ObjectForesight: Predicting Future 3D Object Trajectories from Human Videos
Abstract: Humans can effortlessly anticipate how objects might move or change through interaction--imagining a cup being lifted, a knife slicing, or a lid being closed. We aim to endow computational systems with a similar ability to predict plausible future object motions directly from passive visual observation. We introduce ObjectForesight, a 3D object-centric dynamics model that predicts future 6-DoF poses and trajectories of rigid objects from short egocentric video sequences. Unlike conventional world or dynamics models that operate in pixel or latent space, ObjectForesight represents the world explicitly in 3D at the object level, enabling geometrically grounded and temporally coherent predictions that capture object affordances and trajectories. To train such a model at scale, we leverage recent advances in segmentation, mesh reconstruction, and 3D pose estimation to curate a dataset of 2 million plus short clips with pseudo-ground-truth 3D object trajectories. Through extensive experiments, we show that ObjectForesight achieves significant gains in accuracy, geometric consistency, and generalization to unseen objects and scenes, establishing a scalable framework for learning physically grounded, object-centric dynamics models directly from observation. objectforesight.github.io


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces ObjectForesight, a computer system that watches short videos recorded from a person’s point of view and predicts how a specific object will move in 3D over the next few seconds. Think of seeing someone reach for a mug: even before it happens, you can guess the mug might be lifted, slid, or turned. ObjectForesight tries to give computers that same “common sense” about future object motion.
Objectives
The paper focuses on three simple goals:
- Teach computers to predict an object’s future movement in 3D from short, everyday videos.
- Make these predictions at the object level (not just pixels), including both where the object goes and how it rotates. This is called “6-DoF,” or six degrees of freedom: moving forward/back, left/right, up/down, and rotating around three axes.
- Build a huge training dataset—over 2 million short examples—of objects being manipulated, so the model can learn from many real-life situations.
How It Works (Methods, in everyday language)
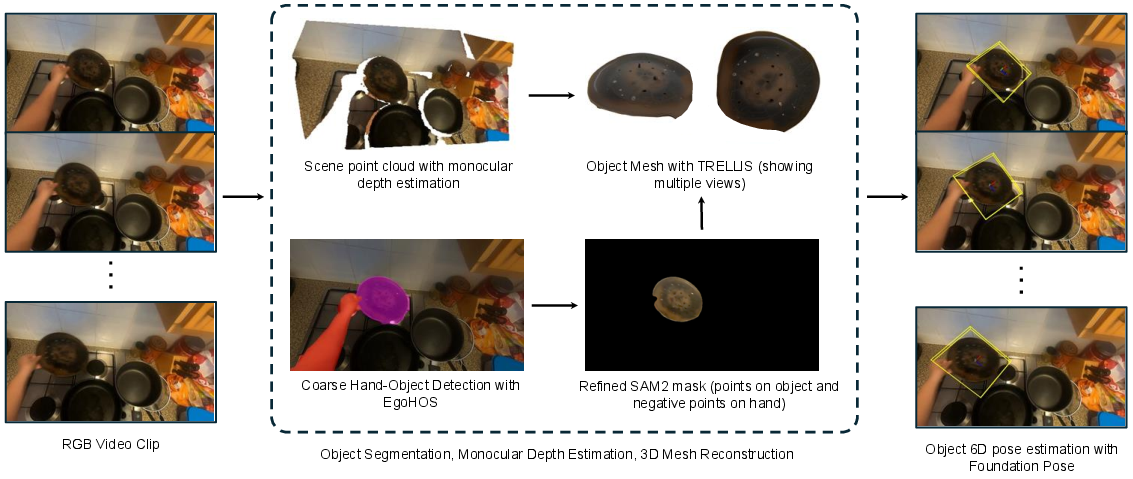
First, the team had to build data the model could learn from. They used videos where people do daily tasks (like cooking) and turned them into 3D motion examples:
- Find the hands and the object: The system automatically detects hands and the object being touched, then cleans up the object’s outline (its “mask”) across frames so it’s consistent.
- Recover the object’s 3D shape and position: It estimates the object’s 3D shape (like a rough mesh) and figures out where it is in 3D, including how it’s turned.
- Separate camera movement from object movement: Since the camera is on a person’s head or chest, it moves too. The system re-expresses everything in a stable “anchor frame” so the model focuses on the object’s true motion, not the person’s camera wobble.
- Slice into short clips: From longer videos, it extracts short windows with a few past frames and the next few frames of object motion to learn from.
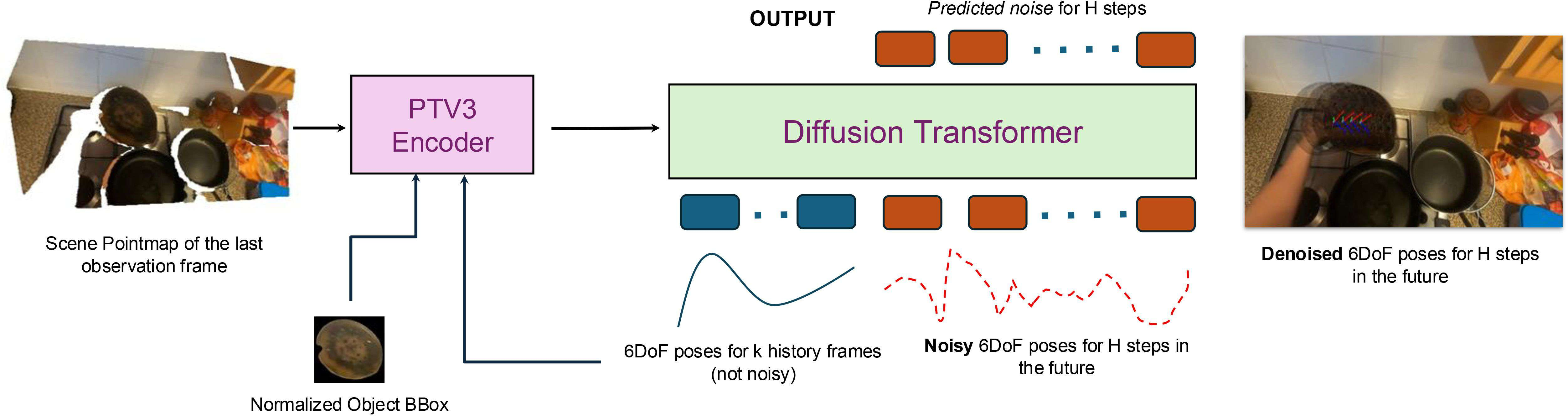
Then they train ObjectForesight, which has two main parts:
- A 3D scene encoder: It uses the depth map (which tells how far things are) to build a 3D point cloud—like a cloud of dots representing the scene—and focuses on the area around the object. This helps the model understand nearby surfaces and obstacles that affect motion.
- A diffusion transformer (DiT): Imagine starting with a fuzzy guess of the future and sharpening it step-by-step. That’s diffusion. The transformer guides this process so the final predictions are smooth, realistic paths of the object’s movement and rotation over time.
In simple terms: the model watches a few frames, thinks about the 3D layout and the object’s recent motion, and then “imagines” several likely future paths, becoming more confident with each step.
Main Findings
The authors tested ObjectForesight in everyday scenes and found:
- It predicts future object motion more accurately and more smoothly than a standard “autoregressive” model (a common way to predict step-by-step).
- Compared to a fancy video generator (which creates future frames), ObjectForesight’s explicit 3D predictions are more stable and physically sensible. Predicting motion directly in 3D works better than generating pixels and figuring out motion afterward.
- It generalizes well: it works on new scenes and objects it hasn’t seen before, thanks to focusing on 3D object poses, not just image patterns.
Why this matters:
- The system captures realistic actions like lifting, rotating, sliding, and placing objects, and keeps them consistent over several future steps.
- It uses “object-centric” reasoning—focusing on the object’s 3D pose—so predictions are grounded in geometry, not just guesswork on images.
Implications and Impact
ObjectForesight moves us closer to computers and robots that understand and plan in the physical world. Possible impacts include:
- Helping robots plan safe, smart actions by predicting what objects will do next when a human interacts with them.
- Improving augmented reality (AR) and virtual assistants that anticipate how you’ll move objects and assist you in real time.
- Building better “world models” for AI—systems that don’t just see but also understand how things change.
The paper also points to future directions, like handling flexible or articulated objects (think foldable lids or bendy tools) and predicting longer time horizons. Overall, ObjectForesight shows that learning from millions of real human videos, combined with explicit 3D understanding, is a powerful way to teach AI how the physical world behaves.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of unresolved issues that future researchers can act on:
- Data supervision fidelity: Quantify the accuracy of the pseudo-ground-truth 6-DoF trajectories produced by TRELLIS, SpaTrackerV2, FoundationPose, and the masking pipeline (SAM2, Diffusion-VAS), via a held-out validation set with motion-capture or fiducial-marker ground truth; report per-trajectory confidence scores and propagate uncertainty into training and evaluation.
- Sensitivity to pipeline failures: Systematically study and report robustness to segmentation errors, occlusions, monocular depth errors, and pose-tracker drift (including re-registration events); provide failure-mode analyses and mitigation strategies.
- Metric scale estimation: Validate the heuristic scale estimation and depth–silhouette alignment at scale; measure cross-scene scale consistency and bias, and quantify its impact on forecasting accuracy.
- Ego-motion disentanglement robustness: Evaluate how anchor-frame canonicalization behaves under large, non-smooth ego motion or camera jitter; quantify the effect of camera-geometry errors on pose normalization and predictions.
- Occlusion and visibility bias: The VLM-based view-quality gating likely biases the dataset toward easy, clearly visible manipulations; measure performance in heavy occlusions/blur and explore training with amodal visibility priors to reduce selection bias.
- Multi-object interactions: Extend beyond single manipulated objects per clip to handle multiple simultaneously moving objects and inter-object constraints; develop tracking and prediction for multi-object SE(3) trajectories.
- Explicit contact reasoning: Incorporate hand–object contact state, contact points, and support surfaces into the model; measure whether explicit contact cues improve trajectory plausibility and reduce ambiguity.
- Physics constraints and compliance: Add collision checking with scene geometry, gravity and support-plane constraints, and frictional limits; report violation rates (e.g., interpenetrations, floating objects) and evaluate physics-consistent forecasting.
- Articulated/deformable objects: Generalize beyond rigid SE(3) to articulated kinematic chains and deformable models (e.g., learned deformation fields, neural implicit surfaces); curate or annotate datasets with these object types.
- Long-horizon forecasting: Study performance beyond H=8 steps (and at higher frame rates), measuring drift, stability, and error growth; explore hierarchical or coarse-to-fine prediction strategies for extended horizons.
- Distributional evaluation: Move beyond single-trajectory ADE/FDE to assess multimodality (coverage of plausible futures), calibration (likelihood/NLL or CRPS-style metrics), and diversity–accuracy trade-offs; define standardized evaluation protocols for stochastic trajectory predictors.
- Uncertainty quantification: Provide calibrated uncertainty over SE(3) predictions (e.g., covariance over translation/rotation), and evaluate how uncertainty guides downstream decision-making or risk-aware planning.
- Downstream robotics integration: Demonstrate closed-loop manipulation where predicted object trajectories inform grasping, placement, or tool-use; report task success rates and failure cases in real robot experiments.
- Cross-domain generalization: Evaluate on non-kitchen and non-egocentric datasets (e.g., workshops, outdoor scenes, exocentric camera views) to quantify domain shift and the need for adaptation or domain-robust training.
- Baseline breadth: Compare against physics-informed predictors, 3D scene-flow/NeRF-based motion models, and established robotics trajectory forecasters; include stronger video generative baselines (beyond Ray3) and report consistent scale across baselines.
- Architectural ablations: Quantify contributions of the geometry encoder (PointTransformerV3), bounding-box conditioning, AdaLN-Zero, SE(3) auxiliary and smoothness losses, depth normalization (u,v,log z), and context length C; report thorough ablations (some were only briefly noted).
- Ground-truth calibration subset: Build and release a small benchmark of clips with verified 6-DoF ground truth to calibrate the curation pipeline and enable absolute accuracy comparisons across methods.
- Camera calibration diversity: Test robustness to varied intrinsics/extrinsics (e.g., fisheye lenses, different mounts), and quantify how calibration errors propagate to forecasting.
- Inference efficiency: Report runtime/latency with S=50 DDIM steps, memory footprint, and trade-offs for fewer sampling steps; investigate fast samplers or distillation for real-time deployment.
- Extreme dynamics: Evaluate on high-speed manipulations (throws, rapid rotations) and rare events; analyze whether the model extrapolates or fails under large accelerations.
- Monocular depth limitations: Measure the impact of depth noise on forecasting; explore multi-view or stereo depth where available, and compare performance with improved geometry.
- Mesh utilization: The reconstructed object mesh is not used during training—test conditioning on object shape (instance-level or category-level) and analyze whether mesh-based priors improve trajectory prediction.
- Semantic/intention conditioning: Integrate language, object category, or human-intent cues (e.g., hand trajectory predictors) to reduce ambiguity; quantify gains and failure cases.
- Coordinate-frame choices: Compare anchor-frame canonicalization to world-frame or object-frame formulations; study the impact on robustness, generalization, and downstream use.
- Failure taxonomy: Provide a comprehensive catalog of typical errors (e.g., rotation flips, depth collapse, collision violations) with quantitative prevalence and targeted remedies.
- Evaluation metrics for physical plausibility: Add metrics for collision rate with scene geometry, support-plane compliance (e.g., object not penetrating/levitating relative to surfaces), and contact timing accuracy; standardize reporting.
- Robustness to degradation: Test performance under low-light, blur, and compression artifacts (outside VLM-gated “clean views”), and develop training strategies that improve resilience.
- Data splits and leakage: Ensure splits prevent instance-level leakage (same object across splits) and report category-level generalization; clarify how train/test independence is maintained.
- Moving environment elements: Address cases where supports or background surfaces move (conveyor belts, doors), requiring scene-motion modeling beyond object-centric SE(3).
- Joint modeling with hands: Explore coupling ObjectForesight with hand trajectory prediction models to disambiguate multi-modal futures and improve contact-aware forecasting.
Practical Applications
Immediate Applications
The following applications can be deployed now with reasonable integration effort, primarily for offline prediction, analytics, and perception modules where short-horizon, rigid-object motion forecasting is sufficient.
- Robot manipulation forecasting module
- Description: Use ObjectForesight as a perception add-on that predicts near-future 6-DoF object poses from onboard cameras to improve grasp timing, pre-grasp path planning, and collision avoidance.
- Sectors: robotics, manufacturing, warehousing.
- Tools/products/workflows: ROS/ROS2 node wrapping ObjectForesight; integration with MoveIt for trajectory planning; safety “trajectory cone” overlays that warn if predicted motion intersects restricted zones.
- Assumptions/dependencies: Primarily rigid objects; short-horizons (~1–2 seconds); monocular depth and camera geometry availability or good estimation; inference may be offline or batched unless DiT sampling is optimized for real-time.
- Learning priors for manipulation from human videos
- Description: Leverage the 2M+ pseudo-ground-truth 3D trajectories and object-centric SE(3) forecasts as training data or priors for robot policies (e.g., imitation learning, model-based RL).
- Sectors: robotics research, software, education.
- Tools/products/workflows: Dataset-driven pretraining pipelines; world-model modules that provide object-motion priors to downstream policies; benchmarking suites using ADE/FDE/rotation metrics.
- Assumptions/dependencies: Kitchen-centric dataset bias; priors reflect human manipulation styles; transfer requires domain adaptation to robot embodiment and task constraints.
- Predictive safety analytics in kitchens and light manufacturing
- Description: Forecast risky object motions (knives, hot containers, heavy tools) from CCTV or wearable cameras to trigger early warnings or log near-miss events.
- Sectors: industrial safety, retail food prep, facilities management.
- Tools/products/workflows: “Predictive Compliance Monitor” that flags unsafe motion trajectories; dashboards with trend analytics (error slopes, motion categories).
- Assumptions/dependencies: Adequate object visibility; reliable segmentation of hands/objects; policies for false positives and alert fatigue; privacy-compliant video use.
- AR/VR predictive overlays for task assistance
- Description: Overlay plausible object motion (e.g., lid closing, cup lifting) in AR to guide users during assembly, cooking, or training, compensating for occlusions or display latency.
- Sectors: education, consumer software, enterprise training.
- Tools/products/workflows: Mobile AR (ARKit/ARCore) plugins that render predicted 6-DoF object futures; “ghost trajectory” visual aids in training apps.
- Assumptions/dependencies: Accurate monocular depth or AR framework-provided depth; rigid-object assumption; short-horizon hints; careful UX to avoid overtrust.
- Video post-production and 3D overlay stabilization
- Description: Improve alignment and temporal stability of 3D graphics or annotations that track moving products or tools in recorded content.
- Sectors: media, e-commerce visualization, technical documentation.
- Tools/products/workflows: NLE (non-linear editor) plugins that ingest frames and output predicted SE(3) tracks to stabilize overlays.
- Assumptions/dependencies: Sufficient object visibility and scene geometry; offline processing acceptable.
- Academic benchmarking for object-centric world models
- Description: Use ObjectForesight and the curated dataset to study physically grounded forecasting in SE(3), compare diffusion vs. autoregressive approaches, and evaluate generalization.
- Sectors: academia.
- Tools/products/workflows: Public datasets, code, and metrics (ADE/FDE/ARE/FRE/RES/DES) for standardized evaluation; coursework modules on 3D dynamics modeling.
- Assumptions/dependencies: Dataset and code accessibility; reproducible pipelines (segmentation, depth, pose).
- Surgical training (offline) for rigid tool trajectory analysis
- Description: Forecast near-future 6-DoF motions of laparoscopic or endoscopic instruments to provide trainees with predictive feedback and motion quality metrics.
- Sectors: healthcare education.
- Tools/products/workflows: Simulation analysis tools that process surgical videos and output trajectory forecasts; training feedback dashboards.
- Assumptions/dependencies: Domain shift from kitchen scenes; rigid-tool suitability; reliable instrument segmentation; offline analytics acceptable.
- Retail and shelf interaction analytics
- Description: Anticipate object motions during stocking or customer interactions to detect potential product drops, misplacement, or unsafe handling.
- Sectors: retail operations, loss prevention.
- Tools/products/workflows: Store-camera analytics that log predicted object movement events and near-misses; staff training reports.
- Assumptions/dependencies: Camera placement enabling clear views; robust segmentation; privacy-compliant usage.
- In-cabin monitoring for consumer/industrial vehicles
- Description: Predict motion of handheld tools or objects inside cabins (e.g., forklifts, service vans) to warn of imminent hazards.
- Sectors: transportation safety, logistics.
- Tools/products/workflows: Edge-camera modules with short-horizon forecasting; event-triggered alerts.
- Assumptions/dependencies: Adequate visibility and depth estimation; rigid-object focus; policy for alerts and liability.
Long-Term Applications
These applications require further research, scaling, domain adaptation, real-time optimization, or modeling extensions (articulated/deformable objects, multi-object reasoning).
- Closed-loop robot co-working with anticipatory control
- Description: Real-time integration of ObjectForesight-like models into robot stacks to anticipate human-induced object motion and adjust plans dynamically for safety and efficiency.
- Sectors: manufacturing, warehousing, assistive robotics.
- Tools/products/workflows: Low-latency DiT variants; multi-sensor fusion (RGB-D, IMU); shared autonomy planners that ingest predicted motion distributions.
- Assumptions/dependencies: Real-time inference (reduce DDIM steps, distill models); robust perception under occlusion; certification for safety-critical deployments.
- Surgical assistance and autonomy
- Description: Predict multi-instrument motions and provide intelligent assistance (e.g., camera reorientation, collision avoidance) during procedures.
- Sectors: healthcare, surgical robotics.
- Tools/products/workflows: Domain-adapted models trained on surgical video corpora; integration with tracking systems and haptics; regulatory-grade validation.
- Assumptions/dependencies: High-precision geometry; rigid/articulated tool modeling; compliance with medical device regulations.
- Household assistive robots handling articulated and deformable objects
- Description: Extend from rigid SE(3) to articulated (hinged lids, drawers) and deformable objects (cloth, bags), enabling general household tasks (folding, packing, tidying).
- Sectors: home robotics, eldercare.
- Tools/products/workflows: Kinematic and learned deformation models; multi-object interaction forecasting; policy learning with object-centric world models.
- Assumptions/dependencies: New datasets for articulated/deformable categories; better depth/geometry estimation; interaction physics modeling.
- Predictive AR glasses for hazards and guidance
- Description: Real-time overlays in wearable AR to warn about unsafe motions and guide tool placement in complex tasks (field service, labs).
- Sectors: enterprise field service, education, labs.
- Tools/products/workflows: On-device optimized forecasting; task-aware UI; integration with AR platforms; multimodal inputs (voice, gaze).
- Assumptions/dependencies: Compute and battery constraints; low-latency pipelines; robust tracking in unconstrained environments.
- General-purpose object-centric world models for embodied AI
- Description: Use large-scale object motion forecasting as a core world-model primitive for planning, exploration, and skill learning across domains.
- Sectors: robotics, software platforms, research.
- Tools/products/workflows: Hierarchical planners that sample future motion distributions; differentiable physics layers; multi-object, multi-agent extensions.
- Assumptions/dependencies: Scalable training across diverse datasets; handling long horizons; uncertainty quantification and risk-aware planning.
- Insurance and occupational safety analytics
- Description: Predictive assessment of risky object motions from workplace videos for proactive risk mitigation and claim analysis.
- Sectors: finance (insurance), policy, occupational safety.
- Tools/products/workflows: Risk scoring engines; incident simulation using predicted trajectories; compliance auditing tools.
- Assumptions/dependencies: Governance and consent; domain-specific model calibration; fairness and bias audits.
- Education: interactive physics and affordance learning
- Description: Classroom tools that visualize predicted object motions to teach mechanics, affordances, and interaction dynamics.
- Sectors: education.
- Tools/products/workflows: Interactive apps that render predicted 6-DoF futures; labs comparing model forecasts with real outcomes.
- Assumptions/dependencies: Simplified scenarios; explainable visualizations; alignment with curricula.
- Policy and standards for video-based predictive analytics
- Description: Develop guidelines for privacy, consent, data curation, and trustworthy deployment of models trained on human videos.
- Sectors: policy, legal, compliance.
- Tools/products/workflows: Standardized documentation of pipelines (segmentation, depth, pose); risk registers; opt-in consent frameworks; dataset cards and model cards.
- Assumptions/dependencies: Multi-stakeholder input; harmonization with regional regulations; mechanisms to mitigate misuse.
- Deployed multi-object forecasting in complex scenes
- Description: Predict coupled motions (e.g., tool-object-surface) and long-horizon outcomes to support advanced assembly lines and autonomous labs.
- Sectors: advanced manufacturing, R&D automation.
- Tools/products/workflows: Multi-object DiTs; scene graphs with SE(3) dynamics; planners that reason over interacting trajectories.
- Assumptions/dependencies: Rich annotations and sensors; improved occlusion handling; physically grounded multi-object constraints.
Notes on Feasibility and Dependencies
- Rigid-object and short-horizon focus: Current model targets rigid objects and near-future (e.g., 8 steps). Extensions are required for articulated/deformable items and longer horizons.
- Geometry estimation: Quality depends on monocular depth and camera motion estimation; RGB-D or multi-view sensors improve reliability.
- Compute and latency: DiT sampling (e.g., 50 DDIM steps) may be heavy; distillation or fewer steps are needed for real-time use.
- Dataset bias: EPIC-Kitchens focus introduces domain biases (indoor, kitchen); domain adaptation is necessary for other sectors (surgery, factory floors).
- Privacy and governance: Using human videos requires consent, secure storage, and adherence to local regulations and organizational policies.
- Robustness: Occlusion, blur, and segmentation errors affect forecasts; production systems need confidence gating, fallback behaviors, and human-in-the-loop review.
Glossary
- 6-DoF: Six degrees of freedom describing 3D translation and rotation of a rigid body. "predicts future 6-DoF poses and trajectories of rigid objects from short egocentric video sequences."
- ADE: Average Displacement Error; mean Euclidean translation error across all forecast timesteps. "We report ADE (mean Euclidean error across all timesteps)..."
- AdaLN-Zero: A conditioning technique that injects context into transformer layers via adaptive LayerNorm with zero-initialized gates. "A diffusion transformer (DiT, AdaLN-Zero) then denoises future depth-normalized pose tokens..."
- Amodal object masks: Segmentation masks that include both visible and occluded parts of an object. "We use Diffusion-VAS to complete amodal object masks."
- Anchor-frame camera coordinates: The coordinate frame of the first (anchor) frame used to express poses and remove camera motion effects. "All frames in the window are expressed in the anchor-frame camera coordinates..."
- Anchor-query attention: An attention mechanism where the anchor token queries conditioning tokens to summarize motion context. "we summarize motion context with anchor-query attention..."
- Anchor-relative time embedding: A learned representation encoding timestep offsets relative to the anchor frame. "a signed anchor-relative time embedding."
- ARE: Average Rotation Error; mean rotational error across timesteps, typically measured on SO(3). "ARE (average rotation error)..."
- Autoregressive transformer: A model that predicts future tokens sequentially conditioned on previously generated tokens. "than an autoregressive transformer baseline trained on the same object-centric representation."
- Cosine noise schedule: A diffusion training schedule where per-timestep noise magnitudes follow a cosine function. "uses a cosine noise schedule with v-parameterized denoising."
- DDIM sampling: Deterministic Denoising Diffusion Implicit Models; a fast, non-stochastic diffusion sampler. "At inference, DDIM sampling produces smooth, diverse, and physically coherent 3D trajectories."
- Depth-floor penalty: A regularization term discouraging predictions with unrealistically small depths. "A small depth-floor penalty is also applied to discourage degenerate solutions with extremely small depth:"
- Depth-normalized pose space: A reparameterization of translation by image-plane coordinates and log-depth to stabilize learning. "The model operates in a depth-normalized pose space for stability..."
- DES: Distance Error Slope; the rate of change of Euclidean translation error over time. "DES (slope of the per-timestep Euclidean distance error)..."
- Diffusion Transformer (DiT): A transformer architecture trained via denoising diffusion to model distributions over sequences. "ObjectForesight integrates a Diffusion Transformer (DiT) with a geometry-aware 3D point encoder..."
- Ego-motion: Motion of the camera/observer, distinct from object motion. "we effectively disentangle ego-motion from object motion."
- Egocentric human videos: First-person viewpoint videos capturing human interactions. "predict future 6-DoF trajectories of rigid objects from egocentric human videos."
- FiLM: Feature-wise Linear Modulation; conditioning that scales and shifts feature channels using context. "feature-wise linear modulation (FiLM)."
- FoundationPose: A model for initializing and tracking 6-DoF object poses across frames. "Pose initialization and tracking use FoundationPose..."
- FRE: Final Rotation Error; rotational error at the last forecast timestep. "FRE (final rotation error)..."
- Geodesic angle (SO(3)): The shortest angular distance between two rotations on the rotation manifold. "rotation error via the SO(3) geodesic angle..."
- Horizon-aware weighting: Loss weighting that increases toward later steps in the forecast horizon. "horizon-aware weighting that linearly increases toward later forecast steps..."
- IoU: Intersection over Union; overlap metric between predicted and ground-truth masks or projections. "We choose the best by FoundationPose score, with an IoU-based override."
- Metric depth: Depth values in absolute physical units (e.g., meters) rather than relative scale. "SpaTrackerV2 provides metric depth and camera geometry."
- Monocular depth: Depth estimated from a single camera stream without stereo or multi-view input. "estimate camera motion and monocular depth using SpaTrackerv2."
- Object affordances: Action possibilities that objects provide based on their geometry and semantics. "capturing the underlying semantics of object affordances."
- PointTransformerV3: A transformer-based encoder specialized for point cloud features and geometry. "PointTransformerV3."
- Pose token: A vectorized representation of pose (translation and rotation) treated as a token for sequence modeling. "each pose token..."
- Pseudo-ground-truth: Automatically generated supervisory signals approximating human-annotated ground truth. "pseudo-ground-truth 3D object trajectories."
- Re-registration: Re-initializing pose alignment during tracking when alignment quality drops. "explicit re-registration events."
- RES: Rotation Error Slope; the rate of change of rotational error over time. "RES (slope of the per-timestep rotation error)."
- SE(3): The special Euclidean group of 3D rigid transformations (rotations and translations). "operates in SE(3) space."
- SE(3) velocity and acceleration losses: Regularizers on first and second differences of poses in SE(3) to encourage smooth dynamics. "We regularize dynamics with SE(3) velocity and acceleration losses..."
- Silhouette consistency: Alignment of a projected 3D mesh’s 2D silhouette with segmentation masks for pose refinement. "refine each using depth alignment and silhouette consistency."
- SNR-weighted regression: Loss weighting by signal-to-noise ratio across diffusion timesteps to stabilize training. "SNR-weighted regression loss (p2 reweighting)..."
- SO(3): The special orthogonal group of 3D rotations. "SO(3) geodesic angle..."
- Temporal consensus prompts: Prompts formed from the intersection of masks across a temporal window to stabilize segmentation. "we form temporal consensus prompts..."
- Token-type embedding: An embedding indicating token roles (e.g., context vs. future) within a transformer sequence. "a token-type embedding (context vs.\ future)..."
- VLM-based filter: A filtering stage using a Vision-LLM to validate manipulation and view quality. "We apply a two-stage VLM-based filter using InternVL3."
- v-parameterization: A diffusion training target predicting v (a linear combination of clean data and noise) instead of noise. "we adopt v-parameterization, which stabilizes training across timesteps."
Collections
Sign up for free to add this paper to one or more collections.