- The paper introduces TrackingWorld, a framework that robustly tracks nearly all pixels in monocular videos by disentangling camera and dynamic object motions.
- It employs a hybrid architecture combining dense 2D tracking, iterative upsampling, and world-centric lifting through bundle adjustment with as-static-as-possible constraints.
- Experiments demonstrate superior camera pose, depth estimation, and occlusion-aware tracking performance compared to SLAM baselines and recent 3D tracking methods.
TrackingWorld: World-centric Monocular 3D Tracking of Almost All Pixels
Introduction and Motivation
The challenge of disentangling camera motion from dynamic object motion in monocular 3D tracking remains a persistent barrier for dense visual reconstruction and temporally consistent downstream video applications. Current state-of-the-art monocular 3D tracking methods are fundamentally constrained: they typically model 3D flow within the egocentric camera coordinate frame, are limited to sparse points, and cannot robustly handle newly emerging dynamic subjects or achieve world-centric disentanglement. The "TrackingWorld" framework (2512.08358) squarely targets these limitations, proposing a system that performs dense 3D tracking of nearly all pixels across all frames from monocular video, within a world-centric reference frame, separating static and dynamic motions at scale.

Figure 1: TrackingWorld estimates accurate, world-centric dense 3D trajectories for both static backgrounds and multiple dynamic objects by disentangling camera and object motions from monocular video.
Methodology Overview
TrackingWorld adopts a hybrid framework, leveraging both foundation model priors and custom optimization. The method is partitioned into two primary stages: (1) dense 2D tracking and upsampling, and (2) lifting tracked trajectories into world-centric 3D via explicit camera pose estimation and bundle adjustment with as-static-as-possible constraints.
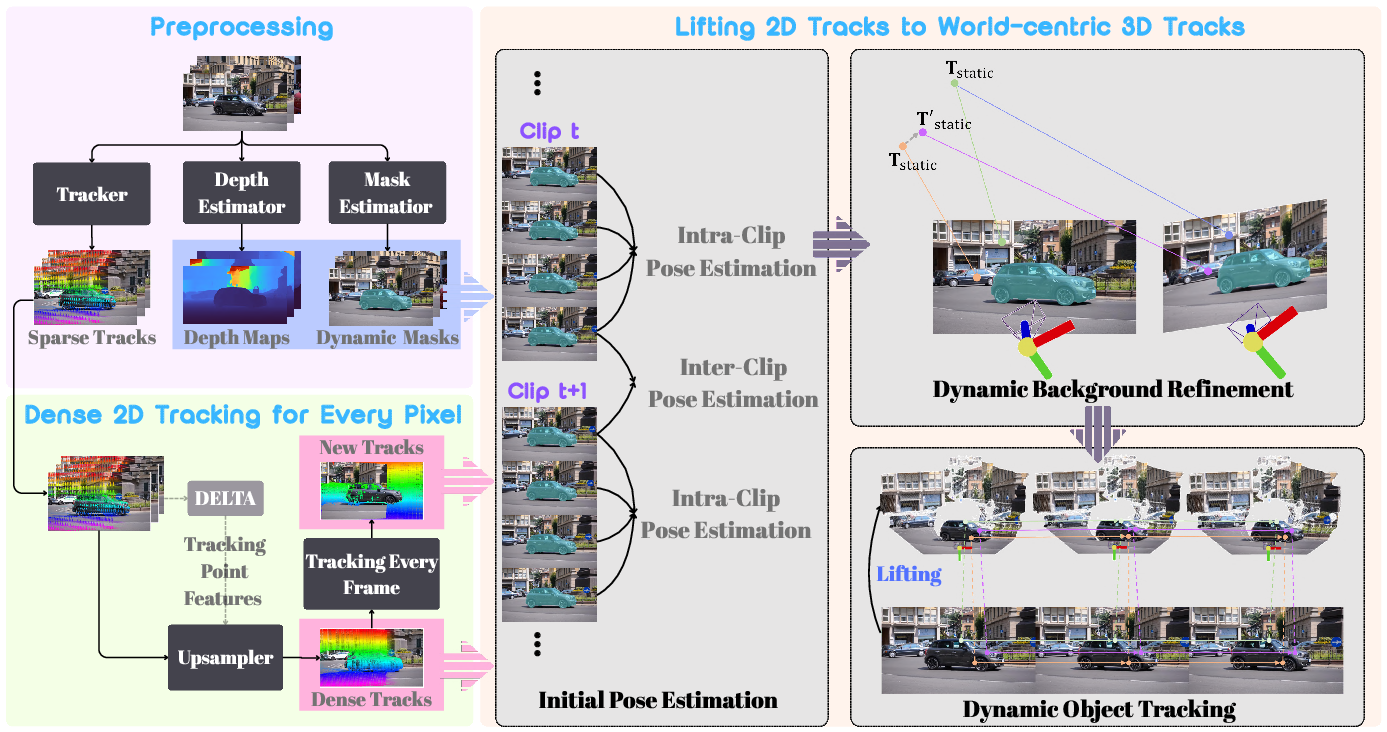
Figure 2: The pipeline takes a monocular video, applies foundation models for 2D tracking, segmentation, and depth estimation, iteratively upsamples 2D tracks per frame, and reconstructs world-centric 3D trajectories using optimization that jointly estimates camera pose and per-point 3D tracks.
Dense 2D Tracking and Upsampling
Given initial sparse 2D tracks (e.g., from CoTrackerV3 or DELTA), depths, and dynamic masks for each frame, the system applies an upsampler module adapted from DELTA, mapping arbitrary sparse tracks to dense trajectories. Crucially, upsampling is performed on all frames, not solely the initial frame, thus capturing new object emergence throughout the sequence. Tracker redundancy is controlled via an overlap-based filtering mechanism, maintaining computational efficiency without loss of coverage.
World-centric Lifting and Camera Pose Estimation
The key technical insight is the explicit bundle adjustment leveraging both a coarse segmentation of dynamic regions and an as-static-as-possible regularization. Initial camera pose is estimated using tracks in regions labeled as static, then further refined by allowing small motion offsets for points in these regions. This joint optimization (camera pose, static point positions, dynamic offsets) robustly separates genuinely static backgrounds from dynamic foreground/background failures in segmentation. Subsequently, dynamic tracks (including background objects not segmented as static) are reconstructed in 3D via back-projection using the refined poses and per-frame depths. Multiple geometric and smoothness losses are employed, including projection loss, depth consistency, as-rigid-as-possible, and temporal smoothness constraints.

Figure 4: Qualitative results on the DAVIS dataset. TrackingWorld outputs reliable camera trajectories (top rows) and dense world-centric tracking for both static background and multiple dynamic objects (bottom rows).
Experimental Results and Analysis
Camera Pose and Depth Estimation
TrackingWorld demonstrates superior camera pose estimation accuracy versus SLAM baselines (DROID-SLAM, DPVO, COLMAP) and recent world-centric 3D trackers (MonST3R, Align3R, Uni4D) across dynamic datasets (Sintel, Bonn, TUM-D)—with substantial improvements in ATE, RTE, and RRE metrics. For example, on Sintel, TrackingWorld with DELTA achieves ATE 0.088, outperforming MonST3R and prior feedforward or optimization methods.
Improvements in 3D depth accuracy are equally significant: absolute relative error (Abs Rel) and correct depth fraction (δ<1.25) exhibit large gains due to the bundle adjustment framework, regardless of the foundation depth model backbone—demonstrating robustness to the monocular prior source.
Sparse and Dense Tracking Evaluation
The method sets new benchmarks in both sparse and dense 3D tracking regimes. It yields higher AJ and APD3D for moving camera datasets (ADT), indicating superior occlusion-aware correspondence and geometric consistency. For dense 2D tracking, the upsampler module allows scalable, accurate long-range optical flow, achieving EPE and IoU metrics on par or exceeding feedforward trackers.
Ablation studies systematically highlight the necessity of every module: both tracking every frame and the as-static-as-possible term are critical for disentangling static and dynamic motions, eliminating background drift, and stabilizing pose estimation.

Figure 3: The static point downsampling/upsampling strategy speeds up the dense optimization with negligible loss in geometric precision, reducing runtime by more than 7×.
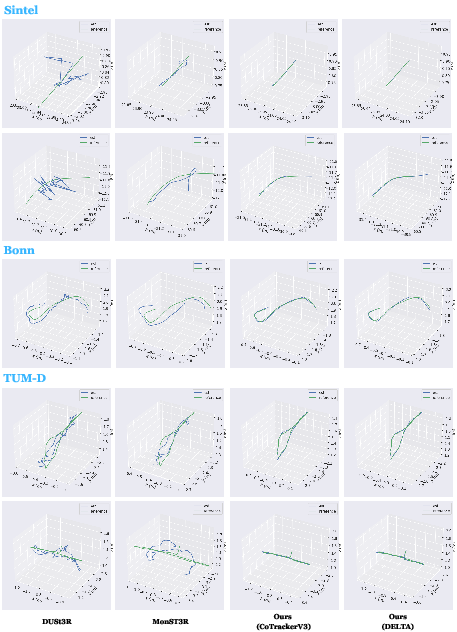
Figure 7: Camera pose estimation curves versus DUSt3R and MonST3R on Sintel, Bonn, TUM-D. TrackingWorld achieves superior alignment and temporal stability.
Qualitative Analyses
Qualitative results illustrate stable, temporally consistent world-centric 3D tracks, including background and multiple dynamic objects. In contrast to prior art, the system robustly tracks points appearing in intermediate frames and dynamically emerging objects, as evidenced in visualizations on datasets such as DAVIS.

Figure 5: Additional visualization of world-centric dense 3D point trajectories across multiple temporally spaced keyframes.
Implications and Future Directions
Tracing the motion of nearly all pixels across frames via a fully disentangled, world-centric model establishes a new baseline for video understanding tasks where explicit separation of camera and object dynamics is required, e.g., video editing, motion analysis, or neural scene and object rendering. Furthermore, the scalability of the upsampler and the modularization around foundation priors (2D tracks, segmentation, depth) make TrackingWorld robust to foundational model quality and future advances therein.
From a theoretical perspective, explicit joint optimization over pose, segmentation, and point-wise dynamics enables holistic scene understanding and provides a path toward more generalizable, feedforward architectures. The methodology further suggests opportunities to integrate richer priors (e.g., video diffusion, language) and to directly align with downstream neural rendering or visual synthesis objectives. Future work may address end-to-end architectures reducing dependency on externally computed foundation priors and extend to real-world video production pipelines.
Conclusion
TrackingWorld (2512.08358) introduces an effective pipeline for world-centric, dense monocular 3D tracking, disentangling camera and multi-object motion for nearly all pixels in arbitrary videos. Through iterative dense 2D tracking, robust redundancy control, and a principled bundle-adjustment regime leveraging as-static-as-possible constraints, it achieves state-of-the-art accuracy in pose and geometric tracking across both public synthetic and real datasets. The approach advances scalable, accurate 3D understanding for dynamic scene analysis and is well-positioned for integration and expansion in future, globally coherent video representation systems.

