- The paper introduces CCUP, a closed-form projection that surgically removes targeted class embeddings from CLIP's joint space without retraining.
- It demonstrates near-zero accuracy on forgotten classes while retaining over 90% accuracy for remaining classes across various benchmarks.
- The method enables legal and bias compliance by unlearning specific classes data-free via nullspace projection with minimal computational overhead.
Selective, Data-Free Zero-Shot Class Unlearning in CLIP via Nullspace Projection
Introduction and Motivation
The proliferation of large-scale, pretrained multimodal models such as CLIP has enabled remarkable advances in zero-shot visual recognition and language-vision alignment. However, deploying these models in real-world settings increasingly necessitates the ability to selectively unlearn or erase information about particular classes—driven by privacy (e.g., GDPR right-to-be-forgotten), bias mitigation, regulatory compliance, or decontamination of outdated knowledge. Standard approaches to model unlearning are ineffectual for CLIP-like systems, as they typically either require access to the original training data (often unavailable or sensitive), or involve high-complexity iterative retraining, risking collateral model degradation.
"Erasing CLIP Memories: Non-Destructive, Data-Free Zero-Shot class Unlearning in CLIP Models" (2512.14137) addresses this problem with a closed-form, data-free, non-iterative projection approach. The method effectively eliminates information about arbitrary target ("forget") classes from the CLIP embedding space, while preserving accuracy on remaining classes and incurring negligible computational overhead.
Methodology
The proposed method, Consistent Class Unlearning Projection (CCUP), is grounded in nullspace projection and orthogonal decomposition of the embedding space. The central aim is to surgically remove projections of forget-class embeddings from the joint vision-language space, while minimally disturbing the semantic geometry relevant to retention classes. This is achieved without retraining, gradient steps, or any visual/textual samples from forget-sets.
Formally, denote the normalized text embedding matrices for forget and retain classes as Tf∈Rd×mf and Tr∈Rd×mr, respectively. The transformation matrix W is defined via the closed-form solution:
W=(I+μTrTrT)(I+λTfTfT+μTrTrT)−1
Here, λ and μ tune the forgetting and retention strength, balancing between total projection onto the nullspace of Tf (for large λ) and identity preservation (via μ). This construction ensures that, once W is applied to the image embedding, its alignment with any forget-class embedding is minimized (ideally annihilated), while its projection onto the retain subspace is preserved up to linear transformation.
After projection and normalization, zero-shot classification proceeds via standard cosine similarity with text embeddings.
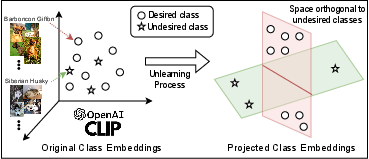
Figure 1: Projecting CLIP embeddings so that desired classes are orthogonal to undesired (to-be-forgotten) classes.
Empirical Results
Extensive evaluation across fine-grained (StanfordCars, StanfordDogs, Caltech101, OxfordFlowers) and established zero-shot datasets (AWA2, CUB), as well as Tiny ImageNet and Mini-ImageNet, substantiates the following key claims:
- Forgetting Efficacy: The accuracy on forget classes drops precipitously (close to zero) after applying CCUP, as measured by before/after accuracy comparisons (e.g., StanfordCars: 82.23→0.38%; StanfordDogs: 80.38→0.00% for ViT-B/32).
- Retention Integrity: Retain-class accuracy remains high (usually >90% of baseline) unlike baselines, which incur significant collateral degradation as forgetting class count increases.
- Superior Selectivity: Compared to leading alternatives such as ZSL-CLIP and synthetic-data (Lip), CCUP shows sharper forget/retain separation, especially as the overlap in semantic subspaces increases.
- MIA (Membership Inference Attack) Scores: Higher MIA scores demonstrate that CCUP better severs the forgotten class information, providing stronger privacy and legal compliance guarantees.
These numerical results consistently support the paper’s bold assertion that selective class unlearning in CLIP can be achieved in a purely data-free, training-free regime, with minimal degradation or computational burden.
Ablation and Trade-off Analysis
The authors dissect the importance of identity preservation and retention terms via ablation. If the identity component is removed, semantic drift harms retain-class performance; removing the retention term allows forgotten features to persist in the projected space. By varying λ (forget strength) and μ (retain strength), the trade-off between strict forgetting and retention fidelity is controlled. As expected, aggressive forgetting (large λ) suppresses forget-class activations at the cost of possible semantic interference for classes with overlapping features.
Visualization and Qualitative Effects
Evaluating pre- and post-unlearning predictions, the method demonstrably causes images from forgotten classes to be misclassified (typically as similar or frequent retained classes). Qualitative analysis further confirms that the transformation cleanly removes class-specific information, as desired, without disrupting the embedding landscape for retained categories.
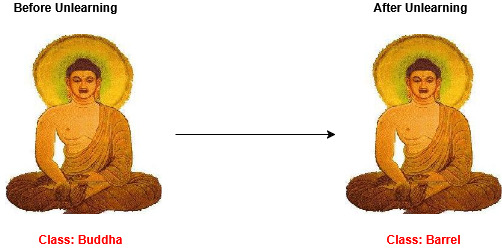
Figure 3: Class predictions before and after unlearning, demonstrating correct suppression of targeted class information via CCUP.
Implications and Future Opportunities
Practical Impact
This projection-based, data-free method stands out for:
- Legal and Privacy Compliance: Enabling organizations to satisfy “right to be forgotten” or similar deletion requirements with minimal operational cost.
- Efficient Lifecycle Management: Rapid removal of hazardous, biased, or obsolete classes without retraining and with guaranteed minimal disruption.
- Deployment Scalability: Integration via a single projection matrix enables real-world application at the edge or on resource-constrained devices.
Theoretical Implications
The results highlight several theoretical directions:
- Geometry of Forgetting: The interplay between forget and retain subspaces in high-dimensional multimodal embeddings is crucial—projective nullification is maximally selective when subspaces are well separated.
- Optimality of Closed-Form Projections: For linear, last-layer class erasure, closed-form methods admit provable guarantees; nonlinear interference (e.g., internal attention) is beyond their purview.
- Generalizability: The success across datasets and architectures indicates that nullspace projection is broadly applicable for vision-language architectures where final embedding structure is known.
Prospective Developments
- Extension to Other Architectures: Exploring nonlinear, deeper, or generative models where simple projection is insufficient.
- Adaptive/Continual Unlearning: Incorporation into continual learning pipelines, enabling on-the-fly class addition and removal.
- Robustness against Adversarial Data: Analyzing whether projection-based unlearning confers resistance to adversarial re-identification or leakage.
- Integration with Personalized and Federated AI: Selective on-device unlearning for user-centric privacy.
Conclusion
The CCUP framework enables precise, efficient, and non-destructive unlearning of class information in CLIP by closed-form nullspace projection of text embeddings—requiring neither training data nor retraining. Empirical results confirm strong numerical forgetting with minimal side effects on retention, outperforming alternative strategies, particularly as semantic overlap increases. Given the regulatory and societal demands for AI systems to “forget,” this approach represents a robust, theoretically principled solution compatible with modern deployment realities. Future directions revolve around expanding its reach to deeper, more nonlinear systems and integrating dynamic, adaptive unlearning in AI pipelines.
Reference: "Erasing CLIP Memories: Non-Destructive, Data-Free Zero-Shot class Unlearning in CLIP Models" (2512.14137)