CoF-T2I: Video Models as Pure Visual Reasoners for Text-to-Image Generation
Abstract: Recent video generation models have revealed the emergence of Chain-of-Frame (CoF) reasoning, enabling frame-by-frame visual inference. With this capability, video models have been successfully applied to various visual tasks (e.g., maze solving, visual puzzles). However, their potential to enhance text-to-image (T2I) generation remains largely unexplored due to the absence of a clearly defined visual reasoning starting point and interpretable intermediate states in the T2I generation process. To bridge this gap, we propose CoF-T2I, a model that integrates CoF reasoning into T2I generation via progressive visual refinement, where intermediate frames act as explicit reasoning steps and the final frame is taken as output. To establish such an explicit generation process, we curate CoF-Evol-Instruct, a dataset of CoF trajectories that model the generation process from semantics to aesthetics. To further improve quality and avoid motion artifacts, we enable independent encoding operation for each frame. Experiments show that CoF-T2I significantly outperforms the base video model and achieves competitive performance on challenging benchmarks, reaching 0.86 on GenEval and 7.468 on Imagine-Bench. These results indicate the substantial promise of video models for advancing high-quality text-to-image generation.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-language summary of “CoF-T2I: Video Models as Pure Visual Reasoners for Text-to-Image Generation”
What is this paper about?
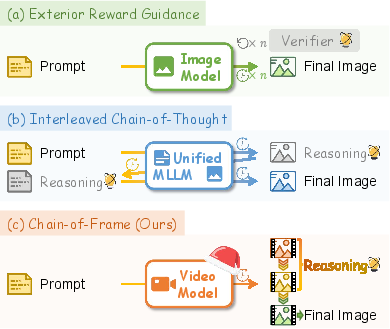
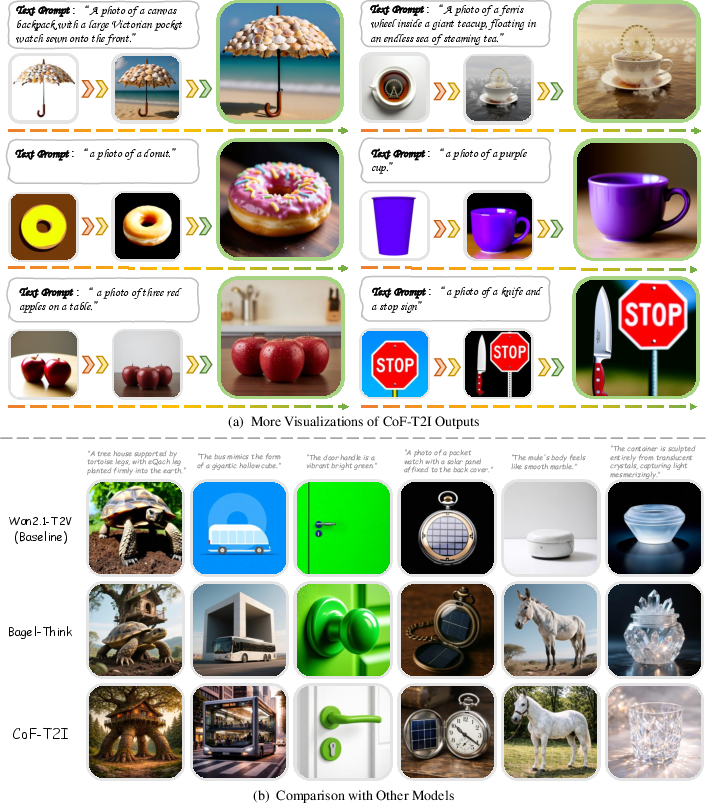
This paper shows a new way to make pictures from text using video-making AI. Instead of making a single image all at once, the AI thinks visually in steps, like an artist sketching a rough draft, fixing the important parts, and then polishing the details. The authors call this Chain-of-Frame (CoF) reasoning: the AI creates a short “mini-video” of 3 frames where each frame is a clearer, better version of the last. Only the final frame is shown as the finished picture.
What were the authors trying to do?
The authors asked a simple question: Can a video model, which already knows how to build scenes step-by-step across frames, be used as a pure visual thinker to make better single images from text?
To do that, they set three clear goals:
- Turn text-to-image generation into a visual step-by-step process (draft → refine → final).
- Build training data that shows these steps clearly, from getting the meaning right to polishing the look.
- Make the system produce high-quality images without weird “motion” artifacts that video models sometimes create.
How did they do it? (Methods explained simply)
Think of the model like a careful artist working in three passes:
- Frame 1: a rough draft that gets the main idea and layout.
- Frame 2: a refined version that fixes mistakes (like wrong colors or missing objects).
- Frame 3: the final, high-quality image with clean details and nice lighting.
Key ideas behind the method:
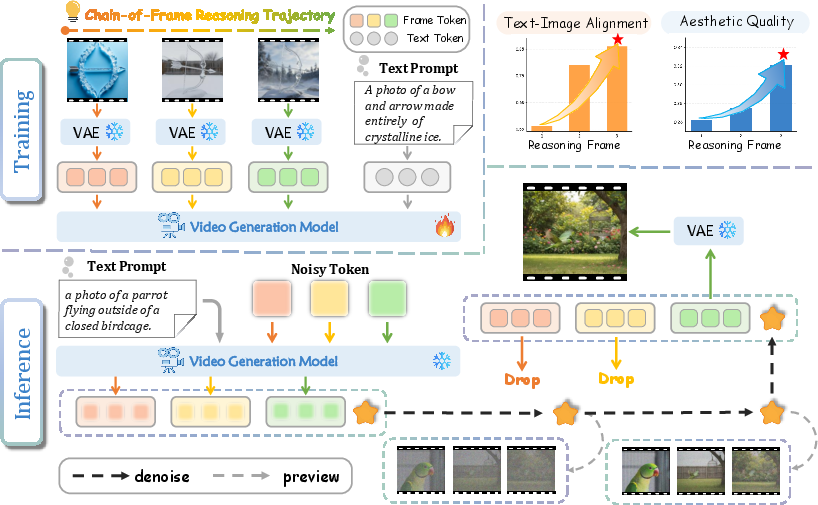
- Using a video model as a “visual reasoner”: Video models are good at improving scenes over time (frame by frame). The authors ask the model to produce just three frames that get better step by step, then they keep only the last frame as the output image.
- A special “camera for data” (VAE) that compresses and decompresses images: Normally, video VAEs compress frames together over time, which can cause tiny wobbles or flickers between frames. To avoid this, the authors compress each frame separately so every step stays crisp and independent.
- A “straight path from noise to image” (rectified flow): When creating images from random noise, the model learns a simple, direct route from noise to the target picture. You can think of it like teaching the model the shortest, smoothest path to reach the final image.
They also created a new dataset to teach the model the right kind of step-by-step thinking:
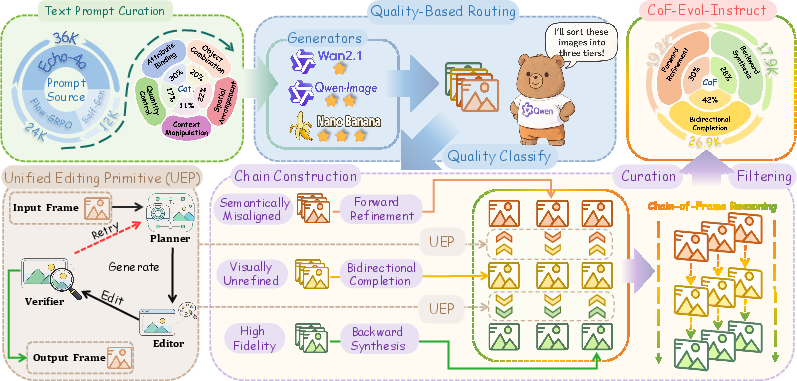
- CoF-Evol-Instruct: 64,000 three-step “mini-videos” that show how an image should evolve from meaning-first to beauty-polished.
- How they built it: They gathered prompts and images from several text-to-image systems (weak, medium, strong). An AI judge sorted images into three groups: “meaning is wrong,” “meaning is right but looks rough,” and “looks great.” Then, using careful AI editing tools, they expanded each one into a 3-frame sequence:
- Forward: messy → okay → great
- Bidirectional: build both a rougher version and a nicer version around the middle
- Backward: great → simpler → slightly flawed
- This keeps the steps realistic and consistent, like undoing or redoing edits in a smart way.
What did they find, and why does it matter?
Main results (higher is better):
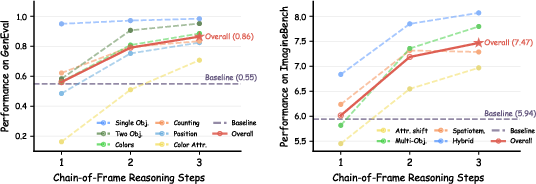
- On GenEval (tests object correctness, counting, colors, positions), CoF-T2I scored 0.86 overall.
- On Imagine-Bench (tests creative, compositional prompts), CoF-T2I scored 7.468 overall.
Why this is important:
- It beats the original video model it was built on by a large margin, showing that “visual step-by-step thinking” really helps.
- It performs competitively with methods that rely on language-based planning, but it does so using only images (no extra text reasoning during generation). That means cleaner, more direct fixes at the pixel level.
- The quality improves from frame 1 to frame 2 to frame 3 in a steady way, proving the step-by-step approach really works as intended.
- Removing the middle steps or not encoding frames independently makes the results worse, showing both choices are necessary.
What could this change in the future?
- Better, more reliable text-to-image tools: Because the model “thinks” visually in steps, it can fix mistakes and sharpen details more consistently.
- Easier debugging and control: The visible middle steps show what went wrong and how it was fixed, making the process more understandable and tunable.
- A new direction for image generation: Instead of relying on language reasoning to guide images, video-style visual reasoning can provide a powerful, purely visual pathway to higher quality.
In short, this paper suggests a simple but strong idea: let video models do what they’re best at—improving visuals frame by frame—to create better single images from text. The three-step “draft → refine → final” process makes images more accurate and beautiful, and could help future systems be both higher quality and easier to control.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains uncertain or unexplored, to guide future research:
- Generalization beyond the Wan2.1 backbone: Does CoF-T2I transfer to other video architectures (e.g., different DiT variants, 3D U-Nets, MMDiT) and pretraining corpora without bespoke engineering?
- Fixed three-step reasoning: How does performance vary with variable-length chains (2, 4, 5+ frames), adaptive stopping, or confidence-gated termination at inference time?
- Efficiency and latency trade-offs: What is the compute/memory overhead of denoising multi-frame latents vs single-image models, and how do throughput/latency scale with steps and resolution?
- Aspect ratio and resolution robustness: The pipeline standardizes to 1024×1024; how well does the method generalize to diverse aspect ratios and higher resolutions (e.g., 2K–4K) without subject truncation or quality regressions?
- Dataset contamination risk: Prompts “adapted from GenEval” were used for training; was train–test overlap fully eliminated? If not, what is the impact on reported benchmark scores?
- Verifier/editor dependence and bias: The routing and UEP rely on Qwen3-VL (8B/32B) and Qwen-Image-Edit; how sensitive are trajectories to these specific models’ biases and failure modes? Does swapping assessors/editors change outcomes?
- Reliability of “monotonic improvement”: Beyond averages, what fraction of prompts exhibits non-monotonic frames (regressions between F2→F3)? Can we detect and correct such regressions online?
- Interpretability of intermediate states: Do F1, F2 consistently encode “semantic” then “aesthetic” phases across prompt types, or do these roles drift by category? Can we quantify interpretability (e.g., via semantic consistency and perceptual metrics per frame)?
- Diversity vs alignment: Does CoF reasoning reduce sample diversity (mode collapse) while boosting alignment? Quantify changes in diversity (e.g., CLIP embedding dispersion, LPIPS across seeds).
- Long-tail robustness: How does the method handle rare concepts, fine-grained attributes, and open-vocabulary prompts? What is the performance on multilingual prompts beyond English?
- Text rendering and OCR: The ability to generate legible, instruction-following text within images is untested; how does CoF-T2I perform on text-in-image benchmarks?
- Safety and content moderation: No safety audits were reported; what are toxicity, bias, and unsafe content rates, and can CoF steps be steered for safer outcomes?
- Combining visual and textual reasoning: Can CoF visual refinement be integrated with textual CoT or external verifiers/RM to yield additive gains, and under what coupling schemes (e.g., intermittent reward shaping, RLHF)?
- Scaling laws for CoF-Evol-Instruct: How do performance and stability scale with dataset size, step balance (F1/F2/F3 ratios), and prompt category distributions?
- Ablations of the construction pipeline: What is the marginal contribution of each component (quality routing, forward vs bidirectional vs backward strategies, category conditioning, retry budget K) to final performance?
- Independent frame encoding design: Are there hybrid encoders (e.g., partial temporal conditioning, cross-frame attention with masks) that retain fidelity while avoiding motion artifacts better than full independence?
- Use of intermediate latents at inference: Can leveraging F1/F2 latents (e.g., through skip connections or ensemble decoding) further improve final fidelity or enable interactive refinement?
- Hard compositional phenomena: Evaluate on negation (“without”), relational chains, deeper spatial logic, and cluttered scenes; what failure patterns persist and how can they be targeted?
- Counting beyond small numbers: How does performance degrade with higher counts (e.g., 10–50 objects) and dense crowds?
- Failure mode taxonomy: A systematic analysis (with examples) of where CoF-T2I fails (e.g., attribute binding, occlusion, lighting consistency) is missing; which errors originate in F1 vs are introduced later?
- Reproducibility details: Key inference hyperparameters (sampler specifics, steps, seeds), training compute budget, and exact filtering rules for prompts/outputs are under-specified; releasing these would enable rigorous replication.
- Comparative breadth and fairness: Include stronger 2025 baselines and human preference evaluations (e.g., HPSv3), matched compute budgets, and report CIs across multiple seeds.
- Energy and cost accounting: What are the training/inference energy footprints versus image-only baselines, and how does CoF length affect cost-effectiveness?
- Conditional controls and editing: How does CoF-T2I interact with control signals (depth, pose, sketches, masks) and with image editing tasks where preservation constraints are strict?
- Domain transfer: Robustness on non-natural domains (e.g., diagrams, charts, medical, satellite) is unknown; what adaptations are needed?
- Extending to video and multi-view: Can CoF reasoning for images transfer to consistent multi-view or video generation (e.g., using F3 as an anchor), and what modifications are required for temporal coherence?
- Licensing and data governance: The dataset uses images synthesized by third-party models; what are the licensing constraints and redistribution policies for CoF-Evol-Instruct, and are the data and code publicly released?
Glossary
- Aesthetic coherence: Consistent and pleasing visual harmony across an image; "High Fidelity () for images achieving both high semantic accuracy and aesthetic coherence."
- Aesthetic refinement: Targeted improvement of visual details and style quality; "(e.g., semantic grounding, aesthetic refinement) while strictly preserving non-target content."
- Attribute Binding: Correct association of attributes (e.g., color) with specific objects; "including five categories: Attribute Binding, Object Combination, Spatial Arrangement, Context Manipulation, and Quantity Control."
- Backward synthesis: Constructing earlier, less-refined states from a final high-fidelity image; "Backward Synthesis ()."
- Bidirectional completion: Expanding an intermediate image both forward (refinement) and backward (controlled degradation) to form a full sequence; "Bidirectional Completion ()."
- Causal spatiotemporal compression: Encoding that respects temporal order to compress video across space and time; "applies causal spatiotemporal compression to raw video frames."
- Causal VAE: A variational autoencoder whose encoding/decoding respects causal temporal ordering; "Only the terminal latent state ...is projected into the visual space using the decoder of the native causal VAE."
- Category-conditioned semantic perturbation: Minimal prompt-specific changes to semantics (e.g., counts, attributes) for controlled degradation; "introduce minimal, category-conditioned semantic perturbation (e.g., altering count, degrading attributes)."
- Chain-of-Frame (CoF) reasoning: Frame-by-frame visual inference that progressively refines scenes; "Recent video generation models have revealed the emergence of Chain-of-Frame (CoF) reasoning, enabling frame-by-frame visual inference."
- Closed-loop system: A pipeline where planner, editor, and verifier iteratively ensure targeted edits succeed; "UEP is implemented as a closed-loop system with three agents: a planner and verifier...and an editor."
- Denoising: Predicting and removing noise to move latents toward the data manifold; "the model predicts the denoising targets for the latent sequence ."
- DiT parameters: Trainable weights of a Diffusion Transformer backbone for generative modeling; "updating only the unfrozen DiT parameters."
- End-to-end optimization: Training the whole generation pipeline jointly from inputs to outputs; "refine earlier ones through end-to-end optimization."
- Flow matching objective: A training loss that learns a velocity field to transport noise to data along straight paths; "optimize a vanilla flow matching objective."
- Frame-wise representation: Encoding each frame independently to avoid entangled temporal artifacts; "we employ a frame-wise representation that encodes each frame independently in the latent space."
- Gaussian noise: Standard normal noise used as the starting point for generative sampling; "starting from Gaussian noise."
- GenEval: An object-centric benchmark for prompt following and composition; "reaching 0.86 on GenEval."
- Imagine-Bench: A benchmark stressing imaginative prompts and compositional reasoning; "7.468 on Imagine-Bench."
- Inference-time reasoning: Performing reasoning steps during generation rather than only at training; "the frontier of text-to-image (T2I)...has shifted toward inference-time reasoning."
- Joint probability distribution: A learned distribution over entire latent sequences conditioned on a prompt; "learning the joint probability distribution of the entire latent trajectory."
- Latent representation: Compressed feature space produced by the VAE for frames; "This yields a latent representation with 8 × spatial downsampling and 4 × temporal downsampling."
- Latent sequence: Ordered set of latent frames representing reasoning steps; "the latent sequence ."
- Latent trajectory: The full path of latents evolving from coarse to refined states; "the joint probability distribution of the entire latent trajectory."
- Multimodal LLMs (MLLMs): Unified models handling both language and vision modalities; "interleaving textual planning within unified multimodal LLMs (MLLMs)."
- Probability density: The model’s learned density over latent sequences; "Here, is the probability density over latent sequences."
- Rectified Flow: A method that learns a straight transport from noise to data via a velocity field; "Our model adopts Rectified Flow to model a straight path from noise () to a complex data distribution () by learning a velocity field."
- Semantic alignment: Agreement between generated content and prompt semantics; "semantic alignment, perceptual fidelity, and visual coherence are jointly refined at each step."
- Semantic defects: Errors such as missing objects or incorrect attributes in initial generations; "anticipate potential semantic defects and progressively refine aesthetic details."
- Semantic grounding: Ensuring the image accurately reflects the prompt’s core semantics; "stage transition (e.g., semantic grounding, aesthetic refinement)."
- Semantic perturbation: Intentional minimal changes to semantics to synthesize draft states; "introduce minimal, category-conditioned semantic perturbation."
- Spatiotemporal prior: Learned assumptions about coherent structure across space and time; "refine scenes frame by frame under a strong spatiotemporal prior."
- Temporal downsampling: Reducing the number of frames in the latent encoding; "4 × temporal downsampling."
- Text-image alignment: Degree to which image content matches the textual prompt; "text-image alignment and aesthetic quality continue to improve."
- Unified Editing Primitive (UEP): A standardized, controllable operation for stage-specific edits; "we introduce a unified editing primitive (UEP) as the shared minimal operation across all strategies."
- Velocity field: The vector field indicating direction from noisy samples to data in flow models; "by learning a velocity field."
- Video foundation models: Large pretrained video generators used as visual reasoners; "Video foundation models are inherently powerful visual learners and reasoners."
- Video VAE: A variational autoencoder tailored to encode/decode video frames; "we employ a video VAE to encode each frame."
- Visual self-correction: Iterative improvement of semantics and details across reasoning steps; "CoF-T2I enables iterative visual self-correction, in which semantic alignment, perceptual fidelity, and visual coherence are jointly refined."
Practical Applications
Below is an overview of practical applications enabled by the paper’s findings and methods, organized by immediacy and linked to sectors, potential tools/products/workflows, and feasibility notes.
Immediate Applications
These can be prototyped or deployed with existing video backbones and the provided training/data curation methods.
- CoF-powered T2I engines with visible reasoning steps
- Sectors: software, creative media, advertising, e-commerce
- What: Integrate CoF-T2I into image-generation products to return both the final image and optionally decoded intermediate frames (draft → refine → final) to improve prompt-following, fix attribute bindings, spatial relations, and counting.
- Tools/Products: “Reasoned T2I” API; UI panels that preview F1/F2/F3 for quick in-tool diagnosis and correction.
- Assumptions/Dependencies: Access to a video backbone (e.g., Wan2.1) and its VAE; GPU capacity at 1024×1024; licensing for base models and any editing LMMs.
- Prompt debugging and QA for content studios
- Sectors: creative media, marketing, design agencies
- What: Use the three-step trajectory to identify at which stage semantics fail (e.g., missing objects at F1 vs. attribute errors at F2) and auto-adjust prompts or seed settings.
- Tools/Products: “Prompt Doctor” assistant that flags root causes and suggests prompt rewrites.
- Assumptions/Dependencies: Decoding intermediate latents for visualization; simple rules or LMM heuristics for error attribution.
- Automated visual refinement loop in production pipelines
- Sectors: advertising, e-commerce, product photography
- What: Embed CoF reasoning in batch pipelines to raise semantic alignment (e.g., color/quantity/position) and aesthetic quality for catalog and campaign imagery, reducing human retouch cycles.
- Tools/Products: Batch asset “CoF-Refine” job with acceptance thresholds (e.g., GenEval proxies).
- Assumptions/Dependencies: Domain adaptation for brand palettes/backgrounds; guardrails for IP/safety policies.
- Controllable image editing via the Unified Editing Primitive (UEP)
- Sectors: imaging software, social media, design tools
- What: Deploy UEP’s planner–editor–verifier loop to perform targeted edits (attribute binding, object addition/removal, quantity control) with minimal collateral change.
- Tools/Products: “Smart Edit” brush or API; category-conditioned edit macros (Attribute/Combination/Quantity/Spatial/Context).
- Assumptions/Dependencies: Qwen3-VL and Qwen-Image-Edit availability or equivalents; success retries and latency budget.
- Synthetic dataset generation for compositional reasoning
- Sectors: academia, model vendors, MLLM training
- What: Use the CoF-Evol-Instruct pipeline to create high-quality, progressive visual reasoning chains for training/fine-tuning T2I, editing models, or VLMs that require compositional data.
- Tools/Products: “CoF-Evol” data factory with quality-based routing and category labels.
- Assumptions/Dependencies: Access to a quality assessor (e.g., Qwen3-VL-8B), multiple T2I model tiers, and editing models; deduplication and prompt governance.
- Better evaluation and acceptance testing for T2I deployments
- Sectors: software, procurement, ML Ops
- What: Adopt GenEval/Imagine-Bench tracking and per-frame scoring curves (F1→F2→F3) to gate model updates and measure real semantic improvements, not just aesthetics.
- Tools/Products: CI/CD “Reasoning Curve” dashboards; regression checks on composition, counting, and spatial relations.
- Assumptions/Dependencies: Benchmark harnesses; consistent random seeds; resolution parity.
- Explainable generation for audits and client review
- Sectors: enterprise creative ops, policy/compliance
- What: Store intermediate frames as an “audit log” of the generation process to facilitate approval workflows and post-hoc analysis.
- Tools/Products: “Visual Reasoning Trace” attachments in DAM (Digital Asset Management) systems.
- Assumptions/Dependencies: Policy to retain or discard intermediate latents; privacy/IP guardrails.
- Domain-adaptive fine-tuning with intermediate supervision
- Sectors: fashion, automotive, architecture, gaming
- What: Fine-tune CoF-T2I on domain prompts/assets to improve layout accuracy (e.g., furniture placement, product variants) and reduce hallucinations.
- Tools/Products: Lightweight SFT with three-frame supervision; independent frame encoding to avoid motion artifacts.
- Assumptions/Dependencies: Domain-specific prompts/images; compute budget; careful hyperparameter alignment at 1024×1024.
- Educational use: teaching visual composition and reasoning
- Sectors: education, design instruction
- What: Use F1→F2→F3 to demonstrate how semantics precede aesthetics and how errors are corrected progressively.
- Tools/Products: Classroom modules; interactive notebooks.
- Assumptions/Dependencies: Suitable curriculum materials; decoding intermediates for pedagogy.
- Content moderation and early-stage safety checks
- Sectors: platforms, policy
- What: Interrogate early frames to catch prohibited elements or unsafe semantics before final decoding and release.
- Tools/Products: “Preflight Safety Scan” that decodes and classifies F1/F2; automatic stop if policy-triggered.
- Assumptions/Dependencies: Safety classifiers; willingness to pay decoding overhead for intermediates.
Long-Term Applications
These will benefit from further research, scaling, or engineering to mature.
- Unified “pure visual reasoning” generation across modalities
- Sectors: video, 3D/NeRF, robotics simulation, AR/VR
- What: Extend CoF to text-to-video, text-to-3D, and scene synthesis where multi-step visual plans iteratively correct semantics and geometry before final renders.
- Tools/Products: CoF-T2V and CoF-T23D variants; multi-stage latent controllers.
- Assumptions/Dependencies: Scalable backbones; task-aligned VAEs; dataset and evaluation protocols for temporal/3D reasoning.
- Interactive user-in-the-loop reasoning
- Sectors: creative software, product design
- What: Allow users to edit at each step (accept/modify F1/F2), combining UEP with sliders/toggles for attribute locks and layout constraints.
- Tools/Products: “Progressive CoF Editor” with constraint-aware refinement.
- Assumptions/Dependencies: Low-latency step decoding; constraint satisfaction within flow schedulers.
- Standardization of “visual reasoning transparency” in generative systems
- Sectors: policy, compliance, enterprise software
- What: Define norms for storing and presenting intermediate visual reasoning states to improve accountability and reduce black-box concerns.
- Tools/Products: Reasoning State Manifest (RSM) format; audit APIs.
- Assumptions/Dependencies: Industry consensus; privacy/IP considerations; storage costs.
- Preference optimization using intermediate rewards
- Sectors: model training vendors, research
- What: Use per-frame rewards (semantic alignment at F1, aesthetic improvements at F2/F3) for RL or direct preference optimization to steer multi-step corrections.
- Tools/Products: Multi-stage reward models; CoF-aware RLHF pipelines.
- Assumptions/Dependencies: Reliable reward signals for semantics/aesthetics; stable training with flow models.
- Automated content pipelines with brand/style governance
- Sectors: marketing, e-commerce
- What: Encode brand constraints as stage-specific checks (e.g., palette/type at F2; lighting/composition at F3) to enforce compliance before shipping assets.
- Tools/Products: “Brand CoF Guardrails” with rule-based or learned verifiers.
- Assumptions/Dependencies: Labeled brand/style corpora; verifier robustness; scaled inference.
- Knowledge distillation and model compression using CoF trajectories
- Sectors: edge AI, on-device apps
- What: Distill multi-step reasoning into smaller models or single-step approximators for mobile/web deployment.
- Tools/Products: Teacher–student CoF distillation; latency-optimized CoF mimics.
- Assumptions/Dependencies: Distillation recipes that preserve semantic alignment; acceptable quality–latency trade-offs.
- Procedural synthetic corpora for multimodal reasoning
- Sectors: academia, foundation model labs
- What: Generalize CoF-Evol-Instruct to other categories (physics plausibility, commonsense scenes) to pretrain VLMs on progressive, causally ordered visual reasoning.
- Tools/Products: “Evol-Instruct++” suite with broader taxonomies and automated verifiers.
- Assumptions/Dependencies: Reliable planners/editors across new categories; evaluation suites for causal progression.
- Safety and bias auditing via early-frame probes
- Sectors: policy, platform integrity
- What: Analyze if problematic biases appear at F1/F2 (even if absent in F3), enabling earlier mitigation strategies.
- Tools/Products: Bias probes on intermediate latents; intervention hooks.
- Assumptions/Dependencies: Valid bias classifiers for partial renders; governance frameworks for interventions.
- Layout-first design tools for architecture and UX
- Sectors: architecture, interior design, UI/UX
- What: Use F1 as a stable layout blueprint, F2 for material/style exploration, F3 for photoreal polish—allowing deterministic layout control with iterative refinement.
- Tools/Products: “Layout→Material→Polish” workflow templates; constraint-aware CoF generators.
- Assumptions/Dependencies: Domain adapters and control signals (depth/seg/graph constraints).
- Cross-model orchestration using quality-based routing
- Sectors: ML Ops, platform engineering
- What: Adopt the paper’s multi-tier sampling and quality-based routing to allocate prompts to weak/medium/strong models and to pick appropriate construction strategies.
- Tools/Products: Router services with cost–quality trade-offs; tiered model farms.
- Assumptions/Dependencies: Accurate and cost-effective quality assessors; orchestration infra.
- IP provenance and generative traceability
- Sectors: legal, enterprise compliance
- What: Use intermediate reasoning chains as a provenance signal (how the output was constructed) to support IP reviews and licensing audits.
- Tools/Products: Provenance bundles embedded in asset metadata.
- Assumptions/Dependencies: Legal acceptance of such traces; secure storage; watermarking/interoperability.
- Applying independent frame encoding to other “image-from-video” tasks
- Sectors: imaging research, product engineering
- What: Reuse frame-wise independent encoding to avoid motion artifacts when repurposing video VAEs for single-image or short-chain tasks.
- Tools/Products: VAE wrappers and encoders that enforce single-frame granularity.
- Assumptions/Dependencies: Compatibility with existing VAEs; retraining or fine-tuning costs.
Notes on feasibility across applications:
- Compute and latency: While only the final frame is decoded in the paper, many applications benefit from decoding intermediates (added cost).
- Model access and licenses: Base video models (e.g., Wan2.1) and editing/assessment LMMs (Qwen family or equivalents) must be available under suitable licenses.
- Safety and governance: Adoption in enterprise/platform contexts requires content safety classifiers, policy alignment, and audit readiness.
- Domain shift: For specialized verticals (e.g., architecture, fashion), targeted fine-tuning and prompt engineering may be necessary to reach production quality.
Collections
Sign up for free to add this paper to one or more collections.