Gecko: An Efficient Neural Architecture Inherently Processing Sequences with Arbitrary Lengths
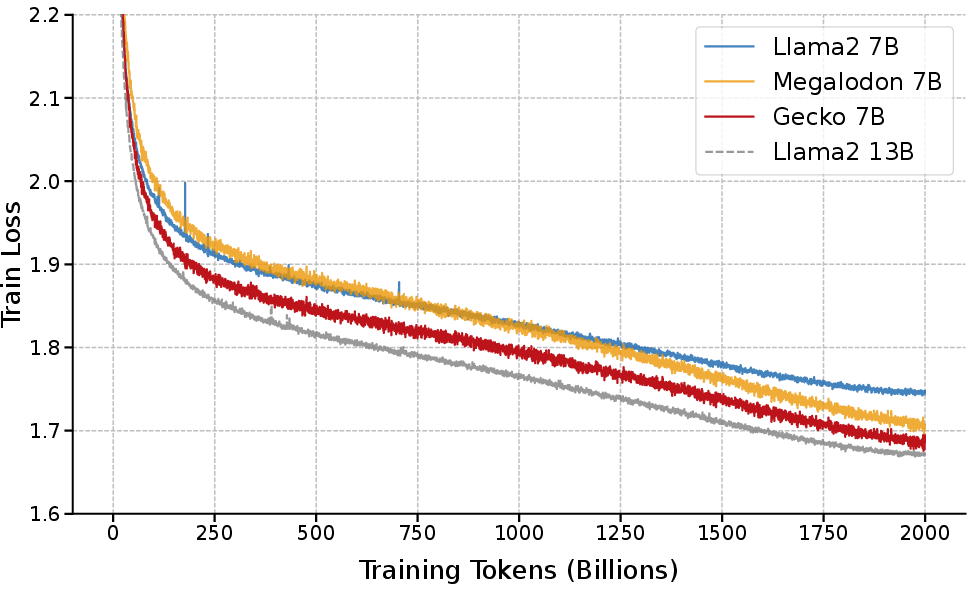
Abstract: Designing a unified neural network to efficiently and inherently process sequential data with arbitrary lengths is a central and challenging problem in sequence modeling. The design choices in Transformer, including quadratic complexity and weak length extrapolation, have limited their ability to scale to long sequences. In this work, we propose Gecko, a neural architecture that inherits the design of Mega and Megalodon (exponential moving average with gated attention), and further introduces multiple technical components to improve its capability to capture long range dependencies, including timestep decay normalization, sliding chunk attention mechanism, and adaptive working memory. In a controlled pretraining comparison with Llama2 and Megalodon in the scale of 7 billion parameters and 2 trillion training tokens, Gecko achieves better efficiency and long-context scalability. Gecko reaches a training loss of 1.68, significantly outperforming Llama2-7B (1.75) and Megalodon-7B (1.70), and landing close to Llama2-13B (1.67). Notably, without relying on any context-extension techniques, Gecko exhibits inherent long-context processing and retrieval capabilities, stably handling sequences of up to 4 million tokens and retrieving information from contexts up to $4\times$ longer than its attention window. Code: https://github.com/XuezheMax/gecko-LLM
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces Gecko, a new kind of AI model designed to read and understand very long pieces of information efficiently—think entire books, long conversations, or hours of video transcripts. Unlike many current models that slow down or forget things when the text gets very long, Gecko is built to handle sequences of almost any length smoothly and to remember important details over time.
The big questions the paper asks
- Can we design a model that reads very long inputs without becoming slow or running out of memory?
- Can that model keep track of important information from far back in the text—like remembering a clue from chapter 1 while reading chapter 20?
- Can it do all this while performing as well as or better than popular models like Llama2 on standard tests?
How Gecko works (in simple terms)
Gecko improves on earlier models (called Mega and Megalodon) and adds three new ideas. You can think of Gecko as a super-organized reader that uses good habits to remember and connect information across a very long story.
1) Timestep Decay Normalization: a better “running average”
When models read, they normalize their inputs (like keeping a running average and spread). Older methods treated older information as much more important than recent information as time went on. Gecko fixes this by carefully balancing how much the “current” and “past” information matter, so the model stays stable even as sequences get very long. Analogy: Instead of averaging all your test scores equally (which makes early tests dominate if there are many), Gecko keeps a steady balance so each new test still counts properly.
2) Sliding Chunk Attention: reading with overlapping pages
Many models split long text into chunks (blocks) and only look inside each chunk. That makes them miss connections across chunk boundaries. Gecko uses “sliding chunk attention,” which lets each chunk pay attention to the current chunk and the previous one. Analogy: If you read a book page-by-page, Gecko makes sure each page overlaps with the previous page, so you don’t lose the thread at the page breaks. This is efficient because it computes attention in chunk-sized pieces (fast on modern hardware), not tiny per-token pieces.
3) Adaptive Working Memory: a compact long-term memory
Even with overlapping chunks, really old information can still fall out of view. Gecko adds a compact memory that keeps a summarized version of everything seen so far. It’s updated as the model moves through the text, so useful facts don’t get lost. Analogy: You keep a small notebook with running summaries as you read. You can quickly look up past notes (long-term memory) while still focusing on the current pages (short-term memory). Gecko’s memory uses a smart “online softmax” trick to keep these summaries stable and accurate without blowing up in size.
What the researchers did
The team trained Gecko at different sizes and compared it fairly against well-known models using the same training data and similar settings:
- Gecko-7B (about 7 billion parameters) was trained on 2 trillion tokens (tiny pieces of text, like words or subwords), just like Llama2-7B and Megalodon-7B.
- They tested Gecko on both regular tasks (short inputs) and long-context tasks (very long inputs), including:
- Standard benchmarks (like MMLU, BoolQ, PIQA, etc.).
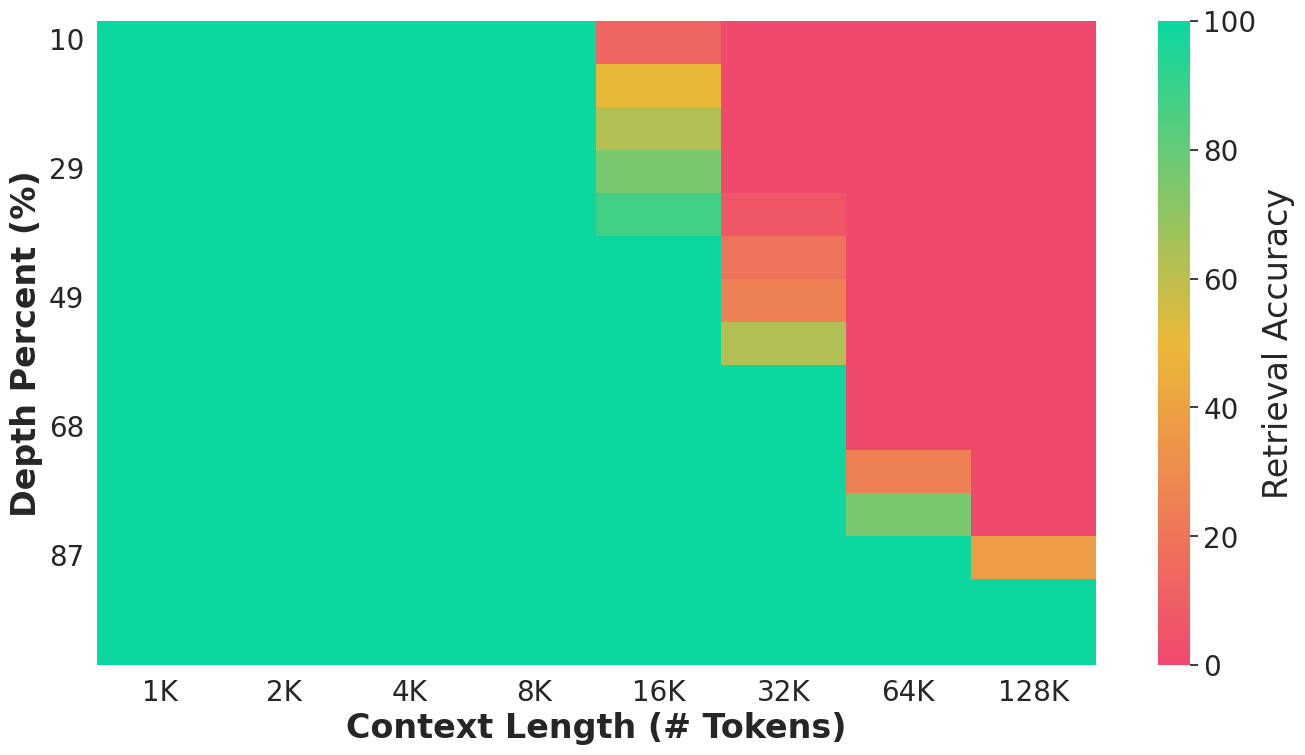
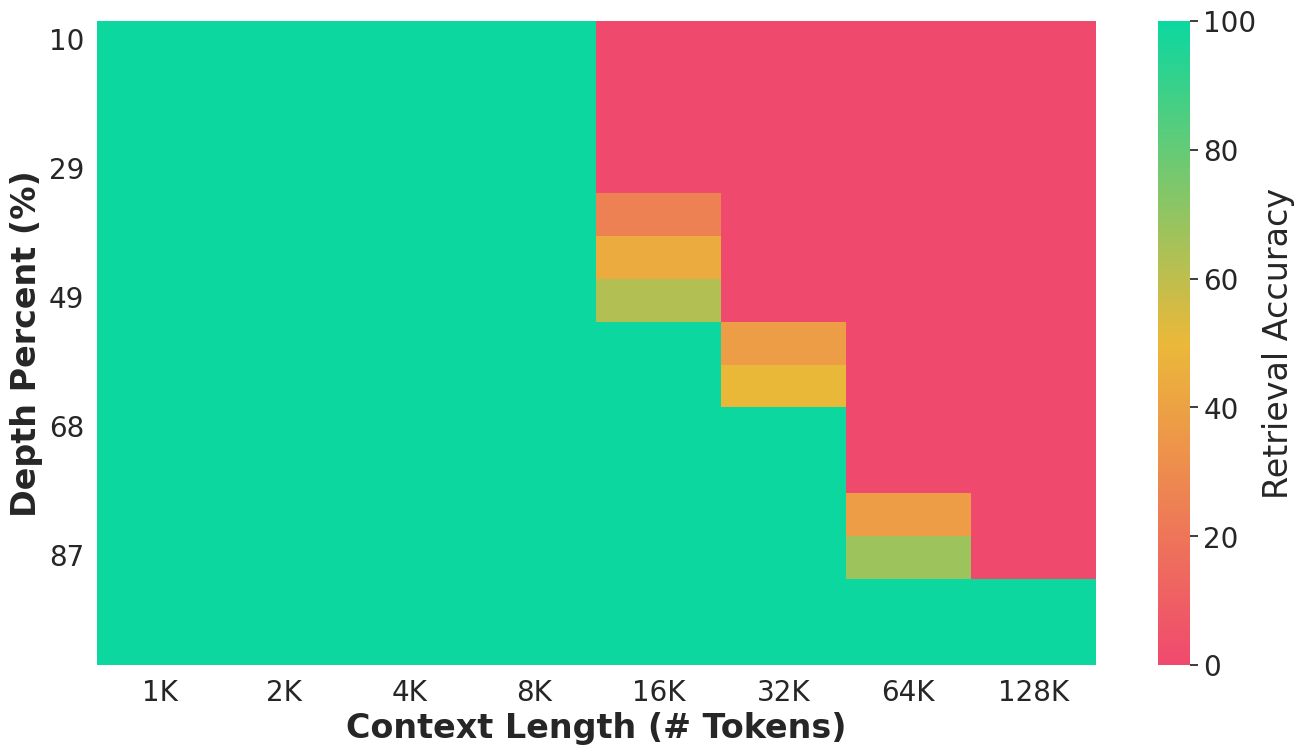
- “Needle in a haystack” tests (finding hidden information in long text).
- Long-question-answering tasks (Scrolls benchmark).
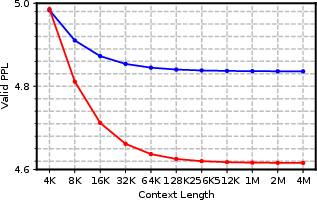
- Very long validation sequences (up to 4 million tokens) to see how well it scales.
Main results and why they matter
Here are the most important findings from the paper:
- Better training efficiency and quality:
- Gecko-7B reached a training loss of 1.68 (lower is better), beating Llama2-7B (1.75) and Megalodon-7B (1.70), and nearly matching Llama2-13B (1.67), which is a much larger model.
- Strong on standard tasks:
- On common academic benchmarks, Gecko-7B consistently matched or beat Llama2-7B and Megalodon-7B, even though it didn’t need extra special data tricks.
- Built-in long-context ability:
- Gecko handled sequences up to 4,000,000 tokens during evaluation without relying on extra “context extension” methods.
- As the context got longer, Gecko’s performance kept improving, showing it actually uses the extra context well.
- Finds hidden information in long texts:
- On “needle in a haystack” tests, Gecko could retrieve information from contexts up to 4 times longer than its attention window—meaning it could remember and retrieve facts from far beyond what it was directly focusing on.
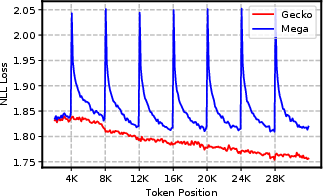
- Smoother performance across chunk boundaries:
- The model avoided the usual “drop” in quality at chunk edges that other chunk-based methods suffer. This means it keeps the story coherent across boundaries.
- Efficient and hardware-friendly:
- The sliding chunk design and memory updates are done in larger, chunk-sized operations that run fast on GPUs. This makes it practical for training and using Gecko on long inputs.
What this could lead to
Gecko shows that LLMs can be designed to naturally handle very long inputs without slowing down or forgetting. This opens the door to:
- Better long-form understanding: reading books, legal documents, research papers, and long conversation histories without losing track.
- More reliable reasoning over long time spans: solving problems that depend on connecting far-apart facts.
- Practical and scalable systems: faster, more memory-friendly training and use on modern hardware.
- Less need for “context extension” hacks: models like Gecko can handle long context by design.
In short, Gecko points to a future where AI can read and remember truly long stories—efficiently and accurately—making it more useful in real-world tasks that involve lots of information over time.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper. Each point identifies a concrete direction for future work.
- Lack of theoretical guarantees for Adaptive Working Memory (AWM): no analysis of information preservation, collision behavior, error accumulation, or stability bounds when compressing arbitrarily long histories into fixed-size memory.
- Numerical stability of position-aware online softmax in AWM is unaddressed: potential overflow/underflow in the cumulative denominator over millions of tokens, precision requirements (e.g., BF16/FP32), and whether log-sum-exp or rescaling is needed for safe long-context inference.
- Absence of component-level ablations: the paper does not quantify the individual and combined contributions of Timestep Decay Normalization (TDN), Sliding Chunk Attention (SCA), and AWM to efficiency, perplexity, retrieval, and robustness.
- Hyperparameter sensitivity is unexplored: the impact of TDN parameters (
β₁=0.999,β₂=0.9999), chunk sizec, SCA window composition (current vs. multiple previous chunks), and AWM kernel choices on performance and stability across tasks and sequence lengths. - No guidance on adaptive or learned TDN schedules: how to set or adapt
β₁,β₂per layer, per group, or over training to balance responsiveness vs. stability in very long sequences. - Interaction between RoPE and Gecko’s long-context modules is unclear: the role of positional embeddings beyond the 32K training window (e.g., RoPE scaling/YaRN-like methods), and whether Gecko’s gains persist or improve with alternative positional schemes.
- Efficiency claims lack detailed empirical profiling: no wall-clock throughput, latency, memory footprint, and FLOPs measurements for training and inference across sequence lengths (e.g., 4K, 32K, 128K, 1M, 4M) compared to Transformers, SWA, SSMs (Mamba/Mamba2), and linear attention variants.
- Distributed training overheads are not quantified: communication volume, overlap effectiveness, scalability limits, and failure modes of SCA’s context parallelism (e.g., at >256 GPUs, heterogeneous interconnects).
- AWM memory size, scope, and implementation details are under-specified: whether memory is per-head, per-layer, or shared; actual dimensionality and storage cost of ; and runtime memory pressure for large models/long sequences.
- Streaming and segmentation protocols are not described: how memory is reset or carried across document/session boundaries, mitigation of cross-document leakage, and policies for session-aware memory management.
- Retrieval robustness is under-tested: behavior under distractors, multiple needles, varied needle salience, noisy or adversarial contexts, and domain-realistic long documents (legal, codebases, multi-source reports).
- Long-context generation quality is not evaluated: beyond perplexity and short-form QA, the paper lacks tests on long-form reasoning, multi-turn dialogue with persistent state, code synthesis across large repos, or multi-document summarization.
- Limits of retrieval beyond 4× attention window remain unknown: quantitative scaling laws for retrieval accuracy as a function of chunk size, depth, and memory design, and how to push this multiplier higher.
- Comparative long-context benchmarks are incomplete: no direct comparisons against strong SSM/linear-attention baselines (e.g., Mamba2, Hyena, GatedDeltaNet) on standardized long-range tasks, including Scrolls variants and Ruler extensions.
- Effects at larger model scales are untested: training/inference stability, efficiency, and performance at 13B–70B+ scales, and whether Gecko’s advantages persist or amplify with model size.
- Generalization to non-text modalities is unverified: application to audio, video, time-series, and genomics where long-range dependencies are prominent; required adaptations for input encoders and positional modeling.
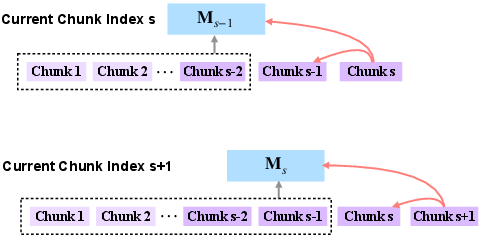
- Chunk design space is unexplored: SCA currently uses the immediately preceding chunk; the trade-offs of attending to multiple previous chunks, dynamic chunk sizes, or learnable chunk boundaries are not analyzed.
- Gradient behavior over extreme contexts is not studied: whether Gecko mitigates vanishing/exploding gradients for sequence lengths of millions of tokens; effects of removing normalization terms in linear attention; and gradient diagnostics per module.
- Interactions between CEMA, SCA, and AWM are not characterized: how local EMA inductive biases, cross-chunk attention, and long-term memory jointly contribute to modeling and whether they introduce redundancy or interference.
- Fairness and reproducibility details are limited: precise data mixtures, preprocessing, tokenization differences (OLMo vs. Llama2 setups), seeds, numeric formats, and training pipelines necessary to replicate the reported results.
- Energy efficiency is not reported: GPU-hours, training power consumption, and carbon footprint compared to Transformers and SSMs for equivalent quality at long context.
- Safety and failure modes are not assessed: susceptibility to prompt injection over very long contexts, memory poisoning, and misretrieval under adversarial or ambiguous inputs.
- Applicability to instruction tuning and RLHF is unknown: how Gecko’s long-context mechanisms behave during post-training alignment phases and whether memory features require special handling.
- Downstream integration with RAG systems is unexplored: whether AWM and SCA synergize with external vector databases, chunking strategies, re-ranking, and retrieval pipelines in end-to-end long-context applications.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now using Gecko’s architecture (or its components), based on the paper’s reported performance, open-source code, and hardware-friendly implementations.
- Long-document QA and analysis at enterprise scale
- Sectors: legal, consulting, publishing, research, government
- What it does: Analyze entire books, legal contracts, regulatory filings, and technical manuals without aggressive chunking; answer questions, summarize, and retrieve details across tens of thousands to millions of tokens.
- Tools/products/workflows: “Long-Doc Assistant” for legal e-discovery and diligence; literature-review copilots that ingest full papers/monographs; unified context windows for due diligence.
- Assumptions/dependencies: Multi-GPU or high-memory servers to use very long contexts efficiently; domain fine-tuning improves accuracy; latency grows roughly linearly with sequence length.
- Conversational analytics with persistent memory
- Sectors: customer support, sales enablement, CX ops
- What it does: Summarize multi-hour/multi-session transcripts; surface commitments and action items; retrieve facts from long histories without external memory hacks.
- Tools/products/workflows: Call-center summarizers; CRM copilots that re-use conversation memory across cases; meeting-minutes generators for large sequences of calls.
- Assumptions/dependencies: Data governance for PII; careful prompt design for long-turn dialogues; throughput tuning to keep latency acceptable.
- Codebase- and repo-scale reasoning
- Sectors: software engineering, DevOps, security
- What it does: Navigate and reason over large repositories (monorepos), cross-file dependencies, and long incident logs; explain diffs and perform multi-file refactoring guidance.
- Tools/products/workflows: IDE assistants that “read the repo”; incident postmortem generators; static analysis helpers on long traces.
- Assumptions/dependencies: Tokenization cost for large codebases; need repo-aware prompting; potentially combine with lightweight retrieval for very large fleets.
- Time-series and log modeling with long horizons
- Sectors: finance (market microstructure), observability (logs/metrics/traces), IoT
- What it does: Model long streams with stable statistics via Timestep Decay Normalization (TDN); retain long-term structure via Adaptive Working Memory (AWM).
- Tools/products/workflows: Anomaly detection over long traces; end-of-day risk narratives from intraday ticks; long-span KPI report generation.
- Assumptions/dependencies: Domain adaptation is needed; throughput constraints on extreme sequence lengths.
- Healthcare longitudinal summarization (structured + unstructured)
- Sectors: healthcare, insurance
- What it does: Summarize patient histories across years of notes, labs, and encounters; retrieve relevant episodes for complex cases.
- Tools/products/workflows: EHR copilots that read long histories; care-plan generators; pre-visit briefs across long records.
- Assumptions/dependencies: PHI/PII handling, HIPAA compliance; fine-tuning on clinical corpora; cost control for very long sequences.
- Scientific literature ingestion and cross-paper synthesis
- Sectors: academia, pharma R&D, policy research
- What it does: Process multiple long papers end-to-end; extract, compare, and synthesize methods/results across documents.
- Tools/products/workflows: Research assistants that operate on full PDFs; grant-application summarizers; triage tools for large reading lists.
- Assumptions/dependencies: High-quality PDF-to-text; domain-specific evaluation/finetuning.
- Built-in retrieval without external context-extension
- Sectors: software, enterprise AI platforms
- What it does: Use Gecko’s inherent retrieval to reduce dependence on complex context-extension methods (e.g., chunk-overlap schemes) for 8–32k contexts, and beyond when feasible.
- Tools/products/workflows: Simplified RAG pipelines with fewer chunking heuristics; better end-to-end reproducibility.
- Assumptions/dependencies: For massive corpora, hybrid RAG still beneficial; tokenizer and prompt design matter.
- Drop-in architectural upgrades for long-context models
- Sectors: ML platforms, model providers, research labs
- What it does: Replace chunk-wise attention with Sliding Chunk Attention (SCA) to fix boundary loss; apply Timestep Decay Normalization for stable long sequences; add AWM for long-range recall.
- Tools/products/workflows: Gecko-blocks as modules in PyTorch/JAX; retrofitting Megalodon-like models; context-parallel training/inference kernels.
- Assumptions/dependencies: Engineering integration effort; careful kernel support; re-tuning hyperparameters.
- Long-context benchmarking and evaluation services
- Sectors: MLOps, evaluation platforms
- What it does: Offer standardized long-context evaluation (Scrolls, NIAH, passkey retrieval) to validate model claims across 8k–4M tokens.
- Tools/products/workflows: “Long-Context Eval Suite” as a service; CI hooks for model regressions.
- Assumptions/dependencies: Compute budget for long-context tests; dataset licensing for benchmarks.
- Cost-efficient multi-GPU training with context parallelism
- Sectors: model-training platforms, large research labs
- What it does: Use SCA-friendly context parallelism to scale training on long sequences, hiding KV-chunk communication latency.
- Tools/products/workflows: Training recipes that combine data parallel, chunk parallel, and context parallel; monitoring/compression pipelines for KV caches.
- Assumptions/dependencies: Cluster with high-bandwidth interconnect; reliable async comm; kernel support.
- Education: end-to-end processing of complete textbooks and lecture transcripts
- Sectors: EdTech
- What it does: Build study guides, practice Q&A, and concept maps from full-length materials; track references across entire texts.
- Tools/products/workflows: Course companions that consume whole textbooks and semester-long transcripts.
- Assumptions/dependencies: Copyright/licensing; robust segmentation from PDFs; prompt curation for pedagogy.
- Policy and regulatory analysis across long corpora
- Sectors: public policy, legal, compliance
- What it does: Compare revisions of long bills; assemble side-by-sides; summarize public comments at scale.
- Tools/products/workflows: Rulemaking assistants; oversight dashboards; compliance traceability across lengthy documents.
- Assumptions/dependencies: Provenance tracking; auditability; human-in-the-loop review.
Long-Term Applications
These require further research, scaling, or productization—e.g., broader weight releases, optimized kernels for extreme contexts, or domain-specific validation.
- Personal “lifelog” assistants with native, persistent memory
- Sectors: consumer software, productivity
- What it does: Maintain an adaptive, in-model memory of emails, notes, chats, and documents spanning years, reducing or replacing external vector databases.
- Tools/products/workflows: Memory-first personal assistants; unified personal knowledge bases.
- Assumptions/dependencies: Privacy-preserving on-device or encrypted servers; scalable AWM variants; low-latency long-context inference.
- Foundation models that natively scale to million-token multimodal streams
- Sectors: foundation model labs, media platforms
- What it does: Train general-purpose models that ingest video+audio+text with unbounded context for long-form generation and understanding.
- Tools/products/workflows: Long-form video QA/generation; episodic podcast summarization with cross-episode recall.
- Assumptions/dependencies: Token-efficient multimodal representations; extreme-scale training; inference acceleration for long sequences.
- Genomics and proteomics sequence modeling at full-chromosome scale
- Sectors: biotech, pharma, academia
- What it does: Model long-range dependencies across whole-genome sequences; integrate multiple omics tracks.
- Tools/products/workflows: Variant effect prediction with long-range regulatory context; enhancer–promoter interaction modeling.
- Assumptions/dependencies: Domain-specific pretraining; alignment/encoding pipelines; interpretability requirements.
- Climate, weather, and geophysical modeling over long horizons
- Sectors: energy, agriculture, insurance, public sector
- What it does: Capture long-term dependencies in spatiotemporal sequences (observations and reanalyses) for forecasting and narrative synthesis.
- Tools/products/workflows: Hybrid physics-ML forecasters with long-context narrative outputs; extreme-event retrospectives.
- Assumptions/dependencies: Robust spatiotemporal tokenization; coupling with physics constraints; compute scale.
- Real-time streaming copilots with rolling adaptive memory
- Sectors: operations, security, industrial IoT
- What it does: Maintain compact working memory of streams (sensor data, logs, network events) while preserving long-range recall.
- Tools/products/workflows: “Always-on” monitors that summarize and explain state changes across days/weeks.
- Assumptions/dependencies: Tight latency budgets; incremental inference kernels; reliability and drift control.
- Autonomous coding agents operating over entire organizations’ code and knowledge
- Sectors: enterprise software
- What it does: Plan and execute multi-repo changes, referencing historical tickets/wiki pages; keep persistent technical context.
- Tools/products/workflows: Org-scale refactoring agents; knowledge-aware debugging assistants.
- Assumptions/dependencies: Access controls; safety/rollback mechanisms; memory governance.
- End-to-end compliance and audit copilots without heavy external RAG
- Sectors: finance, healthcare, manufacturing
- What it does: Read entire policy sets, SOPs, and logs to generate audit trails and compliance narratives directly from model memory.
- Tools/products/workflows: Automated control-mapping and evidence synthesis across long corpora.
- Assumptions/dependencies: High accuracy and verifiability; rigorous evaluation; cryptographic provenance.
- Long-horizon robotics and planning with intrinsic memory
- Sectors: robotics, autonomous systems
- What it does: Use AWM-like memory for episodic, long-horizon tasks, retaining state over extended sequences.
- Tools/products/workflows: Task planners that recall distant subgoals and constraints; lifelong-learning logs.
- Assumptions/dependencies: Closed-loop training and safety; integration with perception/action stacks.
- ML systems infrastructure for extreme-context training/inference
- Sectors: cloud providers, ML tooling
- What it does: Native support for context parallelism, chunk-level compute, KV-chunk caching, and pipeline overlap for million-token sequences.
- Tools/products/workflows: Optimized compilers/kernels; inference servers with streaming memory adapters; autoscaling policies by sequence length.
- Assumptions/dependencies: Vendor kernel adoption; hardware roadmap (HBM, interconnects); standard APIs.
- Educational “course twin” models with semester-scale memory
- Sectors: EdTech
- What it does: Persistently track student interactions across a semester, customizing explanations with long-span context.
- Tools/products/workflows: Adaptive tutors with long-term personalization; curriculum-spanning feedback.
- Assumptions/dependencies: Privacy-by-design; bias mitigation; alignment for pedagogy.
- Financial market modeling with microstructure-level continuity
- Sectors: finance, fintech
- What it does: Retain fine-grained, long-horizon structure in tick data; support scenario analysis and narrative explanations of market moves.
- Tools/products/workflows: Long-horizon market copilots; compliance explainability for trades.
- Assumptions/dependencies: High-frequency data handling; risk controls; strong domain calibration.
- Knowledge management without brittle chunking heuristics
- Sectors: enterprise collaboration, KM platforms
- What it does: Ingest wikis, tickets, RFCs, and emails end-to-end; answer questions with minimal chunk-engineering and fewer retrieval layers.
- Tools/products/workflows: Org knowledge copilots; policy Q&A over entire knowledge graphs in text form.
- Assumptions/dependencies: Access control and security; model updates to avoid drift; hybrid RAG for extremely large corpora.
Notes on feasibility and dependencies (cross-cutting)
- Compute and latency: Handling hundreds of thousands to millions of tokens is feasible for offline or batch use today but may be too slow/expensive for real-time interactive scenarios; moderate contexts (8k–64k) are more practical immediately.
- Integration effort: Gecko is not a trivial drop-in for all Transformer stacks; adopting SCA/TDN/AWM may require kernel support and re-tuning. The provided codebase reduces lift, but productionization needs engineering.
- Domain adaptation: Many high-stakes sectors (healthcare, finance, law) require fine-tuning and rigorous evaluation to achieve acceptable accuracy and reliability.
- Safety, privacy, and compliance: Long-context ingestion amplifies data-governance needs (PII/PHI, access controls, audit logs).
- Hybrid approaches: Even with strong inherent retrieval, extremely large corpora benefit from complementary retrieval (vector DBs, indexes) for cost, latency, and precision.
Glossary
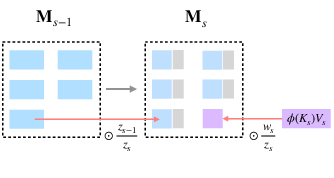
- Adaptive Working Memory (AWM): A fixed-size learned memory that compresses and retains information beyond the local attention window using linear attention with an online softmax, to preserve long-range context. "To capture long-term information that lies outside the sliding chunks, Gecko incorporates an adaptive working memory component, implemented using a linear attention mechanism with a position-aware online softmax activation"
- AdamW: An optimizer that decouples weight decay from the gradient-based update (a variant of Adam) to improve training stability and generalization. "Training is performed using the AdamW optimizer~\citep{loshchilov2019decoupled}"
- CEMA (Complex Multi-dimensional Damped EMA): A complex-valued exponential moving average module that expands features and applies damped EMA to encode temporal dynamics across dimensions. "CEMA first expands each dimension of the input sequence individually into dimensions via an expansion matrix , then applies damped EMA to the -dimensional hidden space."
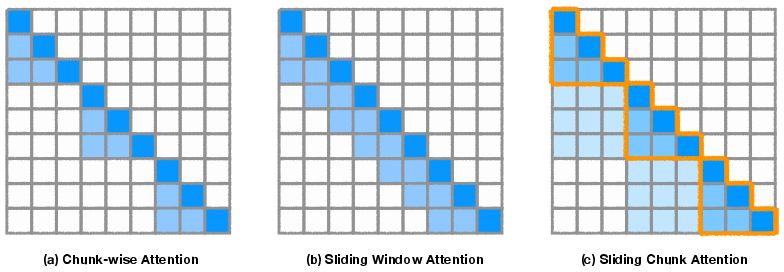
- Chunk-wise Attention: An attention scheme that computes attention within fixed-length chunks independently, reducing complexity but limiting cross-chunk context flow. "losses near the context boundaries of chunk-wise attention (both preceding and following a chunk) increase substantially"
- Compressive Memory: A bounded-capacity state that incrementally accumulates and compresses past information for later retrieval, enabling long-context reasoning. "Technically, the compressive memory in linear attention maintains a bounded-capacity storage."
- Context Parallelism: A distributed training strategy that partitions long contexts across devices while communicating only necessary states (e.g., previous key–value chunks) to scale context length efficiently. "Importantly, sliding chunk attention is well suited for efficient context parallelism in distributed pretraining."
- Delta Rule: An incremental memory update rule that adjusts stored associations based on key–value correlations, enabling continual compression. "compressive memory is updated by applying linear attention with delta rule~\citep{widrow1988adaptive,schlag2021linear}:"
- Exponential Moving Average (EMA): A method that maintains running statistics or signals with exponential decay to emphasize recent information. "with the classical exponential moving average (EMA) approach"
- Gated Attention: An attention mechanism modulated by learned gates that control information flow and improve stability/capacity. "which harnesses the gated attention mechanism~\citep{hua2022transformer,qiu2025gated} with the classical exponential moving average (EMA) approach"
- Gated DeltaNet: A gated variant of delta-based linear attention that uses learnable decay/forget mechanisms to manage memory content. "is reminiscent of the "writing strength" and forget gate in Gated DeltaNet~\citep{gateddeltanet} and Kimi Delta Attention~\citep{team2025kimi}."
- Infini-attention: An attention mechanism that augments local attention with a compressive memory to support effectively unbounded contexts. "With Infini-attention as an example, with linear attention as compressive memory, information that moves beyond attention window is recurrently compressed into a fixed-size state."
- Linear Attention: An attention formulation that replaces softmax with kernel feature maps to achieve linear time and memory complexity. "Recent work, such as Flash~\citep{hua2022transformer} and Infini-attention~\citep{munkhdalai2024leave}, proposed to implement compressive memory as a learnable module with linear attention mechanism~\citep{katharopoulos2020transformers,schlag2020learning}."
- Needle-in-a-Haystack (NIAH): A retrieval benchmark where a small target (“needle”) must be found within a long distractor sequence (“haystack”). "two standard needle-in-a-haystack (NIAH) benchmarks: passkey retrieval and vanilla NIAH~\citep{niah2023,hsieh2024ruler}."
- Position-aware Online Softmax: A normalization kernel that incorporates all past timesteps into the softmax denominator, enabling position-aware compression in linear attention. "Gecko introduces the position-aware online softmax kernel to linear attention."
- Rotary Positional Embeddings (RoPE): A positional encoding that applies complex rotations to queries/keys to model relative positions in attention. "we employ SwiGLU~\citep{shazeer2020glu} in the feed-forward layers and rotary positional embeddings (RoPE; \citealt{su2021roformer})."
- SiLU: The Sigmoid-weighted Linear Unit activation function that can serve as a kernel feature map in linear attention. "Commonly used feature kernels are element-wise nonlinear activation functions, such as SiLU~\citep{ramachandran2017swish}."
- Sliding Chunk Attention (SCA): An attention pattern that attends over the current chunk and the immediately preceding chunk to bridge boundaries efficiently. "we extend sliding window attention by incorporating chunked contexts, yielding the sliding chunk attention (SCA) mechanism."
- Sliding Window Attention (SWA): An attention scheme restricting each token’s context to a fixed-size local window, trading expressivity for efficiency. "a straightforward approach is to replace it with sliding window attention~(SWA)~\citep{beltagy2020longformer}"
- Structured State Space Models (SSMs): Sequence models that parameterize dynamics via state-space recurrences, enabling efficient long-range modeling. "Techniques like sparse attention mechanisms~\citep{tay2020efficient,ma2021luna}, structured state space models~\citep{gu2022efficiently,poli2023hyena,gu2023mamba} and linear Transformers~\citep{katharopoulos2020transformers,mamba2,gateddeltanet} have been introduced"
- SwiGLU: A gated activation/FFN variant combining SiLU and linear gating to improve model capacity and training. "we employ SwiGLU~\citep{shazeer2020glu} in the feed-forward layers"
- Timestep Decay Normalization: An auto-regressive normalization that uses exponential decay for cumulative mean/variance to maintain a fixed influence of recent timesteps. "Similar to Timestep Normalization in Megalodon, we provide hardware-friendly implementation of Timestep Decay Normalization on modern hardware (GPU)."
- Timestep Normalization: An auto-regressive extension of Group Normalization that uses cumulative mean/variance over timesteps for normalization. "Megalodon proposed Timestep Normalization, which extends Group Normalization~\citep{wu2018group} to the auto-regressive case by computing the cumulative mean and variance."
- Transformer-XL: A Transformer variant introducing recurrent segments (memory of past segments) for longer effective context. "Motivated by the recurrent segment mechanism in Transformer-XL~\citep{dai2019transformer} and the block sliding window in LongFormer~\citep{beltagy2020longformer}, we extend sliding window attention by incorporating chunked contexts, yielding the sliding chunk attention (SCA) mechanism."
Collections
Sign up for free to add this paper to one or more collections.