- The paper introduces a novel mid-training stage that integrates RL-tuned model improvements via dynamic token reweighting.
- Experimental results show a 5.2% accuracy boost and a 3.3x reduction in GPU hours across diverse LLM families.
- The iterative, bidirectional framework reinforces pre-training and post-training synergy, preserving model diversity and reasoning ability.
RL-Guided Mid-Training for Iterative LLM Evolution: An Analysis of ReMiT
Introduction and Motivation
Modern LLM training is traditionally sequential, consisting of a pre-training phase—focused on broad knowledge acquisition—and a post-training alignment phase using methods like supervised fine-tuning (SFT), direct preference optimization (DPO), or reinforcement learning (RL). While substantial progress has been made in leveraging post-training to boost model capabilities, there is a notable gap in methodology for systematically feeding post-training improvements back into the pre-trained foundation. “ReMiT: RL-Guided Mid-Training for Iterative LLM Evolution” (2602.03075) introduces a bidirectional paradigm that explicitly couples these stages, forming a self-reinforcing evolution loop for LLMs.
This paper identifies the mid-training phase—a final annealing period of high-quality, reasoning-oriented data and aggressive learning rate decay—as the critical juncture for model capability transformation. Empirical analyses reveal that, at this stage, the token distribution of the base model rapidly aligns with that of an advanced RL-tuned model (Figure 1), suggesting an optimal window for targeted intervention.
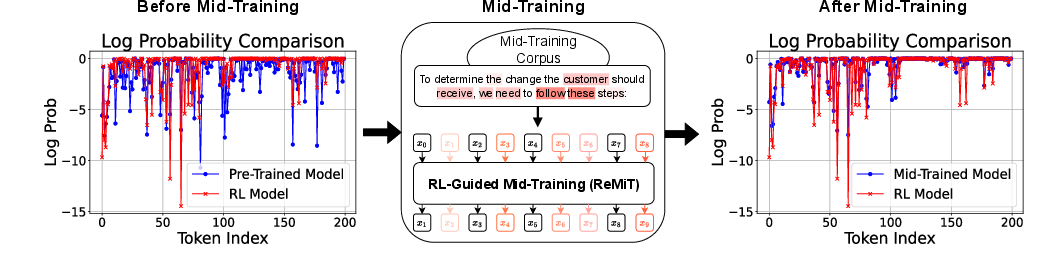
Figure 1: The mid-training stage precipitates a rapid shift in token distributions towards that of the RL model; ReMiT augments this phase via dynamic token reweighting.
The ReMiT Framework
ReMiT departs from unidirectional training by establishing a closed-loop connection between pre-training and post-training. Concretely, ReMiT reuses the in-pipeline RL-tuned model as a frozen reference to assign dynamic, token-level weights during mid-training. No specially curated external teacher or resource-intensive reference is needed, thereby preserving scalability and practicality (Figure 2).
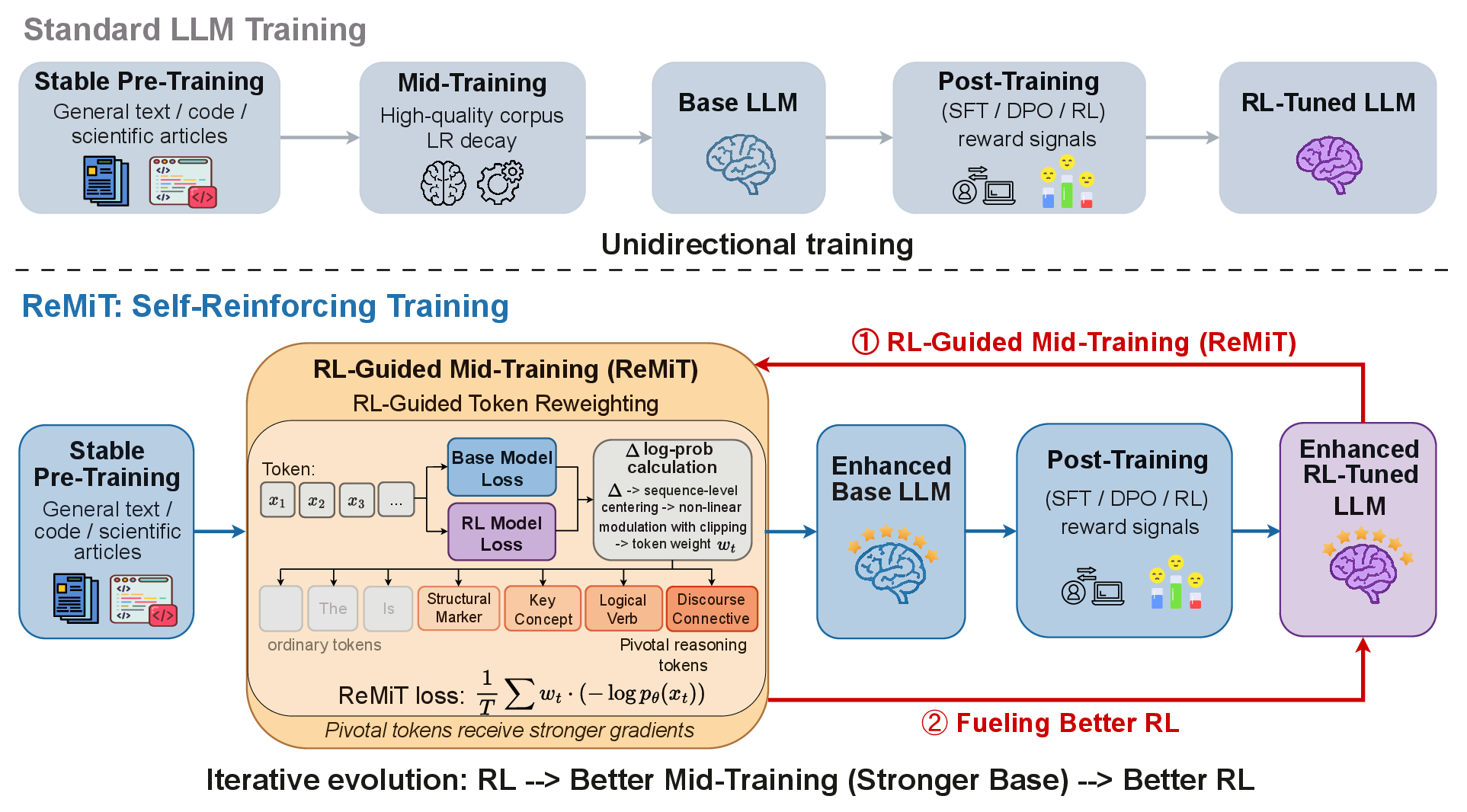
Figure 2: ReMiT’s self-reinforcing flywheel: RL-stage improvements retroactively strengthen the base model, amplifying gains in subsequent post-training.
Specifically, the framework computes the per-token log-likelihood gap between the RL reference and base model, normalizes these gaps via sequence-level centering, and modulates their weighting with a bounded, scaled sigmoid function. This process softly (rather than discretely) upweights informative, reasoning-critical tokens—empirically corresponding to discourse connectives, structural tokens, and logical markers (Figure 3)—thereby intensifying optimization pressure where the RL model shows a confidence surplus.

Figure 3: Log-probability divergence between base and RL models, highlighting sparse, high-margin tokens pivotal for superior RL reasoning.
This mechanism contrasts with existing token selection or knowledge distillation (KD) approaches that may discard context or force over-alignment, yielding suboptimal transfer or compromised plasticity.
Theoretical Contributions
From a theoretical perspective, ReMiT is framed as optimizing the KL divergence between the model and a constructed implicit target distribution (qw), which reweights the data distribution in proportion to the token-level RL gap. The resultant update is proven to locally reduce divergence to the KL-regularized optimal policy, provided the weighted target accentuates optimal decisions. Importantly, ReMiT does not alter the ground-truth direction of the learning signal (as KD does), but adaptively scales its intensity based on informativeness, ensuring both alignment and retained genericity.
The framework further avoids overfitting, as opposed to strict KD, by permitting a moderate divergence from the RL policy, thus “softly” assimilating reasoning priors while preserving model diversity. Empirical KL analyses (Figure 6b) confirm that while KD enforces narrow mimicry—detrimental to downstream post-training adaptation—ReMiT maintains generalizability.
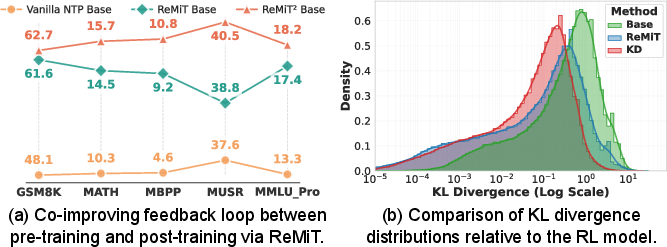
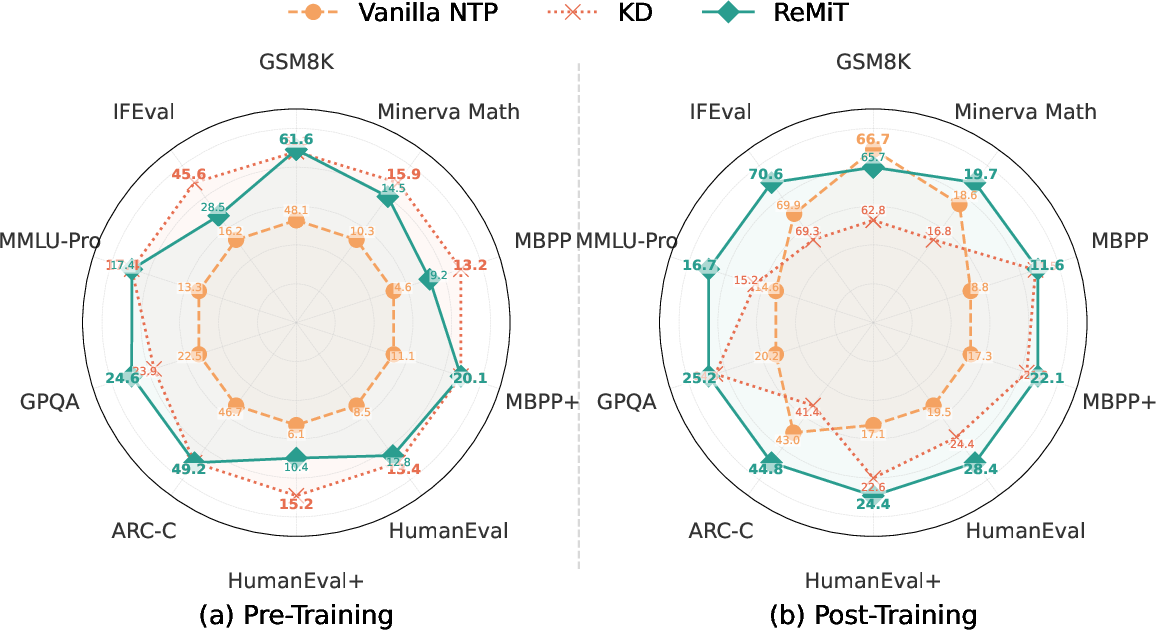
Figure 4: (a) Iterative cycles amplify gains; (b) ReMiT permits moderate KL divergence, preventing overfit to the RL reference and supporting effective post-training.
Experimental Validation
Extensive experiments are conducted across open-source LLM families (including OLMo-1B, SmolLM3-3B, and Youtu-LLM-2B), benchmarking on ten downstream reasoning and coding tasks. Results demonstrate that:
- ReMiT improves average mid-training accuracy by 5.2% and accelerates convergence to baseline levels by a factor of 6 on OLMo-1B (Figure 1a).
- Post-training performance improvements are robust: RL, SFT, and DPO applied to ReMiT-enhanced models consistently outperform those using vanilla mid-training (Figure 6).
- Iterative application (ReMiT → ReMiT2) compounds benefits: Each cycle of RL-guided mid-training using a superior RL reference incrementally amplifies both base and post-trained model performance (Figure 6a).
- ReMiT achieves better downstream retention of reasoning ability compared to strict knowledge distillation and SFT-guided baselines (Figures 10, 12).
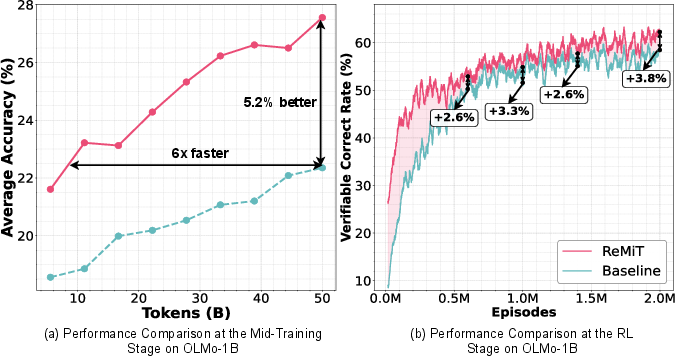
Figure 5: ReMiT delivers a 5.2% accuracy boost over baseline and achieves faster convergence; post-training, higher correct rates and overall performance are maintained.
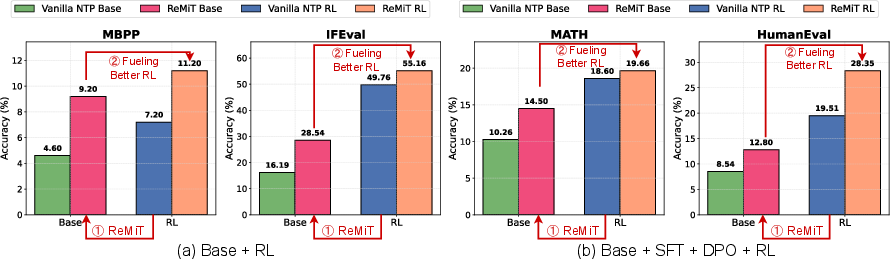
Figure 6: ReMiT’s mid-training gains robustly transfer to post-training, independent of the alignment algorithm.
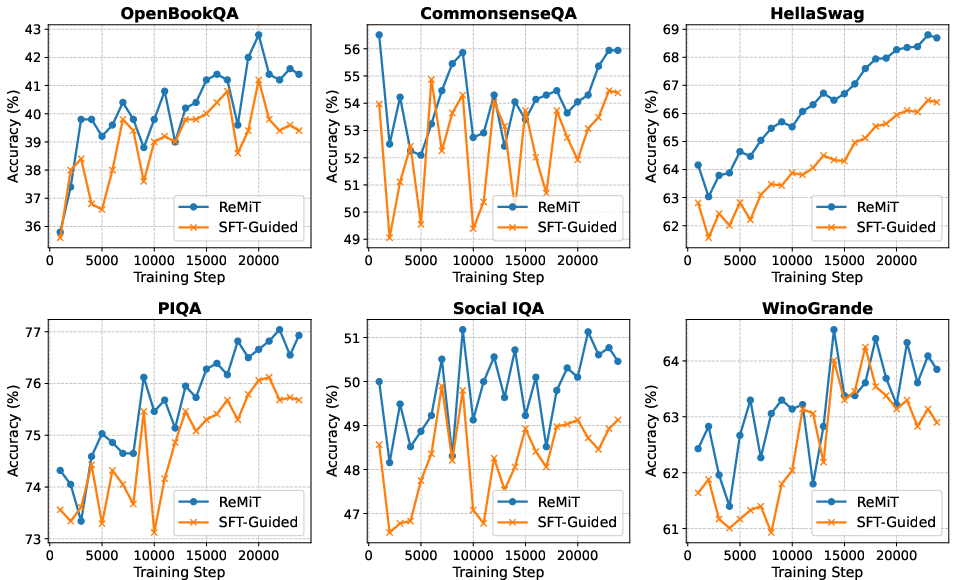
Figure 7: ReMiT outperforms SFT-guided baselines during OLMo-1B mid-training.
Strong ablation studies further validate (1) the necessity of using the RL model (as opposed to SFT) as the reference, (2) the relevance of the clipping mechanism to prevent gradient instability and preserve syntactic/semantic quality, and (3) the positive correlation between RL reference quality and downstream performance (Figure 8).
Efficiency analyses confirm that the extra forward pass required for the fixed RL reference is amortized by the substantial speedup in sample efficiency—ReMiT achieves a 3.3x reduction in total GPU hours to convergence (Figure 9).
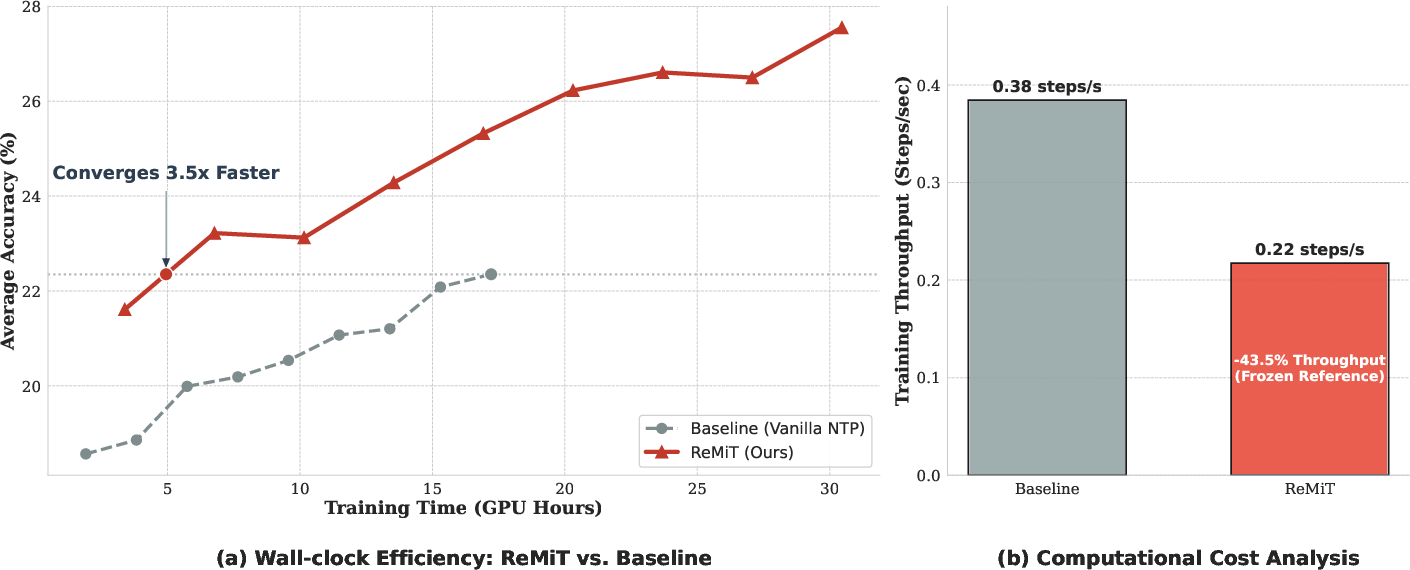
Figure 9: Wall-clock efficiency: ReMiT’s rapid convergence (3.3x speedup) offsets computational overhead.
Practical and Theoretical Implications
Practically, ReMiT offers a drop-in improvement to standard LLM pipelines, requiring neither specially trained teachers nor data filtering steps that reduce sample diversity. By confining intervention to a short, high-impact annealing phase, it circumvents catastrophic forgetting and preserves pre-training efficiency for large-scale corporate deployments.
Theoretically, this work demonstrates that model evolution can be rendered cyclical, not just sequential, with each training stage informing and enhancing the others. ReMiT’s general framework—dynamic, reference-aware weighting—can be further explored using alternative reference policies or additional reward structures, suggesting a generalizable path for progressive self-improvement across generations of LLMs.
Conclusion
ReMiT formulates and validates a systematic method for leveraging RL-tuned models to retroactively enhance the base foundation of LLMs during mid-training. Its dynamic, token-level reweighting both preserves contextual coherence and amplifies high-order reasoning capability. Empirical results demonstrate large and persistent gains in both training efficiency and downstream task performance, substantiating the effectiveness of a bi-directional, iterative evolution strategy for LLMs. This paradigm opens promising avenues for lifelong enhancement of generative models through seamless pre-training/post-training integration.