- The paper provides a systematic categorization of techniques like linear attention, sparse methods, MoE, hybrid models, and diffusion LLMs to enhance LLM efficiency.
- The paper details methods such as kernelized attention, data-dependent gating, and hardware-aware implementations that reduce computational and memory demands.
- The paper explains cross-modal adaptations and hybrid architectures that balance efficiency with model quality for long-context, reasoning, and multimodal applications.
Speed Always Wins: A Survey on Efficient Architectures for LLMs
Introduction and Motivation
The exponential growth in the scale and capabilities of LLMs has been accompanied by a commensurate increase in computational and memory demands, particularly for long-context, multimodal, and reasoning-intensive applications. The Transformer architecture, while foundational, is fundamentally limited by the quadratic complexity of its self-attention mechanism and the scaling of feed-forward layers. This survey provides a comprehensive and technically rigorous synthesis of architectural innovations that address these efficiency bottlenecks, systematically categorizing advances in linear and sparse sequence modeling, efficient full attention, sparse mixture-of-experts (MoE), hybrid models, diffusion LLMs, and cross-modal applications.
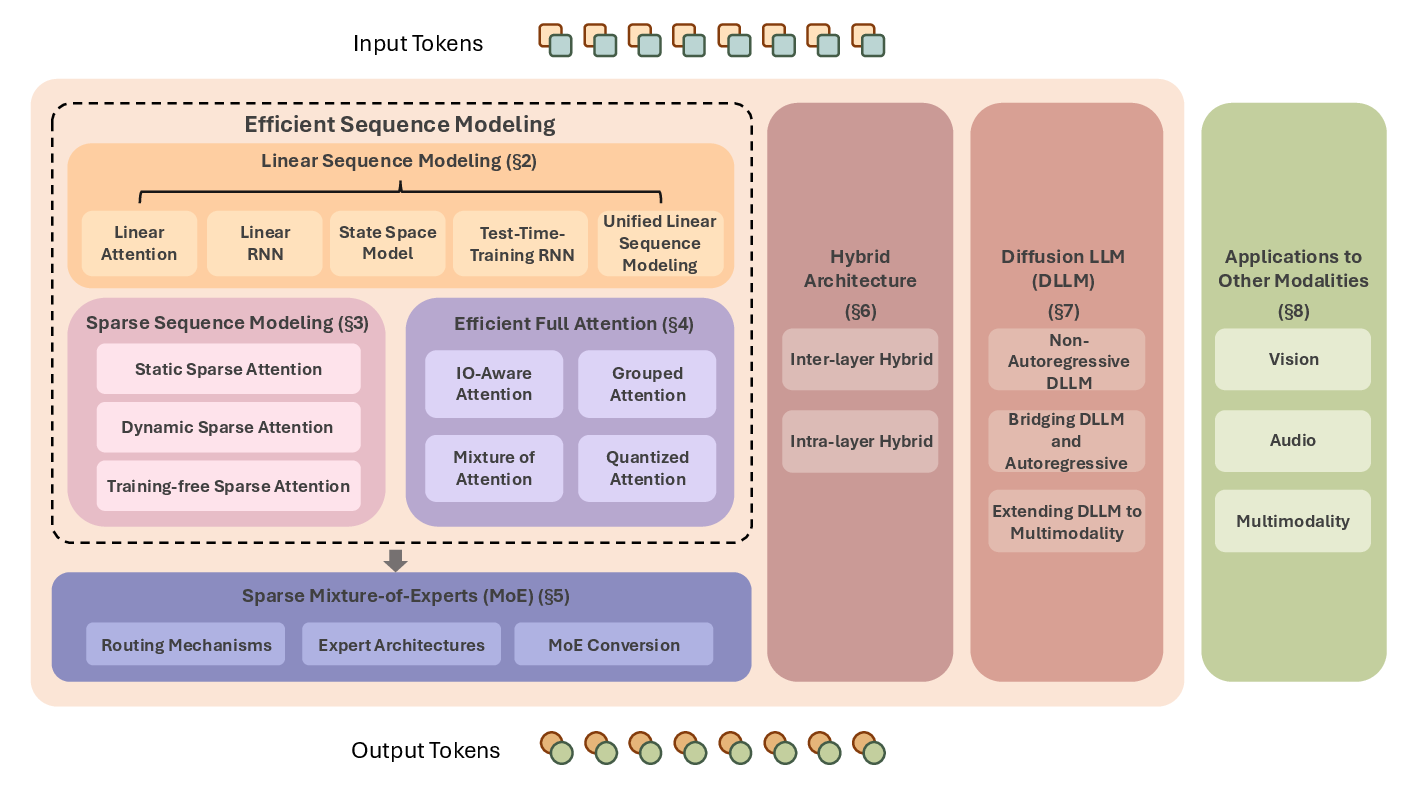
Figure 1: Overview of efficient architectures for LLMs, highlighting the taxonomy of approaches spanning linear, sparse, hybrid, MoE, and diffusion-based designs.
Long-Context and Multimodal Demands
The increasing prevalence of long-context scenarios—retrieval-augmented generation, agentic workflows, chain-of-thought reasoning, and high-resolution multimodal processing—has exposed the inefficiency of quadratic attention and the limitations of fixed-size memory in standard architectures.
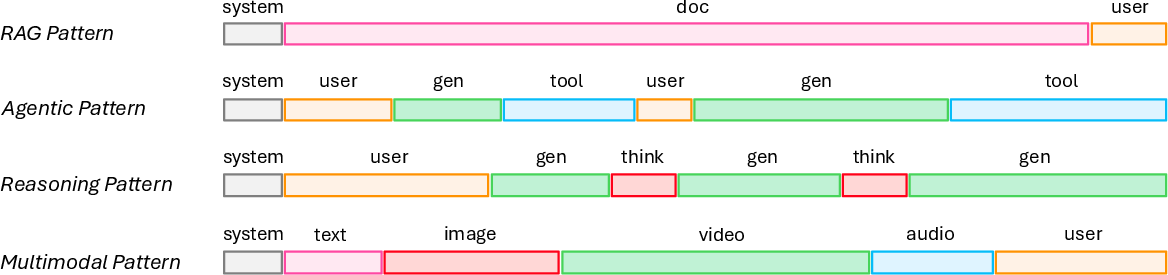
Figure 2: Representative long-context usage patterns in retrieval, agentic, reasoning, and multimodal applications.
Linear Sequence Modeling: Theory, Variants, and Hardware
Linear sequence modeling methods reduce the quadratic complexity of attention to linear, either by kernelizing the attention mechanism, leveraging RNN or SSM formulations, or employing test-time training (TTT) for online adaptation. The survey delineates the convergence of these approaches into a unified framework, emphasizing the role of gating, delta-rule updates, and log-linear memory for balancing expressivity and efficiency.
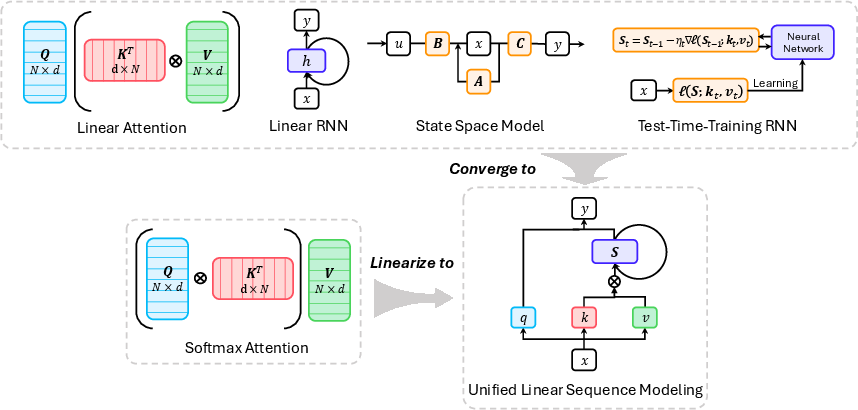
Figure 3: Connections among linear attention, linear RNNs, SSMs, and TTT models, illustrating their unification under a common sequence modeling paradigm.
The survey highlights that while vanilla linear attention suffers from memory conflicts and limited recall, the introduction of data-dependent gating (e.g., GLA, GSA), delta-rule updates (e.g., DeltaNet, MesaNet), and log-linear memory (e.g., Log-Linear Attention) significantly improves long-context performance. Theoretical analysis reveals that optimal softmax approximation in linear attention requires time-varying gating, and that bilinear and nonlinear update rules (as in TTT) further enhance expressivity at the cost of hardware parallelism.
Hardware-efficient implementations, such as chunk-wise parallelization and Blelloch scan, are critical for realizing the theoretical speedups of linear models on modern accelerators.
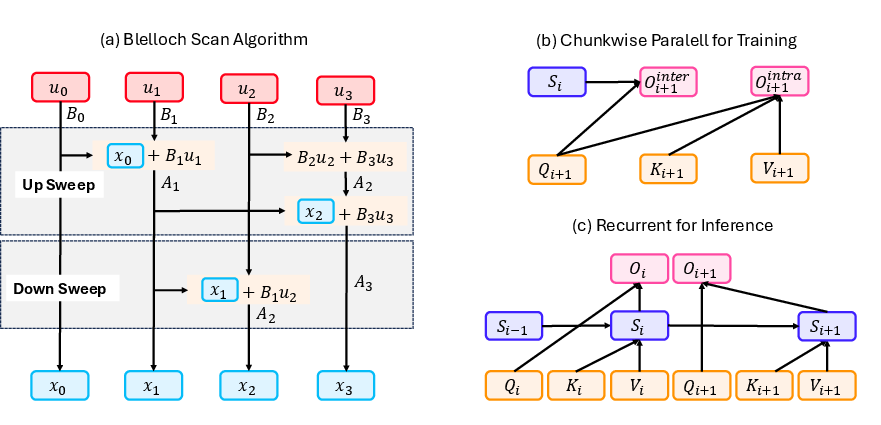
Figure 4: Hardware-efficient algorithms for linear sequence modeling, including Blelloch scan, intra-block parallelism, and constant-memory recurrent inference.
Sparse Sequence Modeling: Static, Dynamic, and Training-Free
Sparse attention mechanisms restrict token interactions to a subset, reducing compute and memory while preserving modeling power. Static patterns (e.g., Longformer, BigBird, ETC) exploit fixed local/global/random connectivity, while dynamic approaches (e.g., Reformer, Routing Transformer, MoSA) adaptively select context based on content or learned routing. Training-free methods (e.g., SeerAttention, StreamingLLM, H2O) focus on inference acceleration by pruning the KV cache or dynamically masking attention blocks, achieving significant speedups in both prefill and decoding stages.
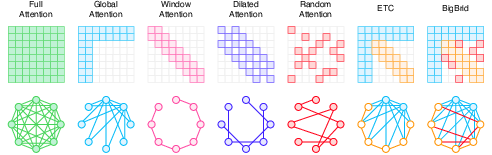
Figure 5: Example static sparse attention patterns, with ETC and BigBird illustrating mixed sparsity within a unified attention framework.
Efficient Full Attention: IO-Aware and Grouped Mechanisms
Despite their quadratic complexity, full attention variants such as FlashAttention-1/2/3 achieve substantial wall-clock speedups by optimizing memory access patterns, fusing computation, and leveraging low-precision arithmetic. Grouped attention methods (MQA, GQA, MLA, GTA, GLA) reduce KV cache size by sharing keys/values across query groups, enabling efficient inference with minimal quality degradation. These techniques are now standard in large-scale LLM deployments.
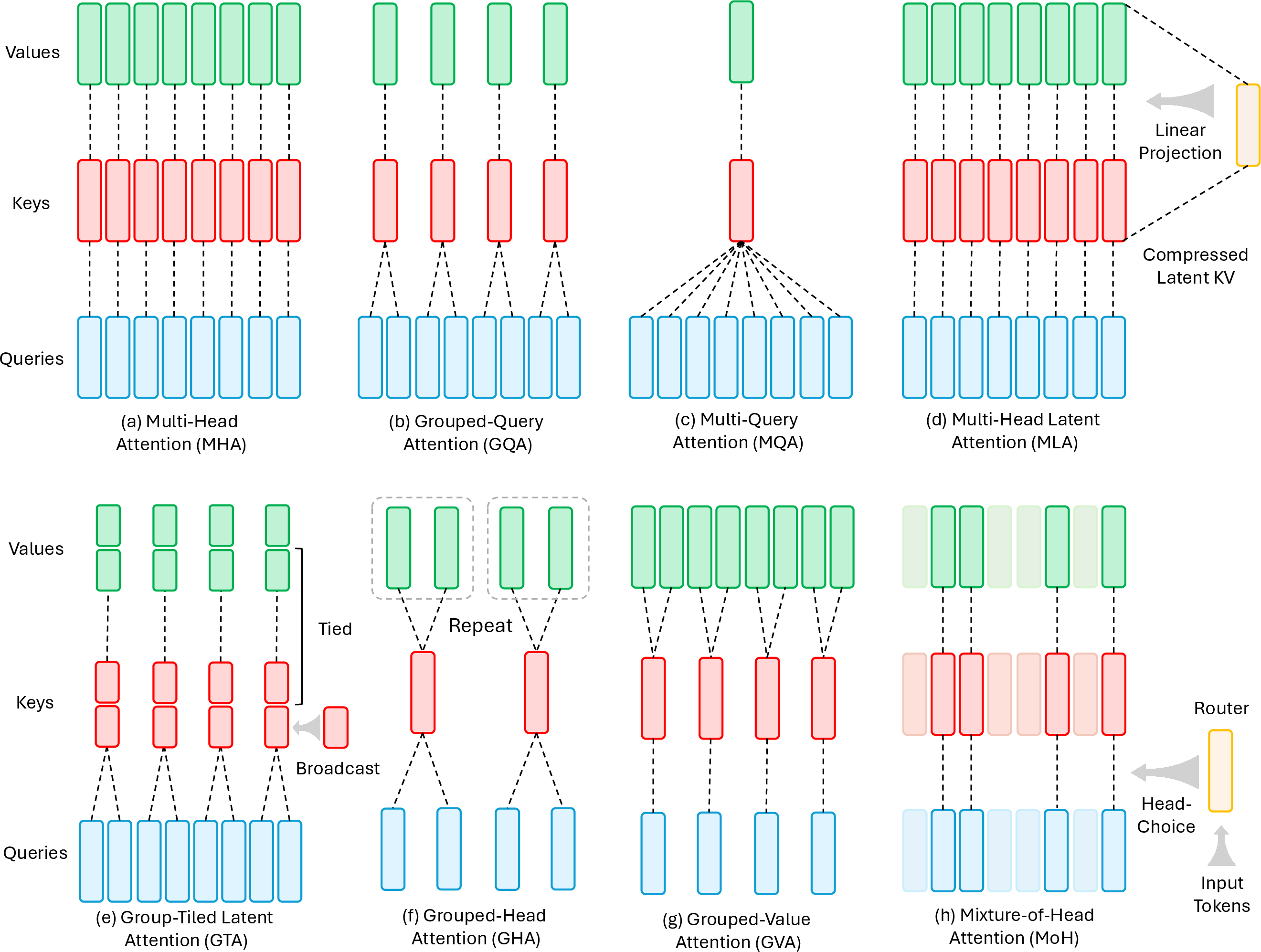
Figure 6: Mechanism comparison of primary grouped attention methods, including MQA, GQA, MLA, GTA, and GLA.
Sparse Mixture-of-Experts: Routing, Expert Design, and Conversion
MoE architectures scale model capacity by activating only a subset of experts per token, decoupling parameter count from compute. The survey details token-choice and expert-choice routing, adaptive top-k selection, and load balancing strategies, as well as the emergence of fine-grained, shared, and depth-wise expert designs. MoE conversion techniques (e.g., MoEfication, Sparse Upcycling, BTM/BTX) enable efficient construction of sparse models from dense checkpoints, facilitating rapid scaling and specialization.
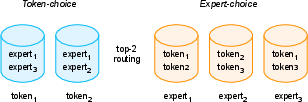
Figure 7: MoE routing strategies, contrasting token-choice and expert-choice paradigms.
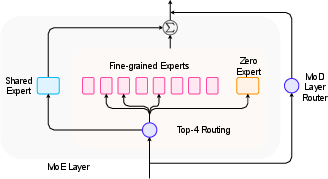
Figure 8: MoE expert architectures, including fine-grained, shared, and mixture-of-depths experts.

Figure 9: MoE conversion strategies, illustrating dense-to-MoE and model-merging approaches.
Hybrid Architectures: Inter- and Intra-Layer Fusion
Hybrid models combine linear and softmax attention to balance efficiency and expressivity. Inter-layer hybrids alternate linear and full attention layers (e.g., Zamba, Jamba, Hunyuan-TurboS), while intra-layer hybrids blend attention types within a layer, either head-wise (e.g., Hymba) or sequence-wise (e.g., LoLCATs, Liger, TransMamba). These designs achieve near-transformer quality with substantially reduced compute and memory, and are now prevalent in production-scale LLMs.
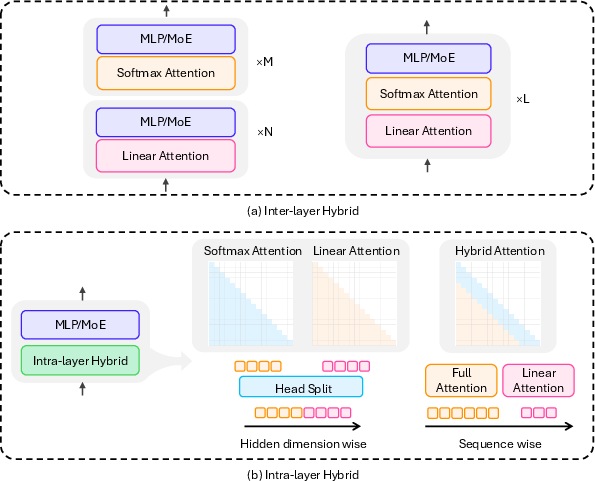
Figure 10: Hybrid model architectures, showing inter-layer and intra-layer fusion patterns.
Diffusion LLMs: Non-Autoregressive and Hybrid Generation
Diffusion LLMs generate text by iterative denoising, supporting parallel decoding and enhanced controllability. Non-autoregressive models (e.g., LLaDA) achieve competitive performance with AR LLMs and overcome unidirectional limitations such as the reversal curse. Hybrid approaches (e.g., BD3-LMs, DiffuLLaMA) interpolate between AR and diffusion, enabling flexible-length generation and efficient adaptation from pre-trained AR models. RL-based fine-tuning (e.g., d1 framework) demonstrates that diffusion LLMs can match or surpass AR models in reasoning tasks.
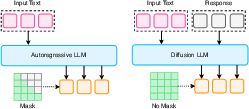
Figure 11: Mechanism comparison of autoregressive models and diffusion LLMs, highlighting differences in generation order and context access.
Cross-Modal and Domain Applications
Efficient architectures are being rapidly adapted to vision, audio, and multimodal domains. In vision, SSMs and MoE backbones enable scalable classification, detection, segmentation, and generative modeling, with strong results in high-resolution and medical imaging. In audio, Mamba and RWKV variants set new baselines for tagging, separation, and streaming ASR. Multimodal models leverage efficient alignment and fusion modules, with diffusion and MoE paradigms supporting scalable instruction tuning and unified cross-modal generation.
Implications and Future Directions
The survey underscores that efficiency is now a primary axis of LLM design, with architectural choices directly impacting scalability, deployment cost, and applicability to new domains. Theoretical advances in memory management, gating, and routing are being rapidly translated into practical systems via hardware-aware implementations. The field is converging on a toolkit of composable modules—linear/SSM blocks, sparse/grouped attention, MoE, and hybrid layers—that can be tailored to specific application and hardware constraints.
Key open directions include:
- Algorithm-system-hardware co-design for end-to-end efficiency, especially on edge and specialized accelerators.
- Adaptive attention and MoE routing for dynamic resource allocation.
- Hierarchical and log-linear memory for infinite context and lifelong learning.
- Diffusion-based and non-autoregressive LLMs for parallel, controllable generation.
- Unified omni-modal models that seamlessly integrate text, vision, audio, and action.
Conclusion
This survey provides a technically detailed and systematic account of efficient LLM architectures, mapping the landscape of linear, sparse, MoE, hybrid, and diffusion-based designs. The synthesis of theoretical insights, hardware-aware algorithms, and cross-domain applications establishes a blueprint for the next generation of scalable, resource-aware foundation models. The trajectory of research suggests that efficiency, not just scale, will be the dominant driver of progress in LLMs and multimodal AI systems.

