- The paper demonstrates that LLMs can serve as general-purpose simulators by synthesizing diverse UI trajectories, reducing reliance on costly real-world data.
- The methodology employs a multi-step simulation pipeline with few-shot chain-of-thought prompting and retrieval-augmented techniques to enhance simulation fidelity.
- Experiments reveal that agents trained via UI-Simulator and UI-Simulator-Grow achieve competitive performance and superior robustness in both web and mobile environments.
LLM-Based Digital World Simulation for Scalable Agent Training
Introduction and Motivation
The paper "LLMs as Scalable, General-Purpose Simulators For Evolving Digital Agent Training" (2510.14969) addresses the critical bottleneck in digital agent development: the scarcity and cost of large-scale, high-quality UI trajectory data. The authors propose UI-Simulator, a paradigm leveraging LLMs as digital world simulators to synthesize diverse, structured UI states and transitions, enabling scalable trajectory generation for agent training. The approach is motivated by the observation that LLMs, pre-trained on front-end code and procedural knowledge, can model environment dynamics and generate plausible UI states, circumventing the resource-intensive process of collecting real-world data.
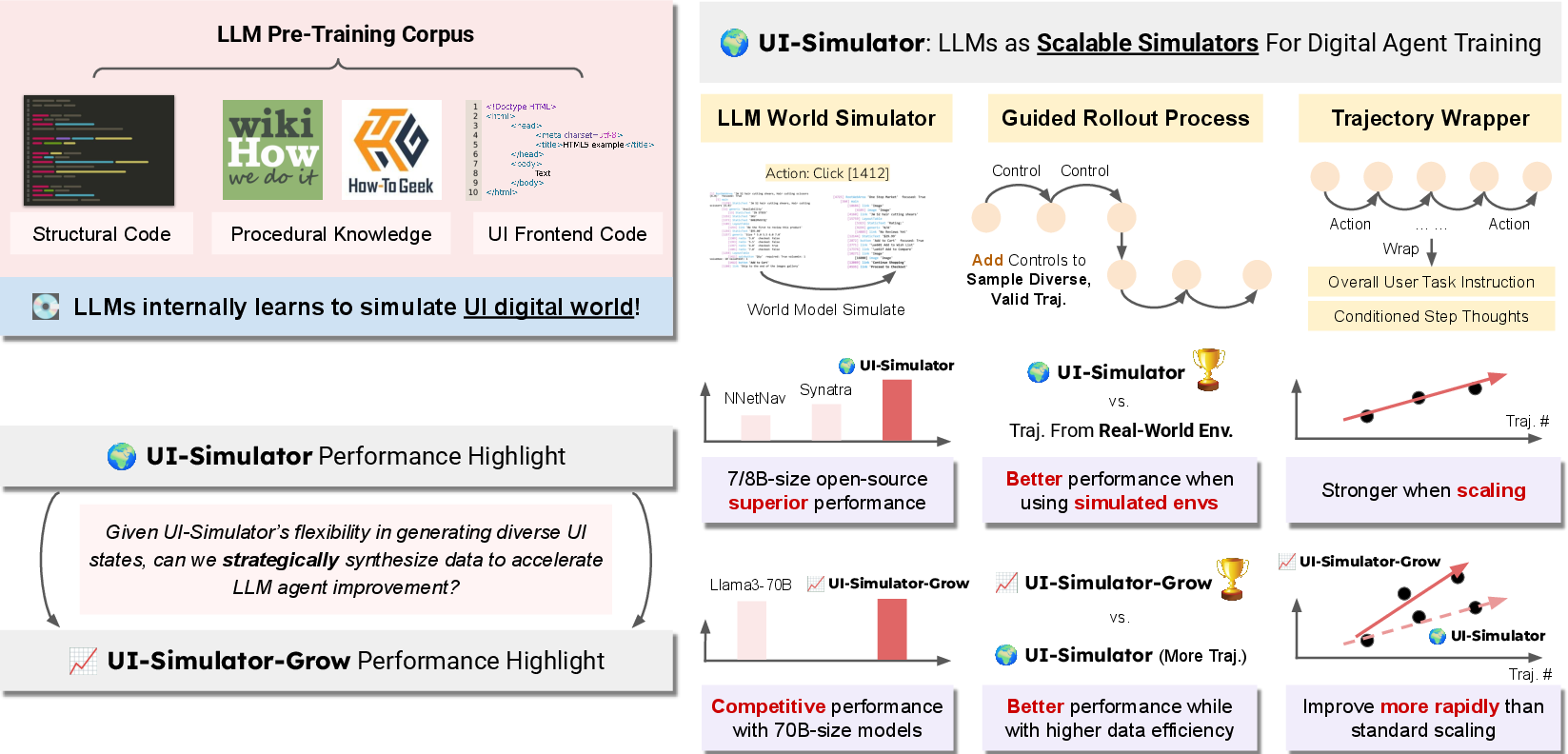
Figure 1: Overview and performance highlights of UI-Simulator and UI-Simulator-Grow.
UI-Simulator: Architecture and Simulation Process
UI-Simulator models UI environments as structured accessibility trees, where each state st encodes textual content, spatial coordinates, and dynamic attributes. The environment dynamics are governed by a transition function st+1=T(st,at), instantiated by an LLM-based simulator MLLM or deterministic rules for specific actions. Observations ot are computed by extracting elements whose bounding boxes intersect with the current viewport.
Multi-Step Simulation Pipeline
The simulation process is decomposed into three stages:
- Overview Prediction: The LLM generates a high-level summary of the next state conditioned on the current state and action.
- Rich Draft Generation: Based on the overview, the LLM produces a semantically rich, unstructured draft describing UI elements and their attributes.
- Structured Conversion: The draft is converted into a structured format, assigning coordinates and hierarchical relationships, suitable for agent training.
Few-shot CoT prompting is employed to guide the LLM at each stage, enhancing coherence and diversity.
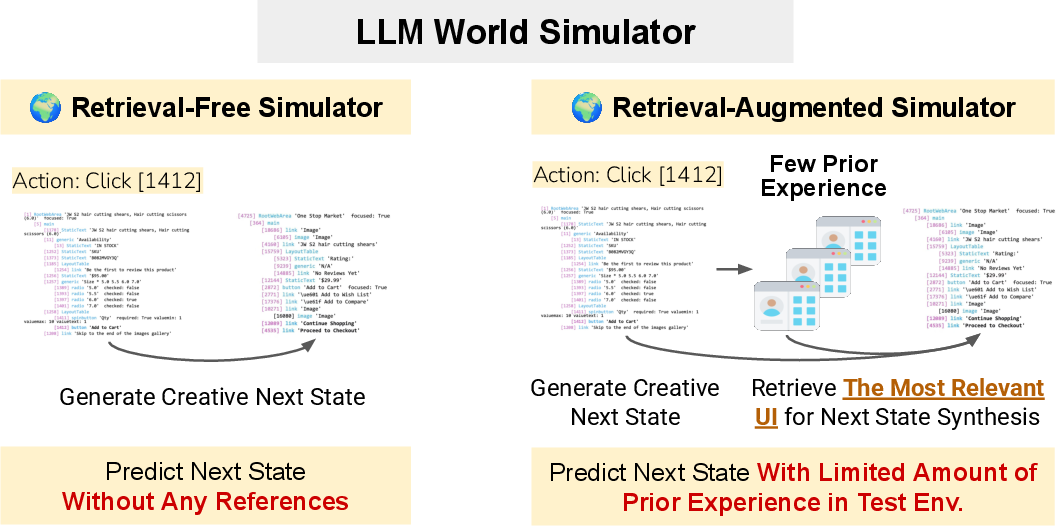
Figure 2: Overall process of how the retrieval-free/-augmented simulators predict the next UI state.
Retrieval-Augmented Simulation
To improve adaptation to new environments, UI-Simulator supports retrieval-augmented simulation. A small offline corpus D of real environment transitions is indexed. During simulation, the most relevant prior state is retrieved using a hybrid BM25 and semantic retriever pipeline, and the LLM is prompted with both the current context and the retrieved state. This grounds the simulation in real experience while maintaining diversity.
Scalable Trajectory Collection and Guided Rollouts
Instruction-Free Rollouts and Trajectory Wrapping
Trajectory synthesis proceeds via instruction-free rollouts, where a teacher agent interacts with the simulated environment, sampling actions until a coherent task is completed. The trajectory is retrospectively summarized into a user instruction G, and step-wise reasoning is reconstructed to align with G. This process yields training instances with user instructions, ground-truth actions, and step-wise reasoning.
Step-Wise Guided Rollout
To mitigate LLM bias and enhance diversity, a step-wise guided rollout process is introduced. At each step, the teacher agent proposes high-level task controls, updating them as sub-goals are completed. Actions are generated with explicit reasoning, and trajectory termination is autonomously decided. This iterative control mechanism increases the diversity and validity of synthesized trajectories.
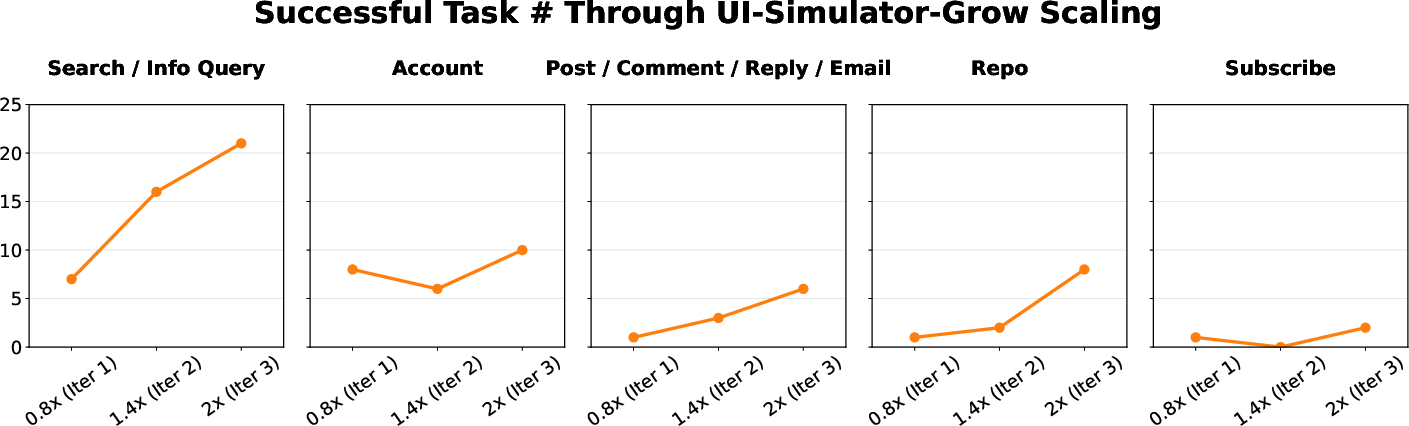
UI-Simulator-Grow: Targeted Scaling Paradigm
Blindly scaling trajectory volume is inefficient. UI-Simulator-Grow implements targeted scaling by iteratively selecting tasks with maximal learning potential, based on teacher-forcing loss signals. Tasks in the 25–75% loss percentile are prioritized, avoiding trivial or infeasible tasks. For each selected task, diverse variants are synthesized via lightweight rewriting, maintaining logical structure but varying content. Continual learning is supported via replay of representative tasks, selected using RoBERTa-based instruction embeddings and cosine similarity.
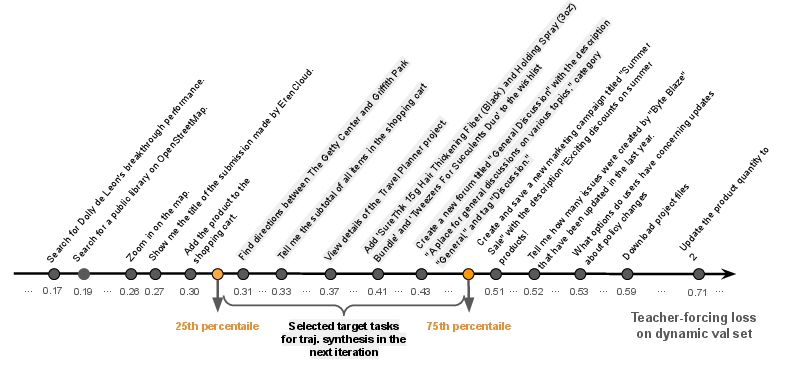
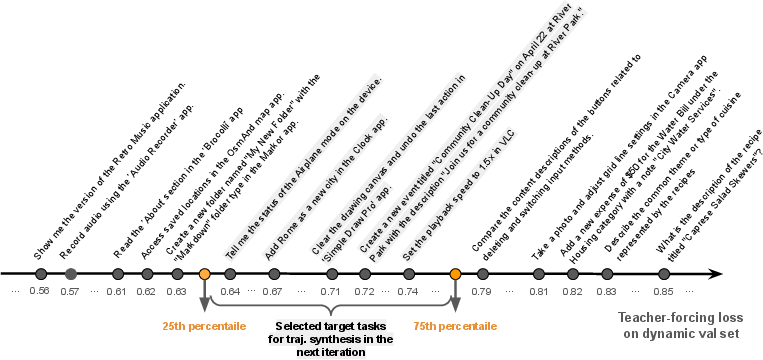
Figure 3: Target task selection for web tasks.
Experimental Results and Analysis
Benchmarks and Setup
Experiments are conducted on WebArena (web navigation) and AndroidWorld (mobile usage), using Llama-3-8B-Instruct and Qwen-2.5-7B-Instruct as base models. UI-Simulator is powered by GPT-4o-mini for simulation and rollouts. Retrieval-augmented simulation uses only a fraction of the real environment experience compared to baselines.
Robustness and Ablation
Agents trained on UI-Simulator trajectories exhibit greater robustness to UI perturbations and outperform agents trained directly on real environments with similar trajectory counts. Removal of step-wise task controls or multi-step simulation leads to significant performance drops and reduced diversity, as quantified by PCA effective dimension of task embeddings.
Qualitative Evaluation
Human evaluation across eight dimensions (realism, reasonability, validity, consistency, completion, etc.) yields satisfaction rates exceeding 90% for both UI-Simulator-F and UI-Simulator-R, confirming the high quality of synthesized trajectories.
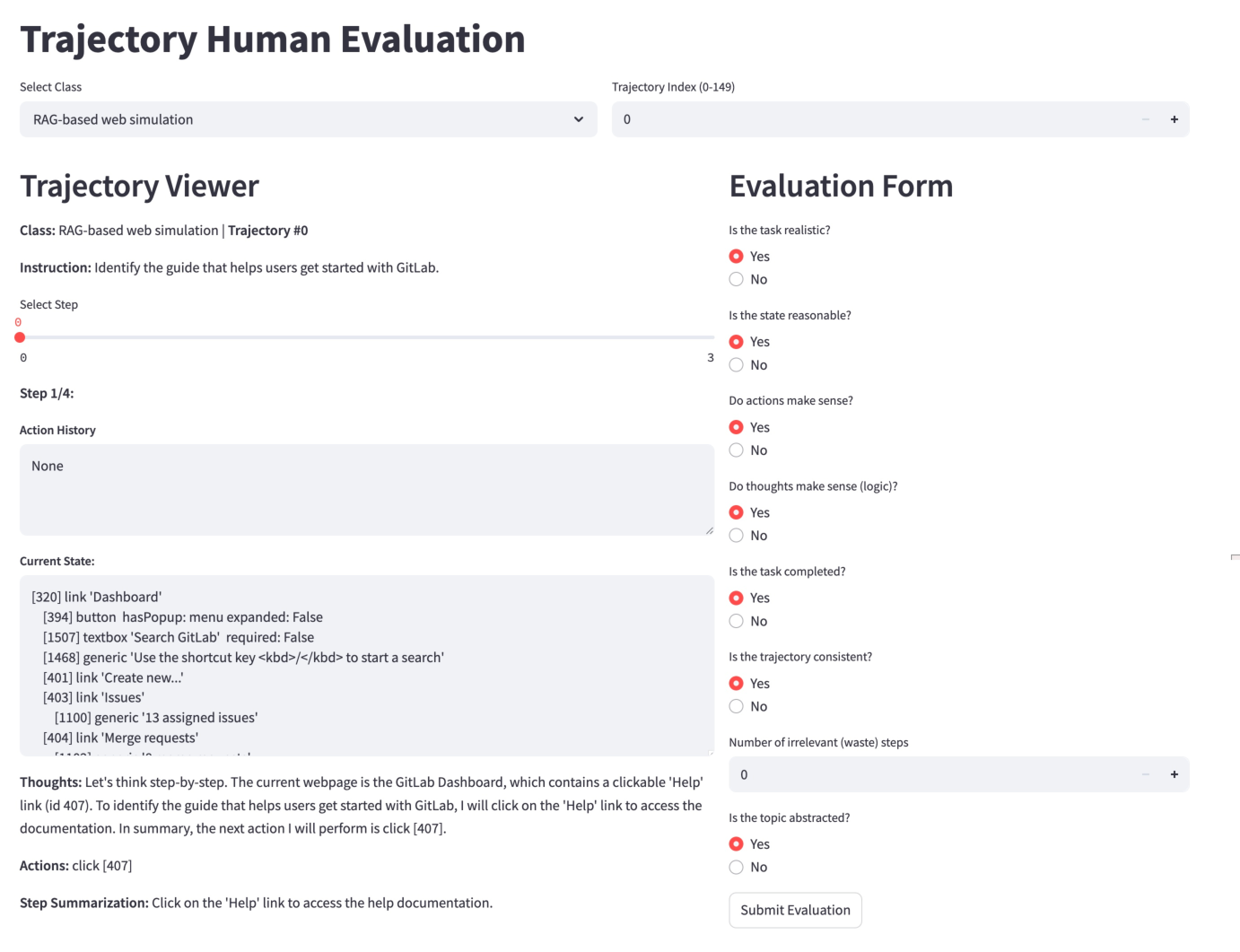
Figure 5: The front-end web interface for trajectory human evaluation.
Failure Modes
Analysis reveals that UI-Simulator-F may fuse irrelevant context, while UI-Simulator-R can overly depend on retrieved states, leading to simulation errors. These cases highlight areas for future improvement in context management and retrieval integration.
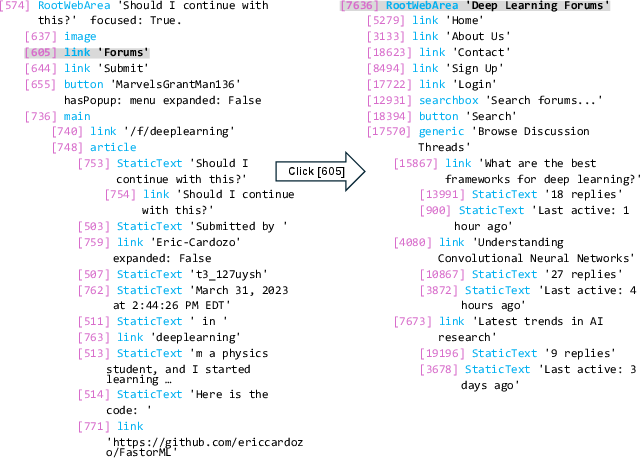
Figure 6: A case of failed simulation where UI-Simulator-F generates the new page based on irrelevant context.

Figure 7: A case of failed simulation where UI-Simulator-R overly depends on the reference state to generate the new page.
Implications and Future Directions
The results demonstrate that LLM-based digital world simulation is a viable and efficient alternative to real environment data collection for agent training. The targeted scaling paradigm enables rapid, data-efficient agent improvement, and the simulation-driven approach yields agents with superior robustness and adaptability. The framework is extensible to other UI domains and potentially to pixel-level simulation, narrowing the sim-to-real gap.
Theoretical implications include the validation of LLMs as general-purpose world models for structured environments, and the effectiveness of loss-based task selection for continual agent improvement. Practically, the paradigm reduces infrastructure and annotation costs, and supports scalable agent development in domains with limited real environment access.
Conclusion
UI-Simulator and UI-Simulator-Grow establish a scalable, efficient paradigm for digital agent training via LLM-based world simulation and targeted trajectory synthesis. The approach achieves competitive or superior performance to real-environment training, with strong robustness and data efficiency. Future work may extend the paradigm to multimodal and pixel-level environments, further enhancing the generalization and adaptability of digital agents.