Rethinking Video Generation Model for the Embodied World
Abstract: Video generation models have significantly advanced embodied intelligence, unlocking new possibilities for generating diverse robot data that capture perception, reasoning, and action in the physical world. However, synthesizing high-quality videos that accurately reflect real-world robotic interactions remains challenging, and the lack of a standardized benchmark limits fair comparisons and progress. To address this gap, we introduce a comprehensive robotics benchmark, RBench, designed to evaluate robot-oriented video generation across five task domains and four distinct embodiments. It assesses both task-level correctness and visual fidelity through reproducible sub-metrics, including structural consistency, physical plausibility, and action completeness. Evaluation of 25 representative models highlights significant deficiencies in generating physically realistic robot behaviors. Furthermore, the benchmark achieves a Spearman correlation coefficient of 0.96 with human evaluations, validating its effectiveness. While RBench provides the necessary lens to identify these deficiencies, achieving physical realism requires moving beyond evaluation to address the critical shortage of high-quality training data. Driven by these insights, we introduce a refined four-stage data pipeline, resulting in RoVid-X, the largest open-source robotic dataset for video generation with 4 million annotated video clips, covering thousands of tasks and enriched with comprehensive physical property annotations. Collectively, this synergistic ecosystem of evaluation and data establishes a robust foundation for rigorous assessment and scalable training of video models, accelerating the evolution of embodied AI toward general intelligence.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching AI to make realistic robot videos—videos where robots see, think, and act in the physical world without breaking the rules of physics. The authors built two things to push this forward:
- A fair, detailed test called RBench that checks how well different AI video models create believable robot actions.
- A huge, high-quality dataset called RoVid-X (about 4 million short robot clips) to train these models to do better.
Together, the test and the data aim to help AI video models move from “pretty visuals” to “physically correct robot behavior.”
What questions were they trying to answer?
In simple terms, they asked:
- How can we fairly judge whether an AI-generated robot video looks real, follows instructions, and obeys physics?
- Which current video models are actually good at showing robots doing tasks correctly?
- What kind of training data do these models need to get better at real-world robot actions?
How did they do it?
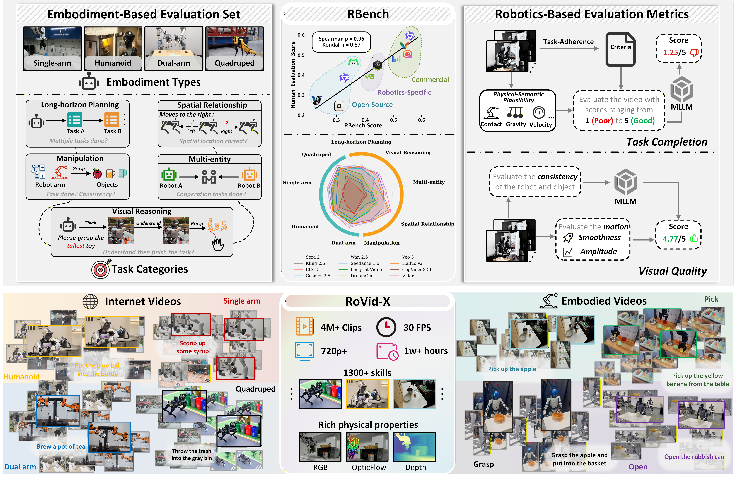
A new test for robot videos: RBench
Think of RBench as a report card for robot videos. It includes 650 carefully chosen image-and-text prompts that tell the AI what video to make. The test covers five everyday robot task types and four kinds of robots.
To make it easy to follow, here are the tasks and robot types it covers:
- Tasks: common manipulation (e.g., pick-and-place), long-horizon planning (multi-step goals), multi-robot or robot–object collaboration, spatial relationships (like left/right, inside/outside), and visual reasoning (understanding colors, shapes, or properties).
- Robot types: single-arm robots, dual-arm robots, humanoids, and quadrupeds (four-legged robots).
RBench doesn’t just check if a video looks sharp. It scores things that matter for robots:
- Does the robot finish the task and follow the steps in order?
- Do objects and robot parts behave realistically (no floating, teleporting, or melting shapes)?
- Is the motion smooth and meaningful (not just the camera moving while the robot stands still)?
To grade videos at scale, they used “virtual judges” (AI systems that understand pictures and text) to answer checklist-style questions about each video. These AI judges’ scores matched human opinions very closely (agreement of 0.96 on a 0–1 scale), which means the test is trustworthy.
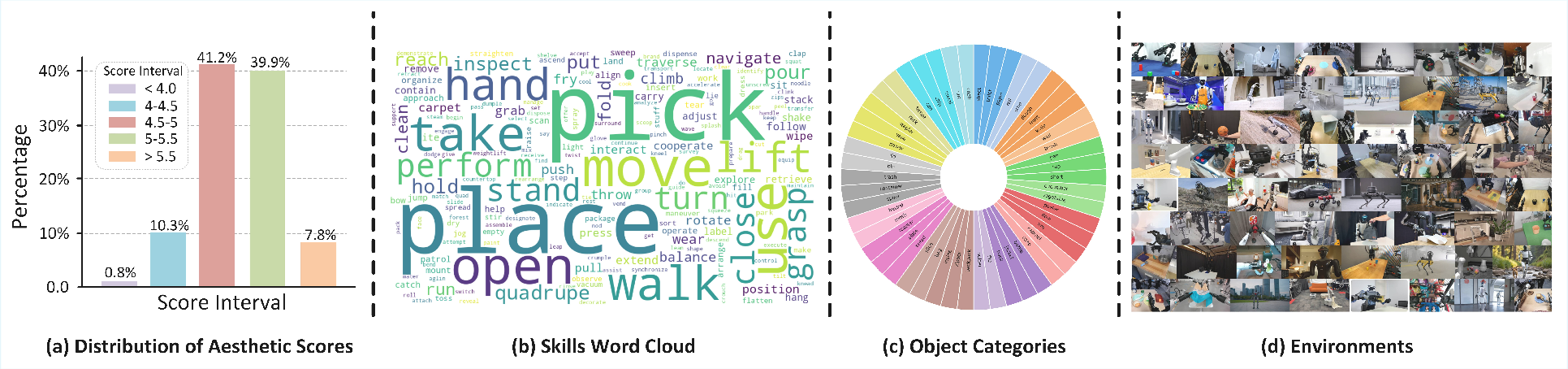
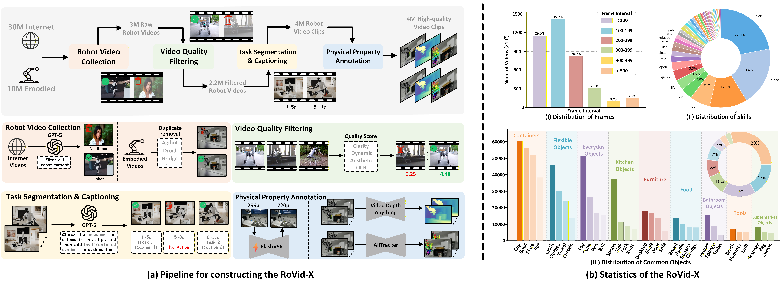
A giant training set: RoVid-X
RoVid-X is a massive, open-source robot video dataset built to teach models good physical behavior. It contains about 4 million short clips from many sources and robot types. The team built it with a four-step pipeline:
- Collect: Gather robot videos from the internet and open datasets.
- Clean: Remove low-quality clips and non-robot parts; keep clear, useful footage.
- Label: Split videos into task-sized chunks and auto-generate simple captions like “left gripper grasps the box and moves it onto the shelf.”
- Add physics info: Attach helpful signals like motion tracks and depth (how far things are) so models can learn real-world structure, not just color and texture.
They also made sure the test set (RBench) doesn’t overlap with the training data (RoVid-X), so the scores are fair.
What did they find?
They tested 25 well-known video models and found several big patterns:
- Many models can make beautiful videos but still “break physics.” Common errors include floating hands, objects moving without being touched, robot parts bending in impossible ways, or skipping steps in tasks.
- Models built for general media (like cinematic demos) often struggle with robot tasks, because they focus on looks over physics.
- The best results came from top commercial models, which handled tasks more realistically. Open-source models are improving but still lag behind at robot-specific realism.
- Models trained or tuned on physically grounded robot data do better at robot tasks than similarly sized models not trained on such data.
- Fine, precise hand/arm actions (manipulation) are harder than walking or general body movement. Visual reasoning (like following color-based instructions) is also a common weak spot.
- Training with RoVid-X helps: when models were fine-tuned on this dataset, they scored higher across many task types and robot forms.
Why does this matter?
Robots need to understand cause and effect: if the gripper doesn’t touch the cup, the cup shouldn’t move. Better AI video models that respect physics can:
- Generate realistic robot practice videos, reducing the need for expensive, slow human demonstrations.
- Help robots plan steps and predict what will happen next, leading to safer and smarter behavior.
- Speed up research toward embodied AI—intelligent systems that perceive, reason, and act in the real world.
In short, this paper gives the community a strong “test” (RBench) and a lot of “study material” (RoVid-X). That combination makes it easier to see what’s broken, train better models, and close the gap between cool-looking videos and robots that actually work correctly in the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, actionable list of what remains missing, uncertain, or unexplored in the work, to guide follow-up research:
- Benchmark scope is open-loop: RBench evaluates video realism from prompts but not closed-loop executability (e.g., whether a policy can reproduce the video in sim/real). Add “execute-from-frames” evaluations where generated sequences are re-enacted in physics simulators or on hardware.
- Limited task coverage: Five categories omit deformable/fluid manipulation, transparent/reflective objects, non-prehensile actions (push, pour, throw), tool use, tactile-dependent skills, human–robot interaction, and mobile manipulation with navigation. Expand task taxonomy and include these regimes.
- Long-horizon undefined: “Long-horizon planning” lacks explicit duration/steps; minute-scale coherence and multi-stage tool-use are not evaluated. Introduce standardized horizons (e.g., ≥30–120s) and stepwise success labels.
- Conditioning mismatch: RBench uses image–text pairs; many T2V models are not optimized for image conditioning. Provide parallel text-only and image-conditioned tracks to ensure fair comparison.
- Benchmark size risks overfitting: 650 items may be learnable by model-specific prompt-tuning. Provide multiple held-out splits, yearly refreshes, and near-duplicate checks to reduce test-set contamination.
- Data contamination not ruled out: Closed-source models may have trained on similar web videos/prompts. Add near-duplicate detection against public corpora and report contamination risk per model.
- MLLM evaluator dependence: Metrics rely on Qwen3-VL and closed-source GPT-5, which are non-deterministic and evolve over time. Release prompts, seeds, versions, and a frozen open-source evaluator; quantify inter-model evaluator variance.
- Prompt sensitivity and bias: VQA-style checks may be brittle to phrasing and language. Benchmark prompt perturbations (paraphrases, languages) and report confidence intervals for evaluator robustness.
- Detector-tracker reliance in metrics: MAS/MSS depend on GroundingDINO, SAM, and CoTracker, which can fail under occlusion, fast motion, or multi-robot scenes. Publish a labeled validation set for metric failure analysis and calibrate per-scene.
- Physical plausibility is qualitative: Violations (e.g., floating, penetration) are judged by MLLMs. Add physics-engine re-simulation or contact-consistency checks (contact points, interpenetration, momentum/energy plausibility).
- Camera-motion confounds: MAS/MSS may misinterpret ego-motion as subject motion. Incorporate camera ego-motion estimation and subtract it from motion metrics; report camera-motion-normalized scores.
- Metric gaming risk: MAS clamping and MSS thresholds may be exploitable (e.g., small periodic motions, excessive blur). Disclose hyperparameters and add adversarial test cases to detect metric gaming.
- Weighting and aggregation opaque: The benchmark averages nine indicators, but weighting and uncertainty are not detailed. Publish metric weights, per-metric confidence intervals, and sensitivity analyses.
- Human study underpowered: 30 annotators and 10 models with a non-standard 5/3/1 aggregation may inflate rank correlation. Use larger, stratified studies with Bradley–Terry or Thurstone models and task-level analyses.
- Fairness across closed-source APIs: Sora v2 could not produce ~50/650 videos; how missing outputs affect scores is unclear. Standardize failure handling (timeouts, retries) and report “attempted vs. succeeded” rates per model.
- Safety not evaluated: Generated behaviors that collide with humans, cause damage, or violate lab safety are not quantified. Introduce safety/ethical risk metrics (near-miss rates, unsafe contact, prohibited tool use).
- Robustness unmeasured: No stress tests for occlusions, clutter, adverse lighting/weather, motion blur, or sensor artifacts. Add targeted robustness suites and report performance deltas.
- Generalization/OOD: No experiments on cross-domain transfer (new robots, unseen objects, environments). Include OOD splits and measure zero-shot transfer.
- No downstream control validation: The claim that better RBench scores imply better embodied utility is not verified. Test whether training/finetuning on RoVid-X improves policy learning, IDM accuracy, or sim2real on standard robot benchmarks.
- Limited dataset validation: Finetuning with only MSE on two models lacks ablations. Provide scaling curves (data size), annotation utility studies (with/without flow/depth), and comparisons vs. prior datasets under identical training.
- Dataset modality gap: RoVid-X is video-only; it lacks synchronized proprioception, actions, gripper states, force/torque, audio. Add multi-modal subsets and evaluate their impact on action inference and IDM.
- 3D calibration missing: Depth is relative; no camera intrinsics/poses, no 2D/3D keypoints, no URDF alignment. Provide approximate calibration, per-frame keypoints, and morphology metadata to enable 3D-consistent evaluation.
- Auto captions/segmentation quality unknown: Task segmentation and captions are MLLM-generated without reported accuracy. Release a human-verified subset and inter-annotator agreement; quantify caption/segment error rates.
- Physical annotation reliability: Flow/depth from AllTracker/Video Depth Anything are not ground-truthed. Provide benchmark subsets with sensor GT or synthetic renderings to measure annotation error.
- Distribution balance unclear: No evidence of balanced representation across embodiments, tasks, camera views, or environments. Publish stratified statistics and provide balanced training/eval splits.
- Object/skill ontology not standardized: Lack of a shared taxonomy for objects, affordances, and skills hampers cross-dataset learning. Propose and release a consistent ontology with mappings to common datasets.
- VSR preprocessing may distort dynamics: FlashVSR could introduce temporal artifacts affecting physics priors. Quantify the impact of VSR on motion/physics metrics and consider raw+VSR dual releases.
- Multi-entity collaboration underspecified: Definitions and eval for multi-robot/human–robot collaboration are not detailed. Add role-conditioned prompts, interaction protocols, and metrics for coordination and handovers.
- Cross-embodiment alignment open: No explicit mechanism to align disparate morphologies. Release per-video kinematic graphs/URDF references and propose morphology-conditioned metrics or keypoint-based alignment.
- Reproducibility kit incomplete: Exact seeds, sampling parameters, video lengths, and API settings are not fully standardized. Provide a deterministic eval harness, cached outputs, and versioned leaderboards.
- Environmental/societal aspects: Compute cost/carbon footprint and licensing/consent auditing for web videos (including PII) are not addressed. Publish a dataset card with licensing provenance, PII filtering, and sustainability metrics.
Practical Applications
Immediate Applications
Below is a focused set of actionable, real-world use cases that can be deployed now, drawing on the paper’s benchmark (RBench), automated metrics, and dataset (RoVid-X).
- Benchmark-driven vendor selection and QA for video-generation models in robotics
- Sectors: robotics, manufacturing, logistics, software
- Tools/workflows: adopt RBench and its automated MLLM-based metrics (e.g., Physical-Semantic Plausibility, Task-Adherence Consistency, MAS/MSS, Robot-Subject Stability) in CI/CD to gate releases of video generators used in synthetic data pipelines; create a “RBench CI plugin” to continuously score new model versions
- Assumptions/dependencies: access to Qwen3-VL or GPT-5 evaluators; stable integration with GroundingDINO, GroundedSAM, CoTracker, and Q-Align; the benchmark’s high human alignment (Spearman 0.96) holds for your model/task distribution
- Synthetic teleoperation replacement to bootstrap robot policy training
- Sectors: robotics, manufacturing, logistics; academia
- Tools/workflows: use RoVid-X to pretrain video world models and generate robotic trajectories; extract actions via inverse dynamics or latent action models; build “Video-to-Action” pipelines for policy initialization or data augmentation
- Assumptions/dependencies: adequate compute; reliable IDM/latent-action extraction; careful domain adaptation to your robot morphology and environment
- Pretraining visual modules with physical priors
- Sectors: computer vision, robotics software
- Tools/workflows: leverage RoVid-X optical flow and depth annotations to supervise perception modules (tracking, depth, flow) and improve robot scene understanding; integrate into multi-task training of vision backbones
- Assumptions/dependencies: annotation accuracy from AllTracker and Video Depth Anything; consistent data loading and pre-processing
- Academic evaluation standardization for embodied video generation
- Sectors: academia, research consortia
- Tools/workflows: use RBench for paper benchmarking and ablations; report task completion and physical plausibility sub-metrics alongside visual quality; publish failure-mode analyses (e.g., floating/penetration, non-contact attachment)
- Assumptions/dependencies: community buy-in; reproducibility of prompt templates and temporal VQA checklists
- MLOps monitoring for video generation services
- Sectors: software platforms, ML infrastructure
- Tools/workflows: deploy automated metrics as service-level indicators; flag regressions in motion amplitude and smoothness; alert on robot-subject stability drifts when models are updated
- Assumptions/dependencies: reliable metric computation at scale; threshold calibration to minimize false alarms
- Robotics education and workforce training
- Sectors: education, vocational training
- Tools/workflows: use RoVid-X in coursework to teach physical plausibility, task segmentation, and action semantics; use RBench metrics for grading student models in lab assignments
- Assumptions/dependencies: access to dataset (licensing/hosting), sufficiently modest compute for student-scale experiments
- Content filtering and quality gating for robotic video archives
- Sectors: media platforms, internal knowledge bases
- Tools/workflows: apply Physical-Semantic Plausibility checks to flag implausible robot videos; auto-tag videos with object/embodiment metadata for retrieval
- Assumptions/dependencies: MLLM evaluator robustness to varied camera viewpoints; acceptable error rates for moderation workflows
- Rapid prototyping of robot tasks across embodiments
- Sectors: robotics integrators, startup R&D
- Tools/workflows: use RoVid-X prompts and captions to draft new task curricula; quickly validate feasibility via RBench and qualitative failure-mode checklists before investing in hardware trials
- Assumptions/dependencies: prompt-template transferability; target task coverage in RoVid-X is sufficiently similar to your intended deployment
Long-Term Applications
The following applications require further research, scaling, integration, or standardization before widespread deployment.
- Physically grounded world simulators for general-purpose robots
- Sectors: robotics, industrial automation, consumer robotics
- Tools/products: “WorldSim for Robotics” trained on RoVid-X; plug-and-play simulators that model embodied dynamics for planning and policy learning
- Assumptions/dependencies: larger-scale training and stronger physics priors; closing sim-to-real gaps; robust multi-embodiment generalization
- End-to-end co-training of policies with video world models and inverse dynamics
- Sectors: robotics R&D, autonomous systems
- Tools/products: co-training platform that jointly learns video models, policies, and IDMs using synthetic trajectories; curriculum learning across task difficulty
- Assumptions/dependencies: stable co-optimization; reliable action extraction from generated video; compute-intensive training loops
- Safety auditing and certification benchmarks for embodied AI
- Sectors: policy/regulation, standards bodies, enterprise compliance
- Tools/products: RBench-derived conformance tests and minimal physical realism thresholds; disclosure/reporting templates for embodied generative models
- Assumptions/dependencies: multi-stakeholder consensus; legal clarity around using automated evaluators; expanded test suites (edge cases, hazards)
- Factory and warehouse digital twins powered by video world models
- Sectors: manufacturing, logistics
- Tools/products: digital twin platforms that use physically faithful video generators to stress-test layouts, workflows, and robot fleets before deployment
- Assumptions/dependencies: high-fidelity environment modeling; integration with CAD/IoT telemetry; guaranteed alignment between visual simulators and operational constraints
- Real-time “physics failure detectors” for robot cameras
- Sectors: robotics safety, industrial operations
- Tools/products: on-device or edge services that watch live camera feeds and flag implausible states (e.g., floating tools, spontaneous object appearance) based on RBench-like checks
- Assumptions/dependencies: real-time inference performance; low false-positive rates; robust handling of visual artifacts and occlusions
- Training objectives shaped by physical plausibility metrics
- Sectors: academia, foundational model development
- Tools/products: incorporate MAS/MSS and stability scores as loss terms or regularizers to penalize unnatural motion and morphology drift during video model training
- Assumptions/dependencies: differentiable proxies for metrics; demonstrated gains across architectures; avoiding overfitting to metric-specific artifacts
- Universal latent action spaces across embodiments
- Sectors: robotics platforms, middleware
- Tools/products: cross-embodiment action representation library learned from RoVid-X; transfer policies between single-arm, dual-arm, quadruped, and humanoid robots
- Assumptions/dependencies: robust cross-robot mapping; alignment of kinematics/dynamics; scalable domain adaptation techniques
- Automated curriculum generation and dataset expansion services
- Sectors: data providers, ML platforms
- Tools/products: “RoVid-X++” services that continuously ingest, segment, caption, and annotate new robot videos with physical attributes; task-balanced sampling for training
- Assumptions/dependencies: dependable MLLM-driven segmentation/captioning; strong quality filters; licensing and provenance tracking
- Healthcare and service robotics simulation for task safety and compliance
- Sectors: healthcare, eldercare, hospitality
- Tools/products: video-based simulators to rehearse patient-safe manipulations and service workflows; pre-certification testing under physical plausibility metrics
- Assumptions/dependencies: domain-specific datasets (medical devices, patient interactions); stringent safety and privacy requirements; regulatory acceptance of simulated evidence
Glossary
- Action completeness: A measure of whether all required actions in a task are present in the generated video. "including structural consistency, physical plausibility, and action completeness."
- Aliasing: Temporal or spatial sampling artifacts that create jagged or flickering motion/edges in video. "targeting artifacts from low-level aliasing to high-level jitter/blur."
- AllTracker: A tracking tool used to annotate consistent motion (e.g., optical flow) of subjects across frames. "AllTracker tool"
- Co-training: Jointly training multiple components (e.g., policies and inverse dynamics) together with robot data. "enabling co-training with robot data"
- CoTracker: A point-tracking method used to follow salient features across video frames. "salient points are tracked via CoTracker"
- Contrastive VQA: A Visual Question Answering evaluation that compares reference and generated frames to score consistency. "We adopt a contrastive VQA setup"
- Diffusion models: Generative models that iteratively denoise random noise to produce data like images or videos. "Recent advancements in diffusion models"
- Embodied intelligence: AI that perceives, reasons, and acts within the physical world through a body or robot. "Video generation models have significantly advanced embodied intelligence"
- Embodiment: The physical form or body a robot has, affecting how it can act and interact. "four distinct embodiments"
- Execution completeness: Whether the generated sequence carries out all key steps of an instructed procedure. "incorporating sub-metrics like structural consistency, physical plausibility, and execution completeness."
- Foundation models: Large, general-purpose models pretrained on broad data and adaptable to many tasks. "video foundation models"
- GroundedSAM: A segmentation approach (built on SAM) guided by grounding signals to produce stable object masks. "GroundedSAM"
- GroundingDINO: A grounding-based detector used to localize active subjects from text or prompts. "GroundingDINO"
- Inverse dynamics models (IDM): Models that infer the actions needed to transition between observed states. "inverse dynamics models (IDM)"
- Latent action models: Models that represent actions in a learned latent space to derive executable controls. "latent action models"
- Long-horizon Planning: Planning tasks that require multi-step, temporally extended sequences to achieve a goal. "Long-horizon Planning"
- MLLMs (multimodal LLMs): Large models that process and reason over multiple modalities such as text and video. "multimodal LLMs (MLLMs)"
- Motion Amplitude Score (MAS): A metric quantifying the amount of meaningful subject motion while discounting camera movement. "The Motion Amplitude Score (MAS) is"
- Motion Smoothness Score (MSS): A metric measuring temporal continuity and smoothness of video quality over frames. "The Motion Smoothness Score (MSS) is"
- Non-contact attachment: A failure mode where objects move with a robot without visible contact or with incorrect grasping. "Non-contact attachment/Incorrect grasp"
- Optical character recognition (OCR): Automated extraction of text from images or video frames. "optical character recognition (OCR)"
- Optical flow: Per-pixel motion field between frames describing how image points move over time. "annotate a unified optical flow"
- Perceptual metrics: Measures that focus on visual quality aspects like clarity or sharpness rather than task correctness. "Current practices rely mostly on perceptual metrics"
- Physical plausibility: The degree to which motions and interactions obey real-world physics and constraints. "physical plausibility"
- Physical-Semantic Plausibility: An evaluation of whether actions are both physically valid and semantically consistent with the task. "Physical-Semantic Plausibility."
- Policy learning: Learning control policies for robots, often guided by simulated or real trajectories. "assisting in policy learning"
- Q-Align aesthetic score: A learned score used to assess frame-level visual quality for stability checks. "the Q-Align aesthetic score"
- Relative depth maps: Frame-wise estimations of scene depth up to a scale, capturing spatial relationships. "we generate relative depth maps"
- Robot morphologies: The structural configurations of robots (e.g., arms, legs, joints) that determine capabilities. "robot morphologies"
- Robot-Subject Stability: A metric evaluating consistency of robot shape and object attributes over time. "Robot-Subject Stability."
- Scaling laws: Empirical relationships showing how model performance improves with increased data/model size. "scaling laws and iterative optimization"
- Semantic drift: A deviation where generated actions or interpretations gradually shift from the instructed meaning. "semantic drift (e.g., "wiping" becomes "touching")"
- Spearman correlation coefficient: A rank-based statistic assessing monotonic agreement between two sets of scores. "achieves a Spearman correlation coefficient of 0.96"
- Structural consistency: Preservation of the shapes and spatial relationships of robots and objects across frames. "structural consistency"
- Teleoperation: Human-controlled operation of robots, often used to collect demonstration data. "human teleoperation data"
- Temporal grids: Uniformly sampled frame matrices used to evaluate temporal aspects of generated videos. "We construct temporal grids"
- VBench: A representative benchmark for evaluating perceptual aspects of video generation. "VBench"
- Video Depth Anything: A model for estimating per-frame depth in videos to capture scene geometry. "Video Depth Anything"
- VMBench: A benchmark suite focusing on motion and temporal evaluation of video models. "Following VMBench"
- VQA (Visual Question Answering): Asking and answering questions about visual content to evaluate understanding. "VQA-style protocol"
- World modeling: Learning predictive models that simulate future states and dynamics of the environment. "world modeling"
- World Simulators: Video models that aim to simulate physically coherent, interaction-rich environments. "are beginning to emerge as effective World Simulators."
Collections
Sign up for free to add this paper to one or more collections.

