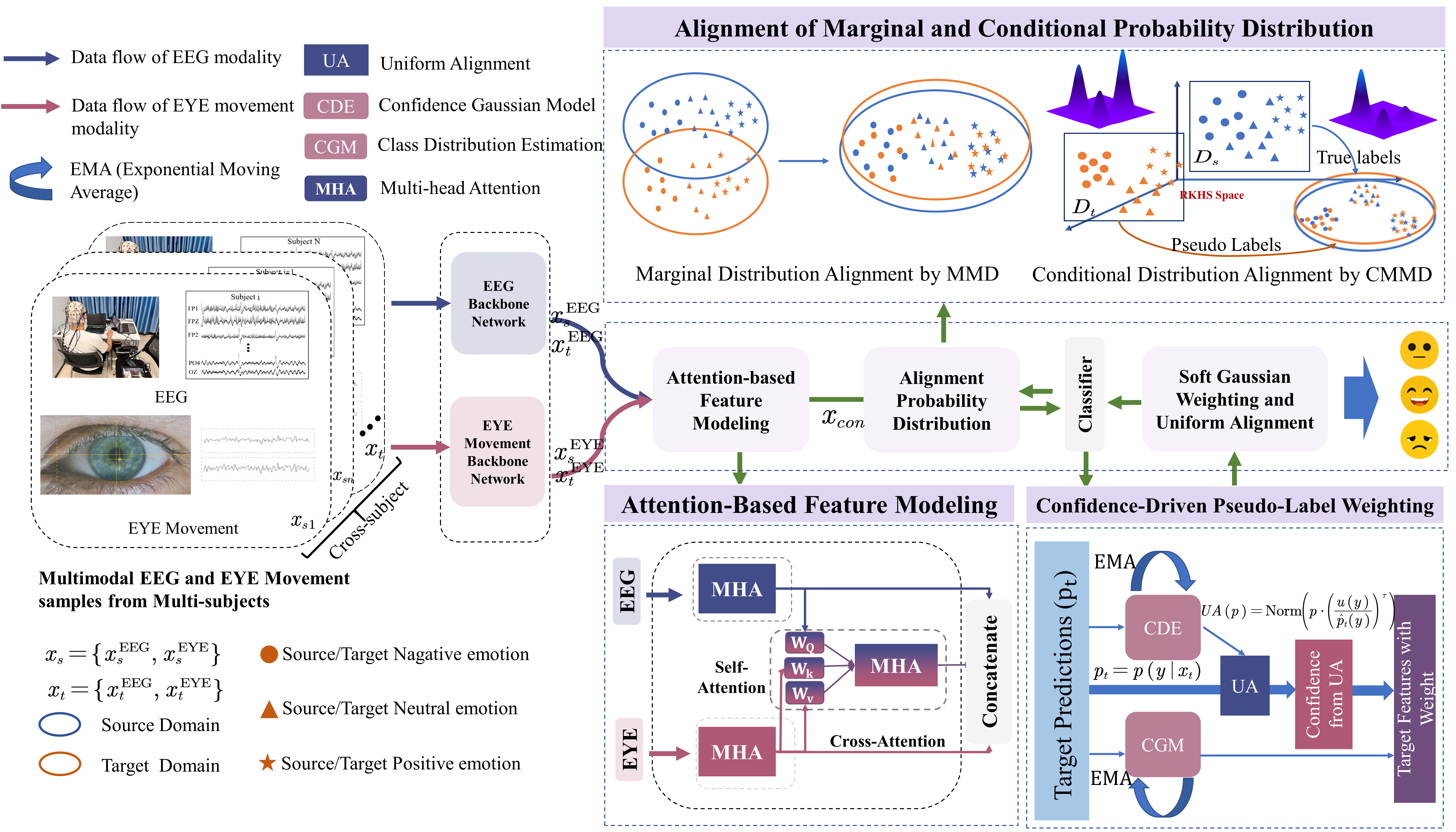
HADUA: Hierarchical Attention and Dynamic Uniform Alignment for Robust Cross-Subject Emotion Recognition
Abstract: Robust cross-subject emotion recognition from multimodal physiological signals remains a challenging problem, primarily due to modality heterogeneity and inter-subject distribution shift. To tackle these challenges, we propose a novel adaptive learning framework named Hierarchical Attention and Dynamic Uniform Alignment (HADUA). Our approach unifies the learning of multimodal representations with domain adaptation. First, we design a hierarchical attention module that explicitly models intra-modal temporal dynamics and inter-modal semantic interactions (e.g., between electroencephalogram(EEG) and eye movement(EM)), yielding discriminative and semantically coherent fused features. Second, to overcome the noise inherent in pseudo-labels during adaptation, we introduce a confidence-aware Gaussian weighting scheme that smooths the supervision from target-domain samples by down-weighting uncertain instances. Third, a uniform alignment loss is employed to regularize the distribution of pseudo-labels across classes, thereby mitigating imbalance and stabilizing conditional distribution matching. Extensive experiments on multiple cross-subject emotion recognition benchmarks show that HADUA consistently surpasses existing state-of-the-art methods in both accuracy and robustness, validating its effectiveness in handling modality gaps, noisy pseudo-labels, and class imbalance. Taken together, these contributions offer a practical and generalizable solution for building robust cross-subject affective computing systems.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching computers to recognize people’s emotions using signals from the body, like brain activity (EEG) and eye movements (EM). The tricky part is that different people’s signals can look very different, so a model trained on one group may not work well on another. The authors introduce a method called HADUA that helps the model stay accurate when it’s used on new people, even when the signals are noisy or unbalanced.
What questions were they asking?
The paper focuses on three main questions:
- How can we combine brain signals and eye movement signals in a smart way so the computer learns the most useful information from both?
- How can we make a model trained on some people work well on new people with different signal patterns?
- How can we handle “guess labels” (called pseudo-labels) for the new people’s data when we don’t know their true emotion labels, especially if some guesses are uncertain or uneven across emotion categories?
How did they do it?
To make this understandable, think of the model like a careful student trying to learn from two different textbooks (EEG and EM) and then taking a test at a new school (new people). The student needs good study strategies and fair grading.
Understanding the signals
- EEG: This is a recording of brain activity. The model looks at different “frequency bands” (like musical notes at different pitches) that relate to brain states. From these bands, it calculates numbers that describe how “surprising” or “complex” the signal is (a concept called entropy).
- Eye movements: The model looks at things like how long you fixate on something, how your pupils change, how often you blink, and how your eyes move from one spot to another.
Hierarchical attention (spotlights on what matters)
- Attention is like a spotlight: it helps the model focus on the most important parts of each signal.
- The model first shines spotlights within each signal type (EEG and EM) to understand their timing and patterns.
- Then it shines a cross-spotlight from EEG to EM, letting the richer brain signal guide which eye movement details are most helpful. This reduces noise and makes the combined features more meaningful.
Learning from new people (domain adaptation)
- Training on one group and testing on another is called cross-subject learning. Think of it like making sure the student’s learning style transfers to a new school.
- The model tries to “align” the source group and the new group so their features look more similar. The authors use a technique (MMD/CMMD) that measures how different two sets of features are and nudges them closer together.
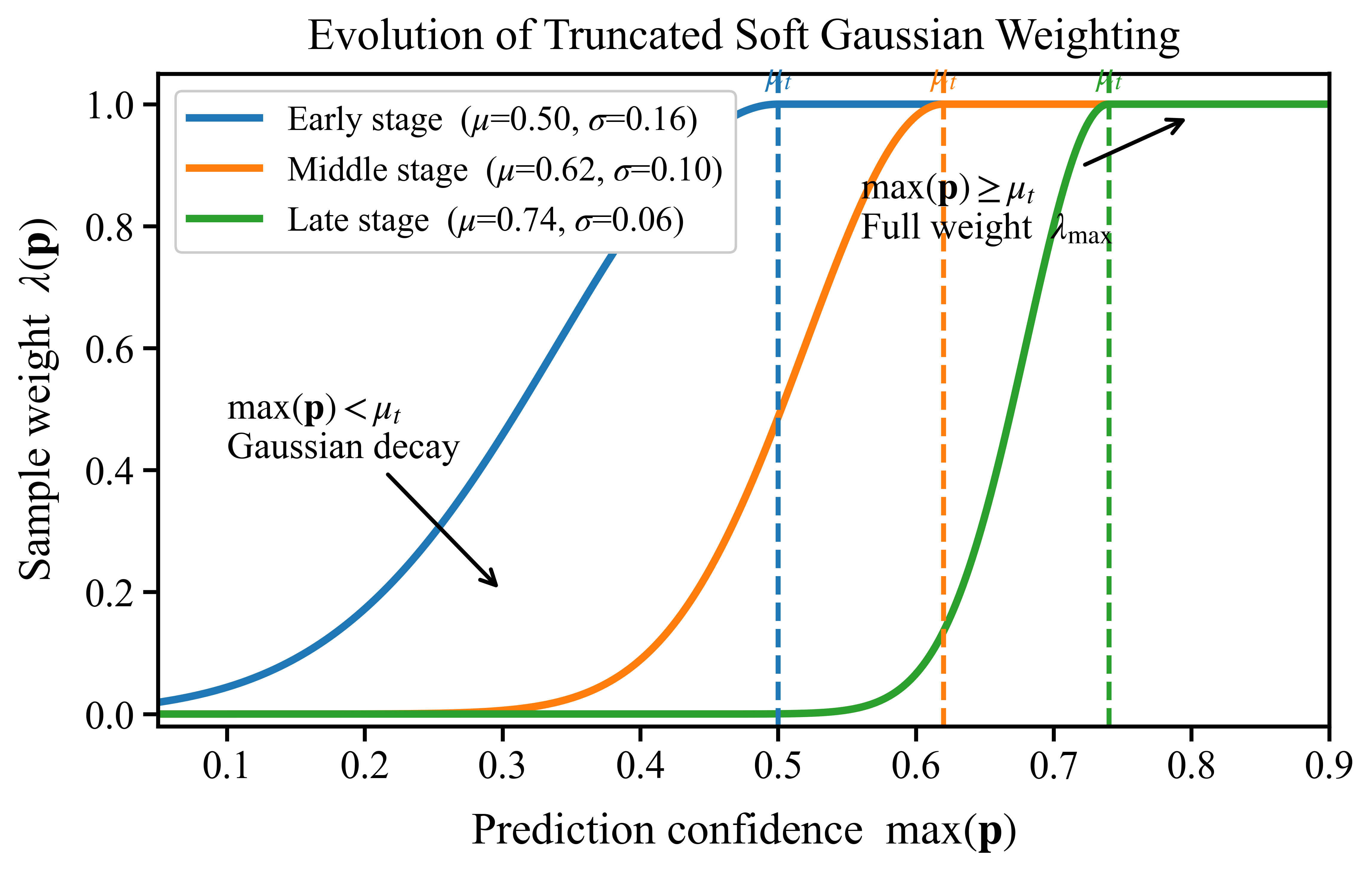
Handling imperfect guesses (confidence-aware weighting)
- For the new people’s data, the model doesn’t have true labels, so it makes guesses (pseudo-labels).
- Instead of throwing away low-confidence guesses, the model softly down-weights them using a smooth curve (a Gaussian). Imagine trusting your answers more when you’re sure, and trusting them less when you’re unsure—but not ignoring them completely. This keeps training stable and uses more of the available data.
Keeping things fair across emotions (uniform alignment)
- Models often predict some emotions (like “neutral”) more than others (“fear”), which can bias learning.
- The authors adjust the guessed class probabilities so each emotion gets a fair chance. Think of it like making sure the student practices all topics, not just the easy ones. This balancing helps the alignment work better and avoids favoring certain emotions.
Putting it all together
- The model learns from labeled data (source people) and unlabeled data (new people) at the same time.
- It optimizes: classification accuracy, overall alignment (MMD), and class-specific alignment (CMMD), while applying the confidence weighting and uniform balancing to the pseudo-labels.
What did they find and why does it matter?
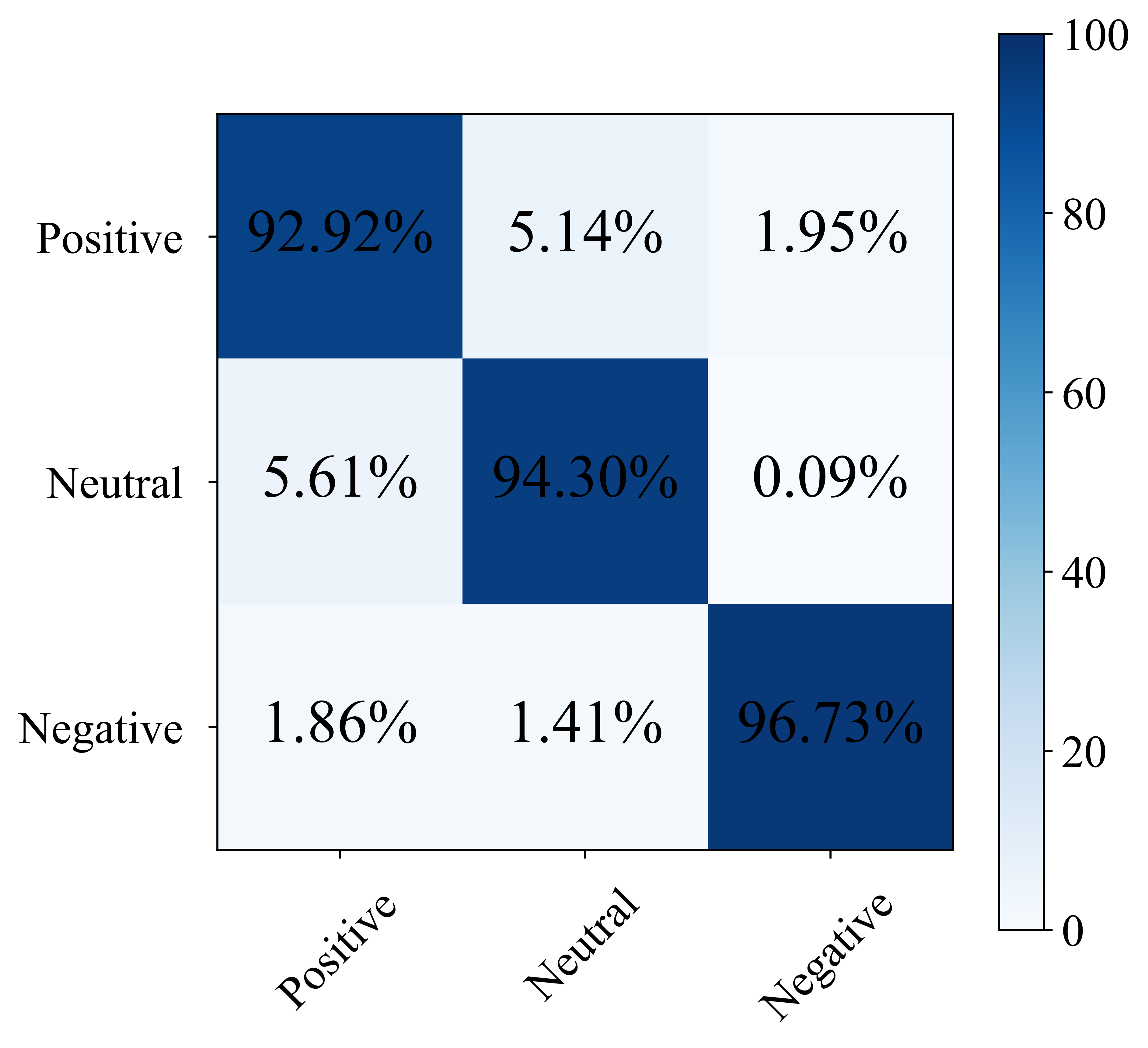
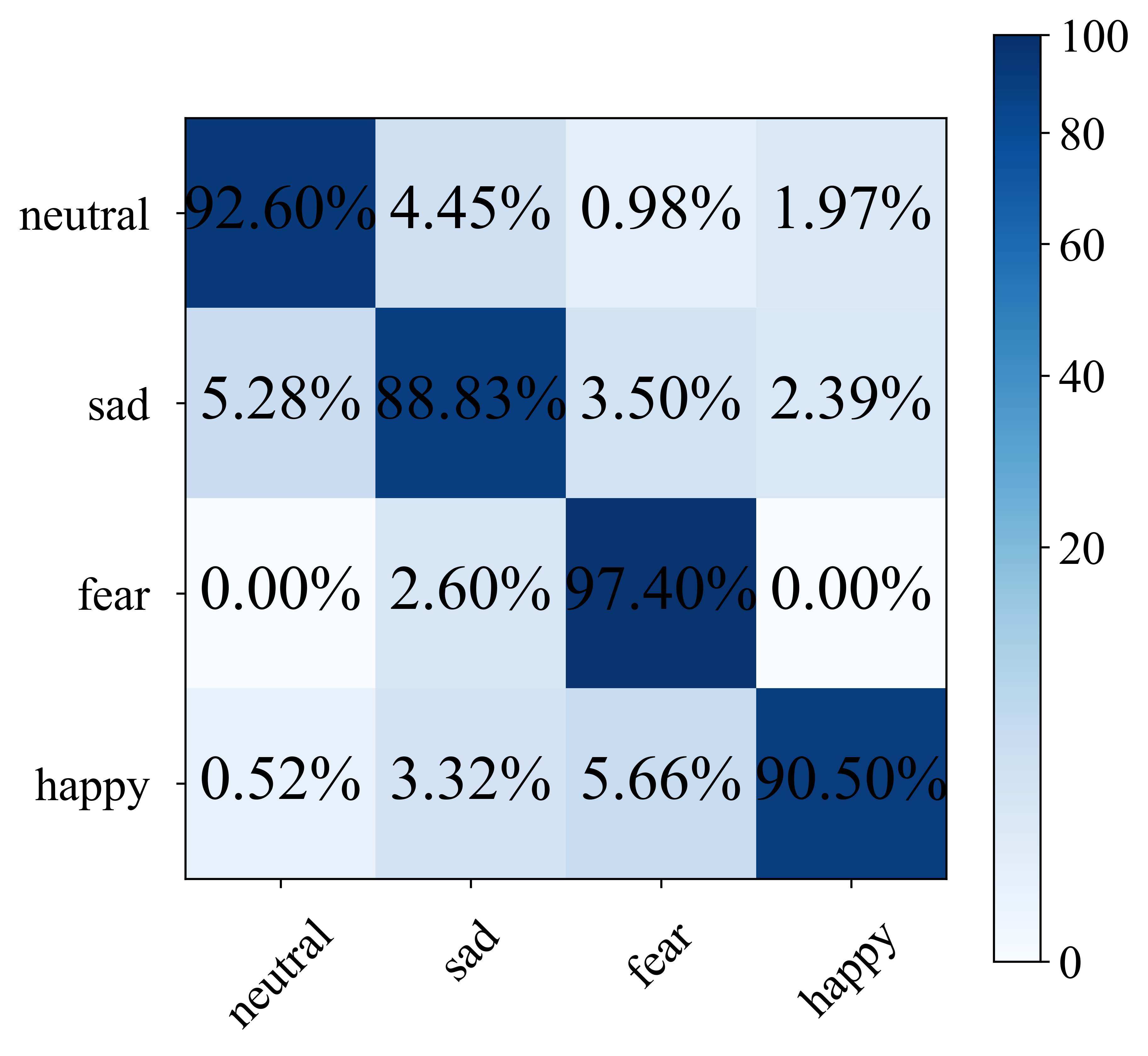
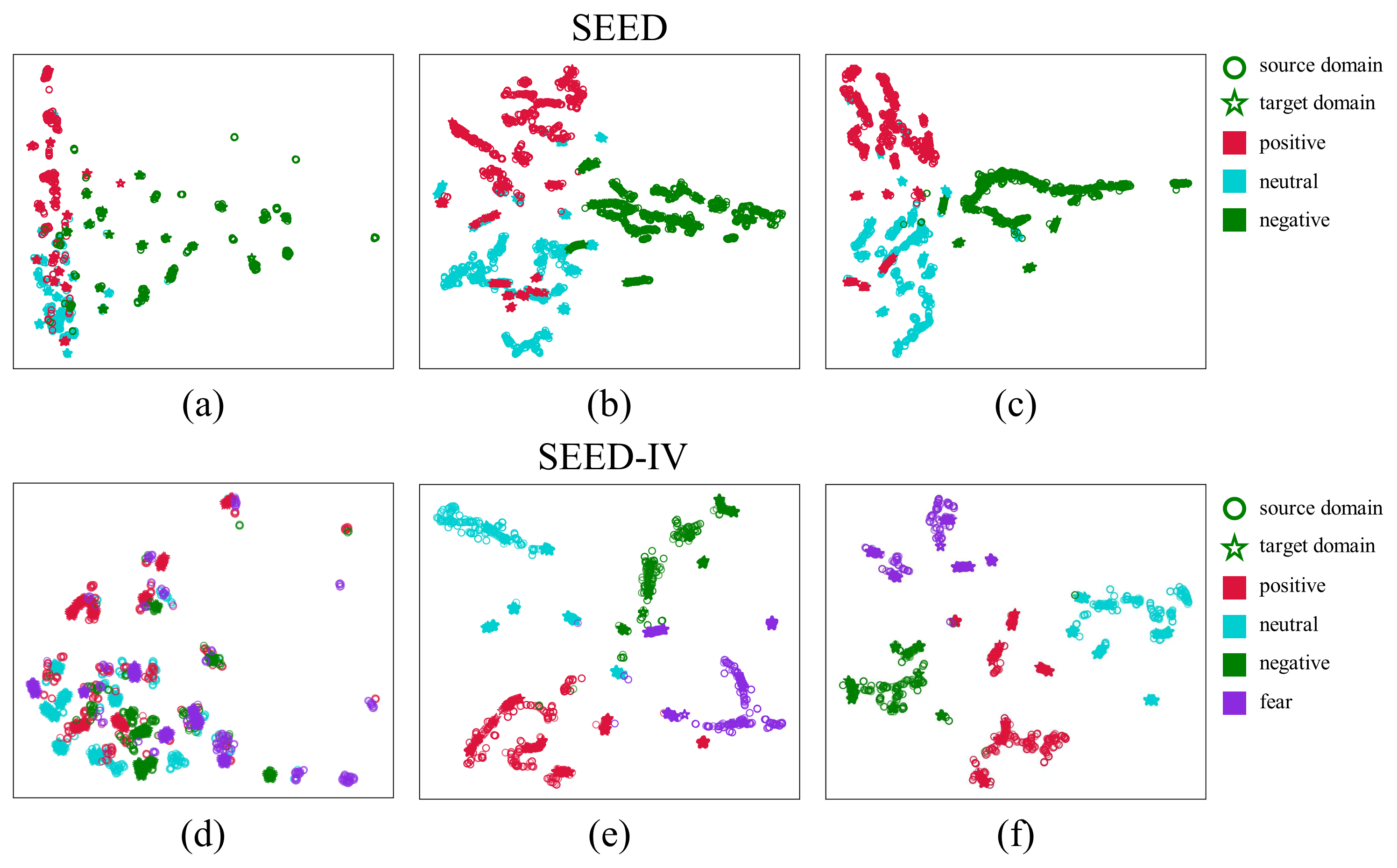
They tested HADUA on well-known emotion datasets (SEED and SEED-IV), which include brain and eye data from people watching emotion-inducing videos.
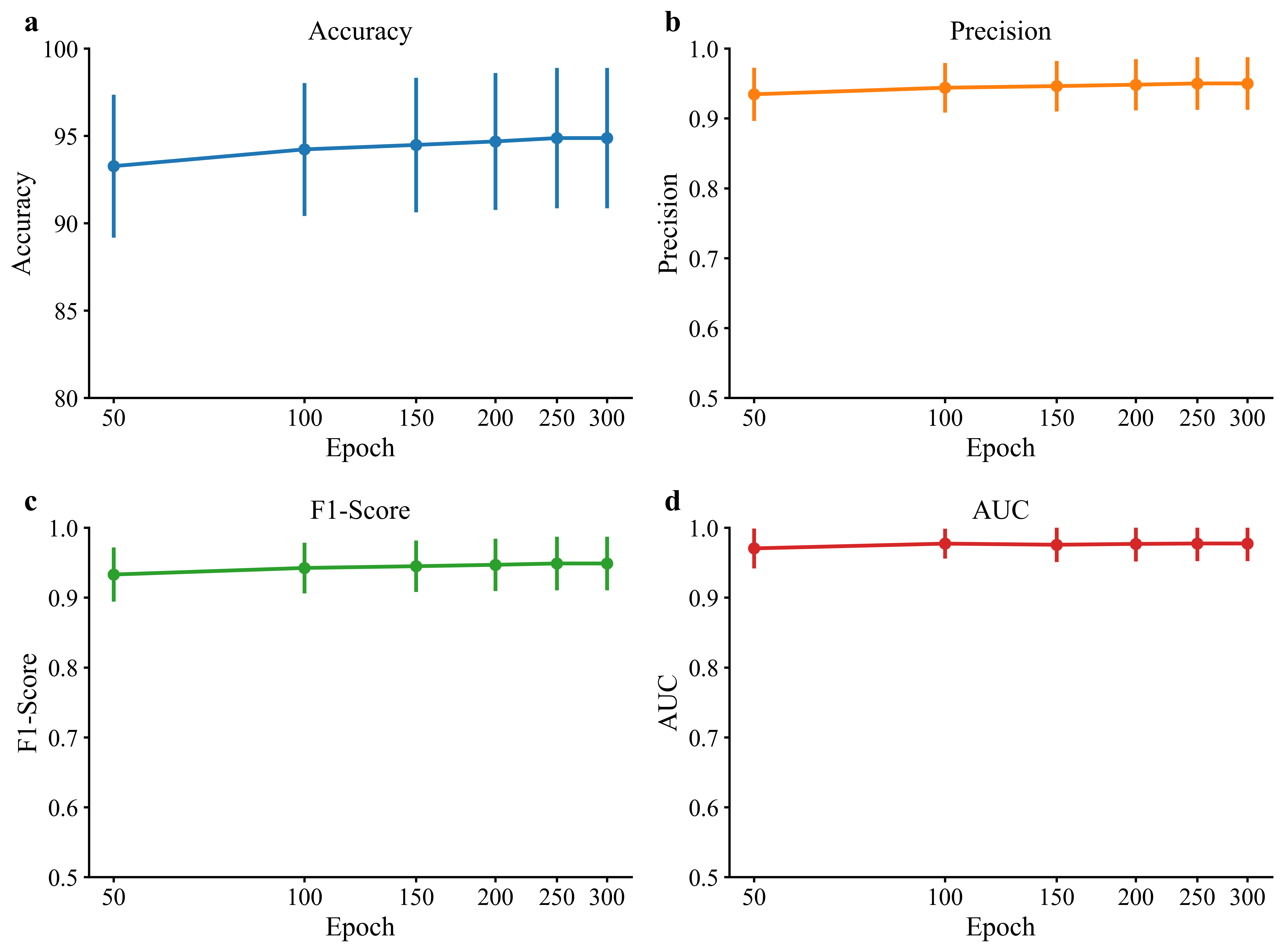
- On SEED, HADUA reached a very high ranking score (AUC 97.68%) and strong accuracy (~94.7%), showing it’s good at telling emotions apart and confident in its decisions.
- On SEED-IV, HADUA achieved top accuracy (~92.0%) and Macro-F1 (~92.9%), outperforming several advanced methods.
These results matter because:
- The model stays accurate when used on new people with different signal patterns.
- It handles noisy guesses and avoids over-relying on “easy” emotion classes.
- It uses both brain and eye signals effectively, gaining more reliable information than either alone.
What’s the impact?
This research helps build emotion-aware systems that work for many different people, not just those seen during training. That could improve:
- Mental health and wellbeing tools (e.g., detecting stress or mood changes)
- More responsive human-computer interfaces (e.g., games or tutors that adapt to how you feel)
- Safer, more empathetic technologies in cars or workplaces (e.g., noticing fatigue or frustration)
By combining smart attention (spotlights), careful alignment (making groups look similar), and fair pseudo-label handling, HADUA shows a practical path to robust emotion recognition across different people and situations.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what the paper leaves missing, uncertain, or unexplored, to guide future research.
- Evaluation scope and generalization
- No cross-dataset evaluation (e.g., train on SEED, test on SEED-IV/DEAP), leaving cross-dataset robustness and domain shift across different recording setups unexplored.
- DEAP is described but no results are reported; continuous affect (valence/arousal) or regression settings are not evaluated, limiting evidence to discrete-class benchmarks only.
- No analysis across sessions (cross-session adaptation) despite multi-session datasets; unclear performance stability across days or sessions.
- Limited classes/settings (3- and 4-class); scalability to more fine-grained or imbalanced emotion taxonomies is not examined.
- Lack of statistical significance testing and per-subject breakdowns; it is unclear whether improvements are consistent across subjects or driven by a subset.
- Methodological assumptions and theoretical clarity
- The confidence of pseudo-labels is assumed to follow a truncated Gaussian; this is not empirically validated nor theoretically justified across training stages or datasets.
- Uniform Alignment (UA) enforces batch-wise uniform class priors; behavior under class-prior shift (label shift) is not addressed and may induce mismatch if target priors are non-uniform in practice.
- CMMD relies on pseudo-label quality; there is no analysis of error propagation (confirmation bias) or theoretical bounds on the impact of mislabeling on conditional alignment.
- The lower-bound claim on expected sample weight under the Gaussian weighting scheme is stated but not derived or verified; sensitivity to initialization (μ0=1/C, σ0²=1.0) and EMA momentum is not analyzed.
- Design choices and ablations
- No ablation study isolating the contributions of (i) hierarchical self-attention, (ii) EEG→Eye cross-attention, (iii) Gaussian weighting, and (iv) UA to quantify each module’s effect.
- Cross-attention is unidirectional (EEG→Eye) based on modality dominance; alternatives (bidirectional, gating, or learned dominance) are not compared, leaving optimal interaction design unresolved.
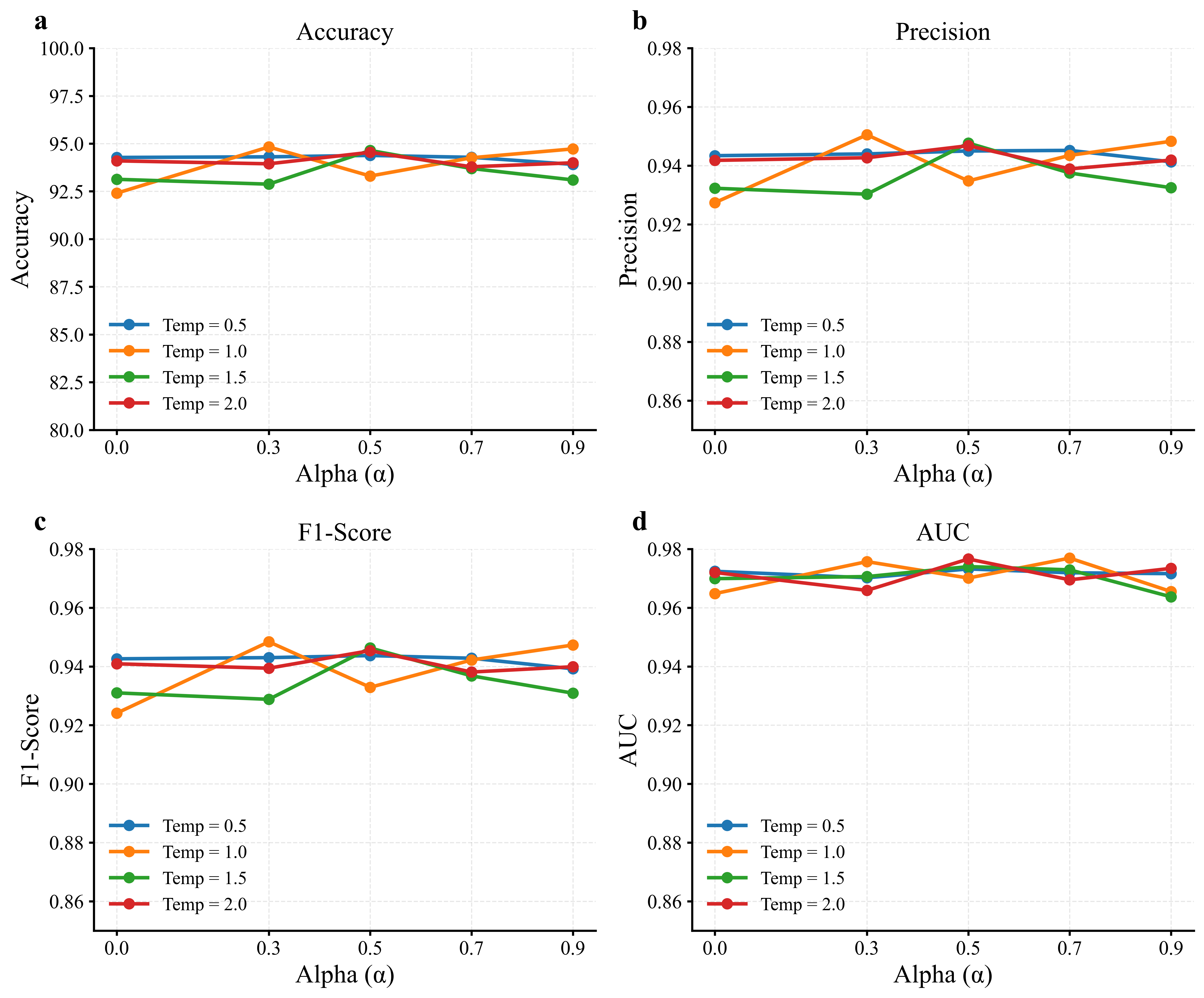
- Hyperparameters (γmmd, γcmmd, τ for UA, α schedule, kernel bandwidth σ for MMD/CMMD) lack sensitivity analyses, hindering understanding of stability and reproducibility.
- Robustness and practical considerations
- Assumes both EEG and EM are available and reliable; robustness to missing modalities, modality dropout, sensor failure, or asynchronous data is not tested.
- No robustness analysis to physiological or recording artifacts (e.g., eye blinks, muscle noise, EM illumination changes); preprocessing/denoising pipeline details and their impact are missing.
- Calibration of model confidence is not considered, despite reliance on confidence-based pseudo-label weighting and probability redistribution in UA; potential miscalibration effects are unquantified.
- Potential negative transfer under strong domain shifts or rare classes is not examined (e.g., when alignment harms discriminability).
- Real-time feasibility and computational cost (GRUs + attention + MMD/CMMD) are not reported; memory/time complexity for kernel computations in larger targets remains unclear.
- Implementation and reproducibility gaps
- Early stopping uses “validation accuracy,” but UDA settings lack target labels; the source/target or cross-validation strategy for early stopping is not specified, risking label leakage or unrealistic tuning.
- Details on time-windowing and alignment between EEG and EM (sampling rates, window size/stride, synchronization) are not provided, challenging replication and temporal consistency assessment.
- Kernel choice and bandwidth selection for MMD/CMMD are fixed without rationale or adaptive strategies; no comparison of different kernels or bandwidth tuning methods.
- Source code is promised post-publication; absence during review limits independent verification.
- Task and deployment realism
- The framework assumes access to unlabeled target-domain data for per-target adaptation; online/streaming adaptation or few-shot/semi-supervised variants are not explored.
- The approach enforces uniform class use; real-world deployments often face non-uniform priors; mechanisms to detect and adapt to changing priors are absent.
- Emotion labels are treated as mutually exclusive; multi-label/overlapping affective states and context dependency are not addressed.
- Interpretability and neurophysiological insight
- No analysis of attention maps or learned features to interpret modality contributions, temporal patterns, or neurophysiological correlates; interpretability and explainability remain open.
- Interaction between handcrafted EM features and learned representations is not examined; potential benefits of end-to-end learned EM features vs. handcrafted descriptors are unclear.
- Comparative and complementary methods
- No comparisons with adversarial domain adaptation or contrastive/self-supervised pretraining within the proposed architecture, leaving potential synergies unexplored.
- Data augmentation strategies (EEG/EM-specific augmentations) are not discussed, despite known benefits for UDA and pseudo-label robustness.
These gaps point to concrete next steps: cross-dataset/session studies (including DEAP continuous labels), ablations and hyperparameter sensitivity analyses, calibration-aware pseudo-labeling, adaptive handling of class-prior shift, robustness to missing/noisy modalities, interpretability analyses, and deployment-oriented evaluations (efficiency and online adaptation).
Practical Applications
Overview
HADUA introduces three practical innovations for cross-subject emotion recognition from multimodal physiological signals (EEG + eye movement): (1) hierarchical attention that models intra-modal dynamics and inter-modal guidance (EEG→eye), (2) multi-level domain adaptation (MMD + CMMD) that generalizes across subjects without target labels, and (3) confidence-aware Gaussian pseudo-label weighting with uniform alignment to stabilize training under noise and class imbalance. These elements enable plug-and-play affect sensing with reduced per-user calibration, a key barrier to deployment.
Below are actionable use cases and workflows organized by deployment horizon. Each bullet notes relevant sectors, candidate tools/products, and key assumptions or dependencies.
Immediate Applications
- Healthcare (Research): Cross-subject affect monitoring in clinical studies
- What: Use HADUA to measure emotional responses (e.g., valence/arousal proxies via discrete labels) across participants without per-subject calibration in studies of depression, anxiety, or stress.
- Tools/products/workflows: EEG+eye-tracking lab kits; PyTorch inference pipeline; research dashboards summarizing session-level emotion metrics; anonymized data logs for longitudinal analysis.
- Assumptions/dependencies: Controlled lab conditions; non-medical-research use (not a diagnostic); IRB/consent; EEG quality control and artifact handling; discrete emotion classes (SEED/SEED-IV-like) rather than continuous ratings.
- Education & Training (Labs/Classrooms): Engagement/workload-aware content adaptation in controlled settings
- What: Adjust difficulty or pacing in training modules or simulators based on cross-subject emotion/engagement signals without individual calibration sessions.
- Tools/products/workflows: Unity/Unreal plugin wrapping HADUA; LMS integration for adaptive sequencing; real-time streaming via LabStreamingLayer; small on-site GPU.
- Assumptions/dependencies: Availability of eye tracking and a comfortable EEG headband; privacy policy and opt-in consent; manageable latency (tens of ms to a few hundred ms).
- Automotive (Simulators & R&D): Driver state monitoring in simulators
- What: Detect stress/fatigue states across drivers during simulator-based testing with minimal re-calibration.
- Tools/products/workflows: Dry-electrode EEG headbands + eye trackers; simulator SDK integration; real-time inference server with online adaptation.
- Assumptions/dependencies: Motion and EMG artifact suppression; not safety-certified; mostly suitable for research/simulation, not production vehicles.
- UX/Market Research: Emotion analytics for product/media testing
- What: Quantify user emotional reactions to interfaces, ads, or media across diverse users, avoiding per-user calibration.
- Tools/products/workflows: Portable lab workflow (EEG headband + eye tracker), session orchestration scripts, batch inference, participant-level reports (accuracy/AUC/Macro-F1).
- Assumptions/dependencies: Lab-like stimulus control; strong privacy safeguards; mapping from predicted discrete categories to business-relevant KPIs.
- VR/AR (R&D, Labs): Affect-aware experiences in head-mounted systems
- What: Dynamically adjust scene intensity, haptics, or guidance based on cross-subject emotion signals in VR/AR experiments.
- Tools/products/workflows: SDK for HMDs with eye tracking; optional add-on EEG headband; on-headset or edge inference; event hooks for adaptive content.
- Assumptions/dependencies: Integration with device SDKs; computational budget on device or edge; user comfort with wearing EEG gear.
- Software/AI Tooling (Academia & Industry): A general-purpose multimodal domain adaptation SDK
- What: Reuse HADUA’s hierarchical attention + (C)MMD + confidence-weighted pseudo-labeling for other biosignal tasks (e.g., EEG+ECG, EEG+EDA).
- Tools/products/workflows: Open-source PyTorch package; pretrained baselines on SEED/SEED-IV; recipe scripts for unsupervised domain adaptation; ablation notebooks.
- Assumptions/dependencies: Availability of labeled source and unlabeled target data; modality-specific feature extractors; consistent preprocessing (e.g., DE features for EEG).
- Human Factors/Ergonomics: Cross-subject affect tracking in safety-critical task trials
- What: Evaluate operator stress and emotional load in lab trials (e.g., air-traffic control simulators, complex UI testing) without per-operator calibration.
- Tools/products/workflows: Lab hardware kits; time-synced logs; experiment-control system integration; aggregated analytics per scenario.
- Assumptions/dependencies: High-quality sensors; ethics approval; result interpretation by domain experts.
- Policy & Standards (Near-term Guidance): Procurement and evaluation guidelines for emotion-AI pilots
- What: Use HADUA’s cross-subject protocol as a template for assessing generalization, pseudo-label confidence auditing, and class balance in pilots.
- Tools/products/workflows: Evaluation checklists; benchmark scripts on public datasets; reporting templates for fairness and robustness metrics.
- Assumptions/dependencies: Pilot scope limited to research; attention to consent and data minimization; no decision automation without human oversight.
Long-Term Applications
- Healthcare (Clinical): Emotion-aware decision support and digital therapeutics
- What: Continuous, cross-subject monitoring of mood/affect for relapse detection (e.g., MDD, anxiety), and closed-loop interventions (e.g., neurofeedback).
- Tools/products/workflows: Regulated wearable EEG + eye-tracking devices; EHR-integrated dashboards; adaptive therapeutic content.
- Assumptions/dependencies: Clinical validation across demographics; device-grade robustness; regulatory clearance; transition from discrete to continuous affect modeling.
- Automotive (Production): In-vehicle driver monitoring systems at scale
- What: Real-time, cross-subject emotion/fatigue detection integrated with ADAS for safety and comfort personalization.
- Tools/products/workflows: Embedded inference optimized for automotive SoCs; dry EEG integrated in headrests or headbands, plus eye tracking; OTA adaptation.
- Assumptions/dependencies: Hardware acceptance by consumers; rigorous validation in the wild; robustness to vibration and lighting; failsafe design.
- Education (At Scale): Affective tutoring systems
- What: Broad deployment of emotion-aware digital tutors that adapt difficulty and feedback to learner state across users and contexts.
- Tools/products/workflows: Edge inference on laptops/AR glasses; class-level dashboards for instructors; privacy-preserving analytics.
- Assumptions/dependencies: Sensor availability in schools; strong privacy and parental consent frameworks; equitable performance across populations.
- Social Robotics & HRI: Robots that generalize emotion perception across users
- What: Home/assistive robots that interpret and respond to human emotion without individual calibration.
- Tools/products/workflows: Onboard multimodal sensing; optimized HADUA with missing-modality resilience; behavior planners conditioned on affect.
- Assumptions/dependencies: Reliable, comfortable sensors; on-device compute; social acceptability and safety standards.
- Workplace Well-being & Occupational Safety: Passive affect monitoring with opt-in consent
- What: Longitudinal monitoring of stress/affect to inform interventions and reduce burnout in high-load roles.
- Tools/products/workflows: Opt-in wearables; aggregated, de-identified analytics; HR dashboards with thresholds and alerts.
- Assumptions/dependencies: Ethical deployment policies; strict governance and anonymization; avoidance of punitive use.
- Telehealth & Remote Care: Home-based affect tracking for triage and follow-up
- What: Remote assessment of emotional states to prioritize care and personalize follow-ups.
- Tools/products/workflows: Consumer-grade EEG headbands + camera/eye tracking; secure app; clinician review workflows.
- Assumptions/dependencies: Reliable at-home sensing; cross-device generalization; reimbursement and regulatory frameworks.
- Entertainment & Gaming: Real-time affect-driven gameplay and media personalization
- What: Games and media that adapt narrative arcs, difficulty, or soundtrack to user emotion across different players.
- Tools/products/workflows: Game engine plugins; user consent flows; performance monitoring for latency and stability.
- Assumptions/dependencies: Comfortable, low-friction sensors; acceptable latency; standardized APIs across devices.
- Privacy-Preserving Edge AI: Federated or on-device adaptation for emotion models
- What: Edge deployment with local domain adaptation to protect privacy while maintaining cross-subject robustness.
- Tools/products/workflows: Federated learning pipelines; on-device (C)MMD and confidence-weighting; secure enclaves.
- Assumptions/dependencies: Algorithmic adaptation to limited compute; robust on-device calibration; privacy-by-design compliance.
- Cross-Modal Generalization & Missing-Modality Robustness: Beyond EEG+Eye
- What: Extend HADUA to other biosignals (ECG, EDA, respiration) and to scenarios where a modality is intermittently unavailable.
- Tools/products/workflows: Modular encoders; mixture-of-experts heads; training recipes for modality dropout.
- Assumptions/dependencies: Access to multi-sensor datasets; careful tuning of attention routing and alignment losses.
- Policy & Regulation: Standards and certifications for emotion-AI systems
- What: Define benchmarks for cross-subject performance, pseudo-label auditing, and class-balance controls; certification schemes for safety-critical use.
- Tools/products/workflows: Open test suites; documentation standards for confidence weighting and uniform alignment; bias and fairness evaluations.
- Assumptions/dependencies: Multi-stakeholder consensus; legislative clarity on emotion AI; alignment with medical and automotive standards where applicable.
Cross-Cutting Assumptions and Dependencies
- Sensors and data quality: Access to reliable EEG (consumer dry electrodes may reduce SNR vs 62-channel lab systems) and eye tracking; robust preprocessing (artifact rejection, differential entropy features).
- Label space and ecological validity: Current validation on discrete emotions (SEED/SEED-IV); real-world deployment may require continuous valence–arousal and domain-specific taxonomies.
- Compute and latency: Attention-based models are feasible on modern edge GPUs; real-time constraints demand optimization and batching strategies.
- Data governance: Strong privacy, consent, and transparency practices are essential; pseudo-labeling and adaptation must be logged and auditable.
- Generalization boundaries: Cross-subject adaptation assumes availability of labeled source data and unlabeled target streams; large domain shifts (different devices, cultural contexts) may require additional fine-tuning or re-training.
- Ethics and fairness: Regular audits for demographic performance parity; avoid high-stakes automated decisions without human oversight.
Glossary
- Adam optimizer: Adaptive moment estimation optimizer used to train neural networks efficiently. "parameters are updated via the Adam optimizer."
- Affective computing: Field focused on computational recognition and response to human emotions. "robust cross-subject affective computing systems."
- Attention-based fusion: Technique that integrates modalities by weighting features via attention mechanisms. "attention-based fusion-which achieve certain success under single-subject or controlled conditions"
- Canonical Correlation Analysis (CCA): Statistical method that finds maximally correlated projections between two sets of variables. "CCA-based methods"
- Class imbalance: Uneven distribution of samples across classes that biases training and evaluation. "pseudo-labels in the target domain often exhibit severe class imbalance"
- Conditional MMD (CMMD): Kernel-based distance used to align class-conditional distributions across domains. "Conditional MMD (CMMD)"
- Conditional probability distributions (CPD): Probability distributions of data conditioned on class labels. "align the Conditional Probability Distributions (CPD), specifically and "
- ConvLSTM: Convolutional Long Short-Term Memory for modeling spatiotemporal sequences. "incorporating ConvLSTM"
- Cross-attention: Mechanism where one representation queries another to integrate complementary information. "introduce a cross-attention mechanism"
- Cross-modal attention: Attention modeling interactions between different modalities. "cross-modal attention mechanisms"
- Cross-subject adaptation: Adapting models to new subjects to handle inter-subject distribution differences. "under cross-subject adaptation frameworks"
- Differential entropy: Entropy measure for continuous variables quantifying distribution uncertainty. "Differential entropy is a continuous analog of the discrete Shannon entropy"
- Domain adaptation: Techniques to transfer knowledge from a labeled source to an unlabeled target domain. "unifies the learning of multimodal representations with domain adaptation."
- Domain shift: Change in data distribution between training and deployment domains. "under domain shifts"
- EEG (electroencephalogram): Brain electrical activity measured via scalp electrodes. "electroencephalogram (EEG) signals"
- EM (eye movement): Signals capturing ocular behavior including fixations and saccades. "eye movement (EM)"
- Exponential Moving Average (EMA): Running average that emphasizes recent values for stable statistics. "exponential moving averages (EMA)"
- Gaussian kernel: Radial basis function kernel used in kernel methods and MMD. "denotes the Gaussian kernel"
- Hierarchical attention: Layered attention that models intra- and inter-modality dependencies. "hierarchical attention module that explicitly models intra-modal temporal dynamics and inter-modal semantic interactions"
- i.i.d. assumptions: Independent and identically distributed assumptions underlying many models. "independent and identically distributed (i.i.d.) assumptions"
- Maximum Mean Discrepancy (MMD): Kernel-based divergence measuring differences between distributions. "Maximum Mean Discrepancy (MMD)"
- Mixture-of-experts: Architecture combining multiple specialized models with gating for fusion. "a mixture-of-experts framework"
- Multi-head attention (MHA): Attention with multiple parallel heads capturing diverse relationships. "Transformer-style multi-head attention (MHA)"
- Probability density function (PDF): Function describing likelihoods of continuous variable values. "the probability density function (PDF) of the signal amplitude was calculated."
- Pseudo-labels: Model-generated labels for unlabeled target data used for training. "pseudo-labels in the target domain"
- Rectified Linear Unit (ReLU): Activation function defined as max(0, x). "ReLU activation"
- Reproducing Kernel Hilbert Space (RKHS): Hilbert space induced by a kernel for embedding distributions. "Reproducing Kernel Hilbert Space (RKHS)"
- Saccade: Rapid eye movement between fixation points. "saccade features are computed"
- Self-attention: Mechanism that models dependencies within the same sequence or modality. "apply self-attention within each modality"
- Short-time Fourier transform (STFT): Time-frequency analysis via localized Fourier transforms. "the short-time Fourier transform (STFT) was employed"
- Soft Gaussian Weighting: Confidence-based weighting using a truncated Gaussian to scale pseudo-labels. "Soft Gaussian Weighting"
- Stochastic Gradient Descent (SGD): Optimization method using gradient steps on mini-batches. "Stochastic Gradient Descent"
- Tensor fusion: Fusion strategy using tensor products to capture cross-modal interactions. "tensor fusion"
- Transfer learning: Leveraging knowledge from one domain/task to improve performance in another. "transfer learning and domain adaptation methods have been widely adopted"
- Uniform Alignment (UA): Mechanism encouraging balanced pseudo-label distributions across classes. "Uniform Alignment mechanism"
- W-distance: Distance metric (often Wasserstein) for comparing probability distributions. "W-distance are used"
Collections
Sign up for free to add this paper to one or more collections.

