InternVLA-A1: Unifying Understanding, Generation and Action for Robotic Manipulation
Abstract: Prevalent Vision-Language-Action (VLA) models are typically built upon Multimodal LLMs (MLLMs) and demonstrate exceptional proficiency in semantic understanding, but they inherently lack the capability to deduce physical world dynamics. Consequently, recent approaches have shifted toward World Models, typically formulated via video prediction; however, these methods often suffer from a lack of semantic grounding and exhibit brittleness when handling prediction errors. To synergize semantic understanding with dynamic predictive capabilities, we present InternVLA-A1. This model employs a unified Mixture-of-Transformers architecture, coordinating three experts for scene understanding, visual foresight generation, and action execution. These components interact seamlessly through a unified masked self-attention mechanism. Building upon InternVL3 and Qwen3-VL, we instantiate InternVLA-A1 at 2B and 3B parameter scales. We pre-train these models on hybrid synthetic-real datasets spanning InternData-A1 and Agibot-World, covering over 533M frames. This hybrid training strategy effectively harnesses the diversity of synthetic simulation data while minimizing the sim-to-real gap. We evaluated InternVLA-A1 across 12 real-world robotic tasks and simulation benchmark. It significantly outperforms leading models like pi0 and GR00T N1.5, achieving a 14.5\% improvement in daily tasks and a 40\%-73.3\% boost in dynamic settings, such as conveyor belt sorting.






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
InternVLA-A1: A simple explanation
Overview
This paper introduces a new robot brain called InternVLA-A1. It’s designed to help robots understand what they see, imagine what will happen next, and then act accordingly—all inside one system. The big goal is to make robots better at handling everyday tasks and tricky dynamic situations, like grabbing moving objects on a conveyor belt.
What questions does the paper try to answer?
- How can we make robots not just recognize things (like a cup or a zipper) but also predict how the world will change when they move (like where a box will slide next)?
- Can we combine internet-style smart LLMs with “world models” (which imagine future frames like a video) so robots plan smarter actions?
- Does training on a mix of realistic robot data and large-scale simulated data make robots more reliable in the real world?
How does the system work?
Think of InternVLA-A1 as three teammates working together inside the robot:
- Understanding expert: This is like the robot’s eyes and brain for meaning. It reads instructions and sees images to figure out what’s happening and what the goal is. It’s built on strong vision-LLMs (like InternVL3 and Qwen3-VL) that already know a lot about objects and tasks.
- Generation expert (visual foresight): This is the robot’s imagination. It predicts what the scene will look like a short moment into the future—helpful when things are moving. It compresses images into small “codes” using a tool called a VAE (you can think of it like shrinking a photo into a tiny version that still contains the important details) and then learns to predict the next tiny “photo” quickly.
- Action expert: This is the robot’s hands. It decides which moves to make (like how to grasp, turn, or place something). It uses a method called flow matching, which is like starting with a rough guess for the robot’s moves and nudging that guess step-by-step toward expert-level actions.
All three experts share one “Transformer” architecture and pass information in a controlled way: first understanding, then imagining the future, then choosing actions. This helps the robot plan with both meaning and physics in mind.
To train the system, the authors use a “data pyramid”:
- Lots of simulated data for variety (many scenes and objects, like a giant sandbox).
- Lots of real-world robot demonstrations to teach true physical behavior.
- A smaller amount of special, targeted real-world data to fine-tune for specific tasks.
They also make training efficient by smartly spreading different datasets across machines, so memory isn’t overloaded and sampling stays balanced.
What did they do to evaluate it?
They tested InternVLA-A1 on:
- 12 real-world tasks (like zipping a bag, making a sandwich, sorting objects, wiping stains).
- Challenging dynamic tasks (like grabbing moving packages on a conveyor belt).
- A large simulation benchmark with 50 tasks (RoboTwin 2.0).
They compared against strong models: π₀ (pi zero) and GR00T N1.5, which are popular vision-language-action systems.
What did they find, and why does it matter?
InternVLA-A1 performed better than the leading models, especially when the scene was changing:
- On everyday tasks, the 3B version of InternVLA-A1 improved average success by about 14.5% over π₀.
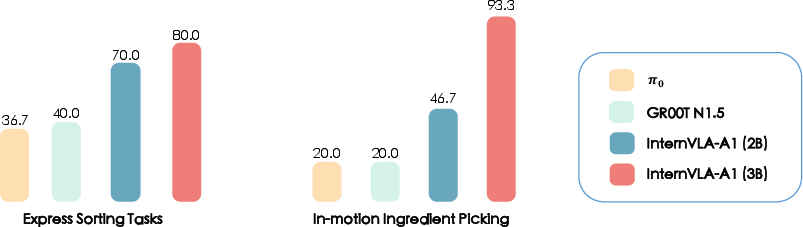
- On dynamic tasks:
- Express Sorting (moving packages): up to 80.0% success vs. 40.0% or less for others.
- In-motion Ingredient Picking (multi-robot grabbing moving food items): up to 93.3% success, beating other models by more than 70 percentage points.
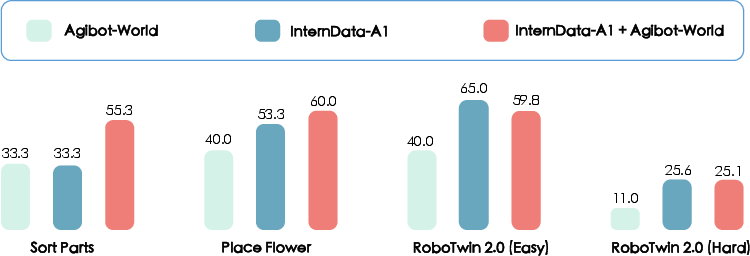
- In simulation (RoboTwin 2.0), the 3B version improved average success by 10.5% (Easy) and 5.6% (Hard) over π₀.
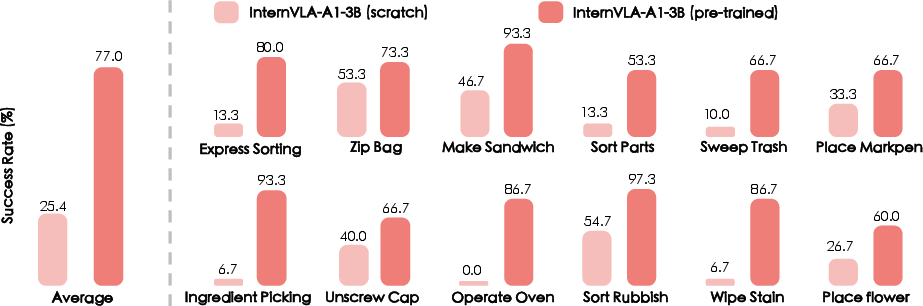
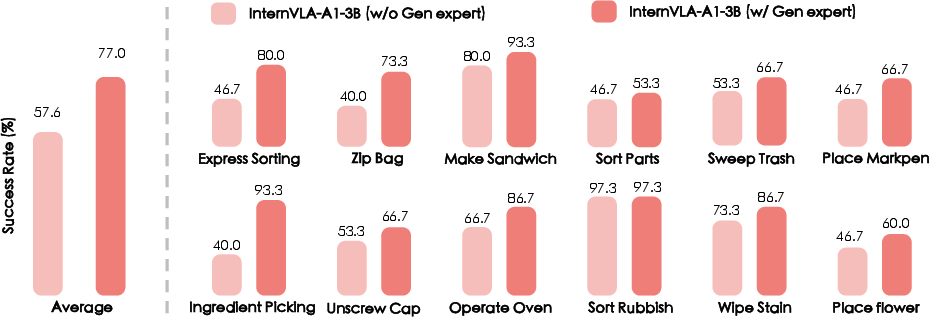
Important ablations (tests where they remove parts to see what’s essential):
- Without pretraining, performance dropped massively (from 77.0% to 25.4%). Pretraining gives the robot strong base skills.
- Without the generation expert (no visual foresight), average success fell from 77.0% to 57.6%. Imagining the near future clearly helps robots act better.
- Mixing simulated and real data beats using only one. Simulation gives variety, real data gives true physics—together they make the robot more robust.
Also, the system runs at around 13 updates per second, which is fast enough for smoother control.
Why is this important?
If robots can both understand their goals and predict how the world will change as they move, they can handle:
- Messy, changing environments (like factories with conveyor belts).
- Long, multi-step tasks (like cooking or cleaning).
- Fine, contact-rich actions (like unscrewing caps or zipping bags).
This makes robots more reliable and useful in homes, restaurants, offices, and industrial settings.
Final thoughts: What’s the impact?
InternVLA-A1 shows a practical path to more general and capable robots:
- Unifying understanding, imagination, and action in one model helps robots plan smarter and react better.
- Training with both simulated and real-world data gives breadth and realism without huge costs.
- Strong results in dynamic tasks suggest real industry potential, like sorting packages or coordinating multiple arms.
Looking ahead, this approach could become a foundation for “generalist” robots that learn faster, adapt better, and safely handle more complex, real-world situations.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed as actionable items for future research.
- Action-conditioned foresight: The generation expert predicts future latents from visual tokens and language without conditioning on planned actions or proprioception. Investigate action- (and state-) conditioned predictive dynamics to improve causal fidelity and counterfactual reasoning.
- Prediction horizon and multi-step rollouts: The foresight horizon is fixed at and only a single future frame is predicted. Assess sensitivity to horizon choice, evaluate multi-step rollouts, and quantify compounding error effects in closed-loop control.
- Temporal modeling depth: Generation uses two timestamps ; the benefits of longer visual context (e.g., multi-frame history, explicit optical flow) for dynamics understanding are not explored.
- Latent compression trade-offs: Visual latents are compressed to tokens per image before generation. Quantify how this compression impacts fine-grained spatial fidelity, small-object manipulation, and contact-rich tasks; explore adaptive compression or learned pooling schemes.
- Decoder training and reconstruction quality: The Cosmos decoder is used for reconstruction, but it is unclear if it is trained jointly or frozen. Measure reconstruction quality and its downstream effect on action prediction; evaluate end-to-end training of tokenizer/decoder to improve fidelity.
- Uncertainty-aware control: The model provides point predictions of future latents and actions without uncertainty estimates. Explore predictive uncertainty calibration and risk-aware control policies to improve safety and robustness.
- Robustness to prediction errors: While prior world models are noted as brittle, this work does not quantify InternVLA-A1’s sensitivity to foresight errors. Conduct stress tests on degraded foresight quality and measure how action performance degrades.
- Flow matching design choices: The action policy uses a fixed Beta schedule, an Euler ODE solver, and a specific chunking strategy (with unspecified). Systematically compare solvers (e.g., Heun, RK4), schedules, and chunk lengths; analyze stability, sample efficiency, and multimodality handling.
- Data-efficiency and scaling laws: Post-training uses specialized real-world data, but the minimal data required and performance scaling with dataset size/composition are not quantified. Establish data-efficiency curves and sample complexity analyses for both synthetic and real data.
- Mixture-of-data sensitivity: Pretraining mixture proportions (Table: 0.39 real vs 0.61 synthetic frames) are fixed. Evaluate sensitivity to mixing ratios, curriculum strategies, and dataset weighting to optimize sim-to-real transfer and generalization.
- Fair benchmarking and data parity: Comparisons to and GR00T N1.5 do not control for training data scale/composition differences. Provide matched-data baselines and report training compute to ensure equitable comparisons.
- Generalization breadth: Real-world evaluation covers 12 tasks with two dynamic families (conveyor sorting; in-motion picking). Extend to other challenging dynamics (deformables, fluids, tool use, nonprehensile manipulation), varied lighting/occlusions, and environmental shifts to probe generalization limits.
- Cross-embodiment transfer: The model is evaluated on three embodiments but lacks a systematic study of zero-shot cross-morphology transfer, embodiment mismatch, and policy portability to unseen robots.
- Multi-robot coordination: The two-robot task results are promising, yet the architecture and training strategy for coordination (centralized vs decentralized control, communication protocols, timing) are not detailed. Investigate scalability to more robots and heterogeneous teams.
- Real-time performance constraints: Inference runs at ~13 Hz on an RTX 4090. Assess performance on edge/onboard compute, latency under multi-view/high-resolution inputs, and the control quality needed for faster dynamics (e.g., 50–100 Hz).
- Sensor modality gaps: Foresight excludes proprioception and force/tactile inputs; action uses proprioception but foresight does not. Explore integrating depth, force/tactile, audio, and haptics to improve contact-rich manipulation and physical reasoning.
- Attention mask design: The cumulative segment mask enforces understanding → generation → action flow. Analyze alternative attention topologies (e.g., cross-attention bridges, bidirectional coupling) and their impact on information flow, stability, and interpretability.
- Interpretability and diagnostics: There is no analysis of what the model attends to across experts. Provide attention visualizations, feature attribution, and causal probes to understand how foresight influences actions and to aid debugging.
- Safety and failure modes: The paper does not discuss safety constraints, contact force limits, or recovery strategies. Establish safety-aware training and runtime safeguards; report failure taxonomies and near-miss analyses.
- Domain gap quantification: The sim-to-real gap is argued to be reduced via hybrid data, but gap metrics and ablations (e.g., Fréchet-like metrics for embodied domains, pose/contact distributions) are missing. Quantify and track domain gap across tasks and data mixtures.
- Policy stability and smoothness: Success rates are reported, but trajectory smoothness, jitter, energy use, and contact quality are not measured. Include kinematic/dynamic quality metrics and human-rated assessments of manipulation fluency.
- Long-horizon planning: The method focuses on short-horizon action chunks and single-step foresight. Investigate hierarchical planning (high-level sequencing plus low-level control), temporal abstraction, and memory mechanisms for extended tasks.
- Online adaptation and self-improvement: Post-training is offline on specialized data. Explore online learning, preference corrections, self-supervised or RL fine-tuning, and safe exploration to adapt during deployment.
- Task-specific underperformance analysis: Some simulation tasks show lower performance for certain variants (e.g., “Pick Dual Bottles” easy setting). Provide per-task error analyses to identify weaknesses (e.g., grasp strategy, visual ambiguity, timing).
- Reproducibility of specialized data: The collection process for specialized real-world data is not fully specified (task definitions, teleoperation protocol, annotation quality). Release protocols/specs and minimal datasets to facilitate replication.
- Licensing and ethical considerations: Large-scale datasets (especially real-world) may have licensing, privacy, or safety constraints. Clarify licensing, consent, and ethical review processes for data and deployment.
- Integration with low-level controllers: The mapping from predicted actions to robot-specific controllers (compliance, impedance, trajectory smoothing) is not detailed. Evaluate controller compatibility, parameterization, and failure recovery across embodiments.
- Task instruction grounding: The pipeline relies on instruction tokens for conditioning, but misinterpretation or ambiguity in language inputs is not addressed. Study robust instruction grounding, ambiguity resolution, and language-to-dynamics alignment.
Practical Applications
Immediate Applications
Below is a concise list of deployable, real-world use cases that can be implemented now, along with sectors, potential tools/products/workflows that might emerge, and key assumptions or dependencies.
- InternVLA-A1 Dynamic Sorting Kit for Conveyors [industry: manufacturing, logistics]
- What: Retrofit existing conveyor lines to perform “chasing” grasps, package flipping, and label-presenting for express sorting, as validated in the paper’s Express Sorting task.
- Tools/products/workflows:
- Product: “InternVLA-A1 Dynamic Sorting Kit” (multi-view cameras + 3B model + ROS 2 node + PLC interface).
- Workflow: Post-train with 100–500 teleoperation episodes; calibrate cameras; integrate with conveyor PLC; use safety stops.
- Assumptions/dependencies: Requires GPU (e.g., RTX 4090-class or industrial GPU), multi-view cameras, ROS 2 integration, safety compliance (ISO 10218/TS 15066), line speeds compatible with ~13 Hz inference, modest domain-specific post-training.
- Moving-target Ingredient Picking for Food Assembly Lines [industry: food service, manufacturing]
- What: Multi-robot coordination to pick moving bread/lettuce/steak on a belt; demonstrated 93.3% success in “In-motion Ingredient Picking.”
- Tools/products/workflows:
- Product: “Kitchen Line Assistant” with synchronized dual-arm control.
- Workflow: Use InternVLA-A1 3B with foresight latents to predict future positions; integrate with existing HMI; add hygiene-compliant grippers.
- Assumptions/dependencies: Food safety protocols, sealed/cleanable surfaces, reliable belt speed sensing, GPU availability, multi-robot communication middleware.
- Retail and Warehouse Item Sorting and Restocking [industry: retail, logistics]
- What: Sorting rubbish, placing items, part sorting; proven robustness on general-purpose tasks (e.g., Sort Rubbish 97.3%).
- Tools/products/workflows:
- Product: “Retail Bin Restocker” for end-of-aisle restocking and waste segregation.
- Workflow: Few-shot post-training on store-specific SKUs; domain randomization in simulation; deploy as ROS 2 nodes.
- Assumptions/dependencies: SKU variance within training domain, reliable labeling/scanning systems, adequate lighting and multi-view coverage.
- Table bussing and light cleaning (sweep trash, wipe stains) [daily life; industry: hospitality]
- What: Robust manipulation for light cleaning tasks validated in the general-purpose suite.
- Tools/products/workflows:
- Product: “Back-of-house Bussing Assistant.”
- Workflow: Calibrate wiping and sweeping trajectories; add compliance control; run ~13 Hz control loop.
- Assumptions/dependencies: Safe human-robot co-presence, non-slippery surfaces, manipulation tools (wipers/brushes), post-training with environment-specific materials.
- Household assistance for routine tasks (zip bags, place items, sort rubbish) [daily life]
- What: General household manipulation and organization tasks supported by semantic understanding plus foresight.
- Tools/products/workflows:
- Product: “Home Organizer Assistant” with task scripts (zip, unscrew, place/organize).
- Workflow: Fine-tune with small-scale home-specific teleoperation; add safety gating on contact forces.
- Assumptions/dependencies: Consumer-grade robot hardware, reliable sensing, local compute or cloud offload, caregiver supervision for safety.
- Visual Foresight Plugin for Existing VLA Policies [software, robotics]
- What: Use InternVLA-A1’s generation expert (Cosmos VAE + fast latent prediction) to enhance dynamic scene handling for other VLA controllers.
- Tools/products/workflows:
- Product: “Foresight Action Planner” plugin (latent rollout + flow-matching action synthesis).
- Workflow: Insert foresight module as a ROS 2 node; cache understanding prefixes for low latency; align action spaces.
- Assumptions/dependencies: Access to camera latents and action interface; compatible tokenization; modest code integration effort.
- Hybrid Sim-to-Real Training Stack for Robotics Teams [academia; industry: R&D]
- What: Adopt the paper’s Data Pyramid (InternData-A1 + AgiBot-World + small specialized post-training) for rapid task onboarding.
- Tools/products/workflows:
- Product: “Sim→Real Starter Pack” with domain randomization templates and Load-balanced Parallel Training (LPT) data loader.
- Workflow: Pretrain on mixture; post-train with targeted teleoperation; evaluation on RoboTwin 2.0 tasks.
- Assumptions/dependencies: Access to datasets (HF links), compute cluster for LPT, task-relevant simulated scenes, modest real data collection.
- Academic Benchmarking and Method Studies [academia]
- What: Reproduce ablations (generation expert on/off, dataset mixes); benchmark on RoboTwin 2.0; study world-model integration with MLLMs.
- Tools/products/workflows:
- Product: Curriculum using InternVLA-A1 repo + datasets; standardized evaluation harness with domain randomization.
- Assumptions/dependencies: GPU availability, lab robots or simulators, access to InternData-A1 and AgiBot-World.
- Pre-deployment Simulation Certification via Domain Randomization [policy; industry: safety/compliance]
- What: Use the paper’s simulation benchmark approach to stress-test policies across randomized conditions prior to workplace deployment.
- Tools/products/workflows:
- Product: “Sim Cert Harness” and reporting template for safety audits.
- Assumptions/dependencies: Acceptance of sim-based evidence by regulators/insurers, defined thresholds (success rates, contact forces), traceability of training data.
- Teleoperation-Assisted Post-training Pipeline [industry: robotics services; academia]
- What: Rapidly adapt a pre-trained policy to a new site with a small apex dataset of teleop episodes.
- Tools/products/workflows:
- Product: “Post-train Studio” (record, annotate, fine-tune, validate).
- Assumptions/dependencies: Skilled operators, safe data collection environment, reproducible deployment toolkit.
Long-Term Applications
The following applications are promising but require further research, scaling, or development before broad deployment.
- High-speed Dynamic Manipulation Lines (60–120 Hz control) [industry: manufacturing, logistics]
- What: Extend InternVLA-A1 to high-throughput conveyor operations (small objects at high velocities).
- Tools/products/workflows:
- Product: “Sprint VLA” with accelerated foresight (optimized Cosmos latents, model compression, hardware acceleration).
- Assumptions/dependencies: Faster generation/inference (>30 Hz), low-latency perception stacks, better grasp planning for high-speed dynamics, certification for near-human co-presence.
- Generalist Co-bots Across Heterogeneous Embodiments [industry: cross-sector]
- What: Robust cross-embodiment transfer for varied arms/hands/end-effectors without extensive per-robot post-training.
- Tools/products/workflows:
- Product: “Cross-Embodiment Operator” SDK (calibration tools, embodiment adapters).
- Assumptions/dependencies: Standardized action spaces, adapter layers for kinematics and compliance, broader diverse datasets, embodiment-aware safety controls.
- Dexterous, Contact-rich Assembly at Scale (e.g., caps, zippers, fasteners) [industry: manufacturing]
- What: Move beyond demos to fully automated assembly tasks with fine contact dynamics.
- Tools/products/workflows:
- Product: “Dexterous Assembly Suite” combining foresight with tactile feedback and force control.
- Assumptions/dependencies: High-fidelity tactile sensors, advanced compliance control, improved world model accuracy for contact dynamics, detailed task libraries.
- Household Assistive Robotics for Elderly/Disability Support [daily life; policy: healthcare standards]
- What: Broad skill repertoire (cleaning, organizing, light meal prep) with safety and reliability in unstructured homes.
- Tools/products/workflows:
- Product: “Assistive Generalist” certified home-robot package, caregiver dashboard, teleop override.
- Assumptions/dependencies: Rigorous safety certifications, user privacy protections, robust failure handling, clear liability frameworks, subsidies/reimbursement pathways.
- Safety-aware Predictive Control with Formal Guarantees [policy; industry: safety]
- What: Integrate foresight with formal verification, constraints, and risk-sensitive planning.
- Tools/products/workflows:
- Product: “Predictive Safety Layer” (shielding policies, runtime monitors).
- Assumptions/dependencies: Verified models of dynamics, certifiable constraints, standards for ML-based controllers in safety-critical settings.
- Cloud Robotics Services (Fleet Learning and Continuous Improvement) [software; industry: robotics-as-a-service]
- What: Centralized training using Data Pyramid; continuous updates pushed to fleets with site-specific post-training.
- Tools/products/workflows:
- Product: “InternVLA Cloud” (fleet data aggregation, versioning, rollout gating).
- Assumptions/dependencies: Secure data pipelines, governance and privacy, edge-device compatibility, MLOps for robotic policies.
- Model Compression and Edge Deployment (Jetson/ARM) [software; robotics; energy efficiency]
- What: Bring ~3B models to embedded platforms while retaining dynamic-task performance.
- Tools/products/workflows:
- Product: “Edge VLA” (quantization, distillation, low-rank adapters).
- Assumptions/dependencies: Efficient tokenization and latents, optimized flow-matching sampling, hardware acceleration (DSP/NPU), real-time guarantees.
- Standardization of Sim-to-Real Data Governance and Certification [policy]
- What: Create guidelines for mixing synthetic and real data, dataset documentation, and performance thresholds for certification.
- Tools/products/workflows:
- Product: “Sim-to-Real Datasheet” standard; certification checklists.
- Assumptions/dependencies: Multi-stakeholder consensus (regulators, insurers, manufacturers), auditable training records, reproducible benchmarks.
- Healthcare and Lab Automation (pharmacy sorting, sterile handling) [healthcare]
- What: Use foresight and action synthesis for precise handling in controlled environments.
- Tools/products/workflows:
- Product: “Lab Manipulation Suite” (sterile grippers, compliance control, validated workflows).
- Assumptions/dependencies: Strict hygiene standards (GMP, CLIA), failure-safe designs, detailed process validations, integration with LIMS.
- Education and Workforce Upskilling [academia; policy: workforce development]
- What: Integrate InternVLA-A1 into curricula; teach hybrid data pipelines; train technicians for teleop post-training.
- Tools/products/workflows:
- Product: “VLA Curriculum Pack” with RoboTwin scenarios and data pyramid projects.
- Assumptions/dependencies: Access to simulators/robots, institutional support, partnerships with industry for internships.
- Hybrid Planning with Predictive Latents (MPC + VLA) [software; robotics]
- What: Combine the generation expert’s future latents with model predictive control for safer, more reliable trajectories.
- Tools/products/workflows:
- Product: “Latent MPC Planner” (costs defined over predicted latents; constraint handling).
- Assumptions/dependencies: Stable latent-to-state mapping, real-time solvers, robust state estimation, integration with robot controllers.
Glossary
- Action chunk: A contiguous sequence of actions predicted together for control. "predicts a target action chunk ."
- AdamW: An optimizer that decouples weight decay from gradient updates to improve generalization. "we optimize the model using AdamW"
- Beta distribution: A continuous probability distribution on [0,1] used to sample interpolation times in flow matching. "we sample time steps "
- bfloat16: A 16-bit floating-point format that balances range and precision for efficient training. "All experiments are conducted using bfloat16 precision."
- Bimanual manipulation: Robotic control involving two arms/hands for coordinated tasks. "which comprises 50 bimanual tasks."
- Blockwise attention mask: An attention scheme that partitions tokens into blocks with controlled cross-block attention. "We implement a blockwise attention mask over the concatenated token streams of the understanding, generation, and action experts."
- Cosmos CI 8×8 continuous VAE tokenizer: A VAE-based visual tokenizer that compresses images into continuous latents at an 8×8 stride. "Cosmos CI continuous VAE tokenizer"
- Cumulative segment mask: An attention mask enforcing staged information flow across segments of a sequence. "A cumulative segment mask enforces a strict information flow understanding generation action"
- Data Pyramid: A hierarchical data recipe mixing synthetic and real-world datasets across training stages. "This study proposes a hierarchical data pyramid framework"
- Decoder-only transformer: A transformer architecture composed solely of decoder blocks, used for autoregressive modeling. "all three experts in InternVLA-A1 adopt a decoder-only transformer architecture."
- Deconvolutional layer: Also known as transposed convolution; used to upsample latent feature maps. "using a deconvolutional layer"
- Diffusion-based action generation: Producing actions by sampling from a diffusion model conditioned on context. "decouples reasoning from diffusion-based action generation."
- Domain randomization: Systematically varying simulated environments to improve robustness and transfer. "domain randomization simulates scene variations to improve the policy's robustness in changing environments."
- Euler update: A numerical integration step to solve ODEs during sampling. "we iteratively apply the Euler update:"
- Flow matching: A generative training framework that learns a velocity field transporting noise to data. "We adopt a flow matching objective to train the VLA model."
- Inverse dynamics model: A model that infers actions from observed state transitions. "paired with an inverse dynamics model to derive actions"
- Load-balanced Parallel Training (LPT): A distributed data-loading strategy that balances dataset assignments across workers. "We therefore adopt Load-balanced Parallel Training (LPT), a distributed data-loading strategy"
- Masked self-attention: Self-attention with masks restricting which tokens can attend to others. "unified masked self-attention mechanism."
- Mixture-of-Transformers (MoT): An architecture that coordinates multiple transformer experts within a unified model. "This model employs a unified Mixture-of-Transformers architecture"
- Multimodal LLMs (MLLMs): Large models that process and align multiple modalities like vision and language. "Prevalent Vision-Language-Action (VLA) models are typically built upon Multimodal LLMs (MLLMs)"
- Multi-view video diffusion model: A diffusion-based generator that uses multiple camera views to improve spatial understanding. "utilizing a multi-view video diffusion model."
- ODE (Ordinary Differential Equation): A continuous-time formulation used to sample actions from a learned velocity field. "sampling from the learned policy distribution is achieved by solving an ODE:"
- Prefix tokens: Conditioning tokens formed from initial vision and language inputs that subsequent modules attend to. "they attend to the prefix tokens $h_{\mathrm{und}$ (cached as K/V at inference)"
- Proprioception: Internal sensing of a robot’s joint states and positions. "proprioception "
- Sim-to-real gap: The discrepancy between simulated environments and real-world deployment. "minimizing the sim-to-real gap."
- Stop-gradient operation: An operator that prevents gradients from flowing through a tensor during optimization. "and indicates the stop-gradient operation."
- Teleoperation: Human-controlled operation used to collect demonstration data. "Collected via teleoperation in targeted environments"
- VAE-based tokenizer: A variational autoencoder that encodes images into a compact latent space for generation. "employs a VAE-based tokenizer"
- Velocity field: A learned vector field guiding samples from noise toward target actions in flow matching. "The model learns a velocity field that transports noisy samples toward target actions:"
- Video prediction: Generating future visual frames to anticipate scene dynamics. "typically formulated via video prediction"
- Vision-Language-Action (VLA): An architecture linking visual perception and language understanding to action generation. "Prevalent Vision-Language-Action (VLA) models are typically built upon Multimodal LLMs (MLLMs)"
- ViT-based encoders: Vision Transformer encoders that capture high-level semantic features from images. "typically captured by ViT-based encoders"
- World Models: Generative models that learn environment dynamics to predict future states. "recent approaches have shifted toward World Models, typically formulated via video prediction"
- Zero-shot sim-to-real transfer: Deploying a model trained in simulation to real-world tasks without fine-tuning. "exhibit strong zero-shot sim-to-real transfer on several challenging tasks."
Collections
Sign up for free to add this paper to one or more collections.

