How Reinforcement Learning After Next-Token Prediction Facilitates Learning
Abstract: Recent advances in reasoning domains with neural networks have primarily been enabled by a training recipe that optimizes LLMs, previously trained to predict the next-token in a sequence, with reinforcement learning algorithms. We introduce a framework to study the success of this paradigm, and we theoretically expose the optimization mechanisms by which reinforcement learning improves over next-token prediction in this setting. We study learning from mixture distributions of short and long ``chain-of-thought'' sequences encoding a single task. In particular, when the task consists of predicting the parity of $d$ bits and long sequences are rare, we show how reinforcement learning after next-token prediction enables autoregressive transformers to generalize, whereas mere next-token prediction requires extreme statistical or computational resources to do so. We further explain how reinforcement learning leverages increased test-time computation, manifested in longer responses, to facilitate this learning process. In a simplified setting, we theoretically prove that autoregressive linear models following this training recipe can efficiently learn to predict the parity of $d$ bits as long as the proportion of long demonstrations in the data mix is not exponentially small in the input dimension $d$. Finally, we demonstrate these same phenomena in other settings, including the post-training of Llama-series models on mixture variations of common mathematical reasoning benchmarks.
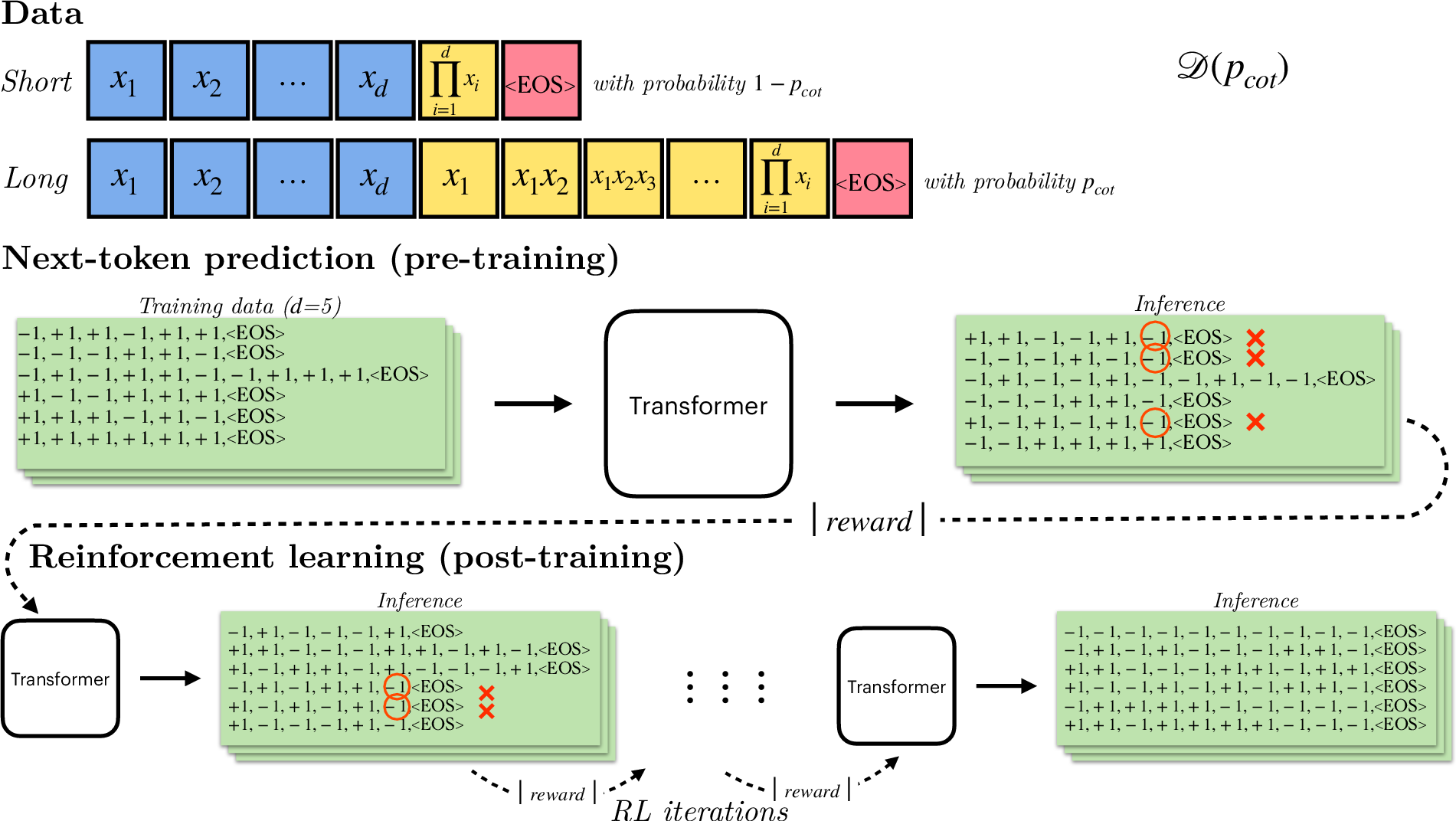
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-English Summary of the Paper
What is this paper about?
This paper asks a simple question: why do LLMs get much better at tricky reasoning problems after a short “reinforcement learning” (RL) step, even when they were already trained to predict the next word?
The authors build a clear, testable explanation. They show that:
- Pre-training (next-token prediction) struggles to learn some reasoning tasks when the training data mostly show short answers.
- Adding RL afterward acts like a smart “guess-and-check” phase that quickly pushes the model to produce longer, step-by-step answers—and that’s what unlocks strong performance.
They explain this with theory, small controlled experiments (like computing parity and multiplication), and tests on real math benchmarks using Llama models.
The Big Questions the Paper Tries to Answer
- Why does pre-training alone fail on some reasoning tasks, even with many examples?
- How does RL after pre-training make models suddenly improve?
- Why do models start giving longer answers after RL—and how does that help?
- Can we prove these effects in a simple, understandable setup?
- Do these patterns show up in real tasks (like school math problems), not just toy examples?
How They Studied It (In Everyday Terms)
The core idea: “short answers” vs “long explanations”
Imagine teaching math with two types of examples:
- Short: you see the question and the final answer only.
- Long: you see the question plus a full, step-by-step solution (a “chain of thought”).
The training data is a mix of these two. Let’s call the fraction of long examples p_long (also written as p_cot in the paper).
The simple test task: parity
Parity means: is the number of 1s in a list even or odd? It’s like checking whether there’s an even or odd count—surprisingly tricky for many learning algorithms if they only see “question → short answer.”
- When the data mostly have short answers, the model struggles to learn parity from scratch.
- When the data include enough long, step-by-step explanations, the model can learn the pattern more easily.
Two training phases
- Pre-training: The model learns to predict the next token by copying patterns from the mixed data (short and long).
- Post-training (RL): The model generates answers, gets a reward for correct ones, and then gets nudged to produce more of the kinds of answers that earned rewards. This is “guess-and-check.”
Think of RL as a teacher who says, “That solution was correct—more like that!” and the model starts favoring the styles that tend to be correct.
A helpful analogy for decoding
- Greedy decoding: always pick the most likely next word (like always choosing your top guess).
- Sampling with temperature: add a bit of randomness to explore other reasonable options.
A simple theoretical model
The authors also analyze an easy-to-understand “linear autoregressive model” (a stripped-down setup) to prove the same effects:
- With too few long examples, pre-training alone won’t generalize when using greedy decoding.
- RL boosts the share of long, correct solutions round by round, making success fast and reliable.
What They Found (and Why It Matters)
1) Pre-training learns “what’s frequent,” not “what’s best”
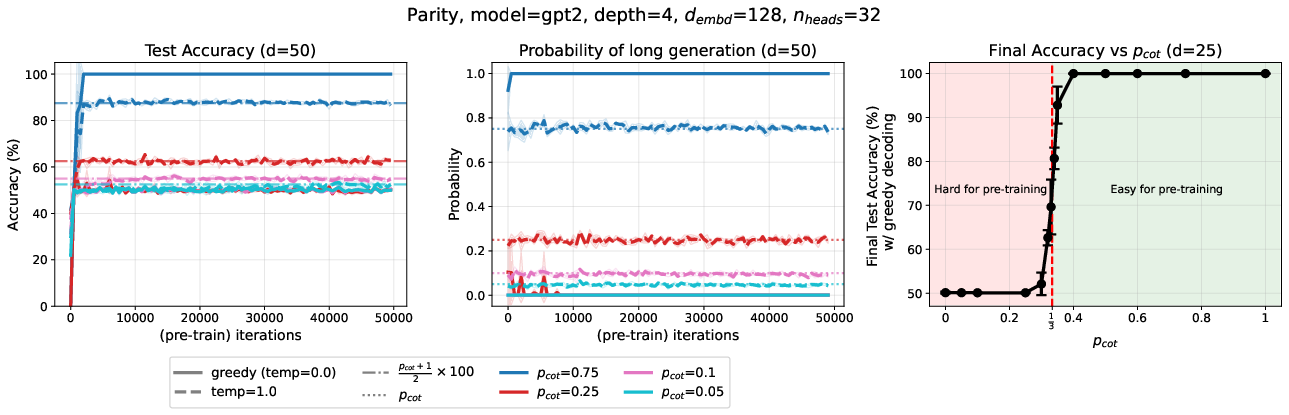
- During pre-training, the model becomes “length-calibrated”: it produces long answers about as often as it saw them in the training data.
- If long explanations are rare (less than about one-third of the time), the model’s greedy (top-choice) answers tend to be short—and wrong on hard tasks like parity.
- Even huge amounts of data don’t fix this quickly. It’s a sample-efficiency problem, not a “model too small” problem.
Why this matters: Just feeding more short Q→A pairs isn’t enough for strong reasoning. You need enough worked-out examples.
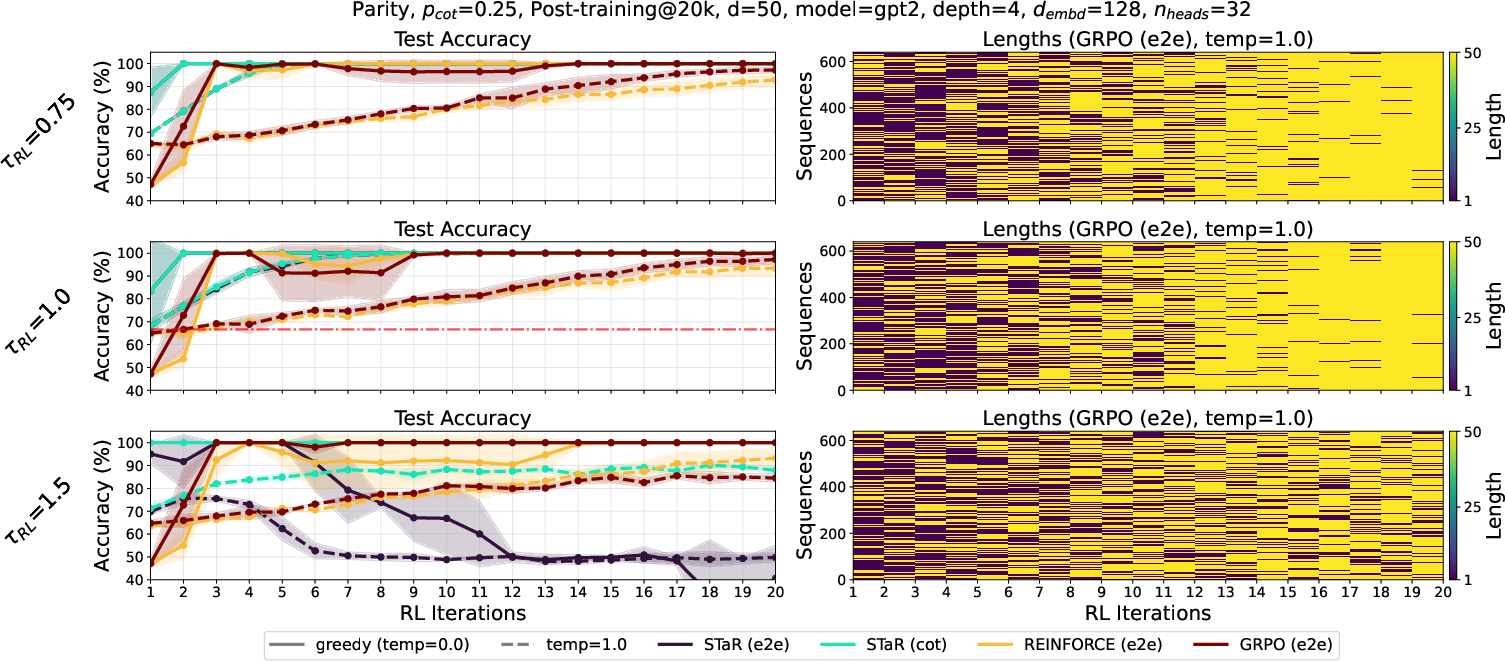
2) RL makes the model “think longer” and gets big gains fast
- In RL, only correct solutions are rewarded. Long solutions are much more likely to be correct on hard tasks.
- So the model quickly learns to produce more long, step-by-step answers. That boosts accuracy, often in just a small number of RL rounds.
- In theory, the “advantage” of long answers doubles each round, so the number of RL rounds needed grows slowly (like the number of times you can double before passing a threshold).
Why this matters: RL acts like a focused booster that turns “some ability under randomness” into “reliable ability under greedy decoding.”
3) A clear threshold: “about one-third”
- If fewer than about 1 in 3 training examples include long explanations, greedy decoding after pre-training alone fails on parity.
- RL crosses that gap by amplifying long, correct solutions until the model confidently generates them even with greedy decoding.
4) It’s not just parity
The same pattern appears in:
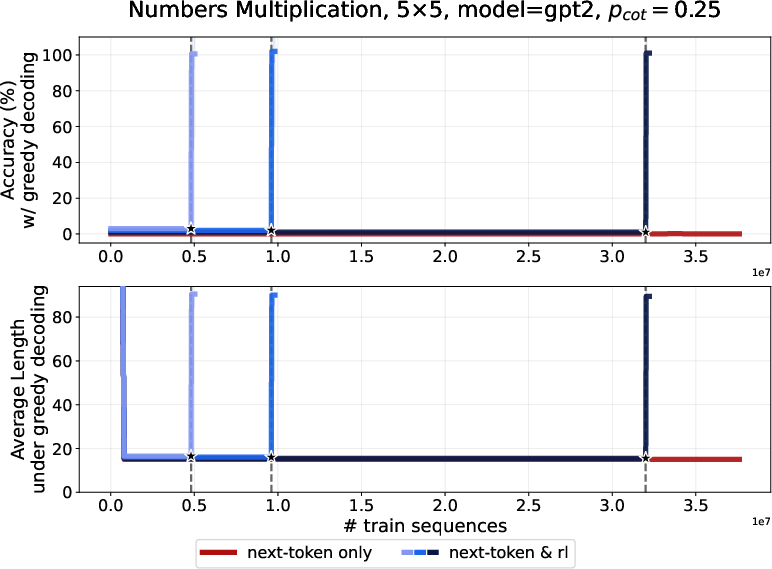
- Multiplication of multi-digit numbers: pre-training struggles with mostly short answers, but RL rapidly improves accuracy and increases solution length.
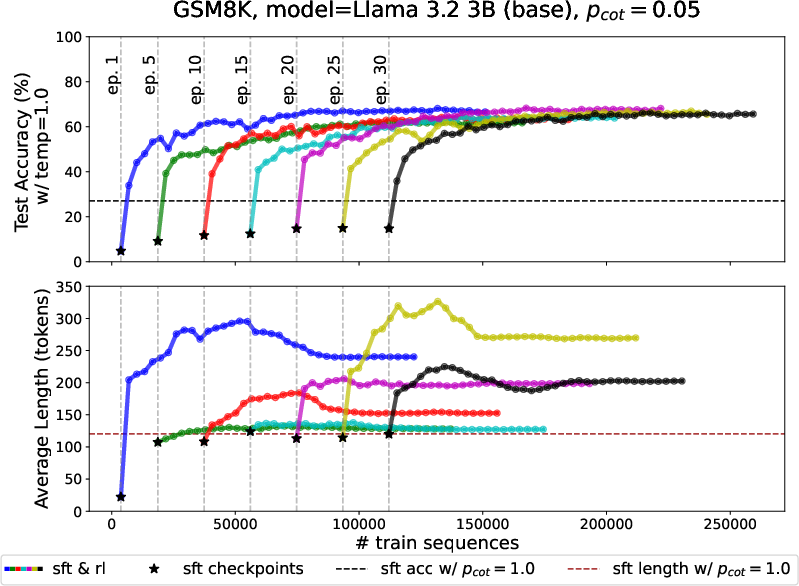
- Real math benchmarks (GSM8K, MATH) with Llama models: supervised fine-tuning on mixed short/long data plateaus below the “all long” baseline; a short RL phase catches up quickly and makes outputs longer and more accurate.
Why this matters: The mechanism is general—it shows up in practical reasoning tasks, not only in toy problems.
Why This Matters for the Future
- Training recipe insight: To build strong reasoning models, include some full, step-by-step demonstrations in the data—even if they’re a minority—and then run a short RL phase. This is efficient and effective.
- Explaining modern “thinking” LLMs: The paper clarifies why RL-trained models often produce longer answers. Longer answers aren’t just fluff—they’re how the model “does the work” to be correct.
- Smarter use of compute: Letting the model “think longer” at test time (produce longer chains of thought) can be crucial for hard problems.
- Theory meets practice: The authors prove a separation between “pre-training only” and “pre-training + RL,” and then show it in real models, bridging the gap between math and engineering.
Key Ideas in Simple Terms
- Chain of thought: a worked-out solution, step by step.
- Length calibration: after pre-training, the model outputs long answers about as often as it saw them in training.
- Greedy decoding: always pick the most likely next token—no randomness.
- Reinforcement learning (RL): guess-and-check training that rewards correct outputs and steers the model to produce more of what works.
- Main takeaway: Pre-training teaches the model to imitate what it sees; RL teaches it to prefer what’s correct. That preference makes the model produce longer, more reliable reasoning.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list captures what remains missing, uncertain, or unexplored, framed to be actionable for future research:
- Extend the theoretical separation (next-token prediction vs next-token prediction + RL) from linear autoregressive models to nonlinear architectures with self-attention (e.g., transformers), including conditions under which a similar length-threshold phenomenon arises.
- Characterize the critical threshold on the proportion of long demonstrations (p_cot) for real transformers: derive when greedy decoding switches from short to long responses, and how this threshold depends on architecture depth, width, attention pattern, and loss choice.
- Provide a rigorous analysis of GRPO and REINFORCE in this setting (beyond STaR), showing how and why they amplify long generations and under what hyperparameter regimes RL remains stable.
- Develop diagnostics and principled criteria for when to switch from pre-training to RL (e.g., based on length calibration, temperature-1 accuracy, entropy, or logit margins), and quantify the minimal pre-training progress required for RL to succeed.
- Systematically study the role of sampling temperature during RL and pre-training, including stability regions, variance reduction, and the interaction with chain-of-thought vs end-to-end rewards.
- Evaluate robustness to noisy, partial, or incorrect chain-of-thought demonstrations: quantify how RL amplifies or suppresses errors in long sequences and design reward functions or filters that resist reward hacking via spurious but long outputs.
- Measure compute–performance trade-offs: quantify test-time compute growth (due to longer responses) versus accuracy gains, and develop methods to allocate or cap test-time compute while preserving performance (e.g., adaptive length control, length-aware rewards).
- Provide causal evidence that length increase is the mechanism enabling generalization: run ablations that (i) enforce longer generations without RL, (ii) penalize length during RL, and (iii) manipulate response length independently to test accuracy changes.
- Investigate generalization under distribution shift: when training uses a long/short mixture but deployment prompts elicit primarily short responses, does performance degrade, and can RL mitigate this?
- Analyze scaling laws: replicate the phenomena across model sizes (from small GPT-2-like models to 8B/70B-scale LLMs) and quantify how the required p_cot and sample complexity change with scale.
- Explore tasks of greater computational depth beyond parity and digit multiplication (e.g., multi-step symbolic reasoning, theorem proving, code synthesis), where verifying the full chain-of-thought is infeasible; design proxies or learned verifiers and test whether RL still amplifies useful long reasoning.
- Study positional encoding and input formatting effects (e.g., reversed digits vs natural order in multiplication) on both pre-training and RL outcomes; determine whether the mechanism holds without such formatting tricks.
- Identify the failure region observed in more challenging multiplication settings (e.g., 7×7 with p_cot=0.1): isolate whether failure is due to insufficient pre-training progress, model capacity, optimization instability, or reward signal sparsity.
- Quantify the sample and compute cost of RL relative to pre-training (including fair comparisons across batch sizes and numbers of generations per prompt), and establish where RL yields net efficiency gains.
- Examine decoding strategies beyond greedy and temperature-1 sampling (e.g., beam search, self-consistency, tree-of-thought sampling) and their interaction with RL training on length and accuracy.
- Test robustness and safety implications of encouraging longer outputs: measure hallucination rates, off-task verbosity, susceptibility to jailbreaks, and design safeguards (format constraints, content filters) compatible with the proposed training.
- Analyze interference across tasks when applying RL post-training: does length amplification for reasoning degrade performance on other skills (e.g., concise instruction following), and can multi-objective rewards balance this?
- Study context window constraints: when RL increases response length near window limits, does accuracy degrade due to truncation or memory bottlenecks, and can models learn to allocate compute efficiently across steps?
- Generalize beyond two-component mixtures (short vs long): characterize learning dynamics for mixtures with variable-length partial chains-of-thought and derive how thresholds and calibration evolve with richer length distributions.
- Develop reward functions that balance correctness with brevity (e.g., minimal sufficient reasoning), and test whether models can learn to produce the shortest correct chain-of-thought without sacrificing accuracy.
- Formalize the impact of proper scoring rules (e.g., logistic loss) on length calibration for transformers (not just linear models), including when calibration fails or becomes biased under architectural or optimization choices.
- Replace oracle correctness checks with realistic reward sources (e.g., programmatic graders, preference models, or weak verifiers), and assess whether the RL length-amplification mechanism persists under noisy or learned rewards.
- Investigate multi-sample training and inference: quantify how many generations per prompt are needed during RL to achieve the observed gains, and how self-consistency or majority voting interacts with length growth.
- Provide out-of-distribution generalization tests (e.g., longer input sequences than seen in training, different formatting, novel problem types) to validate whether the mechanism scales and remains robust beyond the curated datasets.
Practical Applications
Immediate Applications
Below are concrete ways to apply the paper’s insights today, organized by sector and accompanied by key assumptions/dependencies.
- Fine-tune reasoning models with RL after next-token prediction on “mixture-of-length” datasets (software/AI, education)
- What: Build training sets where a small fraction of samples include full chain-of-thought (CoT) traces, then switch from SFT/NTP to RL (e.g., GRPO, REINFORCE, STaR) with correctness-based rewards.
- Why: RL reweights the on-policy data toward long, correct responses, rapidly improving generalization even when long traces are relatively rare.
- Tools/workflow:
- Data: Create “short+long” mixes with p_cot ≥ 5–25% (domain-dependent).
- RL: Use correctness rewards (final answer, format compliance) and optional CoT validators when feasible (e.g., unit tests for code, step-checkers for math).
- Monitoring: Track accuracy under greedy vs. sampling, and the response-length distribution.
- Assumptions/dependencies: Availability of some correct long CoT traces; implementable reward function; compute budget for longer responses; begin RL after the model has learned to exploit long traces (early RL can underperform).
- Deploy dynamic test-time compute policies that selectively “think longer” (software/AI, consumer apps)
- What: Implement a two-stage decoding policy: try fast/short inference first; if uncertain or incorrect, escalate to longer CoT generation or temperature-1 sampling.
- Why: The paper shows gains come from increased test-time computation (longer responses), and that sampling can reveal learned long answers even when greedy fails.
- Tools/workflow: Confidence thresholds, reranking multiple sampled chains, “step budget” escalations, length-aware stop criteria.
- Assumptions/dependencies: Calibrated uncertainty signals; cost controls for token usage; UX to hide/show CoT as needed.
- Create domain-specific reward functions and validators to safely drive longer, correct chains (education, software, code, math)
- What: Use auto-graders and checkers as rewards (final-answer exact match; unit tests for code; proof/derivation format checks).
- Why: Reliable rewards accelerate the length-amplification mechanism in RL and stabilize learning.
- Tools/workflow:
- Math: Step-by-step arithmetic/verifier for intermediate steps.
- Code: Unit tests; fuzz tests; lints.
- Structured tasks: Schema/format validators.
- Assumptions/dependencies: High-precision validators; well-defined correctness criteria; guardrails against reward hacking.
- Build “Reasoning SFT→RL” pipelines for internal enterprise tasks (finance, legal ops, analytics)
- What: Fine-tune internal models with a minority of curated long exemplars and correctness rewards to improve auditability and robustness on complex queries.
- Why: RL dramatically reduces the sample complexity required for generalization once some long traces exist.
- Tools/workflow:
- Data curation: Short/long mixes with governance.
- RL ops: On-policy sampling, reward scoring, checkpointing, length monitoring.
- Assumptions/dependencies: Access to proprietary ground-truth checkers; privacy-preserving handling of CoT; compliance with data governance.
- Tutor and grading assistants that show work reliably (education)
- What: Fine-tune math and science tutors to produce consistent, correct chain-of-thought and final answers; use RL on mixture datasets to reach baseline CoT accuracy quickly.
- Why: The paper demonstrates rapid improvements on GSM8K/MATH with RL after SFT, including length increases that track better solutions.
- Tools/workflow: Student-facing mode that hides or reveals CoT; teacher-facing grading with CoT validation.
- Assumptions/dependencies: Rubrics or ground-truth solutions; policies for when to display or conceal CoT.
- Operational guidance for when to switch from SFT to RL (software/AI MLOps)
- What: Introduce a “readiness” criterion (e.g., temperature-1 accuracy or probability of long correct generations) before switching to RL.
- Why: Starting RL too early may increase length without improving greedy accuracy; the paper observes success when pretraining has already learned from long traces.
- Tools/workflow: Track temperature-1 accuracy approaching (1 + p_cot)/2 and/or long-output success rate crossing a target; then begin RL.
- Assumptions/dependencies: Continuous evaluation pipelines; sufficient pretraining signal from long examples.
- Evaluation and governance updates that monitor length-accuracy trade-offs (policy, industry standards)
- What: Standardize metrics for accuracy under greedy vs. sampling, distribution of response lengths, and “hitting time” to long outputs during RL.
- Why: The mechanism of improvement is length amplification; without tracking length, performance claims can be misleading.
- Tools/workflow: Add length histograms, calibration checks, and cost-per-accuracy dashboards to model cards and audits.
- Assumptions/dependencies: Agreement on reporting templates; inclusion in internal governance and external disclosures.
- Cost-aware deployment that balances accuracy gains with longer outputs (industry, consumer apps)
- What: Apply gentle length penalties or budgeted step caps only after the model reliably reaches correct long responses; avoid early penalties that stunt learning.
- Why: The paper shows length penalties can be counterproductive if applied before the model learns to benefit from long reasoning.
- Tools/workflow: Dynamic pricing for “extended reasoning” mode; per-query budgets with fallback plans.
- Assumptions/dependencies: Token cost management; acceptance of longer latency for hard queries.
- “Private CoT” presentation patterns (policy, safety, compliance)
- What: Generate chain-of-thought internally for correctness, but only display short, human-readable rationales or final answers externally.
- Why: Many domains discourage exposing full CoT for privacy or risk reasons; the paper’s mechanism relies on long internal computation, not necessarily public display.
- Tools/workflow: Dual-channel generation (hidden scratchpad + public answer), redactors, audit logs.
- Assumptions/dependencies: UI support; organizational policies for handling sensitive rationales.
Long-Term Applications
These opportunities require further research, scaling, or development to reach production-grade reliability.
- Domain-verified reasoning systems for high-stakes decisions (healthcare, finance, energy, robotics)
- What: Use correctness-verifiable reward functions (clinical guideline checks, risk rules, control constraints) to train models that reliably “think longer” only when needed.
- Why: The RL amplification mechanism can preferentially select long, correct plans; adding domain verification can make this safe and reliable.
- Tools/products:
- Healthcare: Clinical decision support with guideline verifiers and hidden CoT.
- Finance: Risk/explainability engines that produce auditable step-by-step analyses.
- Energy/Robotics: Long-horizon planners trained with environment rewards and plan validators.
- Assumptions/dependencies: High-quality verifiers; robust reward design; regulatory approvals; strong safety evaluations.
- Data markets and standards for rationale-bearing datasets (industry, academia, policy)
- What: Establish shared formats and licensing for high-quality long CoT traces across domains, along with metadata about p_cot and validation quality.
- Why: Even small fractions of long demonstrations dramatically reduce sample complexity under RL; standardized supply can accelerate progress.
- Tools/products: Rationale repositories; p_cot-aware curation toolchains; provenance tracking.
- Assumptions/dependencies: IP/licensing clarity; privacy-preserving curation; incentives for sharing.
- Adaptive compute allocators that optimize “thinking time” per query (software/AI infrastructure)
- What: Scheduling systems that allocate test-time compute based on uncertainty, estimated benefit of longer chains, and cost constraints.
- Why: The paper formalizes how length increases drive accuracy; production systems need optimal policies that manage cost-latency-accuracy trade-offs.
- Tools/products: Confidence-and-compute controllers; “hitting time” estimators for when the model will switch to long outputs; RL policies for compute allocation.
- Assumptions/dependencies: Reliable uncertainty estimates; telemetry; service-level objectives.
- RL algorithms and theory for extremely sparse long-trace regimes (research)
- What: Methods that remain stable and effective when p_cot is very small (e.g., self-bootstrapping with STaR-like methods, synthetic rationales, or stronger reward models).
- Why: The paper proves efficiency when long traces aren’t exponentially rare; pushing further expands applicability in low-resource domains.
- Tools/workflow: Self-augmentation, consistency checks, weak-to-strong supervision for rewards.
- Assumptions/dependencies: Containment of reward hacking; careful evaluation of hallucinated rationales.
- Length-aware multi-objective RL that balances accuracy, cost, and safety (software/AI, safety)
- What: Directly optimize for a Pareto frontier (final-answer correctness, minimal necessary length, adherence to safety constraints).
- Why: Unconstrained length can be costly; multi-objective RL can formalize trade-offs and prevent overlong or unsafe outputs.
- Tools/products: Scalable multi-objective GRPO/REINFORCE variants; safety classifiers; reward shaping libraries.
- Assumptions/dependencies: Reliable safety metrics; robust optimization against gaming.
- Regulatory guidance on chain-of-thought generation and storage (policy)
- What: Frameworks governing when CoT may be stored, displayed, or required for audit; best practices for “hidden CoT” vs. public summaries.
- Why: Longer internal chains can improve correctness but risk privacy leaks or over-interpretation by end users.
- Tools/workflow: Model cards with length/accuracy disclosures; CoT handling policies; audit mechanisms.
- Assumptions/dependencies: Sector-specific compliance needs; consensus on transparency vs. privacy trade-offs.
- Education platforms with adaptive reasoning depth (education technology)
- What: Systems that tailor the amount of shown reasoning to student needs and task difficulty, using RL to master complex solution chains while controlling verbosity.
- Why: The mechanism supports better learning of multi-step tasks; adaptivity can improve student outcomes and reduce cognitive overload.
- Tools/products: Tutors that toggle between hints, partial derivations, and full CoT; auto-grading with rationale checks.
- Assumptions/dependencies: High-quality labeled problems; careful UX design; academic integrity policies.
- Reasoning RL Ops as a first-class MLOps discipline (industry)
- What: End-to-end pipelines for on-policy data generation, reward evaluation, length monitoring, and “p_n scheduler” controls to reach target long-output rates safely.
- Why: The paper highlights operational levers (sampling temperature, RL start time, length monitoring) critical to success.
- Tools/products: Dashboards tracking (accuracy_greedy, accuracy_sampling, length distribution); automated curriculum switches; regression tests for reward models.
- Assumptions/dependencies: Cross-functional teams (data, infra, safety); continuous evaluation; incident response for reward failures.
- Extending the theory and benchmarks beyond parity/multiplication (research, eval)
- What: New mixture-of-length benchmarks in logic, code synthesis, theorem proving, and planning; theoretical analyses that capture deeper compositional tasks.
- Why: Demonstrating the same mechanisms in complex domains strengthens confidence and guidance for model design and policy.
- Tools/workflow: Public benchmark suites with explicit p_cot controls and step verifiers.
- Assumptions/dependencies: Community adoption; open baselines; shared evaluation resources.
Notes on Assumptions and Dependencies
- Data: Some non-negligible fraction of correct long demonstrations (p_cot not exponentially small). Quality of rationales matters.
- Rewards: Domain-appropriate, high-precision reward functions (final-answer correctness, step validators, format checks). Mitigate reward hacking and sparsity.
- Training stability: Switch to RL after the model shows signs of learning from long traces (e.g., temperature-1 accuracy and long-output probability above thresholds).
- Inference cost: Longer outputs increase latency and token spend; deploy cost-aware policies and potential length penalties only after competence is established.
- Safety and privacy: Prefer hidden CoT for sensitive domains; adopt governance for rationale generation, storage, and display.
- Evaluation: Always report accuracy under greedy and sampling, plus response-length distributions; monitor the evolution of long-output probabilities during RL.
Glossary
- Autoregressive linear models: Sequence models whose components are linear predictors generating each token conditioned on previous tokens. "we theoretically prove that autoregressive linear models following this training recipe can efficiently learn to predict the parity of bits"
- Autoregressive transformers: Transformer-based sequence models that generate text token-by-token conditioned on prior tokens. "enables autoregressive transformers to generalize"
- Bernoulli random variable: A binary random variable that takes value 1 with probability p and 0 with probability 1−p. "We denote a Bernoulli random variable with parameter as "
- Chain-of-thought: An explicit sequence of intermediate reasoning steps leading to an answer. "long “chain-of-thought” sequences encoding a single task"
- Chain-of-thought correctness: A reward signal that evaluates whether the entire reasoning sequence (including intermediate steps) is valid. "Chain-of-thought correctness: The reward function assesses whether the whole sequence is valid:"
- Decoder-only transformer: A transformer architecture consisting solely of decoder blocks, used for autoregressive generation. "we train decoder-only autoregressive, transformers"
- End-of-sequence token: A special token indicating the end of a generated sequence. "where is a special symbol denoting the end of a string"
- End-to-end correctness: A reward signal that evaluates whether the final answer token is correct, irrespective of the reasoning steps. "End-to-end correctness: The reward function assesses whether the last token is equal to the correct answer:"
- Feature map: A transformation that augments inputs into a higher-dimensional representation (e.g., adding monomials) to enable linear separability. "where is a feature map that augments the input with all second-degree monomials involving the last input bit"
- Greedy decoding: A generation strategy that repeatedly selects the highest-probability token at each step without sampling. "Test accuracy under greedy decoding."
- GRPO: A reinforcement learning algorithm for optimizing model generations via group relative preference optimization. "followed by GRPO (with a final token accuracy reward)"
- Hypothesis class: The set of functions (models) considered during learning, often parameterized by weights and architectures. "we consider a linear hypothesis class = $\left\{ \mathbf{x} \mapsto {\mathbf{w}_1}{\mathbf{x} \right\}$"
- Kleene star: A formal language operator denoting zero or more concatenations of elements from a set. "The notation denotes a finite concatenation of elements of to produce sequence (Kleene star)."
- L2 regularization: A penalty term on the squared norms of parameters to improve generalization and ensure strong convexity. "with an additional regularization term"
- Length calibration: The model’s learned alignment between the probabilities of generating short vs. long responses and their frequencies in data. "The model’s length calibration at the end of pre-training arises from the use of the logistic loss, which is a proper loss"
- Logits: The unnormalized scores output by a model before applying a softmax or sigmoid for probabilities. "greedy decoding from the model logits"
- Logistic loss: A convex loss used for binary classification that relates logits to probabilities via the sigmoid function. "arises from the use of the logistic loss, which is a proper loss"
- Mixture coefficient: The parameter determining the proportion of different sequence types (e.g., long vs. short) in a data mixture. "Each color denotes a training distribution with a separate mixture coefficient $p_{\mathrm{cot}$."
- Mixture distribution: A probabilistic distribution composed of multiple component distributions (e.g., short and long reasoning sequences). "We study learning from mixture distributions of short and long “chain-of-thought” sequences encoding a single task."
- Product distribution: A distribution over a vector where components are independent, often denoted via tensor products. "we use the tensor product symbol for product distributions"
- Proper loss: A loss function whose minimization yields calibrated probabilities aligned with true conditional probabilities. "which is a proper loss"
- Rademacher random variable: A symmetric binary variable taking values +1 or −1 with equal probability. "We denote a Rademacher random variable (uniform in ) as "
- REINFORCE: A policy-gradient reinforcement learning algorithm using Monte Carlo estimates of returns to update parameters. "We consider three reinforcement learning algorithms: STaR, REINFORCE and GRPO."
- Reward-weighted loss: A training objective where sequences are weighted according to their rewards to bias learning toward successful generations. "and training proceeds on (prompts, guesses) with a next-token prediction loss that weights each sequence according to its reward"
- Sampling temperature: A parameter controlling randomness in sampling from a probability distribution over tokens; higher values increase diversity. "we can optionally set the sampling temperature $\tau_{\mathrm{RL}$ to a value different than 1."
- STaR algorithm: A reinforcement learning method that trains only on model-generated sequences that achieve correct reasoning chains and answers. "we consider the STaR algorithm~\citep{Zel+22} (which is a REINFORCE~\citep{Wil92}-type algorithm)"
- Stochastic Gradient Descent (SGD): An iterative optimization method that updates parameters using noisy gradient estimates from random batches. "We analyze pre-training (next-token prediction) with Stochastic Gradient Descent on $\mathcal{D}(p_{\mathrm{cot})$"
- Strong convexity: A property of objectives ensuring unique minima and faster convergence, often induced by regularization. "Then, strong convexity (afforded by the regularization term) and a case-to-case analysis establishes calibration"
- Tensor product symbol: Notation indicating independent components combined into a product distribution over vectors. "and we use the tensor product symbol for product distributions"
- Test-time computation: The amount of computation performed during inference (e.g., longer generated reasoning), which can affect accuracy. "reinforcement learning leverages increased test-time computation, manifested in longer responses"
- Universal learners: Models capable of learning a broad class of functions efficiently under suitable conditions. "linear autoregressive models can be efficient universal learners"
- XOR: The exclusive-or parity function that outputs 1 if an odd number of inputs are 1, otherwise 0. "Predicting the parity, or XOR, of objects has been an influential learning problem"
Collections
Sign up for free to add this paper to one or more collections.

