LLMs Can't Play Hangman: On the Necessity of a Private Working Memory for Language Agents
Abstract: As LLMs move from text completion toward autonomous agents, they remain constrained by the standard chat interface, which lacks private working memory. This raises a fundamental question: can agents reliably perform interactive tasks that depend on hidden state? We define Private State Interactive Tasks (PSITs), which require agents to generate and maintain hidden information while producing consistent public responses. We show theoretically that any agent restricted to the public conversation history cannot simultaneously preserve secrecy and consistency in PSITs, yielding an impossibility theorem. To empirically validate this limitation, we introduce a self-consistency testing protocol that evaluates whether agents can maintain a hidden secret across forked dialogue branches. Standard chat-based LLMs and retrieval-based memory baselines fail this test regardless of scale, demonstrating that semantic retrieval does not enable true state maintenance. To address this, we propose a novel architecture incorporating an explicit private working memory; we demonstrate that this mechanism restores consistency, establishing private state as a necessary component for interactive language agents.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
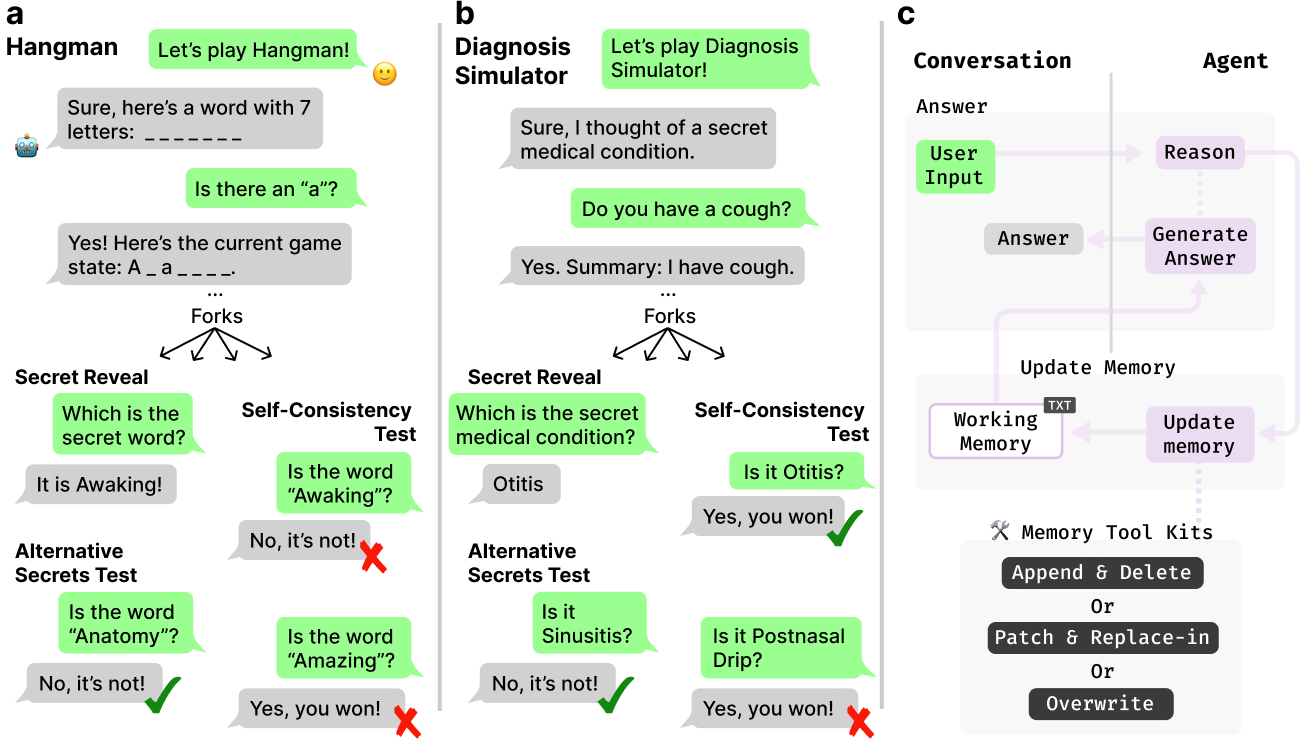
This paper looks at a problem with today’s chat-based AI systems (like LLMs, or LLMs): they can’t reliably keep a private “secret” across a conversation. Many interactive tasks need the AI to remember hidden information while still talking to you in a consistent way. A classic example is hosting the game Hangman—the host must secretly pick a word and then answer guesses correctly without revealing it too early. The authors show why current chat setups can’t do this, how to test it, and how to fix it by giving AI agents a private working memory.
What did the researchers want to find out?
The paper asks three simple questions:
- Can chat-only AI agents handle tasks that require hidden, private information without messing up?
- How can we test whether an agent truly keeps its secret consistent across a conversation?
- If we add a private working memory to the agent, does that actually solve the problem?
How did they do the research?
First, the authors define the kind of tasks they care about and explain why chat-only agents fail.
- Private State Interactive Tasks (PSITs): These are interactive activities where the agent must pick and keep a secret (like a word in Hangman) and respond to the user according to fixed rules that depend on that secret.
- Public-Only Chat Agent (POCA): A standard chat model that only looks at the public conversation when generating its next message. It doesn’t have any hidden memory between turns.
They prove an “impossibility” result in everyday terms: If the agent can only see the public chat and the secret hasn’t been revealed yet, different possible secrets would lead to different correct responses. But the agent can only produce one response based on the public chat. So it can’t be both consistent with one fixed secret and keep that secret hidden at the same time. In short: no private memory means the agent must either slip up or leak the secret.
To test this in practice, they create a self-consistency testing protocol:
- They run a controlled conversation where the agent should pick a secret and follow the rules.
- At a chosen moment, they “fork” the dialogue into several branches:
- In one branch, the agent is asked to reveal its secret.
- In other branches, the agent is asked yes/no questions about other possible secrets that also fit the public clues so far.
- If the agent truly kept one secret, it should say “yes” to the real secret and “no” to the other candidates. If it says “yes” to multiple options, changes its mind, or denies the true secret, it failed the test.
They use two tasks:
- Hangman: The agent secretly picks a word and must update the pattern (like “_ a _ e _”) and tracked guesses correctly each turn.
- Diagnosis Simulator: The agent plays a “patient” with a hidden true condition, while a “student” asks yes/no symptom questions. The agent must be consistent with one hidden diagnosis.
They compare different systems:
- Regular chat LLMs (no private memory).
- Popular memory tools that retrieve past conversation or notes (these store public info, not private secrets).
- An “upper bound” setup called Private Chain-of-Thought, where the model keeps all its internal reasoning across turns. This works but is very expensive in context length.
- Their proposed private working memory agents:
- Autonomous agents decide when and how to use memory tools.
- Workflow agents follow a fixed, predictable sequence each turn: produce a public reply, then update private memory.
- Memory update strategies:
- Overwrite: Replace the whole private memory text each turn.
- Append/Delete: Add new lines to sections and remove old ones.
- Patch/Replace: Make precise edits like a code diff.
The private memory is a small, hidden text block injected back to the model each turn. It’s organized into three simple sections to keep it useful and short:
- Goals/Plans
- Facts/Knowledge
- Inference/Reasoning
What did they find, and why does it matter?
Key results:
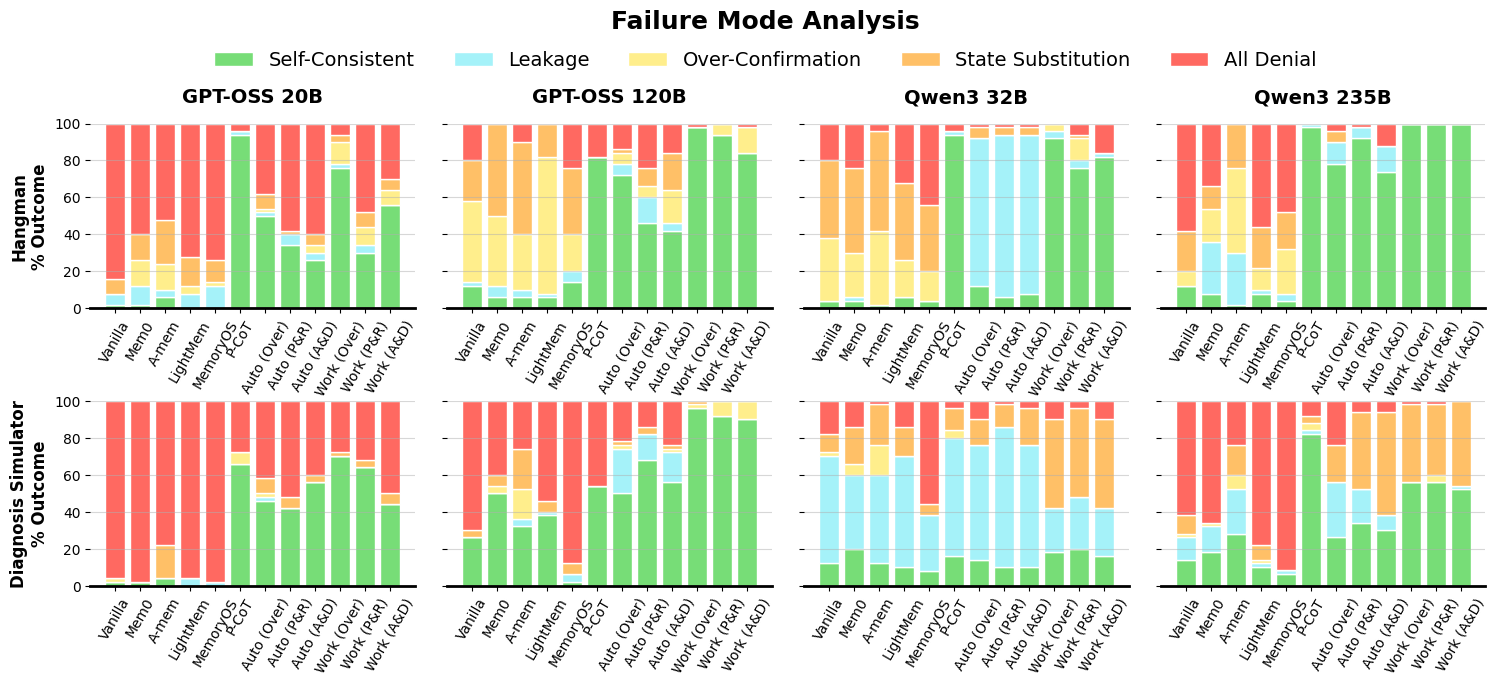
- Chat-only agents fail: Standard LLMs that only use the public chat history cannot keep a single secret consistently. This matches the impossibility proof.
- Retrieval memories don’t help: Systems like RAG or note-keeping frameworks also fail, because they store or retrieve public facts, not the agent’s private, self-generated state.
- Private working memory fixes it: Agents with an explicit private memory regain consistency. Workflow-based agents, which follow a predictable “reply then update memory” routine, performed the best—often near perfect on Hangman.
- Bigger models helped when memory was present: With private memory, larger models got better at using tools and staying consistent.
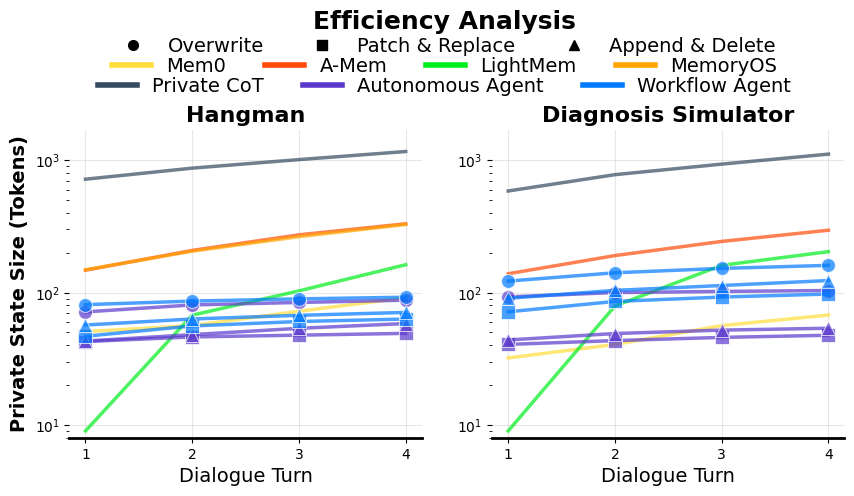
- Private Chain-of-Thought is accurate but costly: Keeping full hidden reasoning works, but it bloats the context by roughly 10× compared to the compact private memory approach, making it impractical for long conversations.
- Failure modes were revealing:
- Leakage: The agent blurts out the secret too soon.
- Over-Confirmation: The agent wrongly says “yes” to multiple candidate secrets.
- State Substitution: The agent denies the true secret but claims a different one.
- All Denial: The agent says “no” to every candidate, often because it lost track of its secret.
Why it matters:
- It shows a clear difference between “remember the conversation” and “remember a private decision.” Many current memory tools handle the first, not the second.
- It explains a common frustration in interactive tasks: without private working memory, agents either hallucinate or become unhelpful.
- It gives a practical blueprint for building reliable interactive AI: add a private working memory and structured routines.
What does this mean for the future?
This work suggests that truly capable language agents need a private workspace, not just public chat memory. With private working memory:
- Agents can host games, role-play characters, negotiate, tutor, or plan—any activity that depends on hidden state—without contradicting themselves or spilling secrets.
- Designers can choose workflows over free-form autonomy for predictability and reliability.
- We can balance “helpfulness” with “secrecy”: the agent can be honest internally while respecting the rules of the interaction publicly.
Overall, the paper provides both a theoretical proof and practical tools showing that private working memory is a necessary building block for trustworthy, interactive language agents.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored, framed to guide follow-up research:
- External validity beyond two tasks: Results are demonstrated only on Hangman and a Diagnosis Simulator; it is unclear how findings generalize to a broader suite of PSITs (e.g., negotiation, tutoring with hidden assessments, multi-agent games, multi-step planning with secret goals, deception tasks).
- Sensitivity to interaction length: The fork point is fixed at ; effects of longer horizons, deeper forks, and tighter public constraints on secrecy/consistency remain unmeasured.
- Candidate-set construction bias: Using Wordfreq and DDXPlus plus LLM-supplemented candidates may introduce coverage and distributional biases; robustness to dictionary choice, OOV items, and candidate-set size/quality is not assessed.
- Leakage detection robustness: Secrecy violations are detected via case-insensitive string matching; methods for detecting paraphrased, implicit, or partial leaks (and false positives/negatives) are not evaluated.
- Consistency vs rule-correctness: The protocol checks self-consistency at the fork but does not rigorously verify that all prior public responses obey task rules (e.g., Hangman letter placement and updates) throughout the full trajectory.
- Limited baseline tuning: Memory baselines (Mem0, A-Mem, LightMem, MemoryOS) are adapted to this setting without task-specific private-state extensions; it remains unknown whether stronger engineering (e.g., task-aware schemas, structured slots, or “private-only” channels) would narrow the gap.
- Model coverage: Only two open-weight families are tested; the generality of results to closed-source, frontier, or fine-tuned models (and to non-“reasoning” variants) is not characterized.
- Autonomy gap analysis: Autonomous agents underperform workflows, but the causes (tool-selection errors, mis-timed updates, prompt sensitivity) are not dissected; interventions such as learned tool-use policies, RL fine-tuning, or critique loops remain unexplored.
- Long-horizon efficiency and cost: Token overhead is measured, but latency, throughput, and monetary cost over very long conversations (and under memory growth/maintenance) are not quantified.
- Memory integrity and recovery: There is no analysis of memory corruption (e.g., erroneous writes), rollback/versioning, transactionality, or automatic consistency checks to detect and repair state drift.
- Garbage collection policies: Strategies for pruning, compressing, or summarizing private working memory (and their impact on performance) are not studied.
- Security and adversarial robustness: The system’s resilience to prompt injection, exfiltration attempts, and “secret extraction” by savvy users is not tested; threat models and mitigations (e.g., access control, red-teaming) are missing.
- Platform leakage risks: Private state is injected into system prompts; the implications of prompt-leak vulnerabilities, logging/telemetry exposure, and deployment platform behavior are not addressed.
- Ethical and user-consent questions: How to reconcile private state maintenance with transparency norms, user expectations, and disclosure policies is left unexamined, particularly in sensitive domains (e.g., medical).
- Formal scope of the impossibility theorem: The result assumes information-theoretic secrecy with deterministic rules; open questions include:
- Extension to stochastic or partially observable rules and to continuous/infinite domains.
- Whether computational secrecy mechanisms (e.g., cryptographic commitments or public ciphertext with secure key access) alter the POCA impossibility under realistic tool assumptions.
- Clarifying boundaries when agents can call tools that hold sealed secrets or server-side state.
- Steganographic/public-commitment channels: Can a POCA reliably embed a recoverable commitment to the secret in the public transcript (e.g., via commitments or steganography) without violating secrecy, and under what assumptions would that be practical or detectable?
- Hybrid memory architectures: How best to integrate vector retrieval with explicit private working memory (e.g., schema-guided slots, key–value stores, structured JSON state) remains open; trade-offs among readability, precision, and efficiency are not mapped.
- Learning what to write: The paper relies on prompting for memory updates; supervised, RL, or contrastive training to learn selective, minimal, and faithful state writes (and deletions) is not explored.
- Update-strategy design space: Only three update strategies (overwrite, append/delete, patch/replace) are tested; effects of stronger structure (e.g., typed fields, schemas, validators, state machines) and verified edits are unknown.
- Partial secrecy metrics: The binary secrecy definition overlooks graded uncertainty; metrics based on entropy over candidate secrets, mutual information, or calibrated uncertainty could reveal more nuanced leakage/consistency dynamics.
- Player policy dependence: Results may depend on the rule-based Player’s questioning strategy; robustness to alternative, adversarial, or adaptive player policies is not assessed.
- Multi-agent coordination: Maintaining private and shared state across multiple agents (and ensuring inter-agent secrecy/consistency) is unstudied.
- Cross-session and long-term private state: How to persist, migrate, or retire private working memory across sessions, devices, or tools (with identity and access control) is not addressed.
- Safety–secrecy trade-offs: Alignment-induced leakage (e.g., models “being helpful” by revealing secrets) is observed but not systematically disentangled or mitigated; principled methods to balance helpfulness with secrecy are needed.
- Reproducibility clarifications: Dynamic evaluation introduces run-to-run variance; full seed control, artifact release (prompts, code, logs), and standardized SCT configurations for comparability across labs would strengthen reproducibility.
Practical Applications
Immediate Applications
Below are actionable uses that can be deployed with today’s LLMs by adding a private working-memory layer and the paper’s self-consistency test harness.
- Private working-memory middleware for agent frameworks — Software/platform
- What: Ship a lightweight “private state” module (text block injected into hidden system context) with deterministic update tools (overwrite, append/delete, patch/replace) and a workflow controller.
- Where: LangGraph, LangChain, LlamaIndex, CrewAI, custom agent stacks.
- Why: Restores hidden-state consistency without the token bloat of private CoT; workflows outperform autonomous tool invocation for reliability.
- Assumptions/dependencies: Model allows system-prompt injection and tool-use; infra can store per-session private state; UI does not expose private memory; logging/redaction policies are in place.
- Self-consistency testing as CI/CD for agent deployments — Software/QA, cross-industry
- What: Implement the paper’s forked-dialogue Self-Consistency Testing (SCT) to verify hidden–public coherence before release.
- Where: Chatbots in customer support, sales assistants, healthcare symptom checkers, edtech tutors, game bots.
- Why: Detects leakage, over-confirmation, state substitution, and all-denial behaviors; provides pass/fail gates.
- Assumptions/dependencies: Deterministic player scripts or probes; automated parsing of yes/no; dataset or generator for candidate secrets.
- Replace “RAG-as-state” with explicit private state — Software/enterprise
- What: Refactor RAG-based assistants that implicitly rely on retrieval for “state” to maintain a proper private working memory.
- Where: CRM co-pilots, IT helpdesk, knowledge assistants.
- Why: Retrieval ≠ state; avoids inconsistent or fabricated internal decisions across turns.
- Assumptions/dependencies: Existing vector stores remain for knowledge; new state channel added for dynamic hidden variables.
- Workflow-first agent templates for reliability — Software/operations
- What: Offer default workflow graphs that force “respond → update private memory” each turn.
- Where: Mission-critical assistants (support triage, KYC intake, internal tooling).
- Why: Deterministic workflows outperformed autonomous agents in consistency.
- Assumptions/dependencies: Orchestration layer (e.g., LangGraph) and minimal tool catalog.
- Cost reduction by compressing private state — Finance/ops for AI teams
- What: Swap private CoT persistence for compact private working memory (<~100 tokens).
- Where: Any long-horizon agent to cut context costs and latency.
- Why: ~10× smaller private state vs. retained CoT per the paper’s efficiency analysis.
- Assumptions/dependencies: Memory compaction prompts; monitoring to avoid information loss.
- Hidden-answer tutoring and assessment — Education
- What: Tutors keep an answer key and graded rubric private while providing hints and Socratic guidance.
- Where: Math/physics problem sets, coding labs, language learning drills.
- Why: Prevents accidental answer leakage; consistent feedback.
- Assumptions/dependencies: Secure private memory; reveal policy; SCT can probe answer-key consistency.
- Standardized patient/chat-based simulations — Healthcare education
- What: Patient agents hold a private diagnosis; students query symptoms to practice differential diagnosis.
- Where: Med/nursing schools, CME modules.
- Why: Demonstrated Diagnosis Simulator; private state ensures consistent case behavior.
- Assumptions/dependencies: Curated case datasets (e.g., DDXPlus); leakage monitoring; institutional oversight.
- Negotiation and role-play training with private types — HR/sales/education
- What: Agents maintain private reservation prices, preferences, or objectives across the scenario.
- Where: Sales enablement, conflict resolution workshops, soft-skill training.
- Why: PSIT framing matches private-type games; improves realism and assessment.
- Assumptions/dependencies: Scenario authoring tools; guardrails to avoid revealing private types prematurely.
- Game and entertainment bots with secrets — Gaming/consumer apps
- What: Hosts for Hangman, Chameleon-like games, mystery puzzles, escape-room NPCs with hidden goals.
- Where: Messaging apps, gaming platforms, classroom activities.
- Why: Private working memory enables consistent hidden-state gameplay.
- Assumptions/dependencies: Content moderation; replayability via seed control.
- “Surprise planning” personal assistants — Daily life/consumer
- What: Plan surprises (parties, gifts) while chatting with multiple participants without revealing details to the recipient.
- Where: Family/workgroup planning tools.
- Why: Architectural secrecy prevents helpfulness-aligned leaks.
- Assumptions/dependencies: Access controls across participants; encrypted private state.
- Compliance-friendly decision support with stable thresholds — Finance/insurance
- What: Keep private internal cutoffs (e.g., risk scores, fraud suspicion thresholds) while explaining decisions consistently.
- Where: Claims triage assistants, underwriting desk support.
- Why: Ensures consistency without exposing proprietary models or enabling gaming.
- Assumptions/dependencies: Audit trails of private memory edits; legal review.
- Red-team harness for leakage and bluffing — Security/safety
- What: Use SCT-derived probes to test if agents bluff, leak, or flip states under adversarial prompts.
- Where: Safety evals, vendor qualification, procurement.
- Why: Empirically surfaces the “bluff vs. abstain” tension highlighted in the paper.
- Assumptions/dependencies: Test suites; controlled decode settings.
- Memory-edit developer tools (patch/replace) — Developer productivity
- What: Provide VS Code–style memory diffing and idempotent edits for reproducible agent runs.
- Where: Agent observability/debugging stacks.
- Why: Fine-grained, safe updates reduce drift and unintended deletions.
- Assumptions/dependencies: Tool APIs; versioned memory logs.
Long-Term Applications
These rely on further research, scaling, productization, or standardization before widespread deployment.
- Native private-memory channels in LLM APIs — Software/standards
- What: First-class hidden context windows (separate from public messages), with policies for visibility, logging, and billing.
- Why: Removes reliance on prompt conventions; standardizes PSIT support across providers.
- Dependencies: API/provider adoption, telemetry design, compatibility with safety layers.
- Architectural persistence beyond prompts — ML research
- What: Models with trainable, persistent working memory across turns (e.g., slot-based or keyed memory) not serialized as text.
- Why: Efficiency, robustness, and reduced leak risk; better than reinjecting text each turn.
- Dependencies: Training objectives for generative-retention loop; long-horizon RL/finetuning.
- Formal PSIT benchmark suite and leaderboards — Academia/standards
- What: Beyond Hangman/diagnosis to negotiation, hidden-intent tutoring, multi-agent games; unified SCT metrics.
- Why: Comparable, reproducible evaluation of secrecy and consistency.
- Dependencies: Open datasets, harnesses, community buy-in.
- Provable secrecy with verifiable consistency — Security/cryptography
- What: Use cryptographic commitments or zero-knowledge proofs so agents can prove consistency with a hidden state without revealing it.
- Why: High-assurance applications (e.g., auctions, sealed-bid procurement).
- Dependencies: Protocol design, performance engineering, integration with LLM tooling.
- Enterprise-grade “Memory OS” with access control — Enterprise platforms
- What: Multi-tenant private memory tiers, encryption at rest/in use, role-based access, retention policies, and auditability.
- Why: Compliance (SOX, HIPAA, GDPR) for PSIT-capable agents in production.
- Dependencies: Security certifications, policy engines, key management.
- Clinical decision support with private differentials — Healthcare
- What: CDS tools that maintain a private hypothesis set to avoid anchoring, revealing rationale selectively with guardrails.
- Why: Safer, more systematic reasoning traces; reduces cognitive biases.
- Dependencies: Regulatory clearance, rigorous validation, human-in-the-loop protocols.
- Market and auction agents with private types — Finance/market design
- What: Agents in simulated or real markets with private valuations, bidding strategies, and commitment devices.
- Why: Research, training, and eventual deployment in mechanism design.
- Dependencies: Oversight, fairness and anti-gaming controls, economic validation.
- Robotics and embodied agents with internal state — Robotics
- What: Task-planning agents that keep private plans, goals, and hypotheses across long-horizon tasks.
- Why: More reliable execution and recovery; better human-robot interaction narratives.
- Dependencies: Tool grounding, safety, and real-time memory operations.
- Multi-agent simulations for social science — Academia/policy labs
- What: Agents endowed with hidden beliefs and preferences for studying institutions, misinformation, and policy interventions.
- Why: More realistic simulations of strategic behavior.
- Dependencies: Calibration to human data, ethical review, reproducibility protocols.
- Procurement and policy guidelines for PSIT — Policy/governance
- What: Require SCT-like evaluation, private-memory separation, and leakage thresholds in government/enterprise RFPs.
- Why: Baseline trust and reliability in interactive agents.
- Dependencies: Standards bodies, reference implementations, compliance testing services.
- Autonomous memory optimization via RL — ML research
- What: Learn when/what to write, edit, and delete in private memory to minimize leakage and maximize task success.
- Why: Scales beyond deterministic workflows while preserving reliability.
- Dependencies: Reward design, safe exploration, telemetry.
- UI/UX patterns for dual-channel conversations — Product design
- What: Interfaces that visualize “what the agent knows publicly” vs. “what it privately tracks,” with controlled reveals and consent.
- Why: Transparency without compromising secrecy constraints; better trust.
- Dependencies: Usability research, accessibility, policy toggles.
- Secure enclaves for agent memory — Infrastructure/security
- What: Run private working memory in hardware-backed enclaves; provide signed attestations for audits.
- Why: Sensitive domains (health, finance, gov).
- Dependencies: Confidential compute, attestation pipelines, integration with LLM runtimes.
Notes on feasibility and cross-cutting assumptions
- Tool-use capability: Many immediate applications presume models that can call tools/functions reliably; smaller models may need finetuning.
- Privacy and compliance: Private memory can contain sensitive data; encryption, retention, and audit controls are essential.
- Safety alignment: Even with private memory, alignment may push toward leakage unless prompts and reward signals are adjusted.
- Observability: Robust logging and diffing of private memory states enable debugging, audits, and reproducibility.
- Determinism vs. flexibility: For critical paths, prefer workflow agents; use autonomous memory agents where variability is acceptable and monitored.
Glossary
- A-mem: An external memory system that organizes interactions into linked notes for evolving knowledge. "A-mem organizes interactions into atomic, linked notes inspired by the Zettelkasten method, with LLM-driven semantic linking and memory updates \citep{kadavy2021digital, xu2025mem}."
- Atkinson-Shiffrin model: A cognitive model positing multi-stage memory (sensory, short-term, long-term). "Similarly, LightMem adopts a three-stage Atkinson-Shiffrin model for efficient retrieval \citep{fang2025lightmem}."
- AutoGPT: A large-scale autonomous agent framework that cycles through planning, execution, and retrieval. "Larger-scale systems such as AutoGPT, BabyAGI, and DeepResearch demonstrate cycles of planning, execution, and retrieval that unlock more autonomous behavior \citep{sapkota2025ai, huang2025deepresearchagents}."
- ChromaDB: An open-source vector database used for storing and retrieving embeddings. "A-Mem~\citep{xu2025mem} utilizes the all-MiniLM-L6-v2 embedding model and ChromaDB; it analyzes the last messages to generate metadata (keywords, tags) and retrieves the top notes per turn."
- CoALA: A cognitive architecture integrating episodic, semantic, and procedural memory in decision cycles. "CoALA integrates episodic, semantic, and procedural memory within a structured decision cycle \citep{sumers2023cognitive}."
- CodeAct: An agent framework that generates and executes code to unify the action space. "CodeAct unifies the action space by generating and executing Python code \citep{wang2024executable}."
- CrewAI: A framework for building multi-agent LLM systems and tooling. "frameworks like LangChain, LlamaIndex, and CrewAI provide tooling for these architectures \citep{langchain2022, llamaindex2023, crewai2024}."
- DDXPlus dataset: A medical dataset for differential diagnosis used to simulate patient conditions. "Utilizing the DDXPlus dataset \citep{fansi2022ddxplus}, the Player issues yes/no questions about specific symptoms (evidences) to prune the hypothesis space."
- Episodic buffer: A component in Baddeley’s working memory model that integrates and stores episodic information. "Classic cognitive theories highlight the modularity of working memory, most notably Baddeleyâs multi-component model with its central executive and episodic buffer \citep{baddeley1983working}."
- Fisher's exact test: A statistical test for categorical data, suitable for small sample sizes. "To assess statistical significance, we employ Fisher's exact test to compare each proposed method against the baselines, stratifying by game and model to account for varying task difficulties and model capabilities."
- Generative Agents: Simulated agents with persistent memory that exhibit realistic behavior. "In parallel, other systems target behavioral simulation, such as Generative Agents \citep{park2023generative} and Reflexion \citep{NEURIPS2023_1b44b878}."
- Generative-Retention Loop: A requirement for agents to both create and persist internal information across turns. "In contrast, solving PSITs requires a Generative-Retention Loop: the agent must not only recall existing data but generate new information (e.g., a secret word, a plan, or a reasoning step) and immediately retain it for future turns."
- HippoRAG: A RAG variant inspired by hippocampal indexing to support multi-hop reasoning. "HippoRAG modeling hippocampal indexing for multi-hop reasoning \citep{gutierrez2024hipporag}."
- HIAGENT: A hierarchical agent framework emphasizing working-memory management with chunking. "HIAGENT uses hierarchical working-memory management with chunking \citep{hu2024hiagent}."
- Holm-Bonferroni correction: A multiple-comparisons procedure that controls the family-wise error rate. "To control the family-wise error rate across the family of all pairwise comparisons, we apply the Holm-Bonferroni correction at a significance level of ."
- LangChain: A framework for composing LLM applications with tools, memory, and retrieval. "frameworks like LangChain, LlamaIndex, and CrewAI provide tooling for these architectures \citep{langchain2022, llamaindex2023, crewai2024}."
- LangGraph: A framework for graph-structured LLM agents and workflows. "All agents are implemented using the LangGraph framework~\citep{LangGraph}, utilizing MemorySaver checkpointing to ensure state persistence across conversation turns."
- LLMLingua-2: A model for prompt compression and topic segmentation. "LightMem~\citep{fang2025lightmem} leverages LLMLingua-2~\citep{pan2024llmlingua} for compression and topic segmentation."
- LlamaIndex: A framework for retrieval-augmented LLM applications over external data. "frameworks like LangChain, LlamaIndex, and CrewAI provide tooling for these architectures \citep{langchain2022, llamaindex2023, crewai2024}."
- Mem0: A memory system that extracts and updates salient facts for personalization and consistency. "Mem0 maintains long-term consistency via LLM-based extraction and dynamic ADD/UPDATE/DELETE operations over stored facts \citep{chhikara2025mem0}."
- MemGPT: A system introducing virtual context management for unbounded conversations. "MemGPT introduces virtual context management to support unbounded contexts \citep{packer2023memgpt}."
- MemoryOS: An OS-inspired hierarchical memory architecture with tiered storage and dynamic updates. "MemoryOS implements a hierarchical storage architecture (short, mid, and long-term) with dynamic updating strategies \citep{kang2025memory}."
- Memory-R1: A memory system that uses reinforcement learning to optimize memory operations. "Memory-R1, which leverages reinforcement learning for structured memory operations \citep{yan2025memoryr1enhancinglargelanguage}."
- MemorySaver: A checkpointing mechanism to persist agent state across turns. "All agents are implemented using the LangGraph framework~\citep{LangGraph}, utilizing MemorySaver checkpointing to ensure state persistence across conversation turns."
- Patch/Replace-in: A fine-grained memory-editing strategy using diff-like patches and precise replacements. "Patch/Replace-in. A fine-grained strategy inspired by industrial code editing tools such as the open-source VS Code Copilot Chat framework~\citep{vscode-copilot-chat}."
- Private Chain-of-Thought: An approach that keeps hidden reasoning across turns to preserve internal state. "Private Chain-of-Thought agents that preserve hidden reasoning across turns;"
- Private State Interactive Tasks (PSITs): Interactive tasks where agents must generate, preserve, and act consistently with hidden state. "We define Private State Interactive Tasks (PSITs), which require agents to generate and maintain hidden information while producing consistent public responses."
- Public-Only Chat Agent (POCA): An agent that conditions only on public dialogue without any private state. "A public-only chat agent (POCA) is an agent whose outputs at each turn are solely a function of the publicly visible dialogue history, without access to any private state."
- Qdrant: A vector database for high-dimensional similarity search used in memory systems. "Mem0~\citep{chhikara2025mem0} employs Qdrant for vector storage with OpenAI's text-embedding-3-small as the default embedding model."
- RAG (Retrieval-Augmented Generation): A method that combines generated text with externally retrieved information. "Retrieval-Augmented Generation (RAG) couples parametric knowledge with external retrieval \citep{lewis2020retrieval}."
- RAG+: An extension of RAG that grounds retrieval in task exemplars. "with RAG+ grounding retrieval in task exemplars \citep{wang2025rag+}"
- Reflexion: A technique enabling agents to improve via self-feedback and iterative reflection. "Reflexion enables agents to iteratively improve via self-feedback and reflection \citep{NEURIPS2023_1b44b878}."
- ReAct: A framework coupling verbal thoughts with external actions to enhance planning and tool use. "ReAct couples verbal âthoughtsâ with external actions to improve planning and tool use \citep{yao2023react}."
- Self-Consistency Testing Protocol: A protocol that forks dialogue branches to probe hidden–public coherence. "we introduce a self-consistency testing protocol that evaluates whether agents can maintain a hidden secret across forked dialogue branches."
- StateAct: A framework that adds self-prompting and explicit state-tracking to reduce goal drift. "StateAct extends this idea with self-prompting and explicit state-tracking to reduce goal drift \citep{rozanov2024stateact}."
- Unified Mind Model: A cognitive architecture proposing layered components with a central working-memory core. "the Unified Mind Model proposes a layered architecture with a central working-memory core \citep{hu2025unified}."
- Wordfreq database: A frequency-based word list used to generate candidate words under constraints. "we filter the Wordfreq database \citep{robyn_speer_2022_7199437} to generate a set of candidate words that are syntactically indistinguishable from the secret given the public history;"
- Zettelkasten: A note-taking methodology that organizes atomic, linked notes into a knowledge network. "A-mem utilizes Zettelkasten-style networking for evolving knowledge \citep{kadavy2021digital, xu2025mem}."
Collections
Sign up for free to add this paper to one or more collections.