- The paper presents a novel approach leveraging LLMs to facilitate multi-scenario conversational interactions in mobile UIs.
- It converts Android UI view hierarchies to HTML and uses exemplars with chain-of-thought prompting for effective task performance.
- Evaluations show improved grammar correctness, screen summarization accuracy, and superior question-answering compared to baseline models.
Enabling Conversational Interaction with Mobile UI using LLMs
This essay discusses the application of LLMs to facilitate conversational interactions in mobile user interfaces (UIs), presenting an approach that bypasses the need for extensive datasets and specialized models for each task. By leveraging LLMs, a common model can adapt to various tasks through effective prompting techniques.
Introduction
Conversational interactions with mobile devices, mediated through natural language, offer significant user advantages, potentially transforming UI manipulation for accessibility and multimodality. Existing solutions often require extensive resources for dataset creation and model training tailored to specific tasks. This work explores how LLMs, well-established in their ability to generalize across different tasks, can be adapted for mobile UIs with minimal task-specific input.
Approach
Conversation Scenarios
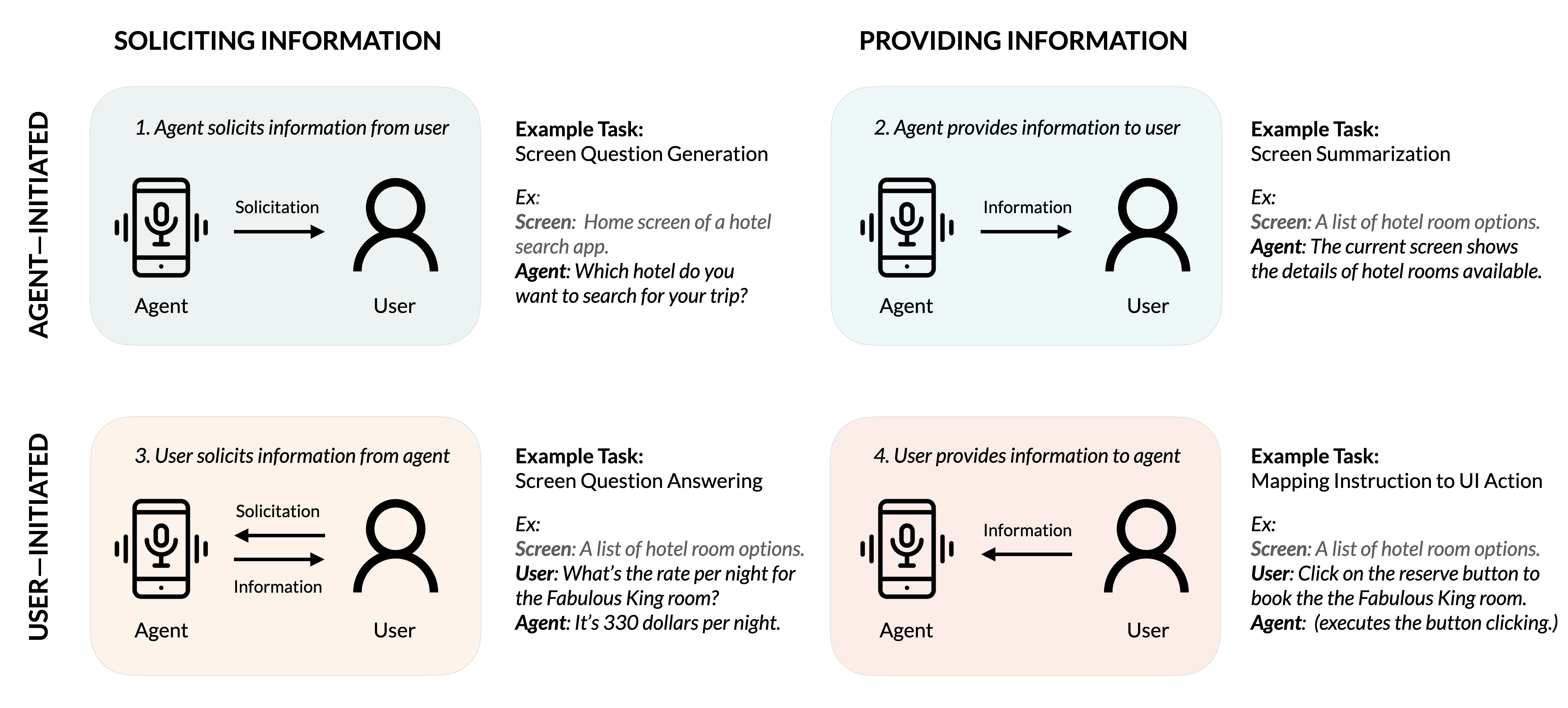
The paper defines four key conversational interaction scenarios between users and agents, each related to UI task types:
Prompts and Screen Representation
To enable LLMs to process mobile UIs, the paper introduces techniques for converting Android UI view hierarchies into HTML syntax, leveraging the HTML structure to align with LLM training data characteristics. The prompts are augmented with exemplars, containing both inputs (screen HTML) and expected outputs (questions, summaries, answers, or actions), with Chain-of-Thought prompting used for complex reasoning.
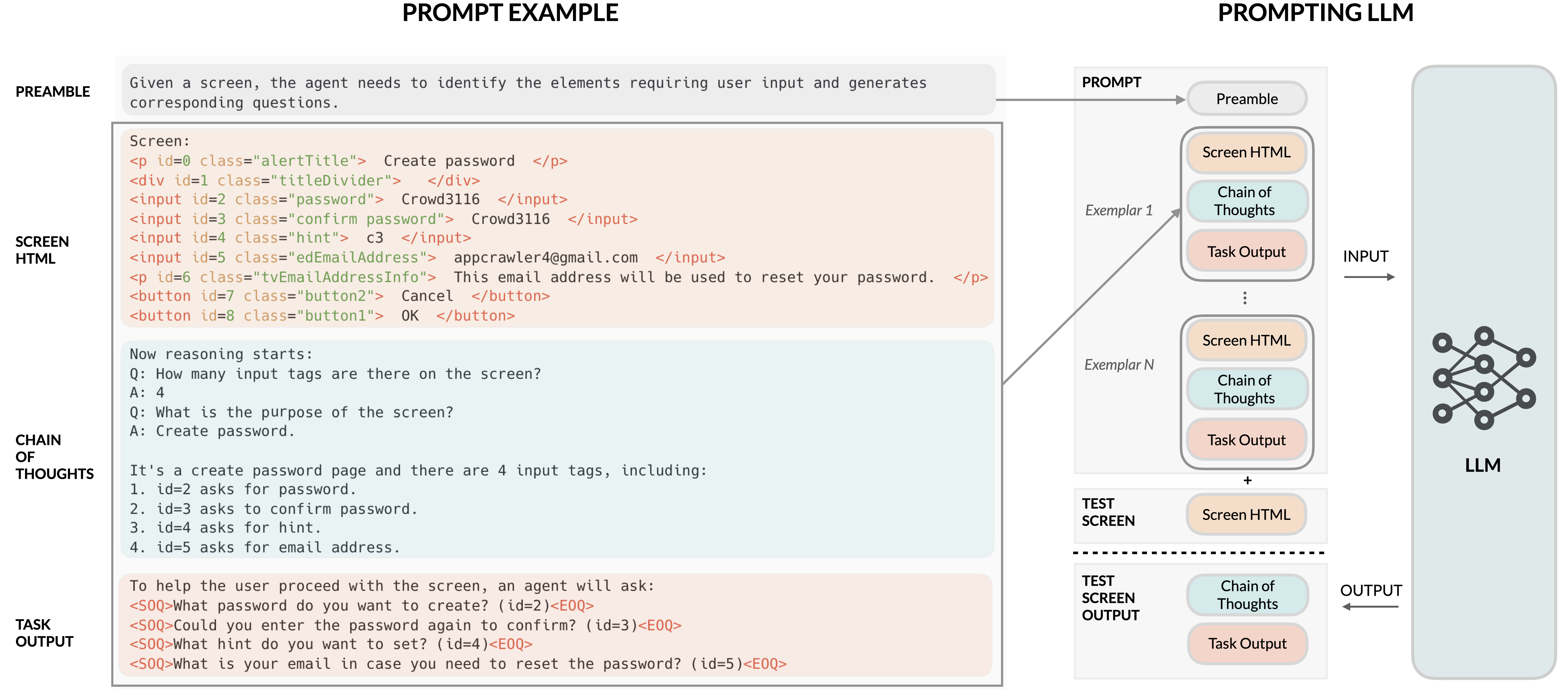
Figure 2: Illustration of the proposed prompt structure and its application in mobile UI tasks.
Task Implementation and Evaluation
Screen Question-Generation
The goal is to generate relevant questions for identified input fields. Experiments with LLMs achieved high grammar correctness and UI element relevance, outperforming a template-based baseline.
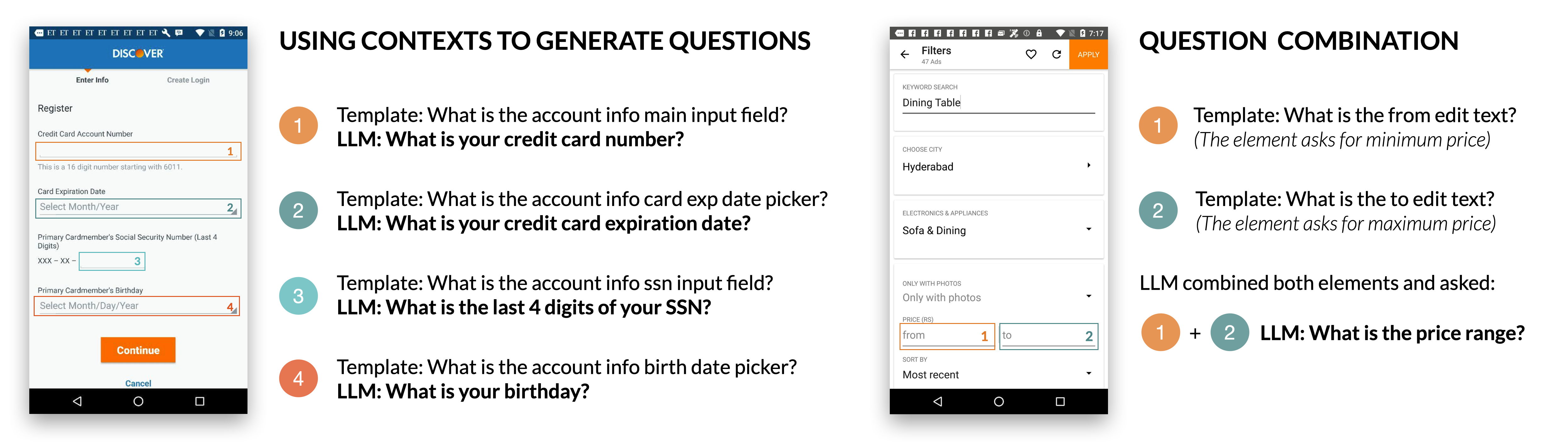
Figure 3: Example screen questions generated by the LLM, demonstrating the utilization of screen contexts for each UI element.
Screen Summarization
LLMs were tasked with summarizing screen functionalities. Human evaluations indicated that LLM-generated summaries were more accurate than those from benchmark models, despite automatic metric scores being slightly lower, showcasing the potential for LLM prior knowledge integration.
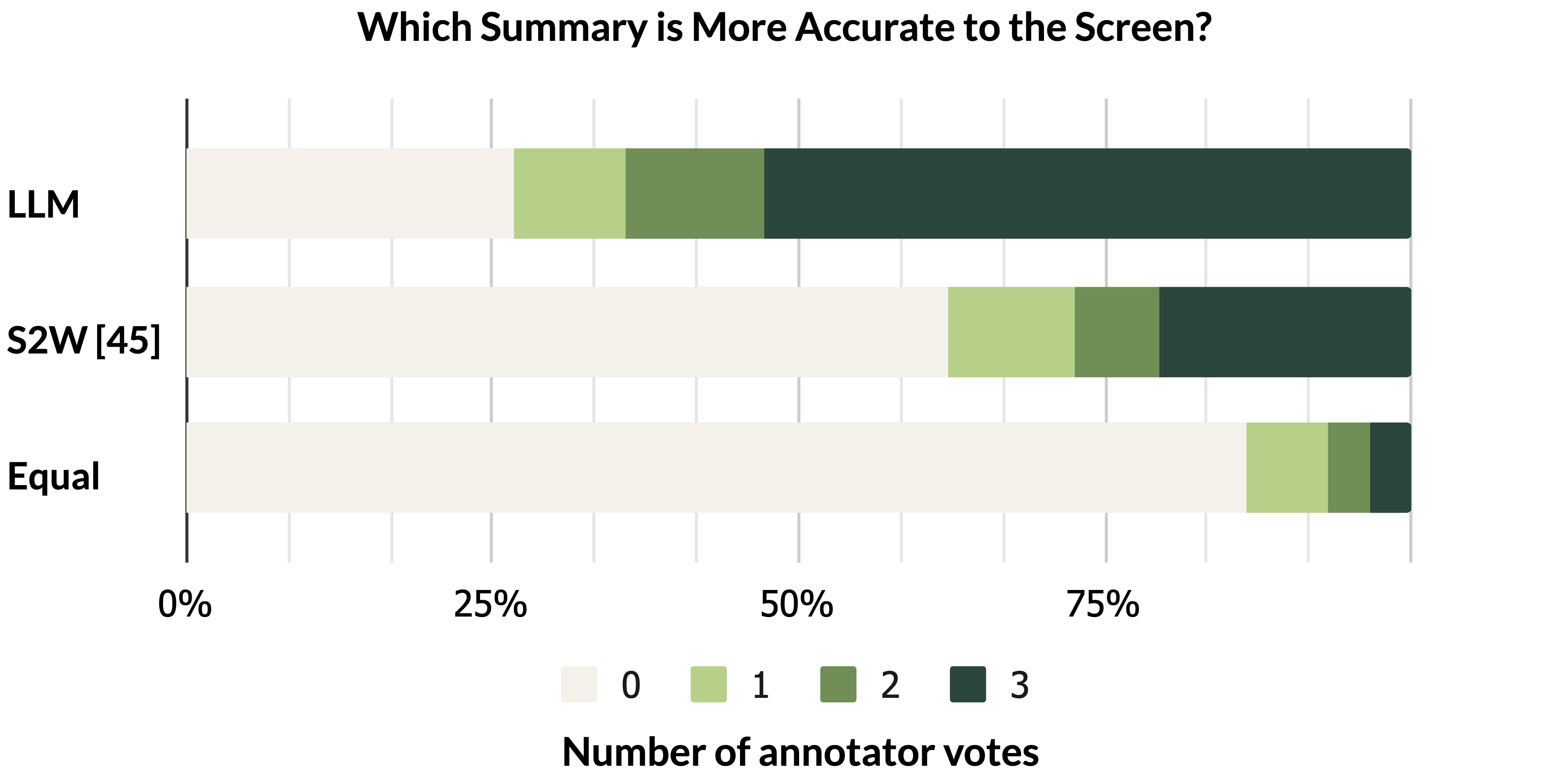
Figure 4: Annotator vote distribution across all test screens, demonstrating higher perceived accuracy for LLM summaries.
Screen Question-Answering
In this task, LLMs significantly outperformed a pre-trained text QA model by understanding screen contexts and extracting accurate information based on questions.
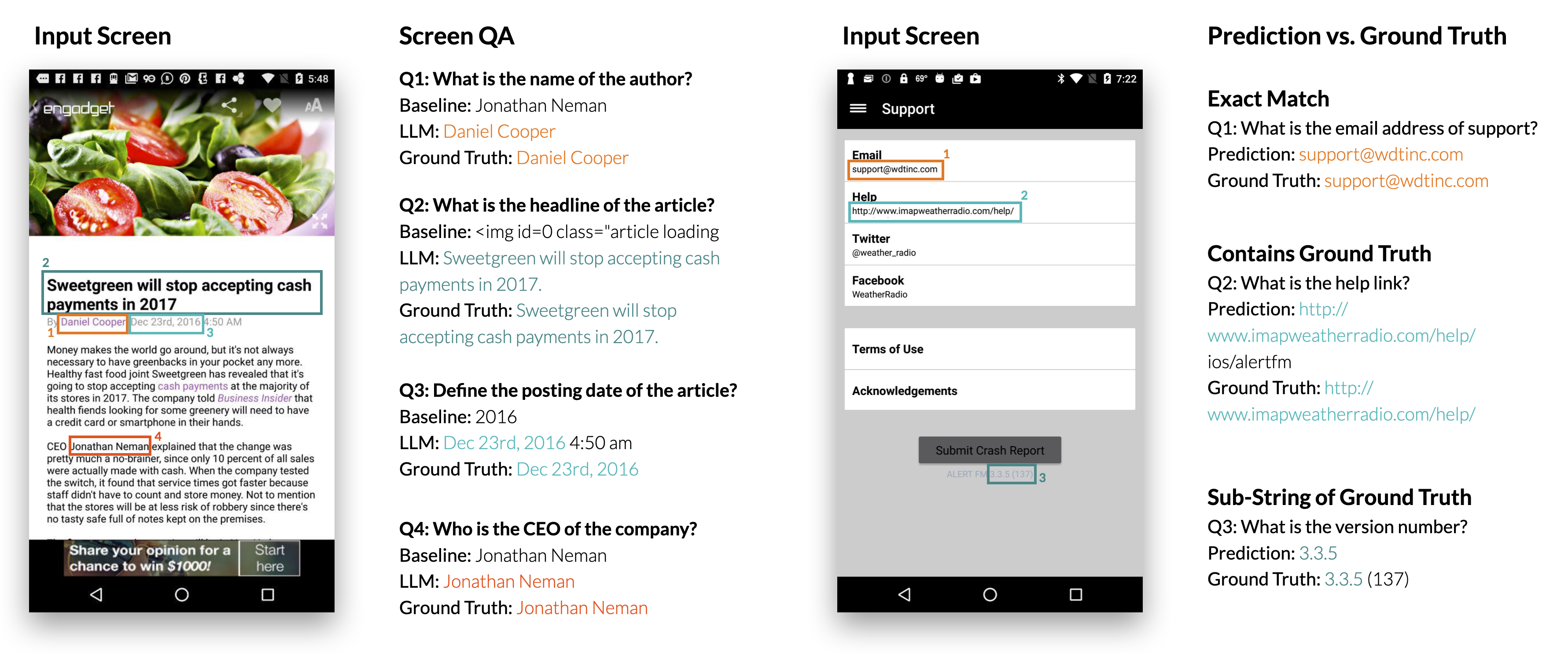
Figure 5: Example results from the screen QA experiment showing the performance superiority of LLMs over baseline models.
Mapping Instruction to UI Action
The LLMs' ability to map language commands to UI actions was evaluated. While the LLMs underperformed relative to dedicated models trained on large datasets, their performance was competitive, achieving reasonable accuracy with minimal examples.
Future Directions
The results suggest promising avenues for expanding conversational interactions, integrating multi-modal elements, and addressing limitations such as leveraging image data and multi-turn conversations. Future work may also focus on enhancing LLM steerability and refining prompt strategies to handle more complex scenarios.
Conclusion
The study demonstrates that LLMs, through strategic prompting and minimal exemplars, can effectively perform a variety of tasks within mobile UIs. This approach not only enables practical applications in HCI but also reduces the need for labor-intensive data preparation, paving the way for more accessible and efficient interface design and testing methodologies.