- The paper presents DFSU, a novel framework that removes memorized PII from LLMs without relying on original training data.
- It employs a three-stage process—comprising inversion model training, pseudo-PII synthesis, and privacy-selective contrastive unlearning—to achieve zero ERR and minimal utility loss.
- The method demonstrates data efficiency and robust performance across model scales, matching oracle unlearning results while safeguarding general model utility.
Data-Free Selective Unlearning for LLM Privacy: The DFSU Framework
Problem Landscape and Motivation
The proliferation of LLMs has intensified concerns regarding the inadvertent memorization and leakage of personally identifiable information (PII) from training corpora. Current machine unlearning methods—critical for enforcing regulations like the "Right to be Forgotten"—are hindered by their dependence on access to original training data, which is often proprietary or irretrievable. This data dependency fundamentally limits the practical applicability of existing exact and approximate unlearning strategies, such as Gradient Ascent (GA), Negative Preference Optimization (NPO), and model-editing methods, in realistic deployment contexts where only model weights are available.
Data-Free Selective Unlearning (DFSU) redefines the operational assumptions of the privacy preservation problem by focusing on erasing PII from LLMs without any access to the original sensitive data. The core technical challenge is to construct a surrogate forgetting signal that is both effective in removing memorized PII and highly localized, thus avoiding unnecessary collateral damage to general model utility.
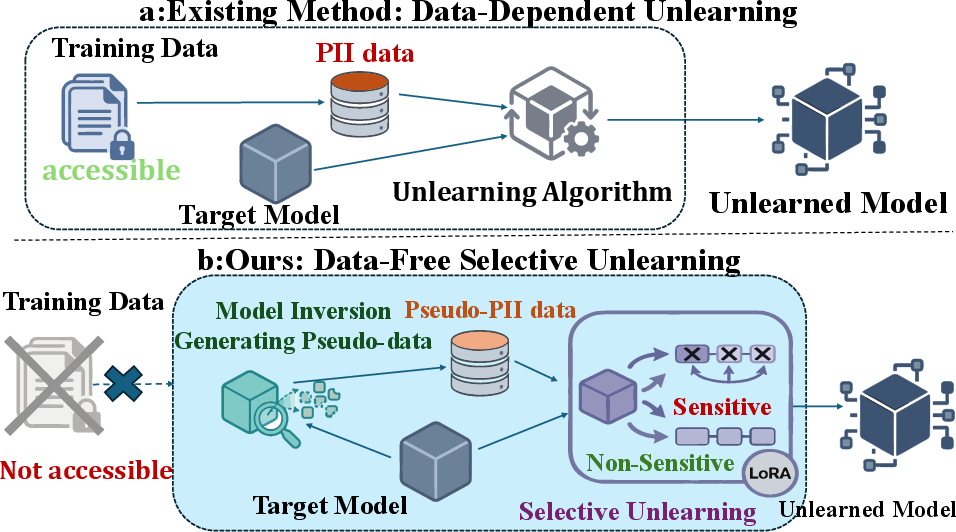
Figure 1: Conceptual comparison of data-dependent unlearning (left) and the proposed data-free selective unlearning (right).
Methodological Advances
Three-Stage DFSU Pipeline
The DFSU framework ingeniously leverages model inversion attacks—a canonical adversarial technique—as a defense mechanism to synthesize pseudo-sensitive samples, thus constructing an effective surrogate for the unavailable forget set. The method is instantiated in three algorithmic stages:
- Inversion Model Training: The framework employs a logit-based inversion model (sequence-to-sequence transformer), mapping output probability distributions from the target LLM to their corresponding input texts. The inversion model is trained to maximize text reconstruction quality, achieving F1 > 30% and BLEU > 15%, thereby ensuring pseudo-PII samples that meaningfully capture the distributional support of the target's memorized PII.
- Pseudo-PII Synthesis and Annotation: Starting from publicly known syntactic templates, entities are swapped for random, disjoint alternatives, and the target LLM’s internal logits are decoded by the inverter to generate pseudo-PII. Few-shot prompting is then applied for token-level privacy annotation, providing fine-grained privacy masks necessary for selective loss maximization.
- Privacy-Selective Contrastive Unlearning (PSCU): With annotated pseudo-PII, DFSU freezes base model weights and confines updates to LoRA adapters in the MLP subspace. The unlearning loss is decomposed: a privacy loss maximized over masked entity tokens and a utility loss minimized over non-sensitive context, governed by a dual-objective (contrastive) loss. This localizes optimization to privacy-relevant dimensions, reducing overfitting and undesirable degradation of linguistic or reasoning proficiency.
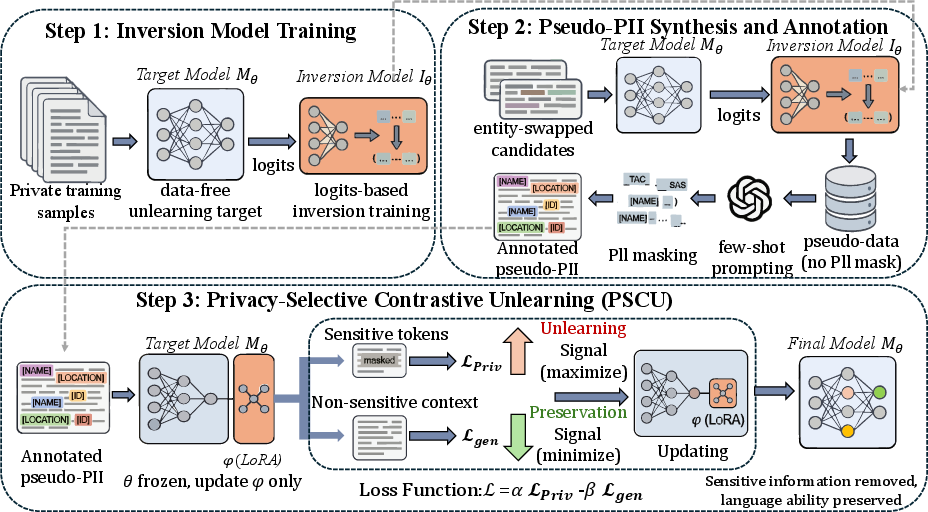
Figure 2: High-level overview of the DFSU pipeline, showing inversion-based pseudo-PII generation, annotation, and selective unlearning.
Experimental Findings
Evaluations utilize the AI4Privacy PII-Masking benchmark with Pythia LLMs (160M/410M/1.4B) and involve both generative (WikiText-103) and NLU (MNLI) tasks.
- Privacy metrics: Exact Reconstruction Rate (ERR), Fractional Reconstruction Similarity (FRS), Sample-Level Exposure Rate (S-Exp), Entity-Level Hit Rate (E-Hit).
- Utility metrics: Perplexity (PPL) for WikiText, accuracy for MNLI.
On both injected and production-like settings, DFSU consistently achieves zero ERR across all model scales and scenarios, matching oracle (data-dependent) unlearning on the strictest privacy leakage metric, while FRS, S-Exp, and E-Hit remain comparable or close. Model utility is well-preserved: e.g., on Pythia-410M (WikiText), PPL increases minimally (oracle: 8.69, DFSU: 8.83). For MNLI, accuracy drops are marginal (oracle: 69.9%, DFSU: 68.45%).
Ablations underscore the superiority of PSCU over naive GA: PSCU delivers nearly complete privacy erasure with graceful utility decay, while GA induces catastrophic utility collapse for similar privacy removal. LoRA target module studies reveal that privacy suppression is largely architecture-invariant, while task-specific utility is sensitive to the subspace of adaptation; MLP-only adaptation offers a Pareto-optimal privacy-utility configuration.
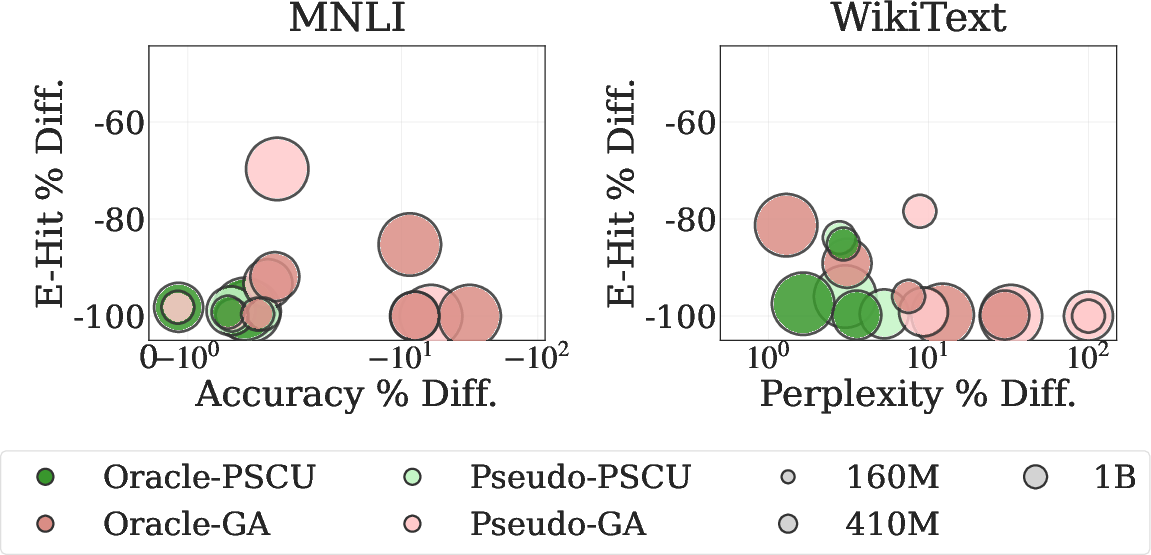
Figure 3: Privacy-utility trade-off: PSCU (green) vs. GA (pink) across model scales and scenarios; PSCU yields superior Pareto frontier.
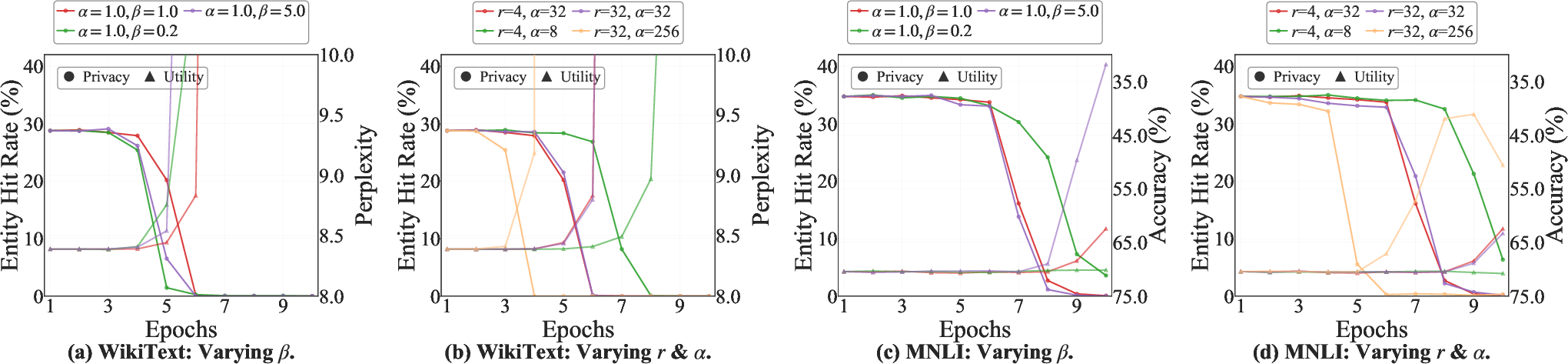
Figure 4: Privacy-utility trajectories as a function of privacy weight β and LoRA configuration for WikiText and MNLI.
Further, DFSU exhibits early privacy saturation and late utility recovery: privacy leakage is nearly eliminated with as few as 100 pseudo-samples, but utility steadily improves with increased surrogate data volume. This empirically demonstrates that the memorization footprint is low-dimensional, while generalization relies on richer support.
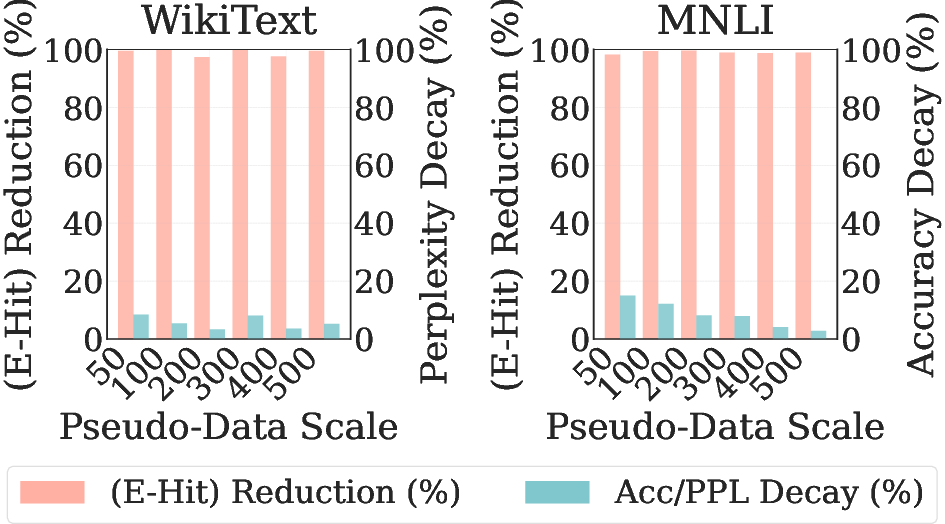
Figure 5: Data efficiency benchmarking shows rapid privacy removal (pink, higher is better) and gradual utility retention (blue, lower is better) as pseudo-set size grows.
Implications and Theoretical Significance
DFSU represents a decisive advance for post-hoc LLM privacy remediation under highly restrictive conditions, setting a high bar for the privacy-utility Pareto frontier in the data-free regime. Its methodological core—using inversion-based pseudo-PII coupled with token-localized, parameter-efficient contrastive masking—resolves key theoretical obstacles in selective unlearning by eliminating the access-to-sensitive-data assumption. Importantly, the findings demonstrate that privacy removal can be decoupled from catastrophic forgetting of non-sensitive distributions, provided that gradient signals are localized and the optimization subspace is appropriately constrained.
The uniform privacy outcome across LoRA modules implies, at least empirically, that sensitive entity memorization may be spatially localized within the LLM parameterization in a manner amenable to selective, minimal intervention. This provides further impetus to investigate the geometry of memorization and erasure within transformer models.
Limitations and Future Directions
The principal limitation is the need for white-box access to model logits, which restricts DFSU’s deployment to settings where such access is possible (excluding true black-box scenarios). Also, the quality of pseudo-PII synthesis is contingent on effective inversion; any domain or entity with poor inversion support may see degraded privacy targeting.
Extensions could involve improved inversion techniques, adversarial surrogate search for broader coverage, and ports to black-box model editing settings, possibly by exploiting output sensitivity or side-channel exposures. Future work should formalize theoretical guarantees for privacy removal and analyze the spatial alignment between surrogate-targeted and real PII representations.
Conclusion
DFSU advances privacy-preserving LLM deployment by introducing a robust data-free framework, integrating inversion-based pseudo-data construction with token-selective unlearning in a parameter-efficient adaptation space. It achieves strong empirical privacy removal with negligible utility penalties, providing a practicable template for privacy mitigation in real-world, post-hoc settings devoid of training data access.

