- The paper introduces PartImageNet++ as a comprehensive dataset with 100K images and 406K part masks across 1,000 ImageNet classes.
- The paper develops a Multi-scale Part-supervised Model (MPM) that integrates true and pseudo part labels to boost adversarial robustness and clean accuracy without added inference cost.
- The paper demonstrates that detailed part annotations enhance segmentation performance and few-shot learning by providing strong localized cues and improved inductive biases.
Advancing Visual Recognition with PartImageNet++: High-Quality Part Annotations for Robust and Interpretable Models
Introduction and Motivation
The lack of high-quality, large-scale part annotations has historically constrained the efficacy and scope of part-based models in computer vision. "PartImageNet++ Dataset: Enhancing Visual Models with High-Quality Part Annotations" (2601.01454) introduces PartImageNet++ (PIN++), a dataset that provides dense, meticulously curated part segmentation annotations for all 1,000 classes of ImageNet-1K. Each class is furnished with 100 manually annotated images, resulting in 100,000 images and 406,364 part masks across 3,308 part categories. This resource removes prevailing barriers in building, evaluating, and scaling part-based architectures for robust recognition, segmentation, and few-shot learning tasks.

Figure 1: Representative PIN++ images, with object names shown and occluded part names.
The primary contributions of the work are threefold: 1) Construction and validation of PIN++ as a diverse, category-balanced, high-density part annotation dataset, 2) Development of a Multi-scale Part-supervised recognition Model (MPM), with auxiliary segmentation supervision yielding state-of-the-art adversarial robustness and human-aligned performance on IN-1K, and 3) Establishment of strong baselines and architectural extensions leveraging part annotations for semantic segmentation, object segmentation, and few-shot classification.
Dataset Construction and Comparative Analysis
PIN++ follows a highly structured annotation protocol, leveraging both human cognition and knowledge bases (e.g., Wikidata) to guide part selection granularity and hierarchy. Each object category is annotated with 3–8 functionally and structurally meaningful part labels, ensuring both completeness and discriminativity. Overlapping/hierarchical parts (e.g., horn/head) are also managed via inclusion relations.

Figure 2: Visual comparison of part segmentation granularity and semantic coverage between PIN (left) and PIN++ (right) on overlapping classes.
In comparison with existing datasets such as PACO, Pascal-Part, ADE20K, and the original PIN, PIN++ uniquely covers the entirety of IN-1K, supports all foreground object categories, maintains category balance (100 images/class), and encodes superior granularity and label consistency. The dataset is annotated by a trained workforce, with extensive validation and re-annotation cycles to maximize label integrity.
A critical empirical finding is that existing standard and open-vocabulary segmentation models such as VLPart and SAM are incapable of generating part segmentations with accurate semantics or alignment on unseen categories without PIN++ supervision. Only models directly trained on PIN++ afford reliable dense part predictions across visual diversity.
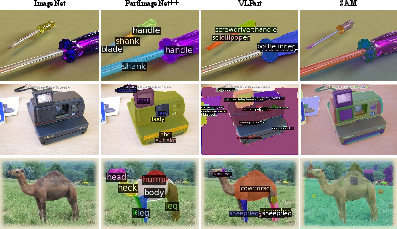
Figure 3: Qualitative segmentation comparisons: only models trained on PIN++ accurately segment fine-grained object parts on held-out examples.
Multi-scale Part-supervised Recognition Model (MPM)
The paper introduces MPM as a model architecture that exploits both dense manual part annotation and pseudo-part labels for all remaining IN-1K train images. A Mask R-CNN, trained on PIN++, produces pseudo part segmentations for unannotated samples. Importantly, a Category Filter (CF) aligns pseudo-label outputs with known object-part relations, significantly improving AP metrics and downstream utility.
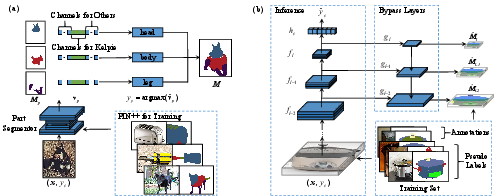
Figure 4: MPM training pipeline: (a) Pseudo-label generation with a Mask R-CNN, (b) MPM’s auxiliary bypass layers for intermediate segmentation supervision and final classification.
During recognition model training, MPM appends auxiliary segmentation heads at multiple resolution scales to a vanilla architecture (e.g., ResNet-50-GELU), using part supervision signals from both true and pseudo-labeled data. Inference dispenses with auxiliary layers, ensuring computational parity with standard models. The final objective is a weighted sum of classification loss and part segmentation loss.
The results demonstrate strong adversarial robustness in all tested adversarial regimes (l∞, l1, l2 norms and increased perturbation magnitudes). MPM achieves 39.1% top-1 accuracy under l∞=4/255 attacks on IN-1K, systematically outperforming all contemporary AT-trained ResNet-50-based baselines, including prior SOTA robust recipes and models.

Figure 5: Masks produced by a PIN++-trained Mask R-CNN; pseudo-label quality is sufficient for robust downstream MPM training.
Notably, MPM achieves increased clean recognition accuracy, improved robustness to common corruptions and OOD data distributions, and substantially higher human-model error consistency relative to standard AT or non-part models. The gain is maintained without any inference cost tradeoff.
Downstream Part Segmentation and Object Segmentation
The authors design comprehensive part and object segmentation benchmarks using PIN++ with ResNet and ViT-based mask predictors, evaluating both independent and cascade variants trained via federated losses. Incorporating part-level supervision yields consistently higher segmentation AP scores compared to object-only settings, especially as model capacity increases.
Comparisons on semantic part segmentation favor architectures leveraging both multi-scale pyramid features and cascade refinement, with the ViT-s + Cascade backbone attaining the best mask AP (32.0) and box AP (32.2). The incorporation of part annotations also improves boundary precision and allows finer-grained recognition, as demonstrated in comparison to models trained on datasets lacking such detail.
Object segmentation benefits directly by fusing part masks, with object+part supervision yielding higher AP on every model variant, again highlighting the transferability and expressivity of detailed part-level supervision in segmentation pipelines.
Part-based Few-Shot Learning
PIN++ enables augmentation of standard few-shot learners with explicit part-extraction branches, providing strong localized cues per sampled support instance. The paper proposes a framework where l part sub-networks extract representations from the top-l largest part regions, fused with the whole-image branch via learnable weight normalization.
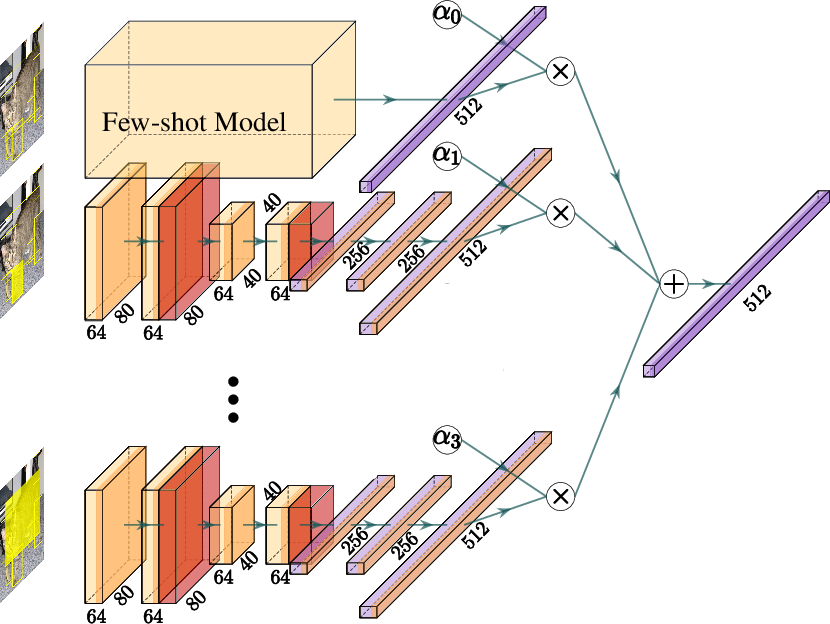
Figure 6: Multi-branch few-shot architecture: the main branch fuses with three part-specific branches, improving representation quality and interpretability.
Replacing random region sampling (DeepEMD v2) with PIN++ part bounding boxes, and augmenting Meta-Baseline with these part branches, yields consistent improvements in 5-way 1-shot and 5-shot classification accuracy on PIN++ tasks. Meta-Baseline achieves 91.3% accuracy in the 5-way 5-shot regime with object+part training. This demonstrates that dense part supervision delivers a strong inductive bias for rapid adaptation in low-data generalization settings.
Ablations, Human Alignment, OOD Robustness, and Practical Implications
Extensive ablations show that part supervision grants clear benefits in every regime, including adversarial robustness, OOD generalization, and human-model behavioral consistency. Detailed analysis reveals that:
- High-quality, category-filtered pseudo part labels are critical; models trained solely on real part annotations overfit.
- Multi-scale, top-down segmentation supervision (MPM) outperforms prior two-stage part-based models, despite equivalent or lower inference cost.
- Fine-grained part segmentation masks provide stronger learning signals than object segmentation masks.
- Part-based modeling, in combination with adversarial training, achieves the best alignment with human error patterns, decreasing accuracy gaps and increasing shared misclassification modes.
Furthermore, PIN++ and MPM facilitate transfer of adversarial robustness to detection pipelines (e.g., initializing Faster R-CNN with MPM checkpoints improves AP on MS-COCO), indicating the broad applicability of part-based pretraining.
Conclusion
PartImageNet++ constitutes a foundational resource for the study of compositionality, structural priors, and robustness in vision models. The synthesis of dense, large-scale part annotation with rigorous model benchmarks yields models that simultaneously set robustness SOTA and demonstrate improved interpretability and alignment with human recognition. Practically, PIN++ enables research programs in robust recognition, data-efficient learning, segmentation, and OOD generalization at a scale previously unattainable. The dataset is publicly available, supporting future work on part-based architectures for both academic and industrial deployment.
Future Directions
PIN++ establishes a new standard for large-scale part-aware annotation and modeling. Immediate directions for AI research include:
- Extending part semantics into video, 3D, and multimodal datasets.
- Unifying part-based and open-vocabulary vision models for zero-shot compositional generalization.
- Investigating the role of part priors in interpretable and trustworthy machine perception at scale.
- Leveraging part-aware representations to improve the interaction, manipulation, and understanding abilities of embodied AI systems.
The empirical and methodological advances of PIN++ and MPM form a platform for the next generation of robust, interpretable, and cognitively aligned visual systems.

