- The paper demonstrates that attention-based architectures achieve superior per-FLOP efficiency compared to traditional MLPs in resource-constrained settings.
- It rigorously compares a variety of models, from linear predictors to transformers, using datasets such as Tiny Shakespeare, PTB, and WikiText-2.
- The study underscores the critical role of tailored positional encoding, finding that RoPE is less effective than learned embeddings in small model contexts.
Architectural Trade-offs in Small LLMs Under Compute Constraints
Introduction
The paper "Architectural Trade-offs in Small LLMs Under Compute Constraints" (2512.20877) provides an empirical investigation into the effects of architectural choices on the performance of small LLMs when operating under strict compute constraints. The research progresses from a linear next-token predictor to more complex architectures such as nonlinear models, self-attention mechanisms, and multilayer transformers. The study evaluates these models using metrics including test negative log-likelihood (NLL), parameter count, and approximate training FLOPs, examining how these factors trade off against one another in constrained environments. An important outcome is the identification of attention-based models as superior in per-FLOP efficiency over multilayer perceptrons (MLPs), even at smaller scales.
Experimental Setup
The study uses a variety of datasets, including Tiny Shakespeare for character-level modeling and PTB and WikiText-2 for word-level tasks. For character-level experiments, models are trained using a character window to predict subsequent characters, utilizing architectures such as linear models, multi-layer perceptrons, self-attention models, and transformers. The Tiny Shakespeare dataset allows quick convergence due to its relatively small size. For word-level modeling, similarly structured transformer-based architectures are adapted for use with PTB and WikiText-2 datasets, focusing on vocabulary built from training data for tokenization.
Character-Level Modeling: Tiny Shakespeare
The research explores various architectural configurations and evaluates them using negative log-likelihood (NLL) as illustrated in several figures. The study provides compelling data demonstrating the effectiveness of attention-based mechanisms in reducing NLL.
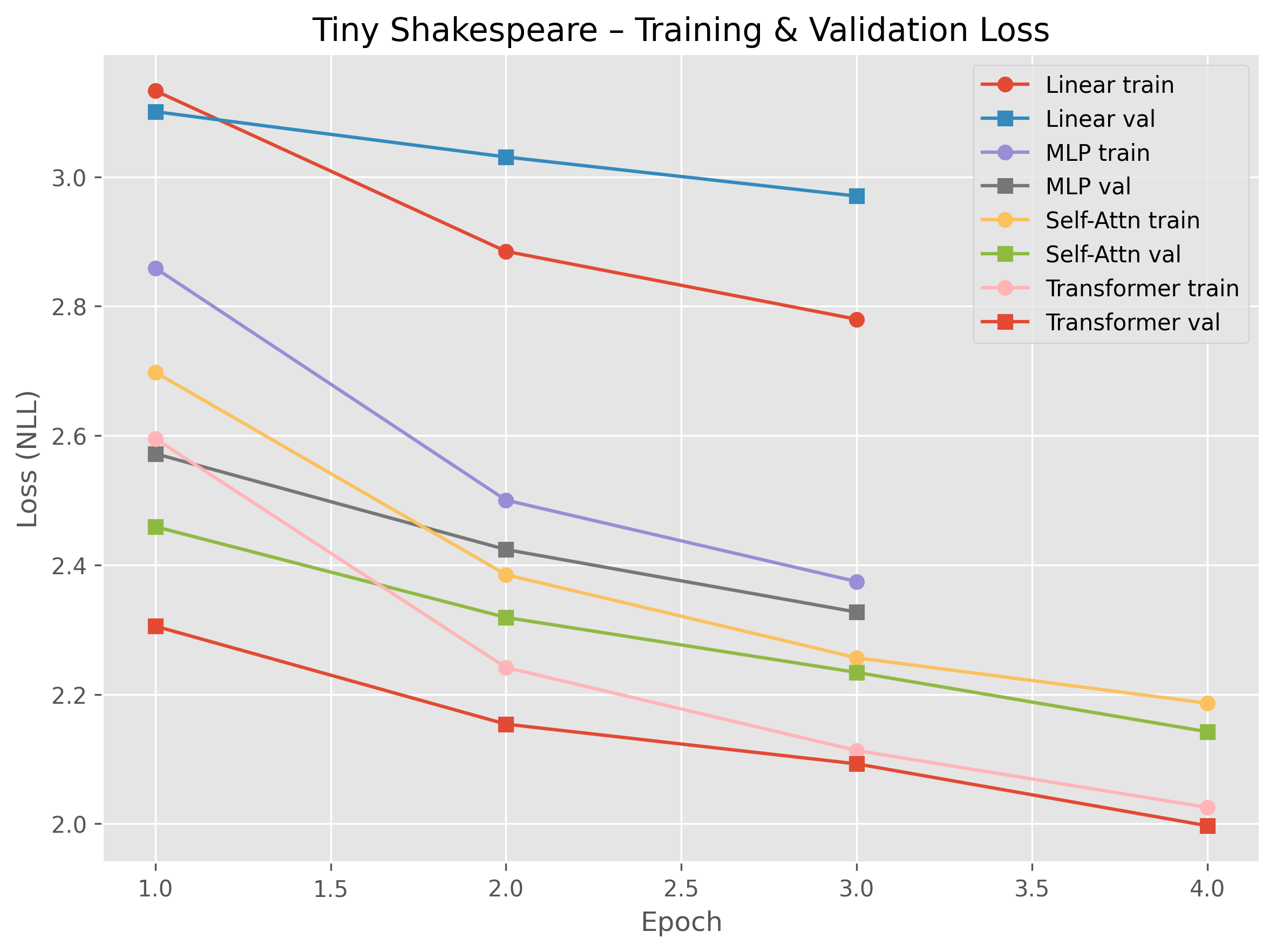
Figure 1: Training and validation NLL for Tiny Shakespeare across architectures. More expressive models achieve lower loss while still avoiding major overfitting in this setting.
An exploration of hyperparameters, such as context length for linear models and number of heads in self-attention mechanisms, demonstrates the nuanced sensitivity of model performance to architectural choices. Notably, attention-based models yield superior efficiency and lower test NLL values per approximate FLOP compared to linear and MLP architectures.
Word-Level Modeling on PTB and WikiText-2
Transitioning to word-level datasets, the paper retains the most effective configuration from Tiny Shakespeare—a 3-layer transformer—and adapts it to the broader vocabulary and variety within PTB and WikiText-2. Training dynamics show rapid overfitting, likely attributable to the short context windows and the transformers' capacity limits.
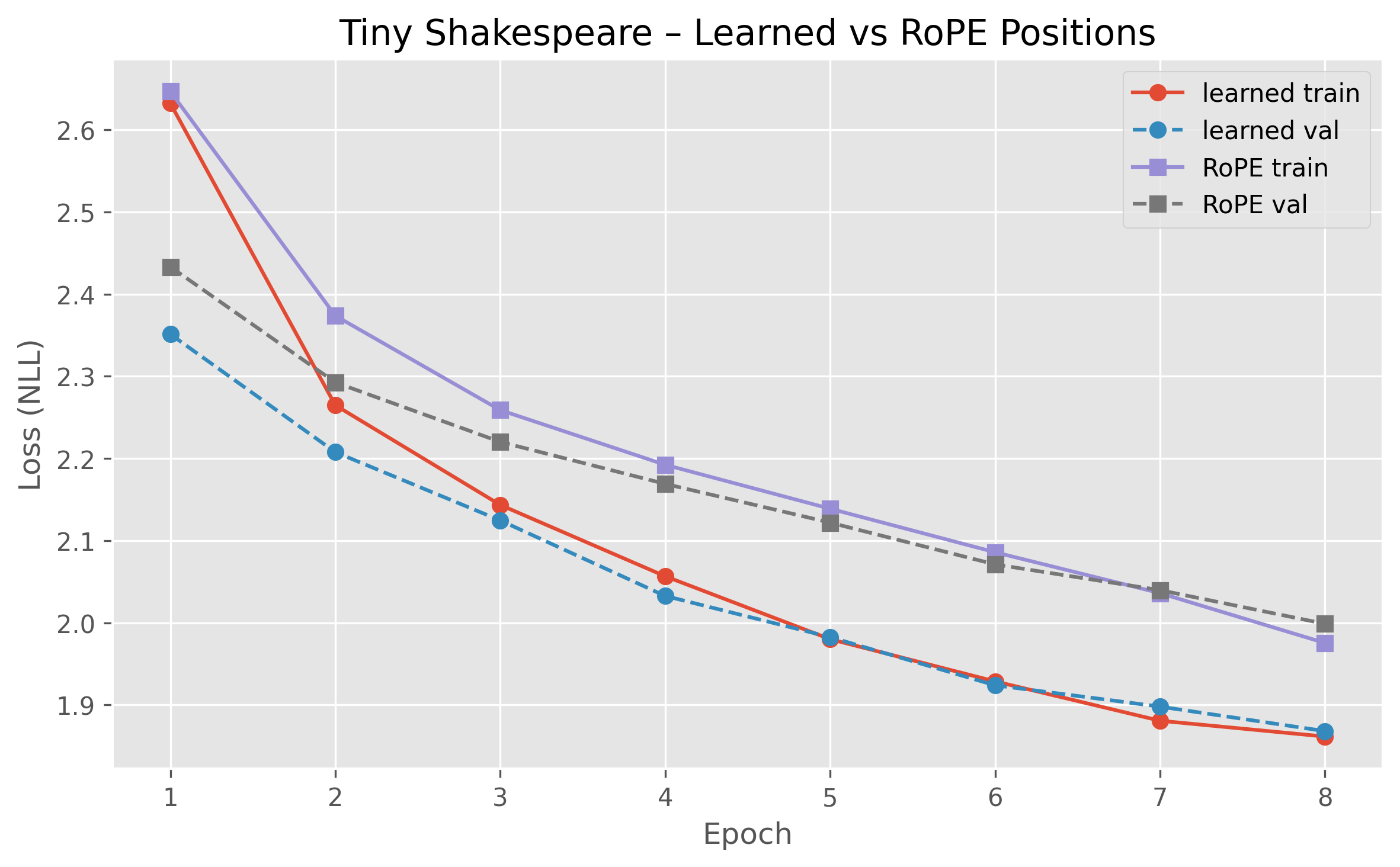
Figure 2: Training and validation NLL: learned vs.\ RoPE positional embeddings.
Positional Encoding Transfer (RoPE)
In a comparative analysis of positional encoding strategies, the paper presents rotary positional embeddings (RoPE) and their performance relative to learned embeddings in small transformers. RoPE, successful in large LLMs, shows diminished efficacy in the constrained setting of small models, emphasizing the necessity of validating architectural choices tailored to specific scales and compute budgets.
Discussion
The exploration reveals critical insights into the architecture-choice interplay within compute-bound environments. Noteworthy is the clear advantage of attention-based models in efficiently representing context-dependent information, unlike static feature concatenation. The research highlights the trade-offs between model capacity and computational budget, where increasing model complexity without proportional increases in computational resources can detrimentally impact performance.
Implications for Future Research
The findings suggest several avenues for further exploration. The need for attention-based architectures in resource-constrained environments underscores the importance of continued refinement in efficient computation strategies. Future research might focus on integrated approaches that reconcile the capacity of LLMs with their computational environment, optimizing positional embeddings for small-scale applications, and further empirical studies into alternative architectures or training techniques that capitalize on minimal computational inputs.
Conclusion
The paper makes a significant contribution by empirically validating how architectural decisions intersect with compute constraints in small-scale LLM performance. Attention mechanisms emerge as highly efficient compared to traditional MLPs, setting a direction for future research in resource-efficient neural network design. The research underscores the necessity for architectural validation within the specific context of application, offering insights that extend beyond theoretical considerations into practical modeling environments.