- The paper achieves hardware-efficient 1.25-bit ternary quantization by employing a novel 3:4 sparsity pattern that aligns perfectly with SIMD lanes.
- It introduces the Arenas mechanism during quantization-aware training to overcome gradient homogenization and enhance model robustness.
- Experimental results on LLaMA models reveal a 25% model size reduction and 10–18% speedup with maintained accuracy across benchmarks.
Sherry: Hardware-Efficient 1.25-Bit Ternary Quantization via Fine-grained Sparsification
Motivation and Technical Problem
Scaling LLMs to edge devices faces persistent challenges due to memory and inference latency bottlenecks. While ternary quantization ({−1,0,1}) offers theoretical bit-efficiency, practical implementations are thwarted by poor alignment with native hardware—namely, inefficient packing that either wastes bits or introduces hardware-incompatible SIMD operations. Standard 2-bit packing negates ternary efficiency, while 1.67-bit packing leads to SIMD-unfriendly, slow execution.
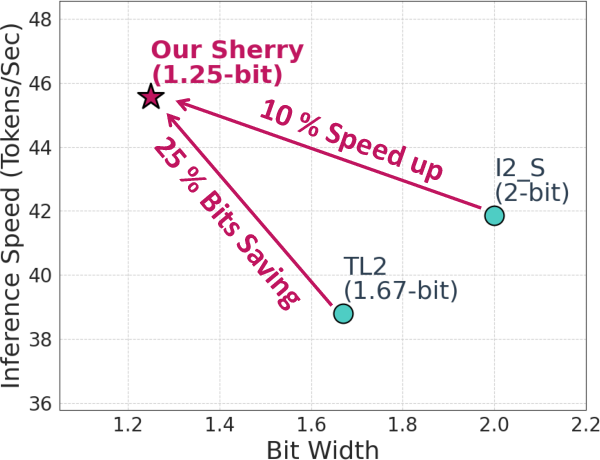
Figure 1: Comparison of different packing strategies for ternary quantization in efficiency.
Binary or multi-bit INT strategies are well-aligned with hardware but fail to achieve optimal compression. Conversely, naive ternary schemes cannot exploit hardware vector lanes, introducing significant runtime overheads. The technical imperative is therefore a quantization framework that achieves sub-2-bit widths while ensuring SIMD-friendly packing for edge accelerators.
Sherry Framework: 3:4 Fine-Grained Sparsity and 1.25-Bit Packing
Sherry introduces a 3:4 structured sparsity as a central innovation: in every block of 4 weights, exactly 3 are non-zero and 1 is zero. This yields two key outcomes:
- SIMD Alignment: Block size of 4 ensures clean mapping to vector lanes.
- 1.25-Bit Packing: Each 4-weight block encodes into 5 bits, producing effective 1.25 bits/weight with no wasted bits or irregular group boundaries.
This design circumvents the incompatibility of 3-way (1.67-bit) packing and maximizes hardware throughput.
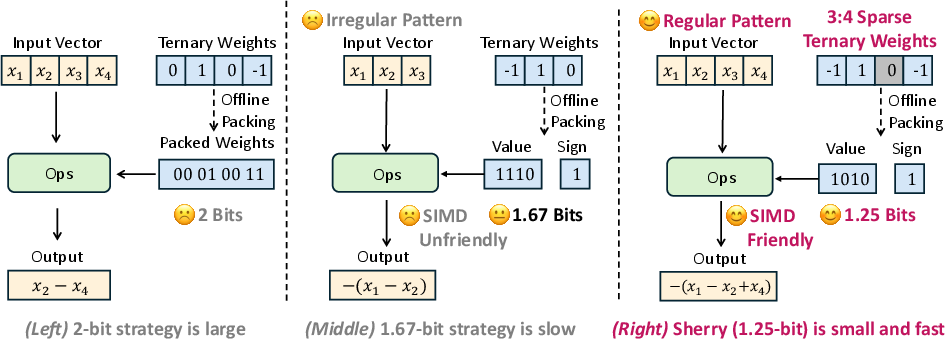
Figure 2: Sherry’s 3:4 pattern enables 4-way, SIMD-friendly packing and minimizes bit wastage versus prior schemes.
The packing mechanism leverages the combinatorial state-space ((34)×23=32 states), which fits exactly into 5 bits—optimizing both information density and hardware addressability.
Training Dynamics and Arenas Mechanism
While 3:4 sparsity enables packing efficiency, imposing this hard constraint during quantization-aware training (QAT) exposes a severe gradient homogenization effect. Ternary weights collapse to near-binary states, reducing effective representation rank and hindering performance—an issue termed "weight trapping."
Gradient singularity arises since uniform zero-distribution produces degenerate update directions, as shown by Effective Rank (ER) analysis.
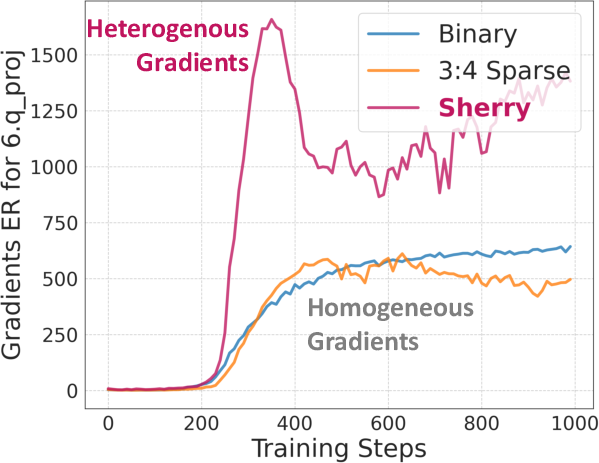
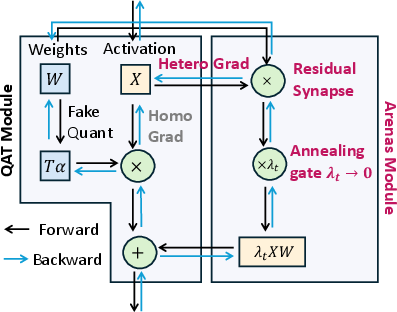
Figure 3: The effective ranks (ER) of the gradients during training. Both Binary and 3:4 sparse ternary training have relatively low ER due to gradient homogenization.
To mitigate this, Sherry introduces Arenas: an annealing residual synapse. During QAT, model outputs linearly blend the ternary transform with a decaying full-precision residual connection:
Y=XTα+λtXW
where λt is an annealing factor scheduled to vanish by the end of training. This mechanism re-introduces pathway heterogeneity, enabling trapped weights to escape local minima and restoring effective gradient diversity. Ablations show consistent accuracy improvement across granularity and quantization regimes with Arenas integration.
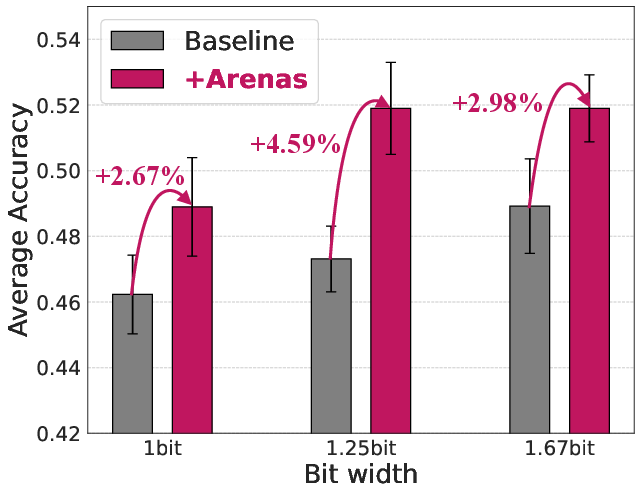
Figure 4: Ablation study of Arenas demonstrates consistent performance gains across schemes with the annealing residual path.
Experimental Results
Sherry is validated on LLaMA-3.2 models (1B, 3B), benchmarked across ARC-e, ARC-c, HellaSwag, PIQA, and Winogrande. Primary findings:
- Accuracy: Sherry matches SOTA ternary baselines (Tequila, Spectra) in average accuracy on all benchmarks, despite using 1.25 bits/weight versus their 1.67.
- Inference Speed & Model Size: On Intel i7-14700HX, the 1B Sherry model achieves zero accuracy degradation, a 25% model size reduction, and 10–18% speedup relative to SOTA.
- Packing Granularity: Performance remains robust for per-tensor, per-channel, and per-group quantization, with per-group (size 128) providing the best tradeoff.
Sherry’s block-aligned 1.25-bit weights maximally utilize hardware vector lanes, reflected in higher token throughput and memory savings. Table and figure analyses confirm that Arenas is crucial for learning stability, especially as quantization sharpness increases.
Hardware and Algorithmic Implications
Sherry’s framework establishes a new Pareto optimal regime for edge LLM deployment:
- SIMD Hardware Compatibility: 4-way sparsity/pattern perfectly aligns with 128-bit and 256-bit register word sizes, eliminating bit packing overhead.
- Low Entropy Loss: 3:4 sparsity maintains 75% density, well below known accuracy cliff thresholds for LLMs.
- Training Overhead: Arenas introduces additional computational cost during QAT, but inference overhead is strictly zero.
Sherry is not directly optimized for server-class hardware (e.g., NVIDIA’s sparse tensor cores). The 3:4 pattern is specifically tailored for edge or device-scale CPUs lacking specialized instructions for irregular sparsity.
Limitations and Future Directions
Sherry's evaluation is limited to edge-constrained scales (≤3B parameters), with theoretical extension to larger models untested. The current design assumes weight-only quantization; BF16 activations and KV-caches remain the memory bottleneck for long-sequence inference. Applying Sherry’s approach to full weight-activation quantization or hybrid quantization is a logical extension. Additionally, adapting structured N:M sparsity in ternary with Arenas for transformer variants and other architectures stands as a promising avenue.
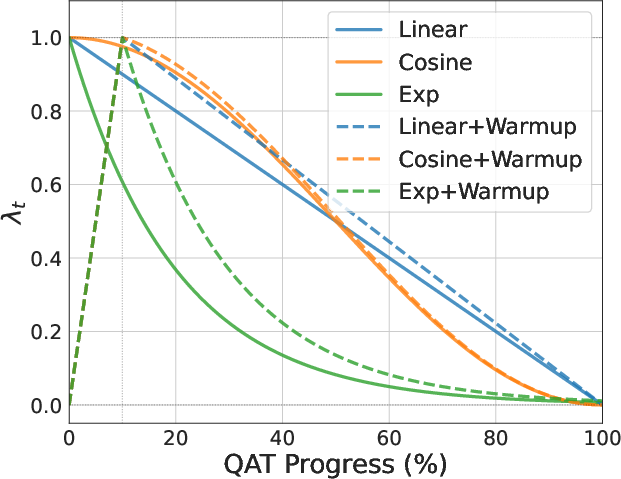
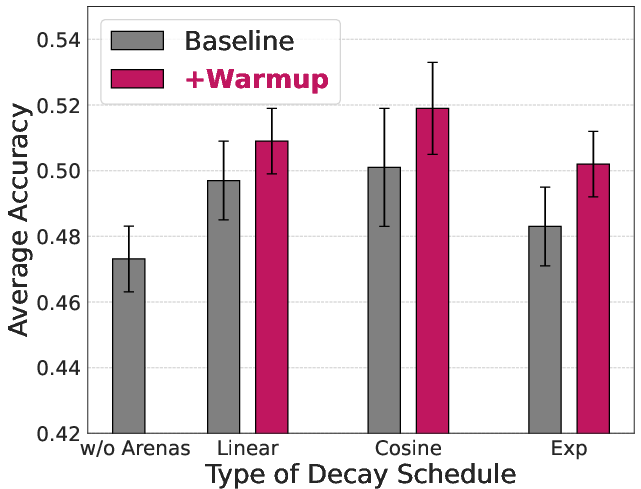
Figure 5: The schedules of annealing factor λt; annealing dynamics are key to Sherry’s optimization stability.
Conclusion
Sherry provides an effective solution to the memory-compute efficiency dilemma inherent in ternary LLM quantization. By enforcing a 3:4 block sparsity that enables hardware-aligned 1.25-bit packing and supplementing with Arenas for training robustness, Sherry achieves no-compromise inference speed, memory reduction, and accuracy. The approach establishes a new baseline for hardware/software co-design in highly compressed neural inference, advancing practical, on-device LLM deployment with rigorous numerics and algorithmic soundness.