WebResearcher: Unleashing unbounded reasoning capability in Long-Horizon Agents
Abstract: Recent advances in deep-research systems have demonstrated the potential for AI agents to autonomously discover and synthesize knowledge from external sources. In this paper, we introduce WebResearcher, a novel framework for building such agents through two key components: (1) WebResearcher, an iterative deep-research paradigm that reformulates deep research as a Markov Decision Process, where agents periodically consolidate findings into evolving reports while maintaining focused workspaces, overcoming the context suffocation and noise contamination that plague existing mono-contextual approaches; and (2) WebFrontier, a scalable data synthesis engine that generates high-quality training data through tool-augmented complexity escalation, enabling systematic creation of research tasks that bridge the gap between passive knowledge recall and active knowledge construction. Notably, we find that the training data from our paradigm significantly enhances tool-use capabilities even for traditional mono-contextual methods. Furthermore, our paradigm naturally scales through parallel thinking, enabling concurrent multi-agent exploration for more comprehensive conclusions. Extensive experiments across 6 challenging benchmarks demonstrate that WebResearcher achieves state-of-the-art performance, even surpassing frontier proprietary systems.
First 10 authors:
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “WebResearcher: Unleashing unbounded reasoning capability in Long-Horizon Agents” for a 14-year-old
Overview: What is this paper about?
This paper is about building smarter AI “researchers” that can search the web, check facts, and write clear reports without getting confused or overwhelmed. The authors created a system called WebResearcher that helps AI think in steps, keep clean notes, and use tools (like web search or Python code) to solve hard problems. They also built a way to generate great practice problems so the AI can learn these skills.
Objectives: What questions are they trying to answer?
The paper focuses on two big questions:
- How can an AI do long, complicated research without getting lost in too much information?
- How can we create lots of high-quality training tasks so the AI learns how to find facts, combine ideas, and prove its answers?
It also explores:
- How to let multiple AIs work in parallel and then combine their findings into one strong final answer.
- Whether this new approach can beat other top AI systems on tough tests.
Methods: How does WebResearcher work?
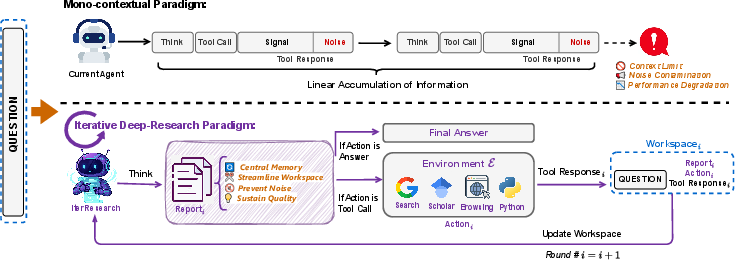
Think of the AI like a student doing a science project. If the student dumps every note onto one crowded desk, they’ll run out of space and make mistakes. WebResearcher avoids this by keeping a tidy “workspace” and rewriting a clear summary after each step.
Here are the main ideas, explained with everyday analogies:
- IterResearch (the step-by-step thinking loop)
- Imagine a turn-based game. In each turn (or “round”), the AI:
- Thinks: It plans what to do next.
- Reports: It writes a short, clean summary of what it has learned so far, like a high-quality notebook entry.
- Acts: It does something concrete, like searching the web or running code.
- After each round, the AI rebuilds its workspace using only the essentials: the original question, its updated report, and the latest tool result. This keeps the “desk” neat and prevents messy, noisy notes from piling up.
- Markov Decision Process (MDP), in simple terms
- This is just a fancy way to say the AI makes decisions step by step, based on what it currently knows. Like playing chess: you look at the board now, plan your move, then update the board and repeat.
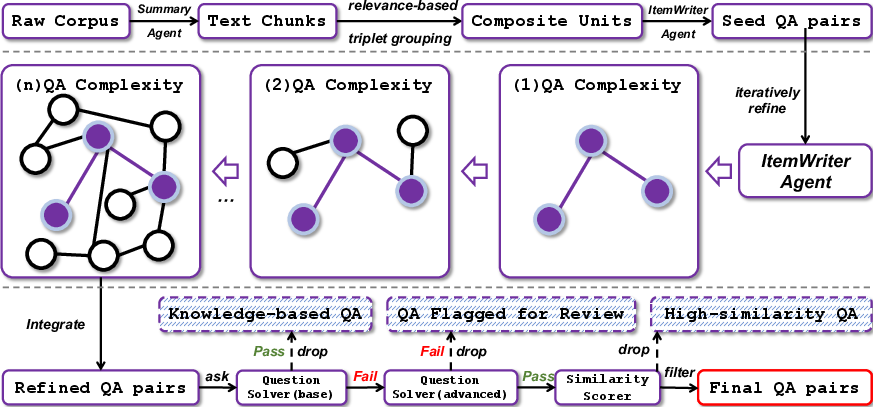
- WebFrontier (the training data engine)
- To train the AI, you need good practice problems. The authors built a system that:
- 1. Starts with real documents (webpages, papers, e-books) and creates basic questions.
- 2. Uses tools (web search, academic search, browsing, Python) to make the questions harder and more interesting—like turning a simple math problem into a real-world data task.
- 3. Checks quality by making sure simple models can’t solve them, but tool-using models can. Bad or confusing questions are thrown out or reviewed.
- Training the AI
- Rejection Sampling Fine-Tuning: The AI generates full step-by-step solutions, and the system only keeps the ones that match the correct answer—like practicing math and only studying your correctly solved problems.
- Reinforcement Learning: The AI learns from many rounds per problem, improving its choices and summaries over time—like getting feedback after each step, not just at the end.
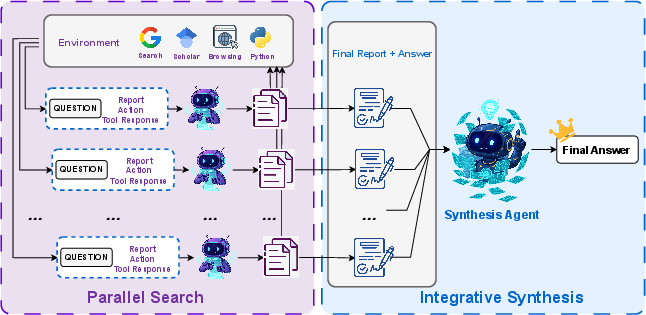
- Research-Synthesis (teamwork at test time)
- First, several AIs explore different ways to solve the same problem. Each one produces a final report and answer.
- Then, a “synthesis” AI reads these reports and writes the best overall conclusion. This is like a group project where everyone tries their idea, and an editor combines the best parts.
- Tools the AI uses
- The system includes tools that help the AI:
- Search and Scholar: Find web pages and academic papers.
- Visit: Read and summarize specific pages based on a goal (e.g., “find the results”).
- Python: Run code for calculations or simulations.
Findings: What did they discover, and why does it matter?
The authors tested WebResearcher on several tough benchmarks (challenge sets). The system performed extremely well—often better than big-name AIs.
Highlights:
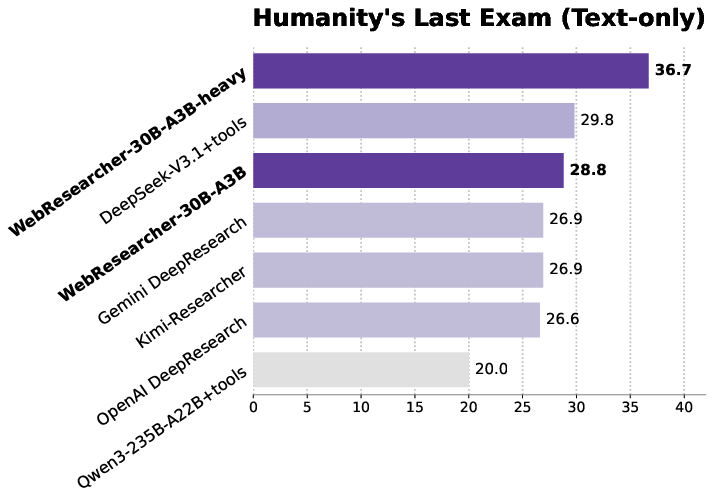
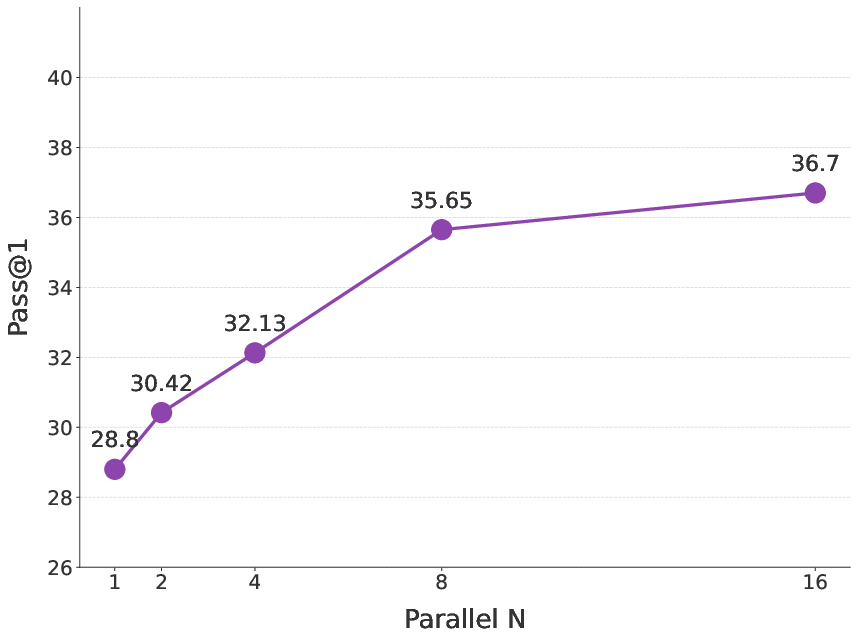
- Humanity’s Last Exam (HLE): WebResearcher-heavy scored 36.7%, beating other strong systems.
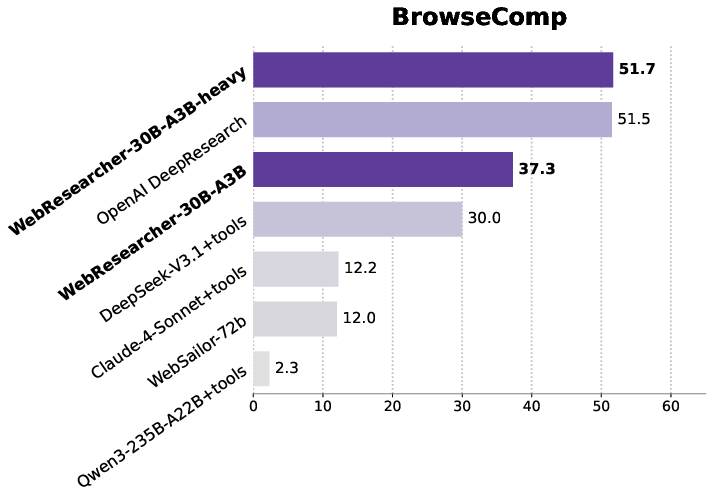
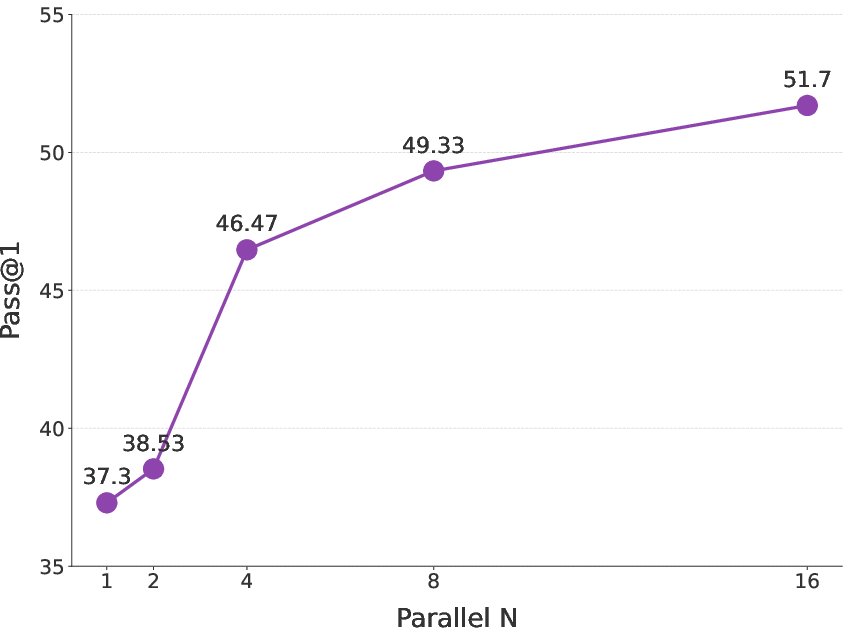
- BrowseComp-en (complex web browsing): 51.7%, matching or beating top proprietary systems.
- GAIA (difficult real-world tasks): 72.8%, ahead of many leading models.
- Xbench-DeepSearch and FRAMES: Strong results, showing reliable fact-finding and multi-step reasoning.
Why this matters:
- The step-by-step, “clean report” approach avoids common problems:
- Cognitive suffocation: When a single giant context gets too full, the AI stops thinking deeply.
- Noise contamination: Early mistakes or irrelevant info stick around and cause more errors.
- By keeping a focused workspace and updating a clean summary each round, the AI reasons better over long tasks.
- The training data generator (WebFrontier) creates realistic, challenging problems that make the AI smarter—and even improves other systems when they train on this data.
Implications: What could this change?
- Smarter AI researchers: Systems like WebResearcher could help scientists, journalists, students, and analysts explore complex topics, check facts, and write high-quality reports.
- Better long-term thinking: The iterative method lets AI handle bigger tasks without getting overwhelmed.
- Teamwork at scale: Parallel research plus synthesis shows how multiple AIs can collaborate to find stronger answers.
- Training improvements: The data engine provides a path to create more advanced practice tasks, pushing AI beyond memorizing facts toward building new knowledge.
- Responsible use: Because the AI relies on sources and tools, it encourages verification and clear evidence—important for trust and accuracy.
In short, WebResearcher shows that organizing AI research into tidy rounds with evolving summaries—and training it on carefully crafted tasks—can make AI much better at real, long-horizon thinking.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, phrased to guide concrete follow-up research.
- Reinforcement learning signal is under-specified: the per-round reward r_{g,j} and its source (e.g., judge score, correctness proxies, trajectory-level credit assignment) are not defined, leaving credit assignment and stability unclear.
- Markov-state sufficiency is unverified: discarding all but the evolving report and last tool response may lose essential long-range details; experiments quantifying information loss and recovery are absent.
- No quantitative evidence for “context suffocation” and “noise contamination” claims; metrics or controlled stress tests comparing iterative vs. mono-contextual scaling with context growth are missing.
- Termination criteria for iterative rounds are unspecified (max rounds, stopping rules, deadlock detection); failure behavior and recovery strategies are not described.
- “Heavy” configuration is undefined (e.g., number of agents, rounds, token budgets, tool caps); reproducibility and cost interpretability suffer without explicit knobs and resource accounting.
- Test-time scaling via Research-Synthesis lacks scaling laws: accuracy vs. number of agents n, latency, cost, and diminishing returns are not characterized.
- Conflict resolution in the Synthesis phase is unspecified: no method for weighting evidence, adjudicating contradictory reports, or estimating consensus reliability.
- Confidence calibration is absent: no uncertainty estimates, self-consistency checks, or evidence scoring accompany final answers or synthesized reports.
- Tool-set generality is untested: performance with additional or domain-specific tools (APIs, databases, authentication-gated content, forms) and interactive workflows remains unknown.
- Robustness to adversarial or hostile web content (prompt injection, SEO spam, misinformation, dynamic/JS-heavy pages, CAPTCHAs/paywalls) is not evaluated; no defenses or mitigations are documented.
- The Visit tool’s goal-oriented summarization may hallucinate or omit critical details; extraction fidelity, quotation accuracy, and citation coverage are not audited.
- Live-web dependence threatens reproducibility: no snapshotting/archiving, caching policies, or timestamped corpora are reported to enable repeatable experiments.
- Data engine scope and release are unclear: dataset size, domain/language distribution, licensing, and public availability are not specified; potential training–test contamination is unaddressed.
- Quality control may entrench model biases: filtering by a particular tool-augmented solver risks overfitting the dataset to that solver’s strengths; cross-model transferability is not studied.
- Human oversight in data curation is under-described: rates of human intervention, guidelines, QA procedures, and inter-annotator agreement are not reported.
- Multimodality is largely unexplored: most experiments restrict to text-only subsets; integration of images, figures, tables, and scanned PDFs is untested.
- Language coverage is limited (primarily English/Chinese); performance on low-resource languages and truly cross-lingual retrieval/synthesis remains open.
- Evaluation relies on LLM-as-a-Judge without calibration: judge identity, prompts, agreement with human judgments, and bias analyses are not provided.
- Baseline comparability is uncertain: several reference numbers are from official reports with differing protocols; matched re-evaluations under identical tool access and settings are missing.
- Statistical rigor is lacking: no confidence intervals, multi-seed variance, or significance tests are reported; stability under sampling temperature/top-p is not analyzed.
- Compute/energy cost is not reported (tool-call counts, tokens processed, wall-time, GPU-hours), preventing cost-effectiveness and carbon impact assessment.
- Python sandbox security details are absent (network/file isolation, package whitelist, time/memory limits); risks of code injection or data exfiltration are not addressed.
- Legal/privacy compliance for web access is not discussed (robots.txt adherence, consent, licensing of scraped content, storage policies).
- Theoretical claims (monotonic information gain, unbounded research depth) lack formal guarantees or error-propagation analysis across iterative report revisions.
- Failure-mode analysis is minimal: no taxonomy, case studies, or diagnostics for when IterResearch fails relative to mono-context agents; no fallback/rollback strategies are proposed.
- No comparison to alternative memory mechanisms (vector databases, structured note-taking, external knowledge bases) or hybrids combining iterative synthesis with retrieval memory.
- Overfitting risks in RFT/GSPO are unexamined: rejection sampling may favor spurious but matching trajectories; safeguards against reward hacking or shortcut learning are not discussed.
- Tool-use policy learning is opaque: how the model learns when to search vs. code vs. read is unclear; ablations disabling individual tools or perturbing tool outputs are missing.
- Chain-of-thought exposure and safety are not considered: training/inference policies for Think content (privacy, prompt injection risks, controllable disclosure) are unspecified.
- Benchmark breadth is narrow: limited real-user studies, longitudinal tasks on evolving topics, or deployment-style evaluations with noisy constraints.
- Generalization beyond web research (e.g., scientific experiment design, software engineering pipelines, robotics/planning) is untested and remains an open direction.
Collections
Sign up for free to add this paper to one or more collections.

