDG adapted to 4–16 channel dry/ear-EEG; edge inference on mobile SoCs; clinician dashboards.
- Dependencies/assumptions: Clinical validation on diverse populations; robust performance with low-channel, mobile, and artifact-prone data; medical device regulation and privacy safeguards.
- Personalized neurofeedback for emotion regulation (healthcare, wellness)
- Use case: Training users to modulate emotional responses via real-time EEG feedback with region-aware targets (e.g., frontal asymmetry).
- Potential tools/products/workflows: Closed-loop training applications with adaptive difficulty; biofeedback games; home-use kits with cloud-assisted calibration.
- Dependencies/assumptions: Evidence of efficacy in randomized trials; safe and interpretable feedback; affordable, comfortable wearables.
- Affective adaptive learning platforms (education EdTech)
- Use case: Courseware that adapts pace and modality to learners’ frustration/engagement detected from EEG, improving retention.
- Potential tools/products/workflows: Classroom headband systems; LMS integration; privacy-preserving on-device inference.
- Dependencies/assumptions: Acceptance by schools/parents; minimized intrusiveness; robust to movement/attention shifts; data protections for minors.
- Driver/operator state monitoring in safety-critical contexts (automotive, aviation, industrial safety)
- Use case: Detect stress, overload, or negative affect that may precede performance degradation.
- Potential tools/products/workflows: Seat-integrated or ear-EEG sensors with artifact-robust RSM-CoDG variants; multimodal fusion with eye-tracking/PPG/EDA.
- Dependencies/assumptions: Feasible, unobtrusive sensors; rigorous validation in real driving/operations; regulatory and legal frameworks.
- Emotion-aware human–robot interaction (HRI) and social robotics (robotics)
- Use case: Robots adapting strategies based on human affect to improve collaboration, therapy, or companionship.
- Potential tools/products/workflows: ROS nodes for affect decoding; policies conditioned on affect embeddings; long-horizon adaptation with MSTT-informed state.
- Dependencies/assumptions: Practical wearable EEG in HRI settings; multimodal fusion to reduce reliance on EEG alone; safety and ethics guidelines.
- Cross-site, cross-device domain generalization for hospital-scale EEG analytics (healthcare systems)
- Use case: Hospital networks deploying robust EEG analytics across different devices, sites, and patient populations without per-site retraining.
- Potential tools/products/workflows: CoDG extended with site/device metadata and federated learning; harmonization layers for channel layouts.
- Dependencies/assumptions: Access to multi-site data; governance for federated training; standardization across acquisition protocols.
- Multimodal affect inference with DG (software, XR, gaming)
- Use case: Combine EEG with eye-tracking, facial EMG, speech, or EDA to improve robustness and reduce calibration, using CoDG for cross-subject invariances across modalities.
- Potential tools/products/workflows: Unified DG loss across modalities; transformer fusion of MSTT temporal embeddings; XR SDKs for adaptive experiences.
- Dependencies/assumptions: Synchronized multimodal datasets; robust fusion under missing modalities; privacy and consent management.
- Lightweight, on-device RSM-CoDG variants for consumer wearables (consumer electronics)
- Use case: Emotion-aware features in AR/VR headsets or earbuds.
- Potential tools/products/workflows: Model compression (knowledge distillation, quantization); sparse attention optimized for mobile NPUs; region mapping for sparse electrode arrays.
- Dependencies/assumptions: Acceptable accuracy with few electrodes; thermal/power constraints; real-world motion/noise resilience.
- Standard-setting and regulation for emotion AI using biosignals (policy)
- Use case: Guidelines that define acceptable use, consent, transparency, and robustness criteria for EEG-based emotion recognition.
- Potential tools/products/workflows: Reference DG benchmarks (LOSO or cross-site splits); standardized interpretability reports (region and time attention); compliance checklists.
- Dependencies/assumptions: Multi-stakeholder consensus; cross-cultural considerations for emotion constructs; alignment with data protection laws.
- Extending region-aware DG modeling to other neuro/biophysiological signals (academia, med-tech)
- Use case: Apply the region-aware + multi-scale + CoDG recipe to MEG, fNIRS, sEMG, or multi-lead ECG where spatial organization matters.
- Potential tools/products/workflows: Domain-specific “region” partition libraries; adapters for different sensor topologies; open benchmarks.
- Dependencies/assumptions: Valid anatomical/functional partitions for each modality; sufficient spatiotemporal resolution; availability of multi-subject datasets.
Notes on overarching assumptions and dependencies:
- Current results are on SEED-series datasets with 62-channel EEG and DE features under video-induced emotion; performance and generalizability may differ in real-world, mobile, or low-channel settings.
- The framework’s strengths (region-aware spatial priors, multi-scale temporal attention, and collaborative DG) are promising but require validation across demographics, cultures, tasks, and recording hardware.
- Ethical, privacy, and regulatory considerations are central for any deployment involving emotion inference from biosignals.
Collections
Sign up for free to add this paper to one or more collections.