- The paper demonstrates that Thinking models outperform Instruct models in structured logical tasks when employing formal language trajectories.
- The paper reveals significant performance variations across deductive, inductive, abductive, and mixed-form reasoning tasks with formal formats.
- The paper shows that augmenting LLMs with formal language datasets improves accuracy by up to 17% on CSP tasks.
Introduction
The paper investigates the performance of LLMs on logical reasoning tasks, specifically utilizing formal languages to guide reasoning processes. The study is motivated by the necessity to offer comprehensive evaluations of LLMs, as most existing work is limited in assessing the logical reasoning capabilities across a spectrum of formal languages. It evaluates LLMs using a framework that considers three dimensions: the type of LLM, the taxonomy of reasoning tasks, and the trajectory formats for modeling the reasoning path (Figure 1).

Figure 1: Evaluation framework with three specific dimensions: spectrum of LLMs, taxonomy of logical reasoning tasks, and format of trajectories.
Methodology
The methodology involves constructing an evaluation framework and gathering datasets corresponding to different logical reasoning types: deductive, inductive, abductive, and mixed-form. The paper implements a comprehensive analysis across these dimensions to ascertain the capabilities of LLMs in leveraging formal languages. The framework is designed to evaluate reasoning trajectories modeled in various formats, namely "Python" (PoT), "Z3", "CSP", and default "Text".
Results
Evaluation of LLMs Across Dimensions
The findings reveal that Thinking models outperform Instruct models, primarily when formal languages are used. However, all models exhibit considerable limitations in inductive reasoning tasks, highlighting the challenges LLMs face in generalizing across formal languages.
Radar plot analysis (Figure 2) indicates a varying performance across different logical reasoning tasks and trajectory formats. Text-based formats generally outperform formal languages except for specific models like QwQ-32B, which maintains robust performance across all formats. The results underline that formal language performance drops significantly on complex tasks.
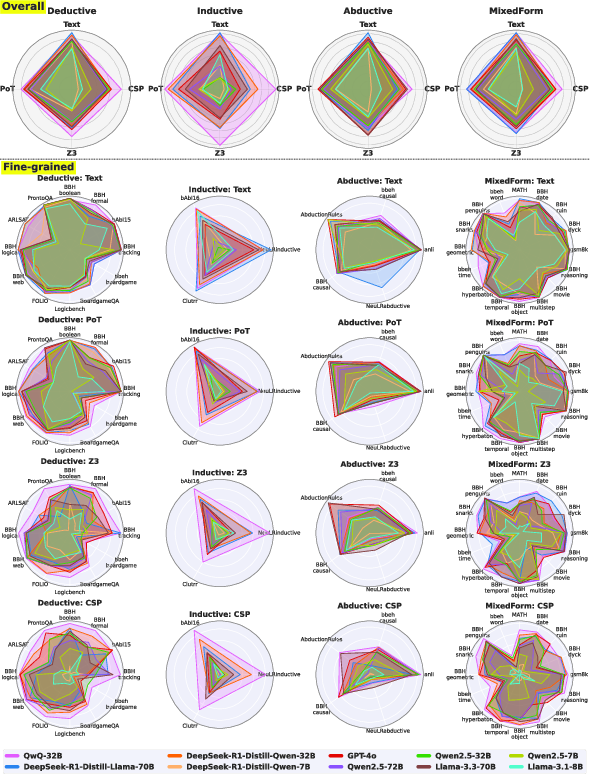
Figure 2: Radar plots illustrating the performance (\%) of multiple LLMs across different reasoning task types and trajectory formats.
The study highlights the preference of certain reasoning tasks for specific trajectory formats (Figure 3). Text format excels in language comprehension and open-ended tasks. Conversely, well-structured tasks demonstrate better performance with the PoT format, particularly in mathematical and symbolic reasoning tasks. Z3 is adapted well for formal logic tasks, evidencing the advantage of logic-based languages for strict logical rules. Lastly, CSP format exhibits strengths in structured logic tasks with numerous constraints.
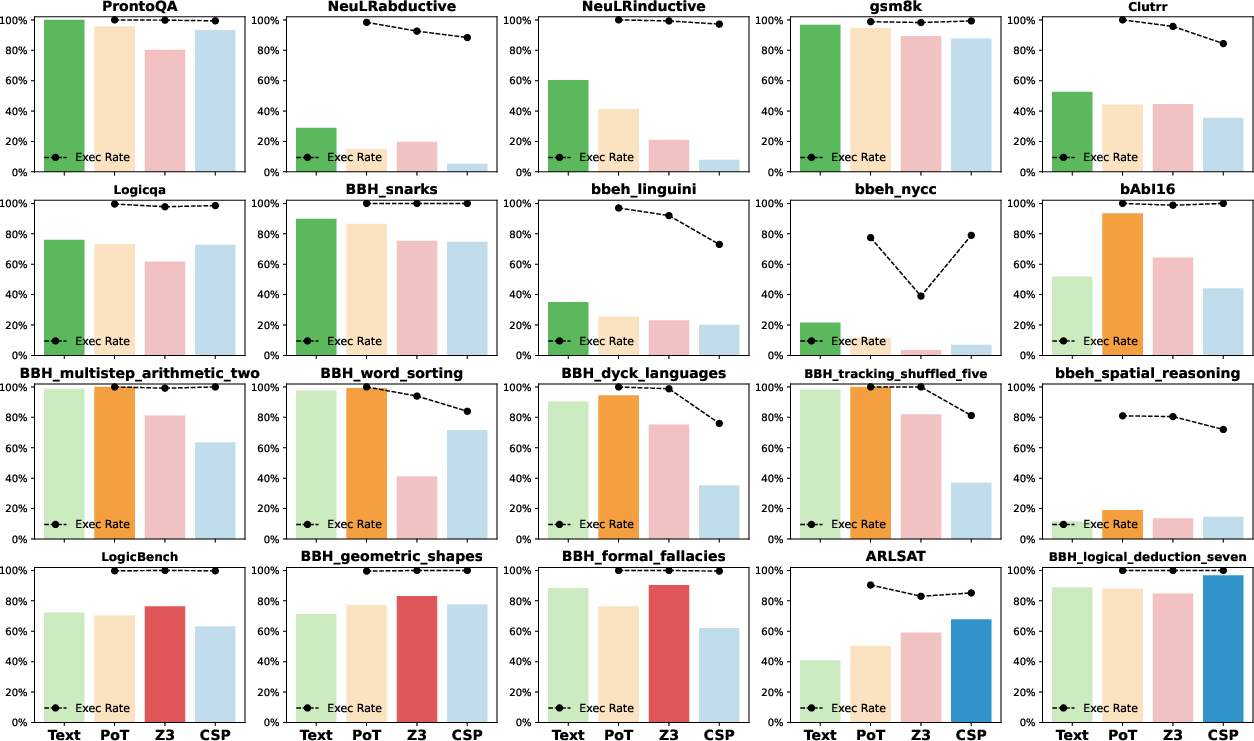
Figure 3: Preferred reasoning task performance across different trajectory formats in GPT-4o results.
Generalization Analysis
The analysis across different reasoning tasks and trajectory formats indicates that while PoT trajectories demonstrate positive transfer capabilities, CSP exhibits poor transferability across other formats, emphasizing structural variances among formal languages (Figures 4 and 5). The results suggest that all reasoning types exhibit positive transfer, with deductive-CSP configurations being the most easily generalized.
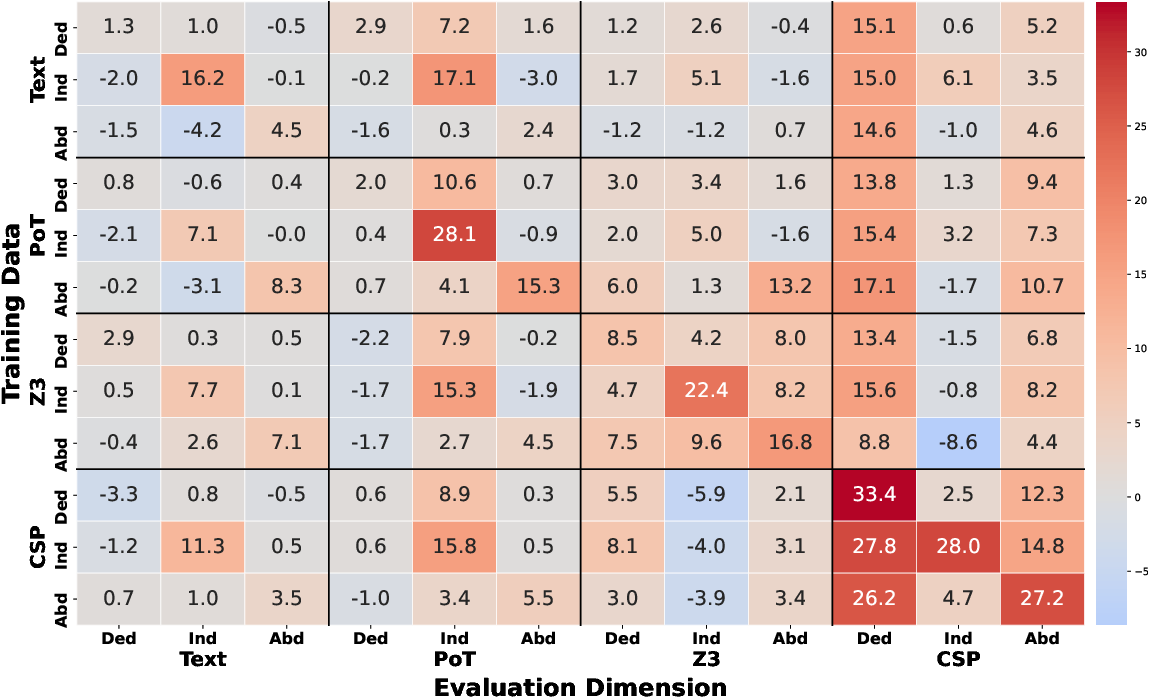
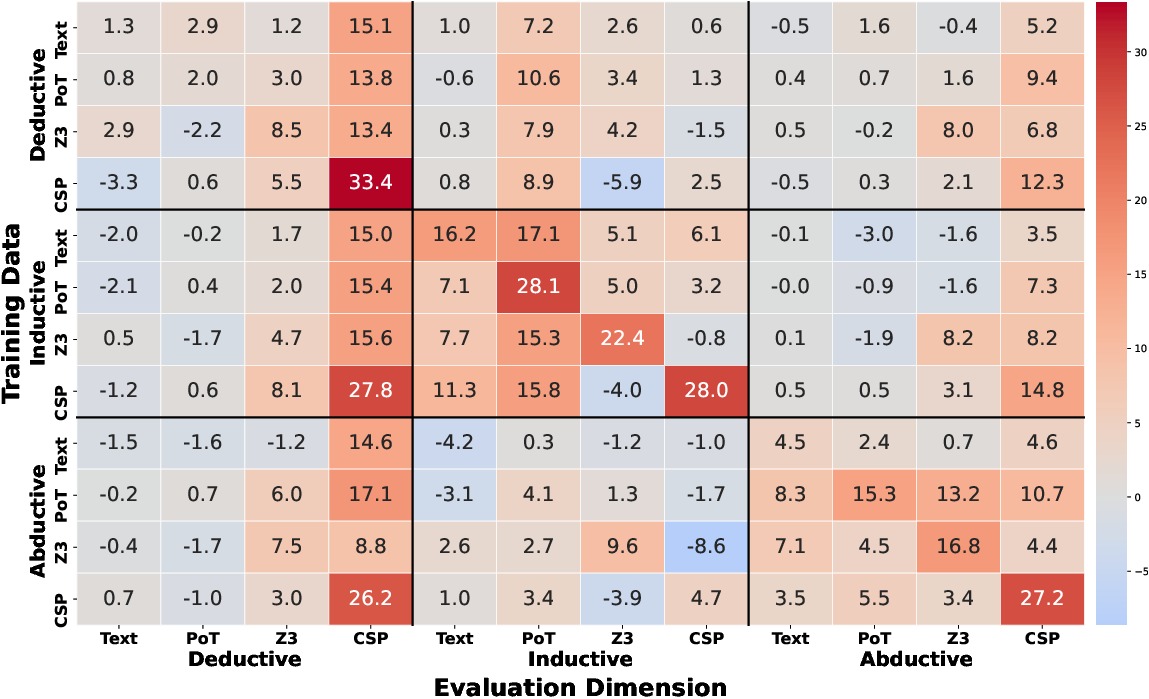
Figure 4: Fine-grained by Trajectory Format.
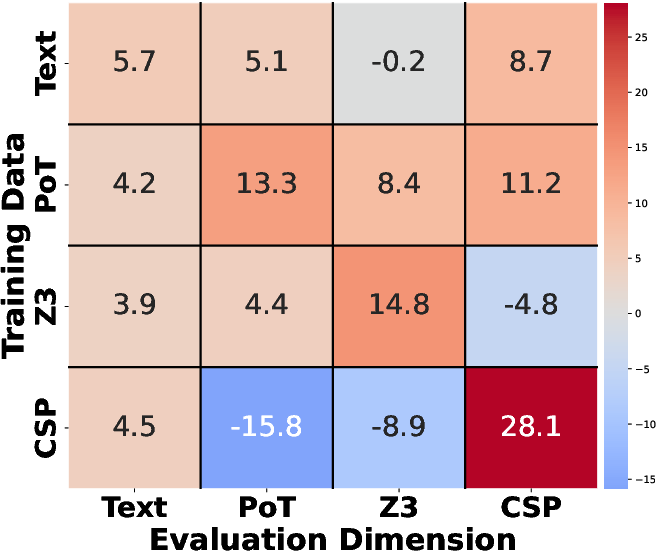

Figure 5: Trajectory Format.
The study further investigates enhancing the LLMs’ capabilities using a rejected fine-tuning approach with formal language datasets. The findings indicate significant performance improvements, enhancing model accuracy by up to 17.0\% on CSP formats (Table below).
| Model |
Text |
PoT |
Z3 |
CSP |
Avg |
| Qwen2.5-7B-Base w.Formal |
+3.0 |
+4.0 |
+7.7 |
+17.0 |
+8.0 |
Table: Performance improvements on different formats using formal data augmentation.
Conclusion
The paper systematically evaluates LLMs’ performance in logical reasoning tasks using formal languages, highlighting key observations about trajectory preferences and generalization capabilities. It provides insights into enhancing LLMs using formal language datasets, advocating for balanced improvements and task-specific trajectory alignment to augment reasoning capabilities.
The comprehensive evaluation underscores that while LLMs exhibit strong capabilities in certain task types, their performance is inconsistent when formal languages are employed, and generalization remains a critical challenge. Future work is directed towards expanding dataset coverage, enhancing formal reasoning capabilities, and exploring diverse symbolic systems.