Diversity or Precision? A Deep Dive into Next Token Prediction
Abstract: Recent advancements have shown that reinforcement learning (RL) can substantially improve the reasoning abilities of LLMs. The effectiveness of such RL training, however, depends critically on the exploration space defined by the pre-trained model's token-output distribution. In this paper, we revisit the standard cross-entropy loss, interpreting it as a specific instance of policy gradient optimization applied within a single-step episode. To systematically study how the pre-trained distribution shapes the exploration potential for subsequent RL, we propose a generalized pre-training objective that adapts on-policy RL principles to supervised learning. By framing next-token prediction as a stochastic decision process, we introduce a reward-shaping strategy that explicitly balances diversity and precision. Our method employs a positive reward scaling factor to control probability concentration on ground-truth tokens and a rank-aware mechanism that treats high-ranking and low-ranking negative tokens asymmetrically. This allows us to reshape the pre-trained token-output distribution and investigate how to provide a more favorable exploration space for RL, ultimately enhancing end-to-end reasoning performance. Contrary to the intuition that higher distribution entropy facilitates effective exploration, we find that imposing a precision-oriented prior yields a superior exploration space for RL.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper explores a simple but important question about how LLMs learn to predict the next word (or token) and how that affects their ability to reason. The authors ask: should we train models to be more diverse (spread their guesses across many possible words) or more precise (strongly favor the one correct word)? They connect this everyday training step—next-token prediction—to ideas from reinforcement learning (RL), where models get rewards for making good choices. Then they design a new training method that lets them adjust the balance between diversity and precision and study which balance helps LLMs reason better in the end.
Key Questions
The paper focuses on three easy-to-understand questions:
- When training an LLM to guess the next token, is it better to encourage many possible guesses (diversity) or to push hard on the most correct guess (precision)?
- How does the “shape” of the model’s guesses before RL—its token probability distribution—affect what the model can explore and improve during RL?
- Can we redesign the pre-training objective so we can control this balance and see which approach leads to better reasoning performance after RL?
How They Did It (Methods, explained simply)
Think of writing a sentence as a step-by-step game. At each step, the model looks at what’s already written (the state) and picks the next token (the action) from a big list of possible tokens (the vocabulary). In standard training, the model is told which token is the correct next one (from the dataset), and it gets trained to assign that correct token a higher probability. This is usually done with a loss called “cross-entropy.”
The authors show that this common training step is similar to a one-step RL game:
- Action = choosing the next token
- Reward = getting “points” when you pick the correct token
- Policy = the model’s habit of how likely it is to choose each token
They then introduce “reward shaping,” which is like adjusting the rules for how many points you get:
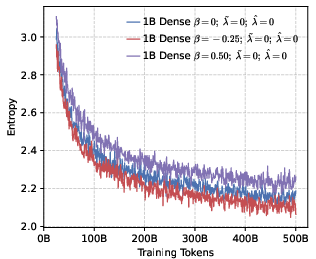
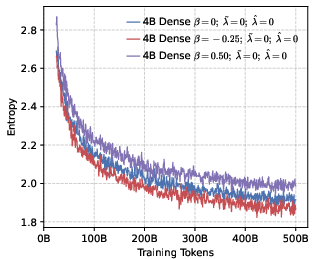
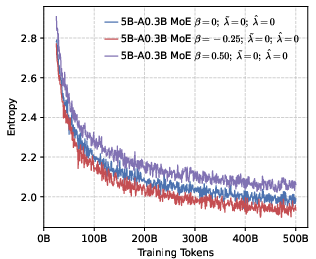
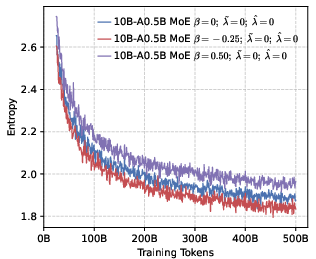
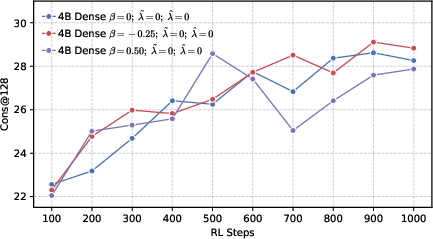
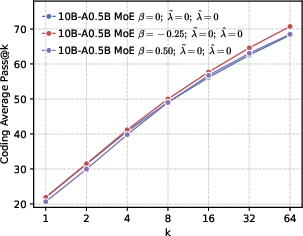
- Positive reward scaling (controlled by a parameter they call β): This changes how strongly the model is pushed toward the correct token. Imagine a volume knob for “be confident in the correct answer.”
- β < 0: Turn up the reward for being right—push probabilities to be more peaked around the correct token (precision).
- β > 0: Turn down the reward—allow a flatter, more spread-out distribution (diversity).
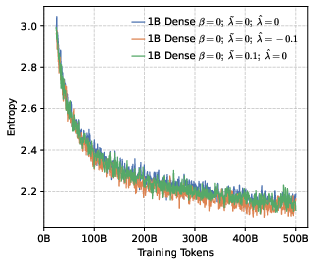
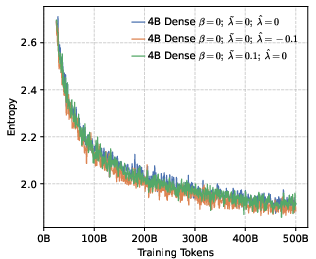
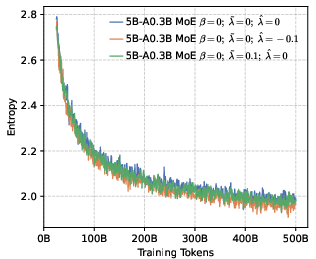
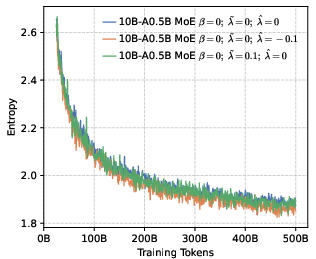
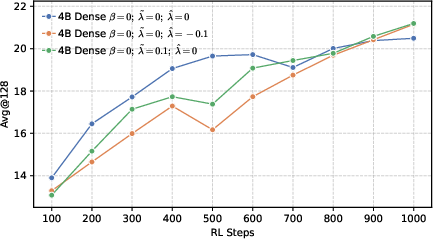
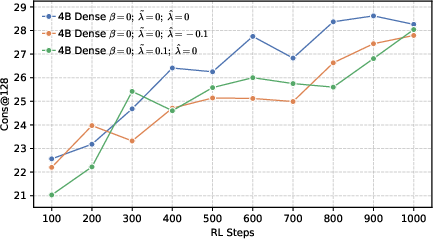
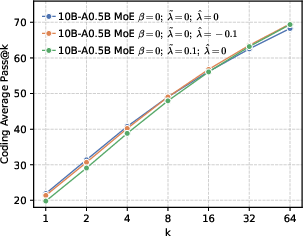
- Rank-aware negative shaping: Not all wrong tokens are equal. The model often has a “Top-K” list of tokens it thinks are likely.
- High-ranking wrong tokens (near the top): Don’t crush them—keep some probability there to preserve local diversity so the model can explore close alternatives.
- Low-ranking wrong tokens (far in the tail): Push these down more strongly so the model doesn’t waste effort on very unlikely options.
In everyday terms: they give more points for being confidently right, some points for “reasonable wrong guesses” near the top, and fewer or negative points for “unlikely wrong guesses” in the tail. This lets them reshape how the model spreads its probabilities across tokens during pre-training.
Main Findings and Why They Matter
The authors ran large-scale experiments with different model sizes and architectures and measured performance on many benchmarks (general knowledge, logic, common sense, math, and coding), including RL stages focused on math.
Here’s what they discovered:
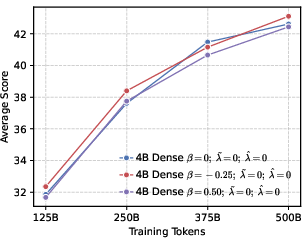
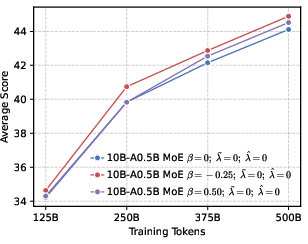
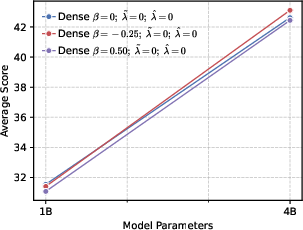
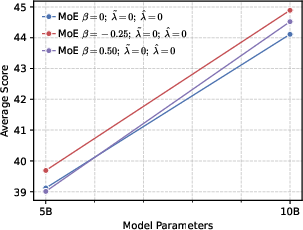
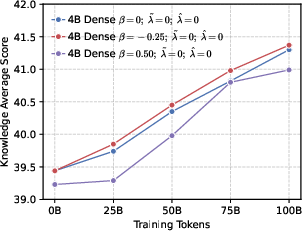
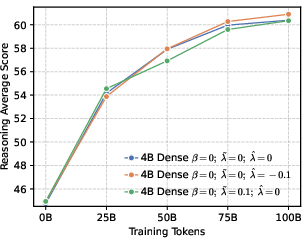
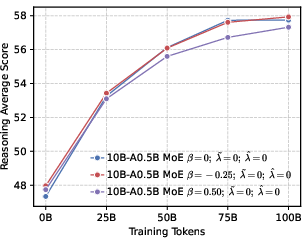
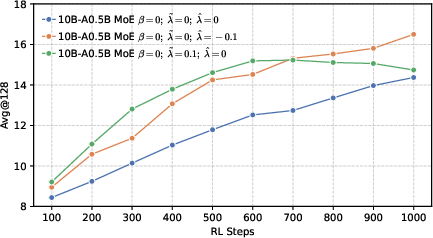
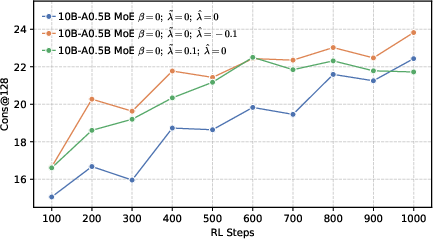
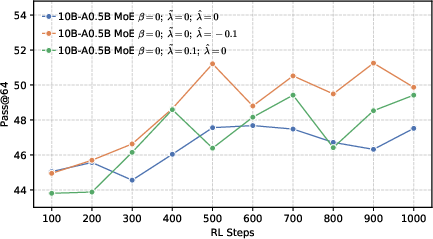
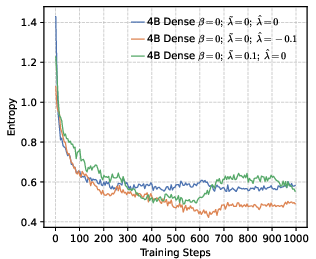
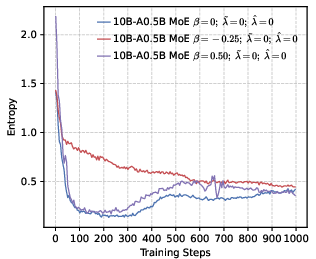
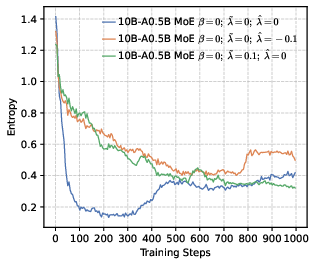
- Precision helps RL more than global diversity. Models trained to be more confident about the correct token (low global entropy) gave a better starting point for RL. Even though it might sound like being more “open” or spread-out helps exploration, their results show the opposite: a precision-first pre-training makes RL exploration more effective.
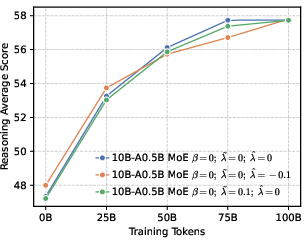
- Local diversity still matters. While pushing for global precision, keeping some probability on top-ranked wrong tokens (local diversity) prevents the model from collapsing too quickly and helps it explore meaningful alternatives during RL.
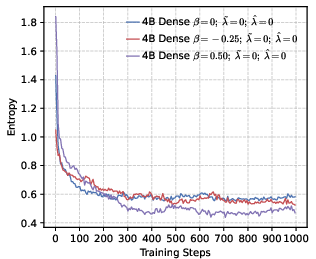
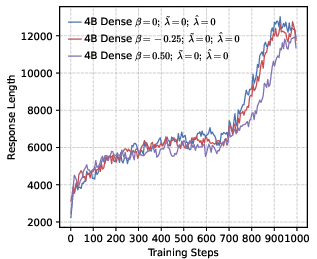
- Stable training and better reasoning. Precision-oriented settings led to smoother RL training, prevented early “entropy collapse” (the model becoming too certain too fast), and supported longer, more thoughtful chain-of-thought answers.
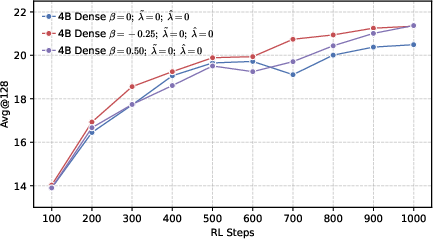
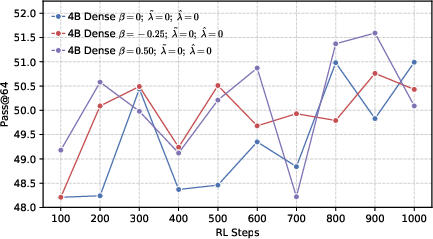
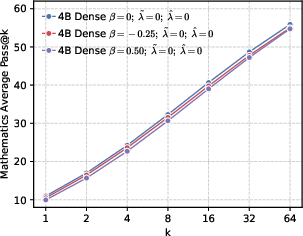
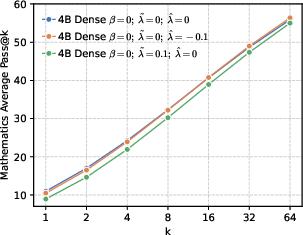
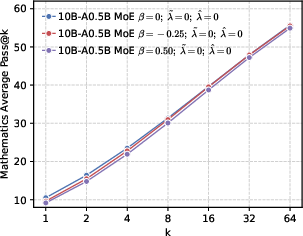
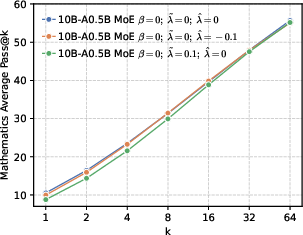
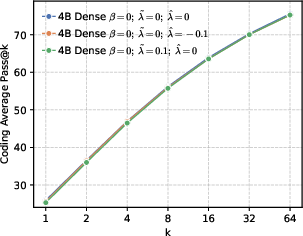
- Better end results in math and code. Precision-first models achieved higher success rates when allowed multiple tries (Pass@k), especially in math and coding tasks, showing they generate more correct solutions overall.
Why this matters: It challenges a common belief that “more diversity is always better for exploration.” Instead, a targeted approach works best—be globally precise about the correct token, but maintain local diversity among top alternatives.
Implications and Impact
This work suggests a new way to pre-train LLMs so they’re better prepared for RL-based improvements in reasoning:
- Design pre-training to be precision-oriented globally, so the model starts with strong, confident guesses about correct tokens.
- Preserve local diversity among the top few alternatives, so the model can still explore nearby options during RL without getting stuck.
- Use reward shaping in pre-training as a tool to set up a better “exploration space” for RL, leading to stronger end-to-end reasoning performance.
In simple terms: if you want an LLM that can reason well after RL, teach it to be confidently right most of the time, but keep it curious about a few close alternatives. This balanced training makes RL more effective and leads to smarter models.
Knowledge Gaps
Below is a single, focused list of the paper’s knowledge gaps, limitations, and open questions that remain unresolved. Each point is concrete to help guide future research.
- Theoretical guarantees are not established for the proposed reward shaping: no analysis of convergence, stability, bias/variance properties of the gradients induced by the positive scaling term and rank-aware negative rewards, nor bounds on gradient magnitudes to prevent explosion or vanishing.
- The “on-policy RL principles” framing remains largely conceptual: pre-training still uses teacher forcing (off-policy data), and the paper does not implement or evaluate true on-policy token sampling during pre-training or quantify its feasibility (e.g., sparse rewards when sampled tokens differ from ground truth).
- Hyperparameter selection for reward shaping is ad hoc: no principled method or adaptive schedule is provided for choosing or annealing β, k, and λ values; sensitivity analyses and task/model-size–dependent tuning guidelines are missing.
- Rank-aware negative shaping is coarse: using a fixed TopK indicator ignores relative ranks and probability magnitudes; alternatives like rank-weighted functions, margin-based shaping, or top-p adaptive sets are not explored or ablated.
- Empirical comparison to established weighted CE variants is absent: although label smoothing and focal loss are discussed theoretically, there are no controlled experiments comparing the proposed method against these baselines across tasks and scales.
- Calibration and confidence are not evaluated: the impact of precision-oriented priors on calibration metrics (e.g., ECE, Brier score), overconfidence, and hallucination rates is unmeasured, despite claims about “precision.”
- Multiple-valid-token settings are unaddressed: the reward equals 1 only for the dataset token, which may penalize legitimate alternatives in open-ended or paraphrastic contexts; effects on generative quality and diversity in non-deterministic next-token scenarios are not studied.
- Domain generality of RL gains is unclear: RL experiments focus primarily on mathematics; there is no evidence the precision-oriented prior improves exploration or end-to-end performance in other RL tasks (code debugging, long-horizon planning, instruction following, preference optimization).
- Mechanistic understanding of “precision prior improves exploration” is missing: there is no causal or theoretical explanation linking initial policy sharpness to better state-space coverage, forking-token behavior, or sample efficiency in RL; exploration is proxied by entropy but not directly measured (e.g., path diversity, solution space coverage).
- Forking-token dynamics are not directly examined: although prior work is cited, the paper does not quantify how the proposed shaping alters entropy and decision uncertainty specifically at pivotal tokens driving reasoning branches.
- Statistical robustness is underreported: results appear to be single runs without multiple seeds, confidence intervals, or significance testing; training variance and reliability across reruns remain unknown.
- Scaling beyond 10B parameters is untested: conclusions may not generalize to larger LLMs (e.g., 30B–70B+), different MoE routing depths, or deployment regimes with stricter compute/latency constraints.
- Data composition confounds are not ablated: the deliberate exclusion of synthetic long-reasoning data may influence conclusions; there is no study on how including such data interacts with reward shaping and RL outcomes.
- RL algorithm dependence is not explored: results are tied to the RLVR setup; it is unknown whether the observed benefits persist under other RL frameworks (e.g., PPO-style policy KL constraints, entropy bonuses, return-to-go baselines, advantage estimators).
- Decoding interaction effects are unexamined: how distribution shaping interacts with decoding strategies (temperature, top-p/top-k, beam search) and impacts Pass@k curves or majority voting consistency is not analyzed.
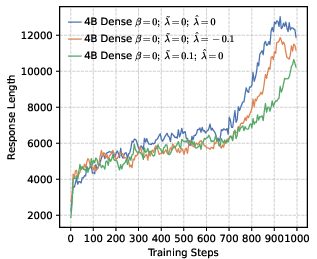
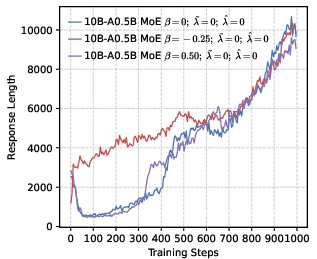
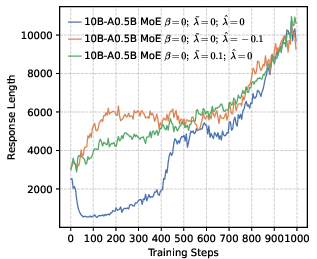
- Response length is used as a proxy for reasoning quality without validation: the paper infers reasoning suppression from shorter outputs, but does not correlate length with correctness or complexity of reasoning steps at the instance level.
- Expert routing and load balancing in MoE are not analyzed: rank-aware negative shaping may alter expert activation patterns; effects on MoE utilization, specialization, and training stability are unreported.
- Tail-token suppression trade-offs are unknown: penalizing low-probability tokens may reduce rare-word usage or harms long-tail knowledge retrieval; the paper does not measure impacts on rare facts or multilingual/vocabulary diversity.
- Compute and sample efficiency are not quantified: the paper does not report training compute budgets, RL sample efficiency (e.g., reward per step, time to target accuracy), or cost-benefit analyses of shaping versus baseline CE.
- Generalization to safety and alignment is not evaluated: the proposed precision-oriented prior might reduce hallucinations or affect toxicity/helpfulness, but there is no assessment on safety, preference alignment, or human judgments.
- Practical guidance for deployment is absent: there are no actionable recommendations on scheduling β/λ/k (e.g., anneal β, context-dependent k), task-adaptive shaping, or criteria for switching between global and local entropy control during different training stages.
- Reproducibility is limited: appendices with detailed hyperparameters and RL settings are referenced but not present here; code, data curation details, and seeds are not provided.
- Pass@k methodology confounds are not isolated: sampling 128 responses with fixed temperature/top-p may interact with prior entropy; the paper does not disentangle improvements due to policy shaping from decoding hyperparameters or sampling budget.
- Token-level, single-step formulation may ignore sequence-level credit assignment: the approach assumes per-token episodes with immediate rewards, but does not address dependencies across tokens or delayed rewards in multi-step reasoning, nor compare against sequence-level objectives.
Glossary
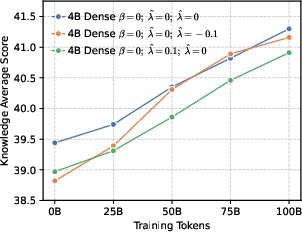
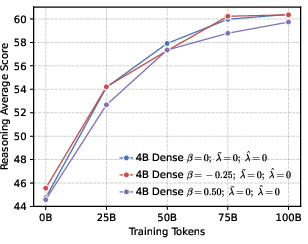
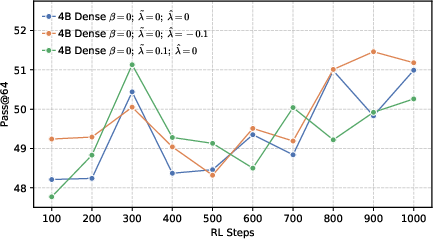
- Actor models: Policy networks used as generators during RL training in actor-critic style pipelines. "Changes of performance during RL training across various actor models, developed based on a 4B dense architecture under different configurations."
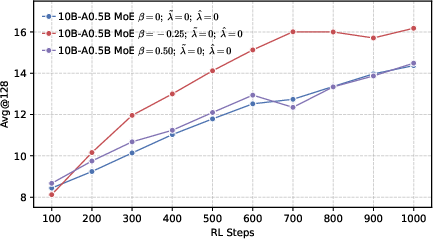
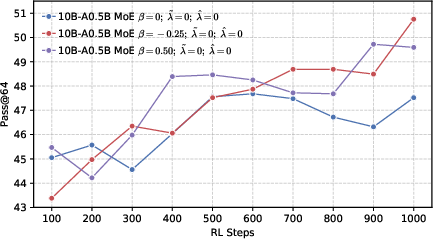
- Avg@128: The average accuracy metric computed across 128 sampled responses per problem. "We sample 128 responses per problem and report 128, 128, and 64 metrics."
- Baseline : A value subtracted from returns to reduce variance in policy gradient estimates without introducing bias. "often incorporating a baseline for variance reduction:"
- Chain-of-thought (CoT): Explicit multi-step reasoning traces generated by LLMs. "to accurately observe the activation trends of the model's long-CoT reasoning capabilities."
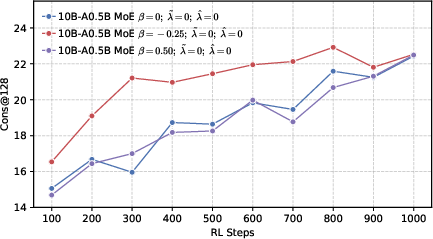
- Cons@128: Majority-vote accuracy across 128 sampled responses, measuring consensus correctness. "while 128 refers to the majority voting accuracy."
- Cross-entropy loss: A supervised objective that maximizes the log-likelihood of ground-truth tokens; here reinterpreted as a single-step policy gradient. "we revisit the standard cross-entropy loss, interpreting it as a specific instance of policy gradient optimization applied within a single-step episode."
- Distribution entropy: The entropy of the model’s token-output distribution characterizing its global diversity. "Contrary to the intuition that higher distribution entropy facilitates effective exploration"
- Entropy collapse: A rapid reduction in policy entropy during training, often harming exploration and reasoning. "setting a higher leads to rapid entropy collapse during the early stages of training."
- Exploration space: The set of behaviors or token choices available to an RL-trained model, shaped by its pre-trained distribution. "the exploration space defined by the pre-trained model's token-output distribution."
- Focal loss: A loss that down-weights easy examples to focus learning on hard ones via a probability-dependent factor. "and focal loss~\citep{lin2018focalloss}, which down-weights easy examples via ."
- Forking tokens: Tokens with high uncertainty that determine branching points in chain-of-thought reasoning. "high-entropy forking tokens that govern pivotal decisions"
- Label smoothing: A technique that allocates small probability mass to non-ground-truth classes to encourage diversity and regularization. "smooth loss (label smoothing), which encourages diversity by allocating a uniform probability mass to all positive tokens"
- Local entropy: The entropy concentrated among a subset of competitive tokens (e.g., top-k), regulating local diversity. "we propose shaping the negative distribution to control local entropy."
- Majority voting accuracy: Accuracy computed by aggregating multiple samples via majority vote. "while 128 refers to the majority voting accuracy."
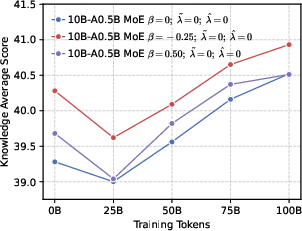
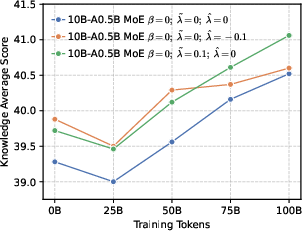
- Mixture-of-Experts (MoE): An architecture that routes inputs to specialized expert sub-networks to improve capacity and efficiency. "we develop LLMs using both dense and MoE architectures."
- Pass@k: The probability that at least one of k independently sampled solutions is correct. "We utilize the unbiased estimator of ~\citep{chen2021passk}, which is defined as:"
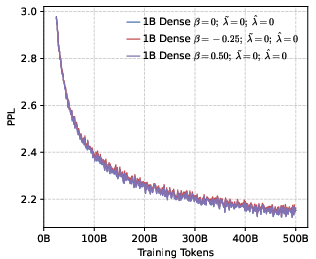
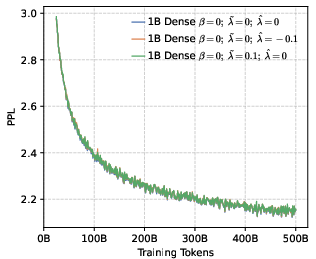
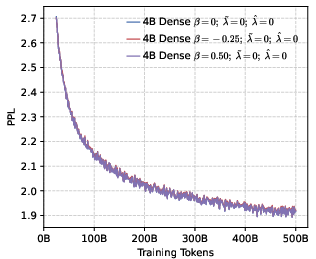
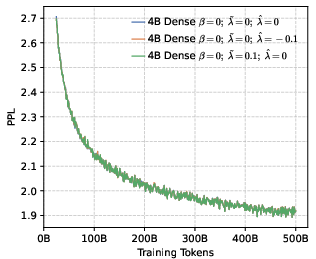
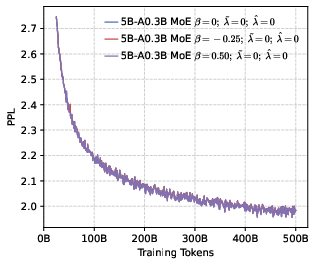
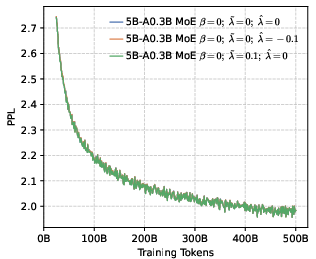
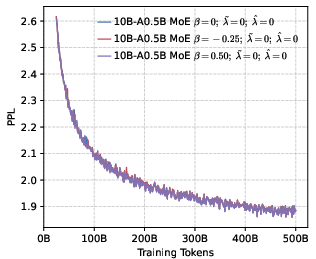
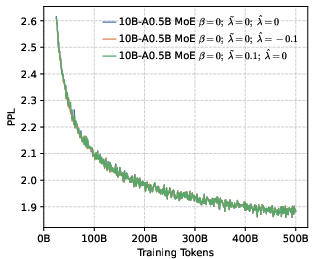
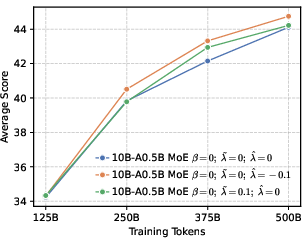
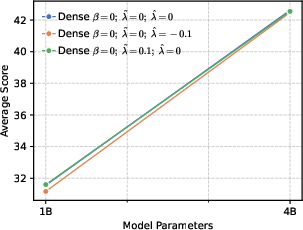
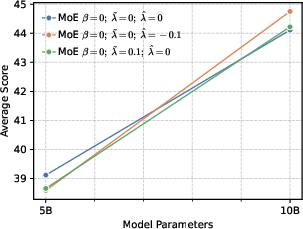
- Perplexity (PPL): A measure of LLM uncertainty; lower values indicate better predictive performance. "perplexity (PPL) consistently converges to comparable low values across both dense (1B, 4B) and MoE (5B-A0.3B, 10B-A0.5B) architectures."
- Policy distribution: The probability distribution over actions (tokens) given a state, defined by . "We can express this gradient as an expectation over the full policy distribution "
- Policy entropy: The entropy of the policy distribution, tracking diversity during RL. "we analyze the evolution of policy entropy and response length throughout the training process"
- Policy gradient: A class of RL algorithms that optimize the expected return by ascending the gradient of policy parameters. "policy gradient optimization applied within a single-step episode."
- Precision-oriented prior: A pre-training bias that concentrates probability mass on correct tokens to favor precise reasoning. "imposing a precision-oriented prior yields a superior exploration space for RL."
- Rank-aware negative suppression: A strategy that treats high- and low-ranking incorrect tokens differently to shape local entropy. "utilizing a positive reward scaling factor and rank-aware negative suppression."
- Reward-shaping strategy: Modifying reward signals to guide policy learning toward desired behavior (e.g., balancing diversity and precision). "we introduce a reward-shaping strategy that explicitly balances diversity and precision."
- Return-to-go: The sum of rewards from the current time step to the end of the episode, used in policy gradient updates. "the return-to-go "
- RLVR: An RL stage (Reinforcement Learning with Verifiable Rewards) focused on tasks with objective correctness signals. "The training pipeline proceeds in three stages: pre-training, mid-training, and RLVR."
- Softmax normalization constraint: The requirement that action probabilities sum to 1 under the softmax, implicitly suppressing negatives when positives are boosted. "Softmax normalization constraint ."
- Stochastic decision process: A formulation where token selection is treated as probabilistic action in an RL framework. "By framing next-token prediction as a stochastic decision process"
- Stochastic policy: A policy that samples actions according to a probability distribution rather than deterministically. "where the LLM functions as a stochastic policy ."
- Stop-gradient operator: An operator that prevents gradients from flowing through its argument during backpropagation. "where denotes the stop-gradient operator."
- Teacher forcing: Training where the model conditions on ground-truth previous tokens rather than its own predictions. "even though standard teacher forcing utilizes off-policy samples drawn directly from the training corpus distribution."
- TopK: A selection of the k highest-probability tokens used to shape negative rewards and local entropy. "Let denote the set of the top- predicted tokens"
- Trajectory: A sequence of states and actions sampled from a policy during an episode. "where represents a trajectory sampled from "
- Unbiased estimator: A statistical estimator whose expected value equals the true parameter, used here for Pass@k. "We utilize the unbiased estimator of "
- Variance reduction: Techniques that lower gradient estimate variance (e.g., baselines) to stabilize RL training. "incorporating a baseline for variance reduction"
- Verifiable rewards: Objective signals of correctness (e.g., tests passed), enabling RL to optimize for factual or mathematical accuracy. "By utilizing verifiable rewards, such as passing unit tests or deriving correct mathematical solutions"
Practical Applications
Immediate Applications
Below are concrete ways the paper’s reward-shaped next-token objective (precision-oriented β for positives; rank-aware Top‑K shaping for negatives) can be used today.
- Drop‑in loss for LLM pretraining and mid‑training
- Sector: Software/AI labs; Academia
- What: Replace standard cross-entropy with the proposed loss (e.g., β≈−0.25 for positives; Top‑K≈100 with tail suppression via or head promotion via ) in existing PyTorch/DeepSpeed/Megatron-LM training pipelines.
- Why: Produces a precision‑oriented output distribution that yields better downstream RL exploration and faster/steadier convergence on reasoning tasks.
- Dependencies/assumptions: Access to large corpora; training code that can compute rank-aware rewards (Top‑K per step); hyperparameter tuning per domain/model size.
- RL warm‑start selection for reasoning-focused products
- Sector: Software (code assistants), Education (math tutors), Finance (quant Q&A), Science/Engineering tools
- What: Use the paper’s entropy diagnostics to choose “precision‑prior” checkpoints (low global entropy, controlled local entropy) as RL starting points for math/coding/planning assistants.
- Why: Improves “Avg@k/Cons@k/Pass@k” curves; reduces RL instability and early entropy collapse.
- Dependencies/assumptions: RL with verifiable rewards (unit tests, math solvers); sufficient compute for multi-sample evaluation.
- Compute- and cost-aware RL pipelines
- Sector: AI infrastructure; Enterprise AI
- What: Adopt precision-oriented pretraining to reduce RL iterations needed to reach target accuracy on verifiable tasks.
- Why: Better exploration space ⇒ fewer RL samples and less wall-clock time per win.
- Dependencies/assumptions: Benefit magnitude is task- and model-size dependent; monitoring needed to ensure no degradation on creative tasks.
- Safer and more calibrated assistants via tail-token suppression
- Sector: Healthcare (clinical QA prototypes), Finance (compliance QA), Enterprise chatbots
- What: Apply negative reward to low-probability tail tokens (Top‑K shaping) during pretraining/mid-training to reduce hallucinations without collapsing plausible alternatives.
- Why: Precision orientation de-emphasizes spurious low-likelihood continuations; improves consistency.
- Dependencies/assumptions: Requires careful balancing so as not to harm necessary local diversity; human evaluation for safety-critical domains.
- Pass@k‑oriented development for coding and math
- Sector: Software development tools; EdTech
- What: Train code/math models with β<0 and local diversity preserved among head tokens (e.g., , ) to maximize Pass@k under multi-sampling workflows.
- Why: Empirically improves Pass@k by combining high precision with targeted local exploration.
- Dependencies/assumptions: Multi-sample inference (temperature/top‑p) and unit-test infrastructure.
- Training dashboards for entropy and rank profiles
- Sector: MLOps/Tooling; Academia
- What: Add global/local entropy tracking, Top‑K mass, and response-length diagnostics to training dashboards to detect entropy collapse and guide β/λ schedules.
- Why: Prevents early collapse that suppresses reasoning; supports principled checkpointing.
- Dependencies/assumptions: Logging infra at token level; negligible overhead for Top‑K stats.
- Domain-adaptive reward shaping
- Sector: Media/Creative vs. Reasoning products
- What: Use precision‑first settings for verifiable reasoning domains; use milder β or positive to preserve creativity/local diversity for open-ended generation (stories, marketing).
- Why: Aligns distribution shape with domain goals (precision vs. diversity).
- Dependencies/assumptions: Clear task taxonomy; evaluation suites aligned with domain outcomes.
- Curriculum schedules for precision/diversity across stages
- Sector: AI labs; Enterprise model training
- What: Start pretraining with modest β (or λ) then move toward β<0 and tail suppression near mid-training before RL.
- Why: Maintains broad coverage early while preparing a precision‑oriented prior for RL.
- Dependencies/assumptions: Scheduling and validation infrastructure; ablations per data mixture.
- Procurement and benchmarking checklists
- Sector: Policy/Compliance offices in enterprises and public agencies
- What: Include “report entropy-shaping approach and Pass@k curves” in vendor evaluations for reasoning models.
- Why: Ties model selection to measurable reasoning robustness and exploration quality.
- Dependencies/assumptions: Vendors provide transparent training reports; standardized metrics available.
- Lightweight research prototyping
- Sector: Academia; Startups
- What: Test β and Top‑K λ on 1B–10B models to replicate trends inexpensively before scaling.
- Why: Findings were demonstrated at these scales; reduces risk before large-scale runs.
- Dependencies/assumptions: May not linearly transfer to ≥70B models; requires careful extrapolation.
Long-Term Applications
These applications need further research, scale-up, or ecosystem development before wide deployment.
- Precision‑first foundation models for high‑stakes domains
- Sector: Healthcare, Legal, Finance, Government services
- What: Train large (≥70B) models with precision-oriented pretraining priors and tailored local diversity, then RL with verifiable rewards (clinical guidelines, statutes, regs).
- Why: Better exploration and convergence in correctness-critical reasoning.
- Dependencies/assumptions: High-quality verifiable reward signals; rigorous domain audits and regulatory approval.
- Standardized “reward‑shaped pretraining” frameworks
- Sector: AI toolchains; Open-source communities
- What: Toolkits that expose β/λ schedules, Top‑K strategies, entropy monitors, and auto-tuners across PyTorch/JAX ecosystems.
- Why: Makes the method accessible and reproducible across organizations.
- Dependencies/assumptions: Community benchmarks and best-practice defaults; interoperability with DeepSpeed/Megatron/Alpa.
- AutoLoss/AutoRL controllers that adapt entropy on-the-fly
- Sector: AI infrastructure
- What: Controllers that adjust β, , by monitoring entropy, Pass@k, and RL variance in real time.
- Why: Minimizes manual tuning; maintains optimal exploration across stages.
- Dependencies/assumptions: Reliable online metrics; stable control loops to avoid oscillations.
- Energy- and carbon-aware training policies
- Sector: Sustainability; Cloud platforms; Policy
- What: Adopt precision‑prior pretraining as a norm to reduce RL compute budgets, with reporting of energy savings and accuracy targets.
- Why: Potentially fewer RL iterations for the same accuracy; lower emissions.
- Dependencies/assumptions: Validation of savings at frontier scales; standardized accounting.
- Robust planning agents for robotics and operations
- Sector: Robotics; Logistics; Manufacturing
- What: Use precision-oriented base distributions with local exploration for plan token emissions, then RL with verifiable simulators.
- Why: Reduces invalid-plan exploration while keeping plausible alternatives.
- Dependencies/assumptions: High-fidelity simulators and reward checkers; transfer from text tokens to action tokens.
- Regulatory guidance for LLM development
- Sector: Policy/Governance
- What: Guidelines encouraging precision-oriented pretraining (with documented local diversity) for models deployed in safety-critical contexts.
- Why: Aligns training practices with harm-reduction goals (fewer hallucinations).
- Dependencies/assumptions: Evidence at scale that precision priors correlate with safety gains; consensus on metrics.
- Sector-specific verifiable reward pipelines
- Sector: Education (grading), Software (CI/unit tests), Finance (financial math), Science (computational proofs)
- What: Build domain test suites to power RL that capitalize on precision‑prior base models.
- Why: Expands RLVR applicability beyond math/coding to broader reasoning tasks.
- Dependencies/assumptions: Creation and maintenance of high-coverage, low-noise verifiers.
- Integration with latent reasoning and adaptive computation
- Sector: Advanced AI R&D
- What: Combine token-level reward shaping with models that iterate internally before emission (loop/latent reasoning), allocating more compute to high-uncertainty states.
- Why: Harmonizes distribution shaping with compute allocation for complex reasoning.
- Dependencies/assumptions: Stable loop architectures; uncertainty estimators.
- Safety hardening via structured tail suppression
- Sector: Trust & Safety
- What: Couple tail-token penalties with red-team datasets and policy constraints to reduce jailbreaks and unsafe continuations during training.
- Why: Suppresses low-likelihood, risky generations while preserving legitimate alternatives.
- Dependencies/assumptions: Adversarial data and detectors; careful tuning to avoid over-suppression.
- Cross-modal precision-oriented pretraining
- Sector: Multimodal AI (vision-language, speech)
- What: Extend β/Top‑K shaping to tokenized vision/speech outputs where verifiable intermediate rewards exist (e.g., OCR with checksums, program-of-thought in VLMs).
- Why: Potentially improves multimodal reasoning and tool-use.
- Dependencies/assumptions: Effective multimodal tokenization and verifiers; compute scalability.
Key Assumptions and Dependencies Across Applications
- Verifiable rewards are available (unit tests, math solvers, curated graders); benefits are strongest where correctness is objectively checkable.
- Findings are shown on 1B–10B dense/MoE models; validation is needed at larger (≥70B) scales and across more domains (e.g., open-ended creative tasks).
- β/λ hyperparameters are data- and task-dependent; misconfiguration can cause mode collapse or loss of creativity.
- Top‑K computation and token-rank logging incur overhead but are typically manageable relative to training cost.
- Precision orientation may trade off with creative diversity; for creative sectors, preserve local diversity (e.g., mild ) and avoid overly negative β.
Collections
Sign up for free to add this paper to one or more collections.