- The paper introduces a novel parametric pipeline that samples diverse 3D motions directly from a static image by leveraging large-scale video diffusion models.
- It employs neural keypoint trajectory factorization and a unified latent space to encapsulate complex motion patterns with high fidelity.
- The approach achieves up to 6x–8x improvements in diversity and efficiency over baselines, enabling rapid and photorealistic 4D content generation.
Diverse 3D Motion Generation for Arbitrary Objects: The DIMO Framework
Introduction and Motivation
The "DIMO: Diverse 3D Motion Generation for Arbitrary Objects" framework introduces a novel parametric generative pipeline for instant and diverse 3D motion synthesis from a single static image of any general object. Unlike prior methods that target category-specific articulated models (e.g., SMPL for humans) or require repeated per-motion optimization runs, DIMO distills object-specific motion priors from large-scale video diffusion models, canonically encodes them via neural keypoint trajectories, and jointly models diverse motion patterns in a shared low-dimensional latent space. This enables direct sampling of multiple plausible dynamic 3D instances in a single forward pass, supporting applications such as language-guided animation, motion interpolation in latent space, and fast test-motion reconstruction. The approach demonstrates significantly increased diversity, fidelity, efficiency, and extensibility compared to established 4D generation baselines.
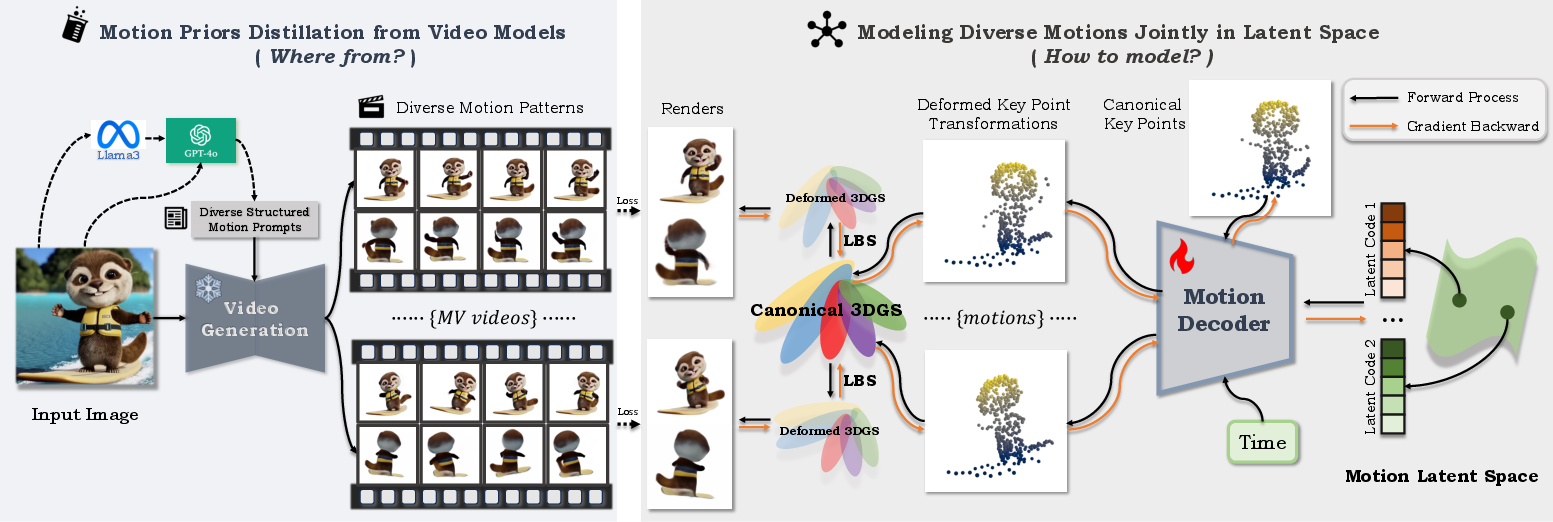
Figure 1: The DIMO pipeline leverages video model priors, auto-generated motion prompts, latent keypoint factorization, and 3D Gaussian splatting for unified geometry and appearance modeling.
Prior Distillation and Data Generation
DIMO replaces traditional motion-capture or template-driven datasets with automated pipelines for motion prior distillation. Multimodal LLMs (Llama3, GPT-4o) generate structured "meta" prompts and a set of diverse text descriptions of potential actions, based on a reference static image. These prompts are then passed into state-of-the-art text-conditioned image-to-video models (CogVideoX) to generate a large set of candidate motion-rich video clips. A filter pipeline combines MLLM-based quality assessment and optical flow-based motion magnitude ranking to curate the set, ensuring coverage of variable, plausible dynamics for each object.
To enable robust spatiotemporal and geometric modeling, multi-view generative video models (SV3D, SV4D) are used to further provide novel viewpoints and stronger 3D priors, facilitating multi-motion, multi-view, multi-frame joint training.
Unified Latent Space and Neural Keypoint Trajectories
Central to DIMO is the construction of a shared low-dimensional latent space encoding the diversity of 3D motion patterns for each target object. This is achieved via explicit neural keypoint trajectory factorization. Each motion is represented by a sparse set of canonical 3D keypoints, each parameterized with position, control radius, and an RBF kernel influencing nearby points. Their time-varying poses are encoded as sequences of 6DoF SE(3) transformations (translation, quaternion rotation). The set of keypoints and their trajectories define the motion basis for all generated instances.
A graph structure connects keypoints based on temporal trajectory similarity (KNN in concatenated positions), allowing topology preservation. A latent-conditioned MLP-based motion decoder maps the motion-specific latent vector, keypoint position, and timestep to the appropriate transformation. Latent codes are optimized via the VAE reparameterization trick, enforcing smooth diversity and continuity through KL regularization.
Geometry and Appearance Modeling via 3D Gaussian Splatting
To couple motion dynamics with object-specific geometric details and appearance, canonical 3D Gaussian primitives are attached to keypoints and further distributed in proximity. Each Gaussian is parameterized by center, rotation, scale, opacity, and SH color. Deformation at each timestep is performed via Linear Blend Skinning (LBS), driven by the nearest keypoint poses and graph edges, resulting in temporally coherent and topologically faithful geometry.
Differentiable rasterization using splatting-based rendering allows efficient photometric supervision across multiple views and timestamps, supporting direct optimization of geometry, keypoints, and latent codes.
Optimization Strategies and Training Regimes
Training utilizes a two-stage coarse-to-fine schedule to disentangle motion factorization from fine geometry optimization. In the first stage, keypoints, latent codes, and decoder are jointly pre-trained to capture robust motion bases and latent embedding continuity, with periodic keypoint resampling and densification. The second stage initializes canonical Gaussians near each keypoint and refines parameters for photorealistic appearance and detailed motions, recycling keypoint trajectories for guidance via Chamfer distance regularization.
Multi-loss training combines RGB, mask, perceptual, depth smoothness, normal smoothness, ARAP rigidity, and KL regularization. Batch sampling across multiple motions, views, and frames provides strong constraints for learning shared structures. Render resolution is annealed for stable convergence.

Figure 2: Qualitative DIMO results illustrating instant generation of diverse and photorealistic 3D motions and 4D contents from the same object image under novel viewpoints and timestamps.
Extensive benchmark comparisons against DG4D, 4DGen, Animate124, STAG4D, SV4D, Consistent4D, and 4D-fy show clear superiority of DIMO in terms of diversity, alignment, fidelity, and efficiency. In the 3D Motion Generation task (Figure 3), DIMO is able to synthesize a variety of high-quality plausible motions for each object, where baselines often fail to produce noticeable motion diversity or suffer identity drift due to repeated diffusion sampling.

Figure 3: DIMO generates high-fidelity, diverse 3D motions per object, outperforming baseline models in pronounced and realistic dynamic behavior.
For image-to-4D and video-to-4D tasks (Figure 4), quantitative and qualitative metrics (CLIP-I, CLIP-F, LPIPS, FVD, user studies) show DIMO surpasses others by large margins, with up to 6x-8x improvement in motion diversity and a drastic reduction in required training time (often achieving results in minutes rather than hours).

Figure 4: DIMO produces photorealistic, multi-motion 4D contents for both synthetic and in-the-wild objects, outperforming existing methods in visual and temporal coherence.
For text-to-4D tasks, DIMO's latent space is compatible with language embedding projections, enabling direct feed-forward generation of plausible, text-specified dynamics at interactive speeds. The framework achieves over 80% text-motion alignment and motion diversity in user studies, versus under 10-16% for prior approaches.
Applications: Latent Motion Interpolation and Language-Guided Generation
DIMO demonstrates continuous and meaningful latent space interpolation, allowing synthesis of novel coherent motion sequences between two anchors. Language-guided motion generation is supported via a learned mapping from text embeddings (BERT) into latent codes, yielding plausible animation driven by compact language prompts.
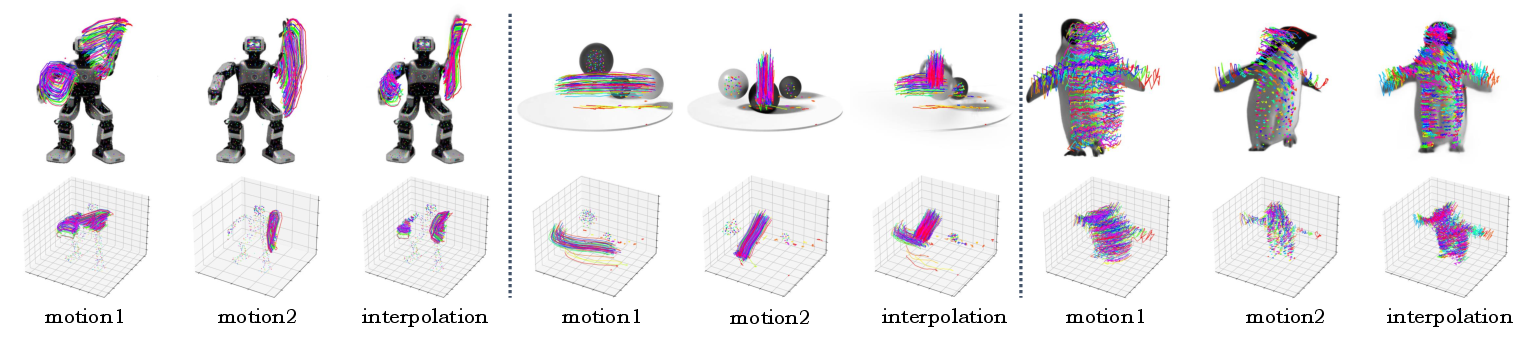
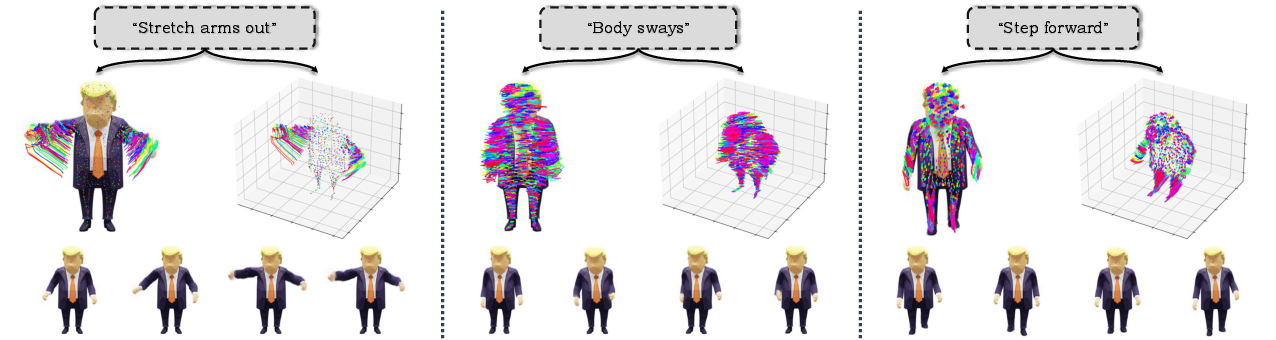
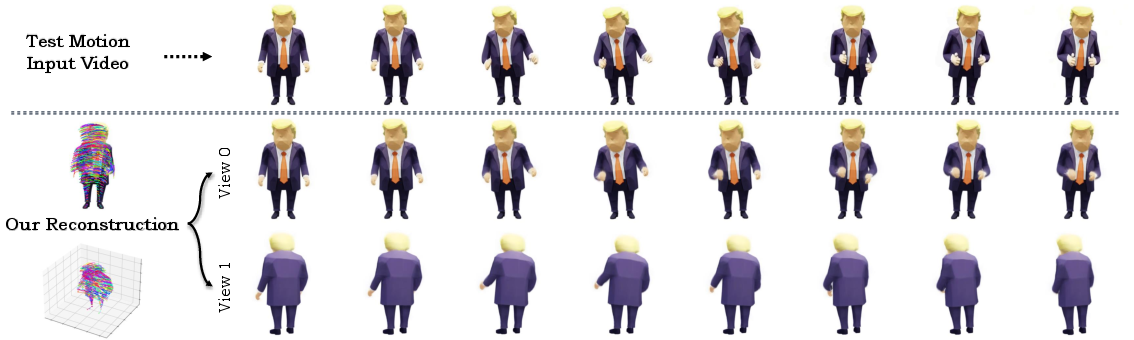
Figure 5: Linear interpolation in DIMO’s latent motion space produces smooth and novel transitions between distinct sampled motion sequences.
Test motion reconstruction is supported by fine-tuning the latent code for unknown videos, providing high-fidelity alignment and rapid convergence.
Ablation and Model Analysis
Ablation studies confirm the necessity of motion factorization, the latent space, coarse-to-fine pre-training, and multi-motion joint training. Removal of any component causes significant degradation in diversity, spatiotemporal consistency, and fidelity. Joint multi-motion training enhances model robustness and preserves object identity and appearance across dynamic behaviors.
Limitations and Future Directions
The reliance on state-of-the-art video diffusion models for prior distillation makes DIMO’s performance contingent on ongoing advances in generative models and multimodal prompting. Current two-stage separation of latent code learning and language mapping could be unified for more efficient end-to-end training. Extension to interactively editable motion content and fine-grained physical realism is a prospective research direction.
Conclusion
DIMO provides a scalable, generalizable, and efficient framework for diverse 3D motion synthesis for arbitrary objects, supporting instant sampling of rich dynamic behaviors from a single image. Its motion latent space, neural keypoint factorization, and joint optimization strategy offer clear advantages for geometric and appearance fidelity, diversity, and real-time applications. The work represents a substantive advancement towards universal data-driven parametric models akin to SMPL, but for any object class with minimal supervision, opening new directions for generative modeling, interactive animation, and content creation at scale.

