ACE-Step 1.5: Pushing the Boundaries of Open-Source Music Generation
Abstract: We present ACE-Step v1.5, a highly efficient open-source music foundation model that brings commercial-grade generation to consumer hardware. On commonly used evaluation metrics, ACE-Step v1.5 achieves quality beyond most commercial music models while remaining extremely fast -- under 2 seconds per full song on an A100 and under 10 seconds on an RTX 3090. The model runs locally with less than 4GB of VRAM, and supports lightweight personalization: users can train a LoRA from just a few songs to capture their own style. At its core lies a novel hybrid architecture where the LLM (LM) functions as an omni-capable planner: it transforms simple user queries into comprehensive song blueprints -- scaling from short loops to 10-minute compositions -- while synthesizing metadata, lyrics, and captions via Chain-of-Thought to guide the Diffusion Transformer (DiT). Uniquely, this alignment is achieved through intrinsic reinforcement learning relying solely on the model's internal mechanisms, thereby eliminating the biases inherent in external reward models or human preferences. Beyond standard synthesis, ACE-Step v1.5 unifies precise stylistic control with versatile editing capabilities -- such as cover generation, repainting, and vocal-to-BGM conversion -- while maintaining strict adherence to prompts across 50+ languages. This paves the way for powerful tools that seamlessly integrate into the creative workflows of music artists, producers, and content creators. The code, the model weights and the demo are available at: https://ace-step.github.io/ace-step-v1.5.github.io/
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces ACE-Step v1.5, an open-source AI that can create high-quality music very quickly on regular computers. It’s designed to give people tools that feel “commercial-grade” (like the best paid apps) but are free and fast. It can turn simple text prompts into complete songs, handle multiple languages, follow detailed instructions, and even edit music without starting over.
What questions did the researchers ask?
The team set out to solve four big questions:
- How can we make an open-source music model as good as (or close to) the best closed-source, paid models?
- How can we make it fast—so it runs in seconds on consumer GPUs—without losing sound quality?
- How can we make it easy to control, so it sticks closely to prompts, styles, lyrics, and languages?
- Can one model handle many music tasks (like creating, covering, repainting, separating tracks, and adding instruments) without needing a bunch of separate tools?
How did they do it? (Methods explained simply)
Think of the system as a two-person creative team working together:
The “Planner” (LLM, LM)
- Like a songwriter or architect, the LM takes your prompt (“upbeat K-pop chorus with a catchy hook”) and turns it into a detailed plan: tempo (BPM), key, mood, structure (intro/verse/chorus), lyrics, and tags.
- It writes this plan in a neat, predictable format (YAML), so the next part can follow it precisely.
- It can also listen to audio codes and describe what’s in them (reverse captioning), help brainstorm bigger ideas from short prompts, and clean up messy instructions.
The “Renderer” (Diffusion Transformer, DiT)
- Like a skilled audio engineer, the DiT takes the plan and turns it into sound.
- It focuses on audio quality, instrument separation, and keeping the rhythm/melody coherent over time.
- The model works in a special “latent” space (a compact code version of audio), using a fast compressor called a 1D VAE.
- Analogy: the VAE is like zipping a huge sound file down into a small package without losing the important details.
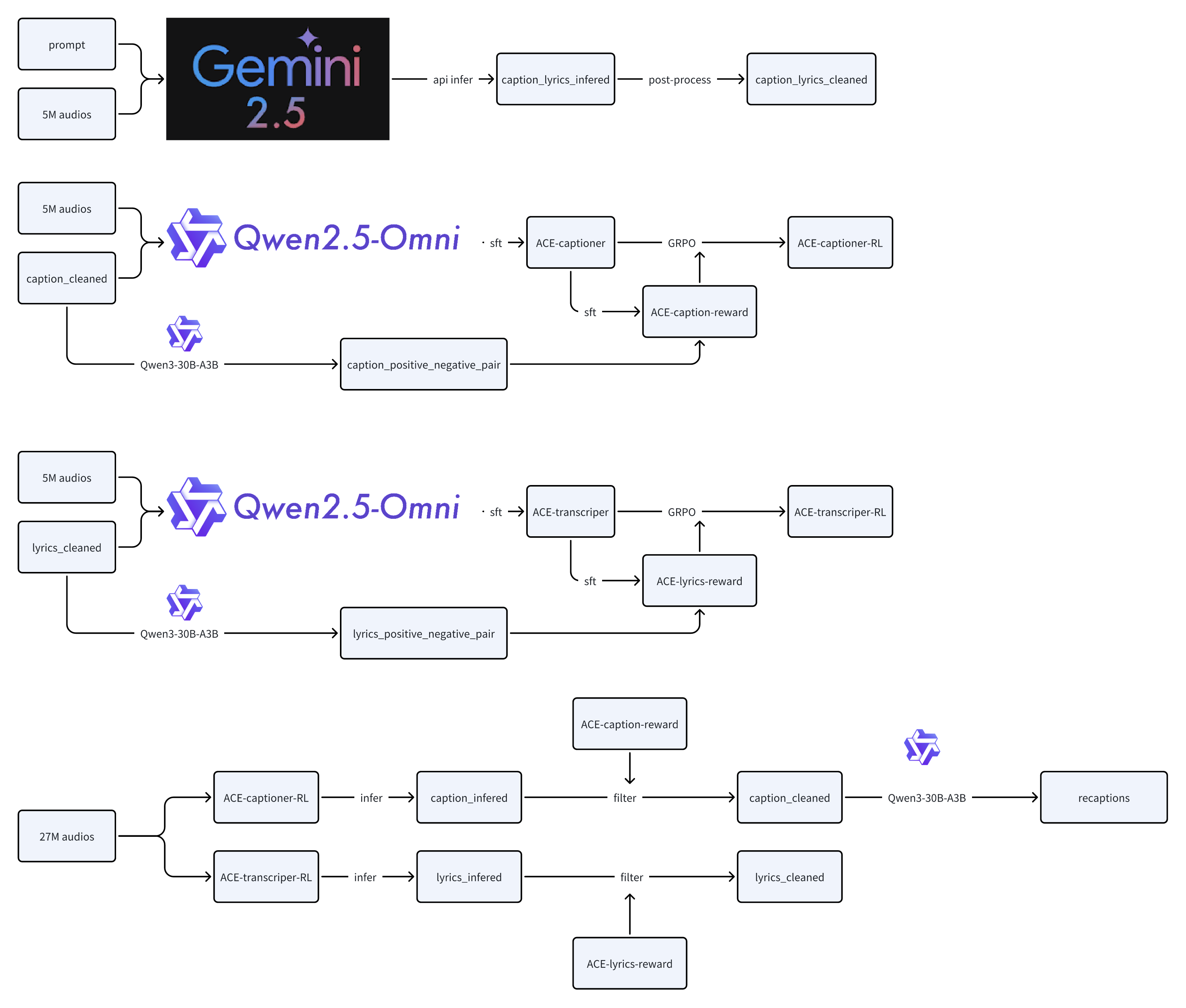
Making the training data smarter (not just bigger)
- They built a careful pipeline to label music with accurate captions and lyrics across more than 50 languages.
- First, a small “golden set” was labeled using a strong reasoning model.
- Then they trained their own captioning/transcribing models, taught them what “good labels” look like using reward models (which spot subtle mistakes), and used reinforcement learning (RL) to refine them.
- This pipeline labeled a massive dataset (27 million samples) while filtering out weak or mismatched pairs (bad caption/audio matches).
One model, many tasks
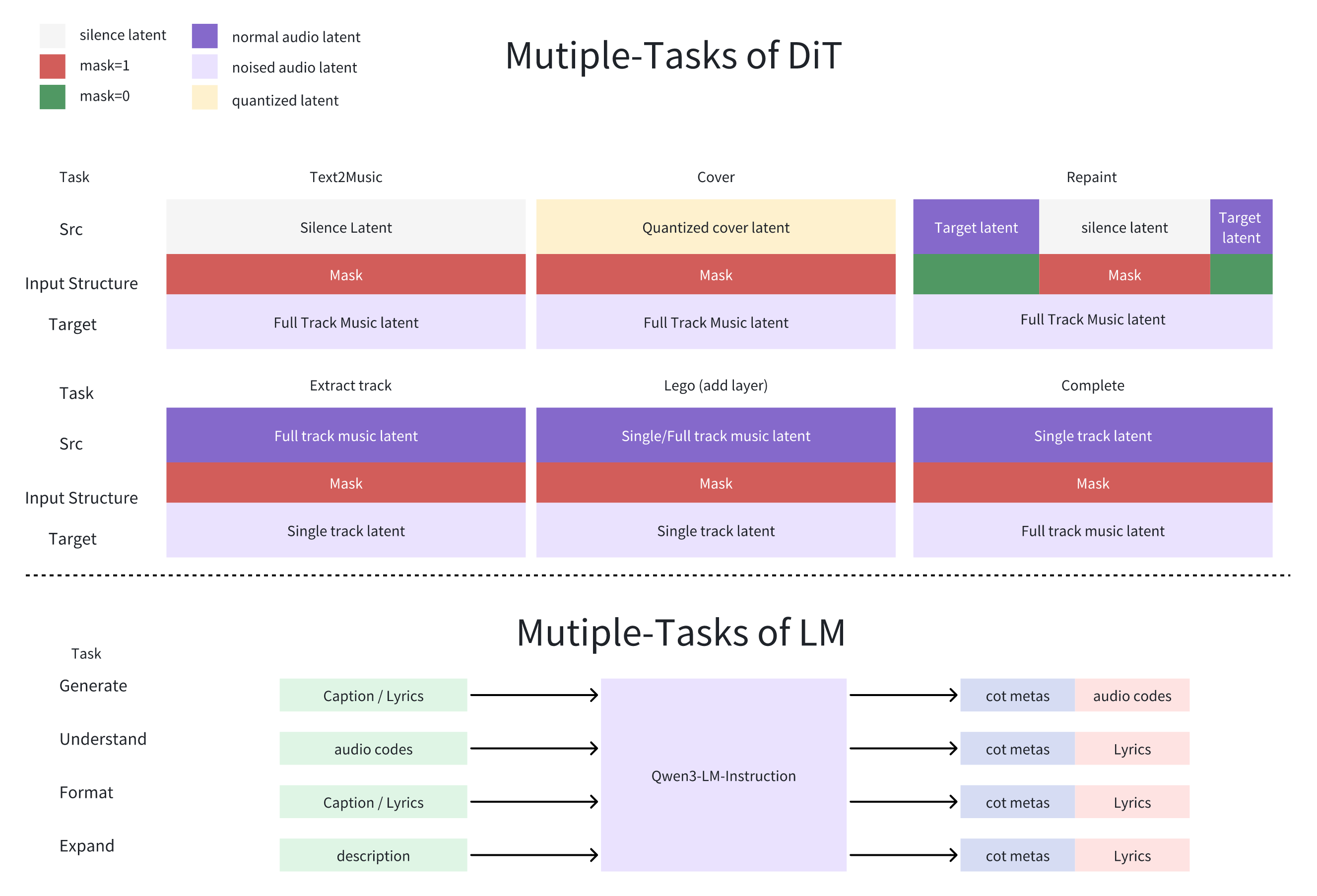
With a flexible “masked generative framework,” the same model can:
- Create music from text (Text-to-Music)
- Make covers that keep the melody but change the timbre (the “voice” or instrument character)
- Repaint parts of a song (edit a section without regenerating the whole track)
- Extract stems (like vocals/drums/bass)
- Add layers (complementary instruments)
- Complete arrangements around a small motif
Analogy: It’s like editing parts of a painting under a clear sheet—you can pick what to change, and the rest stays intact.
Speed-up via “distillation”
- Distillation trains a “student” model to do what a slower “teacher” model does, but in far fewer steps.
- They shrank the generation process from around 50 steps down to 4–8 steps.
- Result: songs are generated in a few seconds on strong GPUs and under ~10 seconds on high-end consumer GPUs (like RTX 3090), while keeping high audio quality.
Better control via self-checks (intrinsic RL)
- Instead of relying on human judges or external scoring models (which can be biased), ACE-Step v1.5 uses its own internal checks to reward good behavior:
- For the renderer: it checks alignment between lyrics and audio over time (like “is the singing lined up with the words?”).
- For the planner: it rewards specific, accurate captions that match the actual audio, not generic ones.
- This helps it follow instructions closely across many languages and styles.
Personalization
- You can teach the model your style using LoRA (a lightweight fine-tuning method) with just a few songs, without needing tons of memory.
What did they find?
The team reports:
- Very fast generation: sub-seconds to a few seconds on strong GPUs; under ~10 seconds on consumer GPUs; runs locally with less than 4GB VRAM.
- Strong audio quality: it scores highly on standard metrics (like AudioBox and SongEval) and has good rhythm/melody consistency.
- In human A/B listening tests (“Music Arena”), people rated ACE-Step v1.5 between popular commercial systems (Suno v4.5 and Suno v5).
- It follows prompts more closely than most open-source models, and works across 50+ languages.
- It’s versatile: create, cover, repaint, extract stems, add layers, and complete long compositions (from 10-second loops to 10-minute tracks).
Why this matters:
- Fast generation means smoother creative flow—you can try many ideas quickly and pick the best.
- Strong control means the music matches your vision (style, lyrics, mood) rather than just “close enough.”
- Running locally with low VRAM and simple personalization lowers the barrier for artists, students, and hobbyists.
Why does it matter? (Implications and impact)
ACE-Step v1.5 helps “democratize” high-quality music creation:
- It brings near commercial-level results to open-source, free tools.
- It works on everyday hardware, so more people can create and experiment without expensive servers.
- Its multi-task design fits real workflows: you can edit specific parts, separate stems for mixing, and keep a consistent sound identity across tracks.
- For creators, it can jumpstart ideas, keep a project’s style consistent, and speed up finishing songs.
Looking ahead, the authors plan to scale the model further, improve lyric alignment even more, broaden world knowledge (so it better captures specific genres, eras, and cultures), and add smarter editing “agents.” If they succeed, future versions could feel even richer, more accurate, and more helpful for musicians, producers, and content creators everywhere.
Knowledge Gaps
Unresolved Gaps, Limitations, and Open Questions
The following list identifies concrete knowledge gaps and open questions left unresolved by the paper. Each point highlights a missing detail, uncertainty, or unexplored area that future work could directly address.
- Data transparency and licensing
- Precise sources, licensing status, and legal compliance of the 27M audio corpus are not disclosed; reproducibility requires a public breakdown (origins, genres, regions, licenses) and a copyright-risk assessment.
- Deduplication, near-duplicate removal, and artist/style leakage checks are not described; quantify how duplicates or over-represented artists/styles affect training and evaluation.
- Annotation pipeline validity and bias
- The paper relies on Gemini 2.5 Pro for seed annotations and proprietary reward models for filtering; there is no external validation of annotation quality or bias across styles, cultures, and languages.
- The 4M synthetic negative pairs (instrument swaps, mood tag corruptions) may induce reward hacking; ablations are needed to show robustness to adversarial or distribution-shifted captions.
- No inter-annotator agreement or human audit on the final 27M annotations; report human QA protocols and cross-cultural checks.
- Multilingual coverage and pronunciation accuracy
- Romanization (50% stochastic) may degrade prosody or lyric stress patterns; quantify pronunciation accuracy and intelligibility across 50+ languages (including tonal languages, code-switching, diacritics).
- Evaluation uses only English/Chinese prompts; extend to low-resource languages and script families (Arabic, Indic, Cyrillic) with explicit metrics for alignment, intelligibility, and lyric timing.
- Timbre cloning and reference control
- Zero-shot timbre cloning claims are not benchmarked; provide objective timbre similarity metrics and human AB tests across varied genres/recording conditions.
- The voice-masking and stem construction process needs specification (algorithm, quality metrics like SDR/SIR/SAR); quantify artifacts introduced and their impact on downstream tasks.
- VAE reconstruction quality and ablations
- “Near-lossless perceptual quality” of the 1D VAE lacks standardized metrics (e.g., PESQ, ViSQOL, SI-SDR, log-spectral distance) and comparative ablations versus 2D mel baselines.
- The late-stage removal of KL penalty and increased adversarial weight could induce mode collapse or artifacts; report failure cases, stability analyses, and reconstruction ablations.
- LM–DiT interface and training details
- The LM is said to output “audio codes” and YAML metadata, but the exact data flow (how LM-produced discrete codes, captions, and constraints condition DiT) is not specified.
- Joint vs. separate training of LM and DiT, synchronization of token/latent timelines, and credit assignment under RL are unclear; document interface schemas, alignment strategies, and failure modes.
- FSQ tokenizer and structural fidelity
- The 5Hz structural codebook (≈64k) needs evaluation of how well it preserves melody, rhythm, and sectional form across transformations (cover, repainting); provide beat/rhythm fidelity metrics and human studies.
- Trade-offs between codebook size, quantization error, and long-form structural coherence are unexplored; run controlled ablations.
- Distillation framework reproducibility
- Claims of 200× speedup (240 s in ~1 s on A100) require detailed measurement protocols (I/O handling, batching, precision/quantization settings, exact step counts), hardware configs, and error bars.
- The dynamic-shift Decoupled DMD2 + GAN pipeline lacks ablations isolating contributions (shift sampling, discriminator architecture, Flow Matching objective) and generalization beyond text-to-music (e.g., editing tasks).
- Intrinsic RL design and external validation
- The Attention Alignment Score (AAS) claims >95% correlation with human judgments, but lacks public datasets, baselines (e.g., phoneme/forced alignment), confidence intervals, and cross-genre/tempo stress tests.
- PMI-based LM reward may penalize creativity or promote safe clichés; quantify reward hacking, diversity loss, and trade-offs between specificity and novelty.
- No comparison to external alignment baselines (CLAP/LAION-audio, phoneme-level lyric aligners); add head-to-head evaluations.
- Editing and separation capabilities
- Track extraction, repainting, layering, and completion are described architecturally but lack quantitative evaluations (SDR for separation, continuity metrics for repainting, musicality ratings for layering).
- Non-destructive editing guarantees (no global drift in unaffected regions) need measurable criteria (e.g., SSM similarity, perceptual continuity scores).
- Long-form generation and structure
- Claims of up to 10-minute compositions are not empirically supported; provide structure metrics (section boundary detection, motif recurrence, key stability, tempo drift) and human composer evaluations for long-form pieces.
- Mitigation of repetition, degeneration, or thematic incoherence over long durations is not studied; propose diagnostics and regularizers.
- Usability checklist operationalization
- The 17-point Usability Checklist is not instantiated with measurable definitions or tests; operationalize each criterion (e.g., “Serendipity Coefficient”) with standardized metrics and public benchmarks.
- “Test-Time Scaling” and “Anti-Gacha” robustness lack quantitative measures; define prompt sparsity/ambiguity stress tests and diversity/coverage metrics.
- Evaluation fairness and independence
- Style and lyric alignment metrics use in-house reward models, risking circular evaluation; include external evaluators and publicly available metrics to avoid endogenous bias.
- Music Arena human study details (sample sizes, rater demographics, inter-rater reliability, confidence intervals, prompt sets) are missing; publish full protocol and raw comparisons.
- Performance vs. resource claims
- A 2B-parameter DiT running with <4 GB VRAM is implausible without aggressive quantization/offloading; specify precision (int4/int8), memory optimizations, caching, and throughput vs. quality trade-offs.
- CPU/GPU utilization, energy costs, and thermal throttling on consumer hardware are not reported; provide real-world deployment benchmarks.
- Personalization (LoRA) and safety
- LoRA training from “a few songs” lacks guidance on data quantity, training duration, overfitting risk, and cross-task generalization; provide procedures and benchmarks.
- Style cloning and voice timbre replication raise ethical and legal risks; propose and evaluate safety filters (copyright/style detectors, consent verification, watermarking, opt-out mechanisms).
- Controllability and technical instruction grounding
- Technical terms (e.g., “Phrygian mode,” “TB-303 acid line,” “sidechain compression”) require music-theory-grounded control; evaluate whether instructions produce correct acoustic phenomena and propose a taxonomy of controllable attributes.
- Parameteric control (BPM, key, instrumentation) needs error bounds and guarantees; quantify adherence under conflicting instructions and noisy references.
- Robustness under distribution shift
- The model’s behavior on out-of-domain prompts (novel genres, uncommon instruments, noisy/low-quality references) is not tested; define stress suites and failure analyses.
- Multimodal conditioning conflicts (e.g., mismatched timbre + lyrics + structural codes) and their resolution are not studied; devise conflict-handling policies.
- Open-source reproducibility
- Training hyperparameters, curricula schedules, and exact model checkpoints for each phase (pre-train, omni-task fine-tune, SFT, distillation, RL) are not fully specified; provide comprehensive recipes and config files.
- End-to-end pipelines (data preprocessing, tokenizer training, LM/DiT joint alignment) need executable scripts and unit tests to ensure community replication.
- World knowledge grounding
- Cultural/era-specific styles (“1920s Shanghai Jazz,” “Cyberpunk 2077 soundscape”) need knowledge grounding evaluations; build and release a benchmark for historically and culturally accurate generation without anachronisms.
- Failure cases and diagnostics
- The paper lacks a catalog of typical failure modes (lyric desynchronization, instrument bleed, mix balance issues, aliasing, beat drift); provide diagnostics, reproducible triggers, and mitigation strategies.
- Legal, ethical, and societal impacts
- No discussion of consent for voice cloning, artist identity protection, attribution, or revenue-sharing; propose a governance framework and measurable compliance mechanisms.
- Content moderation (toxicity, harmful content in lyrics), geographical legal constraints, and user safeguards are not addressed; integrate moderation pipelines and report efficacy.
Glossary
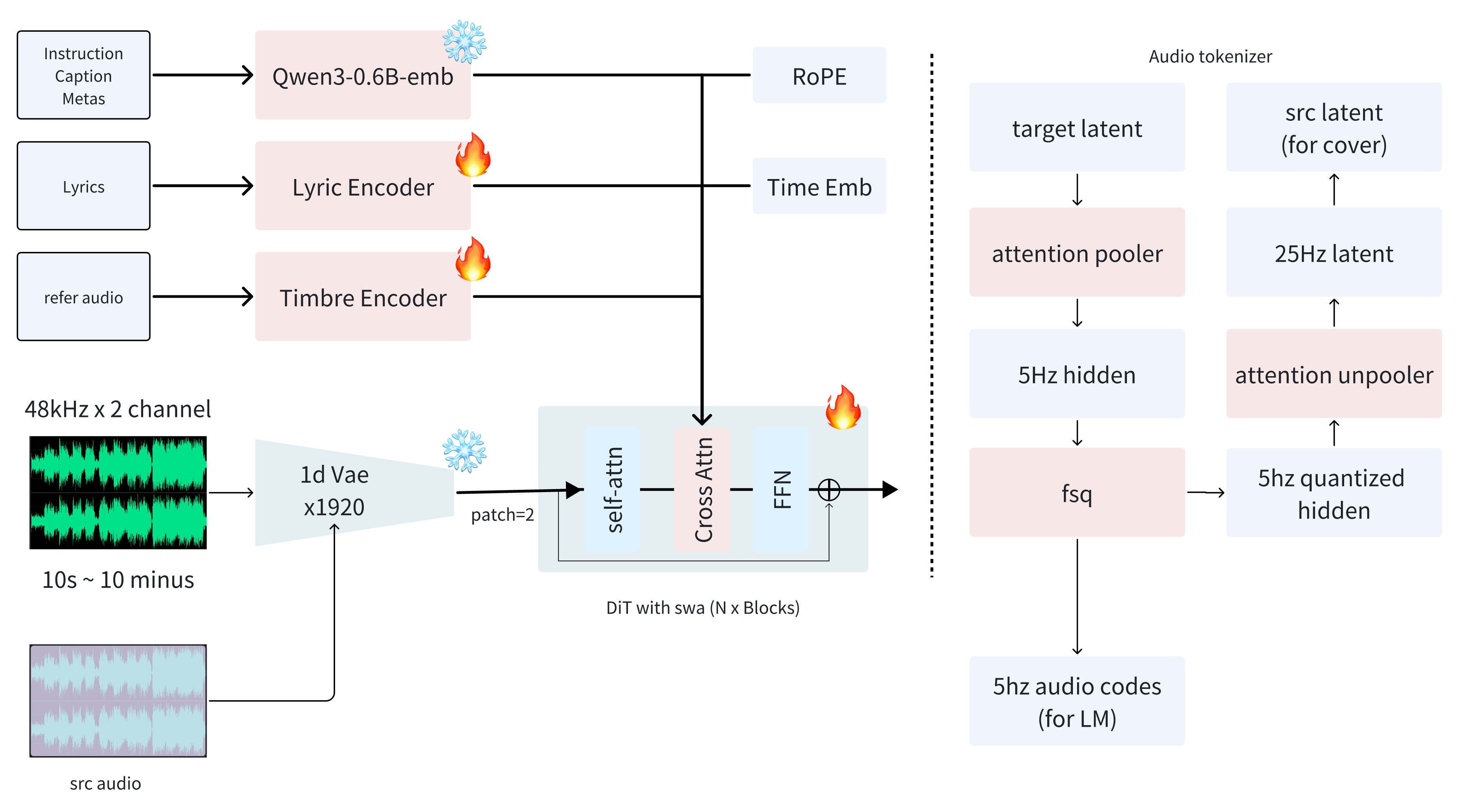
- 1D Variational Autoencoder (VAE): A generative encoder–decoder model operating directly on raw waveforms to compress and reconstruct audio with minimal perceptual loss. "we implement a pure waveform-domain 1D Variational Autoencoder (VAE)"
- 2D DCAE: A 2D denoising convolutional autoencoder baseline used for audio reconstruction comparisons. "2D DCAE baselines"
- 2D Mel-spectrograms: A time–frequency representation of audio that often loses phase information, limiting fidelity. "AceStep v1.0 relies on 2D Mel-spectrograms"
- ACE-Captioner: A specialized model fine-tuned to generate detailed music captions from audio. "yielding the base ACE-Captioner and ACE-Transcriber."
- ACE-Transcriber: A specialized model fine-tuned to transcribe lyrics or musical content from audio. "yielding the base ACE-Captioner and ACE-Transcriber."
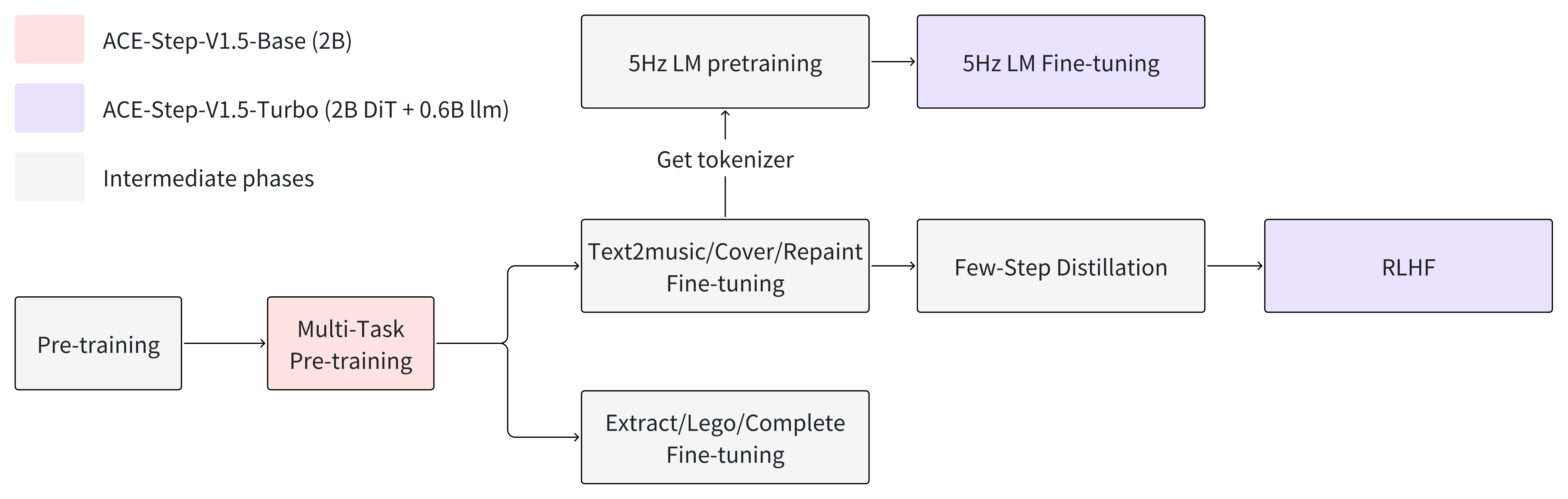
- Adversarial Dynamic-Shift Distillation: A distillation method combining adversarial training with stochastic time-step shifts to reduce diffusion steps while preserving quality. "Adversarial Dynamic-Shift Distillation"
- Adversarial tuning: Training that includes a discriminator objective to sharpen outputs and improve realism. "The model undergoes adversarial tuning for 600k steps"
- Attention Alignment Score (AAS): A metric measuring alignment between text tokens and audio frames via attention maps to improve lyric–audio synchronization. "we develop the Attention Alignment Score (AAS)"
- AudioBox: An aesthetic evaluation framework used to score generated audio. "AudioBox scores derive from Meta's aesthetic assessment framework"
- Bradley-Terry scores: A statistical model for pairwise comparisons used to aggregate human preference judgments. "Aggregating Bradley-Terry scores"
- Chain-of-Thought (CoT): Structured intermediate reasoning steps that guide planning and generation. "via Chain-of-Thought to guide the Diffusion Transformer (DiT)."
- ChatML: A structured prompt/response format for training and running chat-style LLMs. "Utilizing the ChatML template"
- Classifier-Free Guidance (CFG): A technique to control conditional generation strength without an explicit classifier. "without Classifier-Free Guidance"
- Codebook: The set of discrete tokens used to represent compressed audio latents. "(Codebook ≈ 64k)"
- Composer Agent: An LM role that plans musical structure and metadata before content generation. "function as a ``Composer Agent,''"
- Completion: A modality where the model builds a full arrangement around a given motif. "Completion (orchestrating full arrangements around a single motif)"
- ConvNeXt-based discriminator: A discriminator architecture (ConvNeXt) employed for adversarial objectives in latent space. "a ConvNeXt-based discriminator"
- Cross-Attention: An attention mechanism that injects conditioning signals (e.g., captions, timbre) into the generator. "injected via Cross-Attention"
- Curriculum learning: A staged training approach that progressively increases task complexity and data quality. "We adopt a three-phase curriculum learning strategy"
- Decoupled DMD2: A distribution matching distillation variant that separates guidance augmentation from matching objectives. "based on Decoupled DMD2"
- Decoupled Usability-Generation Architecture: A design separating high-level planning (LM) from acoustic rendering (DiT) to improve both usability and quality. "Decoupled Usability-Generation Architecture"
- Diffusion Transformer (DiT): A transformer-based diffusion model backbone for conditional audio generation. "Diffusion Transformer (DiT) scaled to approximately 2B parameters."
- DiffusionNTF: An online diffusion reinforcement learning method leveraging the forward process for reward optimization. "applying DiffusionNTF"
- Dynamic Time Warping (DTW): A sequence alignment technique used to evaluate token–frame alignment over time. "Dynamic Time Warping (DTW)"
- Finite Scalar Quantization (FSQ): A simple quantization scheme (VQ-VAE style) to discretize continuous latents. "Finite Scalar Quantization (FSQ"
- Flow Matching objectives: Training objectives that match probability flows, used here within latent-space adversarial distillation. "operating in the latent space via Flow Matching objectives."
- Foundation Pre-training: An initial broad training phase capturing general acoustic and linguistic distributions. "Foundation Pre-training"
- Global Group Query Attention (GQA): An attention mechanism variant enabling long-range consistency via grouped queries. "Global Group Query Attention (GQA)"
- GRPO (Group Relative Policy Optimization): A reinforcement learning algorithm optimizing policies via group-relative rewards. "we applied GRPO"
- Hard Negatives: Contrived examples that subtly corrupt semantics to challenge reward/model discrimination. "We generated Hard Negatives"
- Heuristic Semantic Augmentation: A strategy to create contrastive pairs by semantically altering annotations for reward modeling. "Heuristic Semantic Augmentation strategy"
- Hybrid Attention: Alternating local and global attention schemes to capture both transients and long-term structure. "Hybrid Attention mechanism"
- Hybrid Reasoning-Diffusion Architecture: A system design that pairs an LM planner with a diffusion renderer for music generation. "Hybrid Reasoning-Diffusion Architecture"
- Intrinsic RL: Reinforcement learning driven by internally derived rewards rather than external labels or human preferences. "Intrinsic RL for Aligned Control"
- KL divergence penalty: The regularization term in VAEs that encourages latent distributions to match a prior. "we eliminate the KL divergence penalty"
- Layering: Adding complementary instruments or parts to an existing track to enrich arrangement. "Layering (adding complementary instruments to a track)"
- LoRA: A lightweight parameter-efficient fine-tuning method using low-rank adapters. "users can train a LoRA from just a few songs to capture their own style."
- Masked Generative Framework: A unified formulation where masks and source latents define diverse generation/editing tasks. "a flexible Masked Generative Framework"
- Mode collapse: A failure mode in generative models where output diversity vanishes. "removing noise that contributes to mode collapse."
- Muon optimizer: An optimizer reported to improve convergence for large 1D convolutional layers. "Training is optimized via the Muon optimizer"
- Music Arena protocol: A human evaluation procedure using blind A/B testing for perceptual comparison. "we adopt the Music Arena protocol."
- Omni-Task Fine-tuning: A training phase focusing on diverse editing/manipulation tasks across modalities. "an Omni-Task Fine-tuning phase"
- Omni-Task Formulation: The unified task design enabling multiple modalities via masks and latents. "Omni-Task Formulation"
- Omni-Task Protocol: The mixture training setup with varying source/mask conditions to decouple style from melody. "introduces the Omni-Task Protocol"
- Patchify layer: A layer that segments sequences into patches to reduce effective length and improve throughput. "through a patchify layer"
- Phrygian Mode: A musical scale/mode with characteristic intervals used for stylistic instructions. "
Sidechain Compression,''Phrygian Mode,'' ``TB-303 Acid Line''" - Planner Mode: An LM interaction mode that translates vague prompts into structured blueprints and audio codes. "Planner Mode"
- Pointwise Mutual Information (PMI): A measure used to reward captions that are specific to generated audio codes. "Pointwise Mutual Information (PMI)"
- Query Rewriting: Augmenting sparse user prompts into richer queries to match training distribution and improve robustness. "for Query Rewriting"
- Repainting: Seamless regeneration of selected audio segments without altering the rest of the track. "Repainting for seamless segment regeneration"
- Reward Models: Models trained to score outputs for alignment and adherence, guiding RL optimization. "Reward Models"
- Romanization: Conversion of non-Roman scripts into phonemic/romanized forms to aid multilingual pronunciation. "stochastic Romanization strategy"
- Sidechain Compression: A mixing technique where one signal dynamically ducks another (e.g., bass ducking to kick). "
Sidechain Compression,''Phrygian Mode,'' ``TB-303 Acid Line''" - Sliding Window Attention: An attention variant focusing on local context windows to capture transients. "Sliding Window Attention"
- SongEval: An evaluation suite providing metrics like coherence, musicality, and naturalness for songs. "SongEval metrics are computed via the ASLP-lab evaluation suite."
- Source Latent: The discrete structural representation derived from quantized audio latents used to condition generation. "serving as the structural Source Latent."
- Stem Separation: Outputting isolated tracks (vocals, drums, bass, other) to support mixing and mastering. "Stem Separation"
- Stems: Isolated audio components (e.g., vocal or instrumental parts) used for reference or editing. "isolate vocal or instrumental stems."
- Stratified high-reward filtering: Selecting training samples by reward tiers to curate a high-quality fine-tuning set. "Selected via stratified high-reward filtering"
- Test-Time Scaling: Generating and ranking many candidates quickly at inference to explore the latent space. "facilitating test-time scaling"
- Timbre modeling: Capturing the color/quality of sound sources to control voice/instrument identity. "For timbre modeling, we construct a dedicated reference dataset"
- Token-to-Frame and Frame-to-Token attention maps: Cross-modal attention maps aligning text tokens with audio frames and vice versa. "Token-to-Frame and Frame-to-Token attention maps"
- Track Extraction: Isolating or reconstructing specific musical layers (e.g., drums, bass) from a mix. "Track Extraction"
- TB-303 Acid Line: A distinctive synthesizer bassline style associated with Roland TB-303, used as a technical prompt. "
Sidechain Compression,''Phrygian Mode,'' ``TB-303 Acid Line''" - YAML: A human-readable data format used to structure metadata (BPM, key, duration, sections). "in YAML format"
- Zero-shot timbre cloning: Replicating a voice/instrument’s timbral characteristics without task-specific fine-tuning examples. "robust zero-shot timbre cloning capabilities"
Practical Applications
Below is an overview of practical, real-world applications that emerge from ACE-Step v1.5’s findings, methods, and innovations. Each item specifies who can use it, where it fits, and what it depends on.
Immediate Applications
- DAW-integrated “Composer Agent” co-pilot for rapid ideation and arrangement — Sectors: music production software, media/entertainment — Tools/workflows: VST/AU plugin or Reaper/Logic/Ableton scripts that take a brief prompt, auto-generate YAML song blueprints (BPM, key, structure), and render stems via DiT; repaint segments without re-generating whole tracks — Assumptions/dependencies: GPU with ≥4GB VRAM for local inference; packaging (pip/conda installers or plugin build); clear UI for masked editing
- High-throughput stock/UGC music generation for creators and SMBs — Sectors: creator economy, advertising, podcasts, indie games — Tools/workflows: batch generation web app that explores many candidates quickly (test-time scaling), allowing users to select, repaint, and export; LoRA personalization for brand-consistent sound — Assumptions/dependencies: content licensing terms; server-side GPUs for burst workloads; lightweight LoRA training pipeline and consented user data
- Multilingual lyric-to-song and cover generation — Sectors: localization, education, karaoke apps, labels — Tools/workflows: generate songs in 50+ languages; cross-language covers with preserved melody via quantized source latents; karaoke/lyric practice tracks — Assumptions/dependencies: current lyric alignment is strong but still improving; quality varies for rare tokens/languages; rights clearance for covers
- Stem separation and vocal-to-BGM conversion for post-production — Sectors: post-production studios, podcasting, broadcasting — Tools/workflows: isolate vocals/drums/bass/others to ease mixing/mastering; convert recorded vocals to new BGM or regenerate sections with repaint — Assumptions/dependencies: stem quality may vary by genre/density; requires UI for per-stem editing; legal consent for vocal processing
- Zero-shot timbre cloning and LoRA “artist packs” — Sectors: labels, artist services, sonic branding — Tools/workflows: create timbre/reference packs from consented recordings; LoRA fine-tuning on a few songs for a consistent artist/brand sound — Assumptions/dependencies: explicit creator consent; small fine-tuning compute budget; governance for impersonation risks
- Rapid loop/variation generator for interactive media — Sectors: gaming, XR/VR, ad-tech — Tools/workflows: generate multiple 10–30s loops and complementary layers (drums, bass, pads) for adaptive scoring; quick repaint for iteration — Assumptions/dependencies: offline pre-generation recommended for strict real-time; latency dependent on device (A100/3090 numbers are upper-bound)
- Background music and sting generation for live streaming and podcasts — Sectors: live streaming, podcast platforms, conferencing — Tools/workflows: OBS/Streamlabs plugin to generate royalty-free stings, intro/outro music, and ambient loops in seconds; batch candidates for “happy accidents” — Assumptions/dependencies: low-VRAM GPU or small dedicated GPU; monitoring of loudness/limiting for broadcast standards
- Music education aides for theory and ear training — Sectors: EdTech, music schools, self-learners — Tools/workflows: generate examples in specific modes (e.g., Phrygian), keys, BPMs; style-specific backing tracks; multilingual lyric exercises — Assumptions/dependencies: relies on model’s terminology adherence; instructors curate prompts to ensure pedagogical coverage
- On-device and offline generation for connectivity-constrained contexts — Sectors: emerging markets, privacy-sensitive users, field work — Tools/workflows: packaged local app that runs under 4GB VRAM; supports offline authoring, batch candidate generation, and repainting — Assumptions/dependencies: GPU availability on end-user devices; CPU-only support would require further optimization/quantization
- Research toolkits for controllability and evaluation — Sectors: academia, R&D labs — Tools/workflows: reuse the AAS (Attention Alignment Score) for lyric–audio sync evaluation; intrinsic RL and dynamic-shift distillation recipes; LM-as-planner blueprints (YAML-based) — Assumptions/dependencies: adoption requires code/docs and standardized datasets; reproducibility needs pinned checkpoints
- Audio “diff” and versioning workflows for producers — Sectors: pro audio, post-production, media asset management — Tools/workflows: repaint-based partial edits saved as revision deltas; rapid auditioning of multiple takes for a single section — Assumptions/dependencies: DAW integration for masked selection; asset management for candidate tracking
- Usability-based procurement and benchmarking — Sectors: public funding, innovation agencies, industry consortia — Tools/workflows: adopt the paper’s 17-point Usability Checklist when evaluating generative audio systems for grants or standards — Assumptions/dependencies: community consensus on metrics; need examples and scoring rubrics
Long-Term Applications
- Real-time, reactive generative music for games/VR/AR — Sectors: gaming, XR/VR, live performance tech — Tools/products/workflows: low-latency, incremental generation/reactive arrangement that follows gameplay/biometric cues in milliseconds — Assumptions/dependencies: streaming/incremental decoding of the 1D VAE; tighter latency budgets; robust loop-seam handling
- Agentic audio editors that plan and execute multi-step edits — Sectors: pro audio software, post-production — Tools/products/workflows: LM plans complex edit sequences (key changes, arrangement swaps, stylistic shifts), DiT executes non-destructive repaints and layer additions — Assumptions/dependencies: stronger planning reliability, undo graphs, and guardrails; human-in-the-loop approvals
- Automatic video soundtrackers with structural alignment — Sectors: film/TV, advertising, social video platforms — Tools/products/workflows: LM ingests video-derived captions/beat data; AAS-like alignment ensures cue hits and lyric placements; exports stems for mixers — Assumptions/dependencies: robust video-to-music bridging; improved fine-grained temporal control; IP clearance pipelines
- Cross-lingual music dubbing and singing voice conversion — Sectors: localization, streaming platforms, labels — Tools/products/workflows: retain melody and timbre while generating new-language lyrics with tight sync; produce multi-territory releases rapidly — Assumptions/dependencies: refined lyric alignment, phoneme-level control; artist consent and contracts; QC by native speakers
- Personalized wellness and music therapy content — Sectors: digital health, meditation apps, hospitals — Tools/products/workflows: generate music tailored to mood, heart rate, or sleep stages; produce consistent sonic identities per patient — Assumptions/dependencies: clinical validation and trials; safety/efficacy studies; HIPAA/GDPR compliance and data security
- Enterprise-scale sonic branding and auditory A/B testing — Sectors: marketing, retail, fintech, mobility — Tools/products/workflows: generate large design spaces of brand-consistent stingers and ambiences; multi-variant testing with customer cohorts — Assumptions/dependencies: governance for brand safety; approval workflows; measurement pipelines linking audio variants to KPIs
- Mobile-first, fully on-device song generation — Sectors: consumer apps, creator tools — Tools/products/workflows: quantized, pruned versions for smartphone NPUs/CPUs; offline creation in travel or low-connectivity contexts — Assumptions/dependencies: heavy model compression; energy and thermal constraints; UX for long-form rendering on mobile
- Provenance, watermarking, and rights-management integration — Sectors: policy, platforms, PROs (performing rights orgs) — Tools/products/workflows: embed imperceptible watermarks and metadata about prompts/LoRAs; integrate with content ID systems — Assumptions/dependencies: standardized watermark tech; ecosystem buy-in; privacy-preserving provenance design
- Fairness and cultural coverage audits — Sectors: regulators, standards bodies, academia — Tools/products/workflows: use the Usability checklist + multilingual/style alignment metrics to audit bias/cultural coverage in generative music — Assumptions/dependencies: representative evaluation datasets; community-endorsed benchmarks; transparent reporting
- Extending intrinsic RL + LM-as-planner to other modalities — Sectors: robotics (sound planning), video generation, multimodal AI — Tools/products/workflows: planner-renderer split for video (storyboard YAML → video diffusion), or for spatial audio/robotic acoustic navigation — Assumptions/dependencies: new intrinsic rewards for each modality; data pipelines akin to the self-evolving annotation system
- MIR (Music Information Retrieval) enhancements using AAS — Sectors: karaoke, music ed-tech, catalog management — Tools/products/workflows: lyric–audio alignment scoring for automatic subtitling, karaoke scoring, and catalog QC — Assumptions/dependencies: calibration on diverse genres/languages; integration with lyric databases
- Live co-creation and performance augmentation — Sectors: concerts, DJ tools, stage tech — Tools/products/workflows: on-stage systems that follow performers’ cues (tempo/key/timbre) to generate accompaniments or transitions in near real-time — Assumptions/dependencies: robust audio input conditioning and fast response; fail-safe fallbacks and human override
- Cross-media content pipelines for studios — Sectors: large media houses, localization vendors — Tools/products/workflows: standardized YAML plans and stems feeding into asset management, version control, and collaborative review systems — Assumptions/dependencies: interoperability standards (e.g., ADM, AAF); enterprise deployment and security hardening
These applications are enabled by ACE-Step v1.5’s core advances: sub-second, high-fidelity generation on low-VRAM hardware; LM-as-planner with YAML blueprints; a masked omni-task framework for generation and editing; and intrinsic RL for controllability and multilingual adherence. Feasibility depends on packaging, UI/DAW integration, legal/ethical safeguards (consent, rights, provenance), and—especially for long-term items—further work on real-time streaming, alignment precision, and model compression.
Collections
Sign up for free to add this paper to one or more collections.