Enterprise Deep Research: Steerable Multi-Agent Deep Research for Enterprise Analytics
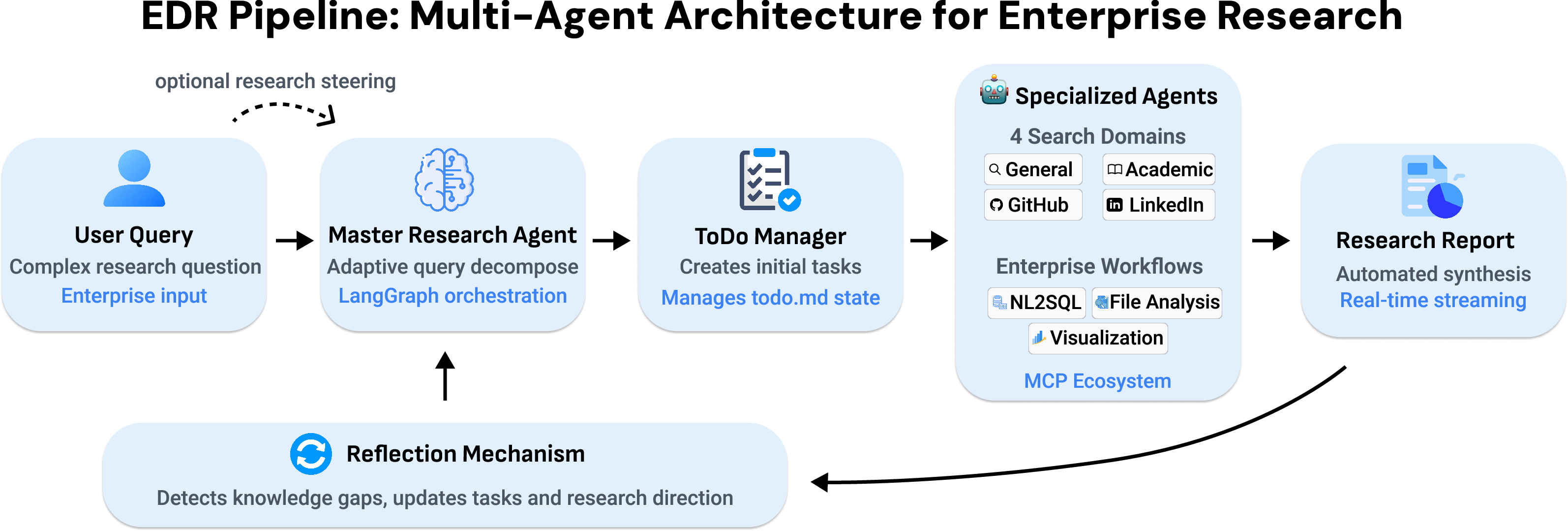
Abstract: As information grows exponentially, enterprises face increasing pressure to transform unstructured data into coherent, actionable insights. While autonomous agents show promise, they often struggle with domain-specific nuances, intent alignment, and enterprise integration. We present Enterprise Deep Research (EDR), a multi-agent system that integrates (1) a Master Planning Agent for adaptive query decomposition, (2) four specialized search agents (General, Academic, GitHub, LinkedIn), (3) an extensible MCP-based tool ecosystem supporting NL2SQL, file analysis, and enterprise workflows, (4) a Visualization Agent for data-driven insights, and (5) a reflection mechanism that detects knowledge gaps and updates research direction with optional human-in-the-loop steering guidance. These components enable automated report generation, real-time streaming, and seamless enterprise deployment, as validated on internal datasets. On open-ended benchmarks including DeepResearch Bench and DeepConsult, EDR outperforms state-of-the-art agentic systems without any human steering. We release the EDR framework and benchmark trajectories to advance research on multi-agent reasoning applications. Code at https://github.com/SalesforceAIResearch/enterprise-deep-research and Dataset at https://huggingface.co/datasets/Salesforce/EDR-200
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces Enterprise Deep Research (EDR), an AI system that works like a team of smart helpers to research complex questions for companies. Its job is to search across the web and private company data, gather trustworthy information, and turn it into clear, well-organized reports. A key idea is “steering”: humans can guide the system while it’s working—like giving directions to a GPS mid-trip—so it stays on track and answers the right question.
What questions did the paper try to answer?
The paper focuses on three simple questions:
- How can an AI do deep, long-term research (not just quick facts) that fits what a business actually needs?
- How can people guide the AI in real time and see where its information comes from?
- Can this approach beat other top systems on open-ended research tasks and work reliably inside companies?
How does EDR work?
Think of EDR as a well-organized research team where each AI “agent” has a role, and a project manager coordinates the work. Here’s the big picture, using everyday language and examples.
The “team” of agents
- Master Research Agent: the project manager. It breaks a big question into smaller tasks, picks which tool to use next, and keeps everything on schedule.
- Specialized search agents: different “experts” for different places:
- General web (news, blogs, reports)
- Academic papers (peer-reviewed research)
- GitHub (code and technical docs)
- LinkedIn (people and company info)
Staying on track with a shared to-do list
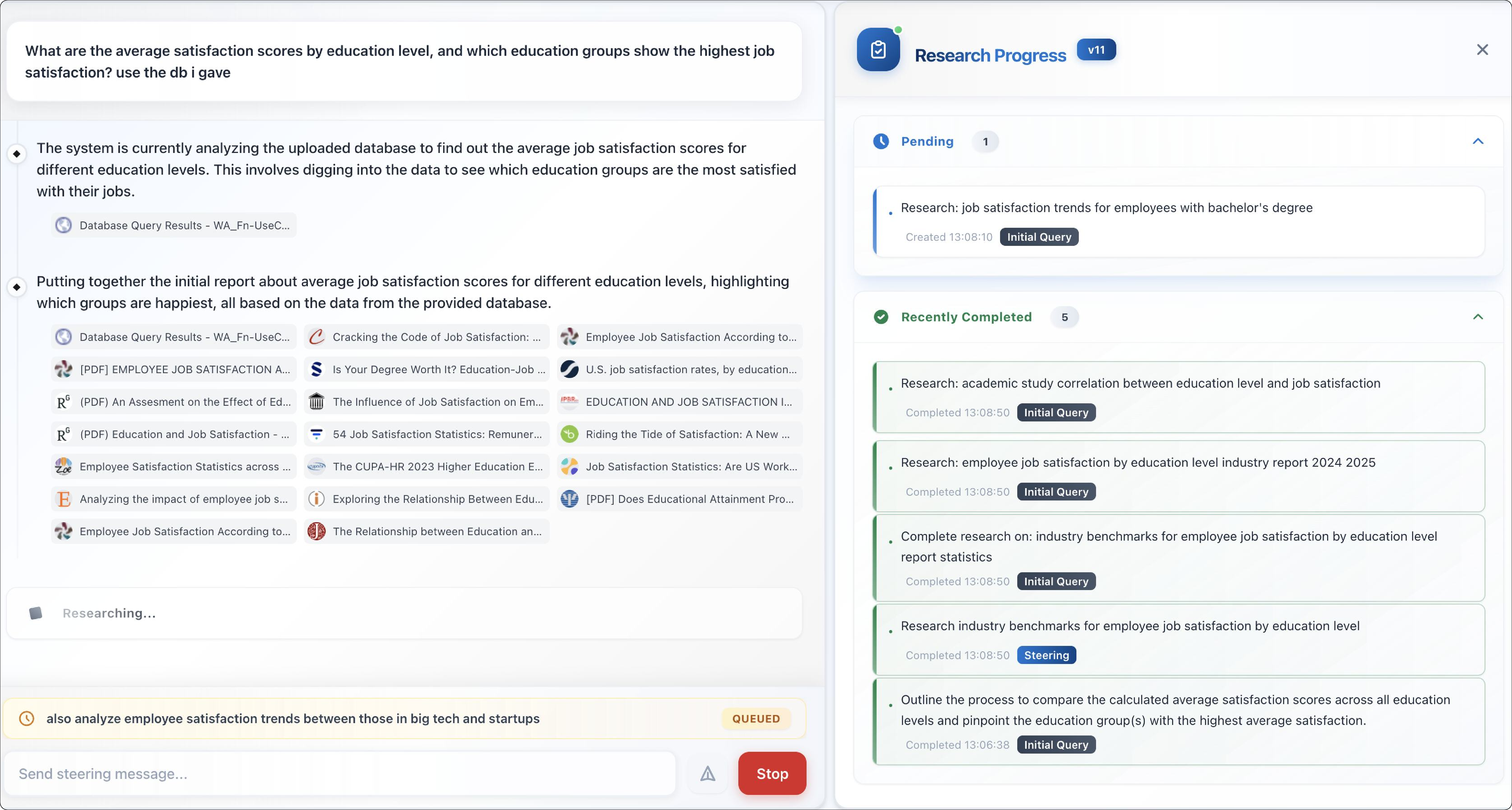
EDR keeps a live to-do list (called todo.md) that everyone—both the AI and the human user—can see. You can:
- Add or remove tasks
- Change priorities (for example, “focus on recent peer-reviewed papers”)
- See what’s done and what’s still missing
This makes the system transparent and steerable: you can adjust the plan while it’s running, instead of restarting from scratch.
Finding information from many places
EDR searches different sources depending on the task. It:
- Avoids duplicate links
- Rates relevance
- Keeps clean citations (so you know where each fact came from)
- Handles time-sensitive info (for example, “current CEO in 2025”)
Asking databases using normal language (NL2SQL)
If the data is inside a company database, EDR uses an NL2SQL agent—this translates a plain-language question (like “What were monthly sales in 2024 by region?”) into the right SQL query to pull the numbers safely and correctly.
Making sense of the findings and creating visuals
EDR doesn’t just collect links. It:
- Summarizes across many sources
- Tracks what’s already known and what’s still missing
- Makes charts (bar, line, heatmap, etc.) when numbers need visual explanation
Reflection: learning and adjusting every loop
After each round of searching, EDR “reflects”:
- What did we learn?
- What gaps remain?
- What should we do next? It updates the to-do list, reprioritizes tasks, and continues until the report is complete.
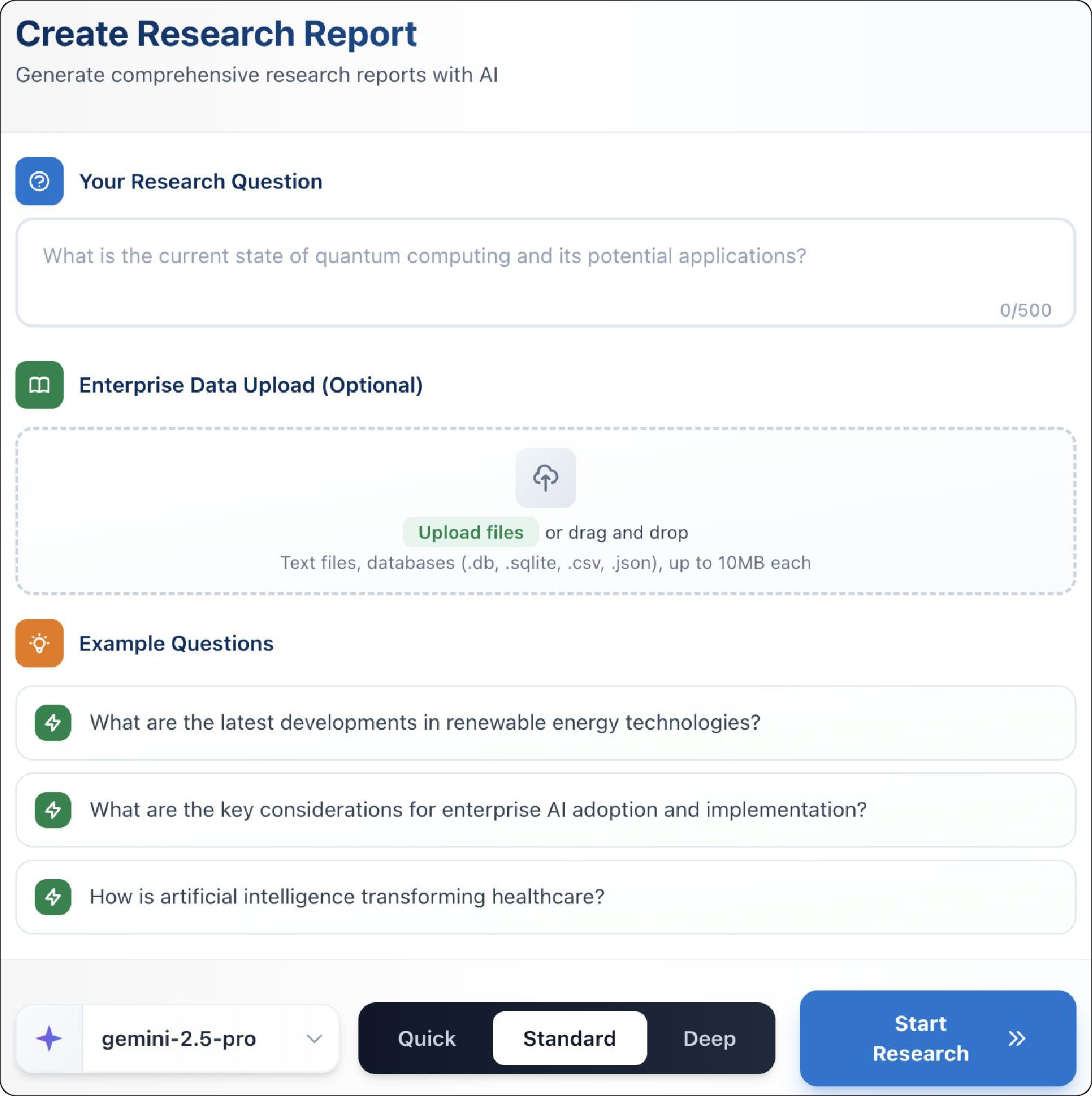
A quick example: If your prompt is “How is AI changing healthcare in 2025?,” EDR might first gather a broad overview, then dig into subtopics (like diagnosis tools, regulations, and costs), and finally compare evidence across sources, adding charts for spending trends. If you steer it—“focus on recent peer-reviewed papers”—it shifts its priorities right away.
What did the system find in tests?
EDR was tested on public benchmarks and inside a company setting:
- DeepResearch Bench (100 hard, PhD-level topics): EDR scored among the top systems overall, especially strong at following instructions and being readable.
- DeepConsult (business/consulting tasks): EDR had the highest win rate against a strong baseline, meaning judges preferred its reports most often.
- ResearchQA (scientific Q&A with rubrics): EDR was competitive but showed weaknesses with citations and examples on some scientific items—an area they plan to improve.
- Inside an enterprise: EDR was highly reliable (near 100% uptime), accurate at database queries, and helped users finish tasks faster with high satisfaction.
They also released their code and a dataset (EDR-200) containing full “trajectories” (step-by-step research logs) so others can study and improve long, complex AI research processes.
Why this matters and what’s next
EDR shows a practical way to do serious research with AI:
- It’s transparent: you can see the plan and sources at every step.
- It’s steerable: you can guide it mid-process to save time and avoid off-track results.
- It fits real business needs: it connects to company tools and data, not just public web pages.
- It builds trustworthy reports: with citations, summaries, and visuals.
Potential impact:
- Faster, clearer decision-making in companies
- Less guesswork and more evidence-based insights
- Better human–AI teamwork on complex, long-running projects
What’s next? The authors plan to improve citation handling, give better examples in scientific answers, and connect to more enterprise systems—making AI research even more dependable and useful for real-world analytics.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper that future work could address:
- Component ablations are absent: quantify the marginal contribution of the Master Research Agent, reflection, todo manager, visualization, and each specialized search agent by toggling/removing components and measuring deltas on RACE/CitAcc., cost, and latency.
- Real-time steering efficacy is untested: benchmarks were run with steering disabled; evaluate interactive settings (simulated and human) to measure gains in alignment, coverage, cost, and time-to-insight under varied steering policies and timing.
- Base-model dependence is unclear: assess performance-cost-latency sensitivity across multiple LLMs (proprietary and open-source, various sizes) and characterize failure modes that vary by model.
- Judge-model bias and reliability are not addressed: re-score with multiple judges (cross-model, majority voting), include human evaluation, report inter-rater agreement, confidence intervals, and significance tests.
- Citation handling is weak and underspecified: implement claim-level citation linking and verification (not just URL-level), evaluate on citation-grounding benchmarks (e.g., SCIFACT-like), and quantify fixes for the 85% citation failures observed on ResearchQA.
- Evidence attribution granularity is limited: move from URL-level provenance to passage/snippet-level support; evaluate precision/recall of evidence selection per claim.
- “Automated fact-checking” and “confidence scoring” are not operationalized: specify algorithms/criteria and validate calibration (reliability diagrams, ECE) against human-labeled ground truth.
- Source credibility modeling is missing: incorporate peer-review status, source type, recency, and site reputation; quantify effects on hallucination, CitAcc., and report quality.
- Deduplication/canonicalization quality is unmeasured: benchmark false merges/misses in inter-/intra-agent dedup and test stronger canonicalization and clustering techniques.
- Stopping criteria are heuristic: design principled termination rules based on marginal information gain/coverage estimates and evaluate cost–quality trade-offs vs fixed-loop settings.
- Cost–quality frontier is not characterized: sweep loops, top-k, and tool-call budgets to build Pareto curves and develop auto-budgeting policies for enterprise constraints.
- Failure-mode analysis is missing: produce a taxonomy (entity confusion, plan drift, tool failure, contradictory sources) and measure how reflection mitigates each category.
- Tool robustness under faults is untested: simulate API failures/timeouts/rate limits and report recovery effectiveness (retry, backoff, circuit breakers) and impact on outcomes.
- Security and privacy risks are not evaluated: red-team web/tool prompt-injection and data exfiltration paths; specify sandboxing, least-privilege, and data-flow controls for MCP tools; measure defense effectiveness.
- Compliance/governance is unspecified: detail access control, auditability beyond todo.md, data lineage, retention policies, and run evaluations in regulated contexts (e.g., HIPAA, SOX) with compliance metrics.
- MCP integration ergonomics and overhead are unclear: quantify developer effort, compatibility issues, versioning, latency overhead, and error propagation across connectors.
- NL2SQL evaluation lacks external baselines: validate on public benchmarks (Spider 2.0, BIRD), report schema generalization, SQL safety constraints, execution cost/latency, and compare to SOTA NL2SQL systems.
- Visualization correctness is unevaluated: measure data-to-viz fidelity (mislabeling, aggregation errors, misleading scales) with human raters and automated checks.
- Multimodal ingestion quality is untested: quantify OCR/table extraction accuracy on PDFs/images and propagate its impact on synthesis and final report fidelity.
- Recency sensitivity is not benchmarked: create time-sensitive tasks with known evolving answers; evaluate freshness, timeliness of sources, and decay over time.
- Bias and fairness are unaddressed: audit demographic and domain biases introduced by LinkedIn/GitHub/web sources; measure representational and topical skew and mitigation efficacy.
- Legal/ToS considerations for source sites are unexamined: assess compliance (e.g., LinkedIn/GitHub scraping), rate-limit adherence, and propose compliant alternatives (official APIs, datasets).
- Scalability and SLOs are not demonstrated: report throughput, latency, and tail behavior under concurrent enterprise workloads; show autoscaling behavior and queueing impacts.
- Long-context mitigation is not quantified: evaluate “lost-in-the-middle” reductions from context compression/summary techniques and their effect on recall and report completeness.
- Learning from trajectories is unexplored: use EDR-200 for imitation/RL to improve planning, reflection, and tool selection; validate gains and guard against overfitting or reward hacking.
- Multilingual capability is unknown: measure performance on non-English corpora (search, NL2SQL, synthesis) and the impact of cross-lingual retrieval.
- Deployment in constrained environments is untested: evaluate on-prem/offline modes, air-gapped networks, and no-web scenarios with only private corpora.
- Reproducibility is limited by proprietary models: provide open-model baselines, configuration details, seeds, and deterministic settings; quantify performance deltas to ensure replicability.
- Benchmark external validity for enterprise is uncertain: evaluate on enterprise-focused public tasks (e.g., DRBench) or release a masked/privatized enterprise benchmark to validate claims.
- Iteration scaling behavior is not mapped: plot performance vs loop count to identify diminishing returns and optimal stopping budgets for different task classes.
- Steering UX and human factors lack rigor: run controlled user studies to quantify cognitive load, error introduction, learnability, and productivity gains; compare novice vs expert steering.
- Confidence calibration is unvalidated: align confidence scores with empirical accuracy, add selective prediction/abstention, and measure coverage–accuracy trade-offs.
- Domain-transfer strategy is unclear: analyze performance by domain, identify gaps, and explore dynamic specialization (tool selection/prompting) learned from trajectories.
- Plagiarism and attribution integrity are not audited: check text reuse, paraphrase sufficiency, and citation completeness; add plagiarism detection and corrective policies.
- EDR-200 lacks error annotations: add labels for hallucination types, plan drift, duplication, and evidence sufficiency to enable supervised learning and diagnostic research.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can be implemented today using the released EDR framework, its MCP tool ecosystem, and the documented workflows.
- Evidence-backed market and competitive intelligence reports (Business, Finance)
- What: Generate battlecards, trend analyses, and competitor profiles with citations and charts.
- EDR pieces: Master Planning Agent + General/LinkedIn/GitHub search, reflection, Visualization Agent, provenance tracking (todo.md).
- Dependencies/assumptions: Web/API access (Tavily, GitHub), LinkedIn usage within ToS, human review for high-stakes decisions, LLM availability/cost budgets.
- Account planning and QBR pack generation inside CRM (Software/SaaS, Sales)
- What: Build account plans and quarterly business reviews by fusing CRM activity, product usage (via NL2SQL), and external news.
- EDR pieces: MCP connectors (CRM, data warehouse), NL2SQL Agent, Visualization Agent, steerable todo.
- Dependencies/assumptions: Data access controls/PII governance, schema introspection, secure SQL sandbox.
- Product feature adoption and opportunity analysis (Software, Product)
- What: Diagnose adoption patterns and surface growth opportunities from telemetry + external market signals.
- EDR pieces: NL2SQL Agent over analytics DBs, reflection for knowledge gaps, General/Academic search, Visualization Agent.
- Dependencies/assumptions: Clean schemas/metadata, access to product analytics, agreed KPI definitions.
- Procurement and vendor risk briefs (Procurement, Legal/Compliance)
- What: Rapid due diligence packs on vendors (leadership, funding, security posture, customer references).
- EDR pieces: General/LinkedIn/GitHub search, File Analysis (PDFs, DOCX), provenance tracking, reflection to fill gaps.
- Dependencies/assumptions: Legal review for claims, rate limits on sources, coverage of subscription databases if needed.
- Regulatory and policy monitoring digests (Financial services, Healthcare, Energy, Public sector)
- What: Weekly briefs that track new rules, guidance, enforcement actions; highlight impacts and required actions.
- EDR pieces: General/Academic search with recency prompts, steerable constraints (jurisdiction, regulator), citation list.
- Dependencies/assumptions: Access to authoritative legal/policy sources; human legal sign-off; scheduling.
- “Ask your data” BI copilot with charts (Enterprise Analytics)
- What: Natural-language questions answered with verified SQL and auto-generated visualizations.
- EDR pieces: NL2SQL Agent (validation, performance/safety checks), Visualization Agent, todo-driven revisions.
- Dependencies/assumptions: Database connectivity via MCP, query governance (cost/row limits), result verification.
- Literature review scaffolding with transparent evidence (Academia, R&D, Healthcare)
- What: Summarize topic landscapes, extract key papers, and build annotated bibliographies with links.
- EDR pieces: Academic Search, Stage-2/3 synthesis and citation management, reflection to close coverage gaps.
- Dependencies/assumptions: Access to paywalled content via institution or alternative APIs; address known citation fragility with human QC.
- Engineering research and RFC synthesis (Software/DevOps)
- What: Aggregate design options from RFCs, GitHub repos/issues, and blogs; produce architecture briefs.
- EDR pieces: GitHub Search, File Analysis, reflection to compare alternatives, Visualization Agent for trade-off tables.
- Dependencies/assumptions: GitHub API quotas, internal repo access via MCP, static-analysis outputs if available.
- Talent and expert mapping (HR/Recruiting, Consulting)
- What: Identify domain experts, assemble candidate shortlists, and summarize public signals of expertise.
- EDR pieces: LinkedIn Search (domain-restricted), GitHub Search, steerable filters (seniority, geography).
- Dependencies/assumptions: Platform ToS compliance, bias/fairness review, human-in-the-loop selection.
- Incident postmortems and ops reviews (IT/Ops, SRE)
- What: Compile incident timelines and root causes from logs/tickets, cross-check with known issues and fixes.
- EDR pieces: File Analysis (logs, PDFs), MCP connectors (ticketing/observability), reflection to identify missing evidence.
- Dependencies/assumptions: Secure connectors, role-based access, data retention policies.
- Customer knowledge base consolidation and FAQ refresh (Customer Success, Support)
- What: Merge docs/tickets into updated, citation-backed FAQs with change logs.
- EDR pieces: File Analysis, todo-based task tracking, citation and provenance.
- Dependencies/assumptions: Access to doc stores (Confluence/SharePoint) via MCP, de-duplication policies.
- Benchmarking and method evaluation with EDR-200 trajectories (Research, ML Ops)
- What: Train/evaluate agentic planners, reflection policies, and cost-control strategies using full trajectories.
- EDR pieces: Released EDR-200 dataset, open-source framework.
- Dependencies/assumptions: Compute resources, data licensing adherence, reproducible seeds/models.
Long-Term Applications
The following opportunities are feasible as the paper’s roadmap items mature (better citation fidelity, predictive steering, broader MCP integrations) and as organizations harden infra, governance, and cost controls.
- Continuous “horizon scanning” with predictive steering (Strategy, Policy, Corporate Foresight)
- What: Always-on signals monitoring that reprioritizes tasks automatically as weak signals strengthen.
- Dependencies/assumptions: Event-driven orchestration, budget caps, improved plan optimization.
- Clinical systematic reviews with evidence grading (Healthcare/MedTech)
- What: End-to-end PRISMA-like pipelines with risk-of-bias grading and audit trails.
- Dependencies/assumptions: Stronger citation handling, PubMed/ClinicalTrials integrations, medical QA oversight.
- Air-gapped, on-prem enterprise research agents (Gov/Defense, Financial services)
- What: Fully private deployments over sensitive data lakes and document stores.
- Dependencies/assumptions: High-quality local LLMs or model hosting, MCP to legacy systems, GPU/CPU scaling.
- Cross-modal research at scale (All sectors)
- What: Blend tables, scanned PDFs, figures, and images into unified evidence graphs.
- Dependencies/assumptions: Advanced document/layout parsers, robust multimodal LLMs, vector stores.
- Decision-support simulators that couple research with scenario modeling (Energy, Finance, Supply Chain)
- What: Link research insights to simulation models for “what-if” planning and policy impact analysis.
- Dependencies/assumptions: Model catalog integration, validation datasets, governance for model risk.
- Autonomous data governance auditor (Compliance, Risk)
- What: Map PII flows, policy conflicts, and lineage gaps across warehouses and apps.
- Dependencies/assumptions: Connectors to catalogs/lineage tools (Collibra, Purview), NL2SQL over audit logs, privacy-by-design.
- ResearchOps platform and “EDR-as-a-Service” marketplace (Software)
- What: Managed platform with plug-and-play MCP tools, cost telemetry, and fine-grained RBAC.
- Dependencies/assumptions: MCP standard adoption, partner ecosystem, enterprise SLAs and observability.
- Real-time supply-chain and third-party risk monitoring (Manufacturing, Retail, Pharma)
- What: Streaming alerts on supplier health, disruptions, and ESG controversies with traceable sources.
- Dependencies/assumptions: Event ingestion (news, filings), deduplication at scale, analyst-in-the-loop triage.
- Codebase-wide refactoring and dependency risk advisor (Software)
- What: Synthesize multi-repo insights to propose modernization plans and security upgrades.
- Dependencies/assumptions: Deep static/dynamic analysis integrations, SBOM/OSS license databases.
- Financial research copilot with alternative data (Finance)
- What: Blend filings, news, job boards, web traffic, and satellite/ship data for theses with provenance.
- Dependencies/assumptions: Alt-data vendor contracts, compliance (MNPI, research rules), stronger citation chains.
- Legal discovery and brief drafting with auditable provenance (Legal)
- What: Evidence clustering across case law, dockets, and discovery materials; draft briefs with exhibits.
- Dependencies/assumptions: Legal DB access (Westlaw/Lexis), strict citation accuracy, privilege controls.
- Personalized career and learning navigator (Education, Daily life)
- What: Multi-source pathway planning (skills gaps, roles, programs, mentors) with labor-market updates.
- Dependencies/assumptions: High-quality LinkedIn/education data, bias mitigation, user-consent data handling.
- Scientific discovery co-pilot for lab workflows (R&D, Robotics/Lab Automation)
- What: Plan experiments from literature, integrate lab results, and adapt hypotheses iteratively.
- Dependencies/assumptions: MCP to ELNs/LIMS/instrument APIs, safety constraints, reproducibility tracking.
- Multilingual, jurisdiction-aware policy assistant (Policy, International organizations)
- What: Comparative policy synthesis across languages and legal systems with localized implications.
- Dependencies/assumptions: Strong multilingual LLMs, localized sources, cultural/regulatory nuance handling.
Notes on feasibility and alignment
- Model dependence: Results vary by base LLM; the paper’s strongest results use gemini-2.5-pro. Cost/performance trade-offs must be managed.
- Citation reliability: ResearchQA highlights weaknesses in citation handling and examples; high-stakes domains require human verification and/or improved citation chains.
- Data governance: MCP integrations must respect PII, data residency, and vendor ToS (e.g., LinkedIn).
- Ops and scaling: The todo-driven steering and iterative loops are powerful but compute-intensive; apply priority scheduling, caching, and rate-limit strategies.
- Human-in-the-loop: Steerable context is a core design feature; organizations should design review points and escalation paths rather than aiming for full autonomy in regulated settings.
Glossary
- Adaptive Query Decomposition: Dynamically breaking complex queries into smaller, targeted sub-queries based on context and intermediate results. "a Master Planning Agent for adaptive query decomposition"
- Agentic Systems: Autonomous, LLM-driven systems that plan, act, and reason to accomplish tasks with minimal human intervention. "EDR outperforms state-of-the-art agentic systems without any human steering."
- Anthropic’s notion of thinking in context: A paradigm that emphasizes maintaining and manipulating the active context to guide reasoning and decisions. "Drawing on Anthropicâs notion of thinking in context"
- Citation Normalization: Standardizing citation formats (e.g., URLs, titles) across sources to ensure consistency and reliability. "Citation normalization ensures consistent URL and title formatting, with priority given to the highest-quality representation of each unique source."
- Confidence Scoring: Assigning a reliability score to findings or outputs based on validation and evidence. "semantic consistency validation, cross-agent result comparison, automated fact-checking, and confidence scoring."
- Context Compression: Summarizing and condensing collected information while preserving key insights and references to fit within LLM context limits. "The LLM performs context compression, extracting key insights while preserving citation links and metadata."
- Context Curation: Intentionally selecting and shaping what information enters an agent’s attention to influence its decisions. "Steering occurs at the context curation layerâdirectly influencing what information enters the agentâs attention at each decision pointârather than through pre-specified constraints or post-hoc corrections"
- Conversation-oriented tool-calling agents: Systems primarily focused on interactive dialogues that invoke tools during conversation, often lacking deep research capabilities. "far beyond the scope of typical RAG systems or conversation-oriented tool-calling agents"
- Deduplicated Dictionary: A unique-source index that maps URLs to metadata while removing duplicates for clean citation tracking. "Extracted sources are tracked in a deduplicated dictionary, maintaining URL-to-metadata mappings for downstream report generation."
- Function Calling: Structured invocation of predefined tool or function interfaces by an LLM to perform specific actions. "Leveraging function calling and context-aware prompt engineering, the agent performs adaptive query decomposition, intent classification, and entity extraction."
- Fuzzy Matching: Approximate string comparison used to detect near-duplicates or overlaps despite variations. "though fuzzy matching provides a safety net for any remaining overlaps."
- Human-in-the-loop: Allowing real-time or iterative human guidance within an automated system’s decision-making process. "with optional human-in-the-loop steering guidance."
- Intent Alignment: Ensuring the system’s outputs and actions match the user’s goals and constraints. "they often struggle with domain-specific nuances, intent alignment, and enterprise integration."
- Lost-in-the-middle: An LLM limitation where information in the middle of long contexts is overlooked or underweighted. "mitigates lost-in-the-middle issues"
- MCP (Model Context Protocol): A protocol for connecting LLM agents to external tools and enterprise systems with standardized transport. "EDR supports extensible integration through the Model Context Protocol (MCP), enabling connection to custom enterprise systems, remote computation services, and additional domain tools."
- NL2SQL: Automatic translation of natural-language queries into SQL for database interrogation. "nl2sql for database queries"
- Orchestration: Coordinating multiple agents and tools to execute complex workflows coherently. "engineered for scalability, robustness, and adaptive orchestration of complex research workflows"
- Priority-based Scheduling: Executing tasks in an order determined by their importance to maximize impact and efficiency. "Priority-based scheduling ensures high-impact research items are addressed first"
- Provenance: The origin and lineage of information or sources to support auditability and trust. "users cannot inspect intermediate reasoning states, source provenance, or decision trajectories once execution begins."
- RAG (Retrieval-Augmented Generation): Enhancing generation with retrieved external knowledge to improve factuality and coverage. "retrieval-augmented generation (RAG)"
- Race-condition-safe: Designed to avoid concurrency issues where multiple events interfere with each other unpredictably. "queue-based, race-condition-safe steering mechanism"
- Reflection Mechanism: A process that evaluates progress, identifies knowledge gaps, and updates plans iteratively. "a reflection mechanism that detects knowledge gaps and updates research direction"
- Sandboxed Execution Environments: Isolated runtimes used to safely render or execute code and visualizations. "Visualizations are rendered in sandboxed execution environments"
- Schema Awareness: Understanding database schema structures to generate valid and efficient queries. "Incorporates schema awareness, query decomposition, multi-layered validation (syntax, semantics, performance, security), and result interpretation."
- Semantic Consistency Validation: Checking that synthesized outputs are logically and meaningfully consistent across sources. "Mechanisms include semantic consistency validation, cross-agent result comparison, automated fact-checking, and confidence scoring."
- Semantic Deduplication: Removing redundant items using meaning-based similarity rather than exact string matches. "semantic deduplication prevents redundant searches by fuzzy string matching with prefix normalization"
- Snapshot-based Merging: Preserving and merging queued updates safely by working with consistent state snapshots. "the system employs snapshot-based merging"
- Steerable Context Engineering: Designing mechanisms for users to dynamically modify the agent’s context during execution. "EDR formalizes steerable context engineering, enabling humans to modify agent context dynamically during execution."
- Temporal Weighting: Emphasizing more recent information in retrieval and ranking to reflect recency needs. "optional temporal weighting to emphasize recent research."
- Top-k Result Retrieval: Selecting the top-ranked k results from search to prioritize relevance and quality. "Implements top-k result retrieval with full content extraction, semantic deduplication, and relevance scoring."
- Version-based Polling: Updating clients only when a state version changes to provide real-time visibility efficiently. "This version-based polling provides real-time visibility into task status and provenance without continuous state streaming"
Collections
Sign up for free to add this paper to one or more collections.

