- The paper introduces a novel unlearning method that uses visual knowledge distillation to selectively erase entity-specific visual data while preserving textual content.
- It employs partial fine-tuning of the visual encoder with neuron pruning and weight masking, reducing unlearning time by over 50% compared to full-model fine-tuning.
- Experimental results on benchmarks like MLLMU-Bench show robust privacy compliance, high retention of non-target knowledge, and strong resistance to relearning attacks.
Machine Unlearning for MLLMs via Visual Knowledge Distillation
Motivation and Problem Definition
Privacy legislation such as GDPR and CCPA necessitates mechanisms for the effective removal of sensitive training data from large pre-trained models, especially in domains where high-dimensional multimodal representations may unintentionally store and propagate private or copyrighted content. While machine unlearning (MU) has been advanced for LLMs, the selective removal of entity-specific knowledge from Multimodal LLMs (MLLMs)—especially disentangling and erasing visual knowledge independent of textual attributes—remains an open technical challenge.
Prior studies indicate the visual encoder and its associated projection layers mainly encode entity identification, while the frozen LLM module is the locus of semantic extraction and textual attribution. This work adopts the selective unlearning paradigm of erasing visual knowledge for target entities while strictly preserving textual knowledge, and proposes a machine unlearning algorithm operating exclusively at the visual module level, leveraging direct intermediate representation supervision.
Methodology
The proposed framework for MLLM machine unlearning introduces Visual Knowledge Distillation (VKD), fundamentally diverging from output-level supervision approaches. The VKD mechanism distills intermediate visual representations from a teacher model into the student model undergoing unlearning, thereby providing granular supervision directly at the locus of stored visual knowledge. The method operates by:
- Partial Fine-Tuning: Only the visual encoder and projector are trainable to erase visual knowledge, with the LLM backbone strictly frozen to preserve textual information content.
- Selective Forgetting: Combination of neuron pruning and weight saliency masking strategies, localized to the vision module's MLP layers, especially the deeper layers most correlated with high-level visual concepts.
- Composite Objective: An optimization function integrating negative VQA loss for the forgetting dataset, positive QA losses, and an auxiliary VKD term controlled via hypertension parameters α (forgetting/preserving trade-off) and β (VKD strength).
The technical formulation is constructed to maximize efficiency and robustness, minimizing unlearning time by restricting parameter updates and enhancing the retention of non-target visual knowledge via representation distillation signals unavailable in conventional output-based approaches.
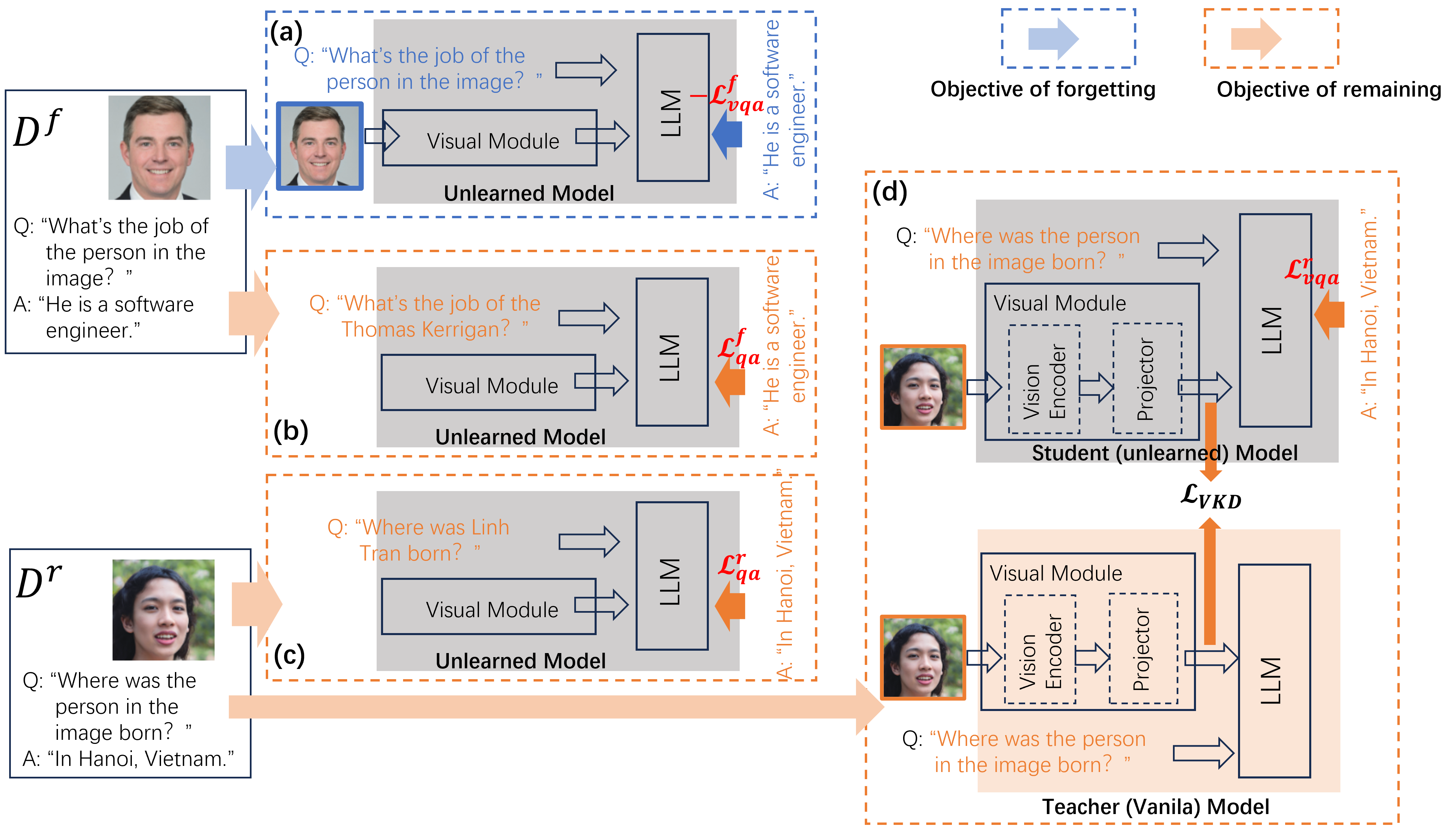
Figure 1: Overview of the MLLM machine unlearning architecture highlighting visual knowledge distillation and selective knowledge retention/erasure objectives.
Experimental Results
Effectiveness
Comprehensive evaluation on MLLMU-Bench and CLEAR demonstrates that the proposed VKD-centric unlearning paradigm achieves the strongest reduction in target entity visual identification, yielding the lowest Forget VQA accuracy on LLaVA-7B and Qwen2-VL (1.4–3.5 pp improvement). This acutely outperforms strong baselines including MMUnlearner and MANU. Notably, textual knowledge retention—measured by Question Answering metrics—is maintained at baseline or superior levels, confirming the effectiveness of module freeze and disentanglement.
Utility Preservation Trade-offs
Qualitative and quantitative trade-offs between knowledge forgetting and utility retention are modulated via α and β.
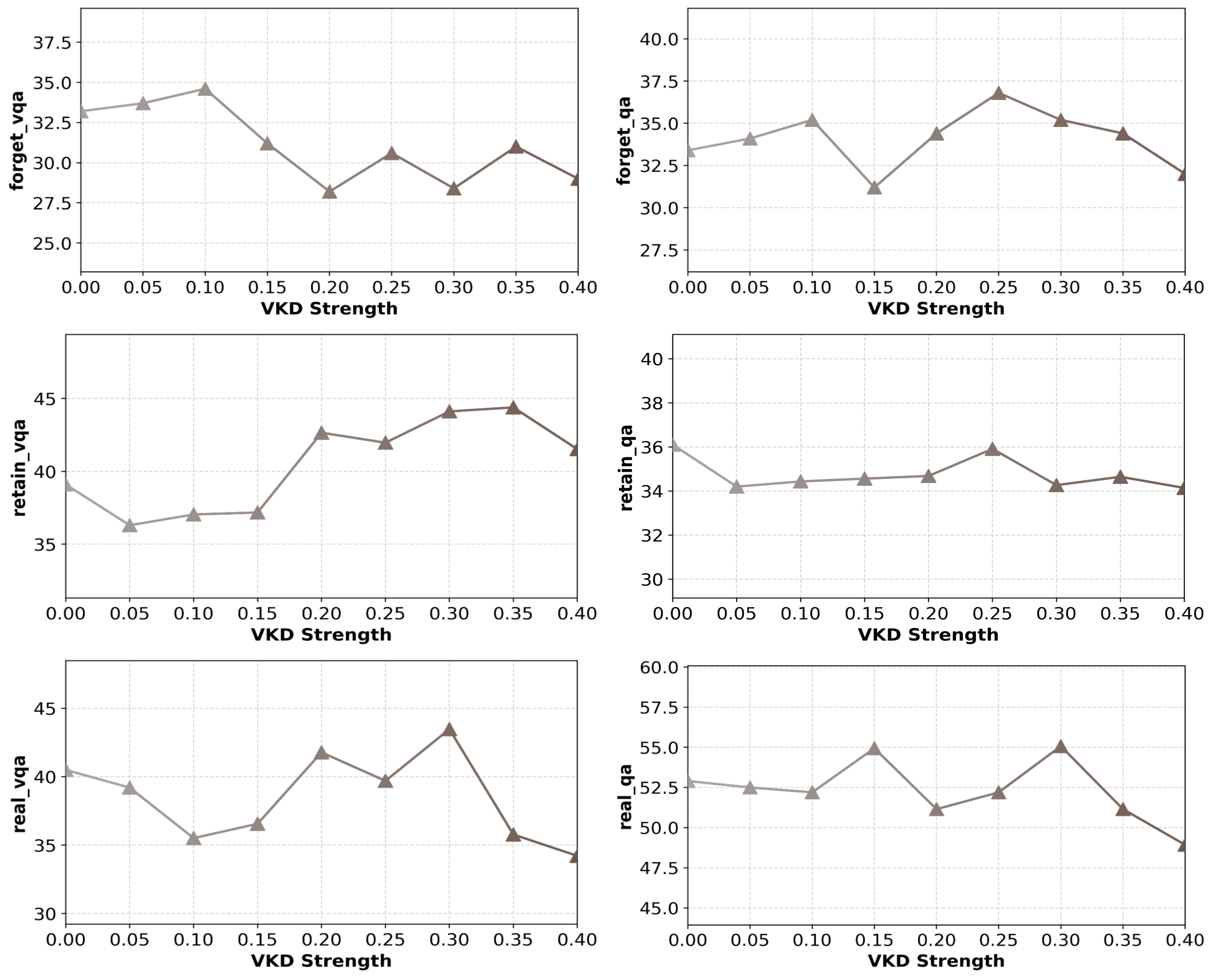
Figure 2: Influence of VKD strength (β) on the trade-off between output objectives and visual knowledge retention.
Tuning β validates that VKD enables pronounced restoration of non-target visual classification while preventing regrowth of target visual knowledge; excessive VKD does degrade general model utility, emphasizing the need for careful parameterization.
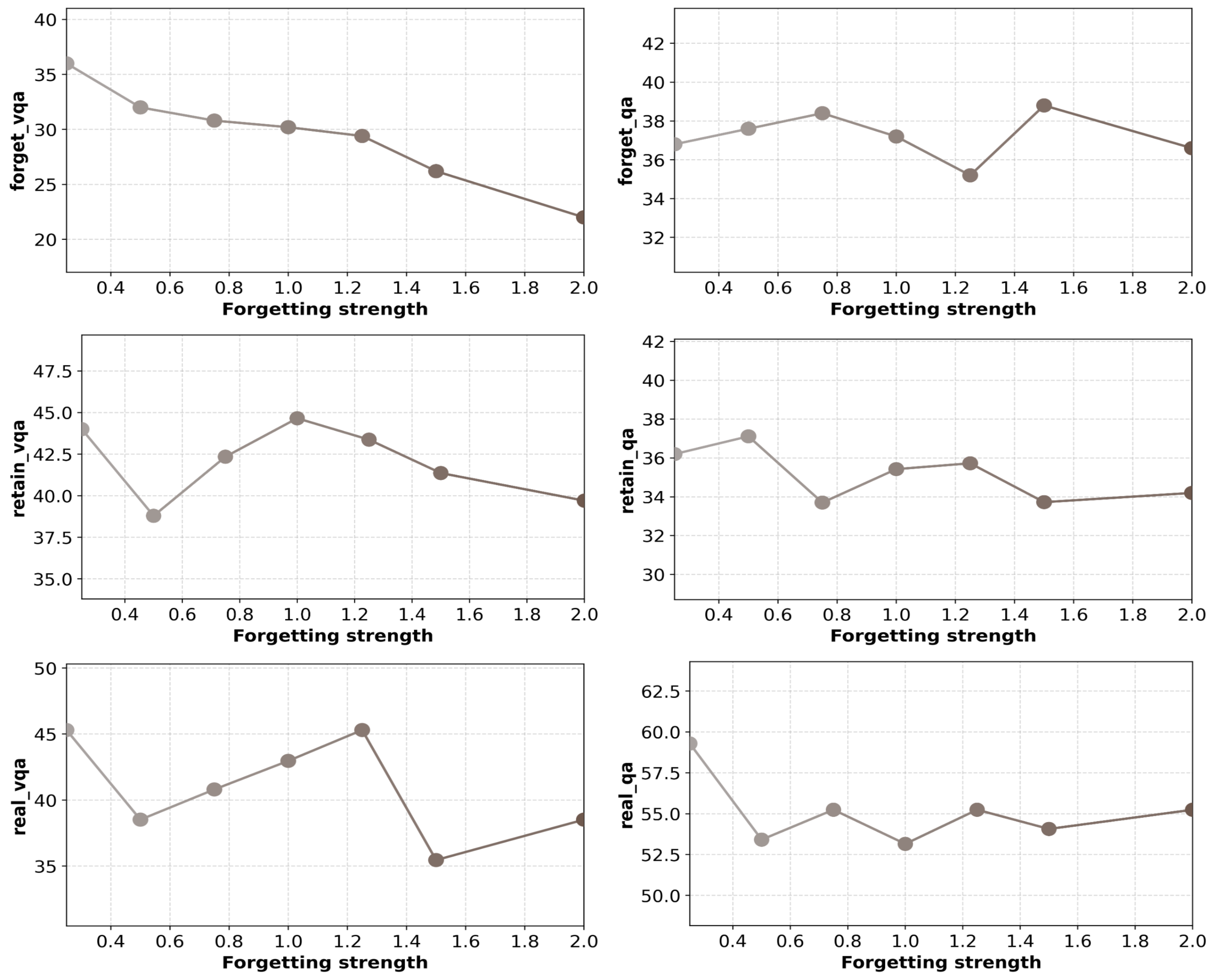
Figure 3: Trade-off curve illustrating the impact of α on knowledge forgetting and retention across VQA and QA metrics.
Similarly, increasing α amplifies target knowledge forgetting, but beyond an optimal α, retention metrics diminish, reflecting the inherent tension in selective unlearning tasks.
Efficiency and Robustness
Per-epoch unlearning runtime with frozen LLM and VKD is reduced by over 50% relative to full-model fine-tuning approaches (16.7 min vs. >43 min) with minimal impact on GPU memory consumption. The approach is optimized for online, sequential unlearning scenarios with frequent data deletion requests.
Robustness to relearning attacks is substantiated via a new Accuracy Gap (AG) metric. Under targeted relearning with partial recall data, the model exhibits minimal AG (1.3% vs. >8% in baselines), confirming substantive forgetting rather than superficial obfuscation. This constitutes the first systematic exploration of MLLM unlearning resilience in literature.
Theoretical and Practical Implications
By operationalizing unlearning via intermediate representation distillation and strict partial fine-tuning, the proposed method advances theoretical understanding of modality-specific memory localization in Transformer architectures and presents a replicable, efficient paradigm for privacy-compliant MLLM deployment.
Practically, this solution enables scalable retraction of visual identity in deployed MLLMs with negligible risk to textual factuality and overall utility—directly addressing emerging regulatory demands and enabling issue-responsive, incremental model updates without full retraining.
Future Work
Directions for technical expansion include:
- Generalizing VKD supervision signals across diverse visual encoders (ViT, CLIP, hybrid backbones)
- Extending selective unlearning to cross-modal knowledge association and structured facts
- Integrating robust privacy auditing for unlearning verification
- Exploring compositional unlearning for both entity- and attribute-level knowledge removal
Research into dynamic continual unlearning and reinforcement learning-based quality maintenance under high-frequency data deletion requests presents significant open questions with direct impact on industrial MLLM deployment protocols.
Conclusion
This work introduces a principled machine unlearning method for MLLMs, disentangling and selectively erasing visual knowledge while preserving textual semantics via a visual knowledge distillation strategy. The approach achieves state-of-the-art effectiveness, efficiency, and robustness against relearning, and establishes a foundational methodology for privacy-preserving multimodal model operations in contemporary regulatory contexts.