- The paper introduces SIMART, a unified MLLM framework that decomposes 3D meshes into semantically segmented parts and generates URDF metadata.
- It employs a novel Sparse 3D VQ-VAE to reduce token redundancy by approximately 70%, enabling high-fidelity geometric encoding and efficient processing.
- The approach improves simulation deployment for robotics and VR by establishing new state-of-the-art metrics in part segmentation and kinematic accuracy.
SIMART: Unified MLLM Framework for Simulation-Ready Articulated 3D Asset Generation
Introduction and Motivation
High-fidelity simulation-ready articulated 3D assets are critical for embodied AI, robotics simulation, and interactive virtual environments. Despite rapid advances in 3D generative modeling, most synthesized assets remain monolithic meshes without semantic decompositions or physical/kinematic metadata, limiting their application for downstream tasks. Traditional articulated asset creation pipelines rely on multi-stage frameworks, which introduce error propagation across decoupled part segmentation, kinematic reasoning, and post-hoc assembly, hampering geometric fidelity and limiting scalability.
The paper introduces SIMART, a unified multimodal LLM (MLLM) framework that directly processes raw 3D mesh geometry, together with vision and textual inputs, to jointly decompose objects into semantically and physically meaningful parts and generate the corresponding simulation metadata, including URDF (Universal Robot Description Format) specifications. The central innovation is a Sparse 3D VQ-VAE encoding, which dramatically reduces geometric token redundancy versus dense volumetric tokenization, facilitating scalable, high-fidelity MLLM-driven articulation reasoning.

Figure 1: SIMART leverages the multimodal reasoning of MLLMs to unify URDF generation and semantic part grounding, transforming static 3D meshes into functional, simulation-ready articulated assets.
Methodology
Sparse 3D VQ-VAE Encoding
A critical bottleneck in prior 3D-native MLLMs is their reliance on dense voxel representations, which result in unmanageably long token sequences and high memory overhead for complex articulated objects. SIMART addresses this via a Sparse 3D VQ-VAE, which quantizes only occupied voxels and assigns a dedicated zero-token for empty space. This design results in approximately 70% fewer tokens on average, enabling high-resolution geometric encoding within practical computational budgets. Additionally, a coordinate-aware serialization ensures correct spatial localization within variable token sequences, preserving topological structure for downstream MLLM processing.
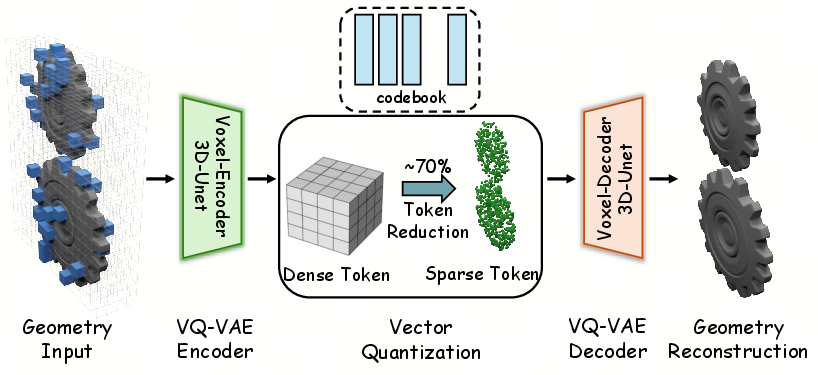
Figure 2: Architectural overview of the Sparse 3D VQ-VAE for high-fidelity geometric encoding. The pipeline employs a 3D-UNet voxel encoder to map geometric inputs into a discrete latent space through vector quantization with a specialized codebook.
Multimodal MLLM Backbone and Pipeline
SIMART integrates Qwen3-VL as the MLLM backbone, exploiting its pretrained cross-modal reasoning abilities. The framework jointly embeds 3D geometry tokens, vision features (processed via a Vision Transformer), and text (functional or task descriptions) into a unified latent space. The MLLM is optimized to output segmentation of the mesh into distinct parts and directly generate structured simulation metadata (URDF), encompassing kinematic joints, physical properties, and articulated hierarchies.
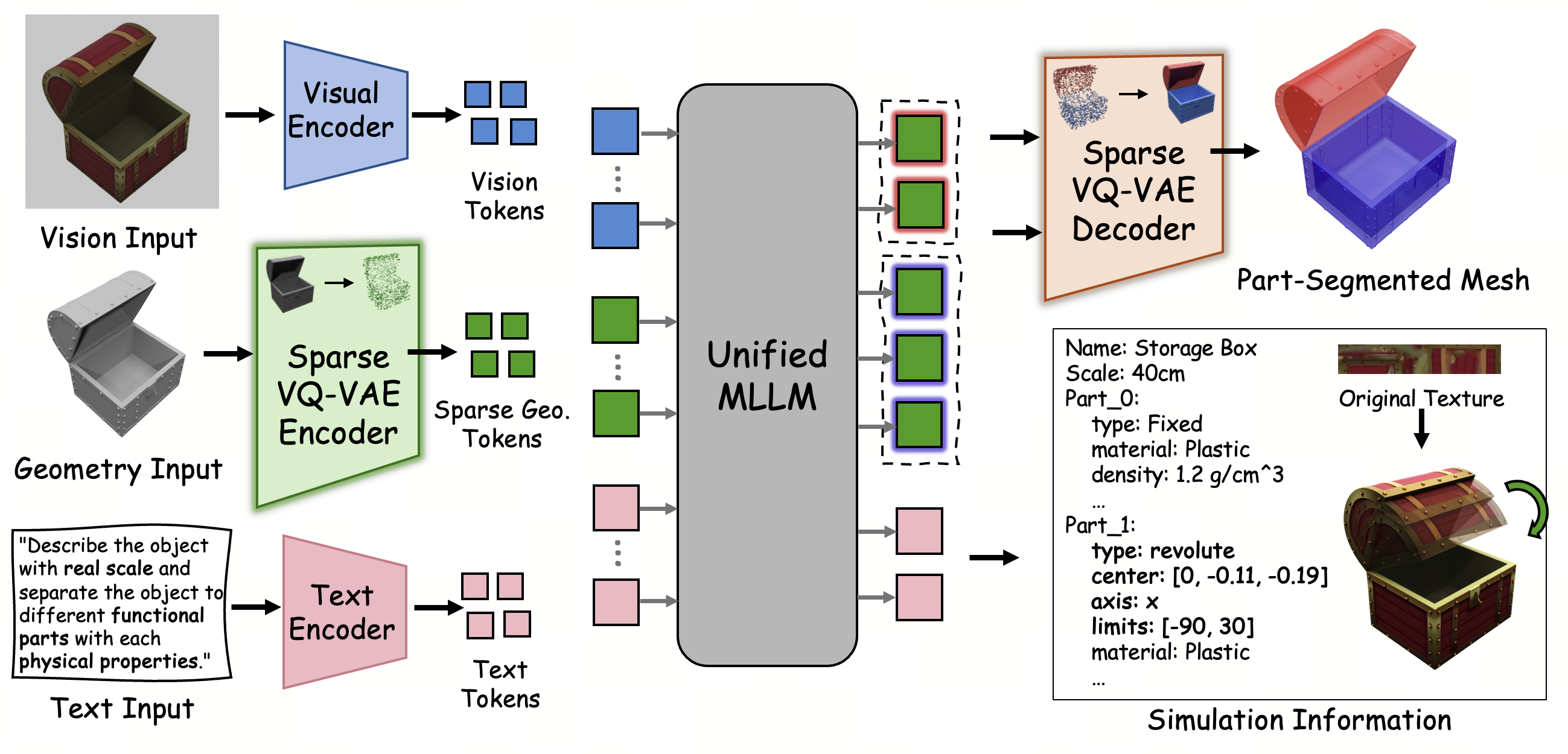
Figure 3: The pipeline of SIMART, showing sparse geometric encoding, multimodal fusion, and simultaneous part grounding and URDF metadata generation.
End-to-End Part Decomposition and Articulation
To reconstruct surface meshes from predicted sparse voxel tokens, a robust graph-based segmentation aligns discrete part seeds back onto the original high-fidelity mesh. This ensures both precise semantic part isolation and faithful preservation of geometric detail for each decomposed segment. All output segments, paired with structured kinematic metadata, enable direct deployment into robotics simulation environments without further manual annotation.
Experimental Evaluation
Benchmarks and Datasets
SIMART-Bench is curated as a composite high-quality benchmark, augmenting canonical datasets (e.g., PartNet-Mobility) with diverse out-of-distribution (OOD) AI-generated objects, expanding category and topological coverage. Annotation protocols combine automated 3D part segmentation with expert-guided corrections, ensuring accuracy in part definitions and kinematic axes.
Quantitative Results
Across all evaluated metrics—Type Accuracy (joint classification), Axis/Origin Error (kinematic structure), IoU (part segmentation), and CD (reconstruction)—SIMART establishes new state-of-the-art performance for both in-domain and OOD assets. The method demonstrates strong geometric fidelity and significant generalization capability to previously unseen or complex object structures, outperforming prior baselines including Urdformer, Articulate-Anything, PhysX-Anything, and Particulate.

Figure 4: Qualitative comparison of articulated asset generation across different methods, showing SIMART's accurate kinematic decomposition and high structural consistency.
Part Grounding and Semantic Reasoning
SIMART, via coordinate-aware tokens and the MLLM's cross-modal reasoning, achieves substantially higher IoU and lower Chamfer Distance than competitors for semantic part localization, especially on AI-generated assets with novel geometries. Integration with vision cues resolves ambiguities inherent in geometry-only representations, as validated by strong ablation study results.

Figure 5: SIMART delivers fine-grained functional part grounding, accurately isolating parts like lids and doors with high geometric coherence.
Applications
Direct Simulation Deployment
A key outcome of SIMART is the ability to generate physically consistent, articulated assets that can be immediately loaded into standard physics engines such as NVIDIA Isaac Sim for robotic manipulation or dynamic interaction. This supports scalable creation of diverse, high-quality 3D benchmarks and facilitates interactive learning paradigms in embodied AI.
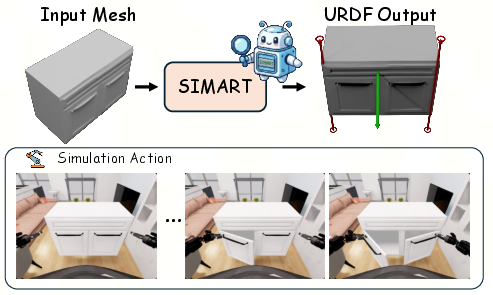
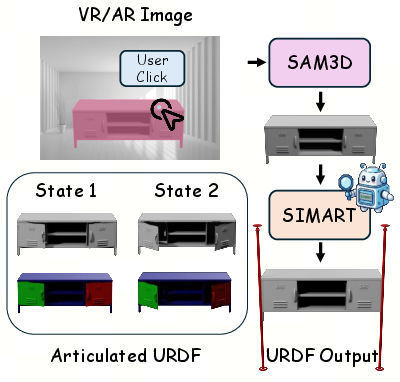
Figure 6: Example deployment of SIMART-generated assets in a physics-based simulator, demonstrating direct applicability for robotics research.
Immersive VR/AR Asset Generation
SIMART can also be integrated with 3D-aware segmentation systems (e.g., SAM3D) to enable user-guided asset creation in VR/AR environments, functionalizing captured static meshes into actionable, kinematically valid digital twins.
Qualitative Analysis
A comprehensive visual gallery and qualitative comparison establish SIMART’s superior ability to handle a broad variety of generated object categories, maintaining detailed part-level structure and articulation properties.
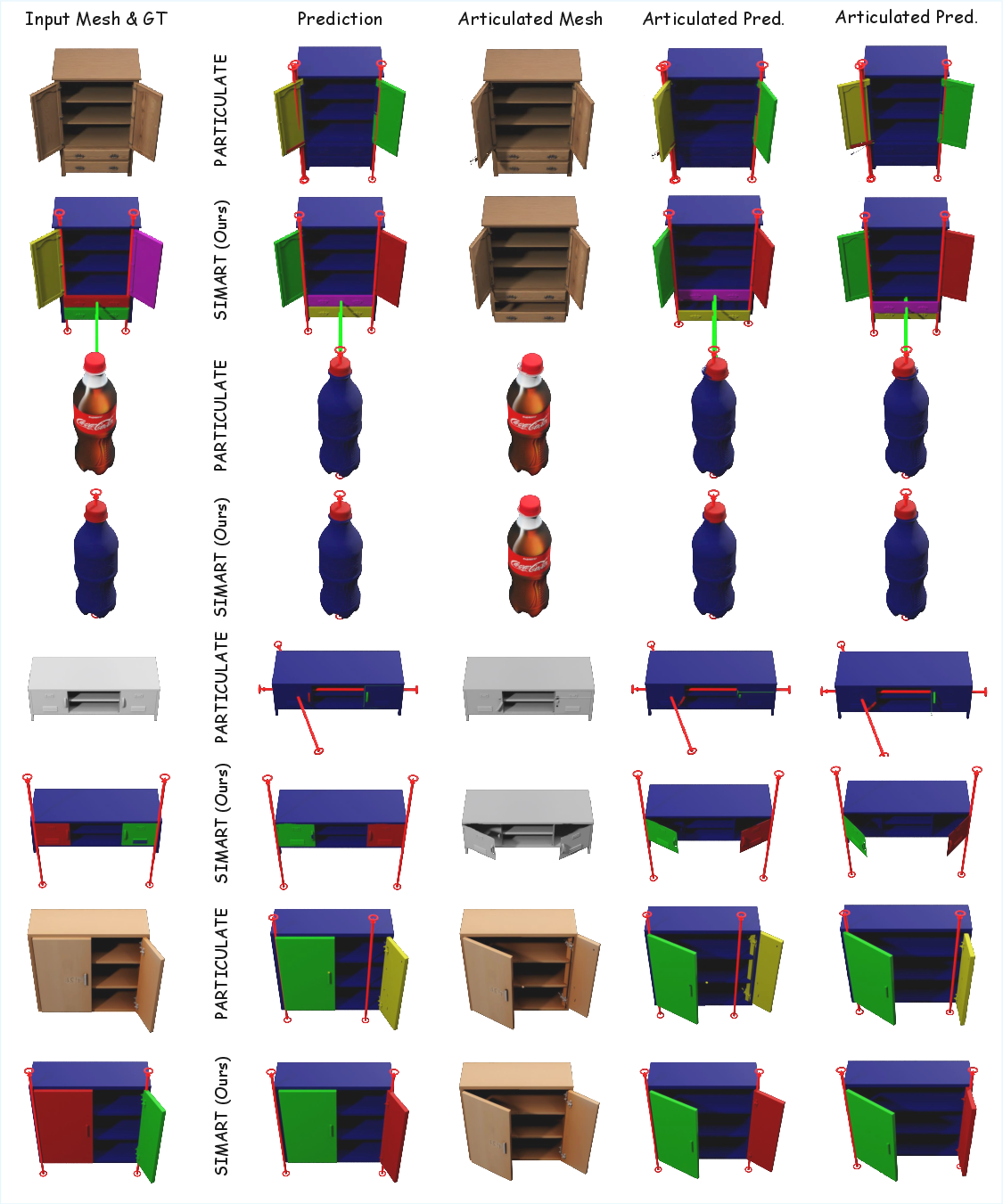
Figure 7: Extended qualitative comparison between SIMART and the Particulate baseline for OOD objects.

Figure 8: Gallery of simulation-ready assets from SIMART, all generated from diverse, AI-synthesized 3D models.
Implications and Future Directions
SIMART reduces the manual effort needed to functionalize 3D assets for simulation, with direct benefits for scalable data augmentation, benchmarking, and interactive robotic learning. Its unified framework and data-driven articulation pipeline advance the practical feasibility of real-to-sim transfer for embodied agents, and open new possibilities for AI-driven content creation in virtual spaces.
A paramount challenge remains the scarcity and low diversity of annotated articulated datasets. The authors anticipate that SMIMART can serve as a bootstrapping tool, generating high-fidelity, pre-labeled articulated assets that will accelerate large-scale dataset construction, further enriching research in 3D generation, robotics simulation, and VR/AR.
Conclusion
SIMART advances the state of the art in 3D articulated asset generation by integrating a memory-efficient sparse geometric representation and a cross-modal MLLM for unified part decomposition, kinematic prediction, and simulation metadata completion. Experimental results establish robust generalization both in quantitative metrics and qualitative outputs, substantiating the framework’s value for practical deployment in physics-based simulation and distributed VR/AR environments. The approach stands as a pivotal step toward scalable, automated functionalization of static 3D content, promising broad impact for embodied AI, robotics, and digital content creation.
[SIMART: Decomposing Monolithic Meshes into Sim-ready Articulated Assets via MLLM, (2603.23386)]