- The paper introduces a novel frame-aware reasoning method (Chain-of-Frames) that significantly enhances video understanding in multimodal LLMs.
- It employs a two-step data generation pipeline to align frame identifiers with annotations, producing coherent CoF triplets for training.
- Experimental results show that CoF-enhanced models outperform baselines by achieving higher benchmark accuracy and reduced hallucination rates.
Chain-of-Frames: Advancing Video Understanding in Multimodal LLMs via Frame-Aware Reasoning
The paper "Chain-of-Frames: Advancing Video Understanding in Multimodal LLMs via Frame-Aware Reasoning" (2506.00318) presents a novel approach to enhance video understanding capabilities in multimodal LLMs by grounding reasoning in specific video frames. It introduces a frame-referenced reasoning technique called Chain-of-Frames (CoF), which notably improves performance and interpretability in video task benchmarks.
Introduction
Recent advances in LLMs, particularly in the area of Chain-of-Thoughts (CoT) reasoning, have demonstrated enhanced decision-making capabilities through intermediate reasoning steps. Extending CoT to multimodal LLMs, especially for video understanding, presents unique challenges due to the need for temporal and contextual integration of multiple frames. This paper proposes a method to directly correlate reasoning steps with relevant video frames, thereby grounding video LLM reasoning in temporal segments of videos.

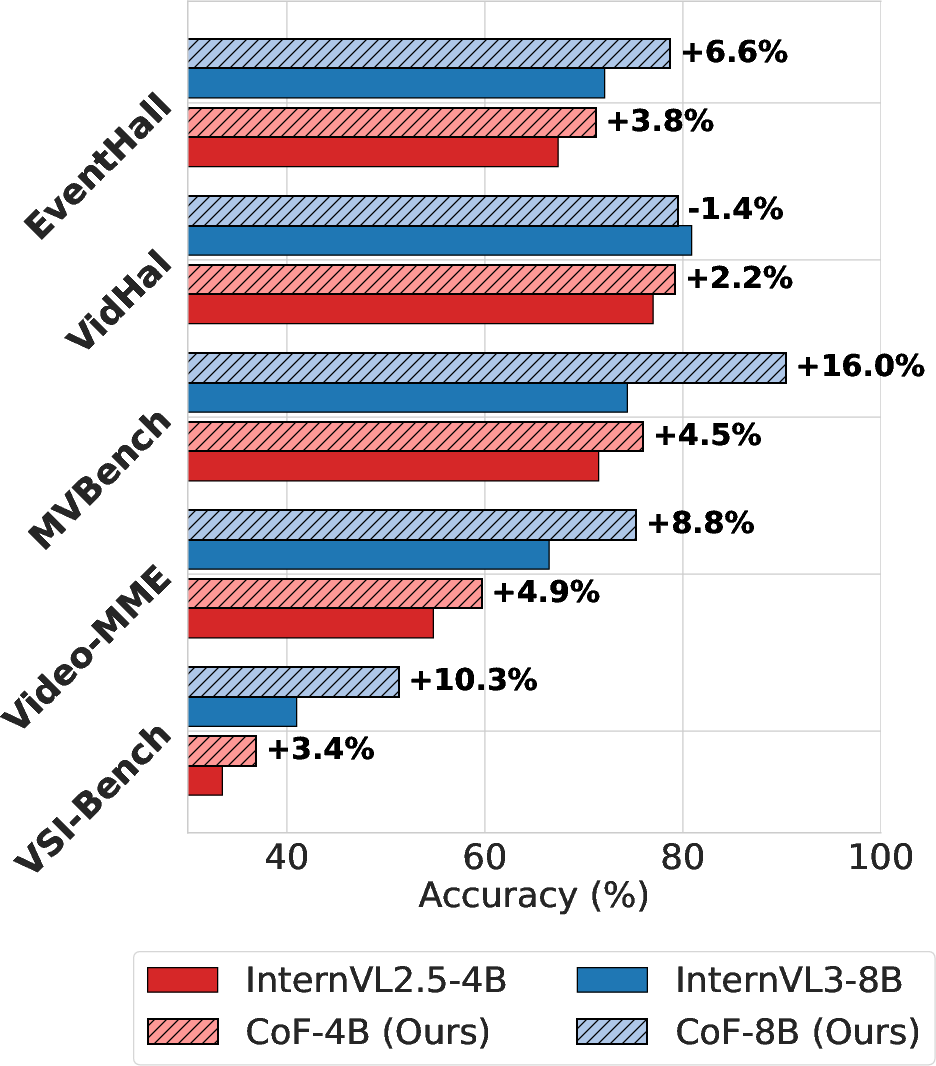
Figure 1: (a) Chain-of-frames reasoning generated by our CoF-InternVL2.5-4B model: it includes the key frames to answer the question (from Video-MME). (b) Comparison of accuracy across multiple video understanding benchmarks between baseline models (InternVL2.5-4B and InternVL3-8B) and their CoF-enhanced counterparts: our models consistently outperform the baselines.
Methodology
Chain-of-Frames Data Generation
The proposed methodology involves creating CoF-Data, which consists of questions, answers, and frame-referenced reasoning traces derived from both real and synthetic video sources. The dataset construction follows a two-step pipeline:
- Frame ID Adjustment: Align and adjust frame identifiers to ensure correspondence with captions or annotations.
- CoF Triplet Generation: Utilize annotations to create reasoning triplets that include questions, frame-aware reasoning traces, and answers.
This pipeline ensures the alignment of reasoning steps with specific frames, crucial for temporal grounding.
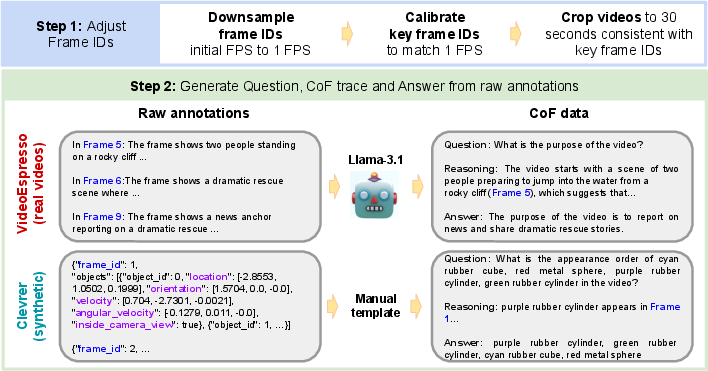
Figure 2: Overview of our two-step pipeline for generating CoF-Data. Step 1 adjusts the frame IDs while preserving frame-caption alignment. Step 2 utilizes raw annotations to generate CoF triplets (question, frame-aware reasoning trace, answer).
Model Training
The approach leverages existing video LLM architectures, such as InternVL2.5-4B and InternVL3-8B, and fine-tunes them on the CoF-Data. The models are evaluated across various benchmarks to demonstrate the impact of frame-grounded reasoning. Unlike traditional CoT methods, CoF does not require auxiliary networks or complex architectural modifications.
Experimental Results
The paper conducts extensive evaluations on several benchmarks including Video-MME, MVBench, VSI-Bench, VidHal, and EventHallusion. The CoF-enhanced models show substantial improvements in accuracy compared to baseline models, with notable enhancements in reasoning capabilities and reductions in hallucination rates.
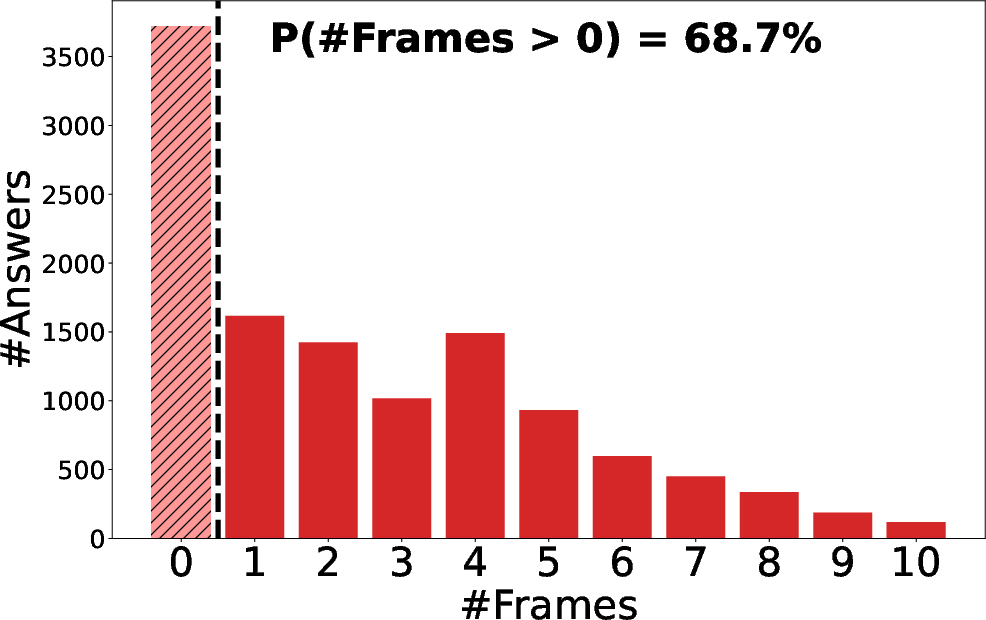
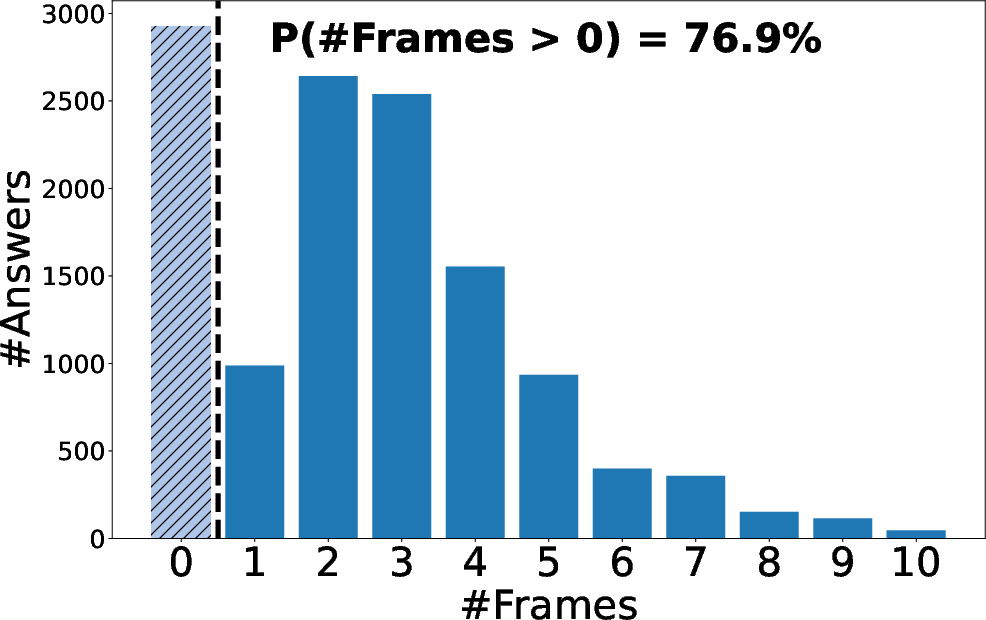
Figure 3: CoF reasoning at inference time. For both CoF-InternVL2.5-4B (left plot) and CoF-InternVL3-8B (right), we show the distribution of the number of frame references generated at inference time: both models learn to produce chain-of-frames during evaluation.
Impact on Video Understanding
Integrating temporal grounding within LLMs significantly enhances the interpretability of model outputs by making the decision process transparent via explicit frame references. This connection between frames and reasoning steps not only improves video comprehension but also facilitates better generalization to unseen scenarios.
Conclusion
The Chain-of-Frames methodology provides a robust framework for enhancing video LLMs without the need for external network overheads, maintaining efficiency in real-world video understanding tasks. Future directions include scaling dataset diversity and exploring adaptations across different LLM architectures. The shift towards frame-grounded reasoning marks an essential step towards more interpretable and capable multimodal systems.

