- The paper introduces a unified Vision-Language-Action framework that learns loco-manipulation skills from cost-effective, action-free egocentric videos.
- It employs distinct latent action models using a VQ-VAE architecture and DINOv2 features to separately capture locomotion and manipulation nuances.
- The discrete LMO RL policy ensures enhanced trajectory precision and robustness, achieving superior task success rates on the Agibot X2 platform.
WholeBodyVLA: Towards Unified Latent VLA for Whole-Body Loco-Manipulation Control
Precise synergy between locomotion and dexterous manipulation is essential for deploying real-world general-purpose humanoid agents. Prior approaches in both modular and end-to-end paradigms have failed to yield robust, manipulation-aware locomotion—that is, moving with the explicit intent to enable downstream manipulation. Common root causes include (i) the prohibitive expense of large-scale teleoperated whole-body data, leading to limited coverage of loco-manipulation scenarios, and (ii) low-level RL controllers, typically velocity-tracking based, that lack the reliability and precision required for manipulation-critical body movement.
WholeBodyVLA directly addresses these limitations by introducing a unified Vision-Language-Action (VLA) framework capable of acquiring generalizable loco-manipulation skills from low-cost, action-free egocentric videos, rather than expensive, embodiment-specific demonstrations. This is complemented by a novel low-level Loco-Manipulation-Oriented (LMO) RL policy utilizing a discrete command interface, explicitly targeting manipulation-relevant movements and enhancing closed-loop stability.
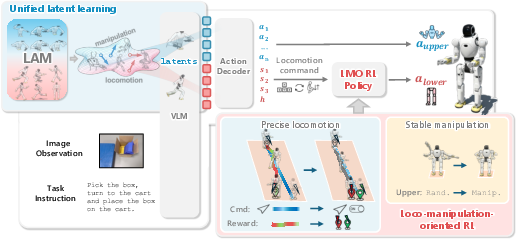
Figure 1: Pipeline of WholeBodyVLA, showing LAM pretraining, LMO RL policy integration, and deployment pathway from egocentric video/language to whole-body robot control.
Unified Latent Action Learning for Loco-Manipulation
The core contribution is the development of unified latent action models (LAMs), learned from egocentric videos and independent of direct robot action labels. Two separate LAMs are trained: a manipulation LAM from extensive real-robot datasets and a locomotion LAM from newly introduced, low-cost, manipulation-aware locomotion videos. Both utilize a VQ-VAE architecture built on top of DINOv2 features to encode frame-to-frame inverse dynamics as discrete latent codes.
Distinct LAMs are necessary due to the divergent visual change semantics in manipulation and locomotion video—static frame centers in manipulation vs. major egomotion/environmental changes in locomotion. Training a unified model without this division empirically yields suboptimal representations and ambiguous attentional foci.
During pretraining, the VLA learns to predict both manipulation and locomotion latent codes given visual and language input, unifying the supervision across modalities. Subsequently, a lightweight action decoder maps these latents to robot-specific commands, including upper-body joint positions and high-level lower-body locomotion directives. This enables a decoupled, scalable approach to whole-body control, disconnecting policy supervision from the bottleneck of expensive teleoperator data.
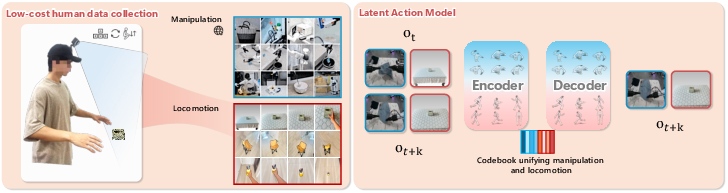
Figure 2: Low-cost egocentric data collection and pretraining pipeline for LAM. Diverse, goal-directed human locomotion is used to expose relevant visual patterns for learning.
Loco-Manipulation-Oriented RL Policy
Low-level motor control is realized via a discrete command LMO RL policy. Unlike conventional velocity-based RL controllers that optimize for generic movement over an impractically broad action space, the LMO interface restricts lower body control to a compact discrete space (advance, turn, sidestep, squat, etc.). This interface matches the needs of manipulation-aware locomotion, supporting explicit start-stop semantics, reduced trajectory variance, and robust disturbance rejection.
Policy learning proceeds in two curriculum stages:
- Stage I—Broad Gait Acquisition: The agent is trained to execute stable gaits under generic disturbances, with the upper body following randomized trajectories and joint limits gradually relaxed.
- Stage II—Precision and Manipulation-Coupled Robustness: Training is refined for trajectory accuracy (especially in yaw/orientation), with structured manipulation-induced disturbances replayed from real human demonstration data.
Empirically, this two-stage approach achieves superior trajectory accuracy and manipulation stability metrics compared to velocity-tracking policies, specifically mitigating error accumulation in long-horizon loco-manipulation sequences.
Experimental Results and Generalization
WholeBodyVLA is evaluated on the Agibot X2 platform across three composite loco-manipulation tasks: Bag Packing, Box Loading, and Cart Pushing. Each task requires nuanced sequencing of locomotion and manipulation subgoals including lateral movements, squatting, turning, dual-arm stabilization, and pushing under significant load.
Key results include:
- Quantitative superiority: WholeBodyVLA achieves a mean task success rate of 78.0%, outperforming GR00T (42.0–56.7%), modular pipelines (64.0%), and several ablated variants, with the largest gap for tasks involving extensive locomotion.
- Ablation robustness: Removing the LAM pretraining degrades performance by 38.7%; training with only manipulation LAM or a shared LAM results in 14.7–39.3% lower scores.
- Generalization improvement: Pretraining with more human video data consistently improves success rates and lowers the required amount of expensive teleoperation data during finetuning.
- Execution efficiency: Task completion times remain competitive with or faster than modular and end-to-end baselines.
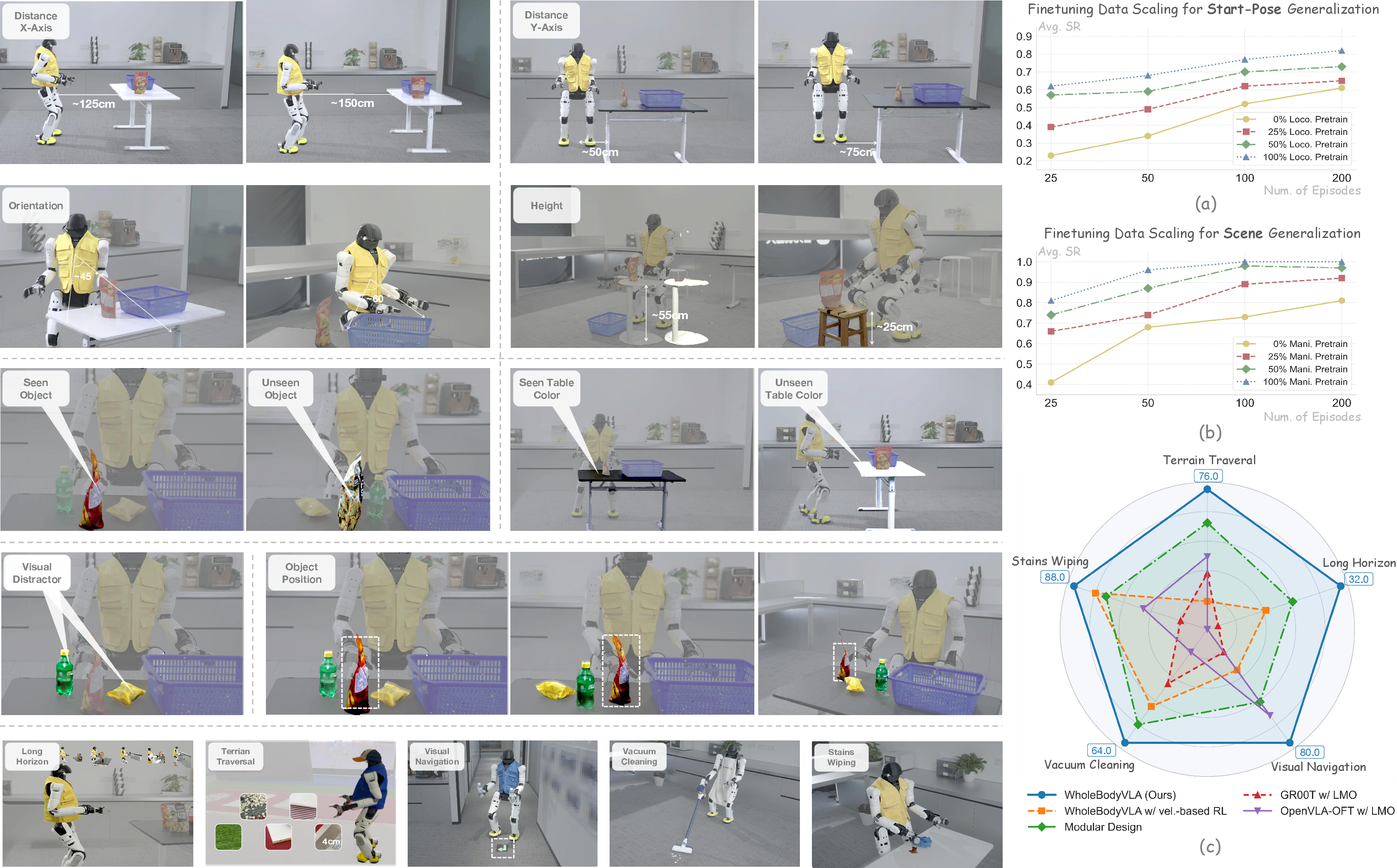
Figure 3: Real-world generalization results under varied start-poses and scene appearance. Top, data scaling curves; Bottom, comparison to baselines on extended scenarios.
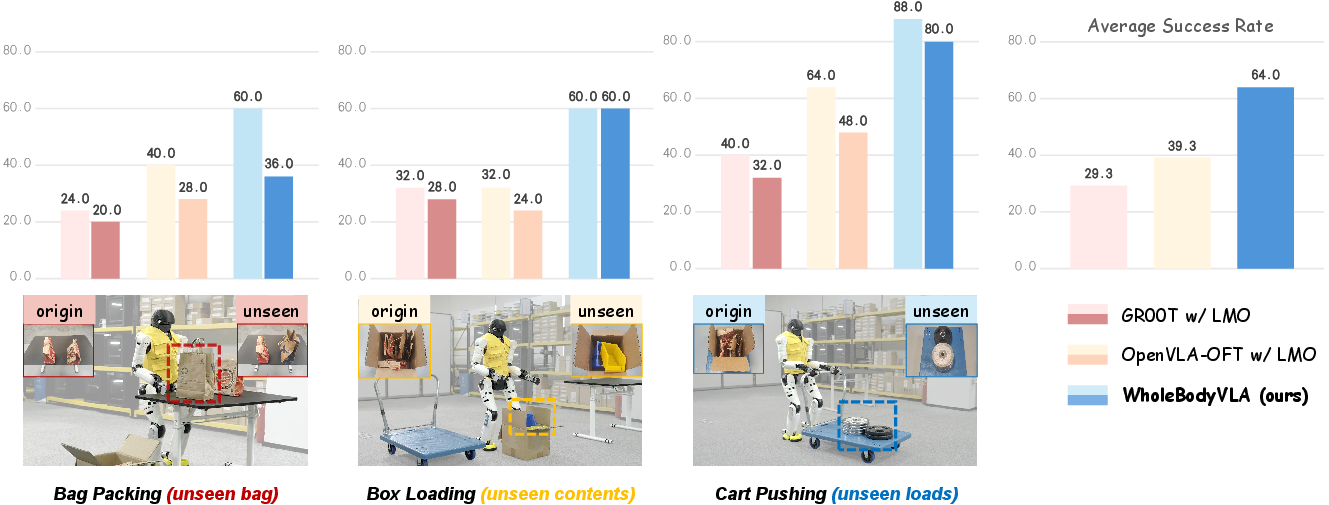
Figure 4: Visual generalization under unseen object appearances and load variations demonstrates strong robustness over GR00T and OpenVLA-OFT.
Detailed failure analysis reveals that remaining errors cluster around small stance/orientation mismatches, which primarily impact the approach phase rather than final manipulation, highlighting the efficacy but also the bounds of WholeBodyVLA's current closed-loop precision.
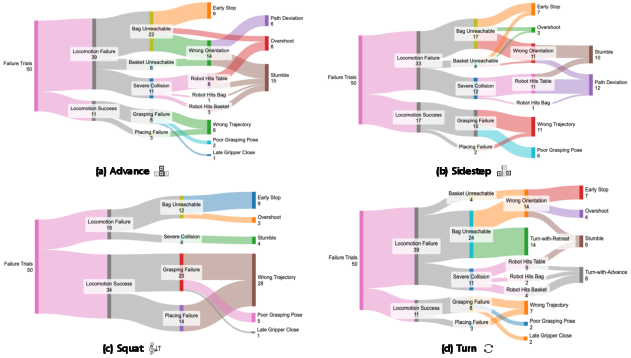
Figure 5: Failure decomposition for each locomotion primitive, partitioning errors into execution versus manipulation causes and attributing major losses to stance/orientation inaccuracies.

Figure 6: Cross-domain retrieval with shared latent actions; the same latent invokes equivalent semantic motion across human and robot video, supporting the claim of a shared, transferable representation.
Theoretical and Practical Implications
- WholeBodyVLA bridges the data efficiency gap in whole-body humanoid policy learning by harnessing action-free, human-collected egocentric videos, dramatically increasing coverage and diversity while reducing annotation cost.
- The division into distinct manipulation and locomotion LAMs illuminates fundamental inter-modal representational conflicts and offers an architectural pattern for other domains with heterogeneous control primitives.
- The LMO RL policy’s discrete interface formalizes a design tradeoff: limiting expressivity at the controller level yields improvements in precision, sample efficiency, and better scaling to long-horizon tasks where misalignments cause compounded errors.
This architecture is a strong candidate for embodied AGI deployments, where data curation and hardware-in-the-loop robustness are persistent obstacles.
Conclusion
WholeBodyVLA demonstrates a unified approach to large-space, real-world humanoid loco-manipulation control. The methodology leverages unified latent learning for acquiring scalable, transferable priors from egocentric video, and a tailored RL framework for robust motor precision. Evaluations show superior generalization, task success, and robustness compared to prior modular and foundation-model baselines. Open problems remain in scaling closed-loop accuracy for long-horizon and highly dexterous sequences, motivating future research directions that include explicit mapping, memory augmentation, and richer active perception strategies.
The framework's modular latent action representation, data-efficient learning, and robust control pipeline provide a robust foundation for the next generation of versatile embodied AI agents.

