A model of errors in transformers
Abstract: We study the error rate of LLMs on tasks like arithmetic that require a deterministic output, and repetitive processing of tokens drawn from a small set of alternatives. We argue that incorrect predictions arise when small errors in the attention mechanism accumulate to cross a threshold, and use this insight to derive a quantitative two-parameter relationship between the accuracy and the complexity of the task. The two parameters vary with the prompt and the model; they can be interpreted in terms of an elementary noise rate, and the number of plausible erroneous tokens that can be predicted. Our analysis is inspired by an effective field theory'' perspective: the LLM's many raw parameters can be reorganized into just two parameters that govern the error rate. We perform extensive empirical tests, using Gemini 2.5 Flash, Gemini 2.5 Pro and DeepSeek R1, and find excellent agreement between the predicted and observed accuracy for a variety of tasks, although we also identify deviations in some cases. Our model provides an alternative to suggestions that errors made by LLMs on long repetitive tasks indicate thecollapse of reasoning'', or an inability to express ``compositional'' functions. Finally, we show how to construct prompts to reduce the error rate.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper tries to explain why LLMs like Gemini and DeepSeek sometimes make mistakes on simple, step-by-step tasks (for example, doing long addition or following a repetitive rule). The authors propose a simple, two-number model that predicts how often an LLM will be correct as the task gets longer. They test this idea on many tasks and show it matches what really happens most of the time.
What questions did the researchers ask?
They focused on easy-to-check, deterministic tasks where the right answer is fixed (no opinion or creativity needed) and the steps repeat over many small symbols (called “tokens,” like digits or bits). They asked:
- Why do LLMs start making more mistakes as these tasks get longer?
- Can we predict the accuracy (chance of getting everything correct) from just a couple of meaningful numbers?
- Are these mistakes due to “collapsing reasoning,” or are they simply small, random attention errors that build up?
- Can better prompts reduce these errors?
How did they study it?
The authors used a “physics-style” approach: instead of tracking every detail inside the huge model, they looked for a simple rule that describes the overall behavior.
- Tokens and attention in everyday language: Think of a token as a small piece of information (like a digit). “Attention” is how the model decides which earlier tokens matter most at each step. If attention weights are slightly off, the model may look a bit too much at irrelevant tokens and not enough at the right ones.
- Small errors that add up: The authors suggest that at each step, tiny attention errors creep in. Over many steps (a longer task), these small mistakes can add up. If the total error gets bigger than a certain threshold (a limit), the model outputs a wrong token.
- Two key parameters: They show that accuracy can be predicted by a curve controlled by just two numbers:
- : a small “noise rate” per token — how much random attention error the model tends to accumulate.
- : the number of “error directions” — roughly, how many plausible wrong tokens compete with the right one.
- Task complexity: They summarize how “long” or “complicated” a task is using a single number (for example, number length in addition, or how many steps you must process). They argue the total error typically grows with , and set a scale choice called .
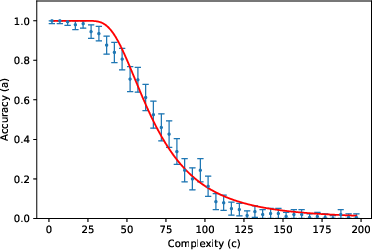
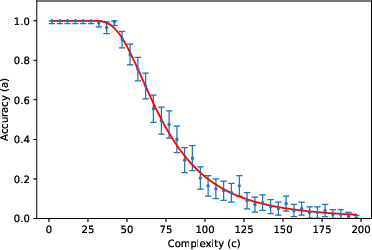
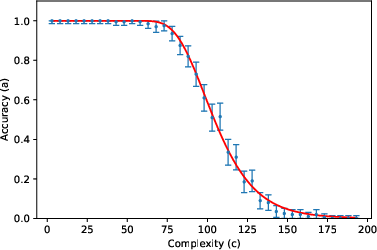
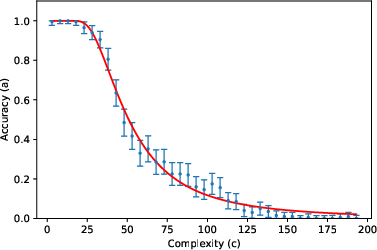
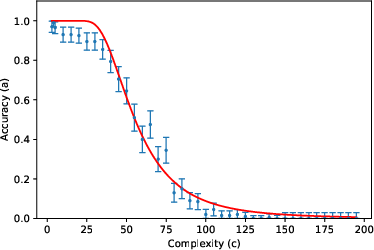
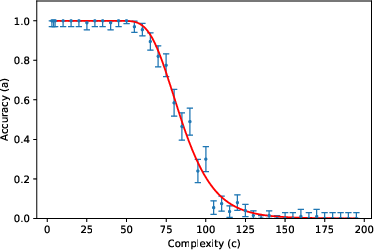
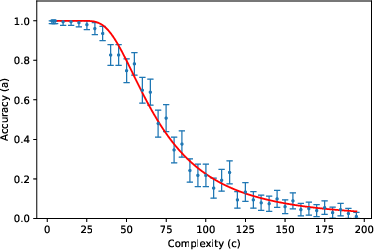
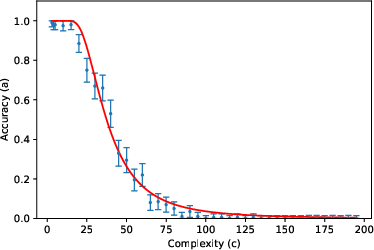
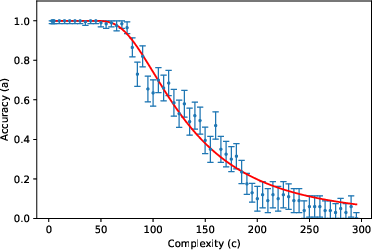
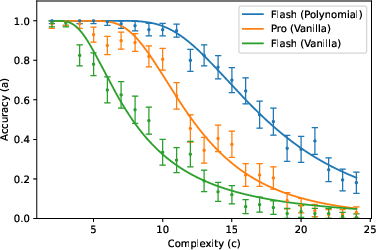
- The accuracy curve: Mathematically, they write accuracy as a specific function (given by an incomplete gamma function). You can think of it like this: for small (short tasks), accuracy stays near 1; as gets large (long tasks), accuracy falls in a predictable way, controlled by and .
They then tested this formula using about 200,000 prompts across 8 tasks (like list reversal, nested linear transformations, dynamic programming, Tower of Hanoi moves, various kinds of addition, and multiplication) and 3 LLMs (Gemini 2.5 Flash, Gemini 2.5 Pro, DeepSeek R1), with “thinking” (chain-of-thought) enabled.
What did they find, and why does it matter?
- The two-parameter model fits very well across many tasks and models. In other words, a huge, complex LLM’s error behavior can often be summarized by just two meaningful numbers ( and ). This is similar to “effective field theory” in physics, where complicated systems behave simply when you look at the right scale.
- Most values were small (around a few), matching the idea that only a few wrong tokens are realistic competitors at each step.
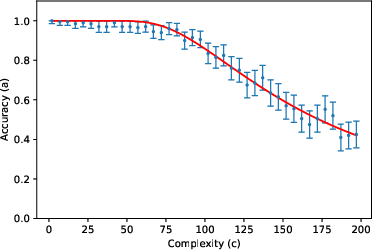
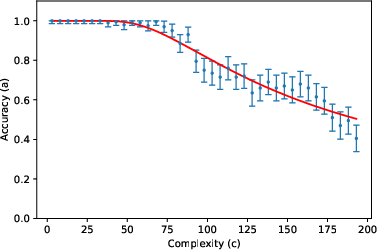
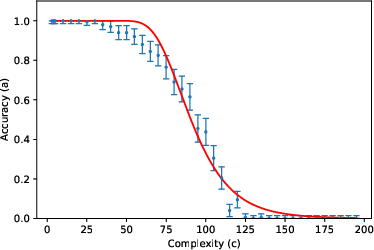
- One exception: “vanilla addition” with Gemini Pro didn’t fit the curve. The authors suggest that in this case the model might be switching between different internal strategies depending on the length of the numbers, breaking the assumption that one steady “effective model” explains all lengths. When they forced the model to use a specific, step-by-step algorithm in the prompt, the accuracy matched the predicted curve again. This supports their theory: the problem wasn’t “reasoning collapse,” it was inconsistent strategy choice.
- Not “collapse of reasoning”: Their results challenge claims that LLMs fail because their reasoning collapses on long tasks or because they can’t do “compositional” functions (building big solutions from small steps). Instead, the data suggest the main issue is small, accumulated attention noise.
- How to improve performance: They showed a simple prompt trick that helps the model focus. For multiplication, they tagged each digit with an extra “label” (like turning numbers into polynomials with tags for place value). This made it easier for the model to attend to the right token at the right step and significantly improved accuracy—sometimes even beating a stronger model’s performance with a normal prompt.
What does this mean going forward?
- Practical takeaway: You can often improve LLM reliability on long, repetitive tasks by designing prompts that sharply guide attention—clearly labeling what matters at each step.
- Bigger picture: Many LLM errors in step-by-step tasks may be explained, measured, and predicted without assuming deep failures of reasoning. Instead, they look like cumulative, predictable attention noise that crosses a threshold.
- Research impact: This offers a simple, testable framework for understanding and reducing errors. It suggests future work in:
- Better prompt patterns and token “tagging” to cut attention noise.
- Model architectures that automatically ignore irrelevant tokens more effectively.
- Extending this two-parameter idea to more complex tasks.
In short, the paper argues that LLM mistakes on long, repetitive tasks usually come from small attention errors that build up—not from a total breakdown in thinking—and that a simple two-number model can predict how accuracy drops as tasks get longer, while also pointing to practical ways to make models more reliable.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of unresolved issues left by the paper that future work could address.
- Lack of a rigorous derivation of the accuracy formula: Provide a formal analysis that starts from perturbed attention (errors in Q/K/V/FFN, layer norm, residuals) and derives the incomplete-gamma accuracy law, explicitly handling correlated errors across positions and layers.
- Unvalidated Gaussian error assumption: Test whether the distribution of maximal error components Ei across inputs is Gaussian (including tails), or whether heavy-tailed or mixture models better fit logit-margin statistics.
- Isotropy and “q” interpretation: Empirically verify whether error energy is approximately isotropic across a small set of confusion directions, and establish a method to map “q” to concrete confusion sets (e.g., number of plausible wrong tokens inferred from logit ranks).
- Thresholding model of misprediction: Validate the “error crosses τ” assumption by measuring when the correct-token logit margin crosses zero; determine whether a probabilistic margin-based failure model fits better than a hard threshold.
- Conflation in r = qσ²/τ²: Develop procedures to disentangle noise level (σ²), number of error directions (q), and decision threshold (τ) from observable quantities (e.g., using logit margin trajectories) rather than fitting a single composite parameter.
- Scaling exponent α fixed to 1: Directly measure how variance of maximal error grows with c from hidden states/logits to confirm α=1 vs α=1/2 or task-dependent α; quantify α across tasks and models instead of fixing it.
- Effective-model stationarity with c: Investigate and detect algorithm-switching within the LLM as c varies (as suggested by Gemini Pro’s failure on vanilla addition), and formalize conditions under which a single effective model is valid for a prompt.
- Robustness of the effective-model architecture assumption: Verify that a simplified attention+nonlinearity+nearest-token projection architecture can reproduce actual logit outputs across c, or develop a more faithful effective architecture (e.g., tied/untied output matrices, multi-head specifics).
- Precise definition and measurement of complexity c: Establish methods to estimate the minimal number of tokens (including CoT) actually required by a task and used by the model; compare fits when c is measured from traced CoT vs assumed linear proxies.
- Position-dependent and heteroskedastic errors: Test whether error variance depends on output position n (e.g., early/late context, boundary effects) and incorporate position-dependent scaling if needed.
- Correlation structure of errors across steps: Characterize the covariance of errors across output tokens, quantify how these correlations impact the “max error” approximation, and refine the formula if correlations deviate from assumptions.
- Role of multi-head attention and layer depth: Determine how head-wise and layer-wise contributions aggregate to the observed q and σ²; test whether specific heads/layers dominate error accumulation.
- Impact of decoding settings: Systematically study how temperature, nucleus/beam sampling, and logit bias affect the error distribution and the threshold-crossing behavior, despite the paper’s claim that temperature does not affect the deterministic output vector.
- Dependence on tokenization and vocabulary granularity: Quantify how tokenization choices (e.g., digits vs wordpieces, binary vs decimal) alter q and σ²; verify whether the small-vocabulary assumption is essential for the model’s validity.
- Generalization beyond deterministic repetitive tasks: Test applicability to tasks with larger vocabularies, semantic variability, non-deterministic outputs, or long-range dependencies (e.g., program synthesis, multi-hop QA, planning).
- Chain-of-thought effects: Measure how enabling/disabling CoT (and varying its length) changes σ², q, and α; assess whether forced algorithmic CoT consistently restores effective-model stationarity and improves fits.
- Prompt sensitivity and mapping from prompt features to parameters: Build predictive models that map structural prompt features (e.g., tags, delimiters, algorithm specification) to changes in r and q; assess prompt-to-parameter stability across models.
- Mechanistic source of attention noise: Provide empirical evidence that Q/K misalignment (vs value/FFN errors, layer norm drift) primarily drives accumulation; use controlled transformer ablations or synthetic tasks to isolate contributions.
- Validation by introspection of attention/logits: Instrument models to record attention weights, key-query similarities, and logit margins over context to directly observe error accumulation and threshold crossing.
- Model-scale and training-data effects: Establish scaling laws for r, q, and α across model sizes and training regimes; determine whether curriculum or algorithmic data reduces σ² or q, and whether RLHF/alignment alters error dynamics.
- Output-layer realism: Test the “nearest embedding token” approximation against actual learned output matrices; quantify deviations and update the decision rule if the projection assumption misrepresents real decoding.
- Tagged-token prompting generality: Evaluate the proposed tagging strategy (e.g., polynomial tags xk) across diverse tasks; run ablations to identify which tag designs most reduce r (noise) vs q (confusion directions).
- Failure-case analysis for Gemini Pro addition: Develop diagnostics to detect algorithm changes with c, and design prompts or constraints that stabilize algorithm choice; relate instability to observed deviations from the model.
- Parameter identifiability and confidence: Report confidence intervals and identifiability conditions for fitted r and q; compare the two-parameter gamma model to alternative error laws (e.g., power-law, stretched-exponential) to rule out overfitting.
- Extension to position-dependent complexity shifts: Test whether adding an offset d (c → c + d) systematically improves fits without overfitting; establish criteria for when such a third parameter is warranted.
- Reproducibility and variance across runs: Quantify run-to-run variability in fitted parameters under fixed prompts, and assess sensitivity to sampling budget per c; propose standardized protocols for parameter estimation.
These items aim to sharpen the theoretical foundations, improve empirical validation, and broaden the applicability of the proposed error model.
Practical Applications
Overview
The paper introduces a quantitative, two-parameter error model for LLMs on deterministic, repetitive-token tasks (e.g., arithmetic, list operations, dynamic programming). Accuracy as a function of task complexity c is captured by a closed-form relationship with parameters r (an effective “noise rate”) and q (the count of plausible error directions). The authors validate the model across 8 tasks and 3 SOTA LLMs, show a targeted failure mode (algorithm switching), and demonstrate prompts that reduce errors (e.g., algorithm forcing and tagging). Below are practical applications that leverage these findings for industry, academia, policy, and daily use.
Immediate Applications
These can be piloted or deployed with existing models and tooling.
- LLM Reliability Envelope Estimation (cross-sector)
- Use case: Before shipping an LLM-powered feature, calibrate r and q for the specific model-prompt-task triplet and compute a complexity budget c* for a target accuracy (e.g., 99%). Route tasks above c* to tools or chunking.
- Sectors: software (code assistants, log/data transforms), finance (ledger reconciliations, fixed-format checks), healthcare admin (code mapping, deterministic form filling), education (auto-grading of stepwise math).
- Tools/products/workflows:
- “Reliability Envelope Estimator” service that runs scaling tests, fits r,q, and exposes an API to predict accuracy for given c.
- “Complexity Governor” in LLM orchestration that blocks/defers long repetitive tasks beyond c*.
- Dependencies/assumptions: Task determinism and small token set; consistency of algorithm selection; calibration data across c; prompts held fixed.
- Prompt Scaffolding to Reduce Errors (prompt engineering)
- Use case: Reduce effective q (and/or r) by constraining the computation—e.g., algorithm forcing (digit decomposition for addition), token tagging (slot tags like xk for place value), and structured intermediate outputs.
- Sectors: software, education (worked solutions), finance (rule-based transformations), data operations (ETL normalization).
- Tools/workflows:
- “Prompt Scaffolding Kit” with templates: algorithm forcing, slot/tag markers, binary/decimal disambiguation.
- Library of domain tags (e.g., “GL_ACCOUNT=…”, “DATE_T+3”) to sharpen attention.
- Dependencies/assumptions: Willingness to update prompts; model follows instructions reliably; tagging vocabulary compatible with tokenizer.
- Model Selection and Routing by r,q
- Use case: Measure r,q per model for a given prompt; pick the lowest-r (most robust) model for long, repetitive tasks; route above-c* tasks to code/external tools.
- Sectors: software platforms, AI ops, ML platforms.
- Tools/workflows: Routing policies in agents; model cards reporting r,q for standard prompts.
- Dependencies/assumptions: Comparable prompts across models; availability of quick scaling tests.
- Automated Fallback to Tools for Deterministic Subtasks
- Use case: For arithmetic or DP-like subtasks, automatically parse → hand off to a calculator/solver → reintegrate into the LLM’s response when predicted accuracy falls below threshold.
- Sectors: software assistants, finance ops (totals, reconciliations), healthcare (dosage calculations), education (exact numeric answers).
- Tools/workflows: Regex/AST-based detectors for deterministic spans; tool-call policies keyed to c and predicted accuracy.
- Dependencies/assumptions: Reliable subtask detection; tool availability; latency budget.
- Accuracy-Aware Chunking and Verification Pipelines
- Use case: Break long deterministic sequences into smaller segments to keep c below c*, verify each segment, then stitch (with overlap checks).
- Sectors: robotics/manufacturing (step plans), back-office operations (batch transforms), content operations (bulk renaming/reformatting).
- Tools/workflows: Segmenter + verifier with majority/self-consistency checks; intermediate token projections as checkpoints.
- Dependencies/assumptions: Tasks decomposable into near-independent chunks; stitching verification is feasible.
- Quality Assurance and Monitoring via Scaling Curves
- Use case: Turn the paper’s scaling tests into “attention-noise stress tests” in CI for agents and prompts; watch for drifts in r,q after model updates.
- Sectors: all; especially platform teams.
- Tools/workflows: “Scaling QA Suite” that runs tasks across c, fits r,q, raises alerts on deviation or algorithm-switch signatures.
- Dependencies/assumptions: Stable prompts; comparable test corpora; environment parity (temperature, decoding).
- Diagnose Failures: Noise Accumulation vs Algorithm Switching
- Use case: If accuracy deviates from the curve or is erratic (as with vanilla addition in Pro), flag “algorithm switching”; fix via algorithm forcing prompts or task-specific parsers.
- Sectors: software product teams, research labs.
- Tools/workflows: Change-point detectors on accuracy vs c; automated re-test with algorithm-forcing prompts.
- Dependencies/assumptions: Access to prompt variants; sufficient samples across c.
- Procurement and Risk Governance Aids
- Use case: Require vendors to disclose r,q for standard deterministic tasks; set minimum envelopes for safety-critical workflows; define “no-LLM zones” for high-c deterministic steps.
- Sectors: finance (SOX-aligned tasks), healthcare (claims coding), public sector (form processing).
- Tools/workflows: RFP addenda with scaling tests; compliance dashboards showing predicted accuracy vs c thresholds.
- Dependencies/assumptions: Standardized test suites; adoption by vendors.
- Education and Tutoring Systems
- Use case: Tune problem difficulty by controlling c; provide algorithmic scaffolding for students and for the LLM; guarantee accuracy on auto-graded steps.
- Tools/workflows: Problem generator with target c; prompts that force explicit digits/tokens per step; calculators for high-c subparts.
- Dependencies/assumptions: Problems fit the small-token deterministic pattern; platform supports tool calls.
- User-Facing Guidance for Daily Life
- Use case: Clear UX hints: rely on LLM for short computations or tagged/structured queries; switch to a calculator/spreadsheet for long, repetitive arithmetic.
- Tools/workflows: Browser/assistant plugins warning when predicted accuracy dips; simple c estimator (e.g., digits × operands).
- Dependencies/assumptions: Basic task classification and c estimation; user consent for tool fallback.
Long-Term Applications
These require further research, model changes, standards, or ecosystem development.
- Architectural Enhancements to Reduce Attention Noise
- Idea: Train or design attention to ignore irrelevant tokens (e.g., relevance gating, sparsity, state-space models, content-based routing); reduce variance growth with c; improve positional schemes.
- Sectors: AI labs, foundation model vendors; downstream beneficiaries across sectors.
- Tools/workflows: New layers/regularizers that minimize variance of the largest error vector; hybrid neuro-symbolic modules for deterministic subroutines.
- Dependencies/assumptions: Access to pretraining/fine-tuning; empirical validation on scaling tests.
- Training Objectives and Regularizers Targeting r and q
- Idea: Directly optimize for low r (noise) and low q (few error directions) on synthetic curricula (arithmetic, DP, tagged sequences); contrastive losses to penalize attention to irrelevant tokens.
- Sectors: model training; education and enterprise assistants benefit downstream.
- Dependencies/assumptions: Differentiable proxies for r,q; scalable curricula; no adverse effects on generality.
- Standardized “r,q Model Cards” and Certification
- Idea: Extend model cards with r,q across reference tasks/prompts; safety certifications for deterministic workloads; policy frameworks to mandate reporting.
- Sectors: policy/regulation, procurement, insurance/liability.
- Dependencies/assumptions: Community agreement on test suites and fitting procedures; governance buy-in.
- Reliability-Aware Compilers for LLM Agents
- Idea: Agent compilers that statically analyze a plan, estimate c distributions for steps, and insert tool calls or chunking to meet an end-to-end accuracy target.
- Sectors: complex orchestration (RPA, robotics, enterprise workflows).
- Dependencies/assumptions: Plan analyzers; accurate c estimation; compositional accuracy models.
- Online Estimation of r,q and Adaptive Reasoning Budgets
- Idea: Estimate r,q on-the-fly from few-shot probes; adapt chain-of-thought length, chunk sizes, and tool-calls during inference to keep predicted accuracy above threshold.
- Sectors: SaaS assistants, copilots, tutoring.
- Dependencies/assumptions: Fast probes; stable per-session behavior; minimal latency overhead.
- Confidence Calibration for Deterministic Outputs
- Idea: Use the closed-form accuracy model to calibrate confidence as a function of c; expose calibrated probabilities in APIs/UX for downstream risk control.
- Sectors: finance (auditability), healthcare (decision support), safety-critical HMI.
- Dependencies/assumptions: Goodness-of-fit on in-domain tasks; handling of out-of-distribution prompts.
- Hardware/Systems Co-Design to Mitigate Error Accumulation
- Idea: Precision/quantization schemes and KV-cache policies that reduce spurious attention interactions; memory layouts to favor locality for relevant tokens.
- Sectors: accelerator vendors, inference platforms.
- Dependencies/assumptions: Joint training-inference considerations; measurable impact on r.
- Domain-Specific Tagging Standards and Tooling
- Idea: Shared ontologies for token-level tags (e.g., healthcare: CPT/ICD slots; finance: GL accounts, value-date tags) to guide attention and minimize error directions.
- Sectors: healthcare, finance, supply chain.
- Dependencies/assumptions: Standards-setting; tokenizer/tag compatibility; vendor adoption.
- Robust Planning in Robotics and Operations
- Idea: When LLMs generate action sequences, keep per-step plans within c* and interleave with classical planners/validators; certify plan segments with predicted accuracy guarantees.
- Sectors: robotics, manufacturing, logistics.
- Dependencies/assumptions: Reliable segmentation; fast validators; safety frameworks.
- Curriculum Design and Assessment Research
- Idea: Formalize c-based curricula for teaching/assessing algorithmic reasoning; study when chain-of-thought helps or harms by trading off more tokens vs error-correction through discrete projection.
- Sectors: education research, cognitive science.
- Dependencies/assumptions: Access to controlled classroom/platform environments; ethics approvals.
Key Assumptions and Dependencies (affecting feasibility)
- Task fit: Deterministic functions with small token alphabets and repetitive steps; c scales roughly linearly with input/output length.
- Model behavior stability: The effective model architecture approximates an idealized one with fixed parameters for a prompt; failures can occur if the model switches algorithms by c.
- Statistical assumptions: Largest-error coefficients approximately Gaussian; variance grows ~ c2α (empirically α ≈ 1); a thresholding decision in the output layer maps vector errors to token errors.
- Prompt stability: r,q are prompt- and model-dependent; changing prompts or decoding can shift parameters.
- Measurement: Reliable estimation of r,q requires running scaling tests across c; standard datasets and procedures improve comparability.
By turning “reasoning reliability” into a measurable function of task complexity with two interpretable parameters, this work enables practical reliability envelopes, safer orchestration, better prompts, and clearer standards for deploying LLMs on deterministic, repetitive workloads.
Glossary
- Attention heads: Multiple parallel self-attention mechanisms operating on different subspaces of the embedding, enabling the model to capture diverse relationships. "In practice, it is convenient to break up the embedding space into different subspaces, and apply separate attention heads."
- Attention matrix: A matrix of attention weights that determines how much each token attends to others, typically normalized to sum to 1 per query position. "where is an ``attention matrix'' that satisfies "
- Autoregressive: A generation process where each token is produced conditioned on previously generated tokens. "by the property that it autoregressively generates the tokens in jj \leq i$" - **Effective field theory**: A physics-inspired paradigm where complex systems are described by a small set of parameters relevant at a given scale, abstracting away microscopic details. "Our analysis is inspired by an ``effective field theory'' perspective" - **Effective model**: A simplified model that replicates the input-output behavior of the LLM for a given prompt, differing slightly from an idealized exact model. "We define an {\em effective model}, ${\cal M}_{\text{eff}."
- Embedding layer: The component mapping discrete tokens to continuous vectors in a high-dimensional space for further processing. "we imagine that the first layer in the idealized model is an embedding layer that maps a sequence of tokens into a sequence of vectors"
- Encoder (transformer encoder): The component in a transformer that processes input sequences with full (bidirectional) attention. "whereas it runs over all allowed values for transformer encoders."
- Gamma function: A continuous extension of the factorial function to real (and complex) numbers, denoted by . " is the gamma function"
- Hard-max: An attention selection mechanism that chooses the single largest score (limit of softmax with large scaling), used in theoretical analyses. "the softmax in \eqref{selfattentdef} effectively becomes a hard-max that is commonly used in theoretical analyses of these models."
- Incomplete gamma function: A special function defined as an integral that truncates the gamma function at a finite limit, used in the paper’s accuracy formula. "where denotes the incomplete gamma function"
- Layer norm: A normalization technique applied within transformer layers to stabilize training and improve convergence. "We have absorbed the ``value'' matrix, the layer norm \cite{ba2016layer} and the fully connected layer into a single nonlinear function ."
- Operator norm: The induced norm of a linear operator (matrix), measuring its maximal scaling effect on vector length. "When the operator norms of are very large"
- Positional information: Encoded indices or signals that allow models to distinguish token positions in a sequence. "Positional information is essential to prove that attention-based models are Turing complete."
- Query and key matrices: Learned linear transformations that produce query and key vectors whose dot products determine attention scores. "where and are the
query'' andkey'' matrices respectively." - RASP-L: A formal programming framework for expressing algorithms with attention-like primitives, used to analyze transformer capabilities. "Alternately, the idealized model can be thought of as a RASP-L program \cite{weiss2021thinking,zhou2023algorithms,yang2024counting} for the given task."
- Residual connections: Skip connections adding a layer’s input to its output, aiding gradient flow and stability. "it can also implement residual connections \cite{he2016deep}."
- Self-attention: A mechanism where each token attends to other tokens in the sequence to compute contextualized representations. "that implements self-attention \cite{luong2015effectiveapproachesattentionbasedneural,bahdanau2016neuralmachinetranslationjointly,vaswani2017attention}."
- Softmax: A function converting scores into a probability distribution by exponentiation and normalization; used to form attention weights. "the softmax in \eqref{selfattentdef} effectively becomes a hard-max that is commonly used in theoretical analyses of these models."
Collections
Sign up for free to add this paper to one or more collections.