Choreographing a World of Dynamic Objects
Abstract: Dynamic objects in our physical 4D (3D + time) world are constantly evolving, deforming, and interacting with other objects, leading to diverse 4D scene dynamics. In this paper, we present a universal generative pipeline, CHORD, for CHOReographing Dynamic objects and scenes and synthesizing this type of phenomena. Traditional rule-based graphics pipelines to create these dynamics are based on category-specific heuristics, yet are labor-intensive and not scalable. Recent learning-based methods typically demand large-scale datasets, which may not cover all object categories in interest. Our approach instead inherits the universality from the video generative models by proposing a distillation-based pipeline to extract the rich Lagrangian motion information hidden in the Eulerian representations of 2D videos. Our method is universal, versatile, and category-agnostic. We demonstrate its effectiveness by conducting experiments to generate a diverse range of multi-body 4D dynamics, show its advantage compared to existing methods, and demonstrate its applicability in generating robotics manipulation policies. Project page: https://yanzhelyu.github.io/chord


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Choreographing a World of Dynamic Objects — Explained Simply
Overview
This paper introduces Chord, a new system that can take still 3D models of a scene and “bring them to life” by making objects move, change shape, and interact over time. Think of it like a smart choreographer that plans and animates the motion of multiple objects in a believable way, using guidance from powerful video-generating AI models.
Goals and Questions
The researchers aimed to solve three main problems:
- How can we animate many different kinds of 3D objects—without writing special rules for each category (like humans, animals, or machines)?
- How can we make different objects move together realistically, especially when they interact (like pushing, pulling, or colliding)?
- How can we do this using what video AI models already know about how things move in the real world—without needing huge specialized 4D datasets?
How It Works (In Everyday Terms)
The system follows a “choreographer and puppets” idea:
- The video AI model acts like a choreographer: it knows what realistic motion looks like because it’s trained on tons of videos.
- The 3D objects are the puppets: the system controls their motion using simple handles and rules.
Here are the key pieces, with simple analogies:
- Using video models for motion guidance:
- The system shows the video AI short clips of what the moving scene would look like from different camera angles.
- It adds “static” (noise), like fuzz on a TV, and asks the video model what changes would make the motion look more realistic.
- Those suggestions are used to adjust the 3D motion. This process is called distillation—learning motion from the knowledge inside video models.
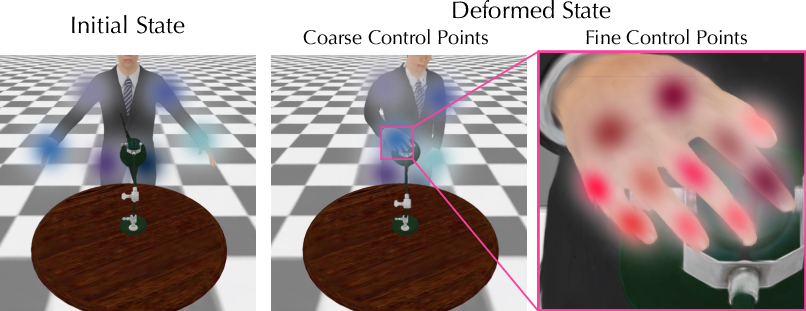
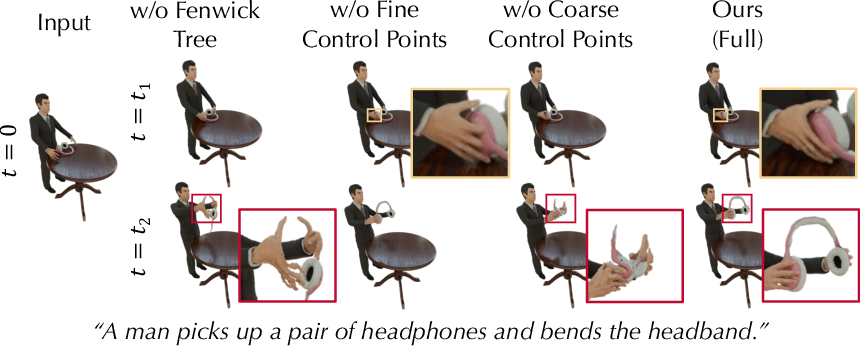
- Hierarchical control points (like puppet strings at two levels):
- Coarse control points: big, simple handles that move large parts of an object (think: moving a whole arm).
- Fine control points: small, precise handles that add details (think: fingers curling to grasp).
- The system first learns big motions, then refines small details—this makes learning stable and natural.
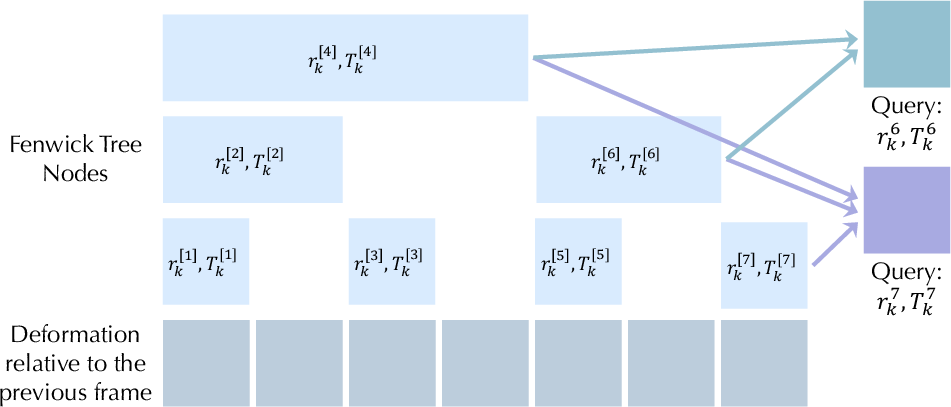
- Temporal structure with a Fenwick tree (stacking motion over time):
- Imagine a timeline made of overlapping blocks. Each block stores the “sum” of motion over a range of frames.
- Later frames reuse parts of earlier motion, so movement remains smooth and consistent over time.
- This helps the system learn long, complex actions without getting messy.
- A 3D representation good for smooth animation:
- Objects are converted to “3D Gaussian splats,” a way of representing shapes that makes rendering and adjusting smooth and fast.
- Smart noise scheduling:
- Early on, the system uses more noise (bigger changes), which helps discover bold motions.
- Later, it uses less noise and refines the fine details.
- Regularization (rules that keep motion realistic):
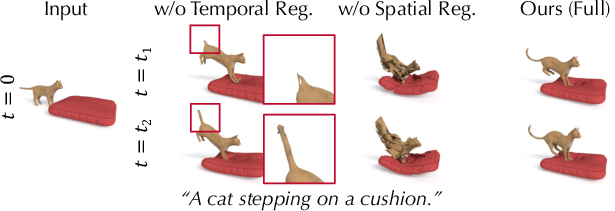
- Temporal regularization: discourages sudden, flickery movement over time.
- Spatial regularization: encourages nearby points on an object to move in consistent ways (like real materials do), so things don’t stretch in impossible ways.
Main Findings and Why They Matter
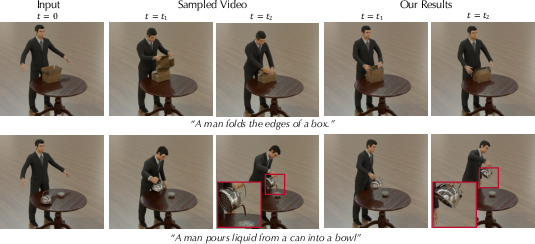
- Better animations: In comparisons with other methods, Chord produced motion that matched text prompts more closely and looked more natural, especially for multi-object scenes and interactions.
- Strong user study results: In a test with 99 people watching different scene animations, Chord was preferred for both alignment with the prompt and realism about 88% of the time—much higher than other methods.
- Automatic metrics: Using an AI tool to evaluate videos, Chord scored best or near-best on semantic alignment (matching the prompt) and physical commonsense (motion that doesn’t break the laws of physics).
- Works on real-world scans: Because it learns motion patterns from real videos, Chord can animate scanned objects from the real world—not just cartoonish or synthetic models.
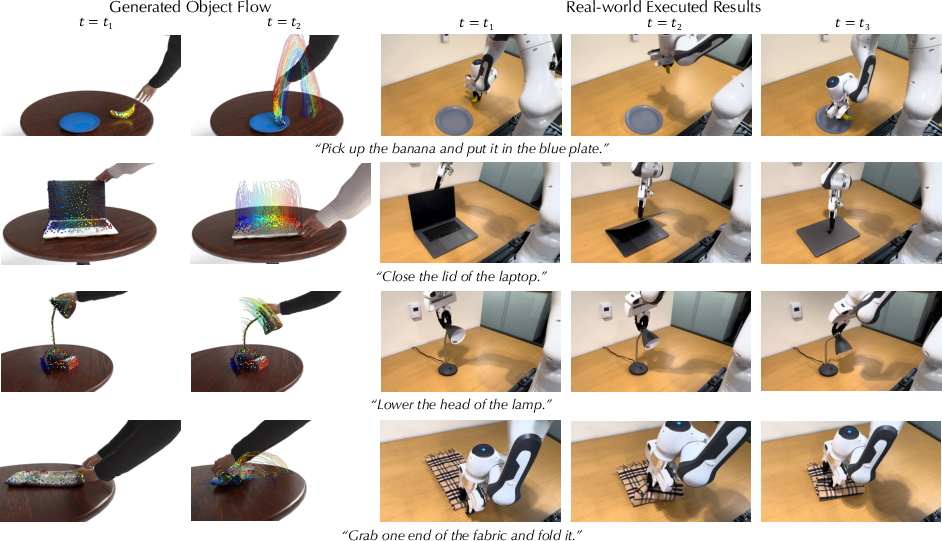
- Helps robots plan actions: The system produces dense “object flow”—a map of how points on an object should move. Robots can use this flow to figure out how to push, grasp, or bend objects, even for articulated (hinged) or deformable (squishy) items.
Implications and Impact
- Easier content creation: Artists, game developers, and filmmakers could animate complex 3D scenes without manually scripting every movement.
- Broader applicability: Because it doesn’t rely on category-specific rules or giant specialized datasets, Chord can work across many types of objects and scenes.
- Robotics and embodied AI: The method provides realistic, physically grounded motion plans that can be used to teach robots how to interact with real objects—potentially improving automation and assistive technologies.
- Longer, richer animations: By chaining motion segments, Chord can create multi-step scenes where objects perform sequences of actions.
In short, Chord shows how to turn static 3D worlds into believable moving scenes by “borrowing” motion wisdom from powerful video AIs, and by controlling motion with simple, stable tools that work across space and time.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper introduces a promising distillation-based pipeline for generating multi-object 4D scene dynamics. However, several aspects remain missing, uncertain, or unexplored:
- Lack of explicit inter-object physical constraints: The method has no differentiable contact, collision, friction, or mass/inertia modeling, which can lead to interpenetration or momentum violations; integrating contact-aware losses or differentiable physics could improve physical plausibility in multi-object interactions.
- Unclear failure modes and robustness: The paper does not characterize typical failure cases (e.g., shape collapse, identity drift, spurious motions, interpenetration) or quantify robustness under occlusions, cluttered scenes, or highly articulated/deformable objects.
- Limited physics grounding beyond ARAP: The regularizers (ARAP and temporal flow L2) encourage smoothness and near-rigidity but do not enforce Newtonian constraints (e.g., gravity, force consistency, energy/momentum conservation); evaluating and adding physics-informed priors is needed.
- Prompt control granularity: Motion is guided via text only, with no mechanisms for specifying timing, keyframes, trajectories, or contact events; adding controllable constraints (e.g., waypoints, force targets, temporal schedules) would enable precise choreography.
- Camera sampling strategy is under-specified: The method relies on rendering from “certain viewpoints,” but lacks a principled camera pose distribution or analysis of viewpoint bias; systematic study of camera sampling and its impact on 3D consistency and motion fidelity is needed.
- Theoretical grounding of W-RFSDS: The modified SDS target for rectified flow (RF) models and its noise schedule are motivated heuristically; a formal derivation, variance analysis, and convergence guarantees—plus generalization to other RF/video model training schedules—remain open.
- Model dependence and reproducibility: The approach is tailored to Wan 2.2 with an implicit training weight function w(τ); portability to other RF-based video models (and to non-RF architectures) requires clear procedures, ablations, and open-source reproducible configurations.
- Rotation composition choice: The Fenwick tree composes rotations by normalized quaternion summation, which is not physically accurate; evaluating Lie group formulations (e.g., cumulative products via exp/log maps) could improve rotational continuity and stability.
- Long-horizon drift and accumulation: The chaining strategy to extend motion can accumulate error and drift; quantifying drift, proposing re-centering/loop closures, and developing horizon-aware regularization remain open.
- Scalability to complex scenes: Experiments involve up to a few objects; the scalability of control-point hierarchies and optimization to scenes with many (>10) interacting objects, heavy occlusion, and dense clutter is untested.
- Topology change and continuum dynamics: The control-point SE(3) blend with ARAP favors near-rigid deformations and cannot handle tearing, breaking, fluid, cloth, hair, or plastic flow; extending to continuum-based models or hybrid representations is needed.
- Automatic control-point placement: The number, radii, and placement of coarse/fine control points are not automatically optimized or adapted per object; learning control-point layouts and radii from geometry/semantics could reduce hand-tuning and improve fidelity.
- Multi-view 3D consistency guarantees: While 3D-GS is used, the supervision is 2D video-based; a study of cross-view consistency and 360° fidelity (e.g., unseen viewpoints, extreme poses) is missing.
- Segmentation and object identity: The pipeline assumes input meshes for each object; automatic object discovery/segmentation from a single scan and handling of partially merged meshes remain unaddressed.
- Timing and contact realism: The method does not model precise timing for contacts (e.g., onset, duration, restitution) or contact forces; evaluating and controlling temporal alignment of interaction events is an open direction.
- Quantitative physical evaluation depth: VideoPhy-2 scores are reported, but broader physical metrics (e.g., collision rates, contact stability, energy profiles, momentum consistency) on standardized benchmarks are lacking; building datasets and metrics for scene-level 4D physical plausibility is needed.
- Computational efficiency and resource profile: Training time, GPU memory footprint, and inference speed are not reported; profiling and accelerating optimization (e.g., via curriculum, cached guidance, or low-rank updates) would aid practical deployment.
- Guidance noise schedule adaptivity: The annealed τ schedule is fixed per iteration and prompt-agnostic; adaptive schedules (e.g., learned or feedback-driven) could reduce artifacts on challenging prompts or fine details.
- Per-object coupling in regularization: Spatial regularization operates within each object’s point cloud; adding cross-object regularizers (e.g., contact persistence, slip constraints) could enforce coherent interactions.
- Appearance and lighting dynamics: The system focuses on geometric deformation; texture stretching, material changes, and dynamic lighting are not modeled—important for realism when objects bend or self-shadow.
- Robot manipulation evaluation rigor: The robotics demos lack quantitative metrics (e.g., success rate, accuracy, force limits, safety) and closed-loop control; mapping dense flows to feasible motions for deformables (beyond a rigid attachment model) needs physics-aware planning and evaluation at scale.
- Safety and ethics in physical guidance: The pipeline can suggest motions that are unsafe for robots (e.g., high-speed impacts); incorporating safety constraints and human-in-the-loop verification remains open.
- Generalization to real-world clutter and backgrounds: Real scanned objects are shown, but multi-object real scenes with background complexity and variable lighting are not systematically evaluated.
- Domain gaps and biases: The approach inherits biases from the video generative model (e.g., common human/object interactions); auditing and mitigating dataset/model bias to ensure fair and diverse motion generation is unaddressed.
Practical Applications
Immediate Applications
Below are practical, deployable applications that can be implemented now with the paper’s Chord pipeline and its supporting methods.
- Rig-free scene-level mesh animation for VFX and games — Sectors: media/entertainment, software
- Use Chord to animate multiple interacting objects from static meshes via text prompts, avoiding category-specific rigging and manual keyframing. Export as vertex caches (e.g., Alembic) or baked meshes back to DCC tools (Blender, Maya) for rendering or engine import.
- Potential tools/workflows: a “Chord for DCC” plugin that converts meshes to 3D Gaussian Splatting (3D-GS), runs the W-RFSDS optimization with prompt guidance, and transfers the learned deformations back to meshes.
- Assumptions/dependencies: high-quality meshes and object segmentation; GPU compute for iterative distillation; access and licensing for a capable video generative model (e.g., Wan 2.2); good prompt engineering; outputs are visually plausible but not strictly physically accurate.
- Previsualization and storyboarding of multi-object interactions — Sectors: film/advertising
- Rapidly choreograph scenes like “two people shaking hands” or “a robot picking up a block” for creative exploration and shot planning.
- Potential tools/workflows: batch prompt iteration; quick camera sampling to preview; export as coarse/fine control-point timelines for later refinement.
- Assumptions/dependencies: iterative optimization time; scene-specific domain coverage in the guiding video model; human review for continuity and style.
- Game prototyping for cutscenes and interactive set pieces — Sectors: gaming/software
- Generate exploratory animation sets of object-object interactions (falling, pushing, grasping) without bespoke rigs; import baked animations into Unreal/Unity for prototyping.
- Potential tools/products: a “Chord-to-Engine” importer producing skeletal-free vertex animations or point caches; in-editor preview.
- Assumptions/dependencies: offline generation time; physical plausibility sufficient for creative prototyping, not simulation-grade accuracy.
- Volumetric AR/VR content from scanned real objects — Sectors: AR/VR, cultural heritage
- Animate scanned assets (e.g., museum artifacts, furniture) to demonstrate use or interaction while maintaining 360° view consistency (via mesh deformation derived from 3D-GS).
- Potential tools/workflows: mobile scanning → 3D-GS conversion → Chord animation → mesh deformation transfer → export to AR/VR runtime.
- Assumptions/dependencies: scanning fidelity; correct scale/units; curated prompts to avoid implausible motions; compute resources for iterative distillation.
- Flow-guided robot manipulation prototypes — Sectors: robotics, manufacturing
- Use Chord’s dense object flow to guide zero-shot grasps/pushes of rigid, articulated, and deformable objects. Demonstrated workflow: AnyGrasp for grasp proposals + a motion planner (e.g., PyRoKi) optimizing end-effector trajectories to align with Chord’s flow under a rigid-attachment forward model.
- Potential tools/workflows: “Flow-to-Policy” pipeline for lab demos; prompt-conditioned manipulation sequences; long-horizon chaining by feeding last frames forward.
- Assumptions/dependencies: accurate robot calibration; reachability constraints; closed-loop sensing is not part of Chord (add perception/feedback externally); domain gap between generated flows and real dynamics (friction, compliance) must be managed.
- Synthetic dataset generation for manipulation and dynamics learning — Sectors: academia, robotics R&D
- Create diverse, multi-object 4D scenes with groundable object flows to augment training data for planners or representation learning (e.g., scene dynamics, interaction priors).
- Potential tools/workflows: prompt-driven scenario factories; domain randomization over geometry, materials, and camera trajectories; export flow fields and deformed meshes per frame.
- Assumptions/dependencies: distribution alignment to target tasks; sim-to-real gap; 4D labeling strategies; compute budgets for scaling data creation.
- E-commerce/product showcases with dynamic demonstrations — Sectors: retail/marketing
- Animate scanned products (e.g., foldable items, furniture with moving parts) to illustrate usage or assembly steps without building rigs.
- Potential tools/workflows: “Scan-to-Showcase” pipeline; prompt-based interactive scenes embedded in web viewers; multi-angle previews.
- Assumptions/dependencies: IP/licensing for scans; accurate geometry and scale; editorial control to avoid misleading dynamics.
- Instructional content and interactive manuals — Sectors: education, industrial training
- Generate step-by-step, multi-object sequences (assembly, packaging, tool use) by chaining Chord’s motions and using camera sampling for illustrative views.
- Potential tools/workflows: timeline editor mapping Fenwick-tree temporal ranges to “steps”; export annotated frames and flows.
- Assumptions/dependencies: prompt clarity and task decomposition; expert review for correctness; plausible ≠ guaranteed physically correct.
- Physics/commonsense QA for generative video content — Sectors: academia, model evaluation
- Use Chord to produce controlled 4D scenes; render videos from varied camera trajectories and score with VideoPhy-2 metrics (Semantic Adherence, Physical Commonsense) to benchmark or regression-test video generative models.
- Potential tools/workflows: evaluation harness integrating W-RFSDS sampling schedule and VideoPhy-2 scoring; ablation pipelines.
- Assumptions/dependencies: evaluation metrics are proxies, not formal physics proofs; cross-model comparability depends on consistent camera/view protocols.
- 3D digitization engagement for museums/heritage — Sectors: culture/education
- Animate artifacts in contextual scenes (non-destructive visualization) to help visitors understand historical use or interaction.
- Potential tools/workflows: curatorial prompts; constrained control-point edits to maintain artifact integrity; 360° viewing.
- Assumptions/dependencies: conservation policies; factual accuracy of depicted interactions; curator approval.
Long-Term Applications
The following applications require further research, scaling, integration, or productization before broad deployment.
- General-purpose “Chord Studio” for 4D scene choreography — Sectors: media/entertainment, software
- A production-grade editor for multi-object 4D generation with GUI access to coarse/fine control points and Fenwick-tree temporal ranges; real-time previews; non-destructive edits; robust export pipelines.
- Dependencies: faster optimization (model distillation speed-ups, caching), interactive noise schedules, better controls for style/constraints, UX engineering.
- Closed-loop text-to-action robot manipulation — Sectors: robotics, logistics, home assistance
- From natural language instructions, generate flow fields and refine them online with perception to yield safe, reliable manipulation (grasping, folding, tool use) across object categories.
- Dependencies: sensor fusion and feedback control, safety and compliance layers, physics-aware constraints, task grounding and robust prompt understanding.
- Physics-aware 4D generation with simulation constraints — Sectors: engineering, healthcare, soft robotics
- Integrate differentiable physics or constraints (materials, collisions, contacts) into the distillation loop to ensure physically consistent deformations (e.g., soft tissues, garments).
- Dependencies: hybrid training targets combining RF SDS and physics losses; material models; compute; reliable contact handling; validation in safety-critical domains.
- Dynamic digital twins for manufacturing and logistics — Sectors: industrial operations
- Animate assembly lines, packing procedures, and human-robot collaboration scenarios for planning and training, with export to simulation and scheduling tools.
- Dependencies: integration with CAD/BIM, accurate asset libraries, synchronization with sensors/IoT, support for domain-specific physical constraints.
- Real-time AR experiences with on-device 4D generation — Sectors: consumer tech, education
- On-device generation of dynamic scenes from user prompts and scans for interactive learning and play.
- Dependencies: model compression, hardware acceleration, low-latency distillation or cached motion libraries, energy efficiency.
- Scaled 4D dataset creation for foundation model training — Sectors: academia, AI labs
- Use Chord to curate large, diverse corpora of multi-object dynamics and interactions to improve generalization in video/3D foundation models.
- Dependencies: significant compute and storage, data governance, coverage of rare categories, standardized annotation of 4D flows.
- Assistive design tools for ergonomic and safety planning — Sectors: architecture, workplace safety
- Choreograph object-human interactions in designed spaces (furniture placement, reachability, hazard simulation) to inform policy and layout decisions.
- Dependencies: validated ergonomics models; integration with building standards; data privacy; stakeholder training.
- Editable 4D motion timelines for technical artists — Sectors: media/entertainment
- A professional tool exposing hierarchical control points and cumulative temporal ranges (Fenwick-tree views) to edit or constrain generated motions.
- Dependencies: deep tooling, collaboration features, stable interfaces to DCC/engine ecosystems.
- Standards and benchmarks for physical plausibility — Sectors: policy, standards bodies
- Develop and adopt metrics (e.g., VideoPhy-like SA/PC) and test suites for certifying generative content used in training, advertising, or educational materials.
- Dependencies: multi-stakeholder consensus, reproducible protocols, sector-specific thresholds, governance and disclosure frameworks.
- Search/curation platforms for dynamic 4D assets — Sectors: content platforms, e-commerce
- Index and recommend dynamic animations (not just static 3D) to support rich product and media discovery.
- Dependencies: metadata and 4D descriptors (flows, interactions), scalable storage/streaming, rights management.
Glossary
- 3D flow map: A rendered per-pixel 3D displacement field between consecutive frames used to encourage temporal smoothness. "we additionally render a 3D flow map video from the same viewpoint, which is used for temporal regularization."
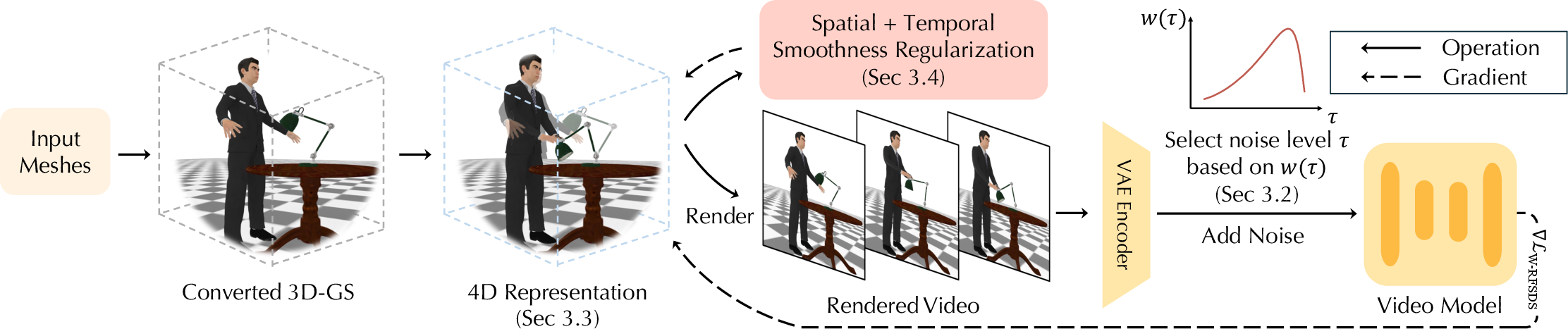
- 3D-GS: Short for 3D Gaussian Splatting; a point-based representation of 3D scenes enabling efficient differentiable rendering. "we first convert them into 3D-GS representations to enable smooth gradient computation."
- Annealing noise schedule: A schedule that gradually reduces the noise level during optimization to transition from coarse to fine motion. "Practically, this noise sampling strategy is implemented with an annealing noise schedule~\cite{huangdreamtime,tangdreamgaussian} during the optimization."
- As-Rigid-As-Possible (ARAP) loss: A regularization enforcing locally rigid deformations to prevent unrealistic distortions. "and compute an As-Rigid-As-Possible (ARAP) loss \cite{sorkine2007rigid} over the resulting sequence of deformed point clouds."
- Cumulative distribution function (CDF): The integral of a probability density function used here to define the annealed noise schedule over training. "where is the cumulative distribution function (CDF) of ."
- Dense object flow: A spatially dense motion field over an object used to guide robotic manipulation. "Given our generated dense object flow, the robot either grasps or pushes the object of interest in a manner that matches the flow."
- Eulerian representations: Motion description fixed in space (observing changes at locations), as opposed to following moving particles. "extract the rich Lagrangian motion information hidden in the Eulerian representations of 2D videos."
- Fenwick query operation: The Binary Indexed Tree query that retrieves cumulative range contributions for composing frame-wise deformation. "where denotes the set of active nodes returned by the Fenwick query operation, and ensures that the summed result forms a valid quaternion."
- Fenwick tree: A Binary Indexed Tree storing cumulative values over ranges, used here to enforce temporal coherence in deformations. "we represent the sequence of deformations for each control point with the Fenwick tree, a hierarchical data structure from theoretical algorithm design~\cite{fenwick1994new}."
- Hierarchical control point representation: A bi-level set of spatial controllers (coarse and fine) that parameterize object deformations locally. "Illustration of the hierarchical control point representation. We represent the deformation using a spatial hierarchical structure."
- Lagrangian deformations: Motion modeled by following individual objects/points over time. "we iteratively optimize the low-level Lagrangian deformations of each object."
- Linear blend skinning: A technique that blends multiple local transformations to deform geometry smoothly based on influence weights. "The deformation of a Gaussian is obtained by blending transformations from neighboring control points using linear blend skinning."
- Multi-view video diffusion model: A diffusion-based generator that produces synchronized videos from multiple camera viewpoints. "Animate3D generates multi-view videos using a multi-view video diffusion model and then performs 4D reconstruction on them."
- Physical Commonsense (PC): An automatic metric assessing whether generated video dynamics obey basic physical plausibility. "Additionally, we report the Semantic Adherence (SA) and Physical Commonsense (PC) metrics computed with VideoPhy-2~\cite{bansal2025videophy}."
- Quaternion: A four-dimensional representation for 3D rotations, supporting smooth composition and normalization. "where are the quaternion representations of rotation on control point , and is the production of quaternions."
- Rectified Flow (RF): A flow-based generative modeling framework whose dynamics are “rectified” to simplify training and sampling. "The major obstacle is the gap between the diffusion architecture used in the original SDS target and the Rectified Flow (RF)-based model architecture in modern video generative models, such as Wan~2.2~\cite{wan2025} used in our paper."
- RFSDS (Rectified Flow Score Distillation Sampling): An adaptation of SDS that formulates guidance for rectified flow models. "With this modification in sampling strategy, the weighted RFSDS update rule becomes:"
- Score Distillation Sampling (SDS): A method that distills gradients from diffusion models to optimize 3D/4D assets without paired data. "We derive a novel Score Distillation Sampling (SDS) \cite{poole2023dreamfusion} target for flow-based video diffusion models..."
- SE(3): The group of 3D rigid motions (rotations and translations) used to parameterize control-point transformations. "In addition, each control point maintains a sequence of deformations in ."
- Semantic Adherence (SA): An automatic metric evaluating how well generated videos match the input text prompts. "Additionally, we report the Semantic Adherence (SA) and Physical Commonsense (PC) metrics computed with VideoPhy-2~\cite{bansal2025videophy}."
- Signed Distance Field (SDF): A scalar field giving signed distance to a surface, used to sample uniformly near object geometry. "Specifically, we first compute a signed distance field (SDF) from the mesh of object ."
- Temporal regularization: A loss encouraging smooth changes across frames to reduce flicker and instability. "We introduce two regularization terms to further stabilize the optimization process: a temporal regularization loss to enforce smoothness over time and a spatial regularization loss to encourage local spatial consistency."
Collections
Sign up for free to add this paper to one or more collections.