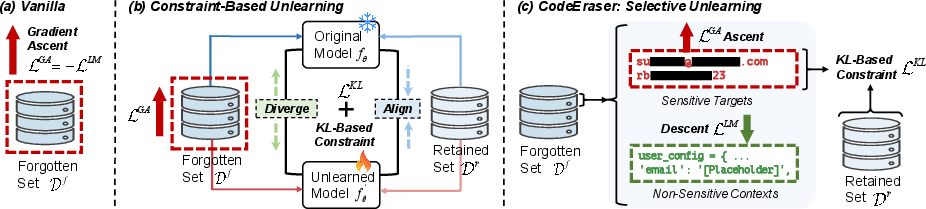
- The paper introduces CodeEraser, a fine-grained unlearning method that selectively erases sensitive memorization in code language models.
- It demonstrates a 93.89% reduction in sensitive memorization on Qwen2.5-Coder-7B while retaining 99.99% of its code generation performance.
- The approach offers an efficient post-hoc solution for_RTBF compliance with only 46.88 seconds per sample and manageable resource usage.
Erasing Sensitive Memorization in Code LLMs via Machine Unlearning
Introduction and Motivation
Code LLMs (CLMs) have become integral to software engineering tasks, including code generation, summarization, and repair. However, empirical evidence demonstrates that CLMs can inadvertently memorize and regurgitate sensitive information from their training data, such as emails, passwords, and API keys. This memorization poses significant privacy risks, especially in light of global data protection regulations (e.g., GDPR, CCPA) that mandate the "Right to Be Forgotten" (RTBF). Traditional mitigation strategies—data de-duplication and differential privacy—require full retraining and are computationally prohibitive for deployed models. The paper addresses the feasibility of post-hoc erasure of sensitive memorization in CLMs via machine unlearning, focusing on efficiency and preservation of model utility.
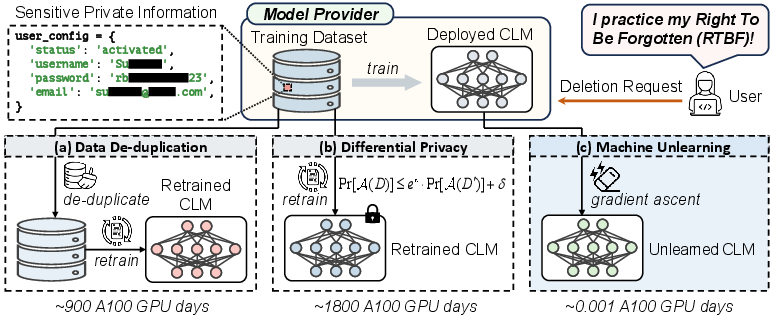
Figure 1: Existing approaches for mitigating memorization in CLMs: (a) data de-duplication, (b) differential privacy, and (c) machine unlearning.
Quantifying Sensitive Memorization in CLMs
The authors conduct a systematic quantification of sensitive memorization in several CLMs (CodeParrot, CodeGen-Mono, Qwen2.5-Coder) using the codeparrot-clean-train dataset. Sensitive segments are identified using the detect-secrets tool, revealing that approximately 18% of training samples contain sensitive information. Memorization is measured using Memorization Accuracy (MA) and Extraction Likelihood (EL), with thresholds empirically established using unseen datasets. The analysis shows that about 7% of training samples are memorized above threshold, indicating substantial privacy risk.
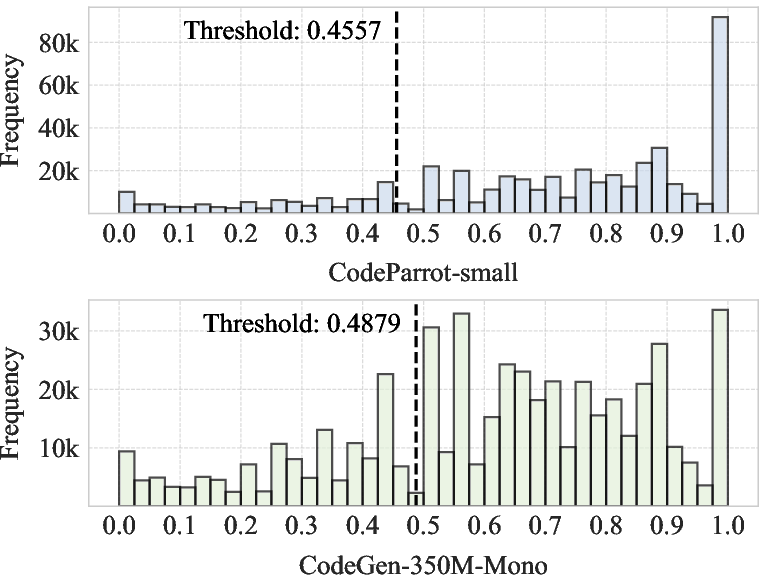
Figure 2: Distribution of memorization accuracy (MA) across sensitive data segments in the training corpus.
A high-risk dataset of 50,000 sensitive memorized samples is curated for subsequent unlearning experiments. The detection pipeline leverages regular expression-based secret identification and memorization scoring.
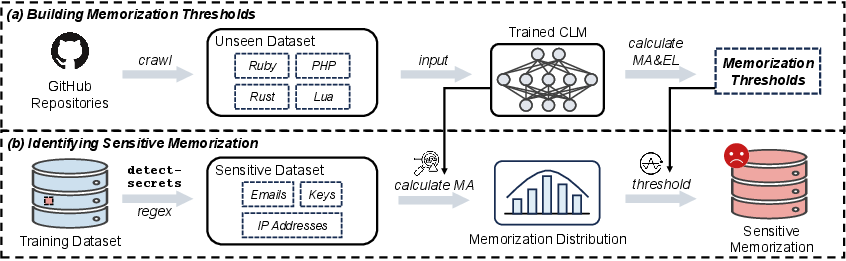
Figure 3: Pipeline for detecting and quantifying sensitive memorization in CLMs.
The unlearning problem is formalized as updating a trained CLM fθ to fθ′ such that targeted samples xf satisfy MA(xf)≤TMA and ELn(xf)≤TELn, effectively erasing memorization. Three gradient ascent-based unlearning methods are considered:
Experimental Evaluation
Effectiveness and Efficiency
CodeEraser achieves substantial reduction in memorization metrics across all tested CLMs. For Qwen2.5-Coder-7B, CodeEraser reduces memorization by 93.89% on the forgotten set, with only 46.88 seconds per sample and peak memory usage of ~200GB for batch unlearning. This is orders of magnitude more efficient than retraining or DP-based approaches.
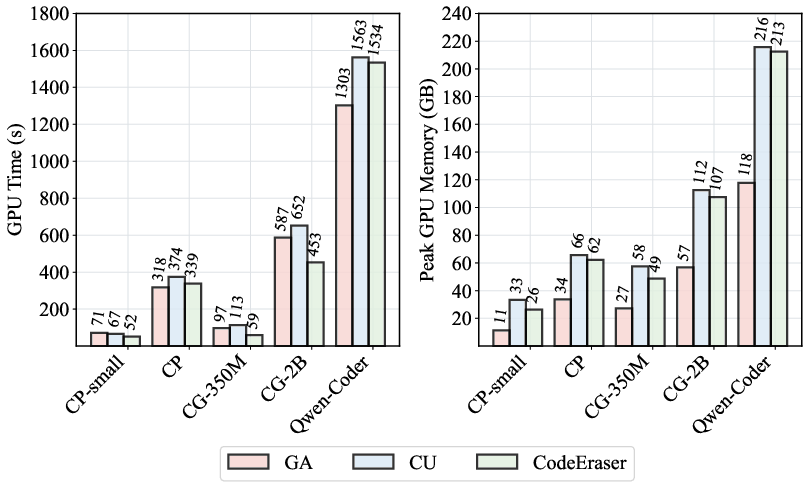
Figure 5: GPU time and memory usage for unlearning with different methods.
Model Utility Preservation
CodeEraser preserves model utility to a high degree, retaining 99.99% of HumanEval code generation performance in Qwen2.5-Coder-7B post-unlearning. In contrast, vanilla GA and CU methods exhibit notable utility degradation, especially as the number of forgotten samples increases. The selective targeting of CodeEraser minimizes collateral loss of non-sensitive code knowledge.
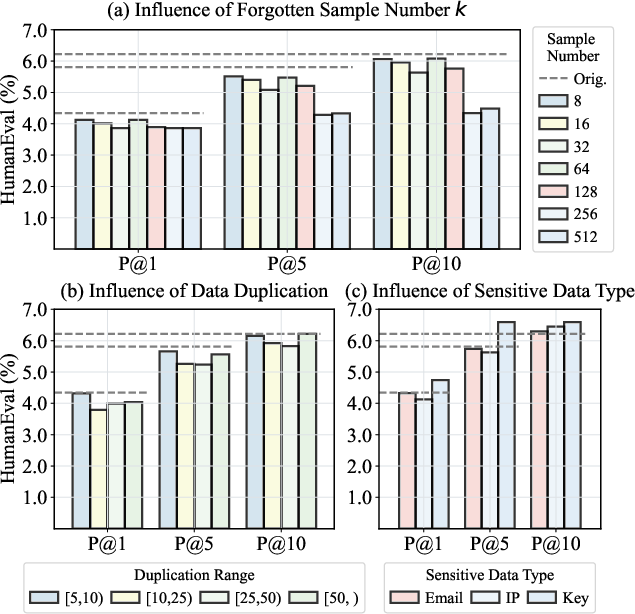
Analysis of Forgotten Data Characteristics
The impact of forgotten set size, duplication frequency, and sensitive data type is systematically analyzed:
Hyperparameter Sensitivity
Learning rate is the most critical hyperparameter for balancing forgetting and utility retention. Regularization parameters (γ, α, λ) have minor effects within reasonable ranges, allowing flexible tuning.
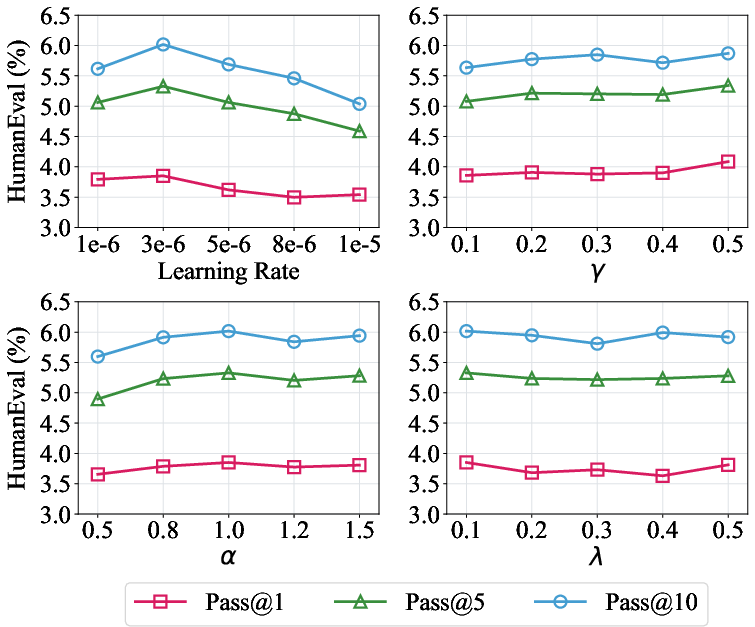
Figure 7: Sensitivity analysis of learning rate, γ, α, and λ on post-unlearning utility.
Implications and Future Directions
The results demonstrate that post-hoc machine unlearning is a practical and efficient solution for erasing sensitive memorization in CLMs, enabling compliance with RTBF and other privacy regulations without full retraining. The selective segment targeting of CodeEraser is essential for maintaining code integrity and functional correctness. However, scalability to large forgotten sets and generalization to other CLM architectures remain open challenges. Future work should explore more robust secret detection, adaptive unlearning strategies, and integration with model deployment pipelines.
Conclusion
This paper establishes a rigorous framework for erasing sensitive memorization in CLMs via machine unlearning, introducing CodeEraser as a selective, efficient, and utility-preserving method. The approach is validated on multiple CLMs and large-scale sensitive datasets, demonstrating strong privacy protection with minimal computational overhead. The findings have direct implications for the deployment of CLMs in privacy-sensitive domains and set the stage for further research into scalable, fine-grained unlearning techniques.