VChain: Chain-of-Visual-Thought for Reasoning in Video Generation
Abstract: Recent video generation models can produce smooth and visually appealing clips, but they often struggle to synthesize complex dynamics with a coherent chain of consequences. Accurately modeling visual outcomes and state transitions over time remains a core challenge. In contrast, large language and multimodal models (e.g., GPT-4o) exhibit strong visual state reasoning and future prediction capabilities. To bridge these strengths, we introduce VChain, a novel inference-time chain-of-visual-thought framework that injects visual reasoning signals from multimodal models into video generation. Specifically, VChain contains a dedicated pipeline that leverages large multimodal models to generate a sparse set of critical keyframes as snapshots, which are then used to guide the sparse inference-time tuning of a pre-trained video generator only at these key moments. Our approach is tuning-efficient, introduces minimal overhead and avoids dense supervision. Extensive experiments on complex, multi-step scenarios show that VChain significantly enhances the quality of generated videos.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces VChain, a new way to help AI create videos that make logical sense over time. Many video-generating AIs can make smooth, good-looking clips, but they often mess up cause-and-effect. For example, if a person drops a cup, the video might look nice but skip the moment where the cup hits the ground and the liquid splashes out. VChain fixes this by borrowing “thinking” from powerful multimodal models (like GPT-4o) and using that to guide video generation at the most important moments.
What are the main questions?
The researchers focused on simple, clear goals:
- How can we make AI-generated videos show realistic cause-and-effect, not just pretty motion?
- Can we use a smart model’s reasoning (like predicting what should happen next) to help a video model without retraining everything?
- Is there a quick, efficient way to nudge a pre-trained video model so it follows physics and common sense better?
How does VChain work?
Think of VChain as a helper that gives a video model a “plan” made of key snapshots and short descriptions, then tunes the video model a tiny bit to follow that plan.
Here’s the three-stage approach:
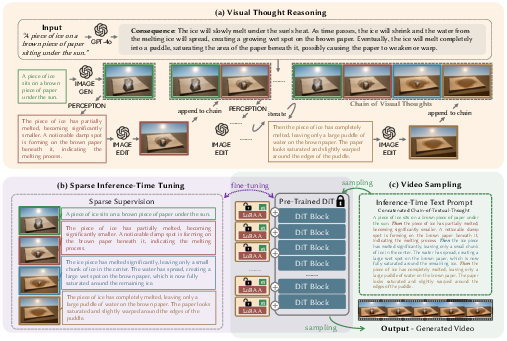
- Visual Thought Reasoning
- A multimodal model (like GPT-4o) reads your prompt and figures out the important steps that should happen.
- It then creates a small set of key images (keyframes) and short texts that show those steps.
- Example: If the prompt is “A rock and a feather are falling from the sky,” the keyframes would highlight the rock falling fast, the feather drifting slowly, and the moment they reach the ground at different times.
- Sparse Inference-Time Tuning
- The video model is lightly fine-tuned using just those keyframes and their captions.
- “Sparse” means it only tunes at a few crucial points, not across every single frame in a long video. This is quick and efficient.
- Video Sampling
- Finally, the video model generates the full clip using the combined text from all the keyframes, guided by the small tuning it received.
Key ideas explained in everyday language
- Diffusion models: Imagine starting with a noisy TV screen and slowly clearing the static until an image appears. The AI learns how to remove the noise step by step to reveal a realistic picture or video.
- LoRA (Low-Rank Adaptation): Instead of rewriting a huge AI model from scratch, LoRA adds small “helper notes” to the model. These notes change how it behaves in a focused way, which is faster and cheaper than full retraining.
- Inference-time: This means making small adjustments while the model is generating results, not during a huge training phase with lots of data.
- Chain of Visual Thoughts: A short, meaningful sequence of keyframes that act like story beats. They capture the critical moments of what should happen, like “ball hits pins → pins fall,” so the video model understands the causal steps.
What did they find, and why does it matter?
VChain leads to videos that follow physics, common sense, and cause-and-effect more reliably. In tests and human ratings, it improves:
- Physics: Objects move and interact in realistic ways (e.g., bowling pins fall correctly when hit, a feather falls more slowly than a rock).
- Commonsense reasoning: Everyday logic is respected (e.g., a rubber duck floats, not sinks).
- Causal reasoning: Actions lead to believable outcomes over time.
The paper shows that:
- VChain beats baselines that use only the original video model or just better text prompts.
- It makes videos more coherent without hurting visual quality.
- It’s efficient because it tunes on a few keyframes, not entire videos.
What is the impact?
VChain shows a practical path to smarter video generation:
- It bridges “reasoning” and “rendering” by letting a multimodal model plan key moments and a video model execute them.
- It reduces the need for big retraining and massive datasets.
- It can help storytelling, education, simulations, and creative work by making AI videos more believable and logical.
The authors also note limitations and responsibilities:
- Relying on external models (like GPT-4o) can add cost and introduce artifacts (e.g., slightly oversaturated images).
- Sparse tuning balances between injecting reasoning and preserving motion.
- More realistic videos can be misused, so ethical, careful use is important.
In short, VChain is a clever way to teach video AIs to “think” about what should happen next, so their videos feel more like the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, organized to be actionable for future research.
- Reliability of Visual Thought Reasoning: No mechanism to detect or correct erroneous or hallucinated causal predictions from GPT-4o; how to verify physical plausibility of LMM-generated “consequences” before using them for tuning.
- Termination criterion for keyframe generation: The “flag==terminate” condition is underspecified; define measurable stopping rules (e.g., convergence of state changes, confidence thresholds) and study their impact on video quality.
- Keyframe selection and spacing: Lack of strategy to determine the number, temporal spacing, and granularity of Visual Thoughts; ablate how N and keyframe density affect reasoning fidelity, motion smoothness, and cost.
- Geometry and camera consistency across keyframes: Keyframes are generated via iterative image edits without enforcing camera intrinsics or scene geometry; explore using pose estimation, optical flow, tracking, or 3D scene priors to maintain spatial consistency.
- Robustness to compounding artifacts in iterative image edits: Oversaturation and smoothing accumulate across edits; investigate artifact mitigation (e.g., denoising, color calibration, perceptual consistency losses) and quantify their downstream impact on tuned videos.
- Sparse tuning objective design: Tuning on static images risks weakening motion priors; develop motion-aware objectives (e.g., flow/acceleration regularizers, temporal adversarial losses) to preserve dynamics while injecting reasoning signals.
- Where to adapt in the generator: LoRA insertion points, ranks, and parameter budgets are not systematically explored; provide layer-wise ablations (VAE vs DiT blocks vs text encoder) and trade-offs in reasoning gain vs motion fidelity.
- Generalization across video generators: Results are reported only on Wan2.1-T2V-1.3B; evaluate transferability to other models (e.g., HunyuanVideo, Gen-3, Sora-like systems) and identify model-specific adjustments.
- Generalization across multimodal models: Reliance on GPT-4o/gpt-image-1 is proprietary; assess performance/robustness with open-source LMMs (e.g., Qwen-VL, LLaVA-Next) and hybrid planners (symbolic commonsense, physics engines).
- Error handling and uncertainty: No self-consistency checks, ensembles, or uncertainty estimates for LMM outputs; add mechanisms to detect contradictions, low-confidence steps, and trigger re-planning.
- Prompt concatenation effects: The impact of long, concatenated textual thoughts on the video generator’s text encoder is not analyzed; compare concatenation vs summarization vs structured prompts and measure alignment, drift, and truncation effects.
- Injection timing at sampling: Visual Thoughts guide tuning but not sampling; explore conditioning the sampler on keyframe latents or scheduled guidance (e.g., classifier-free guidance toward anchor states at specific timesteps).
- Persistence and cross-prompt effects: Inference-time LoRA may cause overfitting or catastrophic forgetting; study whether adapters generalize across related prompts, and design adapter reset/stacking strategies for multi-video sessions.
- Scalability to long-horizon videos: The approach is evaluated on short clips; assess scaling to minute-long sequences, multi-stage narratives, and branching causal chains with revisiting states.
- Complex physical interactions: Evaluate on hard cases (fluids, fracturing, elasticity, occlusions, multi-contact dynamics, frictional stacking) and quantify failure modes; integrate physics-informed priors or simulators for these domains.
- Multi-object identity and continuity: Identity preservation across keyframes and frames is not guaranteed; investigate identity tracking constraints or scene graphs to maintain object properties over time.
- Evaluation breadth and rigor: Only ~20 scenarios and human ratings are reported; adopt standardized causal/physics benchmarks (e.g., PhyGenBench), report inter-rater reliability, statistical significance, and confidence intervals.
- Cost and latency characterization: Claims of minimal overhead lack detailed scaling laws; publish per-video latency, token usage, GPU hours, and cost curves vs number of keyframes and tuning iterations.
- Failure case taxonomy: No systematic analysis of where VChain fails (e.g., high-speed motion, low-light, thin structures); build a public corpus of failures to drive method improvements.
- Safety and bias auditing: Beyond ethical notes, no empirical bias/safety assessment; measure and mitigate bias propagation from LMMs through VChain’s tuned outputs (e.g., stereotyping, content safety).
- Reproducibility and openness: Proprietary dependencies hinder reproducibility; provide open-source pipelines, seeds, and fallbacks for LMMs and generators, and document exact prompts/system messages.
- Hybrid planning alternatives: Compare visual-thought planning to layout/scene-graph planning, temporal storyboards, or physics-based planners; identify when each planner excels.
- Integration at training time: Explore pretraining or finetuning base models with Visual Thoughts to amortize inference-time costs and potentially yield stronger native reasoning without per-prompt adapters.
- Temporal consistency metrics: Current metrics emphasize general quality; add physics- and causality-specific automatic metrics (e.g., energy conservation proxies, force-direction consistency) for scalable evaluation.
- Adapter management and composition: Investigate libraries of reusable adapters for common physical events (e.g., “break,” “melt,” “collide”) and methods to compose them for complex scenarios.
- Multi-view and camera motion: Assess robustness under large camera motion, zooms, and multi-view generation; study constraints ensuring cross-view temporal coherence.
- Domain transfer and OOD prompts: Test ambiguity, contradictions, non-physical/fantasy prompts, and complex cinematography; define failure-aware policies (e.g., graceful degradation, user alerts).
- User control and interactivity: The pipeline is offline; add interactive editing of Visual Thoughts and re-planning during sampling, with immediate feedback on causal outcomes.
- Legal and licensing implications: Clarify IP status of LMM-generated keyframes used for tuning and downstream use; explore training on user-provided or licensed keyframes to avoid legal ambiguity.
Practical Applications
Below are actionable applications derived from the paper’s Chain-of-Visual-Thought approach (VChain) and its sparse inference-time tuning method. Each item notes the sector(s), likely tools/products/workflows, and key assumptions or dependencies that affect feasibility.
Immediate Applications
- AI storyboarding and previsualization for film/VFX
- Sectors: media/entertainment, software
- What: Rapidly convert a text description of a scene into a causally coherent sequence of keyframes and a short proof-of-concept video (e.g., collisions, splashes, breakages) without retraining the base generator.
- Tools/workflows: VChain SDK or plug-in for Blender/Unreal/After Effects to auto-generate “Visual Thoughts” and minimally fine-tune a video model via LoRA; export animatics.
- Assumptions/dependencies: Access to LMMs (e.g., GPT-4o/gpt-image-1) and a high-quality pretrained video generator (e.g., Wan); GPU for brief LoRA tuning; human review to correct artifacts and style.
- Physics-consistent motion inserts for advertising and social media content
- Sectors: marketing, media/entertainment
- What: Produce short product demos or use-case scenarios where cause-and-effect is important (e.g., “spill-proof cup test,” “shock-resistant phone drop”) to boost believability.
- Tools/workflows: Web app that generates keyframes and tunes the model per scene; batch A/B variants using textual thought concatenation.
- Assumptions/dependencies: Physics is only approximated; brand safety review; API costs for LMM calls.
- “Instruction-to-process” microvideos for e-commerce, DIY, and technical support
- Sectors: retail/e-commerce, consumer software, education
- What: Turn assembly or troubleshooting steps into brief, coherent videos that visually show each state transition (e.g., “insert tab,” “tighten bolt,” “reset device”).
- Tools/workflows: CMS integration that converts FAQs or manuals to Visual Thoughts and final video; lightweight LoRA per product.
- Assumptions/dependencies: Clear procedural text; domain-specific visuals may require style images; human-in-the-loop for correctness.
- Classroom demos for physics and chemistry concepts
- Sectors: education
- What: Visualize cause-and-effect phenomena (melting, buoyancy, mixing colors) in short clips that match textbook expectations.
- Tools/workflows: Teacher-facing app that auto-generates keyframe chains and a prompt-concatenated video; library of vetted scenarios.
- Assumptions/dependencies: LMM reasoning must match curriculum; vetted prompts reduce bias/misconceptions.
- Safety training microvideos for manufacturing and energy
- Sectors: energy, industrial safety, policy/public sector
- What: Generate short clips showing hazard progression (e.g., spill → ignition → evacuation steps) to enhance training modules.
- Tools/workflows: “SafetySim Lite” workflow that uses Visual Thoughts as anchors for critical moments; LMS integration.
- Assumptions/dependencies: Expert review to ensure accurate procedures; physics fidelity is limited; compliance sign-off.
- Game cutscene prototyping and level event visualization
- Sectors: gaming, software
- What: Quickly prototype narrative cutscenes or scripted event sequences with coherent cause-and-effect (e.g., switch → door opens → enemy reacts).
- Tools/workflows: Unreal/Unity plug-in that emits keyframes and tunes a generator; designers annotate causal beats.
- Assumptions/dependencies: Style fidelity may require additional fine-tuning; integration with engine timelines.
- Prompt engineering companion for existing video generators
- Sectors: software, media creation
- What: Use the “Chain of Textual Thoughts” alone to produce richer, stepwise prompts that improve alignment even without tuning.
- Tools/workflows: Browser extension/UI that expands user prompts into concatenated textual thoughts for T2V models.
- Assumptions/dependencies: Benefits depend on the base model’s text conditioning strength; no guarantee of perfect physics.
- Automated video QA and benchmarking for causality/physics
- Sectors: academia, software tooling
- What: Create targeted test suites (e.g., bowling pins, falling objects) to score models on physical plausibility, commonsense, and causal reasoning.
- Tools/workflows: “VChain Test Runner” that generates scenario sets and uses human/metric scoring (e.g., VBench, custom rubrics).
- Assumptions/dependencies: Subjectivity in human ratings; need diverse scenarios; model biases may affect results.
- Synthetic dataset augmentation with causal coherence
- Sectors: academia, software, robotics simulation
- What: Enrich datasets with short clips that exhibit correct state transitions for downstream training or evaluation.
- Tools/workflows: Batch keyframe generation + sparse tuning per scenario; metadata tagging of causal steps.
- Assumptions/dependencies: Domain mismatch risk; synthetic-to-real gap; ensure licensing and provenance.
- Content plausibility pre-check for moderation and editorial workflows
- Sectors: media platforms, policy/public sector
- What: Use Visual Thought Reasoning to flag videos that likely violate basic physics or causality (e.g., floating heavy objects) for editorial review.
- Tools/workflows: A “physics plausibility” service that compares expected chains to observed frames; highlight suspicious segments.
- Assumptions/dependencies: Not a definitive detector; high false-positive/negative risk; human moderation required.
- On-the-fly personalization and brand style alignment via sparse tuning
- Sectors: marketing, media/entertainment
- What: Apply lightweight LoRA to adapt the generator to brand colors, materials, and motion patterns at key moments.
- Tools/workflows: “Brand LoRA Pack” attached to Visual Thoughts; reuse across campaigns.
- Assumptions/dependencies: Access to brand assets; minor risk of oversmoothing or color cast noted in the paper.
- Interactive “Storyboard-to-Video” product for creators
- Sectors: creator economy, software
- What: A UI where users refine keyframes and textual thoughts, then export the tuned video—bridging sketch/storyboards to motion.
- Tools/workflows: Web app with iterative keyframe editing, LMM-assisted captions, LoRA tuning slider.
- Assumptions/dependencies: API costs; GPU scaling; user familiarity with iterative design.
Long-Term Applications
- Safety-critical simulation content for robotics and autonomous driving
- Sectors: robotics, automotive
- What: Generate training/simulation clips with high causal fidelity (e.g., complex traffic interactions, rare hazards).
- Tools/workflows: Hybrid pipeline coupling VChain with physics engines and perception simulators; scenario libraries.
- Assumptions/dependencies: Requires stronger physics guarantees and validation; potential liability concerns; multi-sensor realism.
- Training data generation pipeline with physics-grounded consistency
- Sectors: robotics, academia
- What: Systematically produce varied, causally correct video datasets for model training (e.g., manipulation tasks, cause-effect sequences).
- Tools/workflows: “VChain Data Factory” with auto-curation, diversity generation, and labels from textual thoughts.
- Assumptions/dependencies: Validation against real-world benchmarks; domain adaptation; compute and storage scaling.
- Real-time interactive video generation in XR with reasoning
- Sectors: AR/VR, gaming, education
- What: Adaptive, cause-aware scenes that respond to user actions (e.g., knock object → dynamic reaction).
- Tools/workflows: On-device or edge LoRA updates; runtime Visual Thought updates driven by user inputs.
- Assumptions/dependencies: Latency and compute constraints; local LMMs or distilled models; safety constraints.
- Coupling with physics engines and 3D pipelines for hybrid simulation-generation
- Sectors: software, engineering, gaming
- What: Use physics solvers for hard constraints while VChain handles causal sequencing and visual coherence.
- Tools/workflows: Blender/Unreal + PhysX/Bullet integration; “Hybrid Reasoner” that synchronizes keyframes with simulated trajectories.
- Assumptions/dependencies: Nontrivial integration; discrepancies between rendered outputs and physics states must be reconciled.
- Healthcare training and patient education with validated sequences
- Sectors: healthcare, education
- What: Visualize procedural steps (e.g., wound care, device use) with clear causal outcomes; patient-friendly explainer videos.
- Tools/workflows: Clinical review loops, medical ontologies guiding textual thoughts; regulated content pipeline.
- Assumptions/dependencies: Medical validation; regulatory compliance; risk of misleading visuals without expert oversight.
- Policy scenario visualization and public risk communication
- Sectors: policy/public sector, emergency management
- What: Convey consequences of interventions (evacuation routes, crowd flow changes, hazard mitigation) via short causal videos.
- Tools/workflows: “PolicyViz” studio that encodes interventions into Visual Thoughts; public information campaigns.
- Assumptions/dependencies: Requires validated models, domain experts; avoid misinforming the public; transparency about limitations.
- Agent planning integration: from visual thoughts to action plans
- Sectors: robotics, software AI tooling
- What: Use the visual chain as a planning scaffold for agents (predict states, choose actions, verify outcomes).
- Tools/workflows: Multi-agent pipeline where an LMM proposes steps, VChain visualizes/validates, planner updates policy.
- Assumptions/dependencies: Reliable state estimation from visuals; closed-loop control; robust failure handling.
- Enterprise creative suite integration and workflow standardization
- Sectors: media/entertainment, marketing
- What: Standard toolset for studios/brands to author causal sequences, tune generators, and archive reusable thought chains.
- Tools/workflows: “Visual Thought Library,” shot templates, batch LoRA scheduling, MAM/DAM integration.
- Assumptions/dependencies: Vendor partnerships; licensing; governance for AI-generated assets.
- On-device inference-time tuning for privacy and cost control
- Sectors: consumer devices, enterprise
- What: Local LoRA updates using small keyframe sets to personalize content without cloud reliance.
- Tools/workflows: Distilled LMMs and compact video generators; mobile GPUs/NPUs; offline keyframe authoring.
- Assumptions/dependencies: Hardware capability; model compression; secure model updates.
- Provenance, watermarking, and audit trails for causal video synthesis
- Sectors: policy/regulation, platforms
- What: Track textual/visual thought provenance, tuning steps, and model versions; embed watermarks for trust.
- Tools/workflows: “Causal Audit Log,” standardized metadata schema, secure watermarking tied to keyframes.
- Assumptions/dependencies: Industry standards; platform adoption; privacy and security considerations.
- Cross-sector digital twins with narrative state transitions
- Sectors: energy, manufacturing, smart cities
- What: Visualize process states and interventions (shutdown, maintenance, ramp-up) with causal coherence for operator training and stakeholder communication.
- Tools/workflows: Digital twin platforms augmented with VChain-generated sequences; scenario rehearsal tools.
- Assumptions/dependencies: High-fidelity integration with operational data; domain validation; safety and compliance review.
- Comprehensive evaluation and auditing frameworks for video reasoners
- Sectors: academia, standards bodies
- What: Benchmarks and protocols that measure physics, commonsense, and causality across models and domains (expanding beyond VBench).
- Tools/workflows: Open datasets of causal tasks; reproducible test harnesses; human+automatic scoring pipelines.
- Assumptions/dependencies: Community governance; funding for shared infrastructure; standardized metrics across use cases.
Glossary
- Ablation Study: A controlled analysis where components of a system are removed or altered to assess their individual contributions. "Ablation Study. To further understand the impact of each component in VChain, we design the following ablation settings:"
- Causal Reasoning: The ability to model and evaluate cause-and-effect relationships within generated sequences. "{Causal Reasoning.} Evaluates whether the video captures appropriate cause-and-effect relationships."
- Chain of Visual Thoughts: A sparse sequence of keyframes that represent critical intermediate visual states used to guide video generation. "VChain leverages large multimodal models to generate a Chain of Visual Thoughts"
- Commonsense Reasoning: The use of everyday real-world knowledge to judge or generate plausible visual outcomes. "{Commonsense Reasoning.} Assesses whether events in the video reflect everyday real-world knowledge."
- Diffusion Models: Generative models that synthesize data by iteratively denoising from a noise prior. "Diffusion models are a class of generative models that reconstructs data such as natural images or videos by iteratively denoising starting from the Gaussian prior ."
- Diffusion Transformers (DiTs): Transformer-based architectures adapted for diffusion model training and inference. "Recent progress in diffusion-based video generation has been shifting from U-Net architectures to Diffusion Transformers (DiTs) with Flow Matching."
- Flow Matching: A training objective that learns a velocity field to transform noise into data via continuous-time interpolation. "The Wan video generation model uses the flow matching training objective in the Wan-VAE's latent space."
- gpt-image-1: An image generation and editing model used to produce and refine keyframes. "we use gpt-image-1 for steps involving image generation and editing."
- GPT-4o: A large multimodal model with strong cross-modal reasoning used to infer visual consequences and generate guidance. "Models such as GPT-4o have made rapid progress in general reasoning and cross-modal understanding."
- Inference-Time Tuning: Adapting a pretrained model during inference using lightweight supervision, without retraining on large datasets. "an inference-time tuning framework that injects visual reasoning signals from multimodal models into video generation."
- Latent Space: The compressed representation domain (e.g., VAE latents) in which diffusion and training operate. "in the Wan-VAE's latent space."
- Logit-Normal Distribution: A distribution over timesteps used to sample interpolation parameters in flow matching. "where the timestep is sampled from a logit-normal distribution."
- Low-Rank Adaptation (LoRA): A parameter-efficient fine-tuning method that adds trainable low-rank matrices to frozen model weights. "{Low-Rank Adaptation (LoRA).} LoRA is a parameter-efficient fine-tuning technique."
- Prompt Augmentation: Automatically enhancing input text prompts to improve alignment or richness of generated content. "T2V + Prompt Aug: The input text prompt is enhanced using GPT-based prompt augmentation."
- Sparse Inference-Time Tuning: Fine-tuning only at key moments using minimal supervision to efficiently inject reasoning signals. "Sparse Inference-Time Tuning: These visual thoughts (paired with their corresponding textual thoughts) serve as sparse supervision for fine-tuning a pre-trained video generator via LoRA."
- Sparse Supervision: Training or tuning with a limited set of informative examples (e.g., keyframes) instead of dense sequences. "injects high-level reasoning signals through sparse visual supervision, enabling more causally consistent and semantically grounded video generation with minimal overhead."
- Text-to-Video (T2V): Generative systems that synthesize videos from textual prompts. "a design now common in text-to-video (T2V) systems"
- Textual Thoughts: The captions or instructions paired with visual thoughts that describe intended keyframe states. "paired with its corresponding textual thoughts"
- Variational Autoencoder (VAE): A probabilistic generative model used for compressing and reconstructing data via latent variables. "Wan-VAE: a spatio-temporal variational autoencoder"
- VBench: An evaluation framework assessing video generation dimensions such as fidelity, consistency, and motion. "we conduct quantitative evaluations using VBench, an evaluation framework designed to assess key technical dimensions of video generation"
- Video Diffusion Models: Diffusion-based generative models specialized for synthesizing video sequences. "Video Diffusion Models. Our work builds on Wan, a state-of-the-art video generation foundation model"
- Visual Thought Reasoning: A pipeline that uses multimodal reasoning to infer and synthesize causally important keyframes. "Visual Thought Reasoning: Given a user-provided text prompt, a large multimodal model (GPT-4o) infers a causal chain of events and generates a sequence of keyframes, termed the Chain of Visual Thoughts"
- Visual Thoughts: Generated keyframes that capture critical intermediate states guiding video synthesis. "These visual thoughts (paired with their corresponding textual thoughts) serve as sparse supervision for fine-tuning a pre-trained video generator via LoRA."
- Wan: A state-of-the-art video generation foundation model serving as the base generator. "Our work builds on Wan, a state-of-the-art video generation foundation model trained on a mix of video and image datasets"
- Wan-VAE: The spatio-temporal VAE component within Wan that compresses videos into latents. "Wan includes three main components: 1) Wan-VAE: a spatio-temporal variational autoencoder"
Collections
Sign up for free to add this paper to one or more collections.