- The paper introduces a scalable pipeline that synthesizes complex QA from knowledge graphs, enabling long-horizon, multi-step reasoning.
- The method employs end-to-end multi-turn reinforcement learning to align LLM reasoning with optimal tool interaction strategies.
- Empirical results demonstrate that DeepDive enhances open-source deep search accuracy, outperforming several proprietary baselines on benchmarks.
DeepDive: Advancing Deep Search Agents with Knowledge Graphs and Multi-Turn RL
Motivation and Problem Setting
The increasing complexity of real-world information-seeking tasks necessitates LLMs that can perform long-horizon, multi-step reasoning and integrate external tools such as web browsing. While proprietary LLMs have demonstrated strong performance as deep search agents, open-source models lag significantly, primarily due to two factors: the scarcity of sufficiently challenging, verifiable training data and the lack of effective multi-turn reinforcement learning (RL) strategies for tool-augmented reasoning. The DeepDive framework addresses these limitations by introducing a scalable pipeline for synthesizing hard-to-find QA data from knowledge graphs (KGs) and by leveraging end-to-end multi-turn RL to align LLMs' reasoning with deep search tool use.
Automated Deep Search QA Synthesis from Knowledge Graphs
DeepDive's data construction pipeline exploits the multi-hop, attribute-rich structure of KGs to generate complex, ambiguous QA pairs that require long-horizon reasoning and iterative search. The process involves random walks over KGs to construct multi-step reasoning paths, selective obfuscation of entity attributes to increase ambiguity, and LLM-based paraphrasing to further obscure direct cues. To ensure high difficulty, candidate questions are filtered by attempting to solve them with a frontier model (e.g., GPT-4o) equipped with search; only those unsolved after multiple attempts are retained.
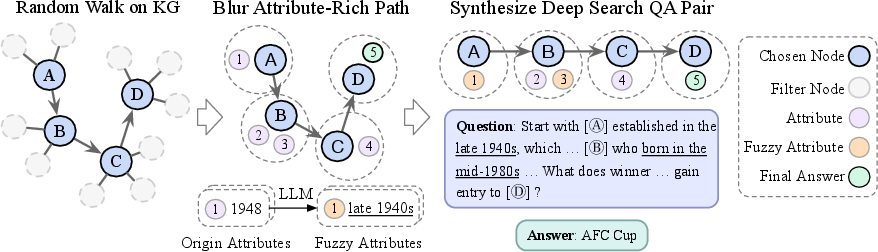
Figure 1: Overview of automated QA data synthesis from KGs for DeepDive, combining random walks and LLM-based obfuscation to generate challenging QA pairs.
A concrete example of a synthesized QA pair illustrates the resulting complexity and the necessity for deep, multi-hop search strategies.

Figure 2: A QA pair synthesized from KGs, demonstrating the obfuscation and multi-hop reasoning required.
This automated pipeline yields a large corpus of high-quality, verifiable, and challenging QA data, which is critical for training agents to handle real-world, hard-to-find information needs.
End-to-End Multi-Turn Reinforcement Learning for Deep Search
DeepDive employs a web interaction environment where the agent iteratively reasons, issues tool calls (search, click, open), and observes web content, terminating only when sufficient evidence is gathered. The RL objective is to maximize a strict binary reward: a trajectory is rewarded only if all tool calls are correctly formatted and the final answer exactly matches the ground truth, as judged by an LLM-as-Judge system. The Group Relative Policy Optimization (GRPO) algorithm is used for policy updates, with early termination on format errors to ensure only valid trajectories receive positive reward.
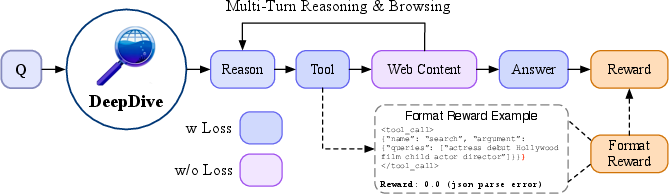
Figure 3: Overview of multi-turn RL for training reasoning and deep search abilities in DeepDive.
This approach directly incentivizes the agent to develop robust, multi-step search strategies and to avoid reward hacking or shortcut behaviors.
Empirical Results and Analysis
DeepDive-32B achieves 14.8% accuracy on BrowseComp, outperforming all prior open-source models and several proprietary baselines, and demonstrates strong results on other deep search benchmarks (BrowseComp-ZH, SEAL-0, Xbench-DeepSearch). The RL-trained model consistently surpasses its SFT-only counterpart, with the performance gap widening on more challenging tasks. Notably, DeepDive-32B's SFT-only variant already outperforms some proprietary models with browsing capabilities, and RL further amplifies this advantage.
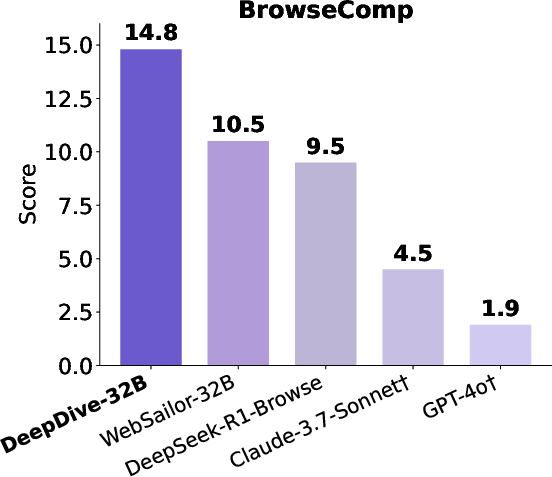
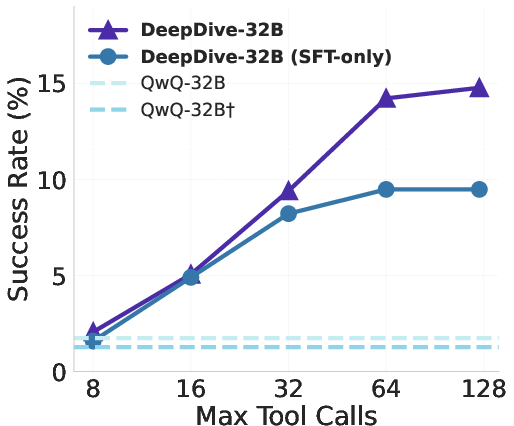
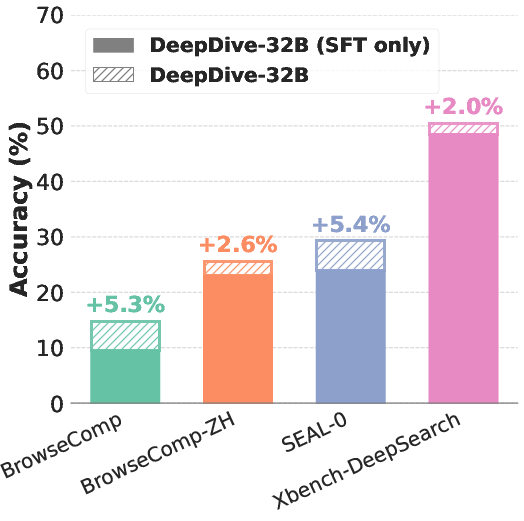
Figure 4: Left: DeepDive-32B outperforms open-source and proprietary models on BrowseComp. Center: Performance scales with maximum tool calls. Right: Multi-turn RL consistently enhances DeepDive-32B across benchmarks.
RL-Induced Deep Search Behavior
Multi-turn RL not only improves accuracy but also increases the average number of tool calls, indicating the emergence of deeper, more persistent search strategies. During RL training, both reward and evaluation accuracy increase in tandem with the number of tool calls, reflecting the agent's growing ability to tackle long-horizon tasks.
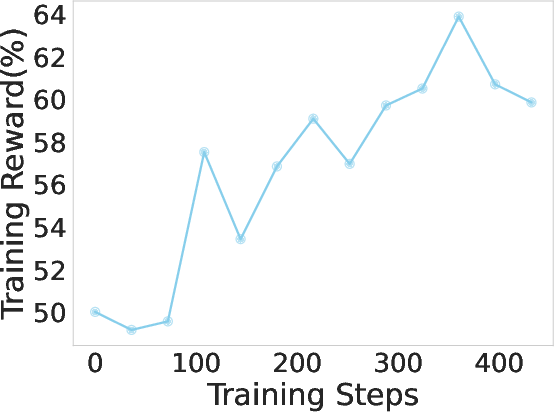
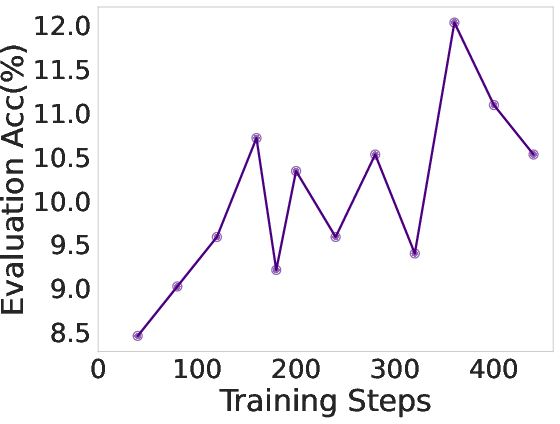
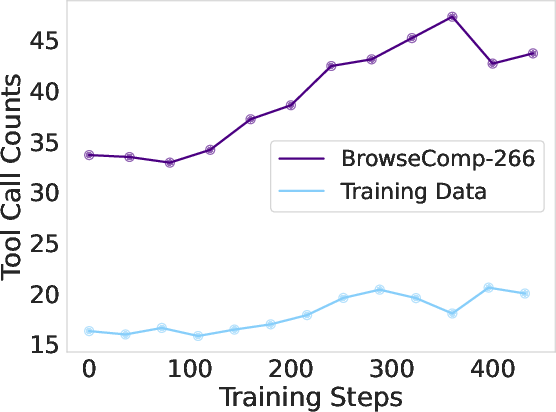
Figure 5: RL training reward, evaluation accuracy, and average tool call counts for DeepDive-32B, showing progressive adoption of deeper search strategies.
Generalization and Transfer
Despite being trained on complex, KG-derived data, DeepDive generalizes well to simpler search tasks (e.g., HotpotQA, WebWalker), outperforming both open-source and proprietary baselines. This suggests that skills acquired on hard, ambiguous tasks transfer effectively to more direct information-seeking scenarios.
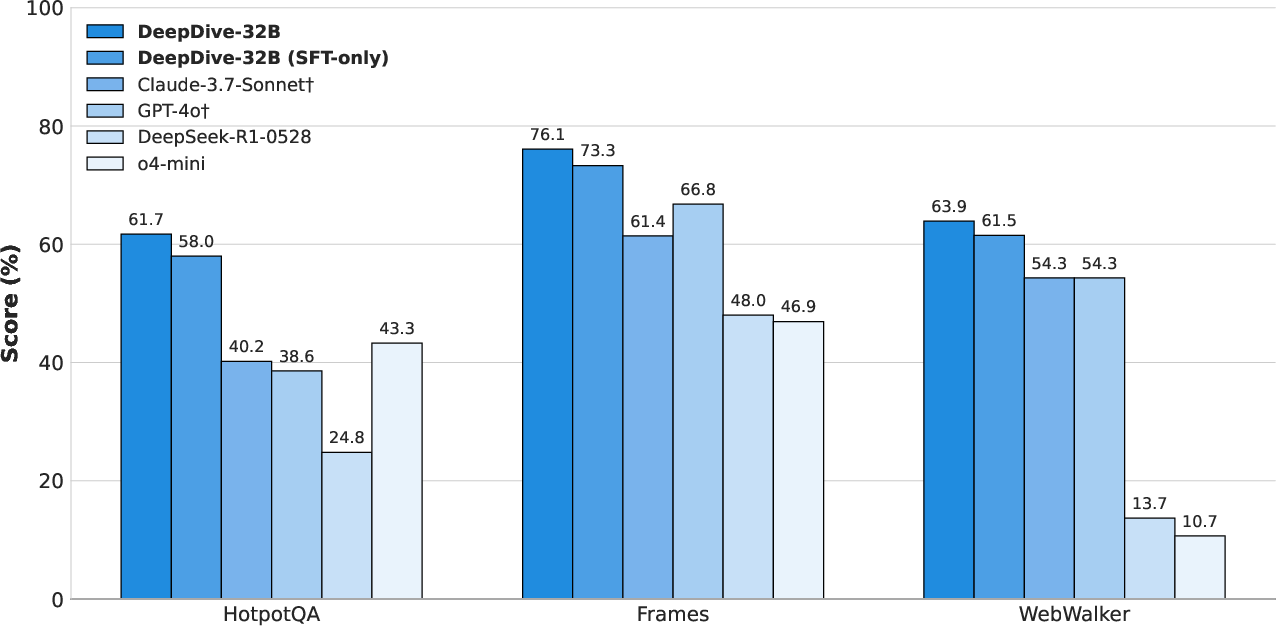
Figure 6: DeepDive generalization on simple search benchmarks, with RL further improving performance.
DeepDive's performance scales with the allowed number of tool calls at inference. Increasing the tool call budget leads to monotonic accuracy gains, with RL-trained models benefiting more from larger budgets. Additionally, parallel sampling—running multiple independent trajectories per question—enables further gains. Selecting the answer with the fewest tool calls among samples yields higher accuracy than majority voting, leveraging the empirical correlation between shorter trajectories and correctness.
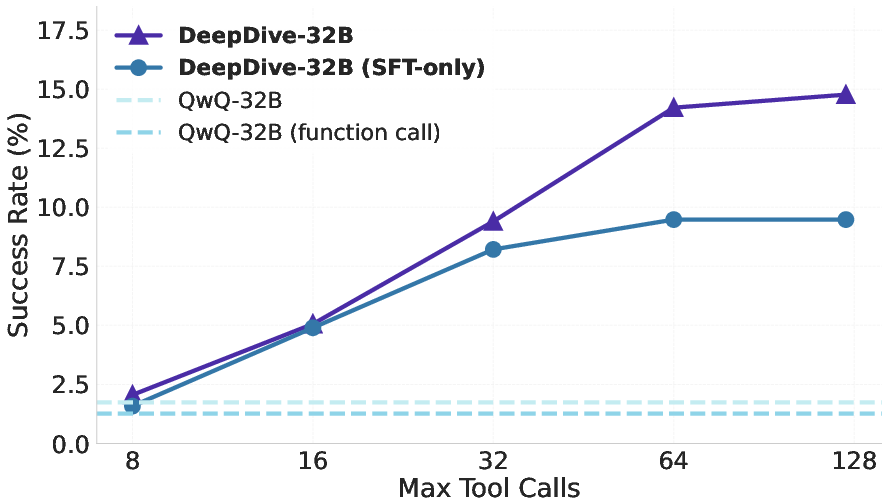
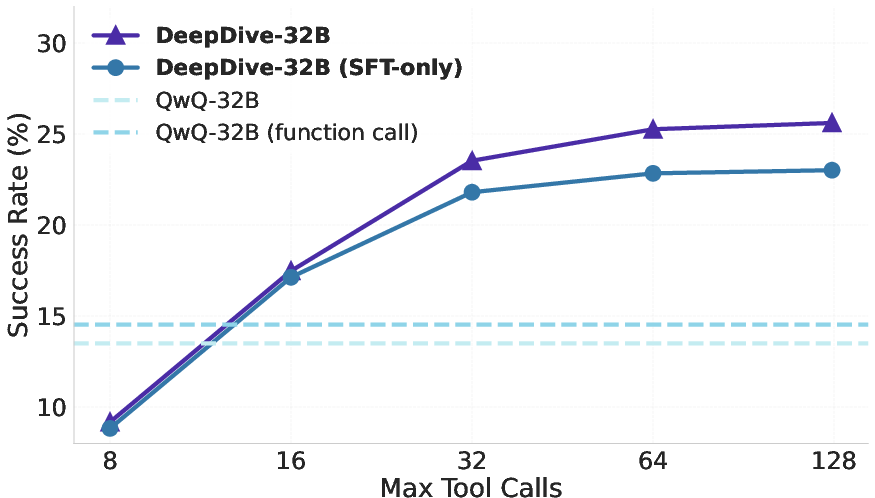
Figure 7: Tool call scaling of DeepDive-32B and SFT-only variant on BrowseComp and BrowseComp-ZH.
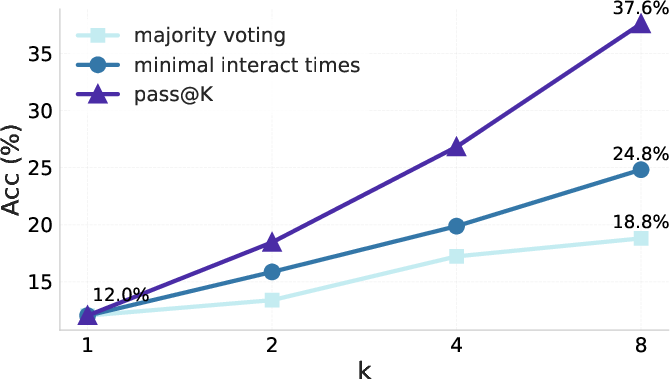
Figure 8: Comparison of answer selection strategies in 8-parallel sampling; minimal tool call selection outperforms majority voting.
Ablation and Data Studies
Ablation experiments confirm that both the synthetic KG-based data and the RL stage are essential for activating long-horizon search capabilities. Fine-tuning or RL on simpler datasets (e.g., HotpotQA) yields only marginal improvements, whereas DeepDive's data and RL pipeline produce substantial gains in both accuracy and tool call depth. An additional semi-automated, human-in-the-loop data synthesis pipeline further boosts performance, with DeepDive-32B reaching 22.2% accuracy on BrowseComp when trained with this i.i.d. data.
Limitations and Future Directions
While DeepDive's data synthesis pipeline produces challenging QA pairs, the upper bound of difficulty remains below that of benchmarks like BrowseComp, limiting maximal attainable performance. The RL training regime, focused on difficult data, can induce "over-search" behaviors, suggesting the need for more nuanced reward shaping and curriculum design. Addressing these issues—potentially via more sophisticated data generation, adaptive reward functions, or hierarchical RL—remains an open research direction.
Conclusion
DeepDive demonstrates that scalable, automated synthesis of hard-to-find QA data from KGs, combined with end-to-end multi-turn RL, can substantially advance the capabilities of open-source deep search agents. The framework achieves new state-of-the-art results among open models, exhibits strong generalization, and provides empirical evidence that both data and RL are critical for aligning LLMs with long-horizon, tool-augmented reasoning. The open release of datasets, models, and code will facilitate further progress in the development of autonomous, verifiable, and robust deep search systems.

