- The paper introduces a two-component system integrating LLMs with annotated UI elements to enable adaptive, real-time voice interactions.
- It employs a tree data structure for semantic annotations, optimizing UI component management and rapid information retrieval.
- Empirical evaluation shows fine-tuned T5 models excel in entity extraction and logical reasoning tasks, enhancing overall UI performance.
Large Language User Interfaces: Voice Interactive User Interfaces Powered by LLMs
Introduction
The paper "Large Language User Interfaces: Voice Interactive User Interfaces Powered by LLMs" (2402.07938) introduces a framework that aims to blend LLMs with contemporary User Interfaces (UIs) to enable dynamic, real-time interactions between users and applications. By leveraging the semantic capabilities of LLMs, the framework offers a new paradigm for UI interactions, allowing the UI components to adapt dynamically based on user prompts, rather than following a strictly defined set of triggers. This essay provides a detailed overview of the key components of the framework and evaluates its performance and future directions.
Framework Overview
The core of the framework is a two-component system consisting of a frontend and a backend powered by LLM agents. The frontend uses a custom tree data structure to store semantic annotations of UI components. Each component's role and expected behavior are textually modeled, enabling the backend LLM to interpret user prompts accurately.
Figure 1 illustrates the tree data structure, which stores these application meta descriptions.

Figure 1: Visual representation of tree data structure used to store application meta descriptions.
The framework employs a semantic annotation-driven approach for UI components to enhance interaction with the LLM engine. This enables a more intuitive user experience by allowing UI components to dynamically react to context-aware prompts.
Figure 2 displays the two-component framework integrating the annotated UI with the multimodal LLM engine.
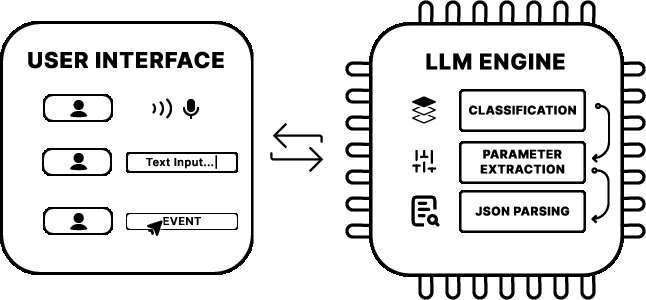
Figure 2: Two-Component Framework.
Implementation Challenges
One of the primary challenges in developing this framework was the integration of LLMs with event-driven UIs in a manner that supports real-time processing. The complex architecture involved scaling the system to manage multiple applications with potential OS-level implications.
Integration Complexity: This required an innovative approach to merge LLM capabilities with UI event management, ensuring scalability for future expansions without compromising performance.
Annotation Methodology: Selecting an appropriate data structure was another formidable task. A tree structure was deemed suitable due to its capability for efficient traversal and hierarchical organization, facilitating rapid information retrieval.
Model Selection and Training: The choice of LLMs for this multimodal engine focused on balancing computational efficiency and task-specific accuracy. The research explored diverse models like Google's T5 and BERT, optimizing them for specific UI tasks.
Evaluation and Results
The framework's evaluation focused on assessing its accuracy in classifying and processing user inputs. This involved testing various model configurations and measuring their performance across different tasks.
Figure 3 shows a comparative analysis of model performances for logical and information extraction tasks within the framework.
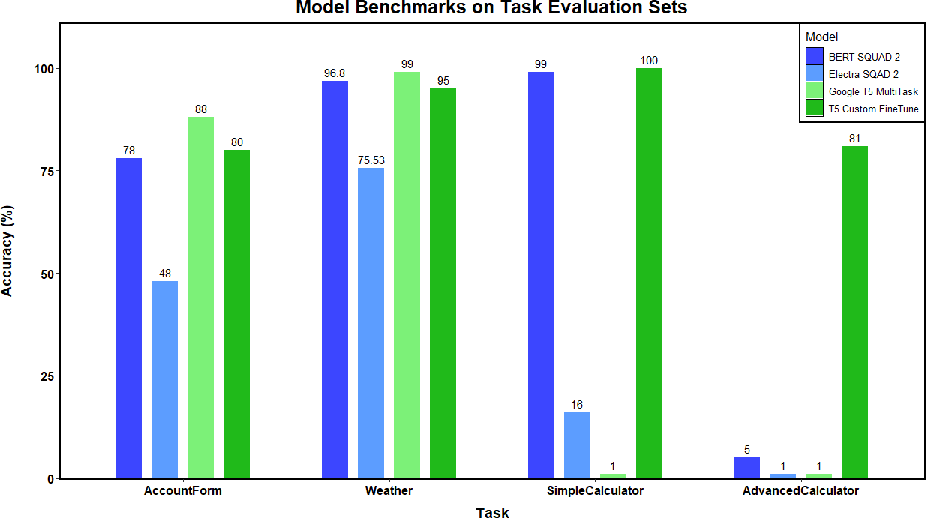
Figure 3: Accuracy comparison between models engineered for our application's tasks. Each model was trained on logical and information extraction tasks, further carefully prompt engineered to achieve the best performance possible for each task.
Task Performance: The custom fine-tuned T5 models demonstrated the best overall performance in entity extraction and logical reasoning tasks, as shown in empirical results.
Challenges: Challenges included optimizing the LLM's task delegation for efficient resource use and implementing a robust system to handle a wide variety of input scenarios.
Future Directions
To enhance the framework, several future directions are identified:
- Automated UI Generation: Expanding the annotations to automatically generate UI components could streamline the integration process, making the framework adaptable to new applications with minimal manual intervention.
- Advanced Model Deployment: Improving model configurations and employing adaptive multimodal agent setups could enhance task-specific performance and efficiency.
- Scalability Enhancements: Leveraging distributed computing and asynchronous processing will be essential to manage larger-scale applications and ensure robust real-time processing capabilities.
Conclusion
The paper details a framework that revolutionizes traditional UI by integrating LLMs to create dynamic, responsive user interfaces. The framework's ability to dynamically adapt UI behaviors based on semantic inputs has broad implications for future software systems, presenting opportunities for more natural and efficient human-computer interactions. As further developments ensue, such frameworks could significantly lower software complexity for end-users, fostering a paradigm shift in interactive and intelligent application design.