- The paper introduces a two-stage optimization framework that leverages data-driven motion priors and explicit kinematic constraints to reconstruct physically-consistent digital twins.
- It achieves state-of-the-art performance with axis errors as low as 0.53° and sub-centimeter positional accuracy even under noisy and sparse data conditions.
- The method scales to complex, multi-part kinematic structures, making it suitable for simulation, robotics, AR/VR, and scalable 3D asset generation.
Articulat3D: Physically-Constrained Articulated Digital Twinning from Casual Monocular Video
Introduction and Motivation
Reconstructing articulated digital twins from monocular video is an open challenge in computer vision and robotics. Most existing methods and pipelines require static multi-view captures, controlled environments, or rely on mesh libraries, limiting their scalability in unconstrained, real-world settings. The "Articulat3D: Reconstructing Articulated Digital Twins From Monocular Videos with Geometric and Motion Constraints" framework addresses these core deficiencies by introducing a method that robustly reconstructs explicit, physically-constrained, interactable digital twins from casually acquired monocular videos, without the need for a separate static scan or prior mesh model (2603.11606).
Articulat3D's approach reformulates monocular articulated reconstruction as a temporally continuous, physically-constrained optimization problem. It brings together low-dimensional motion priors and strict kinematic parameterization, resolving the geometry-kinematics ambiguity that typically plagues monocular setups and achieving digital twins suitable for precise downstream simulation and manipulation.

Figure 1: From casual monocular video to interactive digital twin; Articulat3D produces physically-consistent, simulation-ready models.
Methodology
Articulat3D employs a two-stage optimization paradigm integrating data-driven motion priors and explicit geometric articulation constraints.
Motion Prior–Driven Initialization
Casual monocular captures are prone to heavy occlusion and noisy point trajectories. The pipeline first preprocesses frames with state-of-the-art segmentation (SAM3), hand-object separation (Qwen-Image), and point-wise tracking (TAPIP3D). Rather than degrading to per-Gaussian trajectory fitting, Articulat3D exploits the observation that articulated motions span a low-dimensional subspace. It models trajectories as linear combinations of a compact set of shared, learnable SE(3) motion bases, derived through spatiotemporal clustering of 3D tracks. This encourages trajectory regularization, mitigates data sparsity, and establishes strong temporal consistency.
Geometric and Motion Constraints Refinement
The initialization is insufficient for physically valid articulation—a core problem is that generic bases often lead to overfitting and unmodeled non-rigid deformations. Articulat3D transitions to an explicit kinematic model. Object parts are parameterized by normalized joint axes, part-centric pivots, and temporally evolving motion scalars (angular or translational). Each part's motion follows classic rigid-body laws: either revolute motion, computed via Rodrigues' rotation around the pivot, or prismatic translation.
A robust part assignment and kinematic discovery module leverages PCA on Gaussian trajectories to infer part segmentation and initial axes. Assignments are further refined using a differentiable "re-skinning" strategy that align part boundaries with physically consistent kinematic transformations.
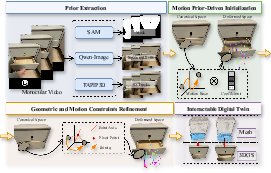

Figure 2: Overview of Articulat3D: (1) motion prior–driven initialization infers low-dimensional articulated bases; (2) geometric/motion constraints refinement enforces kinematic consistency.
Experimental Evaluation
Evaluation leveraged three benchmarks: Video2Articulation-S (single-joint, synthetic), Articulat3D-Sim (2–7 part complex kinematics), and Articulat3D-Real (handheld real-world captures). The comparison included state-of-the-art baselines such as RSRD (part-level optimization), Articulate Anything (library-driven code generation), iTACO (template-based motion inference), and Shape of Motion (4D-GS models using unconstrained motion bases).
Articulat3D achieves superior kinematic estimation, with axis errors of 1.60∘ (Video2Articulation-S) and 0.53∘ (Articulat3D-Sim), far below the >40∘ of competitors in complex settings. It shows sub-centimeter position and Chamfer errors, maintaining geometric fidelity even as others fail with catastrophic drift or axis misalignment. Notably, Shape of Motion and RSRD yield high photometric fidelity but exhibit unphysical geometry due to unconstrained motion representations.

Figure 3: Visual results on Video2Articulation-S; Articulat3D preserves rigid structure and joint orientation.
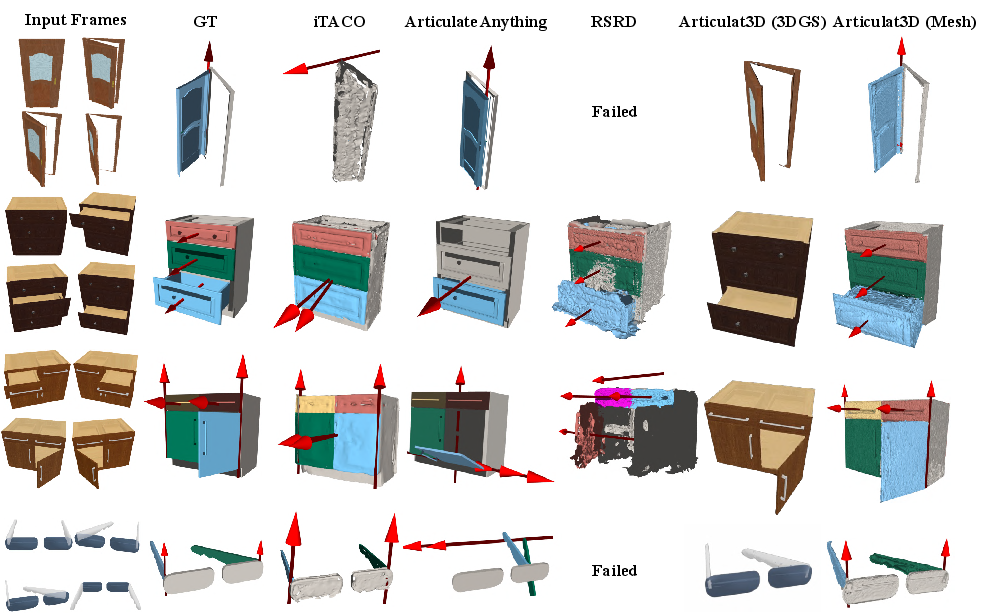
Figure 4: Visual results on Articulat3D-Sim, demonstrating robustness to multi-part and synchronized motion.

Figure 5: Visual results on Articulat3D-Real, validating real-world generalization under clutter and occlusion.
This pipeline enforces physically plausible transitions: alternative methods often optimize independent per-frame states, failing to capture continuous motion, resulting in drift during articulation and poor fit for downstream physics.
Ablations and Robustness
Critical ablations demonstrate that both the motion prior and geometric constraints stages are indispensable. Dropping motion prior guidance causes ambiguity and geometric distortion, as shown by sharp increases in joint and part errors. Removing geometric constraints (Articulat3D w/o kinem. const.) allows non-physical deformations and floating artifacts, which are suppressed with the kinematic bottleneck.
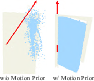
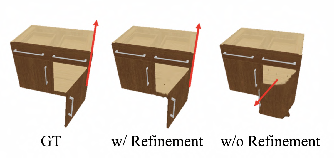
Figure 6: Visual impact of motion prior—without 3D guidance, geometry drifts under motion/geometry ambiguity.
The framework shows high robustness to noisy and sparse data: even when 3D tracks are highly inconsistent or 1/3 of the frames are removed, the axis and position errors remain low (below 1∘, $1$ cm), as the kinematic manifold regularizes inference.
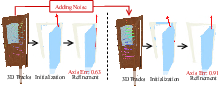
Figure 7: Kinematic refinement corrects misassigned parts/joints even with noisy motion initialization.
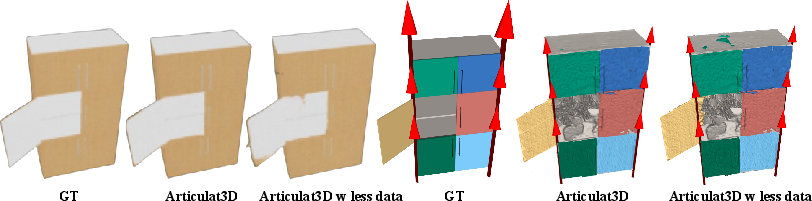
Figure 8: Robustness to data sparsity; reducing frames degrades photometric quality modestly but not kinematic accuracy.
The architecture also scales to complex kinematic topologies (2–7 parts), as demonstrated on Articulat3D-Sim (Figure 9).

Figure 9: Visualization of the Articulat3D-Sim dataset supporting multi-part, multi-axis digital twin benchmarking.
Practical, Theoretical, and Future Implications
Articulat3D directly enables scalable articulated digital twinning for robotic simulation, AR/VR, and internet-scale 3D asset generation from casual videos. By circumnavigating the need for static 3D scans or constrained multi-view acquisition, it facilitates data-driven modeling for agents equipped with monocular cameras, closing the sim-to-real loop in manipulation and interaction scenarios.
Theoretically, its structured optimization—forging rigid-body kinematics onto monocular GS-based representations—establishes a template for physically regularized dynamic scene understanding. The explicit axis/pivot parametric bottleneck also provides a foundation for hierarchical kinematic inference, physical parameter estimation, and scalable scene decomposition in more complex assemblies.
Limitations include performance degradation on textureless or highly symmetric parts, where visual anchors are weak, and a current assumption of independent joints rather than hierarchical kinematic chains. Extensions should integrate learned geometric priors, multi-view constraints, or direct estimation of mechanical properties (e.g., mass, friction) for rich simulation and reasoning.
Conclusion
Articulat3D represents a leap in realism and physical consistency for monocular articulated reconstruction, combining a motion-prior-driven, low-dimensional initialization with strict, optimizable kinematic constraints. It achieves state-of-the-art geometric and photometric fidelity, robustly reconstructs articulated objects under challenging real-world conditions, and yields explicit, simulation-ready 3D representations. This framework sets the stage for new directions in vision-driven digital twinning, physically-grounded robotics, and in-the-wild object modeling.

