- The paper demonstrates that reservoir computing can be effectively used for character-level language modeling by employing a fixed recurrent reservoir and lightweight training.
- It shows that attention-enhanced reservoir models close the performance gap with transformers while offering significant reductions in energy consumption.
- Experimental results on a Shakespeare corpus highlight faster training and inference times, suggesting potential for energy-efficient hardware implementations.
Reservoir Computing as a LLM
The study, "Reservoir Computing as a LLM" (2507.15779), investigates the use of reservoir computing (RC) as a LLM, specifically comparing traditional reservoirs, attention-enhanced reservoirs, and transformer architectures on tasks involving character-level language modeling. The research emphasizes the advantages of RC in terms of reduced energy consumption and faster processing, which could pave the way for energy-efficient hardware implementations, a critical aspect given transformers' high computational costs.
Introduction
Modern sequence modeling tasks, such as language modeling, have predominantly relied on transformers due to their ability to capture long-range dependencies through self-attention mechanisms. The computational and energy demands of transformers, however, present limitations. Reservoir Computing offers an alternative by utilizing a fixed recurrent "reservoir" that requires training only for a lightweight readout layer. This design can be efficiently implemented in software or on analog hardware substrates, offering potential advantages in terms of energy consumption and hardware compatibility for real-time language processing tasks.
The primary task addressed is next-character prediction using a character-level model grounded in a 9-million-character Shakespeare corpus. The problem is formulated as a multi-class classification task, with 59 distinct characters forming the vocabulary. The dataset is divided into six shards, with five shards used for training and one shard for testing. Input sequences comprise 32 characters, and training is optimized using cross-entropy loss.
Model Architectures
Traditional Reservoir Computing
The traditional reservoir computing model consists of a large, fixed recurrent reservoir array, with only the readout layer being trainable. The reservoir maps the input into a high-dimensional space, allowing a simple, efficient readout to learn the sequence patterns.
Attention-Enhanced Reservoir Computing
The attention-enhanced reservoir computing (AERC) features dynamic readout weights, enhancing the model's ability to capture complex temporal dependencies through adaptive attention mechanisms. This improves performance while retaining the efficiency of the RC approach.
Transformers are fully trainable architectures with layers of self-attention and feed-forward networks. They excel at capturing complex sequence patterns through attention mechanisms, albeit at the expense of increased computational and memory requirements.
Results and Analysis
The study analyzed models with 15,000 to 155,000 trainable parameters, highlighting how each architecture scales in resource usage and predictive performance. Transformer models exhibited superior predictive quality with a minimum testing loss of 1.67. Reservoir models showed competitive performance, with classical RC achieving a testing loss of 2.01 and AERC reaching 1.73. These results showcase the potential of RC-based architectures in providing efficient alternatives to traditional deep learning models.
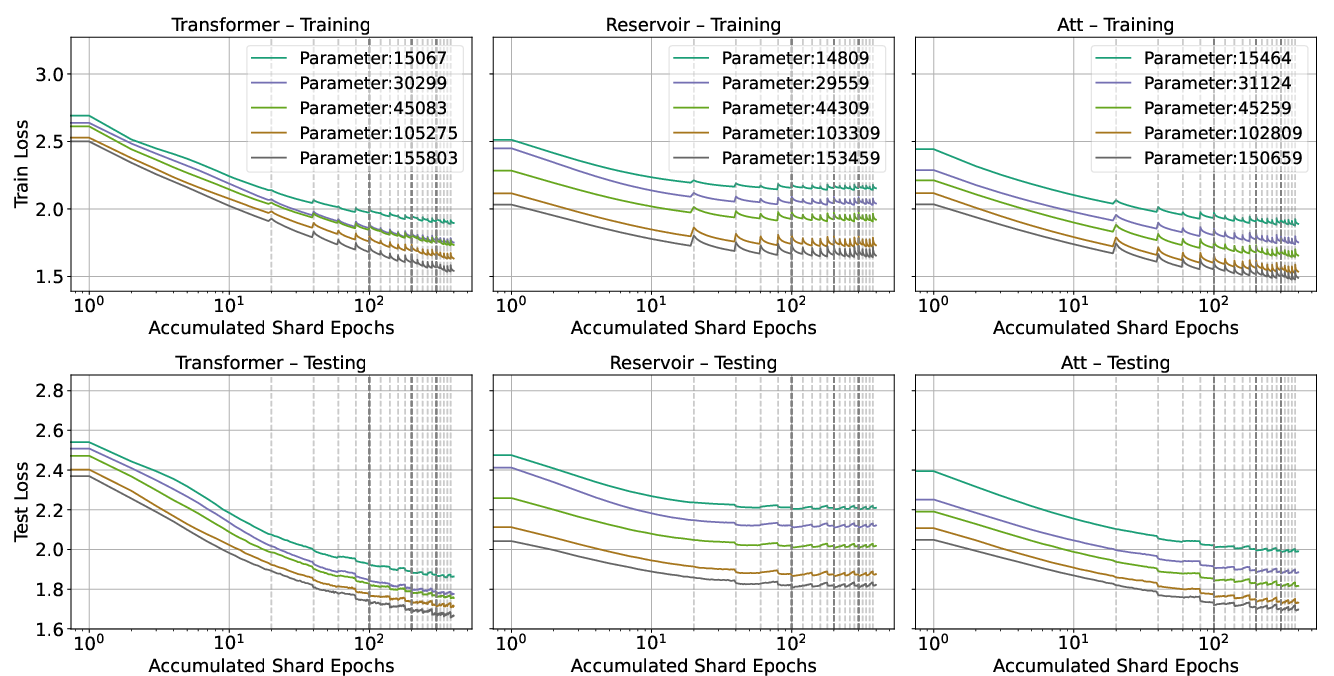
Figure 1: Training and testing loss over accumulated number of shared epochs for the Transformer, Reservoir, and Attention-Enhanced Reservoir Computer for the 5 different complexity models.
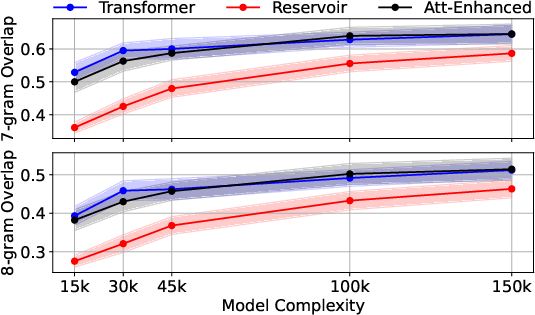
Figure 2: 7-gram and 8-gram overlap for the Transformer, Reservoir, and Attention-Enhanced Reservoir Computer over the number of trainable parameters.
The evaluation metrics, including N-gram overlap, demonstrated that transformers and AERC models better align distributionally with the reference data compared to traditional reservoirs. Training and inference times indicated that reservoir-based models are substantially faster, highlighting their efficiency, especially when offloading reservoir computation to analog hardware.
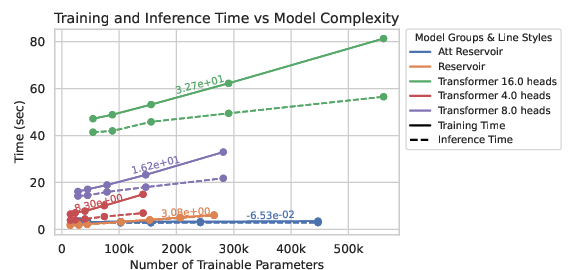
Figure 3: Training and inference time for a longer text generation over the number of trainable parameters for the Transformer, Reservoir, and Attention-Enhanced Reservoir Computer.
Conclusion
The research presented a novel comparative framework evaluating reservoir and transformer architectures for language modeling tasks. Transformers excelled in accuracy but incurred higher computational costs. Reservoir computing, particularly the attention-enhanced variant, showed promising efficiency and performance, suggesting potential for real-world applications where energy consumption and speed are prioritized. Future work may explore scaling reservoir computing in larger LLMs to better understand its scalability and generalization capabilities. The findings here could inform future developments in efficient LLM architectures.
