UltraEval-Audio: A Unified Framework for Comprehensive Evaluation of Audio Foundation Models
Abstract: The development of audio foundation models has accelerated rapidly since the emergence of GPT-4o. However, the lack of comprehensive evaluation has become a critical bottleneck for further progress in the field, particularly in audio generation. Current audio evaluation faces three major challenges: (1) audio evaluation lacks a unified framework, with datasets and code scattered across various sources, hindering fair and efficient cross-model comparison;(2) audio codecs, as a key component of audio foundation models, lack a widely accepted and holistic evaluation methodology; (3) existing speech benchmarks are heavily reliant on English, making it challenging to objectively assess models' performance on Chinese. To address the first issue, we introduce UltraEval-Audio, a unified evaluation framework for audio foundation models, specifically designed for both audio understanding and generation tasks. UltraEval-Audio features a modular architecture, supporting 10 languages and 14 core task categories, while seamlessly integrating 24 mainstream models and 36 authoritative benchmarks. To enhance research efficiency, the framework provides a one-command evaluation feature, accompanied by real-time public leaderboards. For the second challenge, UltraEval-Audio adopts a novel comprehensive evaluation scheme for audio codecs, evaluating performance across three key dimensions: semantic accuracy, timbre fidelity, and acoustic quality. To address the third issue, we propose two new Chinese benchmarks, SpeechCMMLU and SpeechHSK, designed to assess Chinese knowledge proficiency and language fluency. We wish that UltraEval-Audio will provide both academia and industry with a transparent, efficient, and fair platform for comparison of audio models. Our code, benchmarks, and leaderboards are available at https://github.com/OpenBMB/UltraEval-Audio.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
UltraEval-Audio: What this paper is about
Big idea in simple terms
This paper introduces UltraEval-Audio, a “one-stop test center” for AI systems that listen to and create sound. Think of it as a fair, organized report card system for voice AIs: it tests many skills (like understanding speech, translating, or speaking back), works in many languages (not just English), and shows results on public leaderboards so everyone can compare models clearly.
What questions the paper tries to answer
- How can we test many different audio AIs in the same fair, easy-to-use system?
- How can we properly judge the “audio codec” part of these AIs (the piece that compresses and rebuilds sound), not just by one score but from several angles?
- How can we evaluate audio AIs in Chinese as well as English, especially for both knowledge and language ability?
What the researchers built and how it works
A unified evaluation framework
UltraEval-Audio is like a universal scoreboard for audio AI. It:
- Covers 14 kinds of tasks across speech, music, and environmental sounds (for example: speech recognition, translation, question answering, voice cloning, and text-to-speech).
- Works in 10 languages and integrates 24 popular models and 36 trusted benchmarks.
- Offers “one-command” evaluation and public leaderboards so results are transparent and easy to compare.
In everyday terms: instead of collecting tests from lots of different places with different rules, UltraEval-Audio gives you a single, neat toolkit that runs the tests the same way for every model.
Clear task categories (a simple map of skills)
To keep things organized, tasks are grouped into:
- Audio understanding: the model listens and outputs text (like transcribing or answering questions about audio).
- Audio generation: the model creates audio (like speaking a reply or cloning a voice).
- Audio codec evaluation: tests how well the “compress-and-rebuild” part keeps the sound’s meaning and quality.
How codecs are judged (three angles)
An audio codec is like a zip file for sound: it shrinks audio into codes (tokens) and later reconstructs it. The paper evaluates codecs in three ways:
- Semantic accuracy: Does the reconstructed audio keep the original words and meaning? (Measured by WER—word error rate—using powerful speech recognizers.)
- Timbre fidelity: Does the voice still sound like the same person? (Measured by speaker similarity—how close two voice “fingerprints” are.)
- Acoustic quality: Does it sound natural and pleasant, even in noise? (Measured by automated quality models like UTMOS and DNSMOS.)
Analogy: Imagine photocopying a handwritten letter. You check if the words are still correct (semantics), if the handwriting style looks the same (timbre), and if the paper looks clean and readable (acoustic quality).
Chinese-focused tests they created
Most existing speech benchmarks are English-heavy. The authors add two Chinese benchmarks:
- SpeechCMMLU: Tests Chinese knowledge and reasoning (turns a well-known Chinese text exam into spoken form using high-quality text-to-speech, then keeps only perfectly transcribed items to ensure accuracy).
- SpeechHSK: Based on the official HSK Chinese proficiency exam’s listening section, with levels from beginner to advanced. Options are recorded by native speakers so everything is truly spoken, not just text.
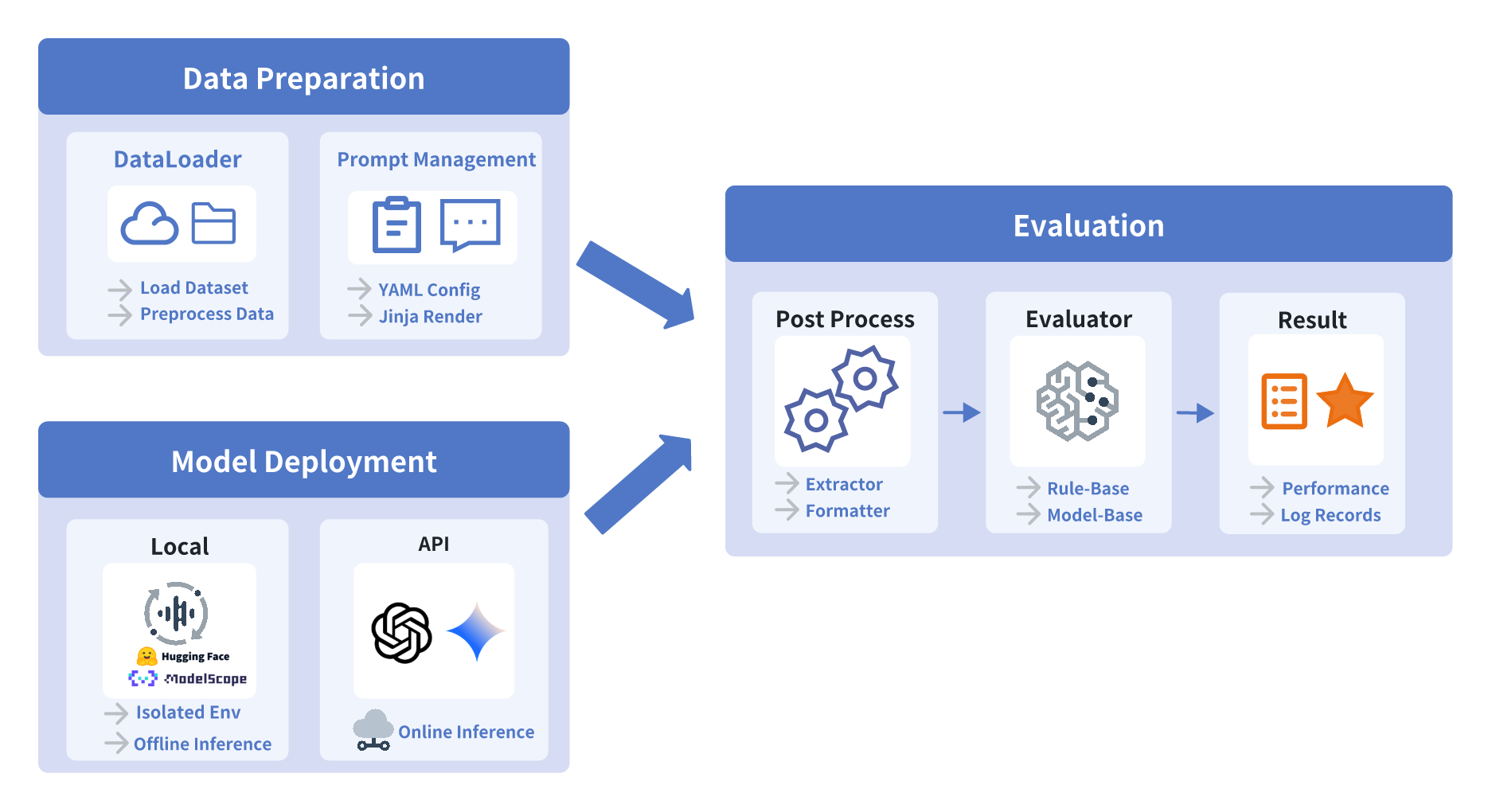
Engineering design (how they made it practical and easy)
UltraEval-Audio uses a modular, config-driven design so you don’t need to write custom code for each test:
- Data preparation: It automatically downloads, decodes, and standardizes audio from various sources so everything is in the right format.
- Prompt management: Prompts (the instructions fed to models) live in simple YAML templates. A bit like filling in a form, the system plugs in the right audio clip and question text. This keeps prompts consistent and easy to change.
- Model deployment: Different models often need different software environments. UltraEval-Audio runs each model in its own isolated “sandbox” to avoid conflicts—like giving each gadget its own charger so they don’t interfere with each other.
- Evaluation pipeline: After a model answers, the system cleans up the output (for example, pulling out A/B/C/D choices) and calculates the right metrics (like accuracy, WER, BLEU, or audio quality scores). For some open-ended tasks, it uses other strong models as judges.
What they found and why it matters
The authors:
- Built a single framework that supports 10 languages, 14 task categories, 24 models, and 36 benchmarks, with one-command evaluation and public leaderboards.
- Proposed a clear, three-part way to score audio codecs (meaning, voice identity, and sound quality) so developers can see exactly where a codec is strong or weak.
- Released two new Chinese speech benchmarks (SpeechCMMLU and SpeechHSK) to fairly test knowledge and language fluency beyond English.
- Ran evaluations and organized leaderboards for audio understanding, audio generation, and codecs, helping the community see how leading models compare across many tasks.
Why this is important:
- Fairness and clarity: Everyone gets tested the same way, so comparisons are more trustworthy.
- Faster research: A single, easy tool saves time and reduces mistakes.
- Better audio tech: The new codec scoring highlights specific issues (like losing a speaker’s unique voice), leading to better audio quality and more natural AI speech.
- Stronger multilingual support: With Chinese-focused benchmarks, progress won’t be limited to English-only systems.
What this could change in the real world
- Smarter voice assistants and chatbots: Clearer evaluations lead to better listening and speaking abilities, making AI more helpful in everyday conversations.
- More natural voices: Improved codec testing can reduce robotic-sounding speech and keep a person’s unique voice in voice cloning or translation.
- Fair global access: Stronger Chinese benchmarks encourage models that work well across languages, supporting global users in education, customer service, and accessibility tools.
- Faster innovation: Public leaderboards and easy evaluation push the field forward by showing what works and what needs improvement.
In short, UltraEval-Audio gives researchers and companies a shared, fair way to test audio AIs. It shines a light on what matters (meaning, voice identity, and sound quality), expands testing beyond English, and makes it simple to compare models—speeding up progress toward more reliable, natural-sounding, and widely useful audio AI.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed as actionable directions for future work.
- Lack of human listening evaluations: validate objective metrics (UTMOS, DNSMOS, SIM, G‑Eval) with multilingual MUSHRA/MOS studies, publish human–objective correlation analyses, and calibrate evaluators accordingly.
- ASR-mediated scoring reliability: quantify and reduce the impact of ASR errors on WER-based evaluation of generated/reconstructed audio (e.g., by using ensembles of ASR systems, confidence-weighted scoring, and accent/noise-stratified analyses).
- LLM-as-a-judge validity: release judge prompts and settings, assess inter-judge agreement, conduct bias audits (language, accent, content domain), and benchmark against human raters across tasks.
- Codec evaluation scope limited to speech: extend codec tests to music and environmental sounds with domain-appropriate metrics (e.g., instrument timbre fidelity, event detection accuracy, perceptual music quality).
- Missing prosody/expressiveness metrics: add F0 contour error, energy/rhythm measures, speaking rate, pause timing, and prosody similarity for TTS/VC/spoken QA outputs.
- Real-time and streaming performance: measure end-to-end latency, first-token delay, streaming jitter, and turn-taking quality; include barge-in handling and interruption robustness.
- Robustness to acoustic conditions: evaluate audio generation intelligibility and codec reconstruction under noise, reverberation, far‑field microphones, and device/channel mismatch.
- Safety, ethics, and misuse: include evaluations of consent and privacy in voice cloning, toxicity/abuse detection, synthetic speech watermarking/detection, and impersonation risk.
- Multilingual coverage gaps: expand Speech QA, TTS, and VC beyond English/Chinese to the claimed 10 languages; include low-resource languages, dialects, and code-switching scenarios.
- Dataset provenance and contamination: audit training data overlap with benchmarks, publish dataset versions/hashes, and provide leakage analyses to ensure fair evaluation.
- Leaderboard aggregation transparency: define task weighting, report confidence intervals, run significance testing/bootstrapping, and quantify ranking stability under metric/benchmark variations.
- Prompt sensitivity analysis: systematically vary templates and roles, report sensitivity curves, and publish a standardized prompt suite per task to enable fair cross-model comparisons.
- Inference parameter standardization: fix and report temperature, top‑p, decoder settings, and voice presets; study their effects on semantic and acoustic metrics.
- Audio captioning metrics: add CIDEr, SPICE, METEOR, and SPIDEr; validate metric choices against human judgments for non-speech audio captioning.
- Music generation/transformation tasks absent: add singing TTS, style transfer, accompaniment generation, and define reproducible music quality/timbre/structure metrics.
- SpeechCMMLU limitations: mitigate TTS-induced artifacts and voice bias by adding human-recorded prompts, multi-speaker/diverse prosody versions, dialect coverage, and expand beyond the 3,519-item subset.
- SpeechHSK limitations: address small size (170 items), ensure difficulty calibration, balance speaker/recording conditions, add conversational/spontaneous speech, and release detailed metadata.
- Codec bitrate/latency trade-offs: evaluate reconstruction quality vs. bitrate, streaming delay, computational cost, and memory footprint; publish comprehensive rate–distortion–latency curves.
- Speaker similarity metric dependence: compare multiple speaker encoders (e.g., ECAPA, x‑vectors, X‑vectors), test cross-language and gender/age robustness, and calibrate thresholds.
- Acoustic quality metric coverage: incorporate PESQ/POLQA/ViSQOL where licensing permits; compare and select metrics based on correlation to human ratings and sensitivity to artifacts typical in AFMs.
- Non-speech semantics post-codec: evaluate downstream classification/captioning/event-detection after reconstruction (e.g., SED F1/ER) to measure semantic preservation beyond speech.
- Reproducibility for proprietary models: record API versions, model snapshots/timestamps, rate limits, and nondeterminism; provide procedures to rerun and verify leaderboard entries over time.
- Post-processing robustness: publish parsers/test suites, handle multilingual tokenization and punctuation normalization; quantify how parsing choices affect scores (especially WER/CER).
- Long-form and multi-turn evaluation: test multi-minute inputs, conversational memory retention, hallucination rates over time, and incremental WER/semantic drift in extended interactions.
- Cross-modal alignment: measure consistency between generated audio and concurrent text outputs (semantic alignment, factuality) and define mismatch penalties.
- Efficiency and environmental impact: report throughput, GPU/CPU utilization, and energy/carbon costs for evaluation and inference to enable efficiency-aware comparisons.
- Leaderboard auditability: release raw outputs (audio, transcripts, scores) with usage permissions to enable third-party verification and error analysis.
- Out-of-domain generalization: include medical/legal/child voices and other OOD domains; report robustness and failure modes with stratified metrics.
- Fairness across demographics: disaggregate performance by age, gender, accent, and sociolect; identify disparities and propose mitigation strategies.
- Security/adversarial robustness: evaluate resistance to audio prompt injection, adversarial perturbations/backdoors, and develop standardized attack/defense benchmarks.
- Licensing/copyright compliance: document dataset rights, synthetic voice permissions, and redistribution constraints to ensure legal/ethical use in evaluation.
Glossary
- Acoustic quality: A perceptual dimension of generated or reconstructed audio encompassing naturalness, clarity, and listening comfort. "evaluating performance across three key dimensions: semantic accuracy, timbre fidelity, and acoustic quality."
- Audio captioning: The task of generating natural-language descriptions for non-speech audio. "such as audio captioning."
- Audio codec: A component that compresses audio into discrete representations and reconstructs it, balancing fidelity and efficiency. "Audio codecs, which serve as the backbone of AFMs, lack systematic performance metrics."
- Audio foundation models (AFMs): Large models for audio that can perform general-purpose understanding and/or generation across tasks and modalities. "audio foundation models (AFMs) with general-purpose interactive capabilities."
- Audio tokenizer: A module that converts raw audio signals into discrete tokens while preserving semantic and acoustic information. "an audio tokenizer, which converts raw audio signals into discrete tokens while preserving both semantic and acoustic information;"
- Autoregressive token prediction: Sequentially predicting the next token based on previous context in a modeling process. "an LLM backbone, responsible for contextual modeling and autoregressive token prediction;"
- Automatic speech recognition (ASR): Converting spoken audio into textual transcriptions. "automatic speech recognition (ASR) or automatic speech translation (AST)"
- Automatic speech translation (AST): Translating speech in a source language directly into text in the target language. "automatic speech recognition (ASR) or automatic speech translation (AST)"
- BLEU: A text-overlap metric used to evaluate machine translation or text generation quality. "translation and captioning tasks rely on text similarity metrics such as BLEU and ROUGE;"
- Character Error Rate (CER): A character-level error metric for ASR that measures edit distance normalized by reference length. "WER: Word Error Rate; CER: Character Error Rate;"
- ConformerASR: A speech recognition system based on the Conformer architecture used for transcribing audio. "it employs ConformerASR~\citep{gulati2020conformer} to transcribe reply audio into text before assessing answer accuracy."
- DNSMOS P.835: A non-intrusive model-based metric aligned with ITU-T P.835 to estimate speech quality, particularly under noise. "alongside DNSMOS P.835 and P.808 to evaluate speech quality in noisy environments."
- G-Eval: A GPT-based evaluation metric leveraging LLMs as automatic judges for open-ended tasks. "G-Eval: GPT-based evaluation metric;"
- Inter-process communication (IPC): Mechanisms enabling data exchange between separate processes. "Inter-process communication (IPC): The main evaluation process communicates with each model subprocess via system pipes, exchanging data and inference results securely and with low latency."
- Isolated Runtime: A deployment mechanism that runs each evaluated model in its own environment to avoid dependency conflicts and ensure reproducibility. "UltraEval-Audio introduces an Isolated Runtime mechanism ensuring environment independence and safe execution at the system level."
- Jinja templating engine: A template system used to render prompts with variables and conditional logic. "combined with the Jinja templating engine to support variable injection and conditional logic."
- LLM backbone: The LLM component that provides contextual modeling and token prediction within an audio model. "an LLM backbone, responsible for contextual modeling and autoregressive token prediction;"
- Mel distance: A measure of difference between log-Mel spectrograms of two audio signals, used as an objective reconstruction metric. "Mel distance computes the difference between the log-Mel spectrograms of reconstructed and ground truth waveforms;"
- MUSHRA: A standardized subjective listening test protocol that uses a hidden reference and a low-quality anchor for audio quality assessment. "Subjective evaluation typically follows the MUSHRA~\citep{series2014method} protocol, which uses both a hidden reference and a low anchor."
- P.808: An ITU-T recommendation for crowdsourced subjective evaluation of speech quality. "alongside DNSMOS P.835 and P.808 to evaluate speech quality in noisy environments."
- ROUGE-L: A text generation evaluation metric based on the longest common subsequence between candidate and reference. "BLEU/ROUGE-L: text generation quality;"
- Scale-Invariant Signal-to-Noise Ratio (SI-SNR): An objective metric that assesses similarity between signals while being invariant to overall scaling. "Scale-Invariant Signal-to-Noise Ratio (SI-SNR) quantifies the similarity between reconstructed and original audio while ignoring signal scale;"
- Speaker similarity (SIM): Cosine similarity between speaker embeddings to assess how well a system preserves voice characteristics. "speaker similarity (SIM) is calculated as the cosine similarity between speaker vectors of the reconstructed audio and ground truth using an embedding model."
- Speech QA: Speech question answering; evaluating or generating answers based on spoken inputs. "In audio understanding tasks, Speech QA evaluates the accuracy of textual responses."
- STOI: Short-Time Objective Intelligibility; an objective metric predicting how intelligible speech is to listeners. "STOI~\citep{taal2011algorithm} assesses speech intelligibility;"
- Text-to-speech (TTS): Synthesizing speech audio from input text. "tasks include TTS, voice clone (VC), and spoken answer generation for speech QA tasks."
- Timbre fidelity: The degree to which speaker-specific vocal characteristics are preserved in generated or reconstructed audio. "evaluating performance across three key dimensions: semantic accuracy, timbre fidelity, and acoustic quality."
- UTMOS: A neural estimator that predicts Mean Opinion Score-like naturalness of speech audio. "UTMOS~\citep{saeki2022utmosutokyosarulabvoicemoschallenge} to predict overall naturalness,"
- ViSQOL: An objective audio quality metric that approximates MOS by measuring spectral similarity to a reference. "ViSQOL~\citep{hines2015visqol,chinen2020visqol} measures spectral similarity to the ground truth as a proxy for mean opinion score;"
- Vocoder: A neural synthesizer that converts discrete audio tokens back into time-domain waveforms. "a vocoder, which synthesizes natural speech waveforms from the generated audio tokens."
- Voice clone (VC): Generating speech in a target speaker’s voice given reference audio and text or other conditions. "tasks include TTS, voice clone (VC), and spoken answer generation for speech QA tasks."
- vLLM: A high-throughput inference serving framework for LLMs. "but it requires users to manually adapt open-source audio foundation models into standardized vLLM services."
- Word Error Rate (WER): A word-level ASR error metric based on edit distance normalized by the reference length. "ASR uses word error rate (WER) or character error rate (CER);"
- YAML-based configurations: Human-readable configuration files used to declaratively specify prompts, datasets, and pipelines. "Prompt structures are defined using YAML-based configurations and combined with the Jinja templating engine"
Practical Applications
Immediate Applications
The following items translate UltraEval-Audio’s current capabilities into deployable use cases across sectors. Each bullet highlights the sector, potential tools/workflows, and key assumptions or dependencies.
- Model selection and A/B benchmarking for voice products (software, telecom, customer support)
- What: Use UltraEval-Audio’s one-command evaluation and public leaderboards to compare ASR, AST, TTS, VC, and spoken QA performance across 24+ models and 36 benchmarks; choose the best model for a given market or feature.
- Tools/workflows: CI-integrated “Audio Model Benchmark” job; vendor scorecards; regression dashboards per release.
- Assumptions/dependencies: Requires access to model APIs or local weights; compute resources (GPU for local inference); prompt templates must be controlled for fair comparison; evaluator dependencies (Whisper-v3, Paraformer-zh, UTMOS, DNSMOS, WavLM) must be installed and version-pinned.
- Continuous regression testing for voice assistants (software/robotics)
- What: Add UltraEval-Audio as a gating check in CI/CD to prevent performance regressions on speech understanding/generation tasks.
- Tools/workflows: YAML/Jinja prompt registry for consistent prompts; isolated runtimes for dependency-safe multi-model testing; post-processing modules for stable metric computation (WER, BLEU, SIM, UTMOS).
- Assumptions/dependencies: Stable dataset snapshots (HuggingFace or local mirrors); reproducible runtime isolation (containers/subprocess IPC); consistent ASR back-ends for WER-based scoring.
- Codec evaluation and selection for communications and streaming (telecom, conferencing, media platforms)
- What: Use the 3D codec evaluation (semantic accuracy, timbre fidelity, acoustic quality) to select codecs/bitrates for real-time calls, conferencing, and streaming.
- Tools/workflows: “Codec Quality Dashboard” summarizing WER, speaker SIM, UTMOS/DNSMOS; bitrate–quality trade-off studies; per-device profile selection.
- Assumptions/dependencies: Objective metrics approximate human perception (MOS proxies); scenario representativeness (clean vs noisy); licensing for evaluation codecs.
- Chinese market readiness checks (education, public sector, consumer platforms)
- What: Validate Chinese knowledge and fluency using SpeechCMMLU (knowledge reasoning) and SpeechHSK (language proficiency).
- Tools/workflows: “Chinese Readiness Report” for procurement; HSK-level coverage analysis; targeted remediation (prompt tuning, fine-tuning).
- Assumptions/dependencies: Benchmarks leverage high-quality TTS (CosyVoice2) and ASR-based QC; synthetic speech approximates real user speech; distributional match to target users may vary.
- Localization and dubbing QA (media/entertainment)
- What: Benchmark AST and TTS quality for dubbing/localization workflows; ensure intelligibility and naturalness in target languages (e.g., English ↔ Chinese).
- Tools/workflows: Automated BLEU/ROUGE for translations/captions; UTMOS/DNSMOS for TTS outputs; SIM for voice-match in voice cloning.
- Assumptions/dependencies: ASR-based scoring for generated speech introduces evaluator bias; need domain-specific text scripts for realistic testing.
- Contact center voicebot benchmarking (finance, retail, telecom)
- What: Evaluate speech QA benchmarks (e.g., SpeechTriviaQA, SpeechWebQuestions) as proxies for spoken instruction-following and knowledge retrieval.
- Tools/workflows: Scenario-specific evaluation suites (billing, KYC, troubleshooting); prompt templates aligned with SOPs; performance alerts on drift.
- Assumptions/dependencies: Knowledge coverage alignment between public benchmarks and enterprise FAQs; LLM-as-a-judge settings (if used) must be consistent.
- Environmental sound analytics validation (smart home, safety, IoT)
- What: Assess sound event classification and captioning for alarms, domestic scenes, and safety-critical events.
- Tools/workflows: Audio classification/captioning dashboards (DESED, CatDog, AudioCaps/Clotho); model comparison for edge vs cloud deployment.
- Assumptions/dependencies: Dataset distribution may not match specific device acoustics; on-device compute constraints.
- Academic reproducibility and leaderboard contributions (academia)
- What: Submit new AFMs/codecs to standardized leaderboards; reproduce baselines; report across 14 task categories and 10 languages.
- Tools/workflows: Paper-ready evaluation tables; standardized YAML configs; artifact release with prompts and seeds.
- Assumptions/dependencies: Respect dataset licenses; report evaluator versions; disclose prompt templates.
- Rapid creation of domain speech benchmarks via TTS+ASR QC (industry/academia)
- What: Convert text QA/knowledge datasets to speech (as done for SpeechCMMLU) for domain-specific evaluation (e.g., healthcare FAQs, banking compliance).
- Tools/workflows: TTS synthesis, ASR verification (CER/WER=0 filtering), pipeline scripts; domain coverage analysis.
- Assumptions/dependencies: Synthetic audio approximates real-call conditions; speaker/accent diversity must be curated; TTS licenses.
- Creator workflows for TTS/voice cloning selection (media, content)
- What: Compare TTS/VC models for narration and voice branding using WER, SIM, and UTMOS.
- Tools/workflows: “Narration Quality Check” reports; voice consistency tracking over episodes; codec checks for platform delivery.
- Assumptions/dependencies: Objective metrics correlate with listener preferences; brand-specific timbre preferences may require human review.
- Procurement and policy-aligned scorecards (public sector, enterprises)
- What: Use leaderboards and standardized metrics to set minimal thresholds for multilingual speech systems (e.g., Chinese speech fluency, ASR accuracy).
- Tools/workflows: RFP annex with required benchmarks/metrics; acceptance tests using one-command evaluation.
- Assumptions/dependencies: Benchmarks reflect target population; transparent reporting of evaluator configurations to avoid gaming.
Long-Term Applications
These items are feasible with further research, scaling, or development, building on UltraEval-Audio’s framework and methodology.
- Standards and certification programs for audio AI (policy, standards bodies)
- What: Formalize UltraEval-Audio taxonomy/metrics into compliance standards (e.g., “ASR-WER ≤ X on dataset Y; UTMOS ≥ Z on TTS tests”).
- Tools/products: “Certified Multilingual Audio Assistant” label; audit procedures; model cards referencing standardized tasks.
- Assumptions/dependencies: Community consensus on metric suites; inclusion of subjective MOS panels for final certification.
- Fairness and multilingual equity audits (policy, enterprise governance)
- What: Expand beyond English/Chinese to broader languages using the same TTS+ASR QC pipeline; audit performance gaps across accents and dialects.
- Tools/products: Fairness dashboards; accent/dialect coverage maps; remediation playbooks (data augmentation, prompt variants).
- Assumptions/dependencies: High-quality TTS/ASR for target languages; culturally valid evaluation rubrics; privacy-respecting data collection.
- Real-time, end-to-end conversational metrics (telecom, robotics, assistants)
- What: Extend evaluation to measure latency, turn-taking, barge-in handling, and streaming quality (bitrate–latency–quality trade-offs).
- Tools/products: “Realtime Conversational KPI Suite”; hardware-in-the-loop testing on edge devices.
- Assumptions/dependencies: Instrumented clients; standardized logging; synchronization across ASR/LLM/TTS components.
- Evaluation-driven model training and autoprompting (ML research, MLOps)
- What: Use UltraEval-Audio metrics as reward signals for RLHF/RLAIF or automated prompt optimization to close benchmark gaps.
- Tools/products: “AutoPrompt for Audio Tasks” using YAML/Jinja registries; evaluation-as-feedback loops.
- Assumptions/dependencies: Stable correlation between automatic metrics and human preferences; guardrails to prevent overfitting to benchmarks.
- Healthcare-grade validation of voice AI (healthcare)
- What: Develop domain-specific clinical speech benchmarks (e.g., medical dictation under clinical noise; patient–provider dialogue) and pathway to regulatory approval.
- Tools/products: Clinical-grade evaluation suites; bias and safety checks (e.g., emotion misclassification); secure PHI handling.
- Assumptions/dependencies: IRB processes, de-identified datasets, clinical annotation; human MOS and clinical efficacy studies.
- On-device optimization and energy–quality trade-offs (edge AI, mobile)
- What: Add energy/compute footprint to codec and model evaluations; produce Pareto frontiers for quality vs latency vs battery.
- Tools/products: Device-targeted “Model Fit Planner”; dynamic codec/model selection at runtime.
- Assumptions/dependencies: Reliable power/latency telemetry; hardware diversity; model quantization support.
- Safety and misuse evaluation for audio generation (platform policy, security)
- What: Extend benchmarks to cover deepfake risks, unauthorized voice cloning, and content manipulation, leveraging timbre similarity and detection models.
- Tools/products: “Voice Clone Risk Index”; detection thresholds; policy-aligned guardrails testing.
- Assumptions/dependencies: Robust spoofing datasets; calibrated detection metrics; evolving threat models.
- Data-centric pipeline for continual benchmark refresh (industry/academia)
- What: Automate periodic updates of speech benchmarks (new topics, accents, background noise) to reduce benchmark saturation.
- Tools/products: “Living Benchmarks” service; dataset governance and versioning; drift-aware score normalization.
- Assumptions/dependencies: Sustainable data sourcing; legal/ethical approvals; reproducible synthesis and QC.
- Cross-domain multimodal audio evaluation (media, ambient intelligence)
- What: Deeper coverage for music and environmental sounds (genre recognition, chord detection, scene understanding) tied to production and smart environments.
- Tools/products: Music production QA suites; smart building sound analytics validation kits.
- Assumptions/dependencies: Expanded, licensed datasets; task-specific subjective metrics; creator and user studies.
- Marketplace and procurement ecosystem for audio models/codecs (enterprise IT)
- What: A catalog where vendors publish UltraEval-Audio-comparable results and downloadable YAML configs/prompts for verification.
- Tools/products: “Audio AI Model Cards” with standardized evidence; verifiable evaluation bundles.
- Assumptions/dependencies: Vendor participation; anti-gaming mechanisms; third-party verification services.
- Education: personalized language learning agents (edtech)
- What: Use SpeechHSK-level profiling to route learners to appropriate content and evaluate progress via spoken tasks.
- Tools/products: “HSK Tutor Bench” for periodic assessment; adaptive TTS/ASR pipelines for feedback.
- Assumptions/dependencies: Validity of automatic scores for pedagogy; inclusivity across accents and speech conditions.
Notes on overarching assumptions and dependencies:
- Metric validity: Objective proxies (WER, UTMOS, DNSMOS, SIM) approximate but do not replace human judgments; domain-specific human evaluations may still be needed.
- Evaluator bias: Results depend on the chosen ASR/evaluator models, versions, and settings; disclosures and version pinning are essential.
- Prompt sensitivity: Performance can vary with prompt templates; the YAML/Jinja registry supports control, but rigorous prompt governance is required.
- Synthetic-to-real gap: Benchmarks created via TTS+ASR QC need careful design to reflect real user speech (noise, accents, spontaneity).
- Legal and licensing: Respect dataset and model licenses, privacy requirements, and regional data governance.
Collections
Sign up for free to add this paper to one or more collections.