HeartMuLa: A Family of Open Sourced Music Foundation Models
Abstract: We present a family of open-source Music Foundation Models designed to advance large-scale music understanding and generation across diverse tasks and modalities. Our framework consists of four major components: (1) HeartCLAP, an audio-text alignment model; (2) HeartTranscriptor, a robust lyric recognition model optimized for real-world music scenarios; and (3) HeartCodec, a low-frame-rate (12.5 Hz) yet high-fidelity music codec tokenizer that captures long-range musical structure while preserving fine-grained acoustic details and enabling efficient autoregressive modeling; (4) HeartMuLa, an LLM-based song generation model capable of synthesizing high-fidelity music under rich, user-controllable conditions (e.g., textual style descriptions, lyrics, and reference audio). In addition, it provides two specialized modes: (i) fine-grained musical attribute control, which allows users to specify the style of different song sections (e.g., intro, verse, chorus) using natural language prompts; and (ii) short, engaging music generation, which is suitable as background music for short videos. Lastly, HeartMuLa improves significantly when scaled to 7B parameters. For the first time, we show that a Suno-level, commercial-grade system can be reproduced using academic-scale data and GPU resources. We expect these foundation models to serve as strong baselines for future research and to facilitate practical applications in multimodal content production.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces HeartMuLa, a family of open-source AI models that can understand and create music. The goal is to make high-quality, controllable music generation possible for researchers and creators using tools that are free to use and study. The system can match text to music, recognize lyrics, turn audio into compact “tokens,” and then generate full songs (up to six minutes) with user controls like style, mood, and section-by-section guidance (intro, verse, chorus). The authors show their open models can reach commercial-level quality using academic-scale data and GPUs.
What questions does the paper try to answer?
The paper focuses on simple but big questions:
- How can we build an open, powerful music AI that others can reproduce and improve?
- How can a model keep long songs coherent (not just short loops) while still sounding detailed and natural?
- How can users easily control the music’s style, structure, and lyrics?
- Can we compress music into fewer, smarter pieces so models can handle long songs efficiently without losing sound quality?
How did they do it? (Methods in everyday language)
The system has four main pieces that work together, like a band with different instruments:
- HeartCLAP: Think of this like a “matchmaker” between music and text. If you give it a description (e.g., “upbeat pop with female vocals”), it can find music that fits, and vice versa. This helps align words and sounds.
- HeartTranscriptor: This is a lyrics listener. It’s trained to hear and write down the words sung in a song, even in real-world, noisy music.
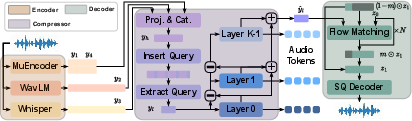
- HeartCodec: This is the “music tokenizer”—it turns a song into a sequence of tiny tokens (like musical letters) and back again. The trick:
- It listens with multiple “ears” at once: some hear detailed sound texture, some hear musical structure, and some focus on vocals and pronunciation.
- It compresses the music into tokens very slowly (only 12.5 snapshots per second), which makes long songs easier to model, but still keeps rich detail using a layered “Lego-like” code called RVQ (Residual Vector Quantization).
- To rebuild the sound from tokens, it uses a “flow” model that starts from noise and “sculpts” it into clean audio. They also speed this up with a technique called Reflow distillation and choose a continuous representation (SQ-Codec) that balances quality and speed well.
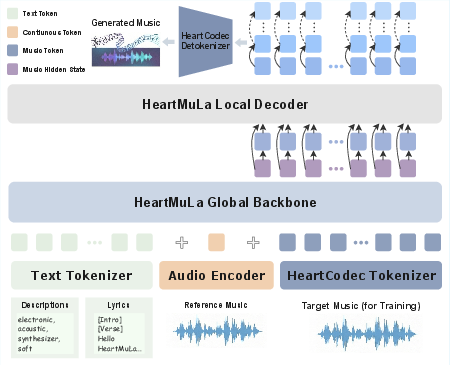
- HeartMuLa (the music maker): This is the generator that writes songs from tokens, guided by your inputs. It has a two-part brain:
- A global planner that decides the big picture over time (structure, main musical ideas).
- A local detailer that fills in fine-grained sound (timbre, texture).
It can take three types of guidance: - Lyrics (with labels like [intro], [verse], [chorus] to shape song structure) - Style tags (genre, mood, instruments, etc.) - Reference audio (a short clip to hint at overall style, using a representation that avoids copying a singer’s voice)
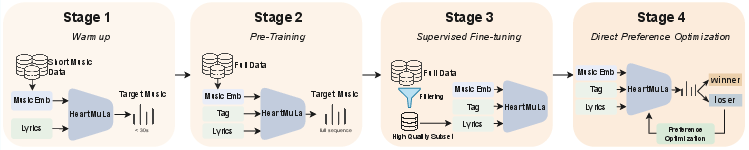
It’s trained in four stages: 1) Warmup on short clips to learn clear sounds fast 2) Pretraining on full songs to learn long-range structure 3) Supervised finetuning on the best-quality data to polish quality 4) Preference training (DPO): the model sees pairs of outputs and learns to prefer the better one (clearer vocals, better style match, nicer sound)
What did they find, and why is it important?
Here are the key results in plain terms:
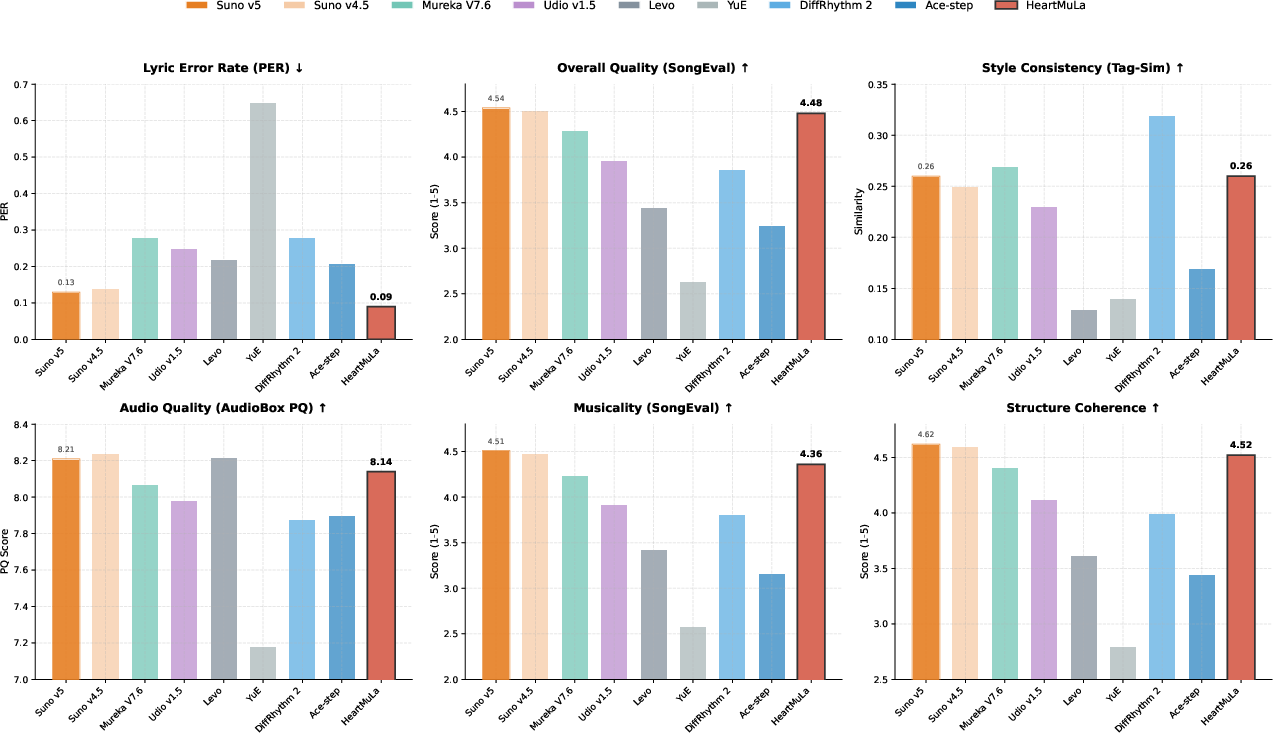
- The new tokenizer (HeartCodec) sets a high bar. Even though it uses very few snapshots per second (12.5 Hz), it reconstructs music with excellent quality and preserves singer identity and lyrics clarity better than many alternatives. This is important because fewer tokens mean the generator can handle much longer songs reliably.
- A specific choice of “continuous latent” (SQ-Codec) gave the best mix of audio quality and speed compared to other options they tried.
- Fine-tuning steps mattered: speeding up the flow model (Reflow) and then fine-tuning the final decoder (SQ finetune) improved both measured quality and how good the music sounds to human listeners.
- For generation, a “guidance scale” of about 1.25 sounded most natural to human ears (higher values can push clarity but may sound harsh).
- HeartMuLa can:
- Generate long songs (up to six minutes) that stay coherent
- Let users control different sections (intro/verse/chorus) with natural language
- Produce short, catchy tracks for short videos
- Improve markedly when scaled up (e.g., 7B parameters)
- The system is open-source and reaches “commercial-grade” quality using academic-scale data and GPUs, which makes high-level music AI more accessible to the research community.
What’s the bigger impact?
This work could change how people build and use music AI:
- For researchers: It provides strong, open baselines—clear starting points that others can reproduce, test, and improve. This speeds up progress and makes results more trustworthy.
- For creators: It offers fine control (by lyrics, style, and section) and can generate music that’s both long-form and high-fidelity, useful for songwriting, demos, and content creation (like background music for videos).
- For industry and tools: The efficient token design means models can handle long, structured music without massive compute costs, opening doors for real-world applications and potentially on-device or streaming scenarios.
- For ethics and safety: The style reference avoids carrying singer timbre information, helping reduce the risk of copying someone’s voice.
In short, HeartMuLa shows that powerful, controllable, and high-quality music generation can be built openly and efficiently, setting a solid foundation for the next generation of music AI.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of what remains missing, uncertain, or unexplored in the paper. Each item is phrased to be concrete and actionable for future research.
- Data transparency and licensing: The “internal dataset” of ~600k songs and the 100,000-hour corpus are not described (sources, genres, languages, rights/permissions, geographic/cultural coverage); release plans and licensing constraints for reproducing training remain unclear.
- Benchmark disclosure: The HeartBeats-Benchmark (English) is referenced but not specified (size, splits, genres, annotation protocol, licensing), hindering reproducibility and fair comparison.
- Component coverage gaps: HeartCLAP and HeartTranscriptor are introduced but lack architecture details, training procedures, benchmarks, and head-to-head comparisons against CLAP or state-of-the-art lyric/ASR models in musical conditions.
- Suno-level claim validation: The claim of “Suno-level, commercial-grade reproduction” is not supported by direct, blinded comparative human studies or objective benchmarks against commercial systems (e.g., Suno, Udio) or widely used academic baselines (MusicGen/MusicLM).
- Long-form generation evaluation: The assertion of up to 6-minute generation lacks quantitative and qualitative evaluation—no metrics for structural coherence across sections, repetition avoidance, transitions, and overall narrative form for lengthy songs.
- End-to-end latency and scalability: RTF is reported only for HeartCodec; end-to-end generation latency, throughput, and memory footprint (global-local transformer, streaming mode) on typical inference hardware remain unmeasured.
- Controllability assessment: No rigorous metrics or user studies quantify adherence to fine-grained section-level style controls (intro/verse/chorus), nor handling of conflicting conditions among lyrics, tags, and reference audio.
- Music theory control: The system does not provide or evaluate control over tempo, time signature, key, chord progression, or structure duration; how to add and evaluate these constraints remains open.
- Multilingual generalization: Training/evaluation is effectively English-centric; performance on non-English lyrics (alignment, pronunciation, prosody) is unknown despite Whisper’s multilingual capability.
- Lyric-to-audio synchronization: There is no metric or analysis of temporal alignment between generated vocals and provided lyrics (e.g., forced alignment accuracy, syllable timing, prosodic fit to meter/rhythm).
- Robustness and OOD behavior: Generalization to noisy, live, lo-fi recordings, non-stereo inputs, extreme vocal techniques (rap, growl, screams), dense mixes, and atypical genres is not tested.
- Safety and ethics: Memorization/plagiarism risk, style imitation boundaries, and voice timbre leakage are not empirically audited (the claim that MuQ-MuLan excludes speaker timbre is unverified); content safety filters/policies are not specified.
- Reference audio conditioning: The relative weighting and interactions between reference audio embeddings vs. text tags/lyrics are not ablated; failure modes under conflicting conditions and generalization to user-supplied external references are unknown.
- Automated metric validity: Heavy reliance on AudioBox and SongEval (learned metrics) lacks correlation studies with large-scale human judgments across genres/cultures; statistical significance testing is absent.
- Human evaluation scale: Codec subjective tests involve only five expert listeners; no large, diverse listener study for HeartMuLa’s generative quality, controllability, lyric intelligibility, and musicality.
- Query-based downsampling and RVQ design: No ablation on downsampling ratio, codebook count K, vocabulary size V, and per-layer weighting; sensitivity analyses and trade-offs (bitrate vs. fidelity vs. controllability) are missing.
- Transient/percussive fidelity: The 12.5 Hz frame rate may blur fast transients; systematic analyses on drums, sharp attacks, and microtiming accuracy are not provided.
- DPO training specifics: Construction of preference pairs (data size, criteria, noise handling), the choice of β temperature, reference policy selection, and the impact on global vs. local layers are not documented or ablated; human-in-the-loop preferences are absent.
- CFG in generation: Classifier-Free Guidance is tuned for the codec; CFG dropout/scale for HeartMuLa generation and its perceptual impact are not explored.
- Tag selection probabilities: Heuristic tag-category probabilities (e.g., genre 0.95, topic 0.1) are not justified or learned; their effect on style adherence and potential bias should be ablated or learned adaptively.
- HeartCLAP integration: The audio-text alignment model is not integrated into generation (conditioning or evaluation); how HeartCLAP could improve style adherence or retrieval-augmented generation remains unexplored.
- HeartTranscriptor utility: While used to compute WER/PER, there is no independent benchmark (lyrics in music vs. clean speech) or analysis of error types (coarticulation, singing prosody); its reliability for evaluating lyric intelligibility is uncertain.
- SQ-Codec dependence: The decoder is adapted to SQ-Codec latents; portability to other continuous tokenizers, licensing constraints, and generalization across codecs are not examined.
- Model scaling evidence: The paper claims substantial improvement at 7B parameters but presents only 3B+300M results; concrete scaling laws, costs, and gains are missing.
- Training compute and reproducibility: Training requires up to 64 A100s; exact recipes (epochs, schedules, curriculum, checkpointing) are partly truncated and may be insufficient for independent reproduction on modest academic resources.
- Stem-level control: The system does not offer or evaluate separate control over stems (vocals, drums, bass, instruments) or mixing parameters, despite reporting mixing similarity in codec tests.
- Streaming pipeline: Although HeartCodec is designed for streaming, the end-to-end streaming generation pipeline (chunking, lookahead, latency, artifacts at chunk boundaries) is not evaluated.
- Fair bitrate comparisons: HeartCodec is compared against baselines with differing bitrates/frame rates; controlled experiments at matched bitrates/frame rates are needed to isolate architectural advantages.
- Data filtering effects: Use of AudioBox/SongEval for filtering “high quality” subsets may cause distribution shifts or metric overfitting; impact on generalization and bias is not studied.
Glossary
- Ablation study: A controlled experiment removing or altering components to assess their impact on performance. "ablation studies on design choices."
- AdamW optimizer: An optimization algorithm that decouples weight decay from the gradient update for better generalization. "We use the AdamW optimizer with a base learning rate of ,"
- Adversarial loss: A GAN-based objective that trains a generator against a discriminator to improve realism. "The adversarial loss $\mathcal{L}_{\mathrm{adv}$ is computed based on the discriminator outputs."
- AudioBox: An automated evaluation framework providing aesthetic and perceptual audio metrics. "including Content Evaluation (CE), Content Understanding (CU), and Perceptual Quality (PQ) from AudioBox \cite{tjandra2025metaaudioboxaestheticsunified};"
- Autoregressive modeling: Generating sequences by predicting each token conditioned on previous ones. "enabling efficient autoregressive modeling;"
- Binary mask: An element-wise mask used to select or hide parts of a tensor during training/inference. "we apply a binary mask "
- Blind listening test: A subjective evaluation where listeners do not know which system produced each sample. "We conducted a blind listening test with five expert listeners with musical backgrounds."
- Classifier-Free Guidance (CFG): A technique to control conditioning strength in generative models without an explicit classifier. "the classifier-free guidance (CFG) scale is set to 1.25."
- Codebook: A finite set of vectors used to quantize continuous features into discrete tokens. "with codebooks of vocabulary size "
- Content Evaluation (CE): An AudioBox metric assessing the content-related quality of audio. "including Content Evaluation (CE), Content Understanding (CU), and Perceptual Quality (PQ) from AudioBox"
- Content Understanding (CU): An AudioBox metric gauging how well audio content is semantically conveyed. "including Content Understanding (CU)"
- Cosine learning rate scheduler: A schedule that decays the learning rate following a cosine curve, often with warmup. "together with a cosine learning rate scheduler that includes a warm-up period of the first steps."
- Cross-modal retrieval: Retrieving items across different modalities, such as matching text to audio. "enabling accurate music tagging and cross-modal retrieval,"
- Diffusion Transformer: A transformer-based backbone for diffusion/flow models in generative tasks. "We utilize a Diffusion Transformer \cite{dit} backbone based on LLaMA architecture \cite{llama3}"
- Diffusion-based music synthesis: Music generation using diffusion models that iteratively denoise signals. "as well as diffusion-based music synthesis~\cite{diffrhythm}"
- Direct Preference Optimization (DPO): A preference-based alignment method that optimizes policies without explicit reward modeling. "Direct Preference Optimization (DPO) \cite{rafailov2023direct}"
- ECAPA-TDNN: A neural architecture for robust speaker embeddings and verification. "Speaker Similarity (SPK_SIM) computed by ECAPA-TDNN model \cite{desplanques2020ecapa}"
- Flow matching: A generative modeling approach learning a vector field to transport noise to data. "The latent distribution is modeled using flow matching \cite{rectifiedflow_reflow}"
- Fréchet Audio Distance (FAD): A distributional metric measuring distance between sets of audio embeddings. "Fréchet Audio Distance (FAD)"
- Fréchet Distance (FD): A general Fréchet-based metric comparing distributions of features. "Fréchet Distance (FD)"
- Global-Local architecture: A hierarchical design with a global model for structure and a local model for details. "Given HeartMuLa's Global-Local architecture, where a lightweight Local Transformer predicts a multi-layer RVQ,"
- HiFi-GAN: A high-fidelity neural vocoder for waveform synthesis from spectral features. "followed by waveform synthesis via HiFi-GAN \cite{kong2020hifi}"
- LLaMA architecture: Meta’s LLM transformer backbone used as a base. "based on LLaMA architecture \cite{llama3}"
- Llama-3.2 tokenizer: The tokenization system associated with the Llama 3.2 model family. "Llama-3.2 tokenizer \cite{llama3}"
- Mel VAE: A variational autoencoder operating on Mel-spectrogram representations. "Mel VAE, 1D VAE, and SQ-Codec"
- MuEncoder: A pretrained (and fine-tuned) music encoder providing semantic/acoustic representations. "we use our training data to fine-tune the MuEncoder with the BEST-RQ \cite{best-rq,musicfm} loss."
- MuQ-MuLan: A model for music tagging/embedding used for style and tag similarity features. "extracted via the MuQ-MuLan model \cite{zhu2025muq}."
- Perceptual Evaluation of Speech Quality (PESQ): An objective speech quality metric correlating with human judgment. "Perceptual Evaluation of Speech Quality (PESQ)"
- Perceptual Quality (PQ): An AudioBox metric assessing overall perceived quality of audio. "Perceptual Quality (PQ)"
- Phoneme Error Rate (PER): An intelligibility metric measuring errors at the phoneme level. "measured by the phoneme error rate (PER)"
- Query-based quantization: A tokenization method inserting learnable queries to summarize frames before quantization. "via a query-based quantization strategy \cite{almtokenizer}"
- Real-Time Factor (RTF): The ratio of processing time to audio duration, indicating efficiency. "Real-Time Factor (RTF)"
- Reflow distillation: A distillation technique for flow models that reduces sampling steps while preserving quality. "We perform reflow distillation on top of HeartCodec (Pt. {paper_content} Ft.)."
- Residual Vector Quantization (RVQ): A multi-stage quantization scheme using residual codebooks for compact discrete tokens. "residual vector quantization (RVQ) module \cite{soundstream_rvq}"
- Short-Time Objective Intelligibility (STOI): An objective intelligibility metric for speech (and vocals). "Short-Time Objective Intelligibility (STOI)"
- SongEval: An automated evaluation suite measuring musical attributes like coherence and musicality. "SongEval \cite{yao2025songevalbenchmarkdatasetsong}"
- Speaker Similarity (SPK_SIM): A metric quantifying how similar two speaker identities are. "Speaker Similarity (SPK_SIM)"
- SQ-Codec: A continuous audio tokenizer (SimpleSpeech SQ-Codec) used for latent reconstruction. "select a 25 Hz SQ-Codec \cite{simplespeech_sqcodec}"
- STFT spectrogram: A time-frequency representation computed via the Short-Time Fourier Transform. "an MSE loss computed on the STFT spectrogram."
- Tag similarity (Tag-Sim.): Cosine similarity between audio and prompt tag embeddings to assess style adherence. "Tag Similarity (Tag-Sim.) defined as the cosine similarity between the embeddings of the generated audio and the prompt style tags,"
- Vector field: A function mapping points to velocities; in flow matching, it transports noise to data. "a vector field transforms Gaussian noise "
- Virtual Speech Quality Objective Listener (VISQOL): An objective measure of perceived audio quality. "Virtual Speech Quality Objective Listener (VISQOL)"
- WavLM: A pretrained speech model used to extract phonetic features. "WavLM phonetic features"
- Weighted CrossEntropy Loss: A loss that assigns different weights to cross-entropy terms (e.g., across RVQ layers). "Weighted CrossEntropy Loss"
- Whisper: A pretrained speech recognition encoder used for embeddings in the pipeline. "Whisper embeddings"
- Word Error Rate (WER): An objective metric quantifying transcription errors at the word level. "Word Error Rate (WER)"
Practical Applications
Immediate Applications
These applications can be deployed with the current HeartMuLa suite (HeartCLAP, HeartTranscriptor, HeartCodec, HeartMuLa), given standard GPU inference and the released open-source assets.
- Short-video background music generation at scale
- Sectors: media/entertainment, social platforms, advertising
- What: Generate short, engaging BGM tailored to tags and brief prompts using HeartMuLa’s “short-music” mode; batch-generate variants for A/B testing of ads.
- Tools/products/workflows: “BGM Autopilot” API for TikTok/Reels/Shorts editors; plug-ins for Adobe Premiere/CapCut/DaVinci to render multiple 10–30s options from text tags (genre, mood, instruments).
- Assumptions/dependencies: GPU-backed inference; prompt and tag curation pipeline; platform policy compliance for synthetic audio disclosures.
- Creator-focused song prototyping with section-level control
- Sectors: music production, independent creators, advertising
- What: Draft complete song structures (intro/verse/chorus/bridge) with natural-language prompts for each section; condition on lyrics and a reference audio clip for stylistic guidance.
- Tools/products/workflows: DAW plug-in (VST/AU) that renders section-by-section drafts; “Jingle Generator” for ad agencies, templated by structure and slogan-like lyrics.
- Assumptions/dependencies: Clear user prompts/lyrics; DAW integration wrappers; legal guidance on commercial release of synthetic works.
- Text-to-music retrieval, tagging, and recommendation
- Sectors: streaming, catalog management, music discovery
- What: Use HeartCLAP embeddings to power cross-modal search and auto-tagging of catalogs; enable “describe what you want” music search for editors or end users.
- Tools/products/workflows: Indexing pipelines that embed tracks and text tags; retrieval APIs for editorial teams and consumers.
- Assumptions/dependencies: Domain adaptation for specific catalogs; governance for tag ontologies and bias mitigation.
- Lyric transcription for subtitling, karaoke, and rights workflows
- Sectors: media localization, streaming, UGC moderation, publishing
- What: HeartTranscriptor extracts lyrics from mixed music for subtitles, karaoke timing, lyric synchronization, and metadata enrichment; supports quality checks via PER/WER.
- Tools/products/workflows: “Auto-Sub Lyric” batch service for UGC platforms; QC dashboards using intelligibility metrics.
- Assumptions/dependencies: Language coverage/accuracy on target markets; human-in-the-loop for quality-critical releases.
- Efficient music tokenization for dataset compression and training
- Sectors: MLOps, research labs, music tech startups
- What: HeartCodec’s 12.5 Hz tokens reduce sequence lengths and storage costs for training/generation, enabling longer-context modeling and faster AR inference.
- Tools/products/workflows: Dataset tokenization pipelines; caching/token stores; streaming generation servers with low-latency token decoding.
- Assumptions/dependencies: Adoption of SQ-Codec backend; reproducible preprocessing; licensing for pretrained components (Whisper/WavLM).
- Quality assurance and alignment gating for generative outputs
- Sectors: platform safety, production QA, enterprise media
- What: Use Tag Similarity (MuQ-MuLan), AudioBox, SongEval, and PER/WER to automatically filter low-quality or off-spec generations before delivery.
- Tools/products/workflows: “Gen-Audio QA Gate” that scores generations and enforces thresholds for style adherence, intelligibility, and aesthetics.
- Assumptions/dependencies: Access to evaluation models; thresholds tuned per use case; acceptance of proxy metrics in production SLAs.
- Educational tools for songwriting and arrangement practice
- Sectors: education, edtech, community music programs
- What: Students input lyrics and structural markers to hear multiple stylistic realizations; compare versions to learn about form, arrangement, and mood.
- Tools/products/workflows: Classroom web app with section-by-section prompts; teacher dashboards to manage assignments and references.
- Assumptions/dependencies: GPU or managed inference; content safety filters for classrooms; licensing for public demos.
- Game and app soundtracks that fit genre/mood briefs
- Sectors: gaming, mobile apps, indie studios
- What: Generate loopable, stylistically consistent tracks and stingers from tag prompts, with long-form coherence up to minutes for level themes.
- Tools/products/workflows: Build-time asset generation; runtime selection of pre-generated variants by level/mood.
- Assumptions/dependencies: Looping support handled at DAW/post step; creative review for brand fit.
- Dataset curation and benchmarking for music ML
- Sectors: academia, industrial research, startups
- What: Reuse the published training/eval pipeline (AudioBox, SongEval, Tag-Sim, WER/PER) for model comparisons and ablation studies; reproduce Suno-level performance on academic-scale hardware.
- Tools/products/workflows: Reproducible training scripts; benchmark suites; demo notebooks with HeartMuLa-oss-3B and 7B variants.
- Assumptions/dependencies: Access to multi-GPU nodes (A100-class) or cloud; data licensing for curated corpora.
- Compliance and moderation aids for UGC audio
- Sectors: platforms, compliance, trust & safety
- What: Use HeartTranscriptor to detect explicit lyrical content; HeartCLAP to flag mismatched/unsafe tags; route flagged items for review.
- Tools/products/workflows: Moderation queues augmented with PER/Tag-Sim signals; policy-based routing.
- Assumptions/dependencies: Policy definitions; evaluator calibration; regional legal requirements.
Long-Term Applications
These require further research, scaling, or productization beyond the current release (e.g., model distillation/quantization, additional modalities, expanded datasets, regulatory alignment).
- Real-time, interactive co-creation and live performance
- Sectors: live music, streaming, creator tools
- What: Low-latency token streaming and conditional control for improvisation with human performers; dynamic prompt changes per song section.
- Dependencies: Further latency reductions, on-device inference or fast edge serving, robust beat/tempo synchronization.
- Adaptive, context-aware game and XR soundtracks
- Sectors: gaming, AR/VR
- What: Runtime music that adapts to gameplay state, narrative arcs, and player emotion using fine-grained section control and style tags.
- Dependencies: Stable real-time generation, state-to-tag mapping pipelines, fail-safe fallbacks.
- On-device/mobile music generation
- Sectors: consumer software, hardware OEMs
- What: Local generation using quantized/distilled 3B or smaller models leveraging HeartCodec’s low-frame-rate tokens to conserve compute and battery.
- Dependencies: Aggressive model compression, hardware acceleration (NPUs/GPUs), memory-optimized decoding.
- Personalized wellness and music therapy tools
- Sectors: healthcare, wellness apps
- What: Generate calming/energizing music tailored to preferences or biofeedback; DPO-like preference alignment for clinically meaningful outcomes.
- Dependencies: Clinical evaluation, ethical frameworks, robust safety filters; data consent for personalization.
- Multilingual lyric generation and transcription at parity
- Sectors: global media, localization
- What: End-to-end multi-language lyric conditioning and accurate transcription across languages for karaoke/subtitling and generation.
- Dependencies: Training on multilingual corpora, evaluation datasets beyond English, cultural/linguistic guardrails.
- DAW-native, professional-grade production workflows
- Sectors: studio production, post-production
- What: Deep integration for arrangement drafts, style iteration, and revision control; eventual multi-track/stem-aware generation for mixing workflows.
- Dependencies: Model extensions for stem/multi-track control, latency improvements, IP and crediting standards.
- Automated audio ad and sonic branding optimization
- Sectors: advertising, marketing tech
- What: Generate many on-brief variants; optimize via preference learning and brand/style adherence metrics; maintain structural templates for campaigns.
- Dependencies: Brand-safe style constraint systems, human feedback loops, measurement integrations.
- Open evaluation standards for synthetic music quality and safety
- Sectors: policy, standards bodies, platforms
- What: Formalize metric suites (AudioBox, SongEval, PER/Tag-Sim) as auditing criteria for deployed generative music systems.
- Dependencies: Cross-industry consensus, dataset governance, transparent reporting and appeals processes.
- Accessibility-first audio generation
- Sectors: accessibility, education, productivity
- What: Tailored music/soundscapes to support focus, reading, or communication needs (e.g., tempo/mood constraints, predictable structure).
- Dependencies: User studies with diverse populations, safe defaults, optional clinician oversight.
- Research on controllability, safety, and provenance
- Sectors: academia, policy, platform safety
- What: Expand controllable attributes (tempo maps, key changes), watermarking/provenance, and misappropriation safeguards (e.g., voice timbre protection).
- Dependencies: New control tokens/architectures, standardized watermarking, legal and ethical guidelines.
Notes on Feasibility, Assumptions, and Dependencies
- Compute and latency: While HeartMuLa-oss-3B and 7B demonstrate strong results, production use typically requires GPU-backed inference or further model compression; real-time use cases depend on additional latency reductions.
- Data licensing and IP: Commercial deployment must ensure training and generation align with licensing and copyright policies; reference-audio conditioning should be restricted to lawful inputs.
- Safety and identity: The paper deliberately uses MuQ-MuLan embeddings that avoid speaker timbre; products should preserve this constraint or implement safeguards to prevent voice cloning.
- Evaluation metrics: Automated gating with AudioBox/SongEval/Tag-Sim/PER are proxies; human review remains critical for high-stakes releases.
- Language and domain coverage: HeartTranscriptor and generation quality may vary across languages and genres not well represented in training; domain adaptation may be needed.
- Integration effort: DAW plug-ins, SDKs, and platform APIs will require engineering beyond the core models (UX, caching, batching, monitoring, and observability).
Collections
Sign up for free to add this paper to one or more collections.