- The paper introduces InternData-A1, a synthetic dataset with 630k trajectories across 70 tasks for robust VLA policy pre-training.
- It employs a four-stage data synthesis pipeline that integrates environment construction, skill composition, domain randomization, and trajectory generation.
- Experimental results demonstrate a 5–6.5% improvement in task success rates and strong sim-to-real transfer across diverse robot embodiments.
InternData-A1: High-Fidelity Synthetic Data for Generalist VLA Policy Pre-training
Motivation and Context
The paper "InternData-A1: Pioneering High-Fidelity Synthetic Data for Pre-training Generalist Policy" (2511.16651) robustly addresses the limitation of real-world data collection for Vision-Language-Action (VLA) models, which is resource-intensive and scales poorly for embodied AI. Synthetic data generated through simulation presents a pathway to bypass these constraints, but prior synthetic datasets have not achieved equivalence with the strongest real datasets in supporting VLA policy generalization. InternData-A1 closes this gap, providing expansive, physically accurate, and diverse synthetic demonstrations for robotic manipulation.
Dataset Scope and Structure
InternData-A1 comprises 630k trajectories encompassing 7,433 hours of interaction over four robotic embodiments (AgiBot Genie-1, Franka Emika Panda, AgileX Split Aloha, and ARX Lift-2), 70 tasks, 18 manipulation skills, and 227 indoor scenes. The object domains include rigid, articulated, deformable, and fluid objects. Tasks integrate both short atomic actions and long-horizon, multi-stage procedures, orchestrated through a modular skill library and a highly automated pipeline for asset selection, scene composition, domain randomization, and joint-space trajectory generation. All content is rendered with physically and visually faithful processes to ensure transferability of learned policies.

Figure 1: InternData-A1 pioneers a large-scale, high-fidelity synthetic dataset with physically faithful, photorealistic rendering, diverse object domains, extensive multi-skill tasks, and broad cross-embodiment coverage.
The dataset statistics establish InternData-A1 as singular in manipulated diversity: 3,185 rigid objects, 321 articulated objects, 20 garments, and a sweeping array of scenes, resulting in 401.4 million frames. The compositional skill design supports bimanual manipulation, multi-robot interaction, and sequential skill execution central to advanced manipulation.
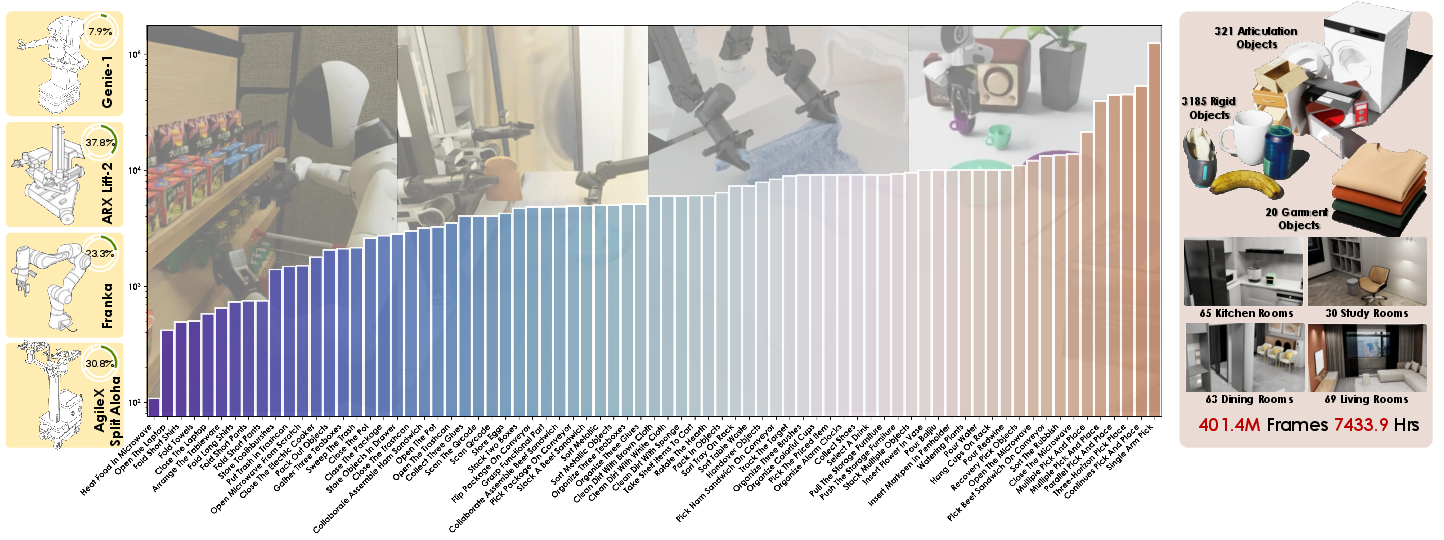
Figure 2: InternData-A1 provides 4 single or dual-arm embodiments, 70 diverse tasks, thousands of objects and rooms, and millions of frames at scale.
Data Synthesis Architecture
The four-stage pipeline involves:
- Environment construction via asset retrieval (robot, scene, object).
- Skill composition using modular, command-driven atomic policies.
- Domain randomization in scene layout, lighting, camera parameters, object poses, and manipulation constraints.
- Trajectory generation with dense joint action interpolation (cuRobo), physics validation, and rendering of successful executions into LeRobot format.
Framework optimizations decouple computationally heterogeneous planning and rendering stages, use dynamic resource scheduling, and deploy stacked render techniques for maximal throughput, yielding 2-3× improvement over baseline synthetic data generation. Large-scale data synthesis proceeds at minimal cost per episode, democratizing access to broad robotic data.
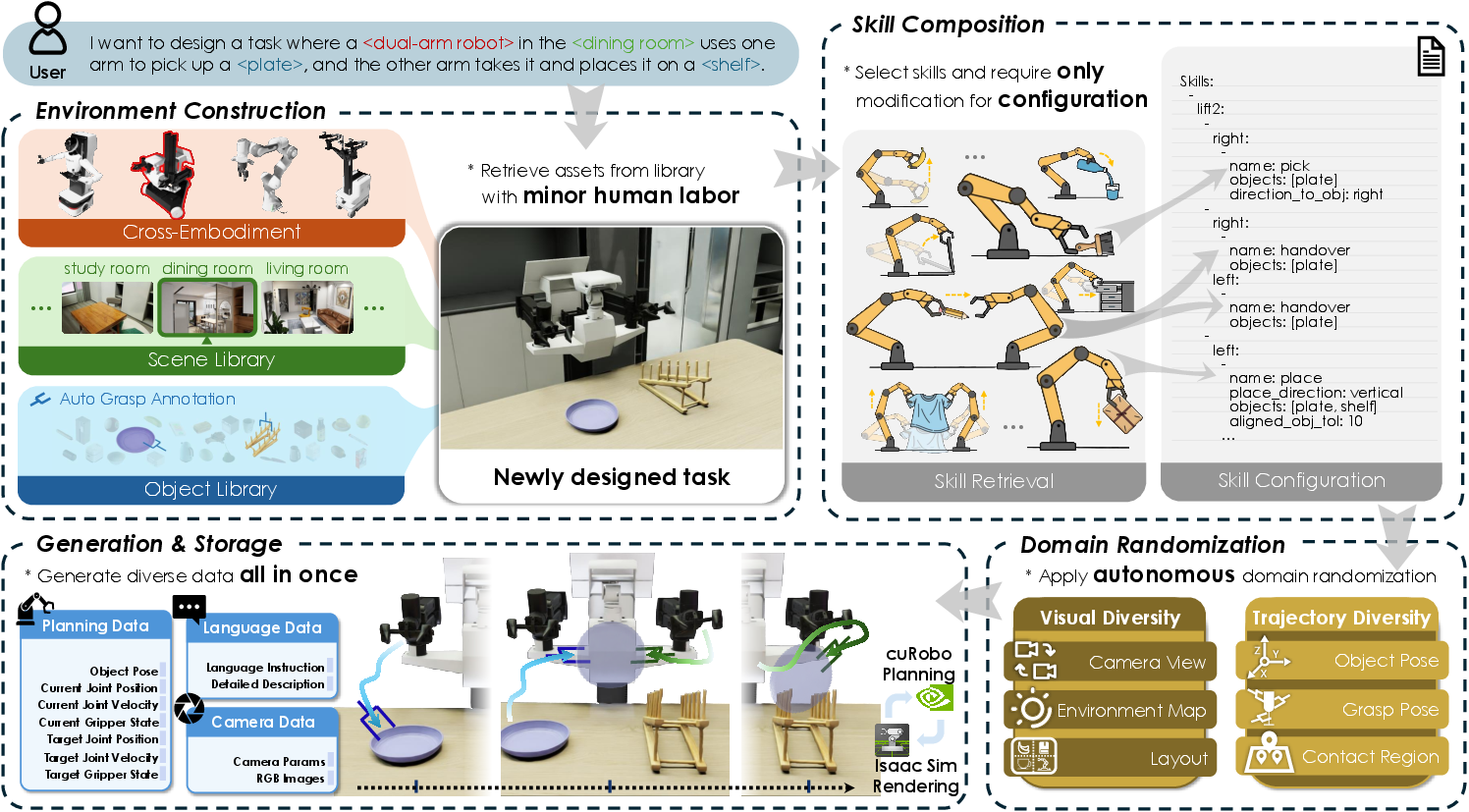
Figure 3: Data synthesis pipeline details environment construction, skill composition, domain randomization, and trajectory generation with physical validation and efficient rendering.
Pre-training Efficacy and Experimental Results
The critical result is that π0 models pre-trained solely on InternData-A1 match or exceed those trained on the closed-source π-dataset baseline in both simulated and real-world environments. Evaluated across 49 simulated bimanual tasks (easy and hard modes), InternData-A1 pre-training yields 5–6.5% higher task success rates.
Real-world evaluation includes nine tasks spanning three robots and challenging dexterous manipulations (garment folding, unscrewing, zipping) with novel embodiments. InternData-A1 pre-trained models demonstrate comparable performance to π-dataset counterparts, including on unseen skills and objects, positively answering whether scaled synthetic data can close the sim-to-real gap for generalist VLA models.

Figure 4: Real-world setup for cross-dataset evaluation on nine tasks with multiple robots.
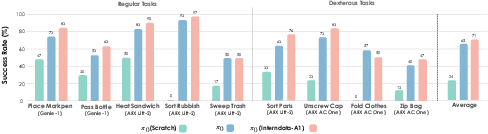
Figure 5: InternData-A1 achieves performance comparable to the strongest real data across diverse real-world and dexterous tasks.
Sim-to-Real Transfer Analysis
Direct sim-to-real transfer is further validated: on ten representative tasks, policies trained on InternData-A1 achieve average success rates exceeding 50% with only hundreds of simulated samples, narrowing the performance gap with real training data to as low as an 8:1 data ratio, and often performing similarly even with coarse simulation-to-real environmental alignment.
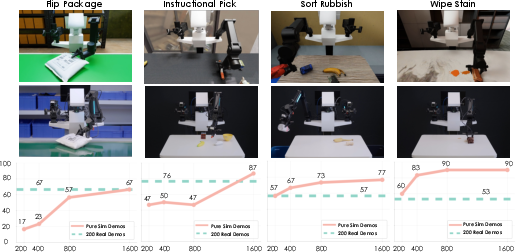
Figure 6: Sim-to-real transfer setup compares performance of purely simulated versus real-trained models across key manipulation tasks.

Figure 7: Additional sim-to-real results show strong transfer rates (50–87%) for complex, multi-skill, articulation, and bimanual tasks with only 500 simulated episodes.
Ablative Insights and Data Composition Effects
Dataset ablation experiments underscore that multi-skill diversity, long-horizon and articulation tasks drive robust VLA pre-training—removal of these elements degrades downstream success rates more than removing pick-and-place instances. This clarifies that mere volume of primitive actions is insufficient; compositional, high-entropy trajectory diversity is an essential inductive bias.
Implications and Future Directions
InternData-A1 reframes simulation as not only a scalable but an equally performant source of VLA action priors for embodied models, unlocking systematic exploration of data scaling laws, cross-embodiment transfer, and skill composition in policy learning. The open-source release of both dataset and pipeline reduces entry barriers, equipping the community for reproducible, systematic pre-training benchmarks.
Theoretical implications center on the compositionality hypothesis: diverse, physically accurate skill combinations, under extensive domain randomization, can generalize robustly, even under visual and physical sim-to-real discrepancies. Practically, InternData-A1 paves the way for rapid policy prototyping, benchmarking, and rigorous investigation of data-driven generalization in manipulation.
Limitations remain in simulating highly dexterous or high-fidelity contact-rich behaviors (e.g., shoelace tying), principally due to simulator physics constraints. Future advancements will likely integrate hybrid sim-real bootstrapping, extend the dexterity and ambiguity of synthetic tasks, and evolve simulator realism via differentiable or learned physics engines.
Conclusion
InternData-A1 establishes synthetic data as a viable substitute for real-world demonstrations in generalist VLA policy pre-training. Its comprehensive scale, diversity, and pipeline automation demonstrate that robust robot manipulation skills can be induced in simulation, enabling reliable zero-shot transfer to reality. Open access to InternData-A1 will catalyze further progress in data-efficient embodied AI, with the next frontier being bridging the simulation gap for high-complexity dexterous tasks.

