Name That Part: 3D Part Segmentation and Naming
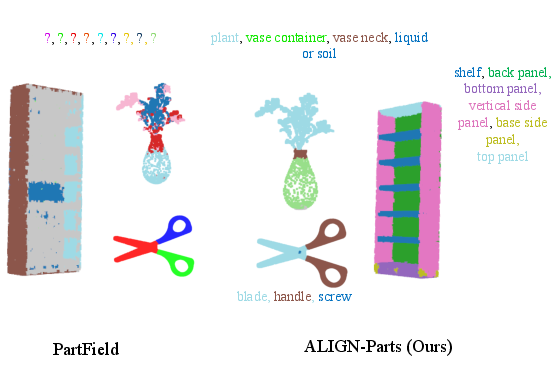
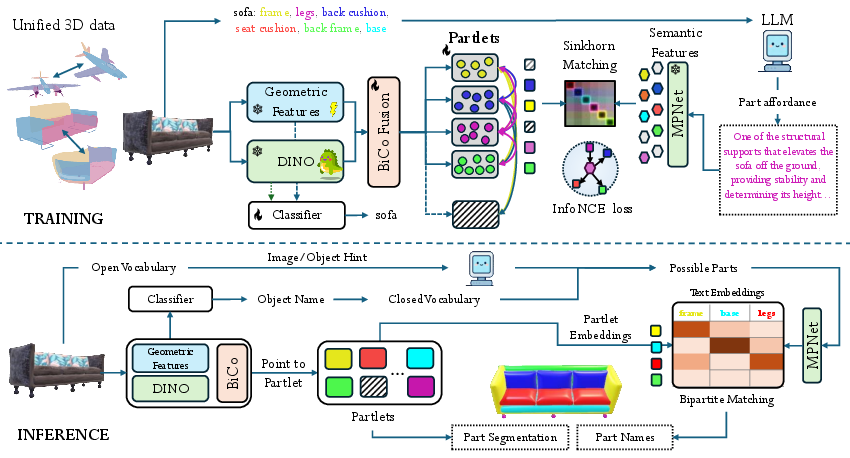
Abstract: We address semantic 3D part segmentation: decomposing objects into parts with meaningful names. While datasets exist with part annotations, their definitions are inconsistent across datasets, limiting robust training. Previous methods produce unlabeled decompositions or retrieve single parts without complete shape annotations. We propose ALIGN-Parts, which formulates part naming as a direct set alignment task. Our method decomposes shapes into partlets - implicit 3D part representations - matched to part descriptions via bipartite assignment. We combine geometric cues from 3D part fields, appearance from multi-view vision features, and semantic knowledge from language-model-generated affordance descriptions. Text-alignment loss ensures partlets share embedding space with text, enabling a theoretically open-vocabulary matching setup, given sufficient data. Our efficient and novel, one-shot, 3D part segmentation and naming method finds applications in several downstream tasks, including serving as a scalable annotation engine. As our model supports zero-shot matching to arbitrary descriptions and confidence-calibrated predictions for known categories, with human verification, we create a unified ontology that aligns PartNet, 3DCoMPaT++, and Find3D, consisting of 1,794 unique 3D parts. We also show examples from our newly created Tex-Parts dataset. We also introduce 2 novel metrics appropriate for the named 3D part segmentation task.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
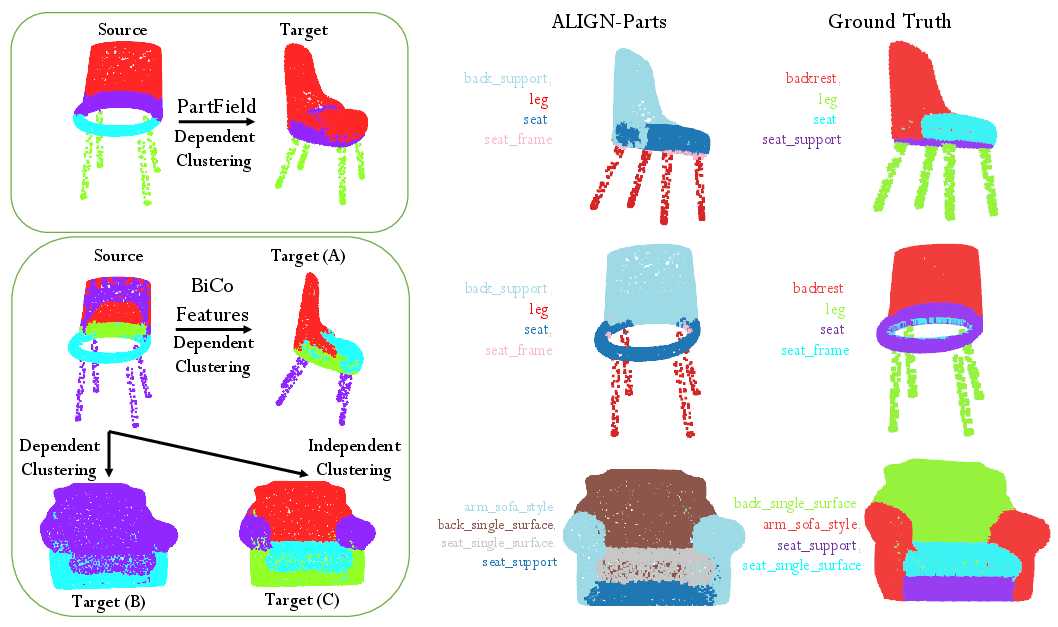
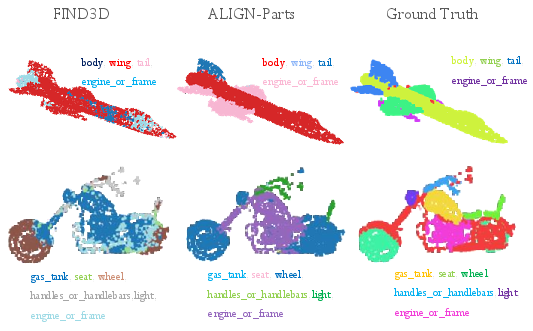
This paper is about teaching computers to look at a 3D object (like a chair, a car, or a plane), split it into its different parts (seat, wheels, wings, etc.), and give each part the right name. The authors built a method called ALIGN-Parts that can do both steps—cutting the object into parts and naming them—quickly and in one go.
What questions were they trying to answer?
Here are the main questions the paper tackles:
- How can we split a 3D object into meaningful parts and give those parts correct names, all at the same time?
- How can we make the computer understand parts in a human-like way (for example, a “seat” is a flat surface where you sit), not just by shape?
- How can we make this work even for new objects or parts the system hasn’t seen before?
- How can we create a consistent list of parts across different datasets that sometimes use different names for the same thing?
How did they approach the problem?
Breaking objects into “partlets”
Instead of deciding the label for every tiny point on the object separately, the method first creates a small number of smart part proposals called “partlets.” You can think of partlets like smart baskets:
- Each partlet gathers the points that belong to one part (like all points that make up the “seat”).
- Each partlet also carries a kind of “name tag” that says what it might be.
Then, the system matches these partlets to a list of possible part names—one name per partlet—so every part gets a single, best-fitting name.
Using three kinds of clues
To figure out the parts and their names, the system blends three types of information:
- Geometry: The shape of the object in 3D (for example, “flat and horizontal” suggests a seat).
- Appearance: What the object looks like from different camera views (textures or colors can help tell parts apart).
- Language: Human-friendly descriptions about what each part does (called “affordances”), like “the part you grasp to open the door” for a door handle.
The language descriptions are written by a LLM and turned into numbers (embeddings) so the computer can compare them to the partlets.
Matching parts to names
The system lines up the partlets with the best-fitting descriptions in a single step. This makes two important things happen:
- It’s fast, because it matches a few partlets to names, not every point.
- It’s consistent, because each predicted part gets at most one name, and each name is used only once.
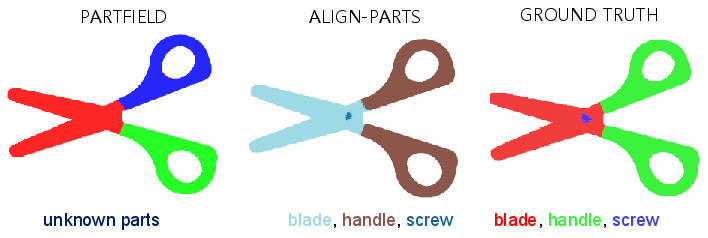
It can also work in “open vocabulary” mode, which means users can provide any set of part descriptions (even new ones), and the system can match parts to those names without retraining.
Making a shared list of parts and a new dataset
Different 3D datasets sometimes use different names for the same part. The authors built a unified part list (an “ontology”) across three big datasets (PartNet, 3DCoMPaT++, and Find3D), covering 1,794 unique parts. They also used ALIGN-Parts to help label a new collection called Tex-Parts, with 8,450 objects and around 14,000 part categories, using human checks only where the system wasn’t confident.
What did they find?
Here are the most important results:
- The method segments and names all parts in a single, feed-forward pass—no need for multiple steps or extra prompts.
- It runs fast: about 100× quicker at producing named segments than a strong geometry-only approach (PartField), after data prep.
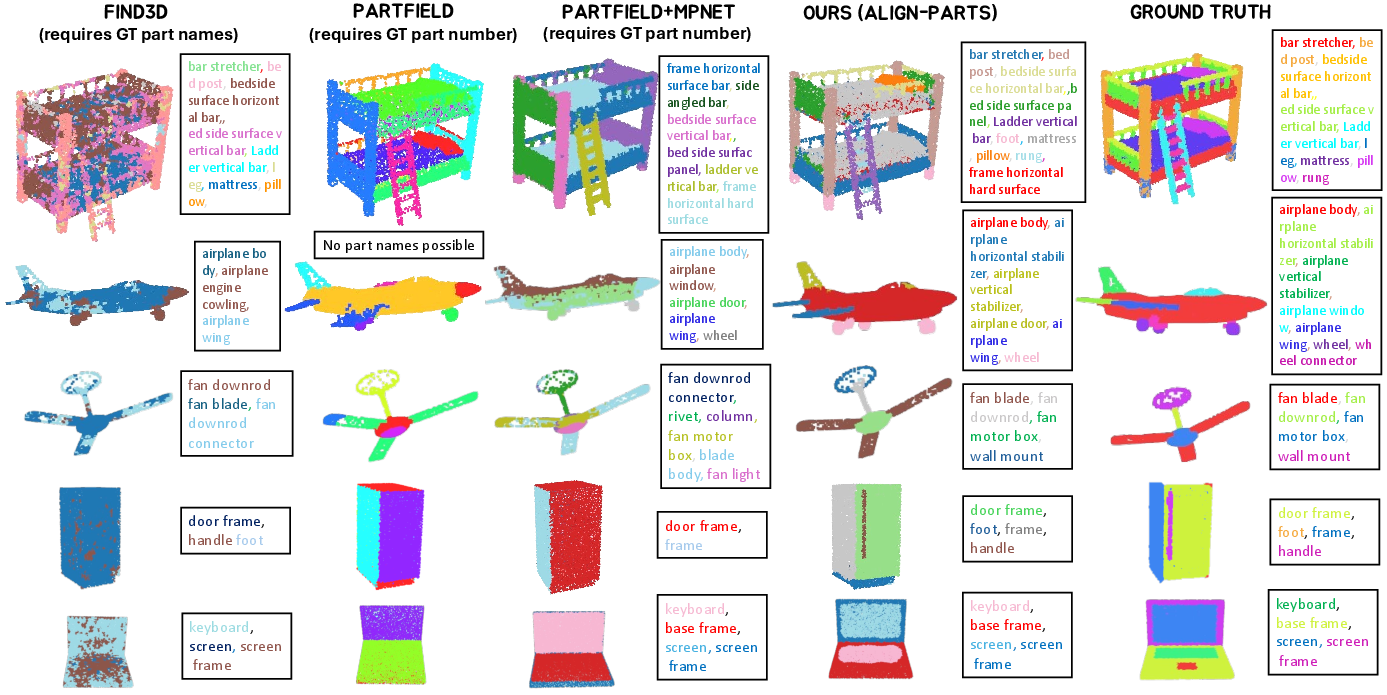
- It works for both known object categories and new ones (open vocabulary), because it matches parts to text descriptions on the fly.
- It handles small, tricky parts (like handles) and keeps parts from overlapping, giving clean, non-overlapping results.
- It reduces the human effort needed for labeling by 5–8×, thanks to confidence scores that only flag uncertain predictions for review.
- It unifies part names across datasets, creating consistent training data and making comparisons fairer.
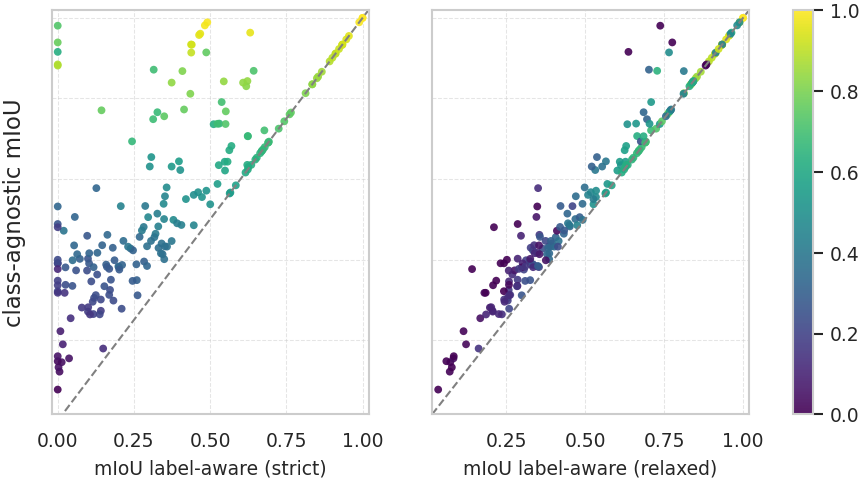
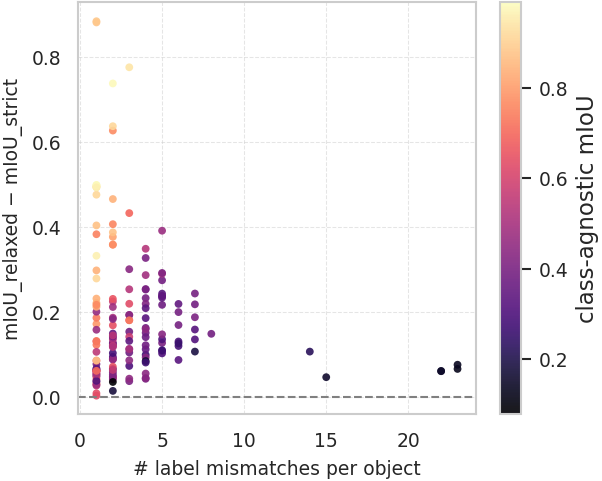
- It introduces two new evaluation metrics that check both the quality of the part boundaries and whether the names are semantically correct (one strict metric and one relaxed metric that gives partial credit for close matches like “screen” vs. “monitor”).
Why is it important?
This research makes 3D understanding more practical and human-friendly. It can help:
- Robotics: A robot can locate and name parts like “handle,” “button,” or “leg” to interact safely and correctly.
- Game and movie creation: Artists can quickly edit or replace specific parts of 3D assets.
- AR/VR and digital twins: Systems can recognize and label parts for repair, training, or simulation.
- Big 3D libraries: Companies can automatically organize and search large collections of 3D models by parts.
- Future AI systems: It provides a faster, scalable way to create high-quality training data by proposing named parts and letting humans verify only uncertain cases.
Overall, ALIGN-Parts moves beyond just cutting objects into shapes—it connects parts to their meaning and purpose, making 3D AI smarter, faster, and more useful in the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, framed to guide future work:
- Open-vocabulary generalization is only partially demonstrated: novel-category evaluation is small (8 objects) and still depends on user/LLM-proposed candidate part lists; the method’s performance under truly open-world, noisy or incomplete candidate sets is not quantified.
- Dependency on LLM-generated affordance descriptions is unexamined: no analysis of description quality, bias, stability across prompts/LLM versions, or how description errors propagate to segmentation and naming.
- Text encoder choice (MPNet) is fixed and non-trainable: no study of domain adaptation, multi-lingual support, fine-tuning strategies, or robustness to paraphrases/synonyms beyond the MPNet space; rLA-mIoU depends on MPNet cosine similarity without human validation.
- Candidate-part generation for unseen categories lacks a principled mechanism: there is no algorithmic way to propose, prune, or rank parts for novel objects without human/LLM intervention, and the effect of overcomplete or noisy candidate lists on precision/recall is untested.
- Instance multiplicity is unsupported by design: the bipartite matching enforces “each name used at most once,” preventing separate instance-level labeling of repeated parts (e.g., four legs), which many applications and datasets require; extending to part-category and instance-level segmentation is open.
- Hierarchical part structure is not modeled: overlapping/parent-child relations (e.g., handle composed of subcomponents) are disallowed by the exclusivity/overlap loss, limiting applicability to layered or hierarchical parts common in CAD and real objects.
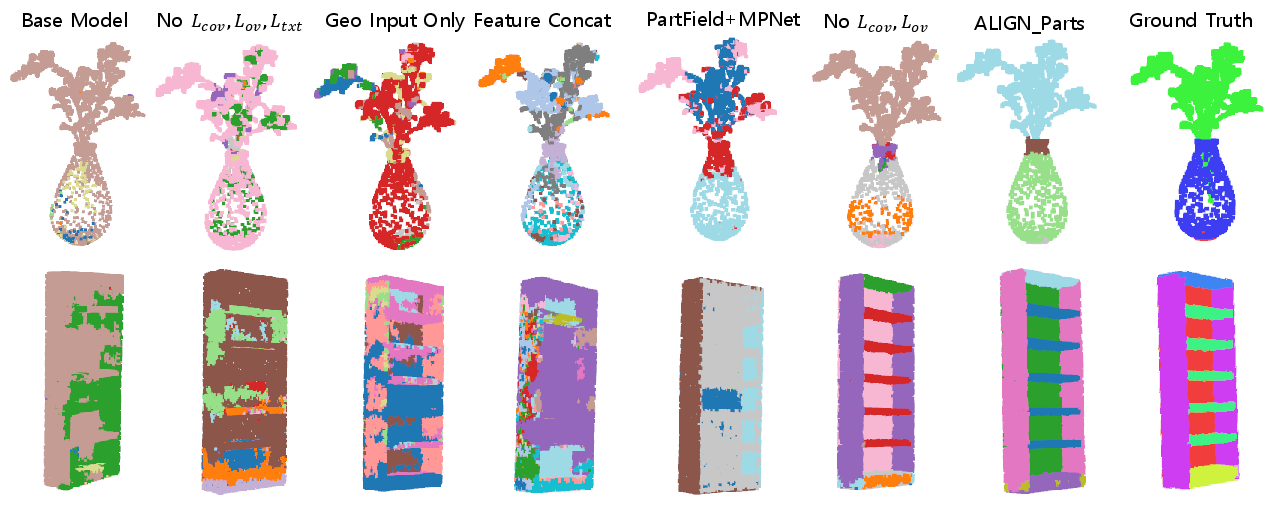
- Sensitivity to K=32 Partlets is not ablated: behavior under objects with far more/fewer parts, dynamic K selection, and trade-offs between over-/under-segmentation and runtime are not studied.
- Fusion and alignment hyperparameters are unexamined: no sensitivity analysis of k-NN size, the geometry/semantics cost weights in OT, InfoNCE temperature, overlap/coverage loss weights, or partness thresholds.
- Generalization to real-world scans is unclear: the method is trained/evaluated on clean CAD-like data with multi-view renders; robustness to sensor noise, partial observations, non-textured meshes, missing UVs, and scene clutter is untested.
- Rendering/appearance dependence is a practical limitation: performance when texture is absent, low-quality, or misleading (style/material domain shift) is not quantified; inner/occluded parts not visible in renders are not addressed.
- Runtime claims exclude preprocessing: speedups do not account for mesh normalization, multi-view rendering, and 2D feature lifting; end-to-end wall-clock cost comparisons (including preprocessing) and scaling with number of views/candidates are missing.
- Confidence calibration is limited to closed-vocabulary: Mahalanobis-based calibration requires class-conditional statistics from training categories; calibration under open-vocabulary settings (and alternatives like deep ensembles, temperature scaling across categories) is not evaluated.
- Ontology unification via LLMs lacks quality assurance: no precision/recall or error analysis of merges/splits, handling of granularity mismatches, or reproducibility across LLM prompts/versions; potential for silent semantic drift is not quantified.
- New metrics need external validation: rLA-mIoU relies on MPNet cosine similarity for partial credit; correlation with human judgments of “near-miss” semantic correctness, and sensitivity to the chosen text encoder/thresholds, is not reported.
- Limited test scale and coverage: evaluation uses 206 shapes across a few datasets; no breakdown by part frequency, size, or rarity, and no robustness curves versus part size or class imbalance.
- Object misclassification cascades are unaddressed: in Mode 1, wrong object-class prediction can yield a wrong candidate-part list and cascading naming errors; there is no safeguard or recovery strategy.
- Handling of ambiguous/polysemous names remains brittle: affordance descriptions help but there is no systematic disambiguation when different objects share part names/functions with divergent geometries.
- Lack of task-driven validation: despite affordance-centric descriptions, there is no downstream validation in robotic manipulation, physical simulation, or functional reasoning to assess whether named parts align with actionable affordances.
- No study of cross-dataset/domain adaptation: training mixes PartNet/3DCoMPaT++/Find3D after ontology alignment, but transfer to other repositories (ShapeNet variants, real scans, industry CAD) and strategies for domain adaptation are not explored.
- Scalability with large candidate vocabularies is unclear: matching cost and accuracy when the candidate label set scales to thousands (e.g., 1,794+ parts) or includes severe distractors is not characterized.
- Data/annotation quality for Tex-Parts is under-specified: human verification rates, inter-annotator agreement, error types, and cost/time per object are not reported; how confidence thresholds impact precision/recall in real pipelines remains open.
- Ethical/licensing and reproducibility concerns are unaddressed: reliance on proprietary LLMs (e.g., Gemini) and external assets (e.g., TexVerse) raises issues of version drift, licensing, and reproducibility; standardized releases and ablation on open LLMs are missing.
Practical Applications
Immediate Applications
Below is a concise set of deployable use cases that leverage the paper’s ALIGN-Parts method (open-vocabulary, feed-forward 3D part segmentation and naming, confidence calibration, unified ontology, and new evaluation metrics).
- Semi-automated 3D part annotation engine for large repositories
- Sectors: software/AI, 3D content platforms, academia
- Tools/Products/Workflow: “Part-Annotation-as-a-Service” API; web reviewer UI integrating fused confidence (softmax + Mahalanobis) for auto-accept/flag; integration with Labelbox/Scale AI; batch processing pipelines for CAD/mesh libraries
- Assumptions/Dependencies: accurate closed-vocabulary calibration data; high-quality meshes or renders for DINOv2 features; access to LLM-generated affordance descriptions; GPU inference
- Plugins for DCC/CAD/game engines to auto-segment and name parts
- Sectors: media/games/VFX, AR/VR, industrial design
- Tools/Products/Workflow: Blender/Maya/3ds Max/Unity/Unreal plugins that assign part groups, naming conventions, and material slots; auto-creation of physics colliders per named part
- Assumptions/Dependencies: asset meshes are manifold/clean; material/texture views available for appearance cues; ontology mapping to studio naming standards
- Robotics grasping and manipulation bootstrap (simulation-first)
- Sectors: robotics, logistics/automation
- Tools/Products/Workflow: part-aware object models in simulators (Isaac Gym, MuJoCo) to find handles/knobs/latches and pre-compute grasp regions; export “graspable part masks” to motion planners
- Assumptions/Dependencies: domain gap from CAD/sim to real scans; grasp success still requires downstream control/planning; thin/small parts may need tuning
- Manufacturing QA and BOM checks from 3D models
- Sectors: manufacturing, PLM
- Tools/Products/Workflow: automatic part counting and comparison to BOM; mismatch reports (missing/extra parts); link named parts to ERP/PLM IDs
- Assumptions/Dependencies: reliable part-to-BOM ontology mapping; tolerance for CAD vs as-built deviations; quality of scans for assembled products
- E-commerce 3D catalog enrichment and search
- Sectors: retail/e-commerce
- Tools/Products/Workflow: auto-tagging of product features (“has armrests”, “5 wheels”, “reversible door”); faceted search filters driven by detected parts; compatibility checks (e.g., mount fits)
- Assumptions/Dependencies: standardized taxonomy across categories; high-quality 3D assets or vendor CAD; precision in counting repeated parts
- AR maintenance and assembly guidance using CAD
- Sectors: field service, consumer electronics, automotive service
- Tools/Products/Workflow: part-aware overlays that highlight named components during step-by-step instructions; on-device part selection by name for exploded views
- Assumptions/Dependencies: accurate CAD-to-physical alignment; device compute constraints; controlled lighting/occlusion conditions
- Cross-dataset ontology unification and dataset curation
- Sectors: academia, platform data teams
- Tools/Products/Workflow: use the LLM+MPNet pipeline to merge taxonomies (e.g., PartNet, 3DCoMPaT++, internal ontologies); maintain alias maps; publish unified ontology with IDs
- Assumptions/Dependencies: human-in-the-loop verification; LLM access and governance; buy-in from dataset owners
- Adoption of label-aware segmentation metrics in evaluation
- Sectors: academia, benchmarking consortia
- Tools/Products/Workflow: integrate LA-mIoU and rLA-mIoU into leaderboards and CI evaluation; use relaxed metric to credit near-miss semantic predictions
- Assumptions/Dependencies: community agreement on metric definitions and test sets
- Content policy/moderation for 3D platforms
- Sectors: platform trust & safety, policy/compliance
- Tools/Products/Workflow: flag or redact regulated parts (e.g., weapon components) at upload; audit trails linking redactions to part names
- Assumptions/Dependencies: reliable detection of sensitive parts; legal definitions mapped to ontology; human review for edge cases
- Repair and 3D printing workflows
- Sectors: maker/DIY, after-sales service
- Tools/Products/Workflow: identify broken/missing parts from scans; isolate and export replacement part meshes for 3D printing; generate part lists
- Assumptions/Dependencies: scan quality; watertight segmentation for printing; tolerances and material selection
- Physics-aware simulation parameterization
- Sectors: simulation, robotics, games
- Tools/Products/Workflow: map part names to default physics/joint templates (wheels → rolling joints; doors → hinge constraints); auto-rigging of mechanical parts
- Assumptions/Dependencies: correct joint semantics per category; manual overrides for atypical designs
- Accessible learning content
- Sectors: education
- Tools/Products/Workflow: export affordance-aware part captions with highlighted 3D regions; interactive “name that part” learning modules
- Assumptions/Dependencies: quality of LLM-generated descriptions; need for age/curriculum alignment
Long-Term Applications
These concepts require additional research, domain adaptation, standardization, or real-world validation (e.g., on scans, in-the-wild lighting, or real-time constraints).
- Real-time, open-world 3D part understanding for mobile/robot platforms
- Sectors: robotics, consumer AR
- Tools/Products/Workflow: on-device models segment/name parts from RGB-D streams; voice or text queries (“find the battery cover”) with immediate highlighting
- Assumptions/Dependencies: model compression and latency targets; robust performance on noisy, partial scans; continual learning and open-set detection
- Universal cross-industry part ontology standard
- Sectors: policy/standards, manufacturing, AEC, retail
- Tools/Products/Workflow: consortium-driven standard for part naming/affordances; mappings to ISO/ETIM/IFC; compliance and interoperability frameworks
- Assumptions/Dependencies: multi-stakeholder agreement; governance for updates; multilingual harmonization
- Automated assembly planning and verification
- Sectors: manufacturing, robotics
- Tools/Products/Workflow: from part-aware CAD, auto-generate assembly sequences, torque specs, and tool paths; verify assembly completeness with 3D scans
- Assumptions/Dependencies: high semantic fidelity; integration with process constraints and safety rules; reliable scan-to-CAD registration
- Construction/AEC digital twins with part-level semantics
- Sectors: AEC, facilities management
- Tools/Products/Workflow: part-aware segmentation of building components (HVAC registers, fixtures, fasteners) for maintenance scheduling, inventory, and safety audits
- Assumptions/Dependencies: large-scale scan robustness; mapping to IFC classes; tolerance for occlusions and clutter
- Medical device and prosthetics design assistants (part-aware)
- Sectors: healthcare/medtech
- Tools/Products/Workflow: design review tools that ensure required subcomponents and connectivities are present (locks, hinges); ergonomic affordance checks
- Assumptions/Dependencies: domain-specific ontologies and regulatory standards; medical-grade validation; privacy and IP considerations
- Part-aware generative design/editing copilots
- Sectors: media/entertainment, industrial design, XR
- Tools/Products/Workflow: text-to-edit (“widen the chair armrests”, “add cable management bracket”) with reliable part localization and topology-preserving edits; closed-loop with generative 3D models
- Assumptions/Dependencies: tight integration with 3D generative models; geometric/topological constraints; user-in-the-loop quality control
- Autonomous inspection and compliance analytics
- Sectors: automotive, aerospace, consumer electronics
- Tools/Products/Workflow: detect missing/incorrect parts, improper fasteners, or safety-critical placements automatically; produce compliance reports
- Assumptions/Dependencies: very high recall/precision; calibrated uncertainty; acceptance by regulators and auditors
- Sustainability analytics (LCA) and materials estimation from part structure
- Sectors: ESG/sustainability, manufacturing
- Tools/Products/Workflow: map part counts/types to materials and processes to estimate embodied carbon; flag high-impact components for redesign
- Assumptions/Dependencies: bill-of-material mappings to materials databases; accurate volume/thickness estimates; data-sharing agreements
- Supply chain and catalog matching for parts
- Sectors: procurement, manufacturing, marketplaces
- Tools/Products/Workflow: match CAD-derived parts to supplier SKUs; cross-vendor alias resolution; substitution recommendations
- Assumptions/Dependencies: robust semantic+geometric similarity; access to supplier catalogs; standardized metadata
- Large-scale educational content generation
- Sectors: education/EdTech
- Tools/Products/Workflow: auto-create interactive part-labeled models for curricula; cross-lingual affordance descriptions; assessments using label-aware metrics
- Assumptions/Dependencies: curriculum alignment; localization; content moderation for age-appropriateness
Cross-cutting assumptions and risks (affecting both categories)
- Domain shift: Models trained on CAD/clean meshes may underperform on noisy, partial, or texture-less real scans without fine-tuning.
- Affordance text quality: LLM-generated descriptions can be ambiguous; human verification remains important for high-stakes use.
- Ontology drift: Different industries require bespoke taxonomies; mappings must be maintained over time.
- Small/thin parts: Performance can degrade on tiny features; may require higher-resolution inputs or specialized training.
- Compute and licensing: Dependence on DINOv2, MPNet, and commercial LLMs (e.g., Gemini) introduces cost, licensing, and privacy considerations.
- Confidence calibration: Closed-vocabulary calibration performs best; open-vocabulary confidence is less reliable and may need conservative thresholds + reviewer workflows.
Glossary
- AdamW: An optimizer that decouples weight decay from the gradient update to improve generalization. "We use AdamW with an initial learning rate of 3e-4 and cosine annealing to a minimum of 5e-6."
- Affordance-aware part descriptions: Function-oriented textual descriptions that link a part’s geometry to its intended use. "Semantic knowledge comes from affordance-aware part descriptions that encode form-and-function relationships"
- Amodal segmentation: Segmenting complete objects or parts independent of occlusion or visibility. "Therefore, most subsequent works have focused on amodal segmentation, which is a relatively easier task."
- Bi-directional cross-attention: An attention mechanism where features from two modalities (e.g., geometry and appearance) attend to each other in both directions. "We fuse these modalities through a bi-directional cross-attention module"
- BiCo Fusion module: A cross-modal fusion component that uses bi-directional cross-attention on local k-NN graphs to combine geometry and appearance. "BiCo Fusion module using efficient bi-directional cross-attention on local nearest-neighbor graphs in 3D space"
- Bipartite assignment: One-to-one matching between two sets (e.g., predicted parts and text descriptions). "matched to part descriptions via bipartite assignment."
- Conditional Random Field Model: A probabilistic graphical model used for structured prediction over sequences or grids. "Conditional Random Field Model"
- Cosine annealing: A learning-rate schedule that follows a cosine curve to gradually reduce the learning rate. "cosine annealing to a minimum of 5e-6."
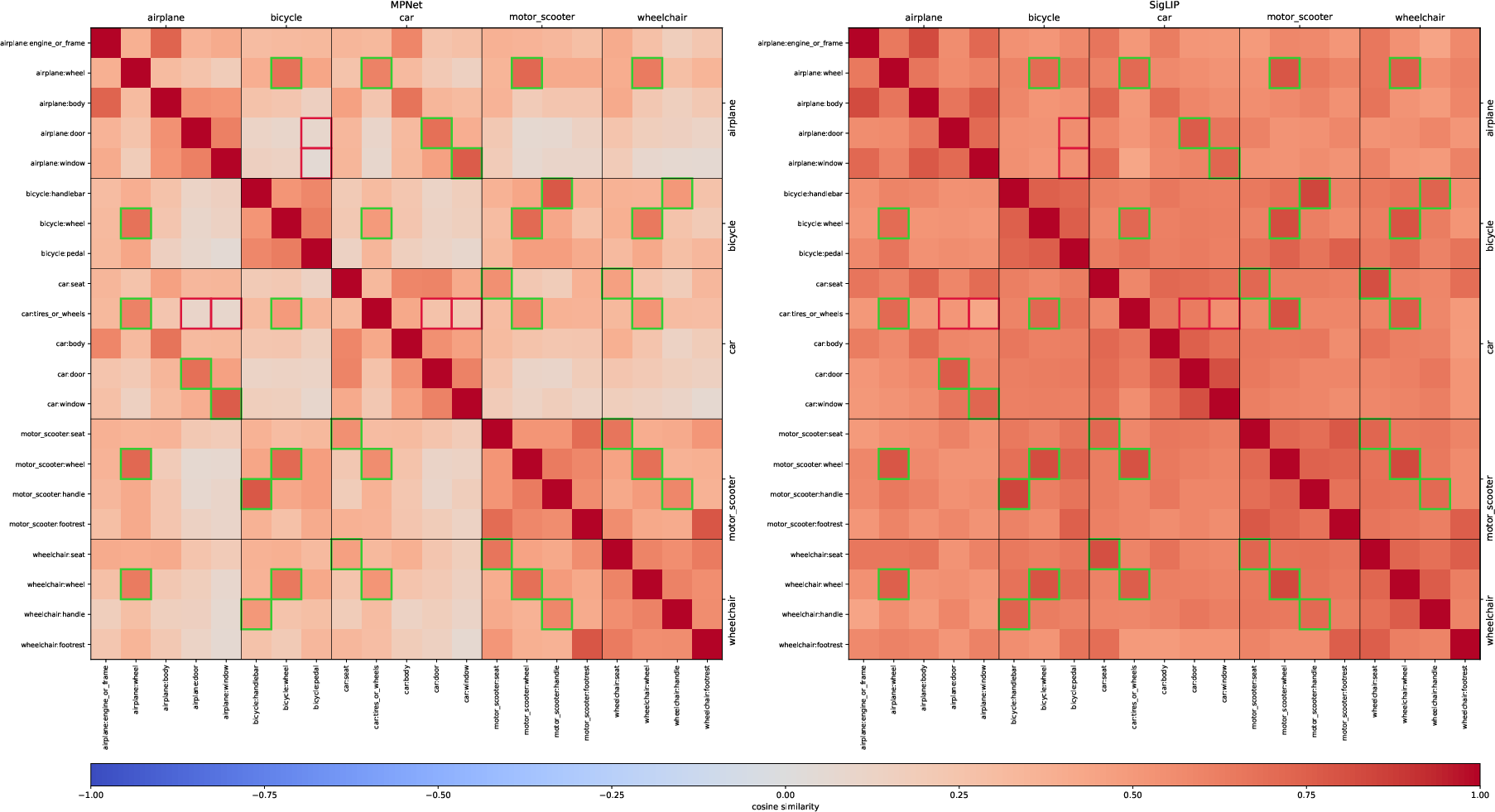
- Cosine similarity: A measure of similarity between two vectors based on the cosine of the angle between them. "Pairwise cosine similarity heatmaps"
- DETR: A transformer-based object detection framework that formulates detection as set prediction. "analogous to DETR"
- Dice loss: A segmentation loss derived from the Dice coefficient, focusing on overlap between predicted and ground-truth masks. "binary cross-entropy and Dice loss supervise masks"
- Differentiable optimal transport: A soft, gradient-based formulation of the optimal transport problem to align probability distributions. "We establish correspondences between predicted Partlets and ground-truth parts via differentiable optimal transport."
- Fourier-encoded relative positional biases: Sinusoidal encodings of relative positions used to modulate attention. "To incorporate 3D spatial structure through Fourier-encoded relative positional biases"
- Gated Fusion: A mechanism using learned gates to control how much cross-modal information is incorporated into features. "Gated Fusion."
- GELU: The Gaussian Error Linear Unit activation function used in neural network layers. "Two-layer MLP with GELU"
- Human-in-the-loop: A workflow where automated predictions are verified or refined by human annotators. "human-in-the-loop pipeline that bootstraps TexParts"
- InfoNCE loss: A contrastive loss that pulls matched pairs together and pushes mismatched pairs apart in embedding space. "Sinkhorn matching establishes a bipartite assignment between Partlet and text embeddings, and an InfoNCE loss further aligns them in a shared representation space"
- Jonker-Volgenant algorithm: An efficient method for solving the linear assignment problem exactly. "At inference, we use the Jonker-Volgenant algorithm"
- KNN graph: A graph connecting each point to its k nearest neighbors to structure local computations. "operates on a -nearest neighbor (KNN) graph"
- Label-Aware mIoU (strict, LA-mIoU): An evaluation metric that credits overlap only when the predicted semantic label exactly matches the ground truth. "Label-Aware mIoU (strict, LA-mIoU)"
- LayerNorm: A normalization technique applied across features within each layer to stabilize training. "LayerNorm"
- Mahalanobis confidence: A confidence score based on Mahalanobis distance in embedding space using class-conditional statistics. "The Mahalanobis confidence (Eq.~\ref{eq:inference_conf_maha}) requires class-conditional statistics"
- Mahalanobis distance: A distance measure that accounts for correlations in the data via the covariance matrix. "Mahalanobis-distance based confidence score"
- mIoU: Mean Intersection over Union, a standard metric for evaluating segmentation quality. "class-agnostic mIoU"
- Multi-head cross-attention: Attention with multiple heads where queries attend to keys/values from a different set or modality. "multi-head cross-attention, LayerNorm, residual connections"
- Null class: A special class allowing the model to discard unused proposals to adapt part counts per instance. "A ``null'' class allows the model to discard unused partlets"
- Open-vocabulary: The ability to handle and match to unseen or arbitrary text labels without retraining. "open-vocabulary matching setup"
- Optimal assignment: Computing a one-to-one matching that minimizes total cost across pairs. "exact optimal assignment"
- Optimal transport: A mathematical framework for moving probability mass between distributions to minimize transport cost. "Training uses contrastive alignment and differentiable optimal transport matching"
- Overlap loss: A regularizer penalizing multiple part assignments per point to enforce exclusivity. "Overlap loss enforces mutual exclusivity"
- Partlet: A learned part-level representation that includes a soft mask, an embedding, and a partness score. "We introduce partlets - shape-conditioned part proposals with text embeddings"
- Partness score: A scalar indicating whether a Partlet corresponds to a valid part for the given instance. "a partness score \text{part}_k \in \mathbb{R} indicating whether it represents an actual part"
- Permutation consistency: Ensuring each predicted part is matched to at most one name and each name is used at most once. "enabling ... permutation consistency: each predicted part receives at most one name, and each name is used at most once."
- Permutation Invariant: A property indicating results are unaffected by permutations of inputs or labels. "Permutation Invariant"
- Relative Positional Bias: A learned bias that depends on the relative positions of points, used in attention computations. "Relative Positional Bias."
- Relaxed Label-Aware mIoU (rLA-mIoU): A label-aware metric that weights IoU by semantic similarity between predicted and ground-truth labels. "Relaxed Label-Aware mIoU (rLA-mIoU)"
- Semantic grounding: Aligning visual/geometric representations with language to ensure meaningful part names. "produce semantically grounded, visually coherent partlets."
- Sentence transformer: A transformer-based model that produces fixed-dimensional embeddings for sentences or descriptions. "embedded with a sentence transformer model, such as MPNet (all-mpnet-base-v2)"
- Set alignment: Formulating prediction as aligning two sets (e.g., partlets and text descriptions) via matching. "treats automatic semantic 3D part segmentation as a direct set alignment problem"
- Sinkhorn-Knopp iterations: Iterative matrix scaling used to compute soft assignments in entropic optimal transport. "Sinkhorn-Knopp iterations produce a soft assignment matrix"
- Temperature-calibrated softmax: Softmax with a temperature parameter to adjust confidence calibration. "temperature-calibrated softmax score"
- Unified ontology: A consolidated, consistent hierarchy and naming scheme across multiple datasets. "we create a unified ontology that aligns PartNet, 3DCoMPaT++, and Find3D"
- Vocabulary compression: Merging duplicate or equivalent labels across datasets into canonical names to reduce ambiguity. "Our annotation alignment and vocabulary compression system"
- Zero-shot matching: Matching to new labels or descriptions not seen during training. "supports zero-shot matching to arbitrary descriptions"
Collections
Sign up for free to add this paper to one or more collections.

